基于相机激光雷达融合的目标检测方法
2024-03-09周沫张春城何超
周沫 张春城 何超

摘要:针对单一传感器在自动驾驶车辆环境感知系统中易受环境干扰的问题,通过融合激光雷达点云数据和相机图像数据,提出一种强鲁棒性的目标检测方法。首先,通过YOLOv4和Pointpillars分别实现相机的2D目标检测和激光雷达的3D目标检测;然后将点云从3D投影到2D笛卡尔坐标下并计算相机帧下的3D边框;进而将相机帧中的3D边界框转换为图像上的2D边框;最后,计算在同一图像上显示的相机和激光雷达检测框的IOU指标后进行边框融合并修正融合后的目标置信度,最终输出目标的融合框、类别和距离信息。在KITTI数据集上的实验结果表明,相较单一传感器的目标检测方法,所提出的方法通过点云和图像数据的优势互补提高了目标检测的精度。
关键词:点云图像;后期融合;置信度修正;目标检测
中图分类号:U472.9;TP391.4 收稿日期:2023-11-20
DOI:10.19999/j.cnki.1004-0226.2024.02.019
1 前言
由于自动驾驶车辆环境感知系统中传感器本身硬件性能的局限性,基于单一传感器的目标检测技术有很大的局限性,多传感器融合目标检测技术可以实现不同传感器间的优势互补,因此近年来多传感器融合技术受到了广泛的关注。传感器融合可以分为前期、中期和后期融合[1]。前融合即数据级融合,直接融合不同传感器的原始数据,具有较高的准确性,但不易将不同维度的数据统一,数据处理量大,实时性较低。中期融合即特征级融合,对不同数据分别提取原始特征,再融合多个特征,根据目标已有特征对融合特征进行匹配,获得目标的信息。后融合即结果级融合,分别在不同的原始数据下检测得到在该数据类型下的目标包络框、类别、位置等信息,然后对目标的包络框等信息进行融合。后融合的方法具有较高的鲁棒性且不受传感器类别的影响。
国内外学者近年来对传感器融合技术已经有了一定的研究。陈俊英等[2]通过使用VoxelNet和ResNet的深度特征学习方法得到点云特征和图像特征后,基于互注意力模块挖掘模态间的互补信息,得到融合特征后使用区域提案网络和多任务学习网络实现了特征级融合3D目标检测及定位,但该方法数据处理量大,实时性难以保证。
张青春等[3]提出了一种基于直线与平面拟合的算法,完成了相机与激光雷达的融合,更好地完成了机器人的环境识别任务。该方法使用的是单线激光雷达,检测精确度仍有待提升。
WEI等[4]提出一种减少激光雷达假阳性检测的融合方法,利用在相机图像上放置信标通过神经网络实现相机到LiDAR的投影,信标能够提高激光雷达检测目标的能力从而实现避免假阳性的检测,该方法有效提升目标位置的检测性和信息标记能力。
郑少武等[5]提出了一种基于激光点云与图像信息融合的交通环境车辆检测算法,通过对图像和点云原始数据分别进行目标检测与跟踪,利用匈牙利算法对检测结果进行最优匹配,并结合点云到图像的投影对未匹配的图像检测框进行进一步筛选,最终对融合列表进行分类后择优输出。
张堡瑞等[6]针对水面这种特殊环境及激光雷达在水面介质中的点云反射特点,提出点云与图像融合的方法来解决水面漂浮物检测问题。有效消除水面漂浮物倒影或水面波纹造成的误识别情况,弥补了相机检测对光照依赖的短板,但该方法仅适用于特定场景,有一定的局限性。
CHAVEZ-GARCIA[7]采用两次聚类算法聚类点云数据,并采用快速Adaboost分类器基于Haar-like特征识别车辆目标。
陈毅等[8]首先将点云数据前向投影形成二维深度图,并通过深度补全方法将深度图的分辨率提高至与图像分辨率一致,然后使用YOLOv3算法分别检测彩色图和深度图中的车辆目标,最后根据改进的D-S证据理论对检测结果进行特征级融合,但对较小目标的识别效果有待提高。
常昕[9]提出了一种基于激光雷达和相机的信息融合的目标检测及追踪算法。利用激光点云数据聚类方法对可通行区域的障碍物进行检测,并投影到图片上,确定跟踪目标后在粒子滤波的算法基础上,利用颜色信息追踪目标,采用激光雷达的目标检测结果对目标追踪结果进行修正,减小了光照、遮挡、背景干扰等因素的影响,提高目标追踪效果。
针对以上问题,在环境感知系统中保证实时性的前提下,為了提高目标检测精度、降低误检率,本文提出一种通用的基于激光点云与图像信息后融合的目标检测方法,选取性能优异的目标检测算法作为基础网络,充分利用点云空间坐标与图像像素坐标的相互转换关系,实现三维目标与二维目标的最优匹配,输出可靠的融合结果。
2 融合方法概述
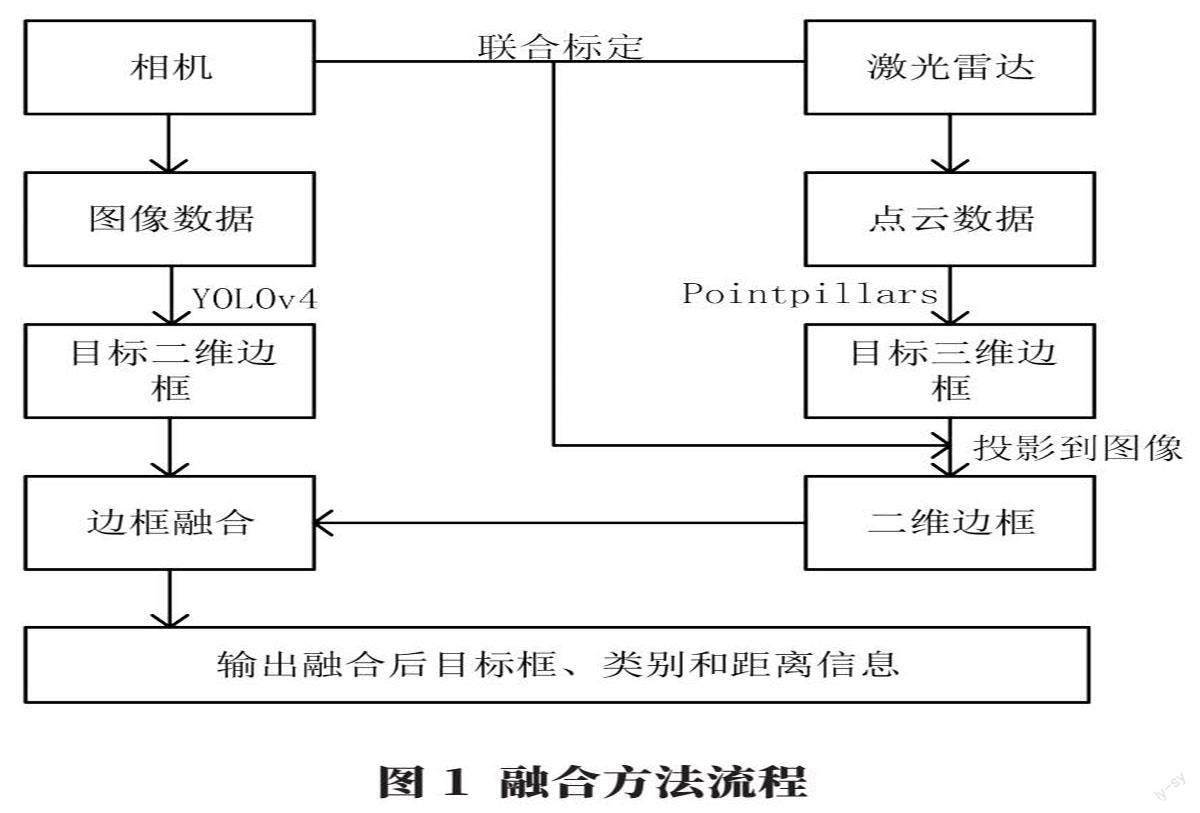
仅使用相机对道路目标进行检测,易受到光照条件等因素影响,且无法获得目标的距离位置信息;仅使用激光雷达传感器进行目标检测,受激光雷达自身线束及探测距离影响较大。为此,本文提出一种相机和激光雷达融合的目标检测方法,整个系统流程如图1所示。
传感器的融合采用后融合(late fusion)的方法。首先分别将图像和点云数据送入YOLOv4和Pointpillars网络中,得到目标的边界框、类别和置信度;然后将点云坐标转换为笛卡尔坐标,并计算相机帧下的3D边框;进而将相机帧中的3D边界框投影到图像上并绘制激光雷达在图像上的2D边框;最后,计算在同一图像上显示的相机和激光雷达检测框的IOU指标,对符合阈值的框进行融合并修正目标置信度,最终输出目标融合框、类别和距离信息。
3 基于相机的目标检测
YOLOv4算法是从YOLOv3发展而来的,YOLOv4在与EfficientDet[10]网络性能相当的情况下,推理速度是EfficientDet的2倍左右,比上一代YOLOv3算法的平均精度AP和FPS分别提高了10%和12%。YOLOv4的网络结构如图2,该算法由主干特征提取网络CSPDarknet53、特征金字塔SPPNet和检测结构YOLO-Head构成如图2所示。主干网络CSPDarknet53在YOLOv3主干网络Darknet53基础上,借鉴了CSPNet的思想,在减少参数计算量的同时保证了准确率。YOLOv4算法在特征金字塔模块中采用了SPPNet结构,进一步提高了算法的特征提取能力,而YOLO Head特征层则继续使用YOLOv3的结构。
本文使用KITTI数据集中图片对神经网络进行训练,通过YOLOv4网络识别得到目标边框和置信度如图3所示。该网络能够在丰富的图像信息中准确地识别到车辆和行人目标。
4 基于激光雷达的目标检测
激光雷达部分的目标检测采用Pointpillars算法,使用全新的编码器来学习点云柱上面的特征,来预测点云数据中目标的三维边界框。Pointpillars保留了VoxelNet的基本框架,主要由特征提取层、二维卷积层和检测输出层组成,如图4所示。特征提取层对点云数据进行柱状编码,并提取柱状体特征;二维卷积层对特征进行多尺度捕获;最后通过SSD(Single Shot Detector)检测输出目标。
该方法有几个优点。a.通过学习特征而不是依赖固定的编码器,PointPillars可以利用点云表示的全部信息。b.通过对柱而不是体素进行操作,不需要手动调整。c.柱子是高效的,因为所有关键操作都可以公式化为2D卷积,在GPU上计算非常高效,检测在图像上的可视化结果如图5所示。
5 后融合方法
本文从结果的层面对相机激光雷达的检测结果进行融合,相机和激光雷达分别通过深度学习网络得到目标在图像数据和点云数据中的检测框。然后需要进行时间和空间同步将激光雷达的三维检测框投影到图像上,对同一帧图片中的不同传感器检测框利用交并比进行筛选,最终输出融合结果。
5.1 时空匹配
时间同步因相机和激光雷达的采样频率不同,正常情况相机的采样频率为30 Hz,激光雷达的采样频率为10~20 Hz。相机完成3帧图像的采集,激光雷达才可以完成1帧的点云数据采集,所以同一时刻下相机和激光雷达的数据会出现不对应的现象,影响融合检测结果,所以需要进行时间同步。本文利用ROS平台的时间同步函数,以激光雷达时间为基准,选择与该时刻最近的相机数据保留为对应的图像帧。
空间同步即相机和激光雷达联合标定过程,激光雷达坐标系的点云数据投影到相机二维坐标系下需要求取相机外部参数。相机坐标系到像素坐标系的转换需要求取相机的内部参数。设空间一点P在激光雷达坐标系为[XL,YL,ZL],在相机坐标系坐标为[XC,Yc,Zc],在图像坐标系下为[xp,yp],在像素坐标系坐标为[u,v]。
激光雷达转换为像素坐标系的关系表示为:
[ZCuv1=1dx0u001dyv0001f000f0001 000RCL tCL01XLYLZL1] (1)
式中,[RCL tCL01]为相机外参矩阵;f为相机焦距;[dx]、[dy]为x、y轴的像素转换单位;[u0]、[v0]为投影屏幕中心相对于光轴出现的偏移。则激光雷达三维坐标系下的点[XL,YL,ZL]转换为像素坐标下点[u,v]的问题,转化为求取相机内外参数的过程。
本文通过Autoware内部的标定工具进行标定,标定过程通过手眼选取圖像和点云的对应关系如图6所示。
5.2 边框融合
在完成传感器的时空同步后,融合激光雷达点云检测结果与相机检测结果。如图7所示,相机和激光雷达检测框显示在同一帧图片上,红色为激光雷达检测投影框,黄色为相机检测目标框。接着对激光雷达检测的投影边界框和相机检测的边界框通过IOU进行关联匹配,当重叠面积大于等于设定的阈值0.5时,会被认为匹配成功,输出融合激光雷达的距离信息与相机传感器的类别信息;当重叠面积小于设定的阈值0.5时,只输出相机检测到的目标信息。
由于在使用深度学习网络对图像和点云数据的目标进行检测时,设置的置信度概率阈值会过滤掉一部分置信度不高的目标。但在实际实验过程中,一部分被识别出的目标会因为设置的置信度阈值而被滤除,所以本文采用sigmoid函数对检测到的目标进行置信度修正,其公式如下:
[P2=sigmoid(P1+C)] (2)
[P2=eP1+C1+eP1+C] (3)
式中,[P1]为图像识别目标输出的目标置信度;[P2]为融合后修正的目标置信度;[C]为调整系数。
6 实验结果分析
为了验证本文融合目标检测算法的有效性,在公开的自动驾驶数据集KITTI上进行主要实验探究。KITTI数据集是目前国际上最大的自动驾驶场景下的计算机视觉算法评测数据集。该数据集用于评测立体图像、光流、视觉测距、3D物体检测和3D跟踪等计算机视觉技术在车载环境下的性能。KITTI包含市区、乡村和高速公路等场景采集的真实图像数据,每张图像中最多达15辆车和30个行人,还有各种程度的遮挡与截断。
在训练模型时,采用KITTI数据集中的3D目标检测数据集。因此,本文将KITTI数据集中7 481帧图像和点云对应数据按照8∶1∶1的比例随机划分训练集、测试集和验证集。本文主要对轿车和行人进行研究。图8为在KITTI数据集中测试的可视化结果,红色框为融合后的目标检测框,标签分别为目标的类别和距离信息。
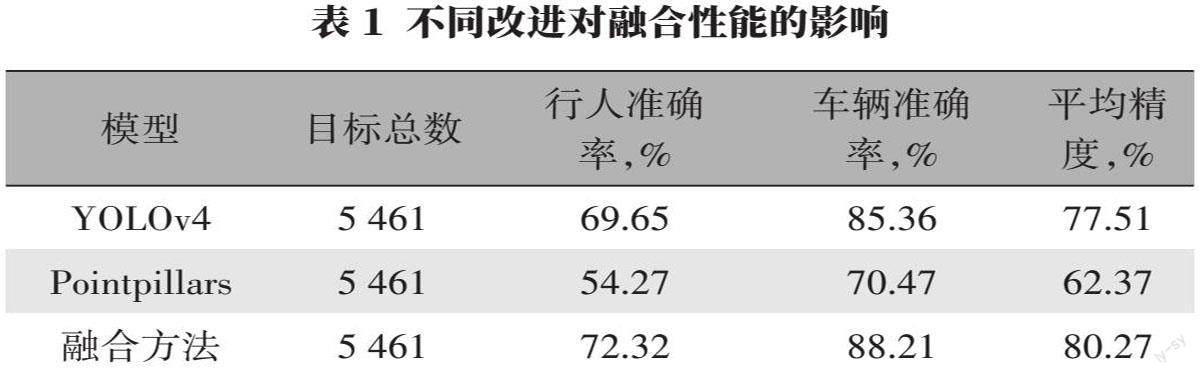
为定量分析融合算法的性能,分别在KITTI中将融合算法分别与单一的YOLOv4检测方法和单一Pointpillars方法进行对比,由表1中可以看出,融合算法识别目标的平均准确率分别较YOLOv4和Pointpillars提高了2.76%和17.90%。
7 结语
本文提出了一种基于相机与激光雷达决策级融合的道路行人、车辆目标检测方法。通过YOLOv4和Pointpillars分别得到目标在图像和点云数据中的检测框,然后经过时间和空间的同步将不同的目标检测框统一在同一帧图片上,通过检测框之间交并比建立关联并进行筛选,最终输出融合检测的结果。在KITTI数据集上的实验结果证明,本文所提方法相对于单一传感器的目标检测方法有效提高了对行人和车辆的检测精度。
参考文献:
[1]LI S,KANG X,FANG L,et al.Pixel-level image fusion: a survey of the state of the art[J/OL]. Information Fusion,2017,33:100-112.
[2]陈俊英.互注意力融合图像和点云数据的3D目标检测[J].光学精密工程,2021(9):2247-2254.
[3]张青春.基于ROS机器人的相机与激光雷达融合技术研究[J].中国测试,2021(12):120-123.
[4]WEI P,CAGLE L, REZA T,et al.Lidar and camera detection fusion in a real time industrial multi-sensor collision avoidance system[M/OL].arXiv,2018.
[5]郑少武.基于激光点云与图像信息融合的交通环境车辆检测[J].仪器仪表学报,2019(12):143-151.
[6]张堡瑞.基于激光雷达与视觉融合的水面漂浮物检测[J].应用激光,2021(3):619-628.
[7]CHAVEZ GARCIA R. Multiple sensor fusion for detection,classification and tracking of moving objects in driving environments[D].Universite De Gremoble,2014.
[8]陈毅,张帅,汪贵平.基于激光雷达和摄像头信息融合的车辆检测算法[J].机械与电子,2020,38(1):52-56.
[9]常昕.基于激光雷达和相机信息融合的目标检测及跟踪[J].光电工程,2019(7):85-95.
[10]TAN M,PANG R,LE Q V.EfficientDet: scalable and efficient object detection[C]//2020 IEEE/CVF comference on computer vision and pattern recognition,2020:10778-10787.
作者簡介:
周沫,男,1998年生,硕士研究生,研究方向为多传感器融合目标检测。
