基于异构平台的图像中值滤波的OpenCL加速算法
2024-03-15肖诗洋王镭杜莹肖汉
肖诗洋,王镭,杜莹,肖汉
(1.东南大学 土木工程学院,江苏 南京 211189;2.郑州师范学院 信息科学与技术学院,河南 郑州 450044;3.郑州师范学院 地理与旅游学院,河南 郑州 450044)
外界环境、传感器件的质量等各种因素会对图像在采集、传输和存储的过程中产生干扰.引入的噪声致使图像质量下降,会严重影响图像后续处理的效果.因此,为抑制图像的噪声,在图像预处理中需要对图像去噪.噪声消除是蜂窝移动通信、图像处理、雷达、声纳及其他应用中需要解决的主要问题之一[1].
目前图像去噪方法有很多种,图像的噪声可根据噪声类型选用空间域方法或变换域方法进行去噪,如中值滤波器、形态滤波器、高斯滤波器等.基于排序统计理论的中值滤波器是一种非线性数字滤波器,常用于消除图像中的脉冲噪声或椒盐噪声.语音、图像和数字信号处理中的平滑操作可用中值滤波实现.非线性中值滤波器既可以有效地消除脉冲干扰和随机噪声,又可实现对图像的边缘信息的充分保留.在大数据技术的推动下,数字图像分辨率快速提高,对图像处理算法的实时性和处理效率都提出了较高的要求.因此,探索高效快速的图像处理方法和理论,是提高应用系统能力的重要需求,也是对图像处理技术发展提出的科学难题之一[2].
利用现场可编程门阵列(field programmable gate array,FPGA)或数字信号处理器(digital signal processor,DSP)实现实时图像中值滤波处理,要求增添额外的硬件,系统的复杂度和费用会增加.随着将多核CPU处理单元引入到并行系统,需要对多核CPU中的每个CPU内核进行编程.该方法操作繁琐,编程量大.近年来,在科学计算和工程计算领域中的加速已广泛运用图形处理器(graphics processing unit, GPU),较于CPU,GPU提供了更强劲的计算能力和更大的数据读写带宽.统一计算设备架构(compute unified device architecture,CUDA)使研究人员可以对GPU进行更高效的编程,GPU的软件生态环境得到了质的提升.但CUDA系统只适用于NVIDIA系列的GPU.面向异构系统结构的开放、免费的并行编程标准开放式计算语言(open computing language,OpenCL)则可适用于任意一种并行处理器.OpenCL支持CPU、GPU、FPGA等并行处理器,拥有独特的任务并行执行模型,特别有利于支持异构计算[3].
图像中值滤波算法是一种计算密集型算法,算法的中值滤波处理对算法的性能造成很大的影响.随着图像像素数据量的增大,算法的计算量迅速增长,进而大幅增加了算法处理时间,算法性能成为亟待解决的问题.而异构计算成为改善算法性能的一种很好的解决方案.本研究将采用OpenCL编程模型,围绕单GPU对中值滤波算法的并行化、算法的深度优化和多种并行计算方案的比对研究等问题展开.
1) 提出了一种基于OpenCL的图像中值滤波并行算法.该算法既具有29.74倍加速比的高速去噪功能,又能够很好地在不同GPU平台中实现可移植性.
2) 采用了多元化的性能对比标准.本文在多种并行计算平台上实现了对图像中值滤波的处理,测试了3种并行方式对算法性能的影响.将基于OpenCL的中值滤波(OpenCL-based median filtering, OCL_MF)并行算法、基于OpenMP的中值滤波(OpenMP-based median filtering, OMP_MF)并行算法、基于CUDA的中值滤波(CUDA-based median filtering, CUDA_MF)并行算法以及相关文献的算法进行性能比较,从横纵2个方向的性能比较看出,OCL_MF并行算法均取得了较好的性能提升.
1 相关研究
经过多年的不懈努力,图像中值滤波算法在算法优化上取得了不少的成果.Zhao等[4]通过改进的加权中值滤波器,在GPU上实现了快速的纹理过滤.PANG等[5]提出了一种自适应中值滤波器去除图像中的随机值脉冲噪声,易于并行处理的实现.Liu等[6]通过并行随机电路的硬件实现了大量随机数排列,提高了中值滤波处理效率.Cadenas等[7]研究了一种快速寻找中位数的方法,用于中值滤波算法,提高了降噪效率.Oded[8]设计了基于GPU直方图运算的中值滤波软件并行可扩展算法,提高速度60倍.李余钱等[9]通过基于FPGA的中值滤波算法确定自适应阈值来实现Sobel边缘检测的方法,提高了系统的实时性.Sachin等[10]提出了一种基于single rogram multiple data (SPMD)的分时处理的中值滤波算法,相比基于remote method invocation (RMI)方式的分布系统性能更佳.刘佳等[11]提出了一种多处理器NoC结构的中值滤波算法,处理速度提高了3.6倍.陈思润等[12]使用ARM硬件架构的Cortex-A处理器,运用SIMD数据级并行计算技术NEON实现了中值滤波并行算法,速度提高了17倍.Zhao等[13]提出了一种基于GPU的实时加权中值滤波器,提高了算法的执行效率.Mao等[14]设计了基于GPU的加权中值滤波算法,应用于油气勘探数据处理平台,获得了4倍加速比.廖文献等[15]在Cortex嵌入式多处理器系统上进行了图像中值滤波算法的并行化,速度提高了近4倍.Mursaev等[16]设计了一种基于FPGA的二维中值滤波器,提高了处理速度.张怡卓等[17]设计了基于FPGA硬件的并行中值滤波算法,获得了3.68倍加速比.Vivek等[18]提出了基于具有深度流水线的FPGA的中值滤波算法,提高了去噪速度.
总之,上述研究工作在中值滤波算法方面取得了很多进展.有些通过改进中值滤波算法来提高去噪速度,有些提出了基于FPGA、ARM和GPU等计算平台的并行算法,应用于实际系统中提高处理速度,有些是在特定硬件平台上加速中值滤波算法的处理效率.然而,各种加速算法的性能提高效果不理想,特别是这些加速算法都不具有平台独立性特点,只能在特定的硬件平台或应用中实现性能提升.本文拟分析图像去噪中经典的中值滤波算法,利用热点分析法将耗时最长的功能模块从中值滤波算法中找出.从而使用OpenCL对这些功能模块进行GPU并行化.借助GPU在大规模并行运算上的优势,实现对中值滤波算法的CPU+GPU协同计算,有效缩短算法执行时间和实现算法在不同GPU计算平台上的性能移植.
2 算法的研究与分析
2.1 算法基本过程
中值滤波器作为一种非线性滤波器,是一种基于排序统计理论的有效抑制噪声的非线性信号处理技术[19].1970年Tukey提出了中值滤波器并在一维信号处理技术中应用,后又被二维图像信号处理技术采用.在一定条件下,它可较好地克服平均值滤波、最小均方滤波等线性滤波器所产生的图像细节模糊问题,对降低脉冲干扰及图像扫描噪声非常有效[20].
中值滤波算法是指用像素点邻域内的所有像素点的灰度值的中位数代替像素点的灰度值,为了保证取中位数的便利性,邻域内的像素点的数目必须是正奇数,可用式(1)来表示.
(1)


图1 3×3滤波窗口Fig.1 3×3 filtering window
中值滤波的具体实现步骤如下:
1)在图像中遍历所有像素点,并以每个像素点为中心形成一系列中值滤波窗口;
2)将滤波窗口内的各个像素的灰度值读取出来;
3)把这些灰度值进行大小排序;
4)将这些灰度值的中位数赋给对应滤波窗口中心位置的像素,作为最终的输出结果.
2.2 算法热点分析
对于像幅大小为height×width的图像进行的中值滤波算法主要包括以下模块:1) 扩充图像功能.拓展过程要求在左右方向进行原图像拓展和上下方向拓展原图像.该过程的时间复杂度为O(height×width+height×MODELDIM/2+width×MODELDIM/2.2)图像中值滤波功能.需要将图像中所有像素点的邻域进行中值滤波处理,需要执行height×width次,其时间复杂度为O(height×width).同时提取滤波窗口覆盖下图像子块中像素点的灰度值,其时间复杂度为O(MODELDIM2/4).在图像子块中的灰度值进行排序,时间复杂度为O(MODELDIM4).由此可得,图像中值滤波算法的时间复杂度为O(height×width×MODELDIM4),模块2)是该算法的核心环节.
为实现图像中值滤波算法的并行化,首先针对基于CPU的中值滤波(CPU-based median filtering, CPU_MF)算法进行热点分析,定位算法的耗时步骤.CPU_MF算法在进行热点分析时,是在像幅大小为5 471×5 682的图像上进行测试,采用bmp图像格式.将clock()函数插入到CPU_MF算法各主要步骤之间进行时间测试,获得各主要步骤运算前后的时间点值,通过计算得到CPU_MF算法主要步骤的时间统计和整个算法的运行时间.
从表1中可以看出,图像中值滤波算法耗时主要集中在第2步.该步骤运行时间占串行算法总执行时间的百分比为90.47%,其他函数处理时间只占据了不到1 s的时间,说明图像中值滤波步骤是串行算法的性能瓶颈所在.如果采取一定并行措施大幅降低中值滤波模块的处理时间,算法就可以获得良好的加速效果.

表1 图像中值滤波算法各步骤运行时间及占比
2.3 算法可并行化
算法自身存在的任务依赖性影响着算法的可并行性.关联性越低的任务,其并行效果越好,反之则效果越差.中值滤波计算过程需要改进,以适合GPU的并行计算架构的特点,并能够充分利用GPU的各种具有各自优势的存储器.本文在图像边界处理时,将待处理的原图像矩阵行和列各补MODELDIM/2行和MODELDIM/2列.扩展处理图像后,所有待处理像素矩阵均处于扩展图像像素矩阵的内部.此时对于每个像素点的处理均可采用一致的算法实现,避免了分支处理,实现过程的高度统一得以保证,算法的并行潜力进一步提高.因此,可以分析得出图像中值滤波功能具有三级并行性:
1)像素级并行:椒盐噪声是以黑白点的形式叠加在图像上,去噪则要对图像中每个像素点的灰度值进行变换处理,这种任务具有相互独立适于并行的特点.
2)图像区域中值排序级并行:像素点邻域中图像数据排序和计算中值任务相互独立,适于并行执行.
3)窗口级并行:对每个滤波窗口覆盖下的图像域处理任务相互独立,适于并行处理.
中值滤波算法的并行性如图2所示.图2a中绿色区域为原始图像待处理区域,局部处理时邻域大小为3×3,白色区域为扩充图像区域.像素点用方块代表.在中值图像滤波处理中,若对像素点A进行处理,即将子图像块1中的数据提取出来,进行数据排序和A像素点的灰度值处理等操作.然后依次对像素点B、C…X、Y进行处理.由于一系列子图像区域之间没有相互依赖性,所以,中值图像滤波算法适于并行化处理.
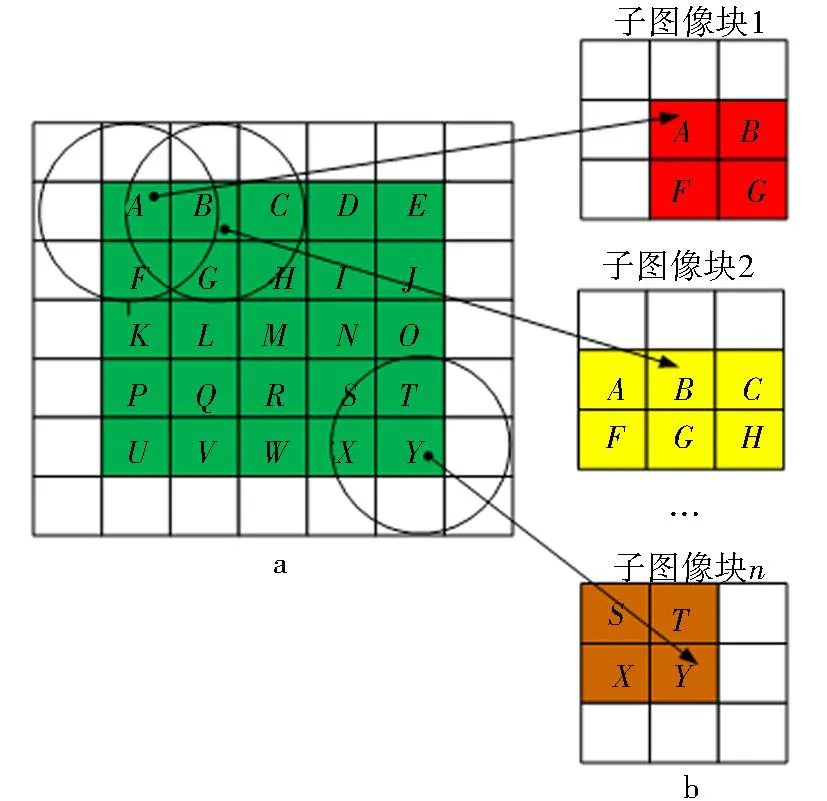
a.扩充图像;b.像素点邻域
由此可见,图像中值滤波算法的计算量非常大并且又具备很强的并行性.因此,算法适合利用GPU计算平台进行大规模并行计算.针对以上分析,本文设计实现了图像中值滤波算法在OpenCL计算平台上的naive版本.采用OpenCL的多工作项对图像中值滤波功能部分进行并行计算,一个工作项负责计算一个像素点邻域的中值,如果系统启动w个工作项,则算法的计算时间复杂度降为O((height×width×MODELDIM4)/w).
3 图像中值滤波算法的OpenCL实现
3.1 算法的加速策略
3.1.1 GPU核函数的设计与实现
设计内核的索引空间,将工作组和工作项的大小确定下来,即设定处理单元和计算单元的大小进行并行计算.主要实现提取像素点邻域灰度值,滤波窗口内像素值的冒泡排序和计算邻域中位数并更新至像素点.详细设计如下:

2) 在采用OpenCL并行设计时,采用2层并行模式.将整幅图像在逻辑上划分成个子图像块,网格中的一个工作组对应处理图像中的某个子图像块,即为粗粒度并行.NDRange索引空间中的工作项依据索引地址和滤波窗口大小,提取位于全局存储器中相应像素点邻域的灰度值.邻域像素值用冒泡法进行排序,计算得到邻域像素点的中位数,并将相应更新的灰度值数据写入主存空间的像素点,即为细粒度并行.图像中值滤波并行设计如图3所示.

图3 计算空间并行化划分Fig.3 Parallel partition of computational space
3) 粗粒度的工作组并行和细粒度的工作项并行组成了OCL_MF并行算法计算架构.粗粒度并行存在于同一N-NDRange索引空间内众多工作组之间,工作组之间无需进行数据交换和通信.这样,系统获得了可扩展性:由于在任意一个计算单元上都可以执行工作组子任务,所以,在核心数量不同的GPU上都能正常运行OCL_MF并行系统.细粒度并行存在于同一工作组内的工作项之间,同一工作组内的工作项之间可以进行数据交换和通信.因此,工作组中的不同工作项可通过(work_group_barrier)进行同步处理.
在OpenCL的执行模型中,需要满足以下3个方面的限制:1)一个计算单元能够支持并行运行工作项总量的限制;2)一个计算单元能够支持并行运行工作组总量的限制;3)一个工作组能够支持并行运行工作项总量的限制.一个计算单元所能并行运行的工作项总数是确定的,为了获得OCL_MF算法的最大并行计算效率,工作组中所包含的工作项数目的设计至关重要.在对OCL_MF并行算法进行GPU实现的过程中,采用计算能力为5.0的GPU.其每个计算单元最多可以激活的工作项数目为2 048.在warp中1次可调度32个工作项,因此,为了提高并行效率,1个工作组容纳工作项数应是32的倍数.同时鉴于工作组中寄存器等资源的限制,设计工作组的大小为16×16=256.256小于工作组中对最大工作项数1 024的限制.每个计算单元将执行2 048/256=8个工作组,小于在计算单元上至多激活工作组数32的限制.因此,GPU中的所有工作项和工作组都同时处于并行计算状态.
公民性缺失抑或制度供给不足?—对我国社区参与困境的微观解读……………………………徐 林 徐 畅(32)
3.1.2 工作项坐标的索引机制
图像中值滤波器是用待处理像素相邻范围内的几个像素的中位数来代替该点的像素值.对一个子图像块数据进行中值滤波处理时,对图像块中每个像素数据的处理是无任何数据相关的.因此,可以将对每个像素数据的处理映射到工作组的相应工作项中.每个工作组中的工作项均可获得二维ID索引位置,将相应像素点的邻域数据调度到处理单元中处理.像素点和工作项之间的位置映射关系,如下所示:
workItemx=get_local_id(0)+get_group_id(0)*get_local_size(0),
(2)
workItemx=get_local_id(1)+get_group_id(1)*get_local_size(1),
(3)
其中,get_local_id(0)和get_local_local_id(1)分别为工作项在工作组中在x和y方向上的索引号.get_group_id(0)和get_group_id(1)分别为工作组在索引空间中在x和y方向上的索引号.get_local_size(0)和get_local_size(1)分别为工作组在x和y方向上的维度.
3.2 优化设计
3.2.1 设备与主机间的通信优化
减少在设备和主机之间的数据传输是OCL_MF并行滤波算法的设计关键.由于设备与主机间的数据传输带宽远低于设备之间的数据传输带宽,若设备和主机之间数据传过于频繁,系统将陷入传输瓶颈而不能充分发挥GPU的并行计算能力,计算效率降低.为了降低传输数据频度,OCL_MF把中值滤波功能中的全部计算任务全部映射到GPU中.一方面减少了中间数据在设备和主机之间的传入传出操作,另一方面一次性在设备和主机之间进行图像数据传输.这种设计大大缩减了传输次数,GPU的计算能力得到充分利用,计算密集度提高.
3.2.2 工作组资源配置优化
在OpenCL框架中,系统定期在不同warp间进行切换以进行工作项调度,以满足对计算单元中计算资源的充分利用.同一指令是在同一warp中的32个工作项间一同执行,因此,每个工作组中工作项数量应是32的整数倍,每个维度上的大小将根据任务量的情况确定.表2显示了像幅大小为3 241×3 753时,系统中设置不同数量工作项时的运行时间.由表2可见,采用16×16的工作组维度时,系统性能最佳.

表2 工作组维度对运算速度的影响
4 实验环境与实验设计
4.1 实验环境
1)硬件平台.选取2个不同计算平台的目的是验证性能可移植性.CPU系统均为具有六核心的Intel Core i7 8700,主频为3.2 GHz,系统存储器为16.0 GB.2种GPU计算平台的性能参数如表3所示.

表3 GPU计算平台性能参数
4.2 实验结果
开展多组数据的对比实验,需要对图像数据进行预处理,通过剪裁取得了图像大小分别为640×480、561×762、1 354×1 785、2 265×2 746、3 241×3 753、5 471×5 682、7 215×7 634和8 146×8 357共8组实验数据.
图4a是原始图像,图4b-e分别为用CPU_MF、OMP_MF、CUDA_MF和OCL_MF系统进行处理后的图像.

a.原始噪声图像;b.CPU_MF效果图;c.OMP_MF效果图;d.CUDA_MF效果图;e.OCL_MF效果图
为检验图像中值滤波算法的性能本文共设计4组实验:第1组运行CPU_MF串行中值滤波算法,第2组运行OMP_MF并行中值滤波算法,第3组运行CUDA_MF的并行中值滤波算法,第4组运行OCL_MF并行中值滤波算法.针对测试图像,4组中值滤波系统被多次运行,计算出各组中值滤波算法的平均耗时,数值结果保留小数点后2位,串/并行中值滤波算法执行时间对比如表4所示.

表4 不同计算平台下图像中值滤波算法执行时间
定义加速比
(4)
其中,s为加速比,Ts是CPU_MF串行算法执行耗时,Tp是并行算法执行耗时.
定义相对加速比1 OMP_MF算法运算耗时与基于NVIDIA GPU的OCL_MF算法运算耗时的比值.
定义相对加速比2 CUDA_MF算法运算耗时与基于NVIDIA GPU的OCL_MF算法运算耗时的比值.
为了客观评估系统的性能,采用了加速比以反映并行算法相比CPU串行算法整体速度改善情况.为了测评不同并行算法的性能,采用了相对加速比1以反映基于NVIDIA GPU的OCL_MF算法相比OMP_MF算法的性能改善情况,相对加速比2以反映基于NVIDIA GPU的OCL_MF算法相比CUDA_MF算法的性能改善情况.具体如表5所示.

表5 不同计算平台下图像中值滤波并行算法性能对比
4.3 CPU与GPU结果一致性实验
缩短图像处理时间是中值滤波并行处理的目的,以求得更高图像降噪速度.但是,若以损失图像质量为代价,并行化处理就没有了意义.下面进行图像中值滤波效果分析.
4.3.1 宏观层面结果一致性
如图4可见,原始图像是一组被椒盐噪声污染的图像,图像中均叠加有许多黑白噪声点.原始图像经过串行/并行图像中值滤波处理后,去掉了大部分的黑白噪声点,各幅图像均变得更加平滑,对于去除脉冲型加性噪声效果很好.同时,图像中值滤波算法采用CPU串行实现,OpenMP多线程并行实现,CUDA架构下GPU实现和OpenCL异构平台实现,四者的滤波变换效果一样.
4.3.2 微观层面结果一致性
采用图像灰度值直方图来表示经过串行系统和并行系统处理后的图像数据,如图5所示.对比分析可见,从微观层面上看,中值图像滤波经过串行和并行处理后的图像直方图均一样.

a.串行处理结果;b.OpenMP处理结果;c.CUDA处理结果;d.OpenCL处理结果
因此,从宏观和微观2个层面来看,中值图像滤波串行算法和并行算法虽然在设计方法和执行时间上不同,然而在图像处理的结果仍保持一致,算法的正确性和可行性得到验证.
4.4 实验结果分析
4.4.1 不同计算平台上中值滤波算法运算时间分析
通过对图6的分析可见,当计算规模较小时,中值滤波算法采用GPU并行计算加速效果较为明显,获得了29.74倍的最大加速比.如像幅大小为561×762时,CPU_MF算法计算时间为149.00 ms,OMP_MF算法计算时间为86.61 ms,CUDA_MF并行算法计算时间为5.21 ms,OCL_MF并行算法计算时间为5.01 ms,传统串行方式和多核并行方式的耗时远高于OpenCL并行加速计算耗时.当像幅较大时,CPU_MF算法计算时间呈现近乎直线的上升趋势,耗时急剧增加.OMP_MF算法的计算时间表现出缓慢上升,而GPU并行算法的计算时间则表现出更为平缓的上升.同时,像幅大小超过5471×5682时,GPU并行算法耗时出现了较快的增长趋势.

图6 中值滤波算法运算时间对比Fig.6 Comparison of operation time of median filtering algorithm
GPU设备和CPU主机相互协作完成算法的处理过程,期间大量的数据需要交换.这种数据交换均由PCI-E总线负责完成.但是GPU内部带宽要远高于PCI-E总线带宽.因此,当通过PCI-E总线进行大量的图像数据交换时,受限其速度,算法执行时间变长,GPU加速的效果出现了减缓的趋势.
下面将文献[17]与OCL_MF并行算法的加速效果进行比对.由于多数文献是利用中值滤波算法进行各种应用研究,很少专门针对中值滤波算法进行加速效果的研究.因此,无法直接进行加速效果的对比.根据文献[17]中提供的测试数据,当图像大小为640×480时,文献[17]中基于FPGA加速的中值滤波并行算法的运算时间为6.144 ms,获得了3.68倍性能提高.而由表4和表5的测试结果可知,本文基于OpenCL加速的中值滤波并行算法的运算时间为3.77 ms,获得了5.04倍加速比.因此,本文并行算法的运算时间比文献[17]中的算法短,并取得了更好的加速性能.
4.4.2 并行计算平台上中值滤波算法加速比分析
从图7可以看出,当图像像幅大小在3 241×3 753以内时,OpenMP并行方式的加速比曲线斜率变化不大,而GPU并行方式的加速比曲线斜率也较小;当像幅大小从3 241×3 753扩展到5 471×5 682时,OpenMP加速方式的曲线斜率仍没有明显变化,而GPU加速方式的曲线则出现一个较陡峭的下降;当像幅大小超过5 471×5 682时,OpenMP加速方式的曲线斜率依然是平稳的上升态势,而GPU加速方式的曲线则呈现了缓慢下降的趋势.因此,从图7中可见,随着像幅规模的增加,在像幅大小的各个区间内GPU曲线斜率的变化都较OpenMP方式曲线斜率有明显变化.

图7 中值滤波并行算法加速比趋势Fig.7 Speedup trend diagram of median filtering parallel algorithm
曲线斜率的大小,在一定程度上反映出数据规模与运算时间的关系,即数据规模相同时,曲线斜率越大,说明该计算方式的耗时变化越剧烈.当曲线负斜率较大时,数据规模稍微增加,就导致运算时间的急剧增加.这时数据规模与时间消耗的性价比较低,形成计算效率的低峰期,并且扩展性也较差.
据上可知,基于GPU的中值滤波算法的扩展性不如OMP_MF并行算法,GPU加速方式表现的更容易形成计算瓶颈.然而,GPU拥有的更加丰富的并行计算资源带来了巨大的加速优势.在图像规模增大时,仍然具有远高于OpenMP多核并行计算产生的加速效果.所以,GPU的中值滤波算法的性能更有优势.
由图7可见,OCL_MF并行算法的运算速度远高于OMP_MF并行算法,且随着图像规模的不断增大,速度差距有缩小的趋势.这是由于CPU核心数较少所致,当CPU处于满载情况下,性能提升空间有限.同时线程创建和调度也存在时间开销.而在一定的计算量范围内,OpenCL中每个工作项有大致相同的计算时间,运算时间的增加仅由于更多的工作项和工作组与硬件之间交互造成的必要时间消耗.
图8中相对加速比2表明,像幅较小时,OCL_MF并行算法与CUDA_MF并行算法性能接近.随着图像规模的增大,OCL_MF并行算法性能相比CUDA_MF并行算法稍快,最高获得了1.15倍性能提升.因此,当像幅较大时,OpenCL并行算法有更大性能优势.相对加速比1显示出OCL_MF并行算法与OMP_MF并行算法性能相比有较大提高,最高获得了17.29倍性能提升.同时,随着像幅的增大,两类并行算法的性能差距有逐渐缩小的趋势.当像幅较小时,OpenCL并行算法有更大性能优势.

图8 相对加速比趋势Fig.8 Relative acceleration ratio trend graph
4.4.3 基于OpenCL的中值滤波并行算法可移植性分析
Radeon RX 470采用的AMD 2012年提出的GCN架构,GTX 1070为NVIDIA 2016年提出的Pascal架构.GTX 1070的基础频率是Radeon RX 470的1.63倍,而且前者使用的存储器带宽也比后者更宽,寄存器数量也更多.因此,本文采用的AMD GPU卡性能不如NVIDIA GPU卡,并行算法的性能受到了一定的影响,如图7所示.然而,OpenCL加速的图像中值滤波并行算法在2种GPU平台上均获得了近30倍加速效果.因此,并行算法在异质GPU计算平台上获得了较好的性能可移植性,符合软硬件实际情况.
5 结束语
利用数字图像数据呈规则格网分布和易于并行处理的特点,针对图像中值滤波处理算法核心部分进行了并行方案的设计与实现.算法索引空间的维度能够自适应于图像的规模,对工作组的资源配置和不同设备间的数据传输进行了优化.通过为并行计算任务合理地分配计算单元和处理单元,充分挖掘了GPU的并行计算能力,图像处理的效率得以提高.实验结果显示,在NVIDIA GTX 1070平台上实现的OCL_MF并行算法与CPU_MF串行算法,OMP_MF和CUDA_MF两种并行算法性能相比,加速比分别获得了29.74倍、17.29倍和1.15倍,算法性能得到极大提升.同时,该OpenCL加速的并行算法在AMD Radeon RX 470和NVIDIA GTX 1070平台上均获得了相近的加速比,实现了在异质GPU计算平台间的性能移植.本文提出的基于OpenCL的图像中值滤波并行处理方法能够有效缩短系统运算时间,实时地完成较大像幅的图像中值滤波处理,对其他图像处理应用也具有一定的借鉴意义.
本文研究还有进一步优化的空间,有待做更加深入的探索:拟在GPU集群上将MPI和OpenCL技术相结合,更大图像块之间的并行由MPI完成,图像块内的并行由每个节点上的GPU完成.通过GPU集群将使系统的处理速度更快,以争取在更加短的时间内完成对更大尺寸图像的处理工作.
