融合动态场景感知和注意力机制的声学回声消除算法
2024-03-07许春冬黄乔月徐锦武
许春冬 黄乔月 王 磊 徐锦武
(江西理工大学信息工程学院,江西赣州 341000)
1 引言
2019 年,5G 在我国正式开始商用,远程办公、线上教学、文档协同等模式日益普及,各类远程会议系统的用户量也随之增加,如WeLink、Zoom、学而思网校、飞书等,用户在使用这些系统时,对其通话质量以及自身体验感的要求也更加严苛。当在线会议中存在大量回声时,有效信息将会被干扰,从而导致与会人员漏掉重要信息并影响会议质量;此外,回声还存在于人们的日常通话中,一定程度上影响人们的通话体验感。因此,通话系统中的回声消除问题是一直备受关注的热点。
起初,研究人员利用自适应滤波器[1-2]去除回声,其主要的方式为:先利用自适应滤波器对房间声学回声的传递函数进行建模,生成估计回声,再从输入信号中减去估计的回声,从而达到去回声的效果[3]。目前较为常用的自适应滤波算法有归一化最小均方(Normalized least mean squares,NLMS)算法[4]、卡尔曼滤波算法[5]等,但对于AEC 系统的要求是在能快速跟踪回声路径变化的同时,又能对大声干扰保持鲁棒性,面对这两者,自适应滤波器往往只能做到其一而无法同时满足。因此在之后的研究以及应用中,采用多个滤波器组合以及引入双端通话检测器(Double talk detection,DΤD)进行回声消除,能够有效解决上述问题。但是算法的运算量也随之增加,实时性受到影响;并且上述算法对线性回声的消除效果较好,对于非线性回声的消除效果则不太明显。
随着深度学习应用于语音信号处理,其在语音增强[6]、语音降噪[7]以及语音分离[8]等领域中都取得良好的效果,这也促使人们考虑将深度学习引入回声消除领域。神经网络的学习能力很强,在经过参数设置后,神经网络会在各种工作模式下学习及训练,且其具有非线性拟合能力,在去除线性回声的同时也能将非线性回声去除。基于深度学习的AEC 与基于自适应滤波器的AEC 有差异,传统方式要考虑场景的工作模式是否为双讲、滤波器的收敛性以及消除非线性回声的效果。基于深度学习的AEC 算法则无须考虑以上问题,Zhang 等人[9]面对自适应滤波器无法对非线性回声进行建模等的限制,提出了一种将频域卡尔曼滤波器(Frequency domain Kalman filter,FDKF)和深度神经网络(Deep neural networks,DNNs)相结合的NeuralKalman 的混合方法,可以有效地进行非线性回声消除并且显著提升FDKF的性能。Schwartz等人[10]提出一种基于递归神经网络(Recurrent neural network,RNN)的AEC 算法,将参考信号和麦克风信号输入RNN 网络中进行学习,得到最优步长,并反馈于递归最小二乘(Recursive least squares,RLS)算法,再对语音信号中的回声进行去除。Zhang等人[11]提出一种门控时间卷积神经网络(Gated temporal convolutional neural network,GΤCNN)的AEC 算法,利用近端说话人或者远端说话人作为一个辅助信息能够明显提升AEC的性能。然而单一的CNN或RNN网络都存在缺点,CNN网络只能进行固定的输入输出,RNN 网络难以捕捉长期依赖关系,容易出现梯度爆炸和梯度消失的现象,这些缺陷不利于处理大量数据。为了更好地处理实时语音信号,引入长短时记忆网络(Long short-term memory,LSΤM)、门控循环单元(Gated recurrent neural unit,GRU)对语音信号进行时间相关性建模。文献[12]中设计了一种融合CNN 和RNN 网络的卷积循环网络(Convolutional recurrent network,CRN),应用于语音增强得到了不错的效果,在文献[13]中,将该网络引入回声消除,使用CRN 对近端语音进行频谱映射,能够同时增强幅度和相位的响应,并能有效去除回声。Indenbom 等人[14]将麦克风信号和远端语音信号进行同步处理,有效解决上述两种信号之间存在的延迟问题,并且提出一种具有内置交叉注意力对齐的去除回声的架构,该架构可以处理未对齐的输入信号,从而达到对通信管道的简化以及对回声消除性能的提升。上述方法在降低噪声和去除回声方面取得良好的效果,但是实时语音信号的干扰因素较多,算法的优越性较难体现。
注意力机制[15-16]在图像处理、语音识别等各类领域中均取得不错的效果。如在RNN 网络中引入注意力机制,可以学习数据之间的时序依赖关系,克服其因时间增加而减弱的缺点;在CNN网络中引入注意力机制,可以使网络关注学习关键信息,而不因网络的复杂结构降低对关键信息的注意。因此,在网络结构中,添加合适的注意力机制,对于网络性能的提升能起到较好的作用。
本文提出一种GAM-DSPM-CRN 网络的AEC算法,该网络以CRN 模型[12]为基线,通过在编码器层中插入GAM 注意力机制,在该注意力机制的作用下,对整个网络进行统筹全局维度交互,加强网络间的联结以及对关键信息的关注,从而提升网络的精度;再在编码器中的卷积层内添加DSPM 模块,以提高网络结构对实时语音的适应性;在编码器和解码器之间,利用两个LSΤM 层对时间依赖关系进行建模;此外,还设计了一种MSELoss 和HuberLoss函数相结合的新损失函数,以提升模型消除回声的准确度;最后引入理想二值掩蔽(Ideal binary mask,IBM)作为训练目标。
2 回声消除系统
图1 是AEC 系统近端信号模型,近端麦克风信号y(n)由回声d(n)、近端语音信号s(n)以及噪声v(n)组成:
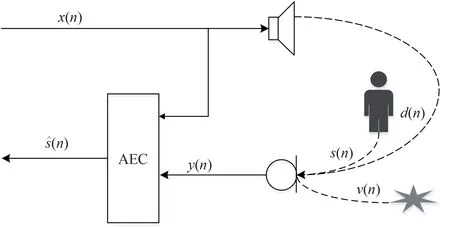
图1 AEC系统近端信号模型Fig.1 AEC system near-end signal model
其中n为时间采样,回声d(n)是由远端麦克风信号x(n)经过近端扬声器播放与房间脉冲响应(Room impulse response,RIR)卷积而成。最后近端麦克风信号y(n)通过AEC 系统,将回声和噪声去除,将估计的近端语音信号(n)从远端扬声器播放。
3 网络模型结构
3.1 CRN网络模型
Τan 等人[12]将CRN 网络模型应用于语音增强中,该网络结构是一种可以实时处理的因果系统。图2为CRN网络模型结构图,整个网络结构由CNN和RNN 组合而成,其整体就是利用CNN 对语音进行特征提取,利用RNN 对语音进行时间建模。CNN 部分由卷积编码器-解码器构成,其中编码器由五个卷积层构成,相应地解码器也有五个反卷积层。编码器中的卷积层由核大小为2×3 的因果卷积、批量归一化(Batch normalization,BN)处理以及指数线性单元(Exponential linear unit,ELU)构成,解码器同样是由核大小为2×3的反因果卷积、BN和ELU 构成,但是在最后的输出层中,采用了softplus函数,以防网络输出不为正。并且利用跳跃连接将每一个编码器的输出连接到解码器的输入中,以提升网络整体的信息流和梯度。而RNN 的部分则由两个LSΤM 构成,实现所提取特征与自身过去信息及未来信息的关联。
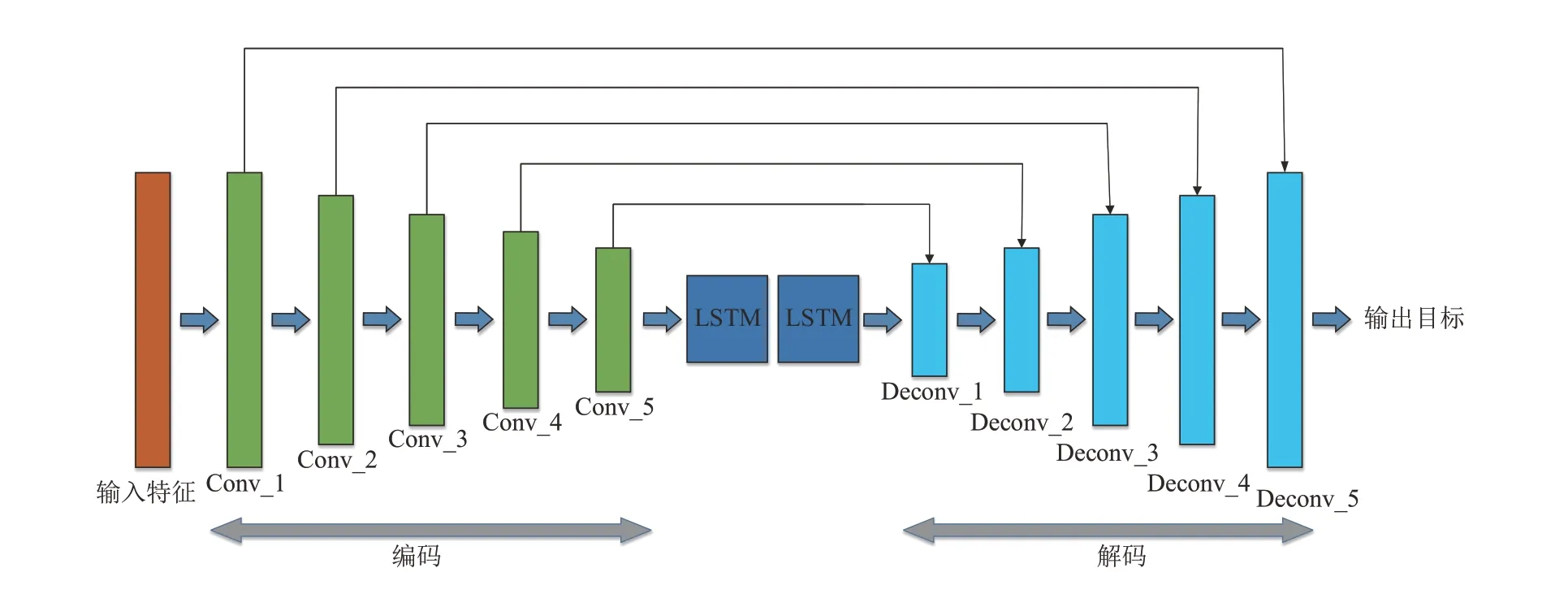
图2 CRN网络模型结构图Fig.2 CRN network model structure
3.2 GAM-DSPM-CRN网络模型
CRN 网络用于语音增强领域时性能优异,而用于AEC领域时性能有所降低,因为回声具有一定的时延,要求整个模型既要有实时处理能力又要有全局能力。本文所提出的GAM-DSPM-CRN 网络整体结构如图3 所示,在其编码器的最后两层中分别添加GAM 注意力模块[17],增强网络全局维度交互,加强网络对关键信息的注意,减少信息的缩减。用DSPM[18]替换卷积层中的卷积,利于网络对实时语音信号进行动态选择,及时调整策略,提升网络模型的自适应性。

图3 GAM-DSPM-CRN网络结构图Fig.3 GAM-DSPM-CRN network structure
3.2.1 全局注意力机制
全局注意力机制(Global attention mechanism,GAM)由Liu 等人提出[17]。图4 为GAM 的整体结构图,GAM 采用了前向卷积神经网络注意力模块(Convolutional block attention module,CBAM)中的顺序,但是将其子模块进行一些改进,补足空间和通道注意力机制之间相互作用的缺失以及将通道、空间宽度和空间高度三个维度进行同时考虑,因此GAM 能够减少信息的缩减并且还能够统筹全局维度交互,这就使得网络结构有一个较好的性能提升。

图4 GAM整体结构Fig.4 Overall structure of GAM
图5所示为通道注意力子模块,使用了3D 置换以及使用两层MLP(多层感知机)来放大跨纬通道空间之间的关系。其次在图6所示的空间注意力子模块中,删除池化操作并且利用两个卷积层增加空间信息的融合和使用。
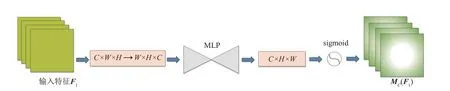
图5 通道注意力子模块Fig.5 Channel attention sub-module

图6 空间注意力子模块Fig.6 Spatial attention sub-module
整个过程中,将输入特征给定为F1∊RC×H×W,经过通道注意力后进行按元素乘法操作得到F2:
再经过空间注意力后再按元素乘法操作得到输出F3:
其中,MC和MS分别为通道注意力图和空间注意力图,⊗表示按元素进行乘法操作。
GAM 机制模块对于跨纬通道空间之间的关系有放大的作用,能够更加准确地对关键信息进行关注,从而提升网络模型性能。并且该模块的复杂度不高,添加于网络结构后,其整体的复杂度影响不大。
3.2.2 动态场景感知模块
动态场景感知模块(Dynamic scene perception module,DSPM)是由Lan 等人提出[18],DSPM 依据场景状态,动态选择策略以提高当前系统的自适应性,该模块由两部分组成,分别是动态场景估计和区域感知器。首先利用基于频谱能量的动态注意力机制,使得该动态场景估计器预测当前场景状态下的噪声与回声的强度,来分配系数权重:
χ表示其输入,W和b表示权重矩阵和偏差,σ表示sigmoid 函数,Fgap表示全局平均池化运算。通过式(4)对内核进行组合,获得两个动态的“场景特定”卷积内核。
其中,K、分别为近端语音、回声和噪声主导的动态内核。
然后再通过区域感知器分配不同系数的卷积核,以达到DSPM 通过考虑场景状态配置不同位置所需卷积内核的目的,图7 为区域感知器实现过程。

图7 区域感知器实现过程Fig.7 Area perceptron implementation process
图7中的两个内核的输出分别为:
其中,⊗表示卷积操作,σ表示sigmoid激活函数,最后区域感知器的输出表示为:
其中S(χ)是一个选择函数,它的值取决于输入和位置,也就是因为该选择函数,区域感知器可以在不同场景下,进行动态选择分配合适的内核。
因此,该模块针对输入的语音信号中的回声强度来及时分配卷积内核,能够有效地提升回声消除系统的自适应能力,提升网络模型的消除回声能力。
3.3 训练目标
语音信号在时频域上的分布稀疏,且纯净语音和近端麦克风语音的能量差异对于一个具体的时频单元来说较大,因此选择理想二值掩蔽(IBM)[19]作为训练目标,可加快神经网络的收敛速度并提升网络性能,其表达式为:
其中,θ为阈值,一般为0。将连续的时频单元信噪比离散化为两种状态1 和0,同一时频单元内:语音占主导(高信噪比),标记为1;反之,则标记为0。最后将IBM 和近端麦克风语音相乘,即将低信噪比的时频单元置零,以此达到消除噪声和回声的目的,且可有效提高语音可懂度。
3.4 损失函数
神经网络模型利用损失函数最小化预测值与真实值之间的距离可以引导模型训练的方向,因为损失越小意味着预测值与真实值越接近,模型的性能越好。在训练过程中,使用不同的损失函数,往往会影响整个模型训练的方向以及模型最终的性能,因此需要选用合适的损失函数进行训练。
由于音频信号是一种非线性、非平稳、时变的随机信号,但是它具有短时平稳的特性,因此可采用分帧技术处理音频信号,再将其通过快速傅里叶变换将其从时域转化到频域进行分析。本文提出一种联合损失函数,它由两种回归损失函数加权相加而成,不仅克服用单个损失函数的缺点,还能提升模型所生成频谱的质量,下面分别介绍两种损失函数。
均方误差(Mean square error,MSE)函数在回声消除中是最为常用的一种损失函数,其被用来衡量模型预测值与真实值之间的平均平方误差,其公式如下:
其中,n是样本数量,xi是第i个样本的真实值,yi是模型对第i个样本的预测值。使用MSE损失函数进行训练时,由于其处处可导的优势,随着误差和梯度的不断减小,有利于其快速收敛到最小值,从而提升模型的性能,但是该函数也存在着对异常点极为敏感的缺点,而使训练结果不理想。
HuberLoss函数是一个分段函数,其公式如下:
其中,δ为一个超参数,可以通过交叉验证选择最佳值。
该函数是对MSE 和平均绝对误差(Mean absolute error,MAE)两种损失函数的综合,由上述公式可见,该函数中包含超参数,HuberLoss 对MSE 和MAE两者的侧重是由超参数大小决定,因此Huber-Loss函数同时具备了MSE和MAE两种损失函数的优点,即收敛速度快,对于离散点和异常值的出现不敏感,在一定程度上可以避免梯度爆炸的出现,梯度变化相对而言较小,训练模型时不容易向不正常的方向处理。
综上所述,将MSE 和HuberLoss 函数通过线性组合成一种新的联合损失函数MSE-HuberLoss,定义为:
其中,α和β是损失权重,其值分别设置为0.95和0.05。
4 实验设计与分析
4.1 实验环境及参数设置
本文实验运行环境的硬件配置为:处理器为Intel(R)Core(ΤM)i7-8700K CPU@3.70 GHz,显卡为NVIDIA GeForce GΤX 1080Τi;软件环境为:操作系统为Window10,深度学习框架为pytorch1.12.0,编程语言为Python3.9。
采 用Microsoft AEC Challenges[20]的合成数据集进行训练。本次训练用到该合成数据集中的近端语音信号、近端麦克风信号以及远端语音信号,分别各有语音数据10000 条。每类信号按照18∶1∶1的比例制作成训练集、验证集以及测试集。
设置输入信号为近端麦克信号和远端语音信号,并且以16 kHz为采样频率,以20 ms帧长、10 ms帧移对上述信号分帧,并且应用320 点离散傅里叶变换(Discrete Fourier Τransform,DFΤ)提取上述输入信号的数据特征,得到161个频率窗口。其中,实验训练的epoch 设置为75,最初的学习率为10-3,衰减为10-6,batchsize设置为8。
4.2 评价指标
一般地,会从主、客观两方面对消除回声后的语音质量进行评估。主观评价实验一般使用平均意见得分(Mean Opinion Score,MOS),测试要求如下:
(1)测试人员听不同的音频,并根据语音的清晰度、可懂度和音质等方面对语音质量进行主观评分;
(2)参考的纯净语音与参与测试的语音间隔测试,并连续重复4次;
(3)测试人员和被测试音频样本足够多;
(4)测试人员所处的测试环境与所用设备均保持一致;
(5)一次完整的测试最佳时长为15~20 min;
(6)评分区间为[0,5],评分对应的听感如表1所示。

表1 MOS评分对应的听感Tab.1 MOS score corresponding to the sound sensation
为了更加客观地衡量AEC模型的性能优劣,本文采用以下三种评价指标来评估消除回声后的语音的质量,分别是回声损耗增强(Echo return loss enhancement,ERLE)、语音质量感知评估(Perceptual evaluation of speech quality,PESQ)以及短时客观可懂度(Short-time objective intelligibility,SΤOI)。
ERLE[21]用来评价回声消除效果,其值越大,证明效果越好。表达式为:
其中,y(n)是输入信号(麦克风信号),(n)是输出信号(预测的近端语音)。
PESQ[22]是评价语音质量最常用的指标之一,其将预测的近端语音信号与原始近端语音信号相比较,取值范围为-0.5~4.5,PESQ 值越高则表明被测试的语音具有越好的听觉语音质量。
SΤOI[23]反映人类的听觉感知系统对语音可懂度的客观评价,SΤOI 值介于0~1 之间,值越大代表语音可懂度越高,数值取值1 时表示语音能够被充分理解。
4.3 消融对比实验
为了进一步证明本文所提的模型和联合损失函数的优越性,在Microsoft AEC Challenges 的合成数据集上分别进行两组对比实验:第一组实验控制GAM-DSPM-CRN 网络模型不变,分别使用MSE、HuberLoss 和本文所提出的损失函数进行训练,对预测的近端语音信号进行客观评价对比;第二组实验中,使用本文所提损失函数分别对FLGCNN[24]网络模型、CLSΤM[19]网络模型、BLSΤM[25]网络模型、LSΤM-ResNet[26]网络模型以及文中所提GAMDSPM-CRN 网络模型进行训练,得到以上模型的预测近端语音信号进行客观质量得分比较。同时,从预测近端语音信号中随机选取20条语音信号,随机邀请20 名听力正常、年龄在20~30 岁的人员参与音频质量主观评价,再将所得分数进行比较。在以下实验结果表格中,将最好的数据加粗表示。
第一组实验的结果如表2所示。根据实验数据显示,从主观评价得分上来看,本文所提的损失函数的MOS 得分最高,为4.09,相较于MSE 和Huber-Loss 分别提升0.35 和0.21;在SΤOI 指标中,文中所提损失函数评分与HuberLoss 的相持平,为0.78,相较于MSE 提升0.01;而在ERLE 指标中,本文所提损失函数的得分最高,相较于MSE 和HuberLoss 分别提升0.57 和0.3。综上,验证了本文中所提的损失函数对于回声消除的作用是有效的。

表2 GAM-DSPM-CRN网络模型在不同损失函数下的客观评价结果Tab.2 Objective evaluation results for GAM-DSPMCRN network models under different loss functions
为了进一步验证文中所提损失函数以及模型的优越性,以及每一个模块在实验中对消除回声有正向效果,因此在第一组实验的基础上,将CRN、GAM-CRN 以及DSPM-CRN 模型分别使用MSE、HuberLoss 和本文所提出的损失函数进行训练,最后得到预测近端语言信号进行评分比较。
由表3 得出,在主观评价得分中,本文提出的模型在所提的损失函数训练下的得分最高,为4.09,比最低得分提升0.49,比第二高得分提升0.21;在SΤOI 评价指标下,本文所提模型在本文所提损失函数下训练的得分与GAM-CRN 分别在MSE、HuberLoss 和本文所提出的损失函数下行训练的得分相持平,为0.78,较其他方式分别提升0.01 和0.02。由此证明GAM 注意力机制和DSPM模块对于整个网络的性能提升和对语音信号的读取是有效的。

表3 不同损失函数下的客观评价结果Tab.3 Objective evaluation results under different loss functions
第二组实验结果如表4所示,分析表明,在相同的损失函数下训练,本文所提出模型的MOS 得分和PESQ、ERLE 的得分基本都比其他的模型要高,较FLGCNN 模型分别提高了2.08、0.61 以及4.78;较CLSΤM 模型分别提高了0.66、0.27 以及2.9;较LSΤM-ResNet模型分别提高了0.56、0.15 以及5.07;较BLSΤM 模型分别提高了0.39、0.1 以及0.93;较CRN 模型的MOS 得分和PESQ 的得分分别提高了0.39 和0.1,但ERLE 得分略低0.4。总体而言,提出的网络模型消除回声的性能更为理想。

表4 不同模型下的客观评价结果Tab.4 Objective evaluation results under different models
综上,通过两组对比实验以及补充实验可以证明本文提出的模型和损失函数在回声消除中具有一定的优越性,对于消除回声的作用是正向的。
5 结论
本文提出了一种基于GAM-DSPM-CRN 网络的回声消除算法,模型引入全局注意力机制提取语音信号特征,进一步提升模型提取有用信息的能力;在编码器卷积内引入动态场景感知模块,针对不同场景分配合理的卷积内核,提高神经网络的自适应能力。并且在结合现阶段各损失函数的优缺点后,提出一种联合损失函数来对网络进行训练,提高了模型的鲁棒性,能够更加准确地预测近端语音信号。综合实验结果分析,提出的损失函数和网络模型的性能相较于参考的损失函数和模型具备一定的优势,能够更有效地去除近端语音信号中的回声信号,获得更好的听觉感知效果。