基于分治方法的声纹识别系统模型反演
2024-03-05张骏飞张雄伟
张骏飞 张雄伟 孙 蒙
(中国人民解放军陆军工程大学指挥控制工程学院 南京 210001)
依赖神经网络模型完成数据处理的移动设备深入到生活中的私人领域,如智能手机、智能家居及可穿戴设备.有如此多的日常设备连接到互联网,智能连接可以通过任何设备随时随地访问数据,效率提高的同时,隐私问题和安全风险也随之产生.在一般情况下,语音常用于日常社交,隐私特性感知不强.语音数据隐私分析表明,语音中除了语义内容外,说话人的语音特征和表达方式可能隐含着丰富的私人敏感信息,如性别、年龄、健康状况和地理来源[1].语音数据的泄露可能对个人隐私构成严重威胁,例如窃取模型中的语音信息,甚至利用这类信息进行深度伪造到其他违法事件当中,对个人生活和工作产生不良影响.因此,模型的语音隐私信息不被窃取是至关重要的.
机器学习(machine learning, ML)被广泛应用于数据处理任务中,移动设备和边缘设备越来越依赖深度神经网络(deep neural networks, DNNs)完成复杂任务.如今,DNNs正被应用于许多涉及隐私和敏感数据集的领域,如医疗、安全等,这可能带来一些隐私问题.事实上,先前对隐私的研究已经证实了从访问模型中恢复未授权信息的可能.其中有一类方法称之为模型反演(model inversion, MI),给定模型的访问权限,模型反演可以重构用于模型训练的私有数据,引发了越来越多的隐私担忧.例如,恶意用户可能会访问人脸识别系统,以重构用于训练的人脸图像.深度学习技术的兴起将模型反演扩展至深层结构和复杂数据集,对隐私数据保护提出了新的挑战.
声纹识别系统是一种凭借语音信息识别说话人的身份认证系统,被广泛应用于需匹配特定说话人身份的访问控制或交易认证等诸多现实场景,利用该技术可以便捷控制和访问计算机、手机等其他私人电子设备.声纹识别模型的训练依赖于神经网络从大量语音数据中提取每个说话人的特征表示,模型输出中可能会包含说话人的部分信息.日常情境中,不论是在私人领域还是在公共领域,受设备计算能力、存储和功耗的限制,通常模型部署在本地,云端按需完成计算过程,设备仅接收云端识别确认的返回结果.这种场景下很容易引发隐私问题,上传云端的语音数据得不到足够的安全保障.
到目前为止,模型反演工作大都集中在图像领域,能较好地从得到的模型相关知识中重构原始输入,但在语音领域还少有相关研究.与图像领域的模型反演类似,声纹识别系统将每个说话人视作一类,语音信息可能被恶意恢复.由于语音数据包含重要的个人可识别信息,针对声纹识别系统的模型反演研究有重要意义.基于DNNs的声学模型在许多语音任务中取得了成功,代替传统低维特征向量如MFCC和PLP系数,Fbank特征可以更多地保留语音本身所携带的信息[2].本文提出的基于分治方法的声纹识别系统模型反演,成功将模型反演扩展至Fbank特征语谱图上,验证了模型反演在语谱图上的可行性.实验结果表明提取此类语音特征信息的声纹识别模型存在隐私安全问题.
1 相关工作

图1 模型反演方法
针对隐私的模型反演其总体目标是获取不被共享的隐私敏感信息,如训练数据和模型信息.模型反演旨在重构训练数据对目标模型隐私敏感信息的安全产生威胁.正常情况下,如图1所示,用户输入私有数据x,模型输出预测结果y;攻击者在得到模型输出的预测知识后,可通过已掌握的模型知识,对模型反演得到与x相同或相似的信息x′.模型反演主要有2类方法:基于优化的方法和基于训练的方法.
1.1 基于优化的模型反演方法
基于优化的方法是利用数据空间中的梯度优化来模型反演.模型反演视为一个优化问题,搜索在目标模型下达到最大似然特征值的输入空间.如图2所示,神经网络模型可看作一个函数Fw,其基本思想是基于梯度优化在输入空间X中搜索x′,使得Fw(x′)的预测值逼近原始输入Fw(x),并使用自然图像空间P中的先验概率P(x′)正则化项来调整优化,使得反演产生的图像更接近原始图像.
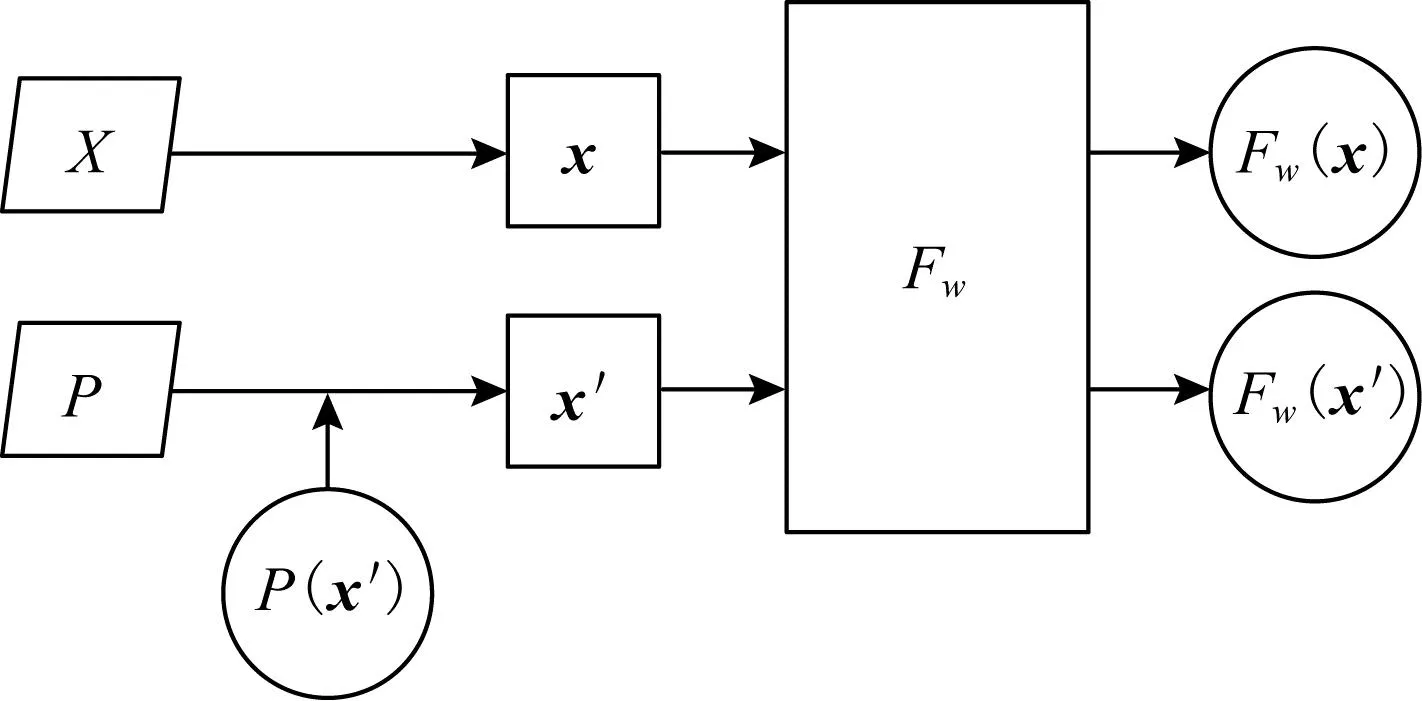
图2 基于优化的模型反演方法
形式上,基于优化的模型反演求逆,就是寻找一个使式(1)最小的x′,使Fw(x′)的输出结果与原始输入x产生的预测值Fw(x)尽可能相似,式(1)中L表示度量距离,如L1距离损失.
d(x′)=L(Fw(x′),Fw(x))+P(x′).
(1)
Fredrikson等人[3]在医药诊断任务下,首次引入模型反演恢复患者的遗传基因标记,表明模型具有隐私风险.然而,对反演的评估仅限于线性模型,反演是否适用于其他环境也是未知的.为此,Fredrikson等人[4]提出基于梯度下降的优化算法,利用预测分类器返回的置信度改进反演方法,成功在浅层网络重构出灰度人脸图像.但这些直接从像素空间重构隐私数据的反演方法对于更复杂的模型,重构质量往往会下降甚至完全失效.为了使深层网络模型下的反演成为可能,Zhang等人[5]提出生成式模型反演(generic MI, GMI),该方法通过在公共通用数据上训练生成对抗网络(generative adversarial network, GAN)学习一个先验分布,然后用它指导反演过程,有效地将搜索空间缩小到特定的相关图像上,将优化问题限制在生成器的潜在空间中.但GAN无法提取针对目标网络中特定的私有知识,知识丰富分布模型反演(knowledge-enriched distributional MI, KED-MI)在GMI的基础上进行改进,Chen等人[6]提出一种新的反演GAN,为了从公共数据中提取关于目标模型的私有知识,采用一个能够区分真实数据和伪造数据的判别器,它可以指导生成器生成与私有训练数据具有更多共同特征的图像,更好地从公共数据中提取有用的私有知识执行模型反演.
1.2 基于训练的模型反演方法
反演神经网络模型的预测实际上是一个困难的不适定问题[7].基于优化的过程从随机初始化输入开始,且反演过程中要求解梯度,难以扩展到更深结构和复杂数据集.不同于基于优化的方法,基于训练的方法是训练一个新的神经网络模型(简称反演模型).该方法学习出一个新反演模型Dθ以逼近从预测知识Ew(x)到输入x的逆映射,即仅靠给定预测知识输出Ew(x)就能直接求解反演样本x′.由于目标模型Ew和反演模型Dθ具有相似的功能,模型反演的训练过程类似于自动编码器结构,即编码器-解码器对,如图3所示:

图3 基于训练的模型反演方法
这种模型反演就是寻找一个反演模型Dθ,最小化式(2)反演样本x′与原始输入x的误差,其中R表示L1范数等损失.
s(Dθ)=R(Dθ(Ew(x)),x).
(2)
可逆神经网络(invertible neural networks, INNs)由于其特殊结构以及限制权值分布,可作为1对1的函数逼近器.Jacobsen等人[8]改进可逆残差网络(reversible residual network, RevNet)[9]仍使用多个不可逆向算子的情况,可以完全反演直至最后的分类器上,不丢弃任何信息并且允许从最后一层中准确地恢复输入.而Yang等人[10]研究对抗环境下的模型反演问题,采用更一般的数据集组成辅助集训练反演模型,作为目标模型的逆执行反演.其提出的基于截断的技术,能够从获得的部分模型预测输出中有效地反演目标模型.为了扩展至更深层的网络,Dong等人[11]引入分治法以分而治之反演DNNs,证明在复杂图像数据集反演深层模型的可行性.同样地,基于训练的模型反演也可用GAN实现.Wang等人[12]提出一个能够在服务器端“隐形”工作的多任务辅助识别GAN(multi-task GAN for auxiliary identification, mGAN-AI),采用多任务判别器提高生成特定样本的质量.Shi等人[13]提出一种基于深度学习的模型反演方法,通过轮询推理分类器的功能,构建出功能等效的模型.而后利用条件生成对抗网络(conditional GAN, cGAN)减少对采集数据量的需求,生成更多的数据训练反演模型[14].
综上所述,2类模型反演方法都在努力寻找与原始输入x距离最小的反演样本x′,并有着对以往研究中所作假设不断减少的共同趋势.本文采用基于训练的模型反演方法训练一个反演模型Dθ.假设目标模型是可访问的,可以在获得模型输出的情况下得到一个单向通道反演的多层前馈反演模型.当再次得到新的模型输出时,只需通过反演模型进行1次正向传递就能根据模型输出重构输入数据.
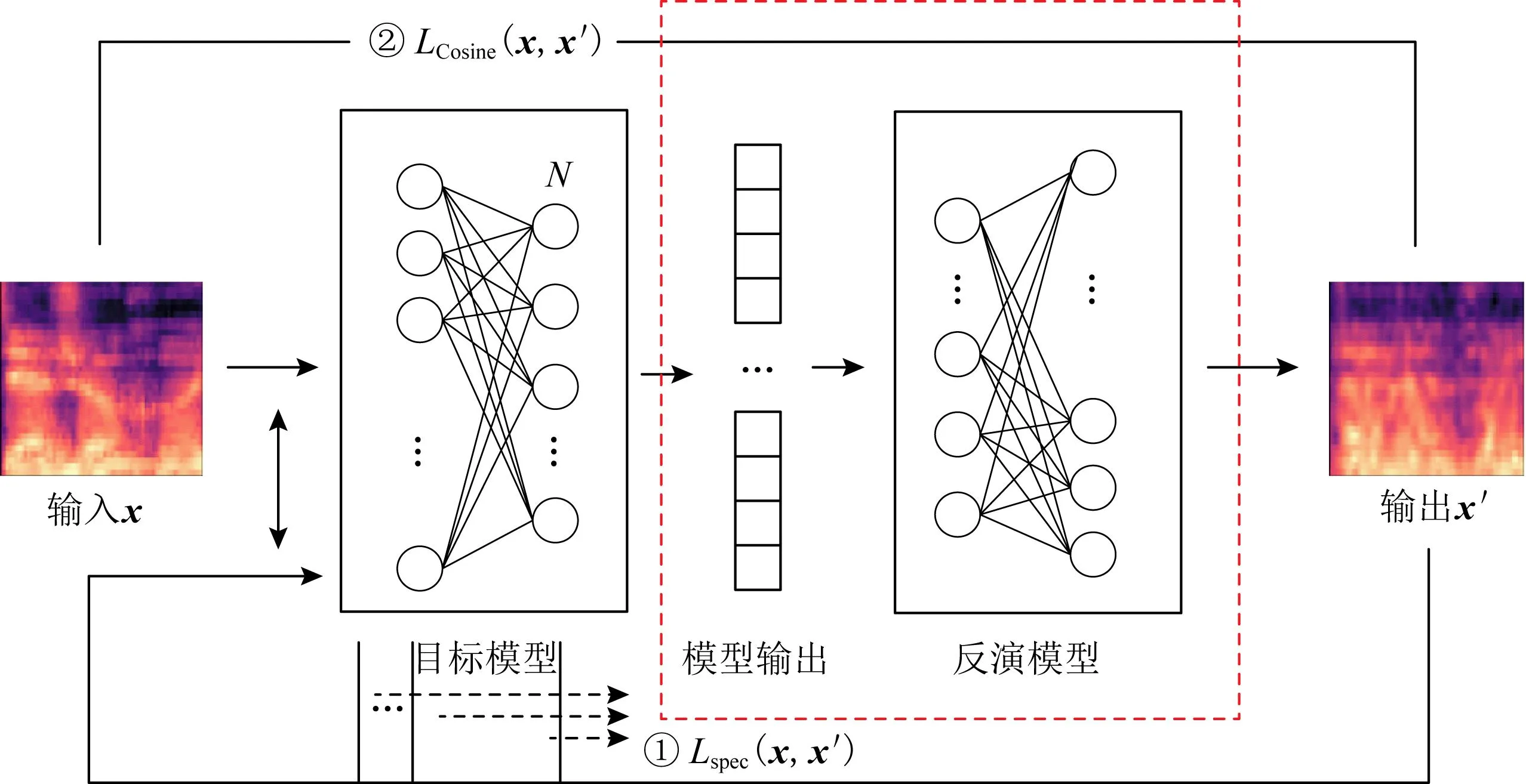
图4 端到端模型反演训练框架
2 本文方法
深度神经网络的学习是一个循序渐进的过程,网络的不同阶段具有不同的学习能力,由此可学习到不同的分层特征.DNNs是具有多层或块的组合结构,随着深度的增加,特征的抽象程度变高,从而产生更复杂的特征图,导致反演难度增加.为避免直接反演所有层的困难,本文引入一种与Dong等人[11]相同的简单而有效的分治反演策略,将整体反演问题分解成若干个逐层反演的子问题,使得每步反演都是一个较为容易解决的问题.不同于仅靠模型2端信息监督的端到端整体反演,分治法会使得模型反演过程更加稳定和有效,特别是对深层网络结构有独特的优势:分层会使模型的非线性和复杂度降低,更易反演;反演能够逐层调整优化,提供更有效丰富的层监督信息,减少训练过程中传播的累积误差.


(3)

(4)
3) 循环一致重构损失.通过将反演样本输入目标模型重新检查循环一致性加强重构质量.利用循环一致性,反演样本x′输入目标模型中,逐层计算循环一致损失并求和,最小化反演样本与原始输入在目标模型输入的逐层输出总和.
(5)
从原始输入起使用式(3)(5),将原始输入作为参考,监督反演样本与原始输入具有相似的特征;同时使用式(4),减少反演训练过程中产生的传播累积误差.综合上述损失,反演整体优化目标为式(6),其中α是超参数.
Ln=Llayer+Lspec+αLcycle.
(6)
特别地,先前应用在图像领域上的模型反演方法中,重构与原始输入接近或相同的反演样本才是有价值的.对于声纹识别来说,语音场景下模型反演的特殊性在于,模型的特征层已经有了大量的说话人信息,足够用于说话人身份识别.尤其是许多声纹识别依赖于余弦相似度[15-16]算法,由此对本文的分治法进一步改进,采用xvector[17]余弦相似损失式(7)替换临时重构损失式(4)来监督反演重构数据过程,如图4中②.重点关注于反演样本与原始输入的xvector特征余弦相似,利用模型反演直接重构说话人身份特征相似的反演样本.
LCosine(x,x′)=
1-cos[xvector(x),xvector(x′)],
(7)
(8)
利用xvector[17]相似会降低计算代价,减少反演样本和原始输入在其表示中的距离,会使反演产生更高的保真度.修改损失后的优化目标如下,其中α,β是超参数.
Ln_xvector=Llayer+βLCosine+αLcycle.
(9)
3 实 验
3.1 实验设置
实验采用Aishell-1[18]数据集.Aishell-1是一个中文语音数据集,由来自400名中国不同口音区域的说话人在安静的室内环境中参与录制,每人300多条语音,录音时长178h,并降采样至16kHz.随机从Aishell-1数据集抽取40位说话人用于实验,首先将数据按5∶5划分为用于训练目标模型和反演模型的数据集,划分数据集间无重叠,之后再按7∶3分别对2个数据集划分训练集和测试集.训练目标模型后固定,再以端到端的方式训练反演模型.α,β这2个超参数用来调节损失中各项保持在同一量级.由以下2个评价指标衡量模型反演的效果.
1) 反演样本在目标模型上正确分类的比例.若反演样本在目标模型上正确分类为原说话人,则视为成功.即目标模型被反演样本欺骗导致正确分类.可以帮助分析经反演模型输出的反演样本对于目标模型是否还能再次被正确识别.
2) 反演样本与原始输入的语谱图可视化对比.侧重于从可视角度量化反演样本与原始输入的相似度,若语谱图相似,反演样本也应当与原始输入相似.分析模型反演是否可由构建的反演模型中恢复原始输入.
3.1.1 数据预处理
提高农产品质量安全预警有利于农业健康发展,提高国民生活水平,是当前相关部门需高度重视的一项工作。只有充分意识到提高农产品质量安全预警的意义,才能使其含有的实效性在农业发展中发挥出最大化,才会为社会经济不断增长做铺垫。
神经网络对高度相关的信息不敏感.经短时傅里叶变换(short-time Fourier transform, STFT)后直接得到的声谱图维度较高,冗余信息过多.而信息变换一般是有损的,原始语音包含信息量更完整,MFCC会造成语音信号的高频非线性部分丢失.Fbank与上面2种特征相比,信息损失少,运算量低且相关度高.按图5流程处理成32维×64帧固定大小的语谱图用于实验.
3.1.2 目标模型
受限于设备性能、存储等,在满足本地化需求的前提下,目标模型需尽可能的轻量化,采用图6所示的网络结构模拟目标模型.

图5 Fbank特征提取流程

图6 目标模型
3.1.3xvector提取
当前的声纹识别依赖于神经网络提取说话人特征表示.使用时延神经网络(time-delay neural networks, TDNN)[19]通过扩张卷积逐步建立时间上下文,可以将变长的说话者语音映射到固定维度的嵌入矢量表示,称为xvector[17].ECAPA-TDNN[16]在原有架构的基础上作了进一步改进,将时间注意力扩展到通道维度,在不同帧的集合上提取一定的说话人属性,使得网络更多地关注那些不在同一时间上的说话人特征.SE-Res2Blocks重新调整帧级特征,将初始帧重组,使得网络受益于更广泛的时间上下文.其中Res2Blocks通过构建层次化的残差连接处理多尺度特征;SE-Block会根据记录的全局属性对每个通道进行重新缩放来扩展帧层的时间上下文.神经网络学习分层特征,每一层操作复杂度不同.为了利用每层的互补信息,对不同层的SE-Res2Blocks的输出特征通过残差连接传播,将其输出特征图串联.实验采用预训练的ECAPA-TDNN模型提取xvector,即图7中的Audio feature.
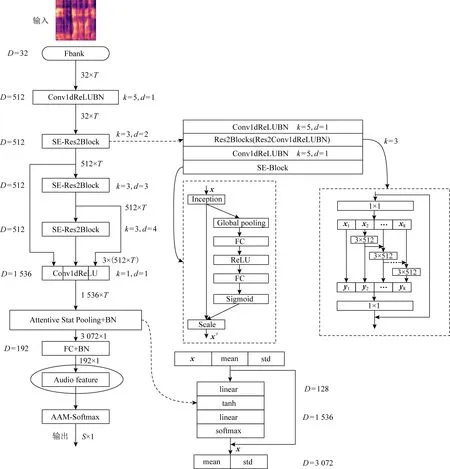
图7 ECAPA-TDNN网络结构
3.2 结果及分析
在实验中,使用反演模型重构完整的原始输入语音数据,同时验证反演样本是否能再次被正确识别为原说话人身份.本文实验结果如表1所示.预训练的目标模型在测试集上的分类准确率为90.135%.2种方法重构反演样本的说话人身份均能被再次正确识别,对目标模型有较高的准确率.分治法反演样本在目标模型上的识别准确率高达84.926%,同样地,针对语音的特殊性,利用xvector[17]余弦相似损失重构的反演样本识别准确率显著提高到89.016%,因为其中已携带有大量可用于神经网络模型对声纹识别的关键特征信息,足够用于说话人身份的识别.结果表明通过模型输出知识反演原始输入时反演样本与原始输入的说话人身份基本保持一致.对于一个使用声纹特征信息作为身份控制和访问的安全系统,反演样本在模型上识别的高准确性是不可接受的.
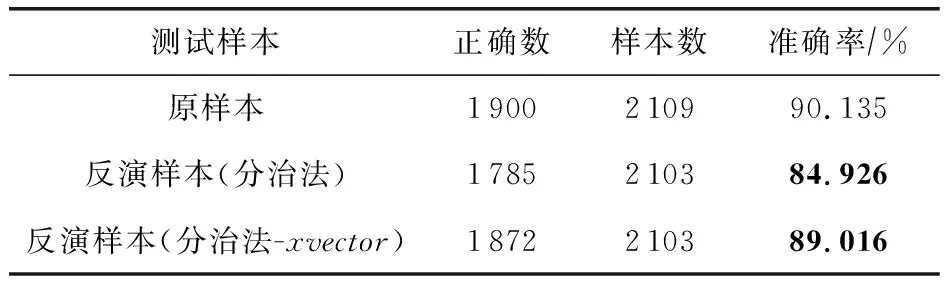
表1 目标模型测试集识别准确率
同时,实验也从可视角度验证了从目标模型输出经反演模型重构原语谱图的可行性,图8可视化了部分模型反演的效果,图8中序号是说话人的身份标签.观察到其与原始输入虽已有可见的相似,可能由于语义信息还原的不完美,并不完全匹配.尤其是改进损失仅衡量反演样本与原始输入的xvector[17]相似,减弱语义信息后可视效果变差.特别地,转换为语音文件后,反演样本听起来与原始语音有相似的内容,然而尽管反演样本与原始输入之间重构距离减小,重构的反演样本听起来仍然不像原始语音那么清晰.另外,由于语音场景的特殊性,声纹识别模型的识别并不需要像原始语音那样自然的声音,改进损失重构的反演样本可视效果虽比原方法差,但对目标模型的识别准确率更高.说话人身份特征已被较好地还原并被原模型正确识别,证明了模型反演在目标模型上的有效性,可以通过模型反演得到与原说话人身份信息一致的反演样本.

图8 语谱图
以上实验基本验证了模型反演在声纹识别系统提取语谱图特征的可行性,结果表明模型存在隐私信息泄露风险.在掌握模型完全知识的情况下,初步可达到从训练好的反演模型中重构对应模型输出的与原说话人身份信息一致的语谱图的目标.实验的成功可为语音隐私信息安全提供有价值的见解,模型反演不仅可以用来重构模型所训练的隐私信息,还会严重威胁提取此类语音特征信息的声纹识别系统安全性.
4 结 语
本文成功将模型反演扩展至语谱图,对模型反演在语谱图上的可行性进行了有效验证.结果表明,反演样本已包含丰富的身份信息.声纹识别模型依赖于神经网络提取学习每个说话人的特征完成识别任务.因此,训练好的神经网络模型中总会包含说话人的部分信息.现有神经网络模型中的语音信息被恶意恢复是有可能的,要重视在此类模型中提供足够隐私保护的重要性.目前模型反演在语音领域的实际影响可能仍然是有限的,随着新的模型反演方法的提出,对声纹识别系统隐私空间安全的关注将变得越来越重要.后续可对更深更复杂的网络进行研究,将模型反演扩展至大规模应用的声纹识别系统,进一步探索语音领域专门的隐私保护方法.
