融入结构先验知识的隐私信息抽取算法
2024-03-05赵玉媛张泽丹李青山胡建斌
赵玉媛 王 斌 张泽丹 李青山 胡建斌
1(北京大学软件与微电子学院 北京 102627)
2(中国中医科学院中医药数据中心 北京 100700)
3(博雅正链(北京)科技有限公司 北京 100037)
4(北京大学计算机学院 北京 100871)
数据脱敏[1](data masking或data desensitization),指通过预设规范或变换算法对隐私或个人信息进行处理,使得数据中个人身份不可识别[2].通常分为4个步骤:定义隐私信息、抽取隐私信息、选择隐私保护算法、完成数据脱敏.随着数据脱敏技术的快速发展,隐私保护算法逐渐成熟,隐私信息定义通常依据相关规范,数据脱敏的准确率主要依赖于隐私信息抽取算法的效果.近年来,隐私信息抽取算法从规则化阶段过渡到模型自动抽取阶段,主要采用自然语言处理技术中的命名实体识别算法,自动标记文本中的隐私信息.
基于深度学习的隐私信息抽取算法分为2个阶段:第1阶段以循环神经网络(recurrent neural networks, RNN)[3]为主,例如Dernoncourt等人[4]建立的长短期记忆(long short-term memory, LSTM)[5]网络模型,结合条件随机场(conditional random field, CRF)[6]进行优化.之后,如Liu等人[7]提出的CharCNN-BiLSTM-CRF模型,将BiLSTM-CRF[8]模型与CNN模型结合,提取字符级特征.第2阶段,以Transformers[9],BERT[10]等模型为代表,例如Khin等人[11]提出的ELMo-BiLSTM-CRF模型,增加了ELMo动态表征和CNN提取的字符特性,显著提升了隐私信息识别效果.
尽管基于深度学习的算法在上下文表征能力方面取得突破,特别是Transformer类预训练模型利用多头注意力机制充分考虑全局上下文信息,但在实体结构感知方面存在不足,影响了隐私信息实体边界的准确判断.为了引入结构感知信息,Strubell等人[12]、Zhang等人[13]、Bugliarello等人[14]尝试利用结构信息优化注意力机制,但这些尝试仅限于特定任务,未应用于隐私信息抽取任务.因此,本文提出一种融入结构先验知识的隐私信息抽取算法,以提升隐私实体边界判断的准确性和抽取效率.
本文算法利用结构先验知识增强机制,将结构感知信息融入预训练模型(PLM)的输入和注意力机制中,提升对句子整体结构和实体边界的感知能力,从而提高隐私信息边界判断的准确率和实体抽取效率.具体而言,本文工作的主要贡献包括:1)提出文本语义编码和文本结构编码2个概念,区分传统文本嵌入和依赖解析树解析出的结构感知信息;2)在结构先验知识增强机制中,分别提出嵌入层面和注意力层面的特征空间融合机制,充分引入结构感知信息到PLM中;3)结合以上概念和机制,提出融入结构先验知识的隐私信息抽取算法,以解决隐私信息边界判断问题,提升实体抽取准确率.
1 任务描述
融入结构先验知识的隐私信息抽取算法中,“结构先验知识”指的是通过依存句法解析算法获取词语间的依存关系.这种“依存关系”表示了句子在句法层面的搭配结构.该抽取任务的核心在于将“依存结构”这一非欧几里得空间数据特征映射到传统隐私信息抽取的数据特征空间,以此增强模型对句子整体结构的感知能力,并提升对实体边界与类型的感知能力.
f(Dtext,Dstructure)→y,
其中Dtext是隐私信息抽取算法中抽取的文本特征,主要由大规模预训练模型处理而来,包含丰富的上下文语义信息.Dstructure特指通过自然语言处理(natural language processing, NLP)技术,从依存解析特征中挖掘并得出的以句子为单位的结构性数据.本文通过设计的算法,将上述2类特征空间进行对齐与融合,以提高隐私信息抽取的准确率.
2 融入结构先验知识的隐私信息抽取算法模型
2.1 整体框架
为了提高以句子为单位的“结构”信息在隐私信息抽取模型中的融合效果,从而提升抽取准确率,本文基于大规模预训练模型,提出了一种融入结构先验知识的隐私信息抽取算法(integrating structural knowledge network, ISKN).如图1所示,ISKN主要包含3个部分:特征编码器、特征空间融合机制和隐私信息抽取网络.
1) 特征编码器.
首先抽取原始数据中的每条文本的“结构”信息,然后将这一结构信息和原文本信息转化为嵌入表示矩阵,通过特征编码器编码对应的结构向量和文本语义向量.本文选用图注意力网络对结构特征进行编码.
2) 特征空间融合机制.
为了有效对齐“结构”特征空间和文本特征并进行特征融合,本文提出了2种特征空间融合机制:一种将图注意力网络编码的“结构”特征视为文本特征的补充,将其特征向量补充输入到BERT模型的文本嵌入部分(下文称为ISKN-EMB);另一种则将图注意力网络所编码的结构特征视为独立的结构语义空间,除了将其特征向量补充到BERT模型的文本嵌入部分外,还将其注意力矩阵融合到BERT的注意力矩阵中(下文称为ISKN-ATTENTION).
3) 隐私信息抽取网络.
将隐私信息抽取任务视为命名实体识别任务,提前定义隐私信息特征类别,并在训练集上标注相应类别的位置.隐私信息抽取网络负责将获取的特征映射到预测概率最大的类别.

图1 融入结构先验知识的隐私信息抽取算法
2.2 模型详细说明
2.2.1 特征编码器
特征编码器由文本语义编码和文本结构编码2部分组成.首先,对应给定的文本样例x={e0,e1,…,et},分别进行文本语义编码和文本结构编码:
1) 文本语义编码.该部分具体使用大规模预训练模型(例如BERT)进行嵌入编码,最终获得1组向量w={w0,w1,…,wt},wt∈d,d为文本语义嵌入维度,一般为768.

图2 依赖解析树解析出的依赖关系表示
2) 文本结构编码.针对输入文本样例进行结构层面编码,主要处理文本的句法结构,通过以依赖解析树形式进行解析.如图2所示,依赖解析树可视化展示了句子的句法结构,拼接的边的类型表示为依赖关系类型.这一解析过程对理解文本上下文意义重大,并且,由于它将文本中的实体按常用词典分词,有助于提高隐私信息边界划分的准确度.
该部分具体采用图注意力网络(graph attention networks, GAT)[15]进行编码获取文本结构特征:
graphh=GAT(w,dep,adj),
其中w即为文本语义编码所获取的初始化文本语义嵌入向量,dep即为对应的token的依赖关系向量,adj即为对应的token的连接向量,通常设定为存在依赖关系则连接向量值为1,否则值为0.最终获得1组向量graphh={graphh0,graphh1,…,graphht},其中graphht∈d,d为文本语义嵌入维度,与wt的维度一致.
2.2.2 特征空间融合机制
该机制一共分为2部分:嵌入层面的特征空间融合机制以及注意力层面的特征空间融合机制.
1) 嵌入层面的特征空间融合机制(ISKN-EMB).
嵌入层面的特征空间融合机制,即在模型嵌入表示阶段进行特征融合,考虑到本文所需利用的特征空间包含2种:文本语义空间和文本结构空间,所以模型所采用的骨干模型为大规模预训练模型的代表(BERT)以及表格模型的代表(TAPAS).模型整体融入思想均为将上文所取得的文本语义编码和文本结构编码并行输入到模型中,从而帮助模型通过不同层面理解所输入的文本.对于以下不同模型而言:
① BERT:
wfinalt=wt+graphht,
hfinal=BERT(wfinal,posfinal,segfinal),
② TAPAS:
借鉴TAPAS的附加嵌入(additional embeddings),这里将上文所获得的结构编码视为TAPAS模型输入中的Rank ID,即将依赖类型映射到TAPAS模型预设的Rank ID的空间中,进而达到将依赖关系这一特征并行输入到模型中的目的,即
hfinalt=wt+post+segt+graphht,
最后,总结这一嵌入层面的特征空间融合机制为
xfinal=embeddingfusionφ(wfinal,
posfinal,segfinal,graphfinal),
φ即为网络对应的所需要训练的参数.
2) 注意力层面的特征空间融合机制(ISKN-ATTENTION).
为了更有效地融合结构特征,本文不仅在嵌入层面加入了结构特征,还设定了注意力矩阵层面的特征空间融合机制.该机制在注意力矩阵中引入了“结构”概念.如图3所示,在文本结构编码过程中,除了获取上述的结构嵌入编码外,还保留了模型中的注意力矩阵,即
attentiongraph=GAT(w,dep,adj),
从而获得attentiongraph,其中
attentiongraph={attentiongraph{0,0},…,attentiongraph{t,t}}.
接下来细化到注意力机制:
Attention-Graph(Q,K,V)=
其中Q=K=V,均为大规模预训练模型输入的嵌入表示,V=(V0,V1,…,Vn),n为输入的句子数目,V0={v0,0,v0,1,v0,2,…,v0,t},v0,t∈d,t为每句话的长度,d为输入嵌入维度,通常为768,注意,本文所采用的骨干attention机制为self-attention机制,在此基础上,本文通过加和机制将结构空间的注意力矩阵与文本空间的注意力矩阵进行融合,同时作用在融入“结构”嵌入的整体嵌入,得到最终的隐藏层表示.

图3 注意力层面的“结构”融合
综上,注意力矩阵层面的特征空间融合机制为
yfinal=Attention-Graph(xfinal,xfinal,xfinal).
2.2.3 隐私信息抽取网络
隐私信息抽取网络,即将上文最后一层编码层所获得的隐藏层表示yfinal经过非线性层gc映射到标签空间所得到的logits:
logits=gc(yfinal),
最后,模型整体的目标函数为
其中yt为第t个token的真实标签.
3 实 验
本节将阐述融入结构先验知识的隐私信息抽取算法在不同公开数据集上的实验结果.这些数据集包括中文和英文数据集:中文数据集为微软发布的命名实体数据集MSRA-NER[16],英文数据集为2014年I2B2 De-identification赛道公开的数据集[17].具体的测试结果如下所述.
3.1 数据集说明
微软命名实体识别公开数据集MSRA-NER是专门用来测试隐私信息抽取算法准确率的中文数据集,因为该数据集需要识别的实体均是带有个人隐私性质的,包括人名、地名、机构名称、年龄、电话、邮编等在内的24种命名实体.该数据集主要由训练集、验证集和测试集构成,而本文所涉及的测试数据为训练集和验证集:训练集包含46400条文本,字符数为2169900,所涉及的实体数量为74800;验证集包含了4400条文本,字符数为172600,实体数量为6200.
I2B2 De-identification 2014数据集是专门用于测试隐私信息抽取算法准确率的英文数据集,所谓De-identification即去识别化操作(去除英文所定义的属于隐私信息类别的实体),具体而言,该数据集中所包含的类别有PHI定义的7大类以及赛事中对这7大类所细分的31小类,整体数据集所涉及的数据为训练集50880条文本、验证集32586条文本.
3.2 基线模型
传统的隐私信息抽取算法种类繁多,如:采用大量人工特征的纯CRF模型;采用词向量或字向量的LSTM-CRF及其变种(如Lattice-LSTM)[18],基于BERT,BERT-CRF及其变种(如CharCNN-BERT,CharCNN-BERT-CRF等).
3.2.1 中文数据集基线模型
1) Word Baseline based on LSTM-CRF.LSTM-CRF应用在中文数据集上的模型,区别于英文版在于模型字典不同和输入采用词为单位.
2) Char Baseline based on LSTM-CRF.LSTM-CRF应用在中文数据集上的模型又一变种,其将模型输入改为以字为单位.
3) Lattice-LSTM.以字为单位的BiLSTM-CRF模型,其与传统的BiLSTM-CRF模型相比,融入了词的特征,具有更准确的预测能力.
4) BERT.大规模预训练模型,其依赖在大规模数据集上自监督训练所获取的强大表征能力,在下游任务中均表现不俗.
5) BERT-CRF.将BERT作为编码层获取字符表征后,通过条件随机场CRF得到受约束后各个位置联合概率最大值的解码路径,从而达到效果提升的目的.
3.2.2 英文数据集基线模型
1) CharCNN-BiLSTM-CRF.即charCNN的模型架构,charCNN模型参考了ELMO模型处理字符嵌入的思想,将字符嵌入目前的浅层表征转化为高维表征,再与单词形态特征向量进行拼接,从而缓解了英文中因为不规则的单词构词法所引起的表征不准确问题.
2) ELMO-CharCNN-BiLSTM-CRF.该模型为CharCNN-BiLSTM-CRF模型的又一变种,即用ELMO模型初始化CharCNN的输入,从而提升模型整体的表征能力.
3) CharCNN-BERT.该模型将CharCNN-BiLSTM-CRF模型的BiLSTM-CRF整体的编码层替换为BERT,从而利用了BERT强大的上下文表征能力提升模型预测的准确率.
4) CharCNN-BERT-CRF.该模型在CharCNN-BERT的基础上增加条件随机场模型,从而缓解了CharCNN-BERT模型计算联合概率分布时的不准确性问题.
3.3 模型具体实现说明
3.3.1 实现设置
1张V100显卡;运行环境为Linux;16GB内存;CPU型号为Intel®Xeon®Platinum8163CPU@2.50GHz;模型搭建采用python3.6,pytorch 1.7.0实现.
3.3.2 数据预处理标注策略
当句子处理为token列表后,数据集所采用的标记方法为“BIO”(B代表实体的开始位置,I代表实体的内部位置,O代表不属于实体的位置),例如“Patient presented to Massachusetts General Hospital on.”则被标记为“O O O B-Loc I-Loc I-Loc O”.需要注意的是,因为将句子进行tokenizer的过程中采用的是WordPiece策略,有些词也会被拆成一些词典里常见的词根或词缀,这时,除了拆下来的第1个词根(缀)外,这个词其余所拆出来的词缀都需要标注为“X”,例如,“Mr.Villegas”将会被切分成“Mr”“.”“Ville”“##gas”,它所对应的标注结果为“O O B-PAITENT X”.此外,tokenizer的文本需要在句首和句尾加入开始标识符“[CLS]”和结尾标识符“[SEP]”.
3.3.3 参数设置
中文数据集采用BERT(110M)为骨干模型,英文数据集采用BERT(110M)和TAPAS为骨干模型.
在提取依赖解析树的过程中,针对不同语言的数据集选用了相应的解析器.在英文数据集i2b2上,采用Biaffine Parser[19]作为解析句子依赖关系的模型,使用Allennlp[20]作为提取工具包.而在中文数据集MSRA-NER上,则选用哈工大提供的pyltp工具及其内置的“parser”解析模型进行解析.
在提取结构特征的过程中采用了图注意力网络(graph attention network, GAT).依赖关系的嵌入维度设定为64,图注意力网络的层数选择为[1,2,3,4].实验表明,网络层数为3时,解析的嵌入表征效果最佳.模型优化器选用Adam[21],模型学习率设为3E-5,条件随机场(conditional random field, CRF)模型的学习率为1E-3,训练轮数为3.
3.3.4 评估方法
由于实验中涉及多类别实体,所以引入多类别下的评估方法MicroF1[22]:
F1mi=2×Pmi×Rmi/(Pmi+Rmi),
其中TPi为其中一个类别的正阳性样本数目,FPi为对应类别的伪阳性样本数目,FNi为对应类别的伪负性样本数目.
3.4 模型结果
本节展示融入结构先验知识的隐私信息抽取算法在不同语言公开数据集上的测试结果,并通过可视化注意力机制观察模型的注意力分布.此外,通过样例分析的方法,解释了本文算法在数据集上的效果.
3.4.1 模型整体效果分析
本文实验将ISKN模型中的ISKN-EMB,ISKN-ATTENTION分别与benchmark模型(CRF, Word Baseline based on LSTM-CRF)在数据集上进行整体对比.从表1和表2可知,ISKN模型在中文和英文数据集上均有助于提升结果,但ISKN-EMB模型在测试集上的表现与BERT-CRF相近.这表明,仅将图神经网络学习到的“结构”嵌入表示融入模型是不足的,还需将图神经网络中的“attention-graph”也整合进网络架构,以实现完整“结构”框架的融合.究其原因,结构嵌入作为模型输入,只在结构建模的初期阶段发挥作用.而当前使用的大规模预训练模型,如BERT,由于其庞大的参数量,训练过程中易出现梯度消散现象.因此,初始传入的“结构”知识在训练过程中易被削弱,对模型效果提升的影响有限.同时将“结构”嵌入和“结构”知识同时输入模型则可以防止训练过程中的知识消散,对隐私信息识别准确率有较大的提升.

表1 在中文数据集MSRA-NER上整体效果 %
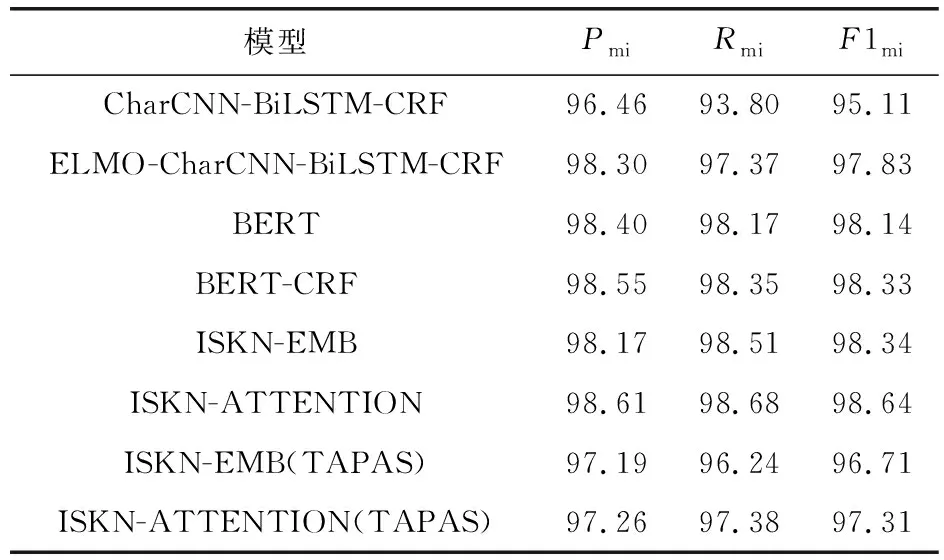
表2 在英文数据集I2B2上整体效果 %
3.4.2 模型局部效果分析
下面将分析本文模型对不同隐私类型提取的效果.从表3可以看出,对于经常出现在训练集中的隐私实体如LOC,模型的帮助有限,表明对这类实体的学习已经较为充分,难以进一步提升.然而,对于ORG和PER这类在训练集中不常出现的隐私实体,模型在MicroF1评估标准中实现了近1%的提升,说明模型在这些较少出现的隐私实体提取中起到了增强效果.这表明模型通过缓解长尾问题,提升了整体的识别效果.
3.4.3 数据分布分析
本节通过TSNE[23]工具展示BERT-CRF与ISKN-ATTENTION训练过程中模型输出表示的数据分布情况.如图4和图5所示,将模型最终获取的嵌入向量用于降维,得到这些特征的2维空间可视化数据分布,从而观察融入结构先验知识的隐私信息抽取算法在数据特征分布上的显著贡献.结果显示,BERT-CRF模型训练得到的数据输出表示较为分散,而ISKN-ATTENTION模型训练得到的数据表示则表现出同一类别的数据更集中,不同类别数据间距离更大.这表明融入的“结构”知识影响了模型训练数据之间的分布,使得同类别数据表示更为相似,不同类别数据表示更分散.

图4 BERT-CRF模型在中文数据集MSRA-NER上的数据分布

图5 ISKN-ATTENTION模型在中文数据集MSRA-NER上的数据分布
3.4.4 模型注意力可视化
本文通过热力图的方式展示了不同模型最终热力图的效果.图6和图7示出了attention矩阵中“结构”知识的显著特征.这一特征在2张图中均有出现,表明在attention层面的“结构”表示已经成功融入到以BERT为代表的大规模预训练模型的attention参数中,辅助进行隐私信息抽取.
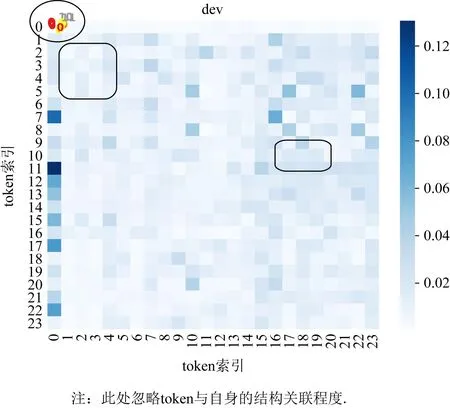
图6 在中文数据集MSRA-NER上的attention可视化

图7 在中文数据集MSRA-NER上的“结构”attention可视化
4 结 语
隐私实体识别任务中经常忽视句子整体的结构感知信息对抽取隐私实体的影响.针对这一问题,本文提出了一种融入结构先验知识的隐私信息抽取算法,设计了隐私数据结构知识增强机制.这一机制赋予模型对句子语义结构的判断能力,增强其判定实体边界的能力,并在一定程度上缓解了隐私实体识别过程中的长尾问题,从而提高了隐私命名实体抽取的准确率.
