加权竞争聚类算法及其在空预器故障识别中的应用
2024-03-08左帅徐璐璐陶鑫王培红
左帅,徐璐璐,陶鑫,王培红
(1.国家电投集团协鑫滨海发电有限公司,江苏 盐城 224500;2. 东南大学能源与环境学院,南京 210096)
基于数据驱动的设备状态诊断方法是借助人工智能来构建基于设备大量历史运行数据的状态诊断方法。数据驱动[1]来源于计算机科学领域,指将某种算法应用于大量数据的分析处理来支持决策。与基于机理模型的方法不同,数据驱动型状态诊断方法不需要建立设备精确的数学模型,只需对采样数据进行处理[2]。人工智能算法包括模糊聚类、神经网络、粒子群算法等[3-4],被广泛应用到火电机组建模、预测及优化中。空预器是电厂重要的辅机设备,对电厂安全运行具有重要意义。林文辉等[5]对空预器差压升高进行研究,并提出提高吹灰压力降低空预器差压的方案。戴松贵等[6]对空预器堵管与低温腐蚀进行研究,分析了堵管原因,并给出减轻低温腐蚀的措施。汪德友[7]通过对网络参数的选择、样本的选取与处理以及网络结构的选择和设计,确定了针对回转式空预器的人工神经网络模型,对空预器漏风率进行预测。TERUEL等[8]引入神经网络算法建立积灰监测模型,实时监测积灰情况。赵明和孙平[9]利用神经网络建立空预器污染系数预测模型,反映空预器积灰的变化情况。此类方法直接利用电厂实时运行数据对空预器积灰情况进行分析。李庆等[10]针对国内某电站600 MW机组锅炉的三分仓回转式空预器进行仿真与建模,分析和验证其故障模拟真实性,在此基础上,又采用基于仿真平台的神经网络技术进行空预器故障诊断的研究。王兴龙等[11]设计了空预器智能诊断管理系统,通过远程数据网络对现有PI实时数据库中的数据进行挖掘提取,对空预器的相关数据进行采集、计算与分析,确定空预器的脏堵、漏风、能效等指标,从而确定空预器当前的运行状态和发展趋势,从而进一步实现在线智能诊断功能。另外,闵国政等[12]对回转式空预器的智能分析及动态诊断系统进行研究,通过对空预器运行指标实时统计和动态分析给出了全方位的性能诊断评估,对空预器运行状态进行预测及预警,并指导优化运行和故障处理。
但是现实故障诊断等领域的数据中存在许多不均衡数据,这类不均衡数据集的特点是同一数据集中归属于某一类别的数据对象的数量和密度与其他类别数据对象的数量和密度有较大差异。将数据样本数量较多的类称之为大类,数据样本数量较少的类称之为小类。通常聚类算法使用全局参数来计算每个数据点的密度,这使得在衡量存在密度差异的数据集时容易忽略小类,又或者习惯于将大类中的部分对象划分到小类中,从而使获得的类拥有相对均匀的尺度,这限制了基于数据样本聚类特征的应用。
为了解决不均衡数据的聚类问题,学者们从不同角度提出了多种方法,大致可以分成以下三类:数据预处理、多中心点和优化目标函数。第一类方法是数据预处理,此类方法对数据集进行欠采样和过采样处理后再进行聚类;过采样方法通过增加小类中对象数量来进行数据分析,使原有数据集达到均衡状态。第二类方法是多中心点的方法,此类方法基于多中心的角度解决模糊聚类算法的“均匀效应”问题,其思想是用多个类中心代替单个类中心代表一个类,在某些情况下,借助该思想模糊聚类算法在迭代过程中根据距离“中心”最近的原则,能够让部分被错分到小类中的数据对象校正回大类中,具有一定的有效性和可行性。第三类方法是优化目标函数的方法,此类方法从目标函数优化的角度提出新的算法,通过推导出相应的聚类优化目标函数,以解决“均匀效应”问题[13]。赵战民等[14]提出的对类大小不敏感的图像分割模糊C均值聚类方法(FCM_S),将类大小引入至含邻域信息模糊聚类算法的目标函数中,使得类大小在目标函数中发挥作用,从而能均衡较大类和较小类对目标函数的贡献,弱化算法对类大小不均衡的敏感度。
然而,目前还没有一种既可以自动识别聚类中心个数又有效保留小类的聚类方法。因此,本文根据类间容量差异均衡化的思想对竞争聚类算法目标函数进行加权,提出一种新的聚类算法,称为加权竞争聚类算法,简称为CA_S算法。该方法通过推导出新的隶属度函数和聚类中心使得类间容量在聚类目标函数中发挥效用从而弱化了类间容量差异对聚类判决的干扰,有效保留了小类,同时通过竞争策略可自动确定最佳聚类个数,改善了CA算法[15]在类间竞争机制中容易淘汰小类的问题。同时,本文将改进后的算法应用于空预器的故障识别中,并与传统的CA算法进行比较。
1 竞争聚类算法(CA)
竞争聚类算法首先将一个数据集划分为大量的小类。随着算法的发展,相邻的类争夺数据点,一些失去竞争的类逐渐枯竭和消失,最后的分区具有“最优”类别数,应该注意的是,类别的数量c在每次迭代中都是动态更新的。CA算法使以下目标函数式(1)[15]最小化:
(1)
满足以下约束条件:
(2)
式中:uij为第j个样本点对于第i个类的隶属度;U=[uij]是一个c×n维的矩阵,称为隶属度划分矩阵;V表示由类心组成的矩阵;m为算法的模糊程度,本文取2;dij为第i个聚类中心与第j个样本点间的欧式距离;α为平衡前后两项的权重。
2 加权竞争聚类算法(CA_S)
构造CA_S算法的目标函数如式(3)所示,可以看到,其目标函数由两个分量组成:第一个分量J1类似于FCM_S的目标函数,它能够控制类的形状和大小,并获得紧凑的类,当聚类中心个数c等于样本数n时,即每个类只包含一个样本点时,可以得到目标函数的全局最小值;第二个分量J2是类似于CA算法目标函数的第二个分量,它能够控制聚类个数。当所有样本点都在一个类中,而所有其他类都为空时,就可以实现目标函数的全局最小值。当这两项结合并正确选择α时,最终的分区将类内的距离之和最小化,同时将数据集划分为尽可能小的聚类中心个数。
JCA_S(U,V)=J1-J2
(3)
(4)
(5)
满足以下约束条件:
(6)
式中:各变量的含义与CA聚类算法相同,同样将m取2代入式(4)从而用于下一步的推导。
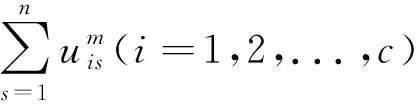
目标函数最小值的选取是一个优化问题,在CA_S聚类算法中,采用的是拉格朗日乘子法交替迭代优化来达到目标函数最小值。具体推导如下:首先假设聚类中心V恒定,解决关于隶属度矩阵U的约束极小化问题,通过构建拉格朗日函数:
(7)
(8)
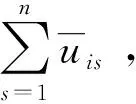
(9)
式中:带“-”的隶属度表示上一次迭代的隶属度;Ni表示为第i类的基数,为保留较大的类而淘汰虚假类的评价指标,表达式如式(10):
(10)
由此得到λj的表达式:
(11)
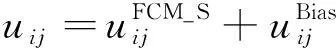
(12)


(13)
在CA_S算法中,选择目标函数式(3)中的α是很重要的,因为它反映了第二项相对于第一项的重要性。如果α太小,则将忽略第二项,类别的数量也不会减少。如果α太大,第一项将被忽略,所有的点将被归为一个类。α的选值如式(14)所示,使这两项具有相同的数量级。
(14)
式中:η(k)=η0exp(-k/τ),k为迭代次数,η0是初始值常数,τ为迭代次数中间值。
加权竞争聚类算法可用伪代码表示,如表1。

表1 加权竞争聚类算法
3 应用与分析
首先, 用不均衡Aggregation数据集来测试CA_S聚类算法识别小类的能力;随后,在4个公共数据集上对CA_S聚类算法、FCM_S算法和CA聚类算法进行比较,其中,FCM_S算法由赵战民等[14]提出,该算法能有效处理不均衡数据集,但无法有效识别聚类个数,需要根据经验提前设置该参数;最后,将CA_S算法应用于热工设备空预器的故障识别中,验证CA_S算法的实用性。
将类大小引入至含邻域信息模糊聚类算法的目标函数中,使得类大小在目标函数中发挥作用,从而能均衡较大类和较小类对目标函数的贡献,弱化算法对类大小不均衡的敏感度。
3.1 CA_S算法执行过程描述
首先,选取UCI标准数据集[11]Aggregation中的3个不均衡类,命名为Aggregation2。Aggregation2数据集分为3类,每类包含的样本点数目不同,为2维341个样本点。算法仿真输入的数据集经过标准化处理,输入参数设定为最大迭代次数kmax=30、最大聚类个数cmax=10、η0=1.3、τ=10、ε1=7。图1~ 图2为实验结果。
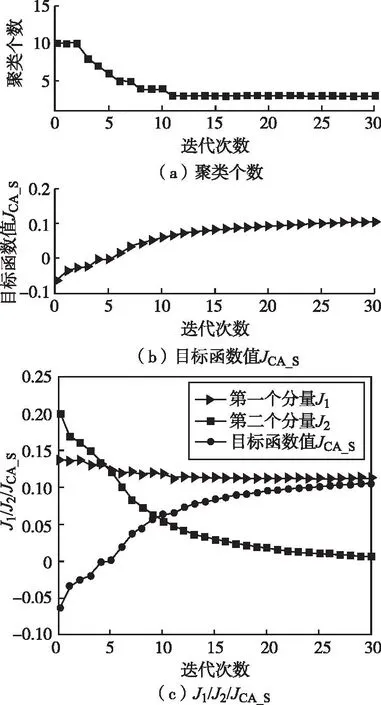
图1 Aggregation2:聚类个数和目标函数的进化
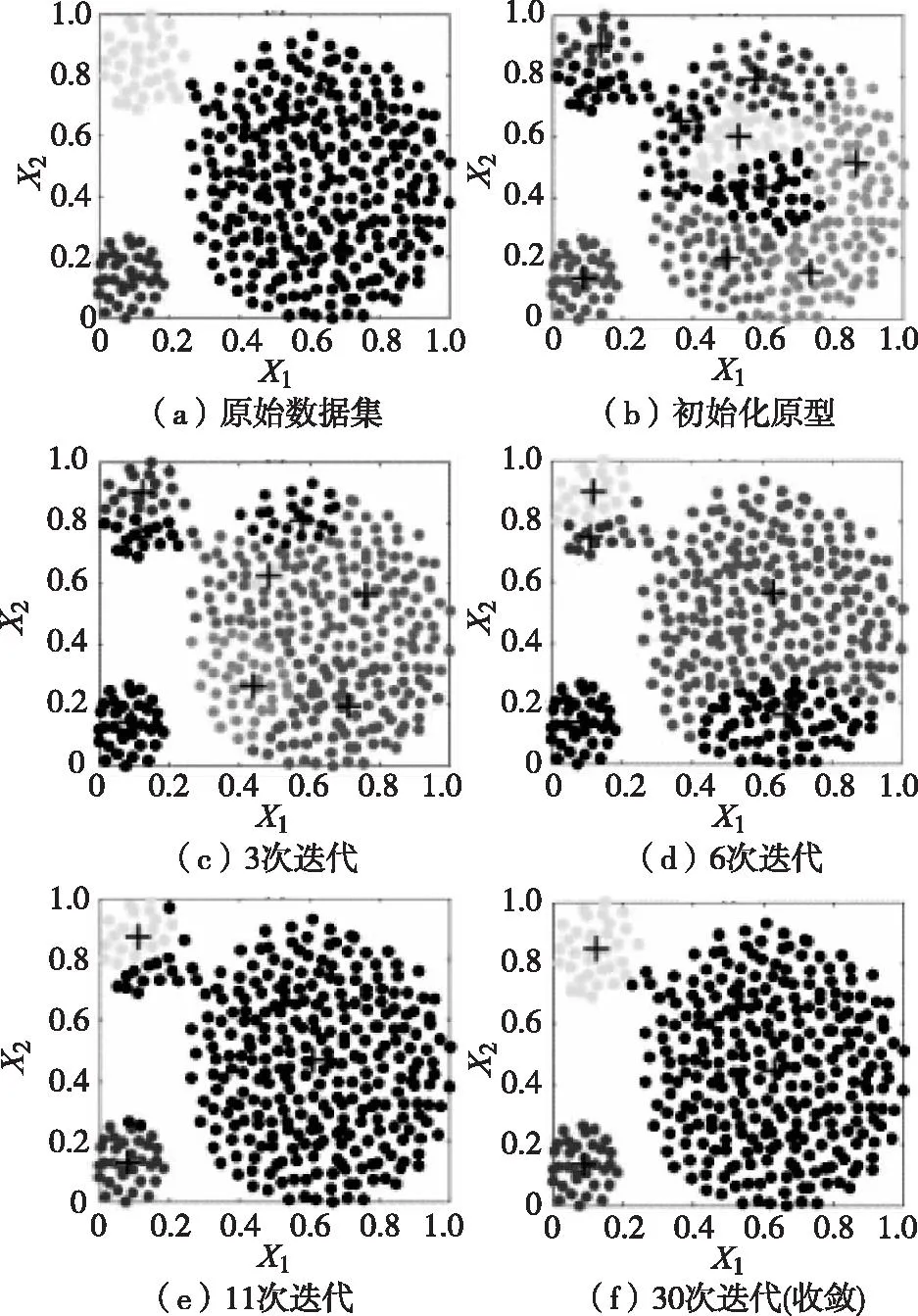
图2 Aggregation2:CA_S聚类算法执行全过程
图1描述了CA_S聚类算法在Aggregation2数据集迭代过程中聚类个数、目标函数值的变化。图1(a)~(b)为随着迭代的进行,聚类个数和目标函数值JCA_S的变化过程,可以看到,聚类个数由cmax=10逐渐减少到c=3(即最佳聚类个数),目标函数值JCA_S缓慢上升,最后随着迭代的进行,最佳聚类个数不再变化,目标函数值趋于稳定。图1(c)为该数据集使用CA_S聚类算法进行聚类迭代过程中目标函数值中的第一分量J1、第一分量J2以及JCA_S值的变化趋势。
由于目标函数式(3)的第二分量J2在不断减小,且减小的程度大于第一分量J1,因此CA_S聚类算法每次迭代记录的JCA_S值是呈现由陡变缓的上升趋势,随着迭代的进行,第一分量逐渐减少,第二项趋向于0,两者相减的值趋于稳定。
图2(a)~(f) 是CA_S聚类算法在Aggregation2数据集中的实现过程。中心的位置显示为叠加在数据集上的“+”符号。图2(a)是原始数据集。图2(b)显示了聚类的初始参数,该数据集被分解成许多小类。图2(c)表明,CA_S聚类算法在3次迭代后减少了2个类。图2(d)表明,在第6次迭代后,再次减少了3个类。图2(e)表明,在第11次迭代后,再减少2个类后,类心个数减少为3个。图2(e)~(f)表明,在后续的迭代中,类心个数不再变化,并在3个类的基础上调整了类心的位置。在达到设定的最大迭代次数后,算法就会终止。结果验证了CA_S聚类算法可以在没有先验知识的情况下识别这3个类,其中包含2个小类。
3.2 与其他聚类方法比较
本文选择FCM_S和CA算法作为比较,采用的数据集总结如表2所示,其中前三个数据集来自UCI数据库[16],选取的数据集都为不均衡数据集。第一个即3.1小节所采用的数据集,最后一个为本文构造的一个具有多密度的人工数据集,简称为DS3。为保证算法的有效执行,仿真输入的数据集都经过标准化处理,且需要对各聚类算法进行输入参数设置,CA_S聚类算法的参数与上述相同,FCM_S聚类算法需要提前设置聚类中心的个数。为了公平起见,以CA_S聚类算法获得的聚类中心个数作为FCM_S聚类算法的前提。对于CA聚类算法,参数设置参考文献[15]。
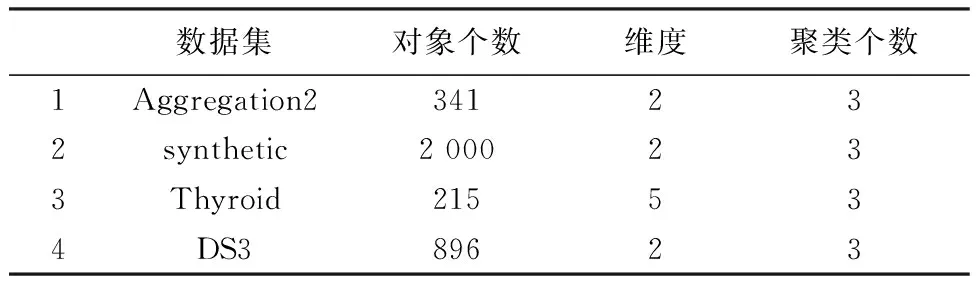
表2 本文采用数据集基本信息
本文采用ARI (Adjusted Rand Index)来衡量这些聚类算法的性能。表3为FCM_S、CA和CA_S算法分别运行30次后模拟的ARI值(平均±方差)。每一行中粗体和下划线的值表示三种算法中聚类效果最优的数据,括号中的数字表示算法应用于此数据集时产生的聚类个数。

表3 FCM_S、CA和CA_S的ARI值对比
可以看出,根据ARI值,与CA算法相比,CA_S在大多数情况表现优于CA算法,在Aggregation2数据集中,CA算法虽然正常识别出了该数据集的聚类个数,但ARI值极低,说明最后的聚类结果不合理;在Thyroid和DS3数据集中,CA算法无法正确识别出数据集的聚类个数;仅在synthetic数据集上,CA算法表现优于CA_S算法;与FCM_S聚类算法相比,CA_S算法的表现与FCM_S算法接近或者略好,考虑到FCM_S算法不能自动获得聚类个数,CA_S算法优于FCM_S算法。如上所述,CA_S算法在这几种算法中的综合表现最好。
3.3 空预器故障识别案例
将CA_S算法应用于热工设备空预器中用于状态识别,以某600 MW机组空预器作为研究对象,采用提出的CA_S算法对空预器有功功率、出口烟温、入口二次风温、进出口烟气压降、进出口烟气含氧量差进行聚类分析,并与采用CA算法的聚类结果进行比较。我们选取了一段空预器运行过程中包含异常运行样本的数据作为测试数据,数据共分为三类,其中一个小类为异常运行样本,包含的样本点远远小于其它两类正常运行样本。
CA算法仿真输入参数设定初始迭代次数k=0、最大迭代次数kmax=30、最大聚类个数cmax=10、η0=5、τ=10、ε1=7,得到如图3所示的聚类结果,用两种不同的符号代表两个类所包含的数据样本点,两个类记为ωi={ω1,ω2},可以看到CA算法无法识别出异常类。在空间划分上,以出口烟温-有功功率两个变量间为例,如图4所示,可以看出CA算法将异常类归并到了正常类,以此均匀了两个类包含的样本点。
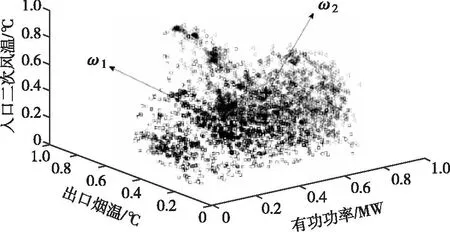
图3 CA算法下的空预器聚类结果
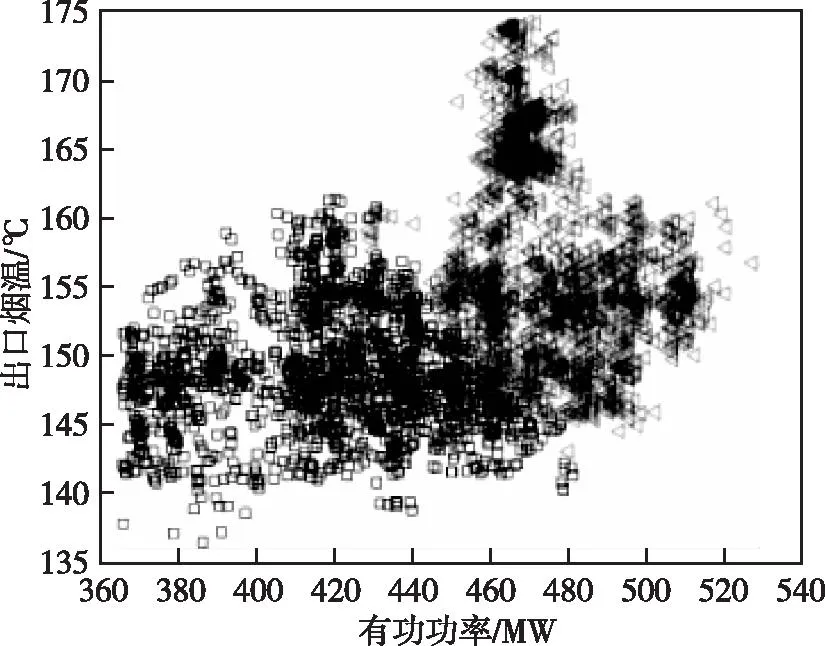
图4 CA算法下的空预器出口烟温-有功功率空间划分
CA_S算法仿真输入参数设定为初始迭代次数k=0、最大迭代次数kmax=30、最大聚类个数cmax=10、η0=1.3、τ=10、ε1=7,得到如图5所示的聚类结果,用三种不同的符号代表各个类所包含的数据样本点,三个类记为ωi={ω1,ω2,ω3},可以看到CA_S正确识别异常类。图6为 CA_S算法下的空预器各变量间的空间划分,可以看出有功功率与出口烟温、有功功率与进出口烟气压降、出口烟温与进出口烟气压降两两变量的空间划分较为清晰,可为后续空预器状态划分指标提供指导性意见。
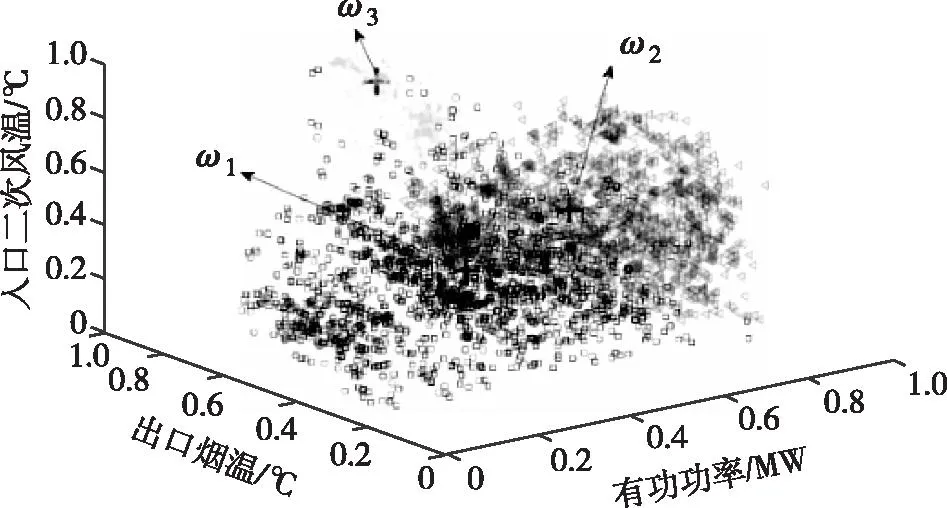
图5 CA_S算法下的空预器聚类结果
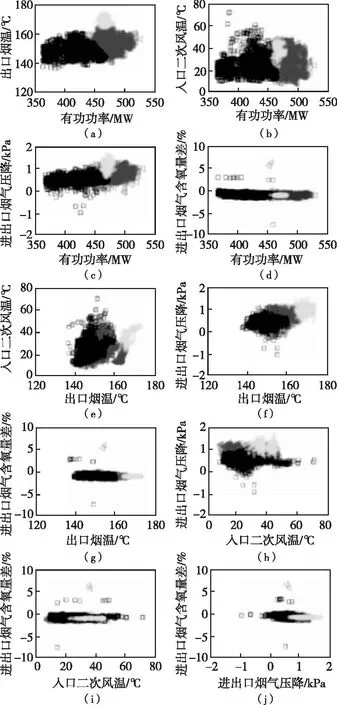
图6 CA_S算法下的空预器各变量间的空间划分
4 结语
针对故障数据在海量历史数据中占比往往较低、传统聚类算法较难识别的问题,本文提出了一种新的聚类算法——加权竞争聚类算法(CA_S),该算法在公共数据集Aggregation上表现很好,成功地识别出了1个大类、2个小类。在与FCM_S算法、CA算法的比较中,CA_S算法也有更好的表现,综合ARI指标最佳。在火电机组空预器的故障识别中,CA_S算法能够很好地识别出历史数据集中的故障类,而传统的CA算法无法识别出故障类。
