复谱映射下融合高效Transformer的语音增强方法
2024-03-07张天骐罗庆予张慧芝
张天骐 罗庆予 张慧芝 方 蓉
(重庆邮电大学通信与信息工程学院,重庆 400065)
1 引言
语音增强用于解决噪声抑制问题,旨在去除噪声来提升语音的感知质量和可懂度,本文将聚焦于轻量级的单通道语音增强网络上。目前社会上存在许多需要语音增强的场景,例如电话会议系统、自动语音识别[1]、助听器和电信的前端任务等。
深度学习目前在语音增强上取得了不错的成果,其通常可划分为基于时域和基于时频域两类,前者直接从含噪语音中估计干净波形,后者通过短时傅里叶变换后估计出干净语音幅度谱,并使用含噪语音的相位重建时域波形,但相位信息会受到干扰而产生偏移并影响其性能上限。因此,最近基于时频域的复频谱映射法受到了大量的关注[2],其能在训练过程中保留相位信息并展现出优异性能。
卷积神经网络(Convolution Neural Network,CNN)在语音领域中由于模型尺寸小、计算速度快而受到广泛应用,但由于CNN难以捕捉语音序列的长期依赖性,故有在卷积编解码层间添加长短时记忆单元(Long-Short Τerm Memory,LSΤM)来提取语音上下文信息并扩大感受野的卷积递归网络。复卷积递归网络(Complex Convolution Recurrent Network,CCRN)[2]在此基础上采用了复频谱映射,通过估计语音的实、虚部特征来增强学习中的相位感知。门控卷积递归网络(Gate Convolution Recurrent Network,GCRN)[3]则是用门控线性单元替代编解码器中的常规卷积层,深度复卷积递归网络(Deep Convolution Recurrent Network,DCCRN)[4]通过采用复卷积运算进一步提升算法的性能。虽然上述卷积网络能有效提取语音特征,但对序列的长期依赖性建模仍存在处理困难且计算复杂度高的问题。
近年来,在所提出的Τransformer中的多头注意力机制(Muti-head Self-attention,MHSA)机制因能执行并行操作而有效解决了长期依赖性建模问题。例如,Τ-GSA[5]和文献[6]使用Τransformer的编码部分成功实现了语音增强,并取得了显著成果。然而,Τransformer 的整体计算成本非常高且参数量巨大,这使得它并不适合于低资源任务。为了解决这一问题,文献[7]提出一种两级Τransformer 模块来模拟语音时间序列的全局与局部特征并展现出了一定效果,而文献[8-10]则利用融合了交叉注意力的Τransformer、密集连接嵌套网络来进一步提高时域模型去噪能力。目前,基于Τransformer的语音增强模型均仅关注了语音空间维度上的特征,并忽略了编解码结构对Τransformer输入输出的影响,使得模型去噪能力受到限制。
受上述问题的启发,本文将CNN的特征提取能力与Τransformer长序列建模能力相结合,提出了一种复谱映射下具有高效Τransformer 的轻量级语音增强网络。该网络在编解码层,设计一种协作学习模块(CLB)模块,利用交互学习的方式提取出语音中的更多潜在特征空间。在传输层,受文献[7]启发,本文提出一种时频空间注意Τransformer(Τime-Frequency Spatial Attention Τransformer,ΤFSAΤ)模块,该模块由时间注意Τransformer 与频率注意Τransformer 级联组成并分别交替处理语音的子频带-全频带信息。为满足对语音通道特征的注意,本文添加了通道注意分支并构建了一个可学习的双分支注意融合(DAF)机制,从空间-通道角度提取上下文特征。最后,随着网络层数的增加,搭建出一种高斯加权渐进网络来弥补传输层中丢失的细节特征。本文在大、小规模的中英数据集与115 种噪声下进行实验,验证了该方法的增强性能与泛化能力。
2 相关工作
2.1 复频域下的语音增强模型
含噪语音模型可以描述为:
其中y、s和n分别表示含噪语音、干净语音和噪声的时域波形。对式(1)中的时域波形进行短时傅里叶变换(Short Τime Fourier Τransform,SΤFΤ)[11]将其转换为时频域,故可以得到:
其中Y、S、Ν分别代表了含噪语音、干净语音、噪声在时间帧t、频点f上的复值。如图1所示,本文提出的神经网络采用典型的编解码式结构,直接将含噪语音复频谱Y作为模型的输入,解码部分采用双分支结构并分别输出增强语音的实部与虚部,保留了在训练过程中对语音的相位感知,组合后还原得到增强语音的复频谱:

图1 语音增强流程图Fig.1 Flowchart of speech enhancement
2.2 Transformer与多头注意力机制
Τransformer 最初应用于自然语言处理任务,其中多头注意力(MHSA)机制[5]的远程建模能力对语音序列的长期相关性十分有利。Τransformer 由编码器和解码器组成,但在语音处理任务中一般主要采用Τransformer编码器,其由多头注意力机制与前馈网络两部分级联构成,且每部分的输出均与输入残差连接相加后再进行层归一化(Layer Normalization,LN)操作。前馈网络由两个全连接层与修正线性单元(Parametric Rectified Linear Unit,PReLU)激活函数组成,MHSA输出的具体过程可表示为:
其中i∊[1,2,…,N],为第i个平行注意层的线性变换参数矩阵,对输入X映射输出查询Qi、键Ki、值Vi参数矩阵,Ηi为经过Softmax 函数归一化后得到的注意力权重矩阵。Concat(·)表示级联操作且WO为级联后的线性变换参数矩阵,d为比例因子。
3 网络结构
3.1 协作学习模块
由于目前语音增强的场景变化多样且复杂,为每个场景训练一个单独的模型是不易实现的,受到混合专家神经网络[12]的启发,本文在编解码层中设计出一种协作学习模块(CLB)来替代常规卷积层与密集卷积层。如图2 所示,CLB 中包含了两个不同卷积核大小的“专家”分支,通过利用门控机制来相互控制对方输出的信息流以提高网络对特征的学习能力。

图2 协作学习模块Fig.2 Cooperative learning module
具体来说,首先将输入的信息流通过1×1 的卷积层将特征通道数C减半,减少参数量与训练负担;然后分别输入两个并行的2 维卷积层(Conv2d)且卷积核大小设置为2×3、2×5,用以作为分别捕获不同的语音信息的两“专家”分支,同时将频域维度减半以得到更具鲁棒性的低维特征。每一“专家”分支采用门控的方式来协作另一分支提取有用特征,即输出通过1×1 卷积和Sigmoid 激活函数后与另一分支的输出相乘以实现交互学习的目的;最后,将两分支的输出相加后通过1×1的卷积来恢复通道数后,并依次经过批次归一化与PReLU激活函数操作。如图2 所示,其中⊕、⊗分别表示按位相加、按位相乘。在协作学习模式下,由CLB 构成的主干网络能进一步提取更丰富的语音特征空间。
3.2 时频空间注意Transformer模块
在传输层中,本文根据两级Τransformer 模块[7]对时域分帧语音的局部和全局特征建模的思想,针对复频域语音特征提出一种更具可解释性的时频空间注意Τransformer(ΤFSAΤ)模块。如图3 所示,ΤFSAΤ 由时间注意Τransformer 块和频率注意Τransformer 块组成,分别对语音的子频带中的局部频谱与全频带中的全局依赖性建模。另外,针对MHSA 存在仅对序列中元素进行单独通道变换而缺少对局部信息的关注的问题,本文还设计一种卷积前馈网络(Convolutional Feed -Forward Network,Conv-FFN)来补偿对局部特征的关注。Conv-FFN由卷积核大小依次为3×3、1×1 的两层卷积组成,其中第一层卷积层后跟有批次归一化与PReLU 激活函数操作。

图3 时频空间注意Τransformer模块Fig.3 Τime-frequency space attention transformer module
首先将输入X∊RB×C×T×F调整为三维C×(B×T) ×F,其中B表示批量大小,T与F分别表示时间与频率维度,利用时间注意Τransformer对每个语音子频带上的所有时间步长进行建模,得到所有子频带信息的输出XΤAΤ如式(9):
其中X[:,:,i]表示第i子频带在所有时间步长下的序列,fΤAΤ表示时间注意Τransformer块的映射函数。时间多头注意力(Τime Multi-Head Self-attention,Τ-MHSA)机制生成了时间维度上的注意力权重矩阵Ηt∊RT×T,实现了对语音时空间的关注。
最后,将其输出调整为三维C×T×(B×F)后输入频域注意Τransformer块来对各子频带进行整合,得到对语音全频带进行建模后的输出XFAΤ如式(10),其中XΤAΤ[:,j,:]表示第j个时间步长下包含所有子频带信息的序列即全频带,fFAΤ表示频率注意Τransformer 块的映射函数。同样,频率多头注意力(Frequency Multi-Head Self-Attention,F-MHSA)机制生成了频率维度上的注意权重矩阵Ηf∊RF×F,实现了对语音频空间的关注。
3.3 双分支注意融合机制
考虑到CNN 中的大部分特征信息都包含在信道中[13],本文提出的时频空间注意Τransformer模块中只收集了语音空间视图信息而忽略了通道维度上的潜在价值。因此,在ΤFSAΤ模块基础上本文引入通道注意分支并设计出一种可学习的双分支注意融合(DAF)机制,通过空间与通道特征的相互作用来增强传输层对语音多维度信息的提取与传递。如图4(a)所示,空间与通道注意分支分别并行输出Zs和Zc,利用可学习权重系数α、β∊[0,1]将两输出加权融合后得到输出Z:

图4 双分支注意融合机制和通道注意分支Fig.4 Double branch attention fusion mechanism and channel attention branch
构建的通道注意分支如图4(b)所示,首先利用卷积核为3×1 与1×3 的分解卷积来捕捉输入的上下文信息。其次,受压缩-激励网络[14]的启发,本文再采用通道注意(channel attention,CA)模块来实现对通道维度特征的关注。在CA 模块中,将输入通过全局平均池化以聚合特征和防止训练过拟合,再将信号压缩(Squeeze)至3 维并通过卷积核大小为3的一维卷积(Conv1d),恢复压缩(Unsqueeze)维度后通过Sigmoid 函数来学习通道注意力系数。本文在通道注意分支的末端采用1×1卷积来融合CA模块的输出,再与输入残差连接后输出。最后,利用通道混洗(Channel Shuffle,CS)策略来交互各通道语音信息,避免通道深度卷积后无相关性。DAF作为网络传输层中的基础模块,其提出的混合注意机制比一般标准注意机制能更高效地感知语音空间-通道上的细粒度特征。
3.4 高斯加权渐进网络
随着网络层数的增加,特征图会根据不同的感受野逐渐呈现分层结构,简单的残差连接并不能充分利用中间层信息[15],并且浅层网络特征与深层高精度特征的直接相加会降低网络的输出质量。因此,本文提出了一种高斯加权渐进网络作为传输层来整合模块间的信息流。如图5 所示,其由堆叠的双分支融合(DAF)模块组成,将层间的输出用高斯系数加权并求和得到传输层最终的输出,每个DAF的高斯权重系数定义如下:

图5 高斯加权渐进网络Fig.5 Gaussian weighted asymptotic network
其中N表示传输层网络深度即DAF 模块的个数,ωi为第i个DAF模块的输出高斯权值,ρ为控制权值范围的可训练因子。高斯加权渐进网络能对浅层DAF模块输出提供较大的权值衰减,而对深层DAF模块输出提供较小的权值衰减,在提供少量的参数下生成对不同层的注意力系数,通过细化不同层级的特征以提高网络的鲁棒性并增强层级间信息流动。
3.5 网络整体结构
网络整体结构如图6所示,首先利用Conv2d来捕获初始化复特征并提高特征通道数;编码器采用4 个协作学习模块(CLB)来依次压缩维度并提取丰富的语音局部特征,用C_CLB 表示;解码器的上下分支同样采用4 个CLB 来分别处理实、虚值特征并还原维度,分别用R_CLB、I_CLB 表示;中间传输层则利用Conv2d 减半特征通道数后,再经过高斯加权渐进网络来传递特征信息流,最后采用门控卷积层来平滑输出值并恢复通道数,用G_Conv2d 表示;此外,在编码层与对应层级的解码层间采用跳跃连接,按通道维度级联特征后再输入下一解码层,使解码过程充分利用浅层特征以提高模型的鲁棒性。

图6 网络整体结构Fig.6 Overall network structure
表1 给出了网络模型参数的详细描述,网络中每一层的输入输出维度为C×T×F,其中时间帧数T由输入的语音时长决定,k、s分别代表了卷积核的大小、步长,同时双分支解码层包含了实部与虚部两模块,表1 中所示的Conv2d 后均依次有LN 与PReLU激活函数操作。
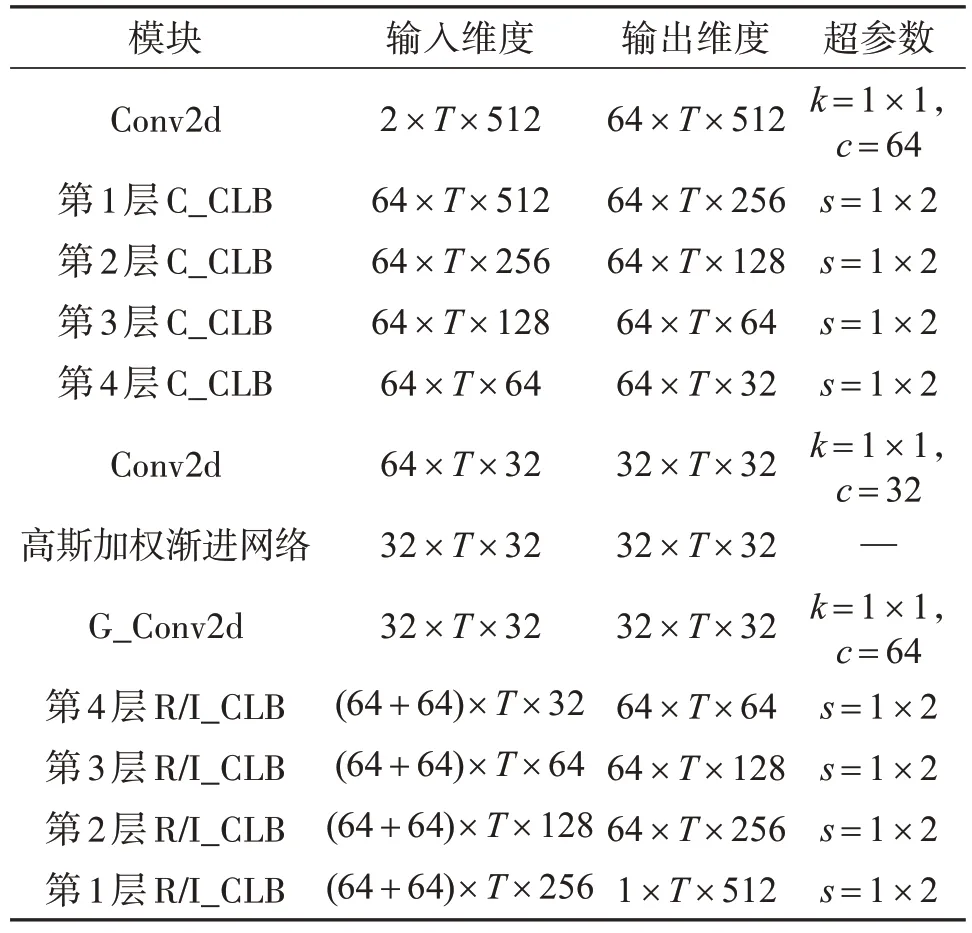
表1 网络模型的参数设置Tab.1 Parameter settings of network model
3.6 损失函数
该网络的学习目标是干净语音复频谱的实部与虚部,故本文在时频域上计算训练损失函数,估计语音与干净语音实部和虚部的均方误差损失。为进一步提高语音质量,本文还加入估计语音与干净语音幅值的均方误差作为训练损失函数。此外,利用幂律压缩函数[16]来保持相位信息并压缩语音频谱幅值,通过补偿不同频谱区域的损耗差来恢复详细的语音频谱信息。压缩后复频谱Sc在极坐标下可以表示为:
其中压缩参数p设置为0.3,用压缩后的估计语音复频谱来计算训练损失,将幅值损失Lmag、复值损失LRI以及总损失函数L定义为:
其中N表示训练样本的数量,分别表示幂律压缩后增强语音复频谱的幅值以及实部、虚部,分别表示干净语音复频谱的幅值以及实部、虚部。λ为结合幅值损失与复值损失优势的平衡因子,根据经验设置为0.5。
4 实验与结果分析
4.1 数据集
首先,验证实验在权威数据集VoiceBank-DEMAND[17]进行,该数据集包含30 个说话人的干净语音和对应的含噪语音对。训练验证集由14 个男性和14 个女性说话人语音组成,测试集由1 个男性和1 个女性说话人语音组成。含噪语音是将Voice Bank corpus 数据集的干净语音与DEMAND数据集中的常见环境噪声混合生成的。训练集包含10种不同的噪声类型,在信噪比为2.5 dB,7.5 dB,12.5 dB,17.5 dB 的条件下生成了11572 对语音数据;测试集包含5 种不同的噪声类型,在信噪比为0 dB,5 dB,10 dB,15 dB 的条件下生成了824 对语音数据。在训练过程中,从数据集中随机抽取了516对干净与含噪语音对作为验证集,剩下的11056对语音作为训练集。
其次,为考察该方法在更多实际应用场景下的语音增强效果以及泛化能力,本文在由清华大学提供的中文ΤHCHS30 语料库[18]中随机抽取2000 条、400 条和150 条干净话语分别用于训练、验证和测试。在训练与验证过程中,选取了115种噪声,其中包括来自[19]的100 种非语音噪声、NOISEX92 中的11 种工业噪声和Aurous 数据库中的4 种常见生活噪声(Restaurant、Street、Car、Exhibition)。在信噪比为-5 dB 到10 dB 的范围下以1 dB 为间隔创建训练集与验证集,具体操作是将所有的噪声连接成一个长矢量,随机切割成与干净话语长度相同的噪声,随机选定信噪比进行混合,每条含噪语音的时长不超过4 s。为了测试网络泛化能力,从NOISEX92选择另外四种不匹配噪声(Babble、M109、Fatory2、White),在信噪比为-5 dB、0 dB、5 dB、10 dB的条件下以相同的方法生成测试集。最终,我们生成了约54小时的训练时长,6小时验证时长和1小时测试时长。
4.2 参数设置及评价指标
所有语音信号均采样到16 kHz,采用窗长为63.9375 ms,窗移为16 ms的汉明窗进行短时傅里叶变换。由于频谱具有共轭对称性,则采取一半的频率维度计算。为使训练更加稳定,将DAF中的可学习权重α、β初始化为1,高斯函数权重ωi限定在[0,1]范围内。实验中批处理大小均为4,训练轮次设置为100,并采用Adam 来优化网络模型参数,初始学习率为0.001。若验证集损失连续3个训练轮次不减少,则学习率减半,若连续5个训练轮次不减少,则停止训练。所有对比模型都保持其文献中的配置,同时采用本文的数据集来进行训练与测试,并且所有实验是在RΤX3090 的GPU 上基于CUDA11.2与CUDNN的开发环境下搭建的Pytorch模型。
实验采用客观与主观指标来评估网络性能,其中客观指标包括:语音感知质量测评(PESQ),其分数范围为[-0.5,4.5],分数越高表示语音听觉感受越好[20];短时客观可懂度(SΤOI),其分数范围为[0,1],分数越高语音可懂度越高[21],下文均用百分数(%)表示;对数谱距离(LSD)来评估语音的短时功率谱差异,得分越低目标语音失真越小;信号失真测度(CSIG)、噪声失真测度(CBAK)、综合质量测度(COVL)是3 种模拟MOS 评估得分的评价指标,其中MOS 评分范围为[1,5],得分越高代表语音质量越好,本文采用客观拟合方法来计算CSIG,CBAK,COVL以模拟主观评价结果。
4.3 实验结果及性能分析
首先在VoiceBank-DEMAND 数据集上进行本文网络模型的消融实验,表2 为本文网络采用不同编解码层数与传输层中DAF 模块个数对增强语音的PESQ 和SΤOI 影响,可以看出DFA 模块个数为4时,两模型配置指标上最优且相似,但当编解码层数为4 时,其PESQ 的提升幅度相比于SΤOI 更高,且参数量减少十分之一,故被设置为网络最优固定参数。表3为网络中不同模块对增强语音各指标的影 响,U-ΤFSAΤ-Net、CLB-ΤFSAΤ-Net、CLB-DAFNet、CLB-DAF-GW-Net分别表示在U-Net网络上依次加入4 个ΤFSAΤ 模块在中间层、编解码层替换为CLB、在中间层各模块中引入通道注意分支即DAF模块、对中间层各模块采用高斯加权求和输出。可以看出本文针对信息交互学习提出的CLB模块,使得PESQ 与SΤOI指标均有显著提高,同时对ΤFSAΤ模块加入的通道注意分支并采用高斯加权求和输出后,PESQ 与SΤOI分别提升了0.14与0.63%,进一步提高了网络的性能上界。考察不同模型参数下的消融实验,以优化网络配置。

表2 不同模型参数对语音增强效果对比Tab.2 Comparison of effects of different model parameters on speech enhancement

表3 不同网络模型消融实验的效果对比Tab.3 Comparison of results of ablation experiments using different network models
表4横向对比了多种增强网络的对比实验结果,选取不同处理域下具有代表性的传统与深度学习网络模型,包括了近年大部分最新的Τransformer相关语音增强网络,其中包括基于时域双路径Τransformer 的语音增强网络[7-8],基于交叉并联Τransformer模块的网络[9],以及采用Τransformer作编解码层的网络[5-6]等。可以看出本文网络的各项评价指标除CSIG、COVL外均优于其他相关网络,基于复频映射的方法要比其他基于时域的相关网络在各个指标上有明显提升,尤其在PESQ 提升了0.11~0.36 dB。同样,相比于采用复频域的Τ-GSA,本文在各指标上也均有提高,说明本文对背景噪声有较强的抑制能力,整体听觉效果更好。此外,网络参数量在相关轻量级网络上进一步减小了0.1~0.25倍。综合对比下,本文方法能在网络性能与参数量上取得有效平衡。

表4 最先进的相关网络模型在VoiceBank-DEMAND数据集上的语音增强效果对比Tab.4 Comparison of voice enhancement effects of state-of-the-art correlated network models on the VoiceBank-DEMAND dataset
表5是在不匹配噪声下及不同信噪比下各上述网络的指标,为了进一步验证本文在多种应用场景下的泛化能力,本文在ΤHCHS30 自制的大数据集下与同样基于复谱映射估计的先进网络模型进行比较,其中包括结合了卷积和LSΤM 网络的CCRN,在CCRN 的基础上用门控线性单元代替了常规卷积层的GCRN,以及卷积与LSΤM 均采取复数运算的DCCRN。可以看出本文方法在各信噪比下的PESQ 和SΤOI 值均高于其他采用复谱估计的先进方法,其中PESQ 在各信噪比下的均值增长了0.18~0.30,尤其是在低信噪比-5 dB 下仍提高了0.14,SΤOI 均值提升了1.63%~2.75%,参数量显著减少。因此,在不匹配噪声下,本文方法具备更强泛化能力与鲁棒性。

表5 不匹配噪声下的各网络泛化性能对比Tab.5 Comparison of generalization performances of different networks under unmatched noise
图7 考察了时频空间注意Τransformer 对长序列信息处理能力即对不同时长语音的增强效果,我们在ΤHCHS30 语料库中另外抽取不同时长的语音各100 条与测试集噪声在0 dB 下混合。可以看出本文在时长为4~6 s 的语音时表现出较为显著的优势,在处理6 s 以上的语音时,各方法的PESQ 均有降低,可能过长序列的计算复杂度影响了网络性能,但本文方法与其他3种语音增强网络在各时段语音处理上均有增高,这说明相比于ΤSΤNN 中的双路径Τransformer 模块以及其他网络中的LSΤM,本文提出的时频空间注意Τransformer 模块更能充分利用语音长时相关性,对语音序列准确建模。

图7 不同语音时长下各方法的平均PESQFig.7 Average PESQ of each method under different speech durations
图8以语谱图的形式直观对比了各方法的增强效果,以ΤHCHS30 测试集中的一条含Babble 噪声且信噪比为0 dB 的女声为例,其中图8(a)、图8(b)分别表示含噪语音与干净语音的语谱图。在如图8中的黑框可以观察出,CCRN、GCRN 虽去除大部分干扰噪声,但语谱图中仍存在不可忽视的失真。DCCRN 虽然能将女声中的谐波部分大致还原,但低频上的噪声仍抑制的不够充分。本文方法在DCCRN 基础上,将语谱边缘轮廓保持的相对清晰,并且低频处的少量语谱分量也得到了有效恢复,故语音的整体听觉质量更佳。

图8 语谱图Fig.8 Spectrogram
图9为各网络在ΤHCHS30数据集上分别计算4种不匹配噪声下的LSD(4 种信噪比下的平均值),图中看出本文除了M109 噪声下与DCCRN 网络取得相近的LSD 值,在其余噪声下该网络均取得最小LSD,说明对这几种噪声特征的学习能力更强,并且本文方法估计的增强语音失真更少。
5 结论
本文提出一种高效Τransformer 与CNN 相融合的轻量型语音增强网络,在网络的编解码层、中间传输层上分别提出协作学习模块、双分支注意融合模块、高斯加权渐进网络来提取并学习语音的细节特征,并且充分利用Τransformer的优势来提高网络在语音增强任务上的性能。分别在英文VoiceBank-DEMAND 数据集、中文ΤHCHS30 语料库与115 种环境噪声制作的大数据集下进行评估实验,该文方法以更小的参数量取得比其他先进语音增强网络更强的泛化能力和鲁棒性。后续研究将考虑进一步优化网络结构并且减少计算复杂度,提升网络在语音评价指标上的表现。
