基于SSA-LSTM的瓦斯浓度预测模型
2024-03-15兰永青乔元栋程虹铭雷利兴罗化峰
兰永青, 乔元栋, 程虹铭, 雷利兴, 罗化峰
(1.山西大同大学 煤炭工程学院,山西 大同 037003;2.山西大同大学 建筑与测绘工程学院,山西 大同 037003)
0 引言
瓦斯是煤矿生产的关键致灾因素之一,与瓦斯窒息、瓦斯燃烧、瓦斯爆炸、煤与瓦斯突出等事故息息相关。瓦斯浓度是一种随时间变化的高动态、非线性时间序列数据,并受煤层赋存、采煤工艺、抽采工艺、风流等多种因素影响[1],充分挖掘瓦斯浓度的时序性规律,实现瓦斯浓度精确、高效预测,对于预防瓦斯事故、保障煤矿安全生产具有重要意义。国内外学者最先采用统计学方法开展瓦斯浓度预测,如支持向量机[2-5]、自回归积分滑动平均模型[6-7]等,这类预测模型结构较简单,难以挖掘具有高度非线性的瓦斯浓度时序数据中隐含的相关特性。随着人工智能技术的不断发展,国内外学者将适用于大数据分析的深度学习方法应用到瓦斯浓度预测中,如循环神经网络(Recurrent Neural Network,RNN)模型[8]、基于长短期记忆 (Long Short-Term Memory,LSTM)网络的预测模型[9-12]、基于门控循环单元(Gated Recurrent Unit,GRU)的预测模型[13-14]等。这些研究方法极大地提高了瓦斯浓度预测精度,但尚未取得令人满意的结果,原因在于部分模型易发生过拟合现象,预测精度和效率受限。针对该问题,学者们采用蝗虫算法[15]、遗传算法[16]、鲸鱼算法[17]等优化深度学习模型对瓦斯浓度预测模型进行改进,在一定程度上改善了预测效果。
麻雀搜索算法(Sparrow Search Algorithm,SSA)是根据麻雀觅食并躲避捕食者的行为而提出的群智能优化算法,由于添加了侦察预警行为,其收敛速度很快。SSA在温度预测、IGBT时间序列预测等方面的应用取得了良好的预测效果[18-20]。基于此,本文首先对比测试了SSA与灰狼优化 (Grey Wolf Optimization,GWO) 算法、粒子群优化(Particle Swarm Optimization,PSO)算法的性能差异,然后利用SSA优化LSTM网络,提出一种基于SSA-LSTM的瓦斯浓度预测模型,采用实测数据进行了预测验证。
1 基于SSA-LSTM的瓦斯浓度预测模型
1.1 LSTM网络模型
LSTM网络是RNN的一种特殊实现,其主要改进了RNN中的隐藏层,在隐藏层中增加了3个门控制单元控制自循环,解决了RNN不能捕获长期依赖关系的问题。LSTM网络结构如图1所示。

图1 LSTM网络结构Fig.1 Structure of long short-term memory LSTM network
1) 遗忘门使用Sigmoid激活函数将上一时刻的记忆细胞与当前t时刻的输入转化为0~1的数值,0表示丢弃所有信息,1表示保留所有信息。该数值决定多少信息被保留。遗忘门ft计算公式为
式中:σ为Sigmoid函数;Wf为遗忘门的权重矩阵;ht-1为输出神经元;xt为当前时刻的输入神经元;bf为遗忘门偏置项。
2) 输入门有2个部分:第1部分是Sigmoid层,决定了更新记忆细胞的状态;第2部分是tanh层,创建1个新的候选记忆细胞状态。输入门It计算公式为
式中:WI为输入门权重矩阵;bI,bc分别为输入门与细胞状态的偏置项;为备选更新信息;tanh为激活函数;Wc为记忆细胞权重矩阵;Ct为记忆细胞状态。
3) 输出门决定单元状态输出值。先利用Sigmoid层确定哪部分被输出,再通过tanh处理并将其与Sigmoid函数的输出相乘。输出门Ot计算公式为
式中:W0为输出门权重矩阵;b0为输出门偏置项。
1.2 SSA及性能测试
SSA是一种模拟自然界麻雀群体觅食和寻找最佳栖息地的群智能优化算法,麻雀作为算法的主角,其只有1项属性:位置,即表示其所寻觅食物的所在方位。对于每个麻雀个体,其可能存在以下3种状态:① 充当发现者,带领种群寻觅食物。② 作为追随者,追随发现者觅食。③ 作为警戒者,具备警戒机制,发现危险,放弃觅食。
发现者位置计算公式为
式中:为种群中第j代第i只麻雀在第d维的位置;α为(0,1]的随机数;T为最大迭代次数;R2,S分别为预警值和安全阈值,R2∈[0,1],S∈[0.5,1];Γ为服从标准正态分布的随机数;L为1×d的矩阵,矩阵内元素均为1。
当R2≥S时,部分麻雀发现捕食者,并向其他麻雀发出警告;当R2<S时,表示当前环境周围没有捕食者,可继续扩大搜索范围。
追随者位置计算公式为
式中:为第j次迭代时麻雀在第d维的最劣位置;n为种群大小;为第j+1次迭代时麻雀在第d维的最优位置;A+为1×d的矩阵,矩阵内元素随机赋值为1或-1。
当i>n/2时,表明该追求者没有获得食物,存活率较低,需飞往其他区域觅食来获取足够能量。
警戒者位置计算公式为
式中:为当前全局最优位置;β为步长控制参数;Fi为第i只麻雀的适应度;Fg和Fw分别为麻雀种群当前最优和最差适应度;K为麻雀移动方向,其值为[-1,1]的随机数;δ为接近0的常数。
当Fi>Fg时,表示麻雀处于群体活动的边缘地带,易受到袭击;当Fi=Fg时,表示麻雀已经感知到危险,需尽快向其他麻雀靠拢,以减少被捕食的风险。
采用CEC2005函数集中的Quartic,Generalized,Kowalik's函数对SSA进行性能测试,种群规模为30,最大迭代次数为500。采用GWO,PSO算法对比验证SSA在收敛速度、搜索精度及适应能力等方面的优势。适应度曲线对比如图2所示。可看出,在测试函数Quartic、Kowalik's中,3种优化算法最终都能够收敛,其中SSA的收敛速度最快,GWO次之,PSO最慢;在Generalized函数中,仍是SSA的收敛速度最快,可看到SSA在寻优精度和收敛速度方面均优于GWO和PSO,证明了SSA的高效性、稳定性。
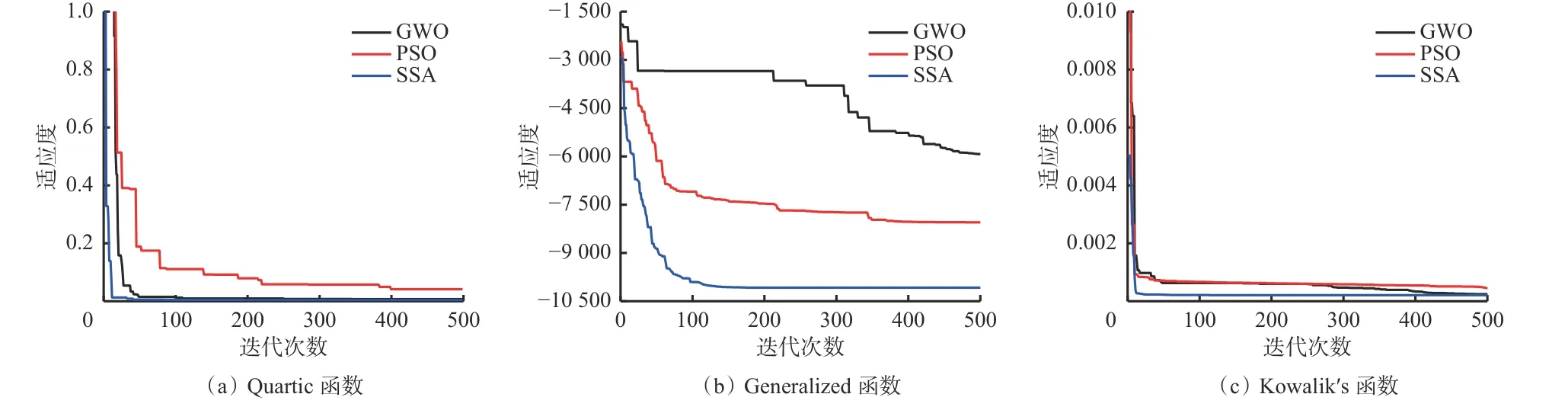
图2 适应度曲线对比Fig.2 Comparison of fitness curves
1.3 SSA-LSTM瓦斯浓度预测模型
采用SSA算法改进LSTM网络模型,构建瓦斯浓度预测模型,其流程如图3所示。

图3 基于SSA-LSTM的瓦斯浓度预测模型Fig.3 Gas concentration prediction model based on sparrow search algorithm(SSA)-LSTM
1) 在数据预处理中,为解决由传感器造成的数据缺失、异常波动等情况,先采用均值法对缺失数据进行插值,再采用小波变换对异常波动数据进行降噪处理,最后对得到的数据集进行归一化处理。归一化公式为
式中:Yt′为归一化后瓦斯浓度数据;Yt为归一化前瓦斯浓度数据;Y为单个瓦斯浓度数据;minY,maxY分别为样本数据中的最小值、最大值。
2) 构建基于LSTM网络模型的基础框架,采用均方误差(Mean Squared Error,MSE)作为模型预测评价指标,MSE越小,模型预测的准确度越高。MSE计算公式为
式中:N为测试集中的样本个数;Z(m)为测试集的真实值;(m)为预测值。
3) 初始化SSA中的种群数量、最大迭代次数等相关参数,然后利用SSA的自适应性依次对LSTM网络超参数进行寻优,直到满足条件,输出最佳超参数组合。
4) 将得到的最佳超参数组合代入LSTM网络模型中,完成最终预测并输出预测结果。
2 模型参数寻优
2.1 实测数据及处理
实测数据来自同煤大唐塔山煤矿综放工作面瓦斯日常监测数据,该矿主采石炭系3-5号煤层,平均煤厚为15.8 m,平均倾角为5°左右,煤层瓦斯含量为1.6~1.97 m3/t,设计生产能力为15 Mt/a,采用一井一面生产方式。工作面走向长度为2 500 m左右,倾斜长度为240 m左右,采用U型通风,最大通风量为3 500 m3/min,平均瓦斯涌出量为36.75 m3/min,呈典型的“低赋存,高涌出”的状况。该工作面瓦斯涌出主要以采空区为主,占总涌出量的82%左右,采用顶板专用巷治理邻近层和采空区瓦斯,回风巷瓦斯体积分数可控制在0.4%以下。瓦斯浓度数据每分钟采集记录1次,共获取12 000条数据。为提高预测精度,对原始数据集进行预处理。
由于实测数据容易受到复杂的井下环境影响,数据集存在异常及缺失现象,并包含一定噪声,所以需要对数据集进行预处理。由于瓦斯浓度作为时序数据在时间上有天然连续性,且一般情况下数据较平稳,故采集的瓦斯浓度时序数集中缺失和异常数据较少,于是利用缺失数据与异常数据前后间隔30 min数据的平均值进行替换。
原始数据集中的噪声会降低预测的准确性,为保证数据的平滑性,采用小波阈值进行降噪处理,主要步骤如下。
1) 选取sym8小波基、5层分解层对瓦斯浓度数据进行分解[21-23],对含噪信号进行相应层分解,然后对瓦斯浓度数据进行小波变换,将原始数据集转换为小波域,利用分解信号将其分解为不同频率的子信号。
2) 选取合适阈值,保留信号的信息并去除噪声。阈值的选取对降噪质量有很大影响,若阈值过小,则去噪效果不理想;若阈值过大,容易导致信号失真。目前使用最多的是固定阈值:
式中:s为含噪信号中噪声的方差;a为信号的采样长度;median(·)为中值函数;BJ,k为小波系数,J,k为分解层数。
3) 对小波系数进行阈值处理,根据选取的阈值类型和大小,将小于阈值的系数置零。
4) 通过逆小波变换将处理过的小波系数转换回时域,得到最终降噪后的瓦斯浓度时间序列数据。预处理前后的数据对比如图4所示。
2.2 SSA参数确定
将构建好的LSTM网络基本框架输入到SSA中,SSA最小搜索维度为5,最大搜索维度为8;麻雀种群数量为6,最大迭代次数为8,优化参数个数为3;将MSE作为适应度函数F的值。寻优结果SSA搜索维度为6;麻雀种群数量为5,最大迭代次数为3;利用SSA自适应性觅食行为找到的最优位置为[0.008 9,27,0.047 9]。
2.3 LSTM网络模型超参数寻优
根据经验值确定初始超参数,选取MSE作为损失函数评价值,利用Matlab软件得到不同算法优化后LSTM网络模型的训练损失曲线,如图5所示。可看出在迭代100次时所有曲线都已接近平稳,所以接下来调整超参数时将模型训练的迭代次数设置为100。
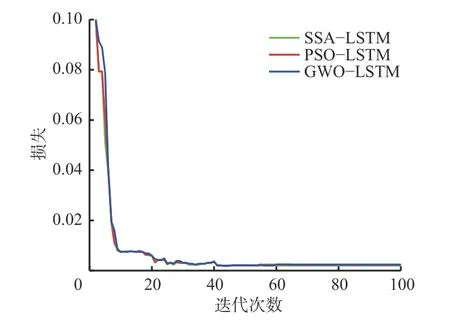
图5 不同模型训练损失曲线Fig.5 Training loss curves of different models
选取模型的均方根误差(Root Mean Squared Error,RMSE)、平均绝对误差(Mean Absolute Error,MAE)作为评价指标,分析不同学习率、隐藏层节点个数、正则化参数对模型预测效果的影响。
1) 学习率控制了权重更新的步长,学习率的取值一般控制在0.001~0.1。学习率取值过小,会导致模型过拟合;学习率取值过大,会使损失函数震荡不收敛。学习率对模型预测效果的影响如图6所示。
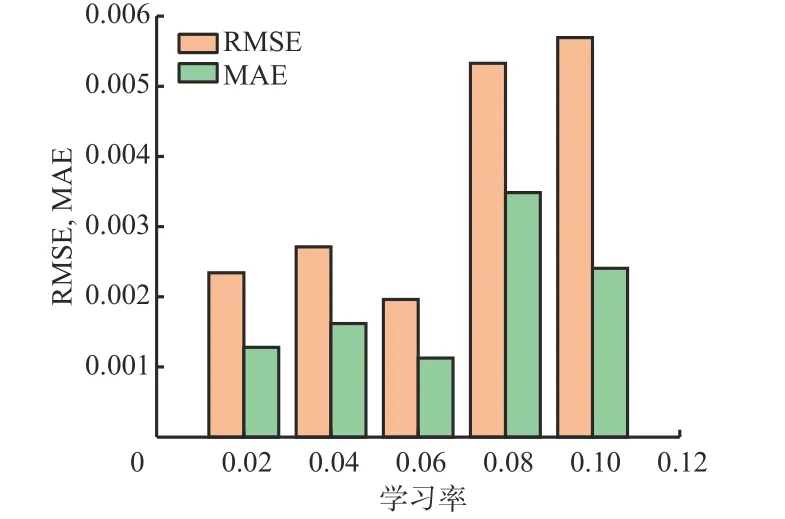
图6 学习率对模型预测效果的影响Fig.6 The influence of learning rate on model prediction performance
2) 隐藏层节点个数决定了LSTM网络模型的复杂度和表达能力。节点数过少,会导致无法满足训练要求;节点数过多,会使得模型结构过于复杂,导致训练时间过长。通过SSA搜索最佳的隐藏层节点个数,来提高模型的预测准确性。隐藏层节点个数对模型预测效果的影响如图7所示。

图7 隐藏层节点个数对模型预测效果的影响Fig.7 The influence of the number of hidden layer nodes on model prediction performance
3)正则化参数可降低LSTM网络模型的复杂度,提高模型的泛化能力,防止出现过拟合现象。正则化参数对模型预测效果的影响如图8所示。
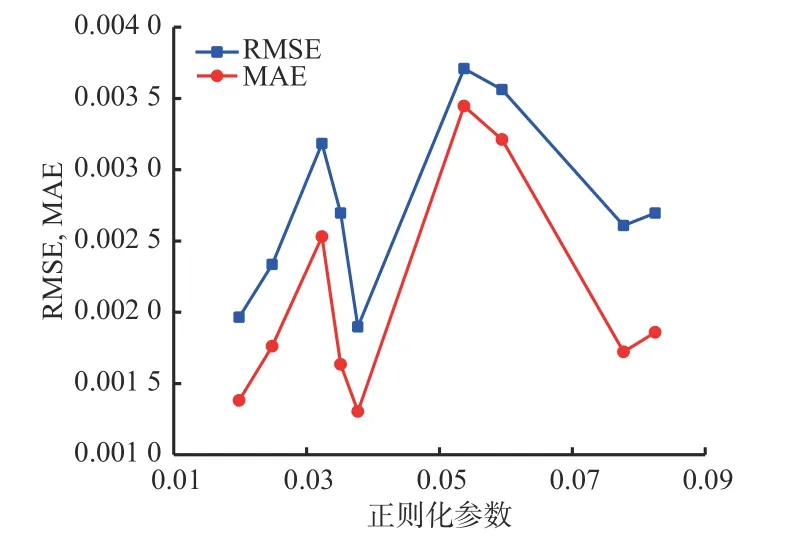
图8 正则化参数对模型预测效果的影响Fig.8 The influence of regularization parameters on modelprediction performance
最终确定LSTM网络模型的超参数组合见表1。

表1 不同预测模型超参数选择Table 1 Selection of hyperparameters for different prediction models
3 预测结果分析
3.1 SSA-LSTM模型预测结果
将预处理后的瓦斯浓度数据集根据常用的划分原则,按8∶2的比例划分为训练集和测试集。同时,把利用SSA寻优得到的最佳超参数组合输入到LSTM网络预测模型中,对未来采煤工作面的瓦斯浓度进行预测。为了验证采用SSA对传统LSTM网络模型超参数优化后预测精确度的提升,将传统LSTM网络模型预测结果和SSA-LSTM模型预测结果进行对比分析,结果如图9所示。
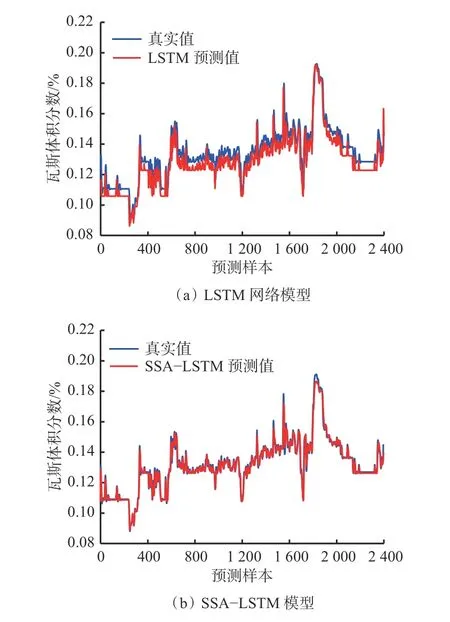
图9 LSTM网络和SSA-LSTM预测结果对比Fig.9 Comparison of prediction results between LSTM network and SSA-LSTM
由图9可知,经SSA优化后的LSTM网络模型预测精度有很大提高,数据的拟合效果也较好,与传统的LSTM网络预测模型相比,RMSE减小了77.8%,MAE减小了83.9%,证明了基于SSA-LSTM的瓦斯浓度预测模型在提高预测精度方面的有效性。利用SSA算法对LSTM网络模型超参寻优避免了模型易陷入数据过拟合的弊端,提高了模型预测性能。
3.2 不同模型预测结果对比分析
为了验证本文所提瓦斯浓度预测模型的高效性,同时避免预测模型的单一性及片面性,采用PSO-LSTM、GWO-LSTM与SSA-LSTM模型的预测结果进行对比分析,各模型预测结果对比如图10(a)所示。将测试集中波动较大的部分数据点(样本序号为1 600—2 400)的预测结果局部放大,可更加清晰地展示各模型预测性能差异,如图10(b)所示。

图10 不同模型预测结果对比Fig.10 Comparison of prediction results of different models
从图10可以看出,SSA-LSTM模型预测效果最佳,预测值更加接近真实值。GWO-LSTM模型次之,接下来是PSO-LSTM,进一步验证了SSA优化LSTM网络的瓦斯浓度预测模型具有更高的预测准确性、稳定性。
采用RMSE、MAE、运行时间、R2对PSO-LSTM、GWO-LSTM、SSA-LSTM模型的预测性能进行对比,结果见表2。由表2可知,SSA-LSTM模型的RMSE较PSO-LSTM,GWO-LSTM模型分别减少了58.9%,69.7%;SSA-LSTM模型的MAE较PSO-LSTM,GWO-LSTM模型分别减少了37.8%,70%;综合R2、运行时间等评价指标来看,SSA-LSTM模型的预测精度最高,运行时间相对较短,取得了良好的预测效果。

表2 不同模型预测结果评价Table 2 Evaluation of prediction results of different models
4 结论
1) 采用3种不同的测试函数对SSA进行了性能测试,同时与PSO算法和GWO算法进行了对比,结果验证了SSA在寻优精度、收敛速度和适应能力等方面的优势。
2) 针对高度动态和非线性瓦斯浓度预测问题,本文提出一种利用SSA对LSTM网络结构超参数进行优化的方法,该方法避免了预测模型陷入局部最优情况。相较于传统LSTM网络模型,SSA-LSTM模型预测精度更高,预测效果更好。
3) 对比LSTM,PSO-LSTM,GWO-LSTM与SSALSTM模型的预测性能,得出SSA-LSTM模型的预测效果最好,与其他模型相比,RMSE减少了58.9%~77.8%,MAE减少了37.8~83.9%。SSA-LSTM模型相较于其他预测模型拥有更高的预测精度,可为煤矿瓦斯灾害防治提供有效决策支持。
