从特征辨识到图像生成:基于AIGC范式的苗族服饰设计
2024-03-07于鹏,张毅
于 鹏, 张 毅
(江南大学 设计学院,江苏 无锡 214122)
科技的发展推动设计的进步,设计的进步为市场带来新的生机活力。苗族以其丰富的文化资源在文旅融合、深度发展的浪潮中迎来新机遇,但同质化的产品使得苗族服饰在市场销售中难以取得更大的发展[1]。纺织品的工业化将当地人从繁重的织布制衣活动中解放出来的同时,传统苗族服饰的重要性逐渐消解。乡村大部分青壮年选择离开家乡外出务工[2],制作者和使用者的缺失,使苗族服饰文化资源流失严重[3]。苗服并非没有受众,当地年轻人没有拒绝本民族文化,更不会排斥具有苗族元素的现代化服装,游客也需要多样化的民族服饰。然而普通设计师不能完全理解苗族文化的深邃,非物质文化遗产的传承人难以兼顾成衣设计的商业性,如何将苗族传统服饰的特征迁移至现代服饰中成为值得思考的问题。近年来人工智能在图像生成技术中的发展似乎为解决这一问题提供了新思路。
随着人工智能生成内容(Artificial Intelligence Generated Content,AIGC)的发展,如对比语言-图像预训练模型(Contrastive Language-Image Pre-Training,CLIP)、扩散模型(Diffusion Models,DM)等多类优秀的图像生成模型陆续问世,它们根据训练逻辑的不同在文本-图片生成领域各有优势。文本生成图像预训练模型是一种在大规模图像和语言数据集上进行自我监督训练的技术,仅通过自然语言即可产出理想效果的内容[4]。稳定扩散(Stable Diffusion,SD)是扩散模型在图像绘制和类条件图像合成方面取得的新成果,并在无条件图像生成、文本到图像合成等任务上具有竞争力,同时显著降低了计算需求[5]。扩散模型在生成结果的多样性上有着先天的优势,能为设计提供灵感素材,而大型模型难以顾及单一领域特别是传统文化的深度。庞大的训练集使大型模型无法灵活应用于垂直领域内容,因此Hu等[6]提出了大语言模型的低秩适应方法(Low-Rank Adaptation of Large Language Models,Lora)的概念。将之引入图像生成模型中,旨在通过少量素材为生成内容添加特征。Zhang等[7]提出的精细控制方法“控制网(Control Net)”,将之运用至图像生成工作中,完成对画面施加进一步控制。
基于以上研究,本文通过对苗族服饰的特征与内涵的分析,提取辨识元素并加以训练,以文本生成图像的方式,将苗族传统服饰特征迁移至现代服饰中,实现辅助苗族服饰成衣化设计的目的。
1 苗族服饰的可辨识特征分析
受感知压缩模型(Perceptual Compression Model,PCM)原理的启发,本文提取苗族服饰中人类感知系统容易分辨的元素,以此组建训练集内容。服饰之间的不同是可辨识的,这种可辨识的特征来自款式、配饰、纹样等元素。在模型训练中,服饰的辨识度影响生成内容中服饰的特征表达,在样本有限的前提下,图像需要选用最具辨识性的元素。本文以苗族服饰为例,从款式、配饰、纹样与配色等角度分析其可辨识特征。
1.1 款 式
目前苗族尚无存在文字的证据[8],服饰在漫长的岁月中承担起传递历史信息的作用。服装既是辨别民族的凭据,也是区分族寨的手段,传统苗服最重要的社会功用是标识统一婚恋集团,被称为“不同服不通婚”[9]。为了实现标识类别的功用,每种款式的苗族服饰都有独特之处。苗族服饰种类丰富,不仅村寨之间款式不同,同村寨、同款式之间也有区别。服饰承担着区分婚姻集团的社会功用,必须有一定的共性,但手工制作使每件服装具备独特之处。本文以表1中四款苗族服饰为例进行对比,款式都应用了交领的构造,并且在领、肩、襟、袖均有装饰,区别在于装饰的样式和工艺;袖部结构主要区别在袖口位置、大小与装饰品;门襟构造亦类似,两襟胸前交叉,“交下式”结构略有不同,在交叉处另系一挑花围腰,上有彩珠下垂流苏更显俏皮;下装多为深色百褶裙,只在长短、装饰与褶量中有所区别,“交下式”的百褶裙长不过膝,在中国传统服饰中是极为大胆的款式[10]144。苗族服饰中,共性占主要地位,但服饰之间又是多样的,其个性主要体现在装饰方式与位置的不同。漫长的文化交流中,各村寨的苗族同胞相互吸取彼此优秀的服装元素,以至于款式逐渐接近。就苗服系统而言,不论是“交领”或是“阔袖”,这样的形制对于苗服都不是必然的,具备“圆领”“窄袖”等特征的苗服也大量存在;对于中华服饰整体而言,此类款式特征也在其他传统服饰中发现,这是苗族同胞与各民族交流的必然结果。
款式的辨识特征需要在苗族服饰的共性中选取,且这样的特征不影响生成结果的自由度。将苗族服饰看作一个整体,其辨识特征的提取要尽量减少款式个性特征的干扰,模型的训练需要考虑其泛化性,如“交下式”中的围腰。尽管此特征具有较高的辨识性,但也存在没有围腰的款式,如不将此元素剔除,则生成的所有服饰都存在围腰。将款式的个性特征保留为辨识元素,降低了迁移模型的泛化能力。若在设计中需要针对某一款式的个性特征生成内容,如“抬拱式”中的“斗纹布”这类复杂的部分,则需要单独建立属于“抬拱式”的训练集,以此训练专属于某一款式的迁移模型。

表1 苗服款式对比Tab.1 Comparison of Miao clothing styles
1.2 配 饰
苗族服饰的装饰以银饰为主,银饰是苗族文化的载体,无论是盛大集会,还是日常劳作,苗人都习惯佩戴银饰[11]。银制品代表的是锋利,在苗族人民心中可以驱魔除恶,银对于苗族人民来说是原始精神信仰[12]。银饰既是以富为美的外化,又是世代传承从“女儿”到“母亲”角色转换的象征[13]。随着新航路的开辟,明朝中期大量白银流入中国,银质装饰逐渐出现在苗族服饰中,银制品不仅受苗族青睐,与苗族邻近的侗族、彝族、羌族等服饰中均有佩戴银饰的习惯。区别在于银饰在苗族服饰中的广泛性,从生命的开始银饰就已经成为伴身之物,随着年龄的增长银饰的数量在女性身上逐渐增加,在节日盛会中部分村落的姑娘们戴十余斤银饰环佩叮当,展示审美情操与彰显家世。如图1[10]157,168所示,银饰造型多样,银泡所代表的“点”元素、银链所构成的“线”元素和银板所呈现的“面”元素,三种元素经过苗族匠人之手组合成纷繁复杂的苗族银饰体系,复杂精美的银饰成了外人对苗族服饰最深刻的印象,可以说银饰是苗族服饰最明显的可辨识特征。

图1 苗族配饰辨识元素分析Fig.1 Element analysis for identifying Miao accessory components
1.3 纹样与配色
中式图案强调“图必有意,意必吉祥”,其中“意”是传统图案的灵魂。这种特征在苗族服饰图案中尤为突出,苗族图案绝大多数具有特殊含义,如体现益寿延年、婚姻幸福、子嗣延绵及福气吉祥等文化意蕴的蝴蝶纹[14],又如代表了正直勇敢、乐于奉献、勤劳善良等精神品质的鸟纹等吉祥纹样[15]。还有极具苗族特色的“龙纹”,当地人将生活中常见的动植物进行“龙化”,或将动植物绘出人脸,或将目标四肢艺术化,或在龙化目标身上增加花卉尾巴,这些纹样是苗族构建出来的精神世界[10]12,是重要的辨识特征。苗族传统服饰善于运用高纯度配色,这种大胆的配色方式与传统中式服装朴素温婉的色彩搭配不同,表现出鲜明的民族特色。苗族传统绣品在色彩搭配上注重整体平衡,且色彩的深浅搭配巧妙协调。苗族纹样中大量运用补色关系,即使在强调整体色调一致性的情况下,也特别注重图案内部元素之间的主次和呼应关系[16]。如图2[10]150所示,红绿两种互补色生动地勾勒出飞鸟与花草的形状,补色的使用是有的放矢的,白色线条中和了两种冲突的色彩,画面丰富跳跃却不失和谐,独特的配色增加了苗族服饰的辨识度。

图2 苗族刺绣Fig.2 Miao embroidery
苗族服饰中丰富且独具特色的配色体现在苗族服饰的方方面面,训练集中的苗族服饰是苗族色彩的载体,因此在选择训练集样本时不需要做额外处理。然而苗族纹样中丰富的意象表达,在一定程度上成为迁移模型训练的难点:文字的缺失加深了图案中“意”的表达,准确表“意”的图案,有着严格的形制,如“江河纹”的形制是三道横线,代表的是黄河、长江、平原[10]11,在生成时增减一道线条都不符合原本纹样的含义;对于少样本迁移模型的训练,纹样的辨识度是不够的,并非苗族纹样不独特,而是有限的样本在有限的像素空间中难以提供足够多的信息以供深度学习。因此,需要发挥传承人自身的能动作用,尽管生成图案是不符合制式的,但其颜色与位置排布符合一定的美学特征。传承人参考生成结果,对固有形制的图案进行二次创作,充分发挥人在非遗产品设计中的主导作用,为生成纹样赋予新的含义。除此之外,还可通过大量分析苗族纹样元素搭建苗族纹样库,使用StyleGAN模型进行大规模数据的训练,这种模型需要大量的图案数据,以便学习到足够的图像特征[17]。
2 辅助苗族服饰设计模型架构
扩散模型的随机性使生成内容的丰富性与差异性得到了保证。基于稳定扩散模型的辅助服饰设计架构分为3个模块,流程如图3所示。首先构想方案选定目标民族服饰,绘制草稿并列出相应提示词(Prompts)。接着根据构想内容进入数据采集模块,分析目标服饰中可供辨识的特征,以此为基础选择图像素材进行标签(Tag)写入,素材来源于书籍或互联网中的图像内容。之后进入训练模块,将图像素材结合标签训练为具有迁移特征功用的Lora,接着把最初绘制的草稿通过控制网中具有边缘检测功能的Canny模型进行精准控制,并与Lora共同作用于预测模块,最终产出可供参考的灵感图。
2.1 基础模型的构筑
潜在扩散模型是生成图像内容的基础模型,其生成内容在多样性方面有着显著的优势。Stable Diffusion由路德维希·马克西密利安大学研究团队在扩散模型上的最新突破,通常扩散模型会引入一个噪声参数,将初始的正态分布随机变量逐渐转化为目标数据分布对应的样本。通过一系列的变换操作对当前的随机变量更新,这些变换操作会逐渐去除噪声并逼近所要学习样本的数据分布。Stable Diffusion架构如图4所示,首先通过训练获得基于感知压缩模型的编码器(E)与解码器(D),对输入像素空间中的内容X用编码器(E)编码,映射至潜空间(Latent Space)并添加固定长度为T的马尔科夫链(Markov Chain)使噪点随机正态分布,再由条件去噪自动编码器(Conditional Denoising Autoencoder)以语义映射、文本和图像含义为条件,利用交叉注意力机制获得适合数据输入到 U-Net 中间层的表示,以实现降噪的目的,最后通过解码器(D)将潜空间中的内容还原成像素图像。感知压缩模型可以将高频率但对人眼不太重要的细节信息从数据中抽离出来,从而得到一个低维的潜空间,这大大提高了训练效率[5]。
扩散模型的底层逻辑决定了其生成内容的随机性,同一文本在生成参数相同的情况下生成内容是不同的,因此在使用扩散模型生成服装设计参考图时,往往能得到意想不到的图像内容,在实际设计中具有一定的启发性。本文潜在扩散模型选择Stable Diffusion官方推出的模型SD 1.5,其中训练数据取自LAION-5B[18],训练集的广泛性基本满足常规服饰内容的生成,但面对下游应用特别是传统文化领域力有不逮,故需要一种对应的解决方法,将传统服饰特征迁移至生成内容中。
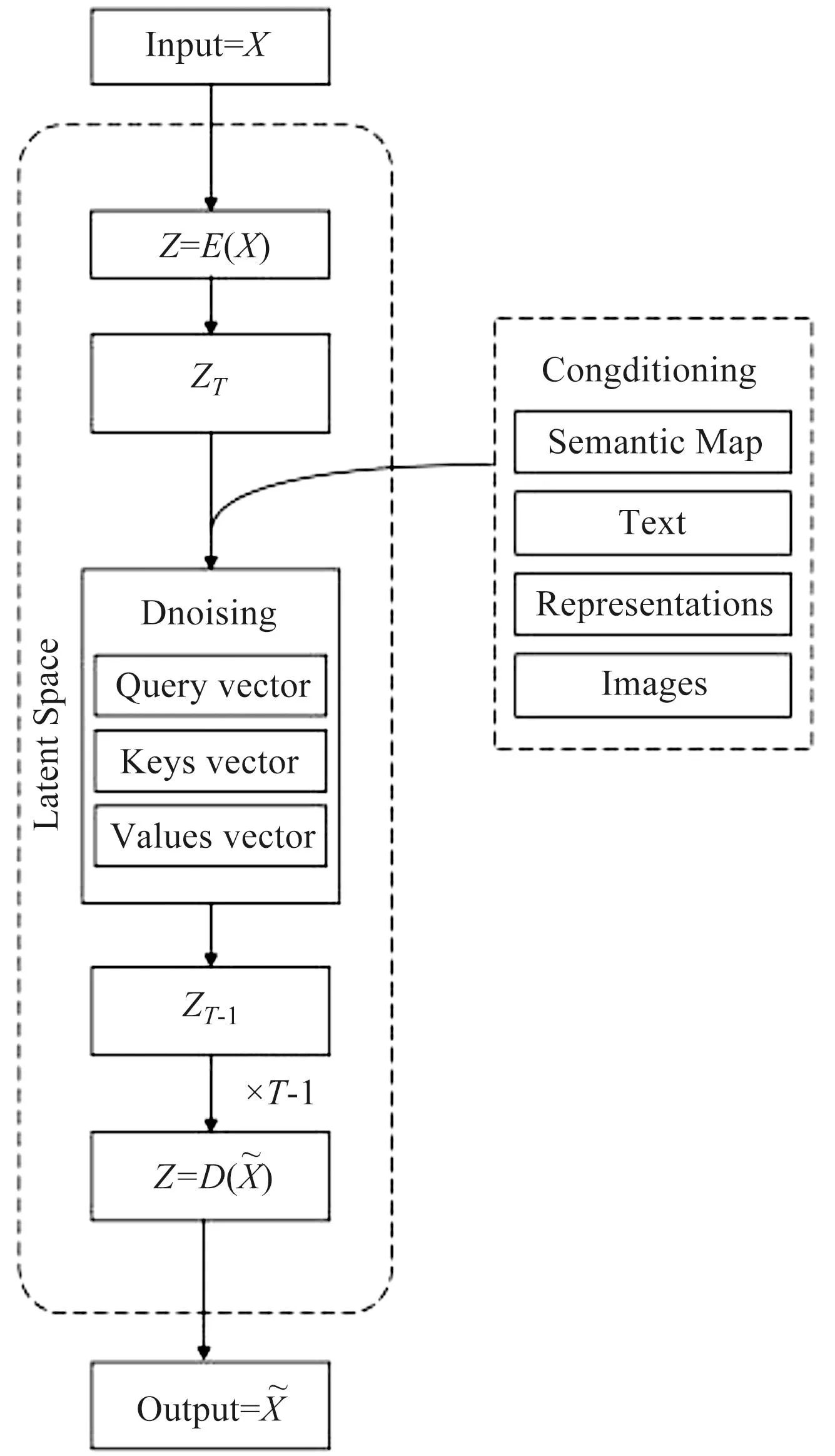
图4 稳定扩散模型架构Fig.4 Model architecture of Stable Diffusion
2.2 迁移模型的构筑
大语言模型的下游应用通常是通过微调(Fine-tune)实现的[19],潜在扩散模型也不例外。在Fine-tune时,扩散模型中的数据量往往是庞大的,然而微调只是针对部分数据调整,在应对少量数据迁移任务时,重复的训练无疑是浪费的,并且大部分个人电脑无力负担大模型训练所需的庞大算力,因此出现了Lora训练方式。
2.2.1 低秩方式
低秩方式Lora的引入使Stable Diffusion能够快速灵活地实现民族服饰特征的迁移。预先训练过的语言模型具有较低的“学习维度”,将之随机投影到更小的子空间,也可以有效地学习[6]。假设通过Fine-tune更新模型为h=W0+ΔW,通过低秩(Low-Rank)的方式约束模型更新为W0x+ΔWx=W0+BAx,其中B属于原模型矩阵中秩与行的积,A属于原模型矩阵中秩与列的积,秩的参数量远小于原始模型中需要更新的参数,则h可表示为:
h=W0x+ΔWx=W0x+BAx
(1)
Lora架构如图5所示,通过这个方式在训练潜在扩散模型训练时,冻结预训练(Pretrained Weights)的模型权重,将需要训练的分解矩阵注入转换模型(Transformer)中,分解矩阵相较于原模型矩阵中的参数量是极小的。在实际应用中,对潜在扩散模型某一领域特征的调整仅需要一个包含十几张图像的训练集,极大地降低训练时间。
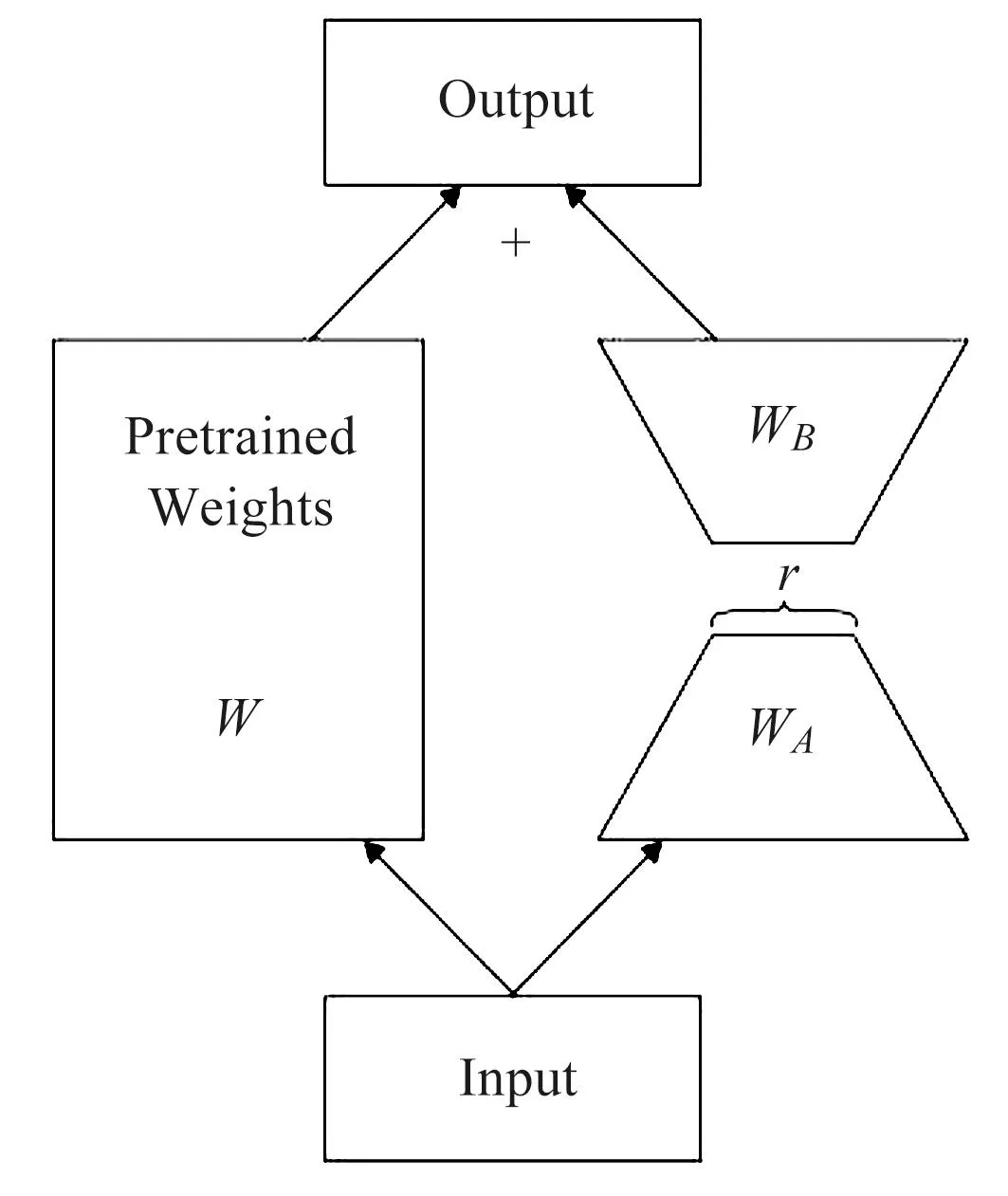
图5 低秩方式架构Fig.5 Low-rank adaptation architecture
2.2.2 损失函数
在生成式模型的设计中,损失函数通过评价模型预测值(Observed)与观察值(Predicted)的差异从而优化模型,通常潜在扩散模型适用于交叉熵损失函数(Cross-entropy)。因为运用对数运算差异值,从而避免了指数爆炸的问题,在数值上更加稳定,并且擅长应对单一样本多标签(Tag)的训练。对于扩散模型这样一张图像多个标签的训练样本,交叉熵函数是合理选择,但对于Lora的训练则不然。Lora训练集中图像素材相较整个潜在扩散模型少得多,Lora的迭代步数与原模型相比也少很多,选择损失函数需考虑在少量素材的前提下目标特征的表现力。Lora的目的是通过少量数据的调整,使生成结果呈现明显的特征,因此在Lora训练时选择均方误差损失函数(Mean Squared Error, MSE)更适合,其对预测值与观察值的敏感性使之适用于Lora训练集的训练,公式如下:
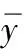
通常生成模型的鲁棒性与损失函数值负相关。
2.3 控制模型的构筑
Stable Diffusion在生成内容时仅依赖提示词,难以实现如姿势固定、款式固定等特定需求,因此斯坦福大学研究团队提出了名为“控制网”的控制架构,这是一种端到端神经网络架构,控制扩散模型学习特定任务的输入条件。控制网架构如图6所示,即将一个大型扩散模型的权重克隆为一个“可训练副本”和一个“锁定副本”,其中“锁定副本”不变,“可训练副本”受特定训练集中训练条件控制,二者通过“零卷积(Zero convolution)”连接;“零卷积”是一种卷积核初始为零的卷积操作,通过训练逐渐使其收敛至最优值并动态调整其更新权重,将基于图像的条件转换为64×64的特征空间,以适应卷积操作的大小,并与完整的模型一起进行训练[7]。
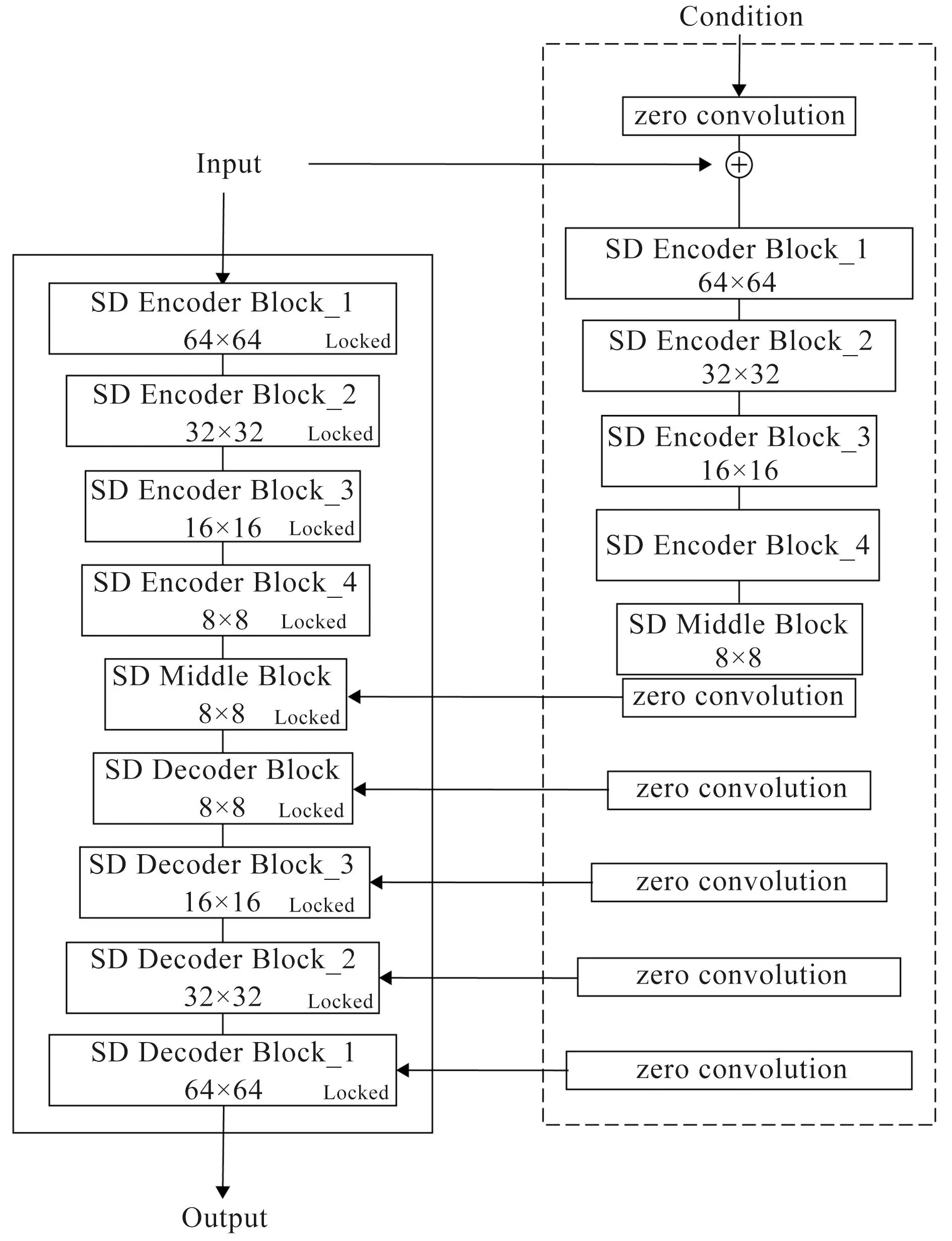
图6 控制网架构Fig.6 Model architecture of Control Net
控制网通过条件任务,限定了扩散模型图像的随机生成,本文从服装设计角度出发,选择边缘检测模型Canny,此模型可以检测参考图中物体的边缘,以此为条件指导图像生成。在非遗服装设计中,Canny能通过手绘稿生成成品参考图,也能通过成衣图为其赋予非遗服饰特色。
3 实验结果与分析
3.1 模型训练准备
3.1.1 实验环境与训练参数设置
本文应用于模型训练与图像生成的实验环境为CPU:12th Gen Intel(R) Core(TM) i5-12490F 3.00 GHz,GPU: NVIDIA GeForce RTX 3060 12G,系统:Windows 10,编程语言:Python,版本:Python 3.10.8。选择SD 1.5模型为基本模型,其训练集是基于512×512像素的图像素材,因此与之匹配的Lora模型训练也应使用同等像素的素材,最大训练周期Max Train Epoches=15,每3个周期保存一次,学习率lr=1e-4,训练集图片数量15,由于Lora样本较少故batch size设置为1。
3.1.2 迁移模型训练集素材整理
Lora训练方法仅需要十几张图像素材即可实现对大模型生成内容的迁移,相对较小的训练集使其训练与应用中快速且灵活,但缺点是信息承载量少,因此对于辨识元素的选取需要慎重。根据Lora训练方法的特性,结合前文对苗族服饰辨识元素的分析,可知银饰是苗族服饰中最明显的特征,因此在训练集素材收集时,需重点选用含有银饰的苗族服饰图像材料。如图7[10]149所示,本文苗族服饰图像选用《中国苗族服饰图志》中的传统苗族服饰,将人物部分通过Photoshop软件去除背景以减少不必要的信息干扰,裁剪图片至512×512像素,并为训练集中图像素材写入标签。 标签在扩散模型中的作用是用来帮助模型理解图像的语义,同时也是生成内容时的触发词,使用Deepbooru提取与图像相关联的文本标签,并通过人工方式对标签调整[20]。

图7 传统苗服Fig.7 Traditional Miao clothing
3.2 实验变量与结果分析
除了训练素材,影响Lora模型训练的因素还有标签写入和训练深度。本文通过控制变量法验证标签写入方法对生成内容的影响,并以此为基础对比迭代次数与训练周期对生成内容的影响。
3.2.1 标签写入方法对迁移的影响
本文通过控制变量法对比标签与生成图片结果之间的关系,根据标签写入方法不同分为三组:LoraA,为所有图片添加以“苗族服饰”拼音缩写“MZFS”命名的服饰特征标签,删除标签包含内容,也就是所有包含于苗族服饰中的文本标签,如项链、手环等,以保持添加标签语义的唯一性;LoraB,仅添加服饰特征标签,其他不做修改;LoraC,直接应用提取内容,作为对照组。以下为生成内容共同提示词:“masterpiece,ultra detailed, realistic, sharp focus, RAW photo,1girl,full body, model figure,detailed skin texture, detailed hair, long hair style, detailed eyes, big eyes,glistening skin,white and black clothes, complex detailed clothes,blank background,standing。”
如图8所示,添加标签 “MZFS”的LoraA、LoraB两款模型,在使用提示词 “MZFS”时,生成内容中苗族服饰元素明显,但提示词内容不能完全体现。在不使用提示词时,能表现出一定的苗族服饰特征,但更好地反映了提示词中的语义信息。LoraC因为没有添加相应标签,所以对此提示词无反应,生成内容依然在保留苗族服饰特征的基础上,且有效地生成与提示词语义内容相符的结果。这是因为即便不添加特征标签,Lora训练集在扩散中为“服饰”这一语义提供了新的信息,致使生成内容中残留有苗族服饰特征,不改动标签的方法对复现训练集内容是不利的,但因其能有效反应提示词信息,在启发苗族服饰成衣设计方面是有优势的。对照表明,在训练Lora时是否保留标签语义的唯一性,对生成内容无明显影响,添加统一标签会提高生成内容中苗族服饰的特征,但相应地会降低模型的灵活性。为了保证特征迁移的同时生成结果的灵活性,本实验对标签不做改动。

图8 标签写入方法对比Fig.8 Comparison of tag writing methods
3.2.2 图像迭代与训练周期对迁移的影响
训练集图像的迭代(Iteration)可以提高模型对特定样本敏感性,通常情况下迭代次数越多训练周期越长,损失函数值越小模型鲁棒性越好。但对于应用了均方差损失函数的Lora模型来说并非如此。如图9所示,对于训练集Iteration=20的Lora模型,其生成结果随着训练周期的递增,苗族服饰特征逐渐增加;在Epoches=3时画面主要反映提示词的语义信息,而苗族服饰特征不明显,但随着训练周期的深入苗族服饰的特征逐渐增多;在Epoches=15时,生成服饰以苗族服饰特征为主。随着迭代次数的增加,至Iteration=40时模型对提示词的反馈能力逐渐不足,除了Epoches=3时能反映提示词语义,其他生成周期均无法获得有效生成内容。最后当Iteration=60时模型的泛化能力失效,在高周期的生成内容中出现了训练集图像的复现,延长训练周期反而不利于Lora模型的训练。

图9 迭代与周期数量生成内容对比Fig.9 Comparison of content generation between iteration and epoches
从各阶段损失函数值分析也能得出相似的结论,在表2中随着模型的迭代,损失函数逐渐收敛,降低的数值没有带来更好的迁移效果,过低的损失函数表现为训练集内容出现在生成图像中,模型呈现泛化能力不足的缺点,降低迭代步数与训练周期能避免这一问题。从以上对比实验可以看出,在图像数量为15的训练集中,每张图像素材迭代20次,训练周期在6~12,最能体现苗族服饰特征且能有效表现提示词内容。
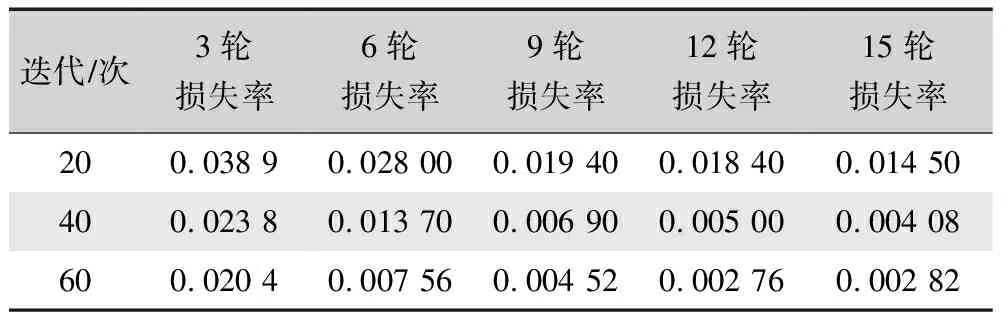
表2 迭代次数与损失函数对比Tab.2 Comparison of iteration count and loss function
3.3 模型灵活性与造型控制
3.3.1 迁移模型灵活性分析
服饰类Lora的灵活性表现为应对不同的服饰类提示词时,在准确反映提示词内容的基础上实现服饰风格迁移。如图10所示,本文方法训练的Lora模型,在基本提示词不变的前提下,仅更换服装品类词语,可实现对多种成衣品类内容的生成,并且不同批次生成内容是多样的。以关键词为“毛衣”的生成内容为例,苗族服饰图案元素以类似费尔岛纹样的方式表现出来,银饰则是表现为类似拉夫领的领部结构,这种形式的组合没有额外的指令干预,仅通过Lora对基础模型SD 1.5的修改实现的。

图10 不同提示词生成内容比较Fig.10 Comparison of content generation using different prompts
3.3.2 造型控制
控制网中的Canny模型可以有效检测输入图像中的“线”,包括服饰中的轮廓线、结构线、分割线等,以此为条件控制内容的生成。如图11所示,本文以四款传统苗族服饰款式图为例,在高权重下,款式图对生成结果有较强的控制效果,图像中服装形制接近传统苗族服饰。随着控制模型权重逐渐下降,扩散模型的特点逐渐凸显,生成内容不再完全受限于款式图的形制,在保留一定款式图形制的基础上开始发散。对于传承人而言,在高权重控制下仅需绘制线稿或草稿,即可模拟成衣效果;降低控制权重可以为传承人提供多样化的设计灵感。

图11 苗服款式图在不同控制权重下生成效果对比Fig.11 Comparison of generated effects of Miao clothing images under different control weights
4 结 论
本文通过对苗族服饰中辨识元素的分析,选择最具辨识性的特征,以此为条件筛选具备相应特征的苗族服饰图像,组成训练集并将之训练为迁移模型。在Stable Diffusion中应用此模型可实现生成服饰内容包含苗族服饰特征,此模型对于降低训练集图像素材需求量、迭代步数和训练时长等方面有一定的优势,且模型的灵活性得到验证,在不同种类服饰的生成结果中均有效果,对丰富苗族非遗服饰的成衣化设计有一定辅助作用。此方法同样适用于辅助其他非遗服饰的成衣化设计。

