信息管理软件自动化测试方法的设计
2024-03-14裘雨音陈江尧
裘雨音 ,张 静 ,陈江尧
(1.国网浙江省电力有限公司,浙江 杭州 310012;2.国网浙江省电力有限公司培训中心,浙江 杭州 310015;3.浙江华云信息科技有限公司,浙江 杭州 310012)
0 引言
信息管理软件产品被大量应用在社会的多个领域,软件产品的质量优劣直接影响软件应用效果与应用寿命[1]。想要确定软件产品的质量,就必须展开软件自动化测试工作[2]。然而,软件测试会耗费较多的人力和时间。自动化测试由于能够优化软件测试质量、保证软件测试效率,目前已成为软件管理领域的研究重点之一[3-4]。
目前,针对信息管理软件自动化测试方面的研究已有许多。文献[5]以虚拟设备数据记录软件为测试对象,构建了软件测试环境并提出测试方法。该方法取得了较好的应用效果,但对软件异常位置的定位效果有待进一步验证。文献[6]研究了基于自动软件过程改进与能力评定及ISO 26262的软件测试方法。该方法对软件质量的测试结果可信,但测试流程相对复杂。文献[7]使用正交试验法完成软件测试。该方法测试结果有效,但存在随机误差。
结合当前软件自动化测试的需求与前人研究方法存在的问题,本文提出了1种基于深度神经网络的信息管理软件自动化测试方法,并对该方法进行了测试与分析。
1 信息管理软件自动化测试方法
1.1 基于 Markov 链的软件任务剖面建模方法
信息管理软件运行剖面代表信息管理软件自动化测试的数据环境。此剖面主要由软件程序任务流构成[8-9]。软件任务剖面建模是信息管理软件自动化测试的基础。为此,本文使用基于Markov链的软件任务剖面建模方法,构建信息管理软件任务剖面模型,提取用于信息管理软件自动化测试的任务流。
1.1.1 提取用户需求并设计任务剖面模型
①设目前需要自动化测试的信息管理软件程序任务剖面为D、D的初始节点为De、目前剖面任务流种类为DT。
②若De属于任务组合状态节点,则设置其剖面种类为RT。
③若目前节点属于D的末节点,不具有任务操作信息,则返回步骤①。
④设置执行的自动化测试操作行为为DO。若DT属于自动化测试任务用例剖面,将DO的变化条件、后置条件、操作概率等信息融合后,归入D;若DT属于自动化测试任务场景剖面,将DO的测试行为局限、顺序关系、测试结果等信息融合后,归入D。
1.1.2 信息管理软件自动测试任务流获取方法
本文提取D中用于信息管理软件自动测试的任务流,深度优先遍历D,检索自首节点到末节点的全部软件程序进程路径。遍历时,若出现循环模式,便会多次判断循环的停止条件,且已遍历的软件程序进程路径与已提取任务流信息会缓存在堆栈中。若全部软件程序进程路径遍历完毕便会停止[10]。获取的信息管理软件自动测试任务流可以用于测试软件是否存在异常。具体操作步骤如下。
①构建空的堆栈用来保存全部软件程序进程路径信息,并设置De。
②若目前节点属于D的末节点(其代表一条自开始至结束的路径已获取)[11],则存储栈中信息,并将其加工为新的任务流。
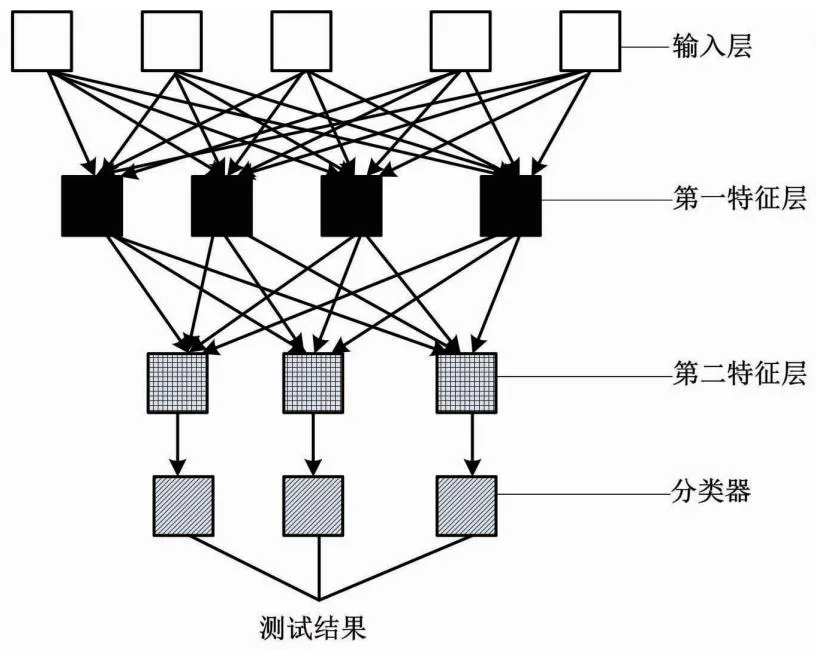
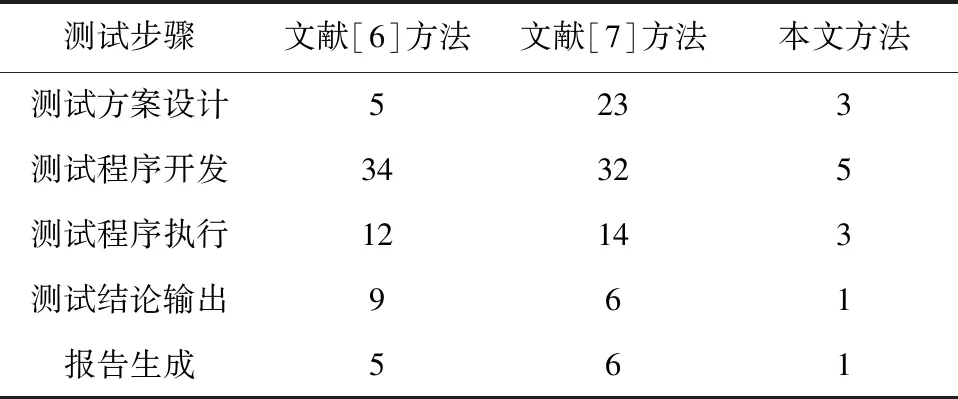
③遍历自De开始的各变化条件,设置目前需要处理的任务为DP,则目标节点为M。在栈中,检索偏序关系DP ④输出栈顶的偏序关系DP 1.1.3 软件任务状态转移概率运算与优化 任务剖面模型和任务流包含信息管理软件自动化测试所用的全部用例与参数信息。本文使用Markov 模型对任务流中的用例与参数信息进行重要性评价,以此提取重要的任务用例与参数信息,用于自动化测试[12-13]。因为信息管理软件任务状态具有常反性,所以可以通过Markov模型,结合已知的软件任务状态转移概率Qji,计算其极限概率αi。 (1) 式中:R为软件任务状态空间。 极限概率αi越大,则D中某节点的重要性越高。使用式(1)计算D中某节点任务流里全部状态,获取组合概率α′。αi较大的任务流,重要性也较高。利用重要性显著的用例与参数信息组成信息集合O,使O作为重要任务流信息样本,并对其优先测试。 深度自编码器网络结构如图1所示。 图1 深度自编码器网络结构 本文使用深度学习神经网络进行软件异常的自动识别。深度自编码器网络属于深度学习神经网络结构中的前向传播神经网络,具有强大的数据识别分析能力。因此,本文主要使用深度学习神经网络技术中的深度自编码器网络来完成软件异常的自动识别。在识别过程中,本文将获取的信息管理软件任务流中重要的用例与参数信息作为此网络的识别样本。 若深度自编码器网络输入样本为重要的任务流信息,则使用式(2)、式(3)能够获取输入层与输出层的激活状态。 x=S(VO+c) (2) 式中:x为输入层的输入数据(软件自动化测试任务流中重要的用例与参数信息)与输出数据(软件自动化测试结果-软件异常识别结果);S( )为sigmoid函数;V为权重;c为第二特征层的偏置量。 l=S(VO+c′) (3) 式中:l为输出层的输入数据(软件自动化测试任务流中重要的用例与参数信息)与输出数据(软件自动化测试结果-软件异常识别结果);c′为输出层的偏置量。 本文设置相对熵(relative entropy,RE)。软件自动化测试结果的损失函数为: (4) 自动编码器使用随机梯度下降算法完成网络训练。权值更新方法为: (5) 式中:ε为更新步长。 在使用自动编码器时需要设置稀疏编码约束条件,以约束神经元的激活量,从而保证一个重要任务流信息样本仅有少数神经元处于激活状态。此方式可实现样本的数据稀疏编码。此条件设置后,软件自动化测试结果的损失函数为: (6) 对训练完毕的多个稀疏自编码器进行堆叠后便可建立深度自编码器网络。此网络参数是以逐层贪婪训练算法获取的,可以使用原始输入的重要任务流信息O′训练网络首层。获取O′的特征参数c1、c2后,网络首层把原始输入的O′变换为激活值构成的神经元向量x′,将其设成第二层的输入,并调整权值再次训练以获取第二层的特征参数c′1、c′2。 在训练各层参数的过程中,应保证剩下的每层参数相对固定。因此,若想获取更好的结果,先要在训练结束后微调全部层参数,再将特征参数c1、c2设成Softmax分类器的分类目标,从而实现软件自动化测试的异常识别。软件自动化测试结果为: (7) 式中:qj为Softmax分类器输出的软件异常与否的分类概率值;m′为c1、c2的数量。 在得到u后,深度自编码器网络会将输出的异常识别结果以信息管理软件自动化测试报告的形式输出。报告包括异常问题、异常问题的内容、异常问题出现的时间等。 结合识别的信息管理软件异常报告,本文使用基于异常报告分析的软件异常定位方法,对软件异常报告与源代码文件结构进行类似性判断。如果类似性较大,便可结合源代码文件的位置信息判断异常出现位置。 1.3.1 软件异常文本预处理 软件异常报告与源代码文件文本中的数据中,并非所有词都能被信息检索技术分析,因此需要对其中的异常文本进行预处理。 为了对软件异常报告与源代码文件结构进行类似性判断,需要对异常报告与源代码文件进行预处理。在处理过程中,需要将异常报告与源代码文件变换为抽象语法树,从而直接提取其中的信息内容,并对其进行分词、去除停用词等处理。 在分割信息管理软件异常报告与源代码文件标志符的过程中,某部分标志符一般会遵循某种分割标准以完成分割操作。而在此操作下,会存在某词命名权值超标问题。因此,本文把信息管理软件异常报告与源代码文件中全部非字母符号转换成空格,并通过空格把文本分割为一组连续的词。 1.3.2 计算源代码结构信息和异常报告的类似度 在异常报告和源代码文件预处理之后,需要将预处理后的源代码文档里的内容依次和预处理后异常报告内容进行词语匹配。预处理后的源代码整体结构化信息ζm和异常报告的结构化信息ψm的类似度运算结果为: (8) 因为异常一般会出现在源代码文件的某个方法或代码块上,本文将V变大,以运算源代码文件里的信息与异常报告结构化信息的契合度。预处理后源代码方法信息τm和异常报告类似度的运算结果为: (9) 对Sima、Simb实施加权处理,便可获取源代码结构信息和异常报告整体类似度运算结果: Simc=Sima-VSimaVSimb (10) 1.3.3 结构信息和堆栈信息类似度运算 异常报告堆栈中会缓存一部分信息,需对这些信息进行类似度运算。为此,本文对ζm和异常报告中堆栈信息Γm的类似度进行运算。 (11) 式中:d(ζm,Γm)、φ分别为ζm和Γm的最小距离、阈值。 1.3.4 整体类似度运算 结合源代码结构信息和异常报告类似度运算结果、异常报告中堆栈缓存信息和源代码结构信息类似度运算结果,可获取如式(12)所示的整体相似度运算结果。 Simo=1-VSimcVSims (12) 如果Simo数值较大,则异常报告信息与源代码文件存在高度类似性,可结合源代码文件的位置判断软件出现异常的位置。 用于卫星轨道控制的信息管理软件任务剖面如图2所示。 图2 用于卫星轨道控制的信息管理软件任务剖面 为测试本文方法的应用性,本文在Matlab软件中,以卫星轨道信息管理软件为例进行测试。本文使用本文方法提取卫星轨道信息管理软件任务剖面,以此提取其任务流信息。 本文方法依次提取2种任务剖面中的任务流信息,以作为软件自动化测试的样本,并统计本文方法的出错次数。本文方法出错次数测试结果如表1所示。 表1 本文方法出错次数测试结果 表1测试结果显示,使用本文方法后的出错次数均为0次。该结果证明本文方法对卫星轨道信息管理软件自动化测试结果可信。信息管理软件自动化测试方法的应用步骤分别为测试方案设计、测试程序开发、测试程序执行、测试结论输出、报告生成。不同步骤自动化测试耗时如表2所示。 表2 不同步骤自动化测试耗时 分析表2数据可知:在执行信息管理软件自动化测试任务时,本文方法自动化测试执行耗时相对较少(最低仅为1 min),且总耗时最少(仅13 min);文献[6]方法、文献[7]方法的执行总耗时较多,分别高达65 min、81 min。根据对比结果,本文方法的应用难度最小,在信息管理软件自动化测试方面具有较高的应用效率。 在使用本文方法对信息管理软件进行自动化测试时,并非神经元激活数量越多越好。因此,需要测试神经元激活数量对测试效果的影响,从而设置合适的神经元激活数量,以保证信息管理软件自动化测试精度。为此,本文将神经元激活数量依次设成1个、3个、5个、7个、9个。得到的神经元激活数量对测试效果的影响如表3所示。 表3 神经元激活数量对测试效果的影响 分析表3可知,神经元激活数量并不是越多越好。当神经元激活数量为3个时,本文方法对卫星轨道信息管理软件的自动化测试结果出错次数为0次。此时,本文方法的应用效果最佳。而随着神经元激活数量逐渐增多,出错次数变多。在实际应用时,需要选择合适的神经元激活数量。 软件测试属于软件研发过程中的核心程序,软件自动化测试方法可以自动测试软件应用程序的性能是否满足研发标准与研发需求。为此,本文将深度神经网络应用到信息管理软件自动化测试问题中,提出了1种基于深度神经网络的信息管理软件自动化测试方法。此方法主要使用基于 Markov 链的软件任务剖面建模方法、基于深度学习神经网络的软件异常自动化识别方法、基于异常报告分析的软件异常定位方法,完成信息管理软件任务流信息提取、软件异常自动化识别、软件异常程序定位。试验结果表明,本文方法对异常问题的测试结果与定位结果都较准确,且在自动化执行效率方面存在优势,具有一定应用价值。但在应用本文方法时,需要注意深度自编码器网络的神经元激活数量。在试验环境中,最优神经元激活数量为3个。1.2 深度学习神经网络的软件异常自动识别
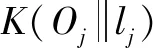
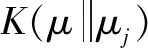
1.3 基于异常报告分析的软件异常定位方法
2 试验结果与分析



3 结论
