基于多组卷积神经网络的梭子蟹性别识别研究
2024-03-06魏天琪郑雄胜李天兵王日成
魏天琪 ,郑雄胜,李天兵,王日成
1. 浙江海洋大学 海洋工程装备学院,浙江 舟山 316002
2. 合肥城市学院,安徽 合肥 231131
三疣梭子蟹 (Portunustrituberculatus),俗称梭子蟹,属于甲壳纲、十足目、梭子蟹科、梭子蟹属,其肉质鲜美、营养丰富,广受消费者青睐,是中国沿海重要的经济蟹类[1]。梭子蟹生长速度快、养殖成本低、经济效益高,已成为中国沿海地区的重要养殖品种。由于雌、雄梭子蟹的营养成分不同,在市场销售前需要对其性别进行分类。目前,梭子蟹的性别分类主要靠人眼识别和手工挑选,效率低下。因此,开发一种计算机辅助自动分类系统来区分梭子蟹的性别非常必要。
早期的分类任务主要是手工设计提取特征,包括传统机器学习[2-4]和利用上下文信息[5-6],但是该类方法的表达能力较弱,所以分类模型的泛化能力不强。例如,Lecun 等[7]提出的一种多层人工神经网络LeNet 是为手写数字分类而设计的卷积神经网络 (Convolutional neural network, CNN)。2006 年,深度学习 (Deep learning)[8]的概念被提出,在深度学习技术的推动下,图像分类及识别的相关研究迅速发展[9-13]。
基于深度学习的图像分类中,Krizhevsky 等[9]构建了一种较深层数的网络AlexNet,并首次引入了Relu 激活函数,同时在全连接层中使用Dropout,解决了模型的过拟合问题。牛津大学的几何视觉组 (Visual geometry group[10])设计的VGG 模型在网络结构上并没有太大的创新,但是通过实验对比发现,增加网络的层数确实能够在一定程度上提高网络的训练效果。此外,VGG 模型始终使用的是非常小的卷积核,通过串联很多小的卷积核后,其感受野和一个大卷积核相同,因此能很大程度地减少模型训练所需的参数。He等[12]开发出一种具有深度残差结构的卷积神经网络ResNet,很好地解决了网络深度达到一定层数时,模型的性能逐渐会趋向于饱和的问题,以及在网络达到某一深层时会使模型的性能急剧下降的问题。
在过去的几年里,图像的成熟分类技术主要得益于两个关键因素:一个是卷积神经网络,另一个是大量的可用图像数据集,如CIFAR 数据集[14]和ImageNet 数据集[15]。当前,一些研究者已经将图像分类方法应用到实际场景中。例如,在医学图像分类领域中,杜丽君等[16]提出了一种基于注意力机制和多任务学习的阿尔兹海默症分类方法。该方法是一种不需要人工提取特征的网络,通过引入注意力机制,能够在不丢失重要特征信息的前提下,将分类任务所需要的关注重点放在目标区域中;随后通过不同的全连接层来实现多任务学习,从而提高了网络的泛化能力。实验结果表明,该方法能够对阿尔兹海默症进行准确分类。在遥感图像分类领域中,王宁等[17]在随机森林、支持向量机和BP 神经网络的基础上设计出一种集成分类模型,并将其应用于水产养殖的水体资源遥感动态监测任务中。该模型很好地弥补了单个分类模型分类精度较低以及鲁棒性较差等缺点,在很大程度上避免了山体与建筑阴影等外在因素对水体特征提取的干扰。最终实验结果显示该分类模型拥有较高的分类精度,表明该模型能够成为水体资源遥感动态监测的分析工具之一。此外,朱明等[18]基于轻量级神经网络构建出一种鲈鱼捕食状态分类网络,满足了现代智能水产养殖的自动投喂需求。
然而,尚未见图像分类的相关技术应用于梭子蟹性别识别的研究报道。为此,本文提出一种应用于梭子蟹性别识别任务的分类方法:首先构建一个用于梭子蟹性别分类的数据集PGCD;然后搭建一种多组卷积神经网络 (Multi-group convolutional neural network, MGCNN),并使用注意力机制更专注地找出输入数据的有用信息;最后通过一系列的调整参数工作提高MGCNN 的分类精度。
1 材料与方法
图1 展示了本文所提方法的整体框架,包括数据预处理、数据增强以及MGCNN。 其中,MGCNN包含了深度提取特征模块和融合特征分类模块。数据预处理主要是将采集到的梭子蟹图像进行降低像素处理,从而解决后续处理速度过慢的问题;数据增强主要是对经过预处理后的梭子蟹图像进行数据扩充,解决了少量样本可能给网络带来的过度拟合问题,或者样本不均衡导致模型预测时对多数类的侧重问题;深度提取特征模块使用几组成熟的CNN 来提取图像的视觉特征,通过实验对比,最终的CNN 本文选取ResNet50;融合特征分类模块主要是先将CNN 提取到的特征进行信息融合,然后利用注意力机制代替传统池化层,在降低融合特征图维度的同时,去除了特征图的冗余信息,保留特征图的重要信息,最后经过输出分类层获取分类结果。
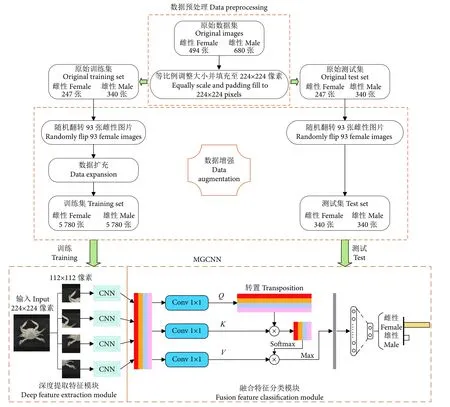
图1 所提方法的总体架构Fig. 1 Overall architecture of our approach
1.1 数据预处理
在公开数据库中,并没有梭子蟹性别分类的数据集,因此首先需要构建相关的数据集。本文的原始梭子蟹数据集主要由课题组在舟山水产品加工公司采集,采集所用设备的配置为10 800 万像素的主摄+1 300 万像素的超广角镜头+500 万像素的长焦微距镜头。采集到的原始数据集共有1 174 张图像,其中雌、雄性图像各494 和680 张,图像像素约为3 024×4 032。图2 为部分采集的梭子蟹样品。

图2 部分梭子蟹样本 (左:雌性;右:雄性)Fig. 2 Samples of Portunid (Left: female; Right: male)
由于所采集的图像像素较大,导致后续操作中处理速度较慢,因此需要对图像进行像素降低处理,调整后的图像大小统一为224×224 像素。传统的降低像素操作通常是利用opencv 库的resize( ),然而这种操作对于尺寸非N×N大小转化为N×N大小的图像来说,会改变图像原有的特征,影响网络的最终分类精度[19-21]。因此,本文采用一种等比例调整图像大小的方法,即在不改变宽高比的情况下进行图片调整,并填充至实验所需要的224×224 像素的图像。resize ( ) 和等比例调整大小并填充的图像对比如图3 所示。

图3 两种降低像素的效果对比Fig. 3 Comparison of two pixel reduction effects
1.2 数据增强
经过预处理后,将数据集随机分成原始训练集和原始测试集,均包含587 张梭子蟹图像 (雌性247 张,雄性 340 张)。为了解决少量样本可能给网络带来的过度拟合问题,或者样本不均衡导致模型预测时对多数类的侧重问题,需要对原始数据集进行数据增强,以扩充出更多数据来提高数据集的数量和质量,提高网络模型的学习效果[22-24]。数据增强的过程如下所述:
(I) 随机翻转:为了解决样本不均衡问题,本文随机从原始训练集和原始测试集中各选取93 张雌性图像,进行随机翻转,从而使得原始训练集和原始测试集中雌性和雄性图像均有340 张。随机翻转是指从3 种翻转方式中 (水平翻转、垂直翻转和水平-垂直翻转) 随机选取一种进行翻转。
(II) 随机旋转:对 (I) 中的原始训练集图像进行随机角度旋转,旋转角度在0°~90°、90°~180°、180°~270°和270°~360° 4 个范围内进行随机选取。
(III) 随机平移:对 (I) 中的原始训练集图像进行随机像素平移,像素平移在−20 至20 之间进行随机选取,包括8 个方向。
(IV) 随机明亮度:对 (I) 中的原始训练集图像进行随机明亮度调整,调整系数在0.8~1.0 和1.0~1.2 两个范围内随机选取。
(V) 随机噪声:对 (I) 中的原始训练集图像随机添加高斯噪声和椒盐噪声,添加噪声的系数均介于0.009~0.011 随机选取。
值得注意的是,除了(I) 对训练集和测试集进行数据增强,(II)—(V) 均仅对训练集进行数据增强。其中,(IV) 和 (V) 主要是针对模型识别过程中图像出现的明亮度变化和噪声影响。通过 (IV) 和(V) 两种数据增强技术可以让模型在现实环境中具有更好的应对能力。
5 种不同类型的数据增强技术示例如图4 所示。因此,经过数据增强后最终的数据集共有12 312 张梭子蟹图像,将其命名为PGCD。其中,训练集和测试集分别各有11 560 张 (雌性 5 780张,雄性 5 780 张) 和680 张 (雌性 340 张,雄性340 张) 图像。

图4 5 种不同类型的数据增强技术的示例Fig. 4 Examples of five different types of data enhancement technologies
1.3 深度提取特征模块
虽然Transformer[25]已经成为自然语言处理任务上的重要体系结构之一,但它在计算机视觉(Computer Vision, CV) 领域的应用却非常有限。为了解决该问题,Dosovitskiy 等[26]开发出一种Vision Transformer (ViT) 模型,可以直接应用于图像块序列 (Sequences of image patches),并且能够很好地执行图像分类任务。受这项工作的启发,本研究在提取特征之前设置了图像块来渲染每张图 (图5)。
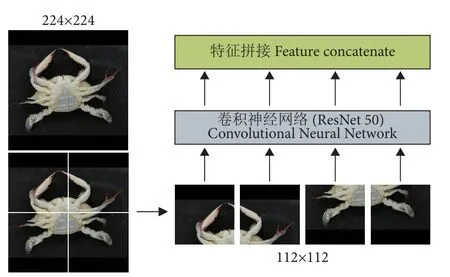
图5 深度提取特征模块Fig. 5 Depth extraction feature module
具体操作是将输入图像切分成多个大小一致的图像块。在此假设输入图像的尺寸大小为N×N,需要切分的图像块数为n2,那么图像块的尺寸大小NP×NP用公式可表示为:
式中:n为正整数。本文所提的MGCNN 的输入图像尺寸为224×224 像素,图像块的个数n2=4,所以图像块的尺寸为112×112 像素。
在4 组图像块渲染图像之后,需要通过CNN来对每个图像块进行特征学习。为了减少特征提取过程的信息丢失,使得特征提取更有力,本文使用具有残差块的ResNet50 作为深度提取特征模块中的主干CNN。ResNet50 的残差块示意图见图6。

图6 ResNet50[12]残差模块示意图Fig. 6 Residuals block diagram of ResNet50[12]
可以看出,残差块具有两条路径,一条是进行跳跃连接的输入特征X,另一条是经过3 次卷积操作后得到的映射函数F(X),然后将这两条路径连接后就能得到残差模块的输出H(X),其过程可用公式(2) 来表示:
1.4 融合特征分类模块
融合特征分类模块如图7 所示。通过CNN 学习不同图像块的视觉特征后,需要一个独特的全局描述符来表示图像。本文将不同图像块的视觉特征拼接 (Concatenate) 成一个全局特征图。最近一些研究表明,适当增加一些注意力机制可以更专注地找出输入数据的有用信息[27-29]。 为此,在分类之前本研究引入了一个注意力机制,来强调全局特征图中的细节重要性。首先,通过3 个1×1 的卷积层从全局特征图中获得Q、K、V3 个特征层;其次,将Q转置后与K做乘积运算形成一个新的特征图,再经过softmax 函数后形成注意力权重;然后,将V与注意力权重做积运算,并使用最大池化对其结果进行降低维度处理;最后,通过全连接层获取待分类类别的概率分布。
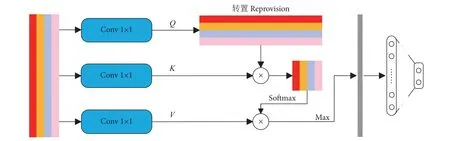
图7 融合特征分类模块Fig. 7 Fusion feature classification module
2 实验
2.1 实验设置
本实验均在同一环境配置的计算机上完成,训练集和测试集均来自于构建的PGCD 数据集。用于实验的计算机配置为Windows10、NVidia Ge-Force GTX 1080 Ti GPU、16 GB 内存,实验基于Pytorch 的方法[30]来实现,损失函数使用交叉熵损失 (Cross entropy loss) ,最大epoch 值设置为100。通过实验对比,本研究提出方法的backbone model 为ResNet50,学习率值设置为 0.000 1,batch size 设置为32。此外,为了优化整体模型架构,本文使用 Adam[31]作为训练阶段优化器。
2.2 评估指标
衡量模型分类性能的评估指标主要包括分类准确率 (又称分类精度)、召回率与查准率等[32-35]。本文主要采用这3 个指标对所提方法进行评价。图8为混淆矩阵图。

图8 混淆矩阵Fig. 8 Confusion matrix
为此,分类准确率可用公式 (3) 进行表征:
召回率可用公式 (4) 进行表征:
查准率可用公式 (5) 进行表征:
式中:Acc代表分类准确率 (Accuracy);R代表召回率 (Recall);P代表查准率 (Precision)。
2.3 实验分析
2.3.1 不同骨干模型对MGCNN 性能的影响
成熟的卷积神经网络能够很好地进行特征学习和特征提取[36-37]。为此,本文主要选取VGG 模型[10]和ResNet 模型[12]作为MGCNN 的深度提取特征模块的主干模型。不考虑DenseNet 模型[23]最主要的原因是该模型属于较大的网络,需要训练更多的参数,并且可能由于过拟合导致分类精度提高不明显。而VGG 和ResNet 系列属于较小的网络,可以节省额外的计算开销以及训练时间。为了公平比较,在这里统一将学习率值设置为 0.001,批大小设置为32;此外,本文选取了 SGD[38]作为不同骨干模型的对比实验训练阶段的优化器。结果如表1 所示,可以看出,在相同的学习率、批大小以及相同优化器的情况下,ResNet 系列普遍优于VGG 系列。值得注意的是,ResNet152 的精度未超过90%,再次验证了较大网络的过拟合现象会影响分类精度。由于ResNet50 以92.79%的分类精度位居第一,因此本研究选取ResNet50 作为MGCNN 的骨干模型。
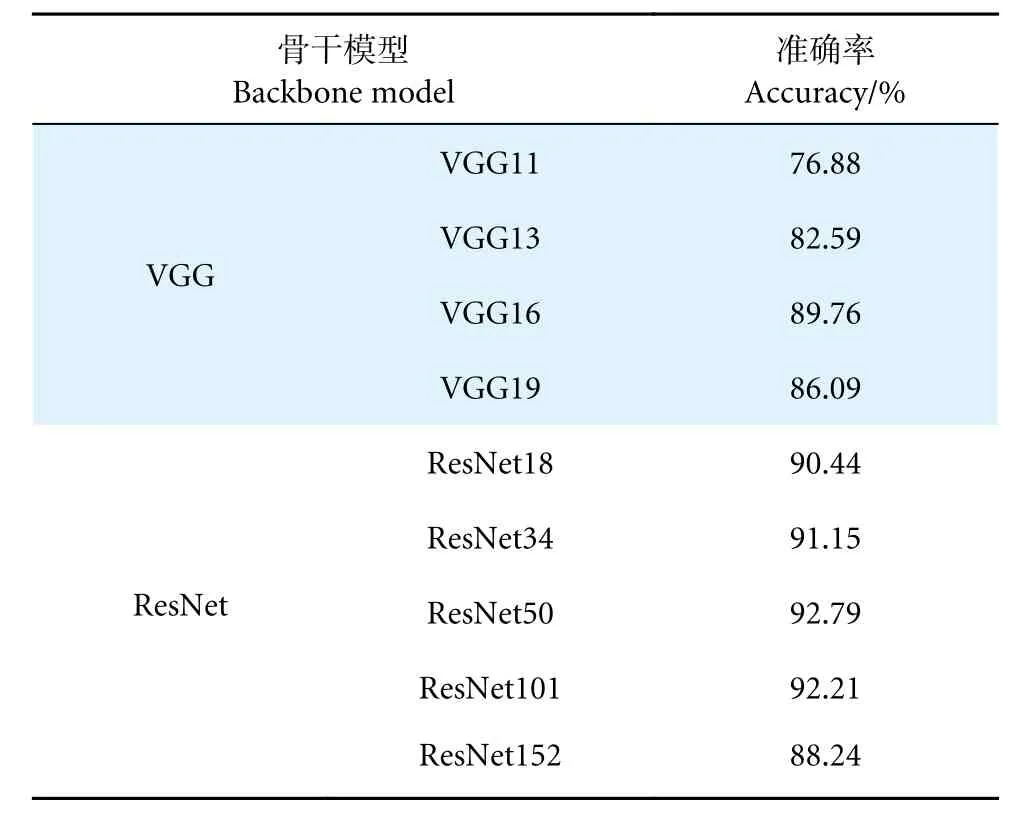
表1 不同骨干模型对 MGCNN 性能的影响Table 1 Effects of different backbone models on MGCNN performance
2.3.2 不同优化器对MGCNN 性能的影响
深度学习的过程中会产生一定的损失[39],所以应尽可能地减少损失来优化所提出的MGCNN模型,使其拥有更好的分类性能。事实上,深度神经网络的每一层都有各自的权重参数,这些权重参数决定着神经网络的输出。因此需要利用优化器(Optimizer) 来降低损失,从而更新模型的可学习权重参数来优化网络模型。本研究以SGD[38]、Ada-Grad[40]、RMSprop[41]、Adam[31]、Adamax[42]、ASGD[43]6 种优化器作为探讨优化器选取的对比实验。在这里学习率仍为 0.001,批大小为32,结果如表2 所示。可以看出,在相同骨干模型的情况下,上述6 种优化器中Adam 最为突出,分类精度达到95.29%,均领先于其他优化器。因此,本文选取Adam 作为MGCNN 的优化器。
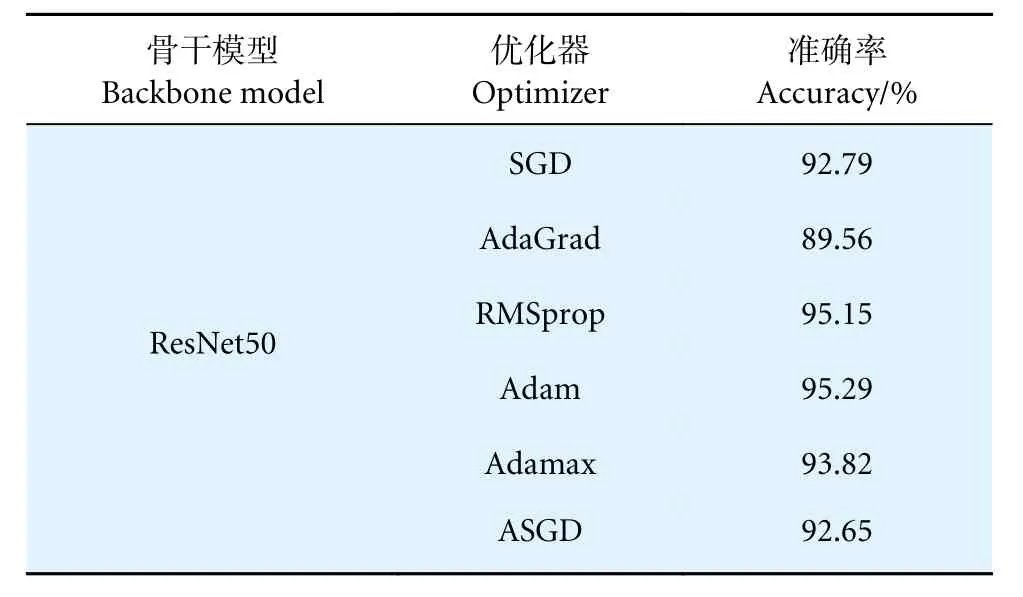
表2 不同优化器对MGCNN 性能的影响Table 2 Effects of different optimizers on MGCNN performance
2.3.3 不同参数对MGCNN 性能的影响
通过调整学习率以及批大小可以提高模型的分类性能[28,44-45],在MGCNN 的骨干模型和优化器均确定的情况下 (ResNet50+Adam),本研究进一步探讨了不同参数对其分类性能的影响,以实现最佳精度。对于模型训练而言,学习率是控制权重更新的重要参数[46]。一方面,使用过大的学习率可能会忽略最优值的位置,导致模型不收敛;另一方面,使用过小的学习率容易出现过拟合,导致模型收敛缓慢。因此,首先应确定最优学习率。在本实验中,将最开始的学习率设置为0.000 1,批大小设置为32。本次实验遵循从较小的速率开始,并依次增加直到发现最佳学习率。当最佳学习率确定后,需要进行实验来确定最佳批大小,以优化网络训练的收敛速度和稳定性[45]。本研究依次将批大小设置为64、32 和16 来训练网络,最终的实验结果如表3 所示。结果表明,当学习率和批大小分别为0.001 5 和32 时,MGCNN 的分类效果最高,分类精度达到95.59%。因此,本文将最佳学习率设置为0.001 5,最佳批大小设置为32。
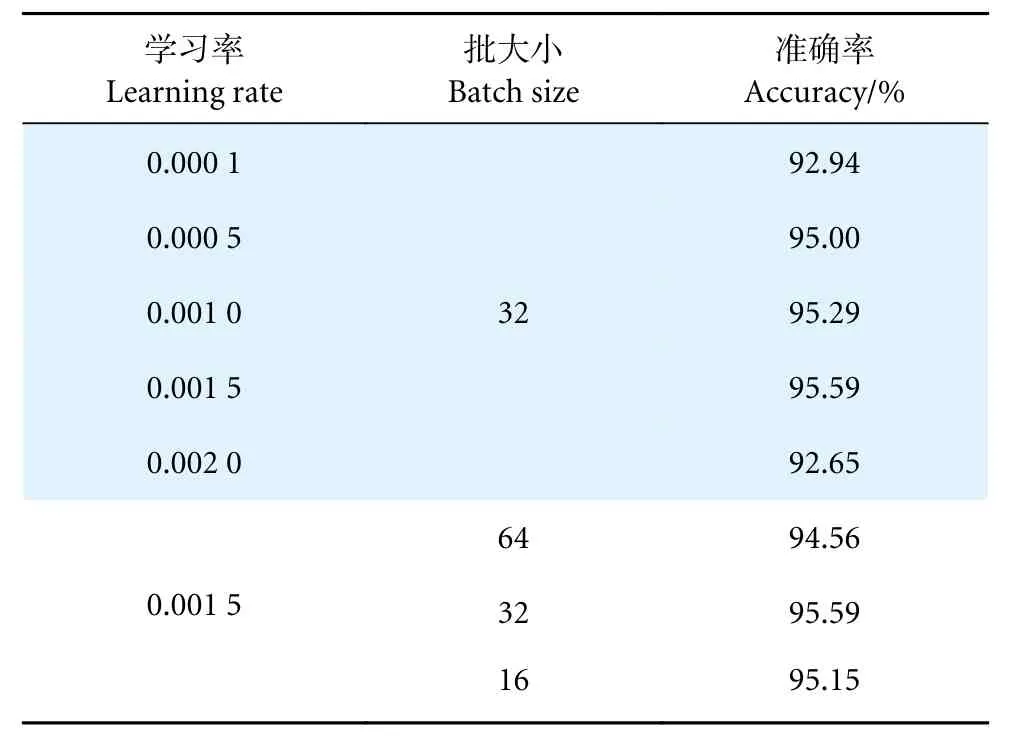
表3 不同参数对 MGCNN 性能的影响Table 3 Effects of different parameters on MGCNN performance
2.4 实验结果及可视化
为了评估所提方法MGCNN 的分类性能,本文在已构建的PGCD 数据集上进行了相关的分类任务实验,并将所提方法与其他先进的模型[9-10,12-13,46]进行比较,包括AlexNet、VGG16、ResNet152、InceptionV3 和DenseNet121。这些模型之前均在用于图像分类的ImageNet 数据集[9]上训练过,但并没有训练过PGCD。为了适应PGCD数据集,实验过程中将上述网络模型的输出分类层替换为具有两个类别 (雌性和雄性) 的输出分类层。
表4 给出了MGCNN 与一些先进方法的实验对比结果。可以看出,AlexNet 显示了最差的性能;ResNet152 和DenseNet121 网络较深,召回率和查准率相对平衡,但分类精度未超过95%;InceptionV3 分类精度达到95%,却因其查准率高导致召回率低;而本文所提的网络相比InceptionV3而言,分类精度有所提升,并且在查准率仅降低0.54%的情况下,将召回率提升1.76%。网络分类错误率最低,仅占4.41%,分类性能均领先于其他方法。
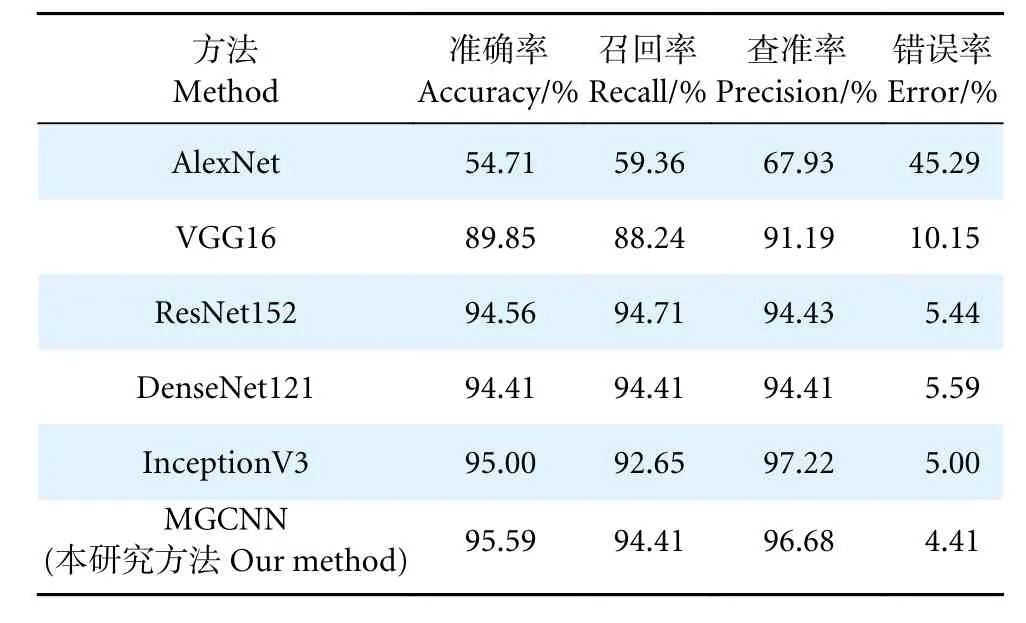
表4 MGCNN 与先进方法的比较Table 4 Comparison between MGCNN and state-of-theart methods
为了更直观地显示所提方法的优越性,本文给出了PGCD 测试集上梭子蟹性别分类的混淆矩阵(Confusion matrix) ,如图9 所示。图中主对角线显示的是识别正确的数目,副对角线显示的是识别错误的数目。可以看出,梭子蟹共有680 只,仅30 只被错误归类。其中,雌、雄蟹各有321、329只被正确归类,仅11 只雄蟹错归为雌性,19 只雌蟹错归为雄性。表明所提方法具有很好的分类效果。

图9 梭子蟹性别分类的混淆矩阵Fig. 9 Confusion matrix of gender classification of P. tritubereulatus
此外,受试者工作特征 (Receiver operating characteristic, ROC) 曲线和ROC 曲线下的面积 (Area under the ROC curve, AUC) 也可以用于度量分类模型的好坏。MGCNN 的ROC 曲线和AUC 如图10所示。可以看出,所提方法的AUC 达到98.88%,在梭子蟹性别分类任务中取得优异的性能。
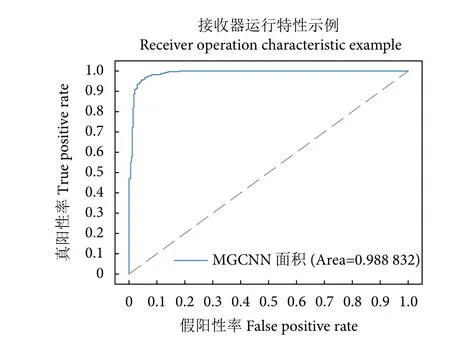
图10 比较不同网络性能的受试者工作特征曲线 (ROC) 和ROC 曲线下的面积Fig. 10 Comparison of Receiver Operating Characteristic(ROC) curve and area under ROC curve for subjects with different network performance
2.5 单幅图像预测结果
为了验证模型的实际应用效果,采购雌、雄梭子蟹各20 只,在实验室对其性别进行自动识别验证。验证图像采用等比例调整大小并填充的预处理方式。图11 展示了单幅图像预测的示例,可以看出预测均正确,且预测概率均超过95%。此外,经统计分析,识别一张图像的时间不超过1 s。因此,本研究所提的算法可以很好地应用在梭子蟹性别自动分类及识别系统。

图11 单幅图像预测概率Fig. 11 Prediction probability of single image
3 小结
为了实现梭子蟹性别的智能化识别,促进现代渔业分拣装备由半机械化、机械化走向智能化,本文构建了梭子蟹性别分类数据集 (PGCD),提出了一种用于梭子蟹性别分类的多组卷积神经网络框架。该网络首先通过引入ResNet 对图像块提取特征,减少特征提取过程的信息丢失,使得特征提取更有力;然后提出一种注意力机制代替传统的池化层,从而更专注地找出输入数据的有用信息;最后进行了一系列的参数调整,使得所提的MGCNN拥有最优分类性能。实验结果表明,所提方法在PGCD 数据集上具有分类优越性,分类准确率高达95.59%。未来,将围绕梭子蟹的尺寸、肥瘦、蟹钳完整程度等特征进行分类,进一步完善梭子蟹智能识别系统。
