面向数字人文研究的三星堆古城祭祀图谱构建与场景应用*
2024-03-10张云中上海大学文化遗产与信息管理学院
张云中 邱 璟 (上海大学文化遗产与信息管理学院)
0 引言
《“十四五”文物保护和科技创新规划》强调要整合文物资源,建立文物数字化标准,加强文物信息基础设施建设[1],为文物资源的组织开发提供了指导意见。三星堆遗址作为近年最重要的考古发现之一,其古城祭祀区器物坑遗存与古蜀先民的祭祀活动密切相关[2],是揭示古蜀地区祭祀体系的重要实物例证,对于保护和传承古蜀文明有重要意义。因此,整合三星堆古城祭祀数字资源,搭建其数据基础设施,并基于此开展相关应用,能够有效实现资源活化。
三星堆古城祭祀数字资源主要涵盖遗存的外在特征描述和内涵属性挖掘两方面,以文本、图像、音视频等形式异构分布在不同机构。尽管博物馆已借助分类法和元数据组织资源,但仍存在组织粒度较粗、资源间关联缺失的问题,知识图谱推动着资源存储、获取、展示方式的变革,为资源开发提供了方案。本文旨在建立三星堆古城祭祀体系与数据体系的对照,设计古城祭祀体系本体模型,挖掘资源蕴含的实体及其关系,构建起三星堆古城祭祀图谱,以此开展场景应用,赋能人文领域研究。
1 研究述评
本文立足于祭祀体系的视角构建三星堆古城祭祀图谱,古城祭祀遗存隶属于文物的范畴,因此本文围绕文物资源数字化建设和三星堆古城祭祀体系两个方面开展研究述评。
1.1 文物资源数字化建设
用户知识需求的不断提升,促使文物数字化建设不能停留在单纯地将实物数字化,而应更多地聚焦于文物资源的语义描述、语义关联和应用开发3个递进的层次。
在语义描述方面,主要有元数据和本体[3]两种形式。元数据是结构化的语义描述,侧重于描述文物资源的物理特征[4]56,DC元数据、CDWA概念框架和艺术建筑数据标准等为资源管理、组织奠定了基础。而本体是形式化的、机器可读的语义描述,是对元数据的进一步抽象,能够为不同元数据建立语义互操作方案[4]57。本体以能够建立概念间联系更符合现实事物存在客观规律而得到广泛应用,文博领域较为通用和成熟的是CIDOC概念参考模型[5]。
在语义关联方面,当前大量资源存储在不同的机构中,一定程度上影响知识的共建共享,因此其研究重点向着关联关系建构倾斜。一方面,通过图数据库等工具实现资源之间的语义关联[6];另一方面,使用关联数据技术实现文物实体间的关系连接,借助平台实现关联数据的存储和发布,并将其与开放知识库进行链接融合,建立内外部数字资源的相互关联[7]。
在应用开发方面,伴随着文物资源语义描述和关联研究的成熟,开始从理论研究转向应用开发。关联展示[8]、语义检索[9]、智能问答[10]等二维空间的应用研究不断发展,同时借助GIS系统[11]、虚拟现实[12]、元宇宙[13]等技术开展的多维空间研究也正在逐步发展。
1.2 三星堆古城祭祀体系
依据《辞海》中对祭祀和体系的定义,祭祀体系是指祭祀活动中若干事物互相联系和制约而构成的一个整体,尽管不同时期、不同地区的祭祀体系有所差异,但基本涵盖祭祀场所、祭祀时间、施祭者、受祭者、祭祀用器和用品等要素。虽然三星堆古城目前尚未发现明确的祭祀相关记载资料,但领域内学者依据古城内祭祀遗存认为三星堆古城应该有着较为完备的祭祀体系[14]442,学者们主要是通过分析古城内建筑和器物坑性质及其祭祀遗存来推论祭祀体系的相关要素。
针对祭祀场所,有学者通过对青关山F1建筑遗迹分析和复原,推测其为礼仪活动场所[15]87;对于祭祀遗存出土的一至八号坑,学者们通过考古勘探基本认定除了五号和六号坑为祭祀坑,其余均为祭祀器物掩埋坑[16]31-32。针对施祭者,依据写实类人像造型器物的头饰、服饰和姿势,辨别其在祭祀活动中的身份和功能[17]。针对受祭者,一方面将夸张抽象的面具与传世文献中的蜀祖蚕丛联系起来[18]96-97,认为其象征着祖先崇拜,更有学者推测三星堆各期文化的主人[19];另一方面是揭示植物[20]152、动物[21]108造型类器物蕴含的宗教信仰。针对祭祀用器和用品,学者多依据器物的器型及其传统用途,来推测其使用方式和功能,容器类器物的内容物被认为是献祭品[22]77。学者们通过科学严谨的论证,描绘出三星堆古城较为完整的祭祀图景,为本文开展三星堆古城祭祀体系研究提供了参考。
当前文物资源的数字化建设研究主要是利用本体和知识图谱等技术建设文物数据基础设施,并在此基础上开展应用研究,为本文提供了经验。聚焦于三星堆祭祀体系数字资源的组织开发,学者多从人文角度出发,博物馆仅利用元数据对资源进行粗粒度组织,尚未形成完备的三星堆古城祭祀体系数据基础设施,难以为相关数字人文研究提供数据支撑。知识图谱是数据驱动的资源组织方式,因此,如何搭建细粒度、关联化的三星堆古城祭祀图谱,并在此基础上开展数字人文研究的场景应用,是本研究着力解决的关键问题。
2 研究路线设计
本文通过考查三星堆古城祭祀区器物坑的遗存属性,提出以古城祭祀体系为核心的图谱构建和场景应用方案,主要包括本体建模、图谱构建和场景应用,如图1所示。
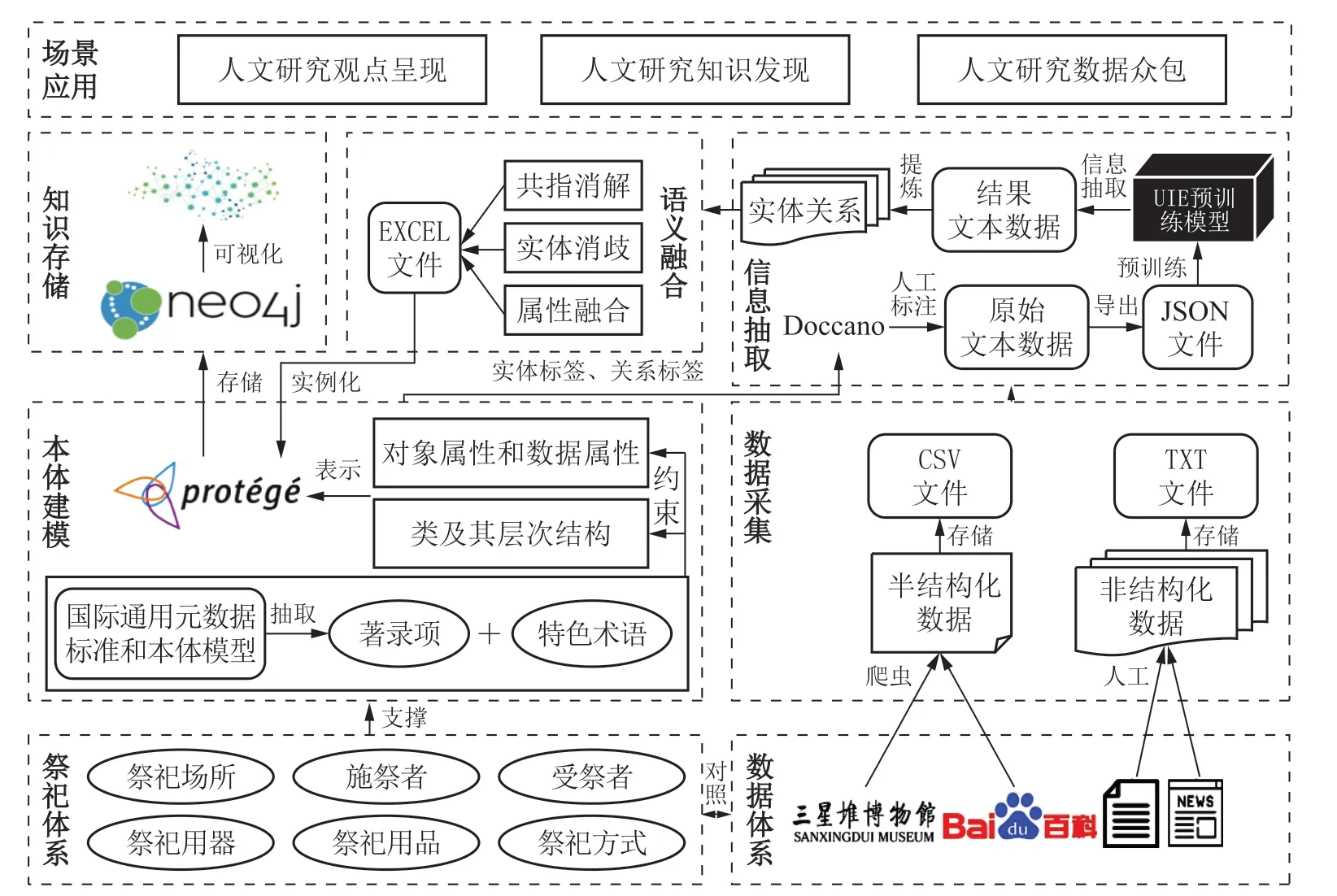
图1 研究技术路线
(1)本体建模。建立古城祭祀体系与数据体系的对照,确立现存数据体系能够支撑祭祀体系的研究维度,据此定义类及其层级、对象属性与数据属性,构建三星堆古城祭祀体系本体模型。
(2)图谱构建。运用爬虫与人工相结合的方式从不同数据源中采集资源,借助UIE预训练模型实现不同结构类型数据的信息抽取,并对不同源的数据进行共指消解、实体消歧和属性融合,将整理好的数据导入Neo4j中完成节点和关系的存储,实现图谱构建。
(3)场景应用。依托图谱结构化的知识表示进行多维信息检索,可以清晰地描述祭祀体系实体间的关联关系,搭建起人文研究观点呈现、知识发现和数据众包的场景应用,以此赋能三星堆古城祭祀相关人文研究。
3 三星堆古城祭祀体系的本体建模
本体是概念化的规范说明[23],能够建立起资源间不同描述形式的语义互操作。三星堆古城祭祀资源多源异构,因此有必要设计全面、规范、可互操作的三星堆古城祭祀体系本体模型,为资源组织提供技术支撑。
本文首先确立了三星堆古城祭祀体系的研究维度,其次复用了文博领域较为成熟的CIDOC-CRM、VRA和CDWA的术语,并自建古城祭祀体系特色著录项,以“sxd”前缀标识,在此基础上定义类及其层级、对象属性和数据属性,构建古城祭祀体系本体模型。
3.1 三星堆古城祭祀体系的维度确立
目前三星堆古城尚未出土祭祀相关文献记载,多依靠古城内的祭祀遗存来开展祭祀体系研究,但这些资源能够支撑祭祀体系的哪些维度,需要进一步探索。调研发现,三星堆古城祭祀资源主要分为两类:一类是描述祭祀遗存客观情况的百科型资源,如尺寸等外在特征;另一类是依据遗存外在特征挖掘其内涵的研究型资源,如功能等内在特征。本文着力从研究型资源出发,从具体遗存切入,梳理古城祭祀体系与数据体系间的联系,见表1。
3.2 确定类及其数据属性
依据上文梳理的祭祀体系具体维度,设置了祭祀场所、施祭者、受祭者、祭祀用器和用品类,补充了时间、工艺和图案纹饰3个抽象类,并根据不同的分面逐级细化,建立起类间层级,见表2。此外,依据数据体系中实体的属性定义不同类的数据属性,层级类目的数据属性具有继承性。
3.3 定义类的对象属性
孤立的类目难以完整地描述祭祀体系,需要限定对象属性的定义域和值域使类目间关联起来。本文共定义14个对象属性,见表3。

表3 三星堆古城祭祀体系本体模型类的对象属性
最终,古城祭祀体系本体模型共包含8个核心类、30个子类、14个对象属性和19个数据属性,借助protégé软件实现本体模型构建,为图谱构建奠定逻辑基础。
4 三星堆古城祭祀图谱的构建
4.1 数据获取
图谱质量由数据源的质量所决定,因此须保障数据源的真实性和完整性。本文主要选取了三星堆博物馆官网、百度百科数字博物馆、中国知网官方平台。此外,由于官网资源更新及时性不足,本文选取了新浪微博“四川广汉三星堆博物馆”账号内容,用于收集更为及时、权威的资源。
针对网页类半结构化数据,利用爬虫技术抓取文物介绍网页,并进行网页内容去噪、提炼等预处理,分别提取三星堆博物馆和百度百科数字博物馆文物介绍网页85和83个,剔除重复内容,最终获得有效文物介绍网页118个,将采集到的数据整理存储到CSV文件中。
针对文本类非结构化数据,主要包括:一是图书《三星堆祭祀坑》,是对祭祀区一号和二号坑发掘撰写的考古报告,是开展三星堆领域研究的基础性资料;二是研究文献,在中国知网中,以“三星堆”为主题进行检索,保留刊载于CSSCI来源期刊和《四川文物》期刊的高质量文献263篇;三是新闻报道,在新浪微博“四川广汉三星堆博物馆”账号,筛选2020年至2022年与三星堆古城祭祀相关博文213篇。在此基础上,人工阅读采集的文本内容,摘录古城祭祀体系相关内容,存储到TXT文件,作为三星堆古城祭祀体系初始语料。
4.2 信息抽取
由于三星堆古城祭祀资源涉及的领域知识范围较广、内容较为复杂,利用现有实体识别工具会出现识别精准度较低的问题,因此本文选用UIE预训练模型来实现三星堆古城祭祀资源的信息抽取。UIE模型支持不限定领域的信息抽取,能够实现零样本的冷启动,降低了标注数据依赖。
为了提高模型信息抽取的准确率,需要针对三星堆专业领域的任务进行预训练。根据前文构建的本体模型预先定义任务所需实体和关系标注标签,将类中实例以及属性值设为实体,将对象属性和数据属性设为关系,设计了20个实体标签和42个关系标签。选取初始语料中的1 000条数据,分析数据的语义内容和文本结构,利用开源数据标注工具Doccano实现资源的人工序列标注,构成预训练模型的初始语料库。
本文配置了python3.7的试验环境和paddlepaddle2.4.0项目框架,参照经验数据和实操惯例,将语料库按照8∶1∶1划分为训练集、验证集和测试集[27]加载入模型中,并根据显存情况调整模型参数,将max_seq_len设置为512、batch_size调整为32,在训练过程中持续关注模型的评价指标,当指标得分不再随着训练轮次的增加而上升时保存模型。该模型在epoch = 6时,评价指标得分达到最高,其中P = 0.93,R = 0.87,F1 = 0.90,保存该模型。
调用模型进行实体和关系联合抽取,尽管通过模型抽取出大部分信息,但由于实体和关系标签数量太多而训练数据量不对等的原因,导致部分实体间关系未被析取,因此笔者通过人工校验对数据中的实体和关系进行补充和修正,以保障图谱的可靠性。
4.3 语义融合
由于三星堆古城祭祀资源来源于不同平台,会存在数据源间的数据重复、对于同一事物存在表述不一的问题,因此需要综合多个数据源的数据去重、合并,增加实体和关系丰富度的同时减少图谱的知识冗余。
(1)共指消解
共指消解主要解决的是实体“同义异名”。该问题产生的原因一方面是由于数据采集于不同的数据源,不同数据源间表述习惯存在差异;另一方面是由于部分数据来自篇章级文本,篇章文本一般仅在专有名词首次出现时使用其全称,在后文表述中使用其简称,如:“青铜大立人”被省略描述为“立人像”等,从而导致实体表述偏差。因此,本文以《三星堆祭祀坑》表述为基准,采用实体名称语义相似度专家人工比对的方法,将同义异名的实体名称更改为同一表述,如:将不同文件中的“立人像”实体合并为同一文件中的“青铜大立人”实体。
(2)实体消歧
实体消歧主要解决的是实体“同名异义”。该问题是由于器物坑出土大量同类型器物,但尚未将每个器物按其特征进行专有命名,如:不同形制的玉璋统称为“玉璋”。针对这个问题,本文在器物名称后缀其标识符,用以区分不同形制的同类器物,若其标识符数据未被收集到,则在其后缀补充器物最显著的特征用以标识,如:标识符K1:78的“玉璋”被命名为“玉璋K1:78”,若无标识符的器物可先后缀其出土坑号,再据其特征加以命名。
(3)属性融合
本文以《三星堆祭祀坑》表述为基准,首先对不同数据源中同一实体相同属性的属性值进行合并更改,其次对官方数据缺失的实体属性进行补充,如:博物馆官网中“青铜大立人K2②:149、150”的“尺寸”属性表述为“长142、直径2.3厘米”,其他数据源中的表述为“长1.42米,直径2.3厘米,重463克”,则将该表述修正为“长142厘米、直径2.3厘米、重463克”。
4.4 知识存储
本文采用Neo4j图数据库实现三星堆古城祭祀体系数字资源的知识存储。相较而言,Neo4j图数据库拥有灵活的数据结构和便捷的开发模式,查询效率更优。因此,本文基于祭祀体系本体模型,编写MappingMasterDSL语句将抽取结果导入protégé软件中存储为owl文件,再将其导入Neo4j中,实现本体模型与数据实例间的映射。
然而,Neo4j直接导入owl类型的文件会存在实例无法显示的问题,需要先将owl文件利用rdf2rdf命令模块转换为rdf文件,再借助Neosemantics插件即可实现RDF数据向Neo4j图数据库的导入,导入后可以对标签下的节点和连线进行进一步调整,最终导入1 098个节点和3 375个关系,完成三星堆古城祭祀图谱构建。
5 基于知识图谱的人文研究场景应用
5.1 场景一:人文研究观点呈现
人文研究的观点大部分是以发表研究文献的方式展现,而文献观点隐藏在论据论证的大量篇幅之间,其隐蔽性为用户探寻观点造成了阻碍。以图谱的形式呈现文献观点既直观,又可以串联多篇文献观点,梳理其脉络形成知识网络,进而为用户提供快捷、准确的知识服务。
(1)研究观点查询
三星堆古城祭祀文献多从祭祀器物着手,针对用户关于器物基本知识的简单知识需求,编写“MATCH(n{name:“器物名称”})RETURN n”语句即可将该器物的相关信息通过节点和边可视化地展示出来,使得研究观点更加清晰明了,为用户查询检索相关器物数据提供便利。以“青铜大立人”为例,通过检索式查询到“青铜大立人”节点,双击节点既可以直观地查询到“青铜大立人”的出土地点、工艺、纹饰等信息,还可以得到“青铜大立人”的冠饰、服饰、姿势等相关属性(见图2),可以发现学者通过严谨论证后认为“青铜大立人”的身份地位较高,在祭祀活动中担任的施祭者身份为主祭。

图2 青铜大立人的相关信息
(2)研究观点循证
针对用户的复杂知识需求,祭祀图谱可以从存储的多篇文献观点中寻找关键证据支撑,更为深入细致地揭示知识内涵。例如,学者在广泛阅读三星堆发掘报告、论著后,得出三星堆古城的宗教信仰主要是由“自然崇拜”“图腾崇拜”和“祖先崇拜”组成的结论,然而该结论分别对应于何种事物,如何通过出土遗存来证实,并未在文章内明确说明。针对这个问题,构建语句“MATCH(a:Ancestor)-[r:symbolicFigure]->(b) RETURN a,b,r”“MATCH (a:Nature)-[r:symbolicThing]->(b)RETURN a,b,r”“MATCH (a:Totem)-[r:symbolicThing]->(b)RETURN a,b,r”从图谱中挖掘,检索结果整体见图3,其中左上图为祖先崇拜结果图,右上图为自然崇拜结果图,左下图为图腾崇拜整体图,右下图为图腾崇拜细节图。从图中可以发现“祖先崇拜”具体包括蚕丛、鱼凫、柏灌和烛龙,“自然崇拜”主要是由太阳、山、树所表现的,“图腾崇拜”所涉及的种类众多,包括鸟、蚕、龙、眼睛、龟背、鱼、鸡、虎、蛇和扇贝,图谱中也详细展示了代表受祭者的具体器物。

图3 三星堆古城的宗教信仰
5.2 场景二:人文研究知识发现
知识图谱不仅可以通过检索查询到关联的节点,还可以发现知识关联网络隐含的信息。祭祀活动需要将祭祀用器和用品盛装于容器类祭祀用器中供奉给受祭者,在同一容器中的不同用器和用品与容器类祭祀用器象征着相同的受祭者。在本研究中,用器和用品之间的关联关系是通过“isPackedIn”建立起来的,用器与受祭者之间的关联关系是通过“symbolicThing”和“symbolicFigure”建立起来的。因此,本文以祭祀用品为出发点,探究祭祀用器和祭祀用品与受祭者间隐含的关联关系。
针对一号器物坑的祭祀用品,通过“MATCH (n:Biologicalobject)-[r1:isPackedIn]->(m)-[r2:symbolicThing]->(o) RETURN n,m,o UNION MATCH (n:Humanmadeobject)-[r1:isPackedIn]->(m)-[r2:symbolicThing]->(o) RETURN n,m,o”建立了祭祀用品—>祭祀用器—>受祭者的直接关联,发现“海贝—龙虎尊—虎”一条知识路径。在此基础上,通过“MATCH(n:Biologicalobject)-[r1:isPackedIn]->(m)-[r2:symbolicThing]->(o)-[r3:symbolicThing]-(p)-[r4:isPackedIn]->(q)-[r5:isPackedIn]-(r) RETURN n,m,o,p,q,r”建立祭祀用品—祭祀用器—受祭者—祭祀用器间的双向关联,检索结果如图4所示。结果发现,一号坑海贝被盛装于青铜人头像和龙虎尊两个祭祀用器中,其中龙虎尊被认为直接与受祭者“虎”相关联,而青铜人头像通过其盛装物金虎形箔饰间接与“虎”相关联;此外,一号坑的玉琮与金虎形箔饰被盛装于同一青铜人头像中,因而合理推测一号坑中的海贝、青铜人头像、玉琮均与受祭者“虎”存在关联关系,海贝可能为祭祀虎的祭祀用品,青铜人头像和玉琮可能为祭祀虎的礼器,该发现可以为三星堆考古学者提供新的思路。
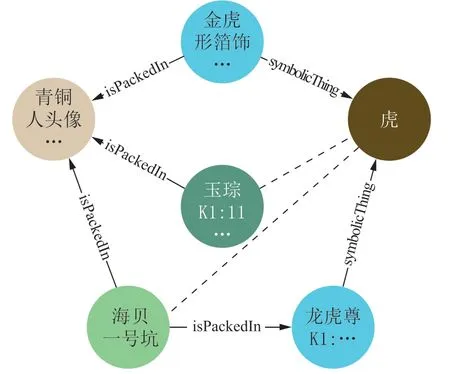
图4 一号坑玉琮和海贝与虎的关联关系
5.3 场景三:人文研究数据众包
知识图谱作为一种支持人文科研活动的基础设施[28],其构建并不是一蹴而就的。三星堆古城祭祀区3—8号器物坑的发现仍在不断更新,当前单兵作战的模式已经难以跟上资源增长的步伐,因此本文设计了古城祭祀数字资源数据众包的模式,不断丰富三星堆古城祭祀图谱,从而建立起更加完备的三星堆古城祭祀数据基础设施,为人文研究提供更坚实的数据基础,其中最重要的是解决3个问题:对什么任务进行众包?任务交由谁来完成?如何设计流程来实现众包?
(1)对什么任务进行众包?
目前利用预训练模型开展三星堆古城祭祀数字资源的信息抽取仍存在一定的缺陷,其抽取的效果有待提升,因此本文的众包任务主要包含两方面:一是扩大预训练模型的语料库,以此提高模型的准确率和召回率;二是对预训练模型信息抽取后的三元组进行人工校对。接包者需要依据上文所构建的祭祀体系本体模型,一方面分析原始数据的语义结构进行人工序列标注,另一方面对信息抽取后的结果数据进行错误纠正和缺失补充。
(2)任务交由谁来完成?
三星堆古城祭祀数字资源的数据众包任务具有较强的专业领域性,对普通用户有一定的门槛,因此需要在发包前筛选接包方,最好为考古专业领域相关学者、从业工作者和兴趣爱好者,并在分配任务前设置祭祀数字资源序列标注和人工校对不同任务的预先测评,依据任务完成的结果来判断接包方与不同任务的适配性,后续为其分配相应的任务。
(3)如何设计数据众包流程?
首先,发包者将不同的任务分解为子任务发布至众包平台,并为子任务设定“考古”“三星堆”“序列标注”“信息抽取”等标签使其易被发现,制定明确的任务要求和操作守则;其次,众包平台根据标签在用户数据库中匹配,将标签一致的任务推荐给用户,以此招募志愿者参与任务;再次,通过测评的用户可以领取任务,若接包方未在规定期限内完成,则将任务重新分配到平台,供其他用户选择;最后,发包方根据质量考核标准进行审核和校验,若质量符合要求,发包方将序列标注任务结果加入预训练模型的语料库中不断提升模型抽取的准确性,另外将校对后的信息抽取结果与现有图谱整合,不断完善图谱。
此外,在任务执行过程中,需要设置质量控制机制,如:标注平台需在任务栏下进行规则说明和约束,并列举标注示例;接包者若在标注过程中存在疑问或者建议,可进行反馈。在任务完成后,发包方还需根据任务的完成质量和用户的参与动机设置用户激励机制,不断调动用户的积极性,吸引和留住用户。
6 结语
本研究通过建立三星堆古城祭祀体系与数据体系的对照,针对当前三星堆古城祭祀资源语义描述缺乏的问题,创新性地构建了三星堆古城可扩展、可互操作的祭祀体系本体模型。利用机器学习等数字技术将分散异构的三星堆古城祭祀数字资源转化为结构化且人机可读的数据,构建起三星堆古城祭祀体系这一人文领域的知识图谱,并在此基础上借助可视化和数据分析技术实现了观点呈现、知识发现和数据众包3个人文研究场景应用,突破了传统三星堆古城祭祀体系的人文研究视角,赋能了相关数字人文研究。未来本研究还可与其他祭祀图谱进行链接,从而促进祭祀相关人文研究发现。不足之处在于三星堆古城祭祀资源的信息抽取依赖人工的程度仍然较高,未来将依靠公众力量增加数据标注语料库,不断提高模型精度。
(本文数据链接地址:http://hdl.handle.net/20.500.12304/11139)
