改进YOLOv5s的纱管目标检测方法
2024-03-08姜越夫吕绪山
姜越夫,王 青,吕绪山
(西安工程大学机电工程学院,陕西 西安 710699)
0 引言
管纱[1]是纺纱和织造工艺流程中必要的纱线存放形式,其中,纱管识别和分类的自动化对于纺纱和织造过程的自动化和智能化非常重要[2-3]。传统的纱管识别和分类主要通过人工实现[4],效率低下,容易出现失误。因此,实现纱管识别和分类的智能化[5-6]是适应我国智能化发展趋势的必要途径。
纱管识别和分类的智能化发展离不开实现纱管目标的智能检测。早期纱管的智能检测可以使用经典的计算机视觉算法进行处理。如任慧娟等[7]基于HSV颜色空间中不同颜色纱线的色调不同,进行筒子纱种类的识别;张帆等[8]采用改进色差法将检测到的纱管图像与模板进行匹配;高畅等[9]采用多分类支持向量机利用提取特征进行纱管分类。然而,这些经典方法十分依赖于定义的特征,在面对复杂背景、光照变化、遮挡等情况时容易出现误判或漏判,难以满足企业的要求。
基于深度学习的目标检测方法已成为目标识别的主流方法,可以分为2类:Two-Stage和One-Stage。Two-Stage算法具有较高的准确率,但检测速度相对较慢。最早将卷积神经网络应用于目标检测的Two-Stage算法是R-CNN[10],该算法在检测速度和精度上均存在一定限制。随后的Fast R-CNN[11]、Faster R-CNN[12]和Mask R-CNN[13]算法在检测速度方面有所提升。One-Stage算法具有更快的检测速度,但准确率相对较低,具有代表性的One-Stage算法包括YOLO[14-16]和SSD[17],这些算法在速度方面表现出色,但随着网络不断加深,导致图像中信息丢失,于是Lin等[18]提出特征金字塔(feature pyramid networks,FPN);徐建等[19]采用改进的AlexNet模型进行了纱管识别,其识别效率有效提高,然而,该方法仅适用于单个物体的图像识别,难以满足现实情况下的多物体场景需求。
针对上述问题,本文以目前主流的YOLOv5算法为基础,进行算法改进研究,以增强对纱管的特征提取能力,提高纱管的检测精度和检测性能,同时实现多物体场景下的纱管识别需求。
1 YOLOv5s网络
如图1所示,YOLOv5s模型由4个部分组成:Input、Backbone、Neck和Head。Input部分包括mosaic数据增强、自适应锚框计算和自适应图片缩放;Backbone部分包括Focus、CBS、C3、SPP等模块,用于从输入图像中提取特征信息;Neck部分采用了PAN结构,通过不同层次的特征融合来提高模型的检测精度;Head部分采用了CIoU损失函数,输出80×80、40×40、20×20这3个不同尺度的特征图,可以检测小、中、大不同尺寸的物体。
2 YOLOv5s算法改进
本文从以下5个方面进行算法改进:
a.将Backbone网络中最后一个C3模块的Res Block替换为Transformer Block。
b.将SPP模块替换为SPP+模块。
c.在SPP模块和C3模块之间添加坐标注意力(CA)模块。
d.在PAN基础上添加BiFPN结构。
e.将原来的CIoU损失函数替换为WIoU损失函数。
改进后的YOLOv5s算法框架如图2所示。
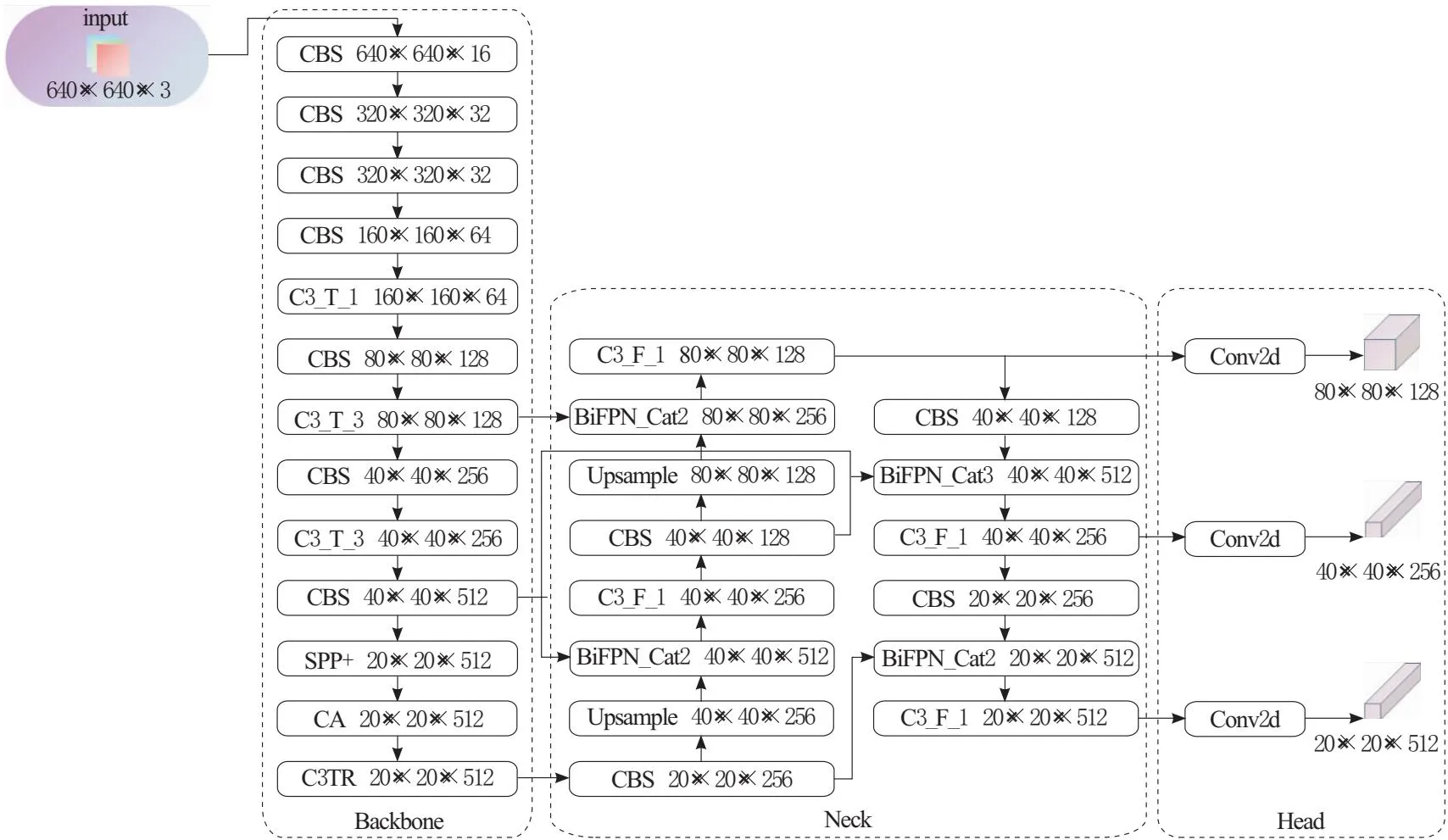
图2 改进后的网络结构
2.1 Transformer模块
Transformer模块可以被用来对目标特征进行全局上下文信息的编码和解码,使得模型能够更好地学习到目标之间的依赖关系,从而提高模型的检测精度,故以Transformer模块替换C3的Res Block模块,Transformer结构如图3所示。
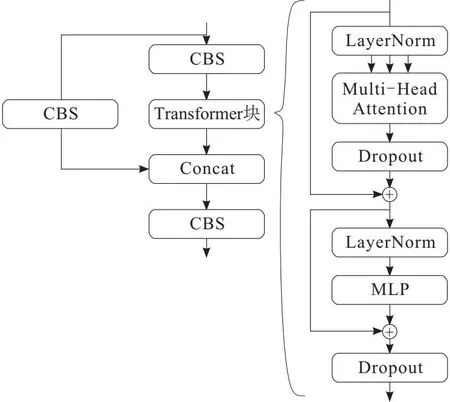
图3 Transformer模块结构
2.2 CA注意力模块
通过将位置信息嵌入到通道注意力中,CA[20]注意力模块能够捕获跨通道信息、方向感知和位置敏感信息,提升网络特征融合能力和捕获更多位置细节。同时,CA注意力模块能够动态调整通道的权重,适应不同的任务和数据集,提高网络的泛化能力。
此外,因为其能够区分不同通道的特征,提高特征的多样性,这使得模型能够更准确地提取重要的特征信息,提高模型的检测精度。因此,在SPP模块和C3模块之间添加坐标注意力(CA)模块。
CA模块可以被视为一种计算单元,可以接受一个形状为X=[x1,x2,…,xc]∈RC×H×W的张量作为输入,然后输出一个形状相同但具有增强特征表示能力的张量Y=[y1,y2,…,yc]∈RC×H×W,具体过程如图4所示。
2.3 BiFPN
在目标检测任务中,由于不同尺度的特征往往包含了不同的信息,因此融合不同尺度的特征对于提高检测准确性非常重要。本文为了实现快速而简单的多尺度特征融合,采用BiFPN的思想[21],并将其应用于YOLOv5s的多尺度特征融合部分。通过添加跨尺度连接,可以将不同尺度的特征融合起来,以便在不增加太多计算成本的前提下提高特征融合的效果。在融合过程中,为了让网络更好地学习到每个特征层对目标检测任务的贡献,为每个节点设置了权重,以便充分学习每个特征层的重要性分布权重,从而在多尺度特征融合过程中提高检测准确性。
2.4 SPP+模块
SPP+是SPP的一种改进,它旨在解决SPP在处理不同尺度物体时可能会出现的信息损失问题。SPP在网络中使用池化操作来处理不同尺度的物体,但由于不同尺度的物体具有不同的空间布局和变形,导致其感受野大小不足以保留所有的空间信息,从而影响了检测精度。为了解决这个问题,SPP+引入了多个具有不同感受野大小的卷积层,这些卷积层与平均池化层叠加和拼接,如图5所示,使得SPP+可以更好地保留不同尺度的空间特征信息,从而减少信息损失,提高了目标检测的准确性。
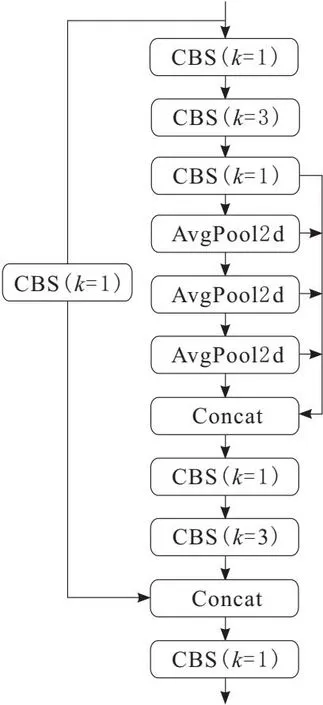
图5 SPP+模块结构
2.5 损失函数
在目标检测中,边界框回归(bounding boxes regression,BBR)的损失函数对于模型的性能提升至关重要。然而,训练集中存在大量低质量实例,若在这些实例上盲目强化BBR,反而会影响模型的检测能力。为了解决这个问题,Zhang等[22]出了Focal-EIoU v1,但其聚焦机制是静态的,没有充分挖掘非单调聚焦机制的潜力。因此,本文引入WIoU策略,它不仅可以降低高质量锚框的竞争力,还可以减小低质量示例产生的有害梯度,使得WIoU可以更好地聚焦于普通质量的锚框,并提高整个检测器的性能。
3 纱管检测实验与结果分析
3.1 纱管数据集
针对目前缺乏标准纱管数据集的情况,本文自行构建了纱管数据集。首先拍摄了不同类型的纱管照片,包括经纱管、纬纱管、粗纱管、宝塔型纱管、宝塔型网眼纱管、并行管、小型塔状纱管和加弹纱管等8种类型。之后采用Roboflow进行纱管照片的实例标注。随后,采用剪切、加入噪声和模糊等方法对数据集进行了数据增强处理,最终得到了一个包含4 385张图片的纱管数据集,其中训练集图片3 965张,测试集图片420张。
此外,为了验证改进的YOLOv5s算法的有效性,实验还使用了开源的安全帽佩戴数据集(safety helmet wearing detect dataset,SHWD)进行验证。该数据集包括9 044个佩戴安全帽的正样本人物头像和111 514个未佩戴安全帽的负样本人物头像,以训练集∶测试集=9∶1的比例划分数据集,得到训练集有2 916张正样本图像和3 905张负样本图像,测试集有325张正样本图像和435张负样本图像。
3.2 实验环境及参数配置
实验平台为Windows11 64位操作系统,Intel(R) Core(TM) i7-12700H处理器,运行内存16.0 GB,6 GB显存的NVIDIA GeForce RTX 3060 Laptop GPU,CUDA版本为11.7,PyTorch版本为1.13.0,Python3.8环境。
实验在数据集上从头开始训练权重,使用Adam优化器对网络参数进行迭代更新,batch大小设为8,训练周期为100个epoch,初始学习率设为0.01,权重衰减系数设置为0.000 5,在前3个epoch使用Warm-Up方法,之后使用余弦退火算法更新学习率。
3.3 评价指标
为了精确评估改进后的YOLOv5s算法模型的性能,本文采用召回率R、精度P、均值平均精度KmAP)3个指标对模型进行性能评估。计算公式为
(1)
(2)

(3)
(4)
式中:n为类别总数;KAP为用于衡量模型对某一类别的平均精度;KmAP为所有类别的平均KAP值;MTP为算法预测正确的正样本;MFP为算法预测错误的正样本;MFN为算法未预测出的正样本。
3.4 消融实验与结果分析
本文算法从特征提取、特征融合和损失函数几个方面对YOLOv5s进行改进,为了评估每个模块对目标检测的优化程度,分别在纱管数据集和公共数据集上设计了单项的消融实验,实验结果如表1和表2所示。
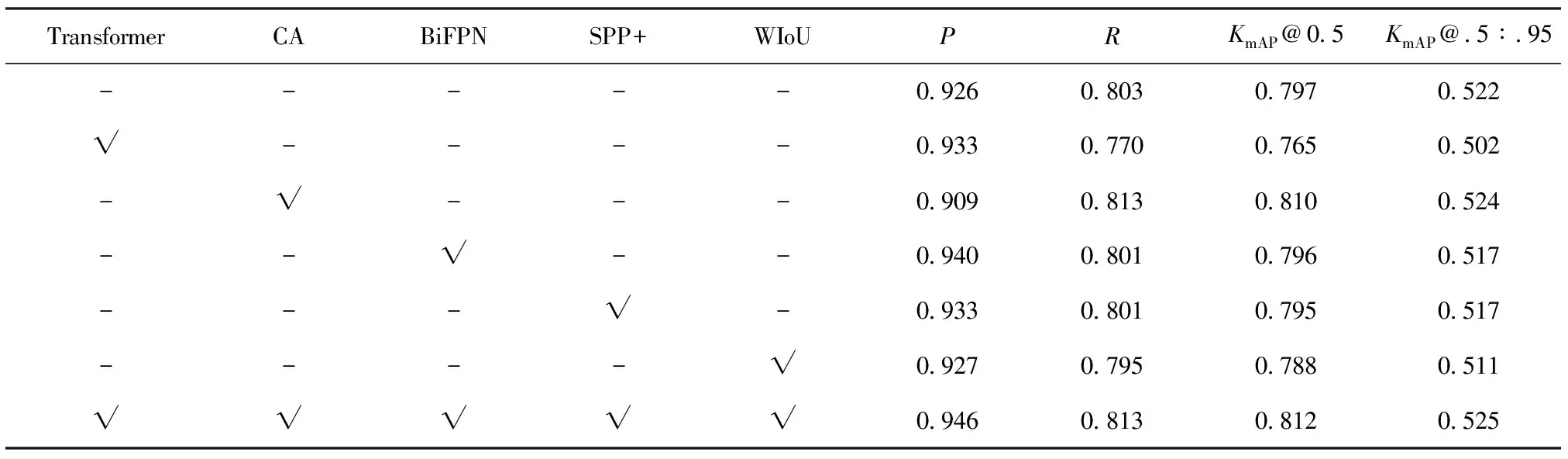
表1 在公共数据集上的性能比较
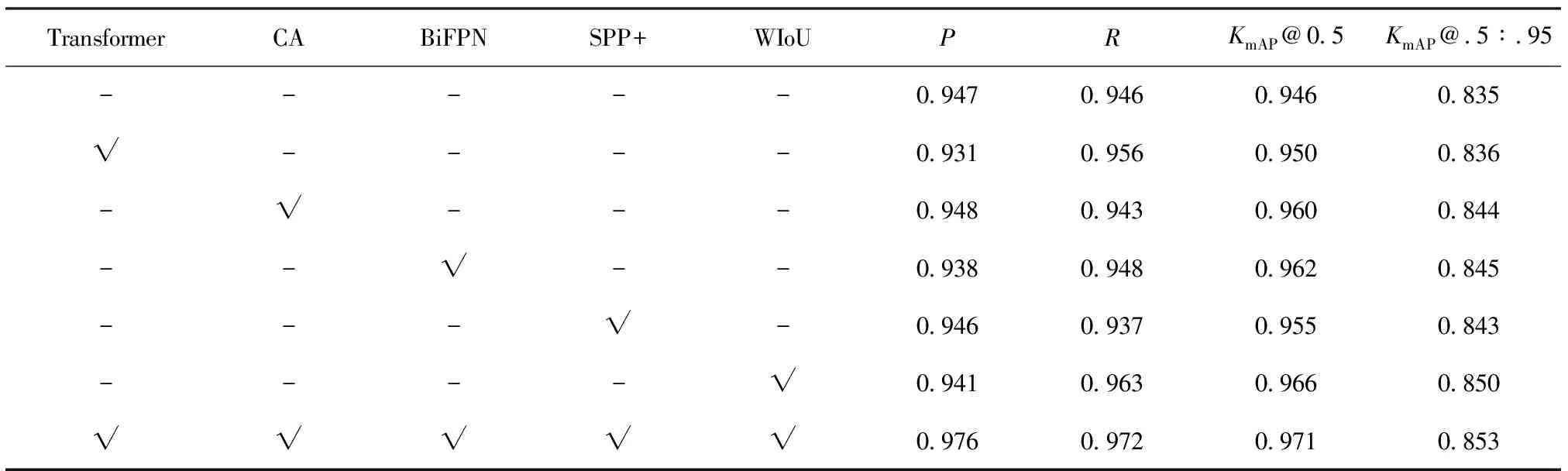
表2 在纱管数据集上的性能比较
表1和表2中,“-”表示未采用当前模块,“√”表示采用当前模块。2个表中的第一行均为原始YOLOv5s算法,最后一行则为所提出的改进算法,中间几行是进行消融实验后得到的对比算法。
根据表1、表2可以看出,对于单个模块的检测效果,无论是纱管数据集还是公共数据集,本文所采用的4个指标并不能全部提升。具体而言:
a.在公共数据集上:BiFPN方法对精度提升较明显,提升了0.014,但是KmAP@.5:.95下降了0.005;CA注意力机制对召回率和KmAP@0.5提升较为明显,分别提升了0.010和0.013,但精度下降了0.017,下降较为明显。
b.在纱管数据集上,采用WIoU作为损失函数对召回率、KmAP@0.5和KmAP@.5:.95提升较为明显,分别提升了0.017、0.020和0.015。
c.相比之下,本文改进后的YOLOv5s算法在纱管数据集上,每个指标都能得到提升,精度、召回率、KmAP@0.5和KmAP@.5:.95分别提升了0.029、0.026、0.025和0.018;在公共数据集上,精度、召回率、KmAP@0.5和KmAP@.5:.95分别提升了0.020、0.010、0.015和0.003。综上所述,改进后的算法漏检率低、误检率低、识别精度高,能够实现对不同种类纱管的有效检测。
图6通过可视化的对比方式直观的体现出改进算法的优势,其中图6a是YOLOv5s算法的检测结果,图6b是改进后算法的检测结果。由图7可以看出,改进后的算法检测出了部分原算法无法检测到的被遮挡物体。

图6 纱管检测效果对比
4 结束语
本文在YOLOv5算法基础上,将CA注意力机制和Transformer融入骨干网络,使用SPP+模块替换传统的SPP模块,采用BiFPN思想来增强特征融合,并使用WIoU损失函数替代原有的损失函数。实验结果表明,改进后的算法表现出漏检率低、误检率低和识别精度高等优点,能够有效地应用于不同种类纱管的检测。
