面向个性化推荐的node2vec-side融合知识表示
2024-03-05倪文锴杜彦辉马兴帮吕海滨
倪文锴 杜彦辉 马兴帮 吕海滨

收稿日期:2023-06-12;修回日期:2023-08-16 基金项目:中国人民公安大学网络空间安全执法技术双一流专项资助项目
作者简介:倪文锴(1998—),男,浙江金华人,硕士研究生,主要研究方向为知识表示、推荐系统;杜彦辉(1969—),男(通信作者),陕西西安人,教授,博导,博士,CCF会员,主要研究方向为人工智能、大数据(duyanhui@ppsuc.edu.cn);马兴帮(1998—),男(回族),云南曲靖人,硕士研究生,主要研究方向为大数据、深度学习;吕海滨(1996—),男,福建泉州人,硕士研究生,主要研究方向为数据分类、知识图谱等.
摘 要:推荐系统中知识图谱对系统的推荐效果起到很重要的作用,图谱中的知识表示成为影响推荐系统的关键因素,这也成为当前的研究热点之一。针对推荐系统中知识图谱的结构特点,在传统node2vec模型基础上增加关系表示和多元化游走策略,提出一种基于node2vec的知识表示node2vec-side,结合推荐系统知识图谱网络结构,旨在挖掘大规模推荐实体节点间潜在的关联关系,降低表示方式复杂度,提高可解释性。经过时间复杂度分析可知,提出的知识表示方式在复杂度上低于Trans系列和RGCN。在传统知识图谱数据集FB15K、WN18和推荐领域数据集MovieLens-1M、Book-Crossing、Last.FM上分别进行链接预测对比实验。实验结果表明:在MovieLens-1M数据集上,hits@10分别提升了5.5%~12.1%,MRR提升了0.09~0.24;在Book-Crossing数据集上,hits@10分别提升了3.5%~20.6%,MRR平均提升了0.04~0.24;而在Last.FM數据集上,hits@1提升了0.3%~8.5%,MRR平均提升了0.04~0.16,优于现有算法,验证了所提方法的有效性。
关键词:知识表示;推荐系统;链接预测;知识图谱
中图分类号:TP391 文献标志码:A 文章编号:1001-3695(2024)02-006-0361-07
doi:10.19734/j.issn.1001-3695.2023.06.0257
node2vec-side fusion knowledge representation for
personalized recommendation
Ni Wenkai,Du Yanhui,Ma Xingbang,Lyu Haibin
(College of Information & Cyber Security,Peoples Public Security University of China,Beijing 100038,China)
Abstract:The knowledge graph in the recommendation system plays a vital role in the recommendation effect of the system,and the knowledge representation in the graph becomes a key factor affecting the recommendation system,which has become one of the current research hotspots.This paper proposed a node2vec-based knowledge representation node2vec-side based on the traditional node2vec model by adding relational representation and diversifing wandering strategy to the structural characte-ristics of the knowledge graph in recommendation system,which combined with the knowledge graph network structure of recommendation system to explore the potential association relationship between nodes of large-scale recommendation entities,reduced the complexity of the representation and improved interpretability.After time complexity analysis,it could be seen that the proposed knowledge representation is lower than Trans series and RGCN in terms of complexity.Link prediction experiments were conducted on the traditional knowledge graph datasets FB15K,WN18,and recommendation domain datasets MovieLens-1M,Book-Crossing,Last.FM respectively.The experimental results show that on the MovieLens-1M dataset,hits@10 improves 5.5%~12.1% and MRR improves 0.09~0.24,respectively.On the Book-Crossing dataset,hits@10 improves 3.5%~20.6%,and MRR improves 0.04~0.24 on average,respectively.And on the Last.FM dataset,hits@1 improves 0.3%~8.5% and MRR improves 0.04~0.16 on average.It is better than the existing algorithms and verifies the effectiveness of the proposed method.
Key words:knowledge representation;recommender system;link prediction;knowledge graph
0 引言
当前互联网中的各类信息呈爆炸式增长,用户个性化需求与海量信息间的矛盾日益突出,为了给用户提供更加个性化、精准化、智能化的信息服务,个性化推荐算法应运而生。推荐算法中应用的技术众多,谷歌公司首次提出知识图谱(know-ledge graph)[1]的概念并将其应用于搜索引擎。知识图谱本质上是结构化的语言知识库,用于表示各领域中的实体和关系,一般的组织形式为有向图,以节点代表实体,以有向边表示关系。目前知识图谱已广泛应用于问答系统[2]、智能搜索[3]和个性化推荐[4]等人工智能领域。知识图谱一方面能够有效组织海量的推荐数据,另一方面能够通过推荐数据挖掘用户的深层兴趣和推荐物品的潜在关系,从而提升推荐的准确性、多样性以及可解释性。构建推荐系统中的知识图谱首先需要将海量推荐信息组织成结构化的知识,再采用知识表示、知识融合等相关技术支撑推荐应用的需要。其中,知识表示是知识图谱应用的基础工程,本质上是将知识图谱中的实体和关系转换为稠密低维实值向量,然后再通过知识图谱的网络结构进行特征表示学习。随着知识图谱的不断扩展,知识的形式更加复杂多样,知识图谱最常用的知识表示为三元组结构,如(实体e,关系r,实体t)。但是,传统以三元组为主的知识表示表达能力有限,无法满足知识挖掘、知识推理等应用需要。随着知识图谱的应用越来越广泛,对知识表示的研究也在深入。当前知识图谱中的知识表示主要包括基于翻译的知识表示(Trans系列)、基于语义匹配的知识表示(如RESCAL[5]、DistMult[6]、SME[7])、基于距离的知识表示(如SE[8])以及基于图神经网络的知识表示(如RGCN[9])。
在推荐系统中,目前最常用的知识表示是以TransE为代表的翻译模型,例如基于知识图谱的推荐算法CKE[10](基于TransR)和DKN[11](基于TransE)均采用翻译模型进行知识表示,但是以Trans系列为代表的知识表示均假设三元组之间是相互独立的,采用相同概率处理三元组进行建模的方式,往往忽略节点的邻域信息和网络结构,对于关系较少的实体表示效果并不理想,存在节点间语义逻辑低、难以挖掘距离较远的节点间关联关系等问题,这都在不同程度上限制了模型的知识表示。有学者尝试将图神经网络(GCN[12])知识表示模型应用于推荐系统,并提出了KGCN[13]推荐模型。基于GCN的知识表示首先利用GCN生成实体表示,然后使用图嵌入模型捕获实体和关系之间的交互,通过在图上进行卷积学习的方式聚合节点的特征与信息,最终形成节点和关系的知识表示。目前基于图神经网络的知识表示包括GCN、RGCN等,但是图神经网络可解释性差,训练时难度大、计算复杂,容易受卷积层数影响,在处理大规模知识图谱时存在复杂度高、效率低等问题。
本文针对个性化推荐领域的知识图谱结构特点,进行知识图谱重构,并在传统node2vec[14]模型基础上增加关系表示和多元化游走策略,提出一种基于node2vec的知识表示node2vec-side,在充分利用推荐知识图谱网络结构的基础上,更有利于挖掘大规模推荐实体节点间潜在的关联关系,同时其表示方式复杂度低、可解释性更强。最后分别在传统知识图谱和推荐领域知识图谱上进行链接预测实验,相比传统知识表示Trans系列模型和基于图卷积网络的RGCN模型,本文提出的知识表示更能满足推荐系统知识图谱的应用需要。
1 相关工作
目前知识图谱与推荐算法的结合过程中一大难点在于对图谱的知识表示上,在推荐领域知识图谱的表示方面,目前还没有针对性的知识表示方式。2013年,Bordes首先提出TransE模型[15]并在鏈接预测方面取得较大成果,TransE所涉及参数较少且计算简单,因此自从TransE提出以来,一直是知识表示最具代表性的模型之一[16],其目的是让head向量和relation向量的和尽可能地靠近tail向量,如图1所示,TransE的核心是尽可能使得h+r≈t。
虽然TransE简单有效,但是难以处理多关系的问题也较为突出,Zhang对TransE进行了改进,对于每一个关系r,都将其抽象成向量空间中的超平面Wr,对于每个三元组,都先将头节点或者尾节点投影到关系r对应的超平面Wr上,再通过超平面上的平移向量计算头尾节点的差值(图2),在此基础上提出了TransH[17]模型,有效解决TransE不能处理一对多,多对一等关系的问题。TransH不要求h+r≈t,但要求保证头节点在超平面Wr上的投影向量与关系向量dr的和与尾节点的投影向量在同一直线上,即h⊥+dr≈t⊥,其中h⊥=h-wTrhwr,t⊥=t-wTrtwr。
由于TransE和TransH都认为实体和关系应该在相同的向量空间。然而,一个实体可能包含多种属性,每种关系实际上是实体的不同属性,头尾节点和关系可能不在一个向量空间中。Lin等人[18]进一步提出了TransR,在TransE的基础上进行改进,对于关系不仅通过向量r来描述它自身,还通过映射矩阵Mr来描述这个关系所处的关系空间,分别将实体和关系在两个不同空间中进行建模,并最终在关系空间中进行翻译操作(图3)。但是TransR没有考虑头、尾实体类型和属性的不同,并且将实体和关系分开建模的方式大大增加了计算难度,导致其处理大规模图谱时效率较低。针对此问题,又不断提出了TransD[19]、TransF[20]、TransA[21]等系列模型。基于翻译的模型都假定实体和关系处于同一语义空间中,但是实体和关系本质上属于两种不同的客观对象,这种将其在同一向量空间中进行表示的方式并不恰当,Trans系列模型均假设三元组之间是相互独立的,在建模时忽略了三元组周围的邻域信息和全局网络结构信息,导致在个性化推荐领域难以深入挖掘信息。相比之下,node2vec-side在节点游走过程中通过聚合节点之间的关系捕捉知识图谱的语义信息,更能适用于推荐系统场景,能够处理多关系建模等问题,在知识表示方面具有更强的表达能力和适应性,为解决知识图谱与推荐系统结合中的问题提供了新的解决方案。
与此同时,word2vec[22]等模型的提出大大推动了自然语言处理领域的发展,同时也促进了网络表示学习的相关研究,有学者尝试将网络表示应用于知识表示阶段。DeepWalk[23]是一种经典的图结构数据挖掘算法,它将随机游走和word2vec两种算法相融合,将图中的节点看成自然语言处理中的单词,通过在图上进行随机游走的方式获得相关路径,然后利用word2vec获得单词的词向量,即作为节点的网络表示,这种方式有利于挖掘节点间的上下文相关性。
node2vec[24]在DeepWalk算法的基础上进一步发展,改变采样策略,采用有偏向的随机游走方式,改变随机游走序列生成的方式。这种方式在更大程度上可以根据用户需求有效地检索分散的相邻节点,如图4所示,node2vec算法能够兼顾深度游走DFS(depth-first-search)和广度游走BFS(breadth-first search)方式,主要通过调节参数p和q实现偏向游走策略。其中DFS偏向游走侧重于遍历高阶节点,遍历结果刻画节点的同质性,BFS偏向游走则侧重于遍历邻近节点,更多地聚合节点的同构性。但是知识图谱本质上属于异构图,节点间的连线代表着不同的关系,node2vec的现有游走策略多用于同构图中,如果将其直接应用于异构网络中,可能会存在以下问题:a)异构网络由实体(异构节点)和关系(不同类型的边)组成,在知识图谱中,三元组(头实体,关系,尾节点)是构建上下文的核心,而直接应用node2vec会忽略这个关键信息,进而影响知识表示质量;b)遇到复杂的异构网络,单一的随机游走策略不能有效得到网络的结构。
node2vec-side针对node2vec在知识表示方面应用存在的问题,引入关系表示并采用多元偏向游走策略,将其更好地应用推荐数据知识图谱表示。
2 node2vec-side融合知识表示
本文针对推荐系统应用场景,提出了基于node2vec的知识图谱知识表示node2vec-side,其基本思想是:将推荐领域以三元组保存的知识图谱进行重构并同质化为带权有向图,然后在该有向图中采用多元随机游走策略(BFS偏向和DFS偏向)分别在节点上进行游走得到节点表示,同时根据生成的游走序列聚合节点间的关系,最终综合各游走策略下的表示结果获得目标知识图谱的知识表示,整体流程如图5所示。
2.1 知识图谱重构
在物品-属性知识图谱的提取过程中,推荐数据通常以三元组的形式进行表示,如(姜文,导演,让子弹飞),其中可以将知识图谱中的 “导演”关系看做头实体“姜文”到尾实体“让子弹飞”的一次翻译操作。传统的Trans系列知识表示单独处理每个三元组,虽然简化了知識图谱向量化过程,但是容易丢失知识图谱结构特征和节点邻域信息,在处理复杂关系和深层次关系语义挖掘中效果不佳。
为了更好地利用知识图谱的网络结构和节点的邻域信息,本节采用基于三元组结构的网络重构方法,在重构过程中,将知识图谱中的实体抽象为节点,将关系抽象为有向边,其中边所指的方向即表示实体之间的关系,由此将知识图谱转换为有向图,同时,在知识图谱重构过程中,将针对每个关系的重要程度进行权重的分配,使得不同的三元组在游走策略中具有不同的影响力,重要关系连接的节点将获得更大概率的遍历。
根据知识图谱中的关系权重将知识图谱同构化为带权有向图的过程如图6所示。其中游走的条件概率为
P(ci=x|ci-1=v)=πvxZif(v,x)∈E
0otherwise(1)
其中:πvx为节点v和x的非归一化转移概率;Z为归一化常数。πvx=wvx则为DeepWalk算法,而在node2vec中设定πvx=αpq(t,x)·ωvx来调整节点之间的转移概率,ωvx表示边权重,带权有向图中各边的权重为该关系在知识图谱中出现的次数,相同的关系在有向图中具有相同的权重,即权重ωr=count(ri),则有
πvx=αpq(t,x)·ωvx=αpq(t,x)·count(ri)(2)
其中: αpq(t,x)=1pif dtx=0
1if dtx=1
1qif dtx=2(3)
如图5所示,其中t为节点v的上一节点,dtx表示节点t与x的最短距离。若t、x直接相连,则dtx=1;若t、x为同一节点,则dtx=0;若t、x不相连,则dtx=2。参数p表示返回参数,参数q表示进出参数,通过调节参数p、q可以权衡网络表示模型的倾向性。由式(2)可知,从当前节点到下一个节点的概率由游走策略和关系权重共同决定,对于知识图谱中关系出现次数较多的节点可能会多次经过,解决了传统的Trans系列模型以相同概率处理每个三元组的问题,同时也可以通过关系权重来反映关系间的重要程度。
2.2 关系聚合
知识图谱在重构后可以通过随机游走的方式获得节点的知识表示,本节在node2vec的节点表示基础上提出边表示方式,使知识表示更符合知识图谱三元组结构特点,提高知识表示的区分度。文献[24]提到简单的边特征表示方法,如表1所示,其中u、v表示边连接的节点。但是目前node2vec适用于同构图中,在关系表示部分简单地认为每条边都是相异的,而在知识图谱中相同关系代表的边向量应该保持一致。为了更好地表示关系向量,本节根据向量平移不变性的思想提出新的关系表示方法,核心思想是在随机游走中对每一步经过的关系进行聚合并根据权重进行调整。在某次游走序列中存在关系ri、头尾节点知识表示f(h)、f(t)和某个包含关系ri的三元组(h,ri,t),通过头尾节点向量差完成关系ri的一次聚合(图6中f1(ri)、f2(ri)等),依此类推,在节点进行随机游走过程中进行关系聚合操作,最后根据关系ri在知识图谱中的权重(图6中Nri)进行平均处理,为了防止某些权重较大的关系经过聚合平均后出现过于稀疏的情况,本文引入中间值Z,当关系权重大于Z时作统一平均处理。
图6展示了在表示过程中从某一起点开始进行随机游走时的具体操作,首先node2vec随机选择游走起点(图6中的h1),然后根据选择的游走策略在知识图谱上进行多次随机游走(图中选择两次随机游走)并得到多个随机游走序列Sh1集,同时针对得到的随机序列,如{h1→t4→h4→t1},通过头尾节点作差的方式得到该步对应关系的一次聚合(图中fi(ri)表示对关系ri的第i次聚合),当针对该起点h1完成所有游走时对关系向量进行求和操作并选择其他节点作为起始节点重复上述操作,依此类推,完成该知识图谱下所有节点随机游走时,对最终关系向量根据其权重进行平均。图7展示仅在h1节点处进行的随机游走。
对于给定的关系集合R={r1,r2,r3,…,rn},假设任意关系ri∈R,可通过式(4)得到关系ri的知识表示。
f(ri)=∑ifi(ri)Nri=∑(h,ri,t)∈G∨Euclid Math OneSAp(f(t)-f(h))min(count(ri),Z)(4)
其中:Z=|a·sum(G)|;Z表示平均化归值;α表示比例系数且α∈(0,1);G表示知识图谱三元组集,即G={(h,r,t)},sum(G)表示知识图谱中三元组的总数;Euclid Math OneSAp表游走序列集,即Euclid Math OneSAp={Sv|v∈V},V为节点集;Nri表示关系ri的权重值;f(t)、f(h)表示基于node2vec表示的头尾节点知识表示;count(ri)表示某一关系ri在知识图谱中出现的次数。基于上述表示方式,确定node2vec-side模型的得分函数如下:
gr(h,t)=sim(h+r,t)=cos(h+r,t)=(h+r)·t‖h+r‖×‖t‖(5)
其中:sim表示相似度函数,本文采用余弦相似度作为相似度计算函数。最终由fi(h)、fi(t)、fi(r)构成某一偏好随机游走下的知识表示fi(h,r,t)。
2.3 多元化游走策略
上文提到针对复杂的异构网络,选择单一的随机游走策略不能有效得到网络的结构,针对这一问题,可采用多种偏好策略并行的方式进行随机游走。其中node2vec算法通过调节p、q可获得不同偏向性的表示结构,其结果主要体现在节点的同质性和结构性上,其中同质性是指相邻节点的知识表示应该相似,而结构性是指结构相似的节点的知识表示应该相似。参数q表示进出参数,根据式(3)可知:q>1时,游走方式偏向于起始点的邻居节点,知识表示倾向于BFS;当q<1时,游走方式偏向于起始点的远处节点,知识表示倾向于DFS。两种游走方式的具體区别如图8所示,颜色接近的节点表示其相似性更高。
本文为充分兼顾知识图谱节点的同质性和同构性,获得更全面的知识表示,将分别通过深度优先游走(DFS)和广度优先游走(BFS)策略获得知识表示f1(h,r,t),f2(h,r,t)后,再融合获得该知识图谱下的知识表示f(h,r,t)。
f(h,r,t)=f1(h,r,t)∪f2(h,r,t)(6)
其中:∪表示拼接操作。
首先根据个性化推荐领域的知识图谱,分别采用两种游走策略进行节点表示学习。同时,根据节点随机游走序列将具有相同关系构成的子图分离,得到同一关系的子图。在这些子图中通过头尾节点对关系进行聚合表示,生成新的特征向量,最后采用向量合并的方式,将两种游走策略下的向量表示结合起来,得到高维向量表示形式。该模型的核心在于利用知识图谱中的关系信息,通过游走过程产生的序列对关系子图进行聚合,并将实体节点与关系信息相结合,生成更加丰富的特征向量,同时进一步采用两种不同的游走策略,分别考虑了全局和局部的信息,从而更加全面地捕捉了知识图谱中的节点信息,进一步提高了特征向量的表达能力,能够有效地提高个性化推荐任务的性能。
node2vec-side融合知识表示得分函数G(h,r,t)如下所示:
G(h,r,t)=h(g1r(h,r,t),g2r(h,r,t))(7)
gir(h,t)=sim(h+r,t)=cos(h+r,t)=(h+r)·t‖h+r‖×‖t‖(8)
其中:sim表示相似度函数,本文采用余弦相似度作为相似度计算函数。式(7)中的h(·)表示融合函数,在本文中取为平均值函数h(X1,X2)=(X1+X2)/2。在预测的过程中通过计算得分函数,从而选择最佳的尾节点或者头节点,得分函数选取的好坏将直接影响知识表示预测的效果。
算法1 node2vec-side融合知识表示
输入:知识图谱三元组集N。
输出:实体的向量表示emb;关系的向量表示embr。
初始化:利用知识图谱中的三元组(h,r,t)∈N得到新的图G=(V,E),其中V为节点集合,E为边集合,初始化r_emb={er|r∈E}
a)edge_weight=count(r)/* 对于每个三元组(h,r,t)∈E,计算新的边权重*/
b)G.add_weighted_edges_from(edge_weight)/*增加边权重完成知识图谱重构化*/
c)基于权重w构建新的转移概率矩阵T
d)在G上为每个节点v∈V进行r次随机游走,得到游走序列集Euclid Math OneSApv={sv,1,sv,2,…,sv,r}
e)node_emb=node2vec(G,dim,walk_length,num_walks,p,q,weight_key)//通过设定p,q进行随机游走得到节点表示
f)for sv,i inEuclid Math OneSApv://获取每个游走序列sv,i∈Euclid Math OneSApv;
for(h,r,t) in sv,i://获取每一步的头尾节点
e′r=e′t-e′h//e′h为头节点h的向量,e′t为尾节点t的向量
er=e′r+er //同一关系er进行累加
g)r_emb={er|er=∑(h,ri,t)∈Eer|min(edge_weight,Z)|}//作平均处理
h)执行后转步骤d),选择不同p、q进行多元化游走
i)输出节点表示列表emb={ev|ev∈node_emb1∪node_emb2}和所有关系表示列表embr={er|er∈r_emb1∪r_emb2}
2.4 时间复杂度分析
node2vec-side融合知识表示在node2vec基础上增加关系表示和多元化游走策略,node2vec随机采样每个采样点平均时间复杂度为O(lk(l-k)),采用层次softmax优化的skip-gram部分的时间复杂度为O(log2Nv),关系聚合部分时间复杂度为O(rlNv),在采用两种游走策略的情况下,node2vec-side的总时间复杂度为O(2lNvk(l-k)+2log2Nv+2rlNv)。其中:l表示随机游走的长度;k表示领域节点个数;Nv表示节点个数;r表示随机游走次数。TransE、TransH、TransR和RGCN的时间复杂度如表2所示[19,25]。其中:dv表示节点表示的维度;dr表示关系表示的维度;N表示三元组总数;Nr表示关系数;M表示图卷积的层数。
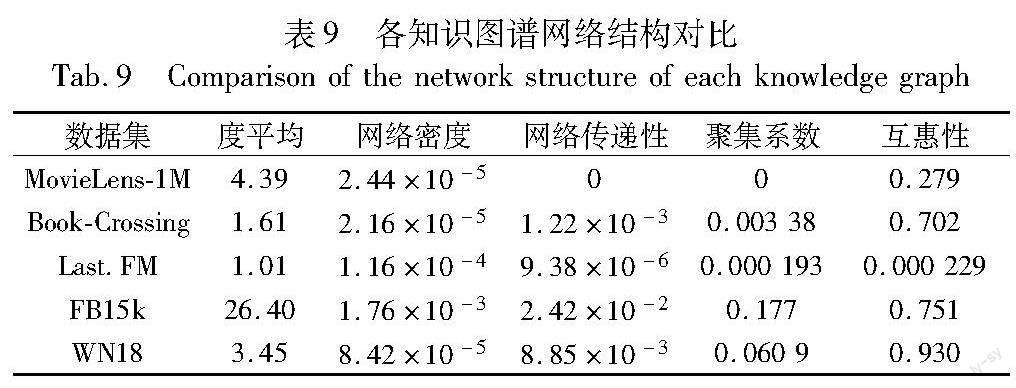
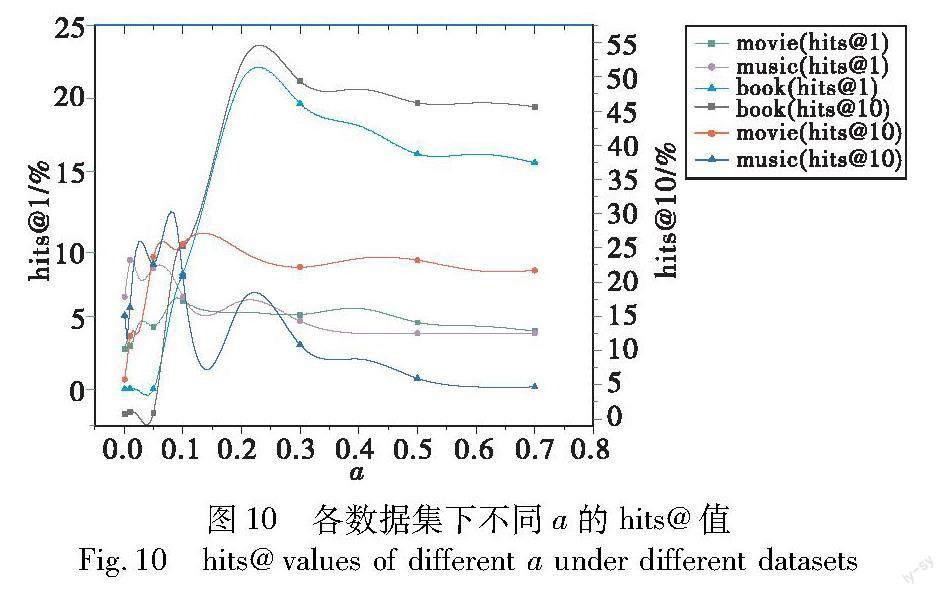
对于node2vec-side而言,在实际应用中k、l和r为常数,同时在大规模知识图谱中Nv< 3 实验设置及结果分析 本章将首先对比node2vec-side知识表示模型在传统知识图谱中链接预测的性能,使用的数据集为FB15K和WN18,然后验证其在推荐系统领域中的有效性。推荐领域的知识图谱大多是以物品为核心,以相关属性为节点,呈现中心发散的结构特点。本次实验将使用公开推荐系统数据集MovieLens-1M、Book-Crossing、Last.FM,在各数据集的知识图谱上进行链接预测实验,并与Trans系列模型和基于图神经网络的RGCN模型进行对比。 3.1 数据集分析 FB15K是基于Freebase抽取得到的稠密子集。Freebase是一个公共的、可编辑的数据集,Freebase中的条目采用了RDF的三元组组织形式,截至2015年,Freebase包含了大约30亿个不同领域的事实、5 000万个实体,包括大约2.7万个实体类型和3.8万个关系类型。 WN18是由Border等创建的词汇知识图WordNet的子集。WN18中的主要关系模式为对称和逆关系。 MovieLens-1M是一个电影推荐公开数据集,其中包括了6 040个用户和3 706部电影的1 000 209条评分数据。相应的知识图谱包含1 241 995个三元组,其中有182 011个实体,有12种关系。 Book-Crossing是一个书籍推荐的公开数据集,包括了来自105 283个用户和340 555本书的1 149 780条评分数据,相应的知识图谱包含151 500个三元组,其中有77 903个实体,有25种关系。 Last.FM是一个音乐推荐的公开数据集,包括了来自1 892个用户和17 632个艺术家的92 834条权重数据,相应的知识图谱包含15 518个三元组,其中有9 366个实体,有60种关系。各数据集的具体信息如表3所示。 3.2 评价指标 由于在推荐系统中,人们更多关注推荐结果的准确性,所以本文主要开展对推荐数据知识图谱的链接预测实验。链路预测的主要过程是对于一个完整的三元组(h,r,t),实验给定(h,r)后预测t或给定(h,t)后预测r,从而验证模型预测实体的能力。首先在推荐知识图谱中随机选取10%的三元组作为测试集,并将其在原知识图谱中予以删除,将删除后的知识图谱作为训练集进行实验。对测试集中的每一个三元组(h,r,t),选择丢弃尾节点t,得到(h,r)后,用实体集中的元素e补全后通过得分函数G(h,r,e)依次进行得分计算,将计算所得的所有结果进行排序,得到原始三元组(h,r,t)的排名。 通常采用排名不超过n的百分比(hits@n)、平均排名(mean rank,MR)和平均倒数排名(mean reciprocal rank,MRR)作为衡量指标,各指标的计算方式如下所示。 hits@n=1|S|∑|S|i=1Ⅱ(ranki≤n)(9) MR=1|S|∑|S|i=1ranki=1|S|(rank1+rank2+…+rank |S|)(10) MRR=1|S|∑|S|i=1 1ranki=1|S|(1rank1+1rank2+…+ 1rank|S|)(11) 其中:S是三元組集合,|S|是三元组集合个数;ranki是指第i个三元组的链接预测排名。MR指标的取值为0~N,其中N是测试集中的三元组数量,越接近0表示模型的性能越好;而MRR的取值为0~1,其值越接近1表示模型的效果越好。 3.3 实验设置与实现 实验采用的操作系统为Ubuntu 22.04.2 LTS,采用的实验环境为CUDA 10.2、Python 3.8.13、Torch 1.10.1+cu102、NumPy 1.23.5。本节实验部分首先进行传统知识图谱上的实验对比。在node2vec-side中将每个节点开始的随机游走次数number-walks设为60,每个节点开始的随机游走长度walk-length设为100,其他超参数如表4所示。 对于基线模型的参数,按照论文中推荐的参数进行设置实验。node2vec-side知识表示模型与其他传统模型如RESCAL[26]、SE[8]、SME[28]、TransE、TransH、TransR等在链接预测方面的实验对比结果如表5所示。 从上述实验结果可以发现,node2vec-side模型在处理大规模知识图谱的情形下表现较好,在FB15K数据集上hits@10提升1.4%、hits@1提升1.8%,而在WN18数据集上hits@1提升6.2%,但是hits@10却较低,由于 FB15K 的规模较大,关系丰富,相较于小规模知识图谱 WN18,链接预测对全局特征的要求更高。然而,传统的 Trans 系列模型采用独立训练三元组的方式,容易忽略知识图谱的网络结构,导致难以挖掘一些较远节点的关联关系。为了解决这一问题,node2vec-side 知识表示采用有偏向的随机游走方式,并引入关系表示,能更好地理解全局特征,并善于挖掘较远节点之间的关联。因此,该模型的精确预测能力(hits@1)优于Trans 系列模型。 表6给出了node2vec-side模型在个性化推荐领域相关实验对比的超参数取值,其中dim表示向量维度,一般来说,较高的维度可以更好地捕捉节点的特征,但可能会增加计算复杂度,本文取值为128,number-walks表示从各节点开始的随机游走次数,通过增加游走次数可以增加采样的多样性,有助于更好地学习节点之间的关系。本实验选择了适中的游走次数,以平衡采样多样性和计算效率,walk-length表示路径长度,较短的路径长度可能更加侧重局部邻域的关系,而较长的路径长度则更多地考虑全局信息。本文根据数据集的情况,考虑在一定程度上平衡局部和全局信息,选择合适的路径长度,这些参数的具体取值是通过多次实验获得的,通过不断尝试不同的参数组合,并根据实验结果进行分析和比较。同时,TransE的嵌入维度设为50,学习率lr为0.01,TransH和TransR的嵌入维度均设为100,TransH的学习率lr为0.01,TransR的学习率lr为0.001,RGCN的嵌入维度设为100,学习率lr为0.01。本文对每个数据集进行处理,经过多次实验后得出实验结果。 在个性化推荐领域,针对物品-属性知识图谱中的链接预测问题,本文进行了一系列实验,对比了node2vec-side知识表示模型与其他几种在个性化推荐领域流行的知识表示模型,包括TransE、TransH、TransR和RGCN。具体实验结果如表7和8所示。 表7主要展示了hits@指标的实验结果,而表8则主要展示了MRR和MR指标。通过这些实验结果可以看到,node2vec-side模型在链接预测问题上表现出了出色的性能,尤其是在hits@1和MRR指标上。相比其他模型,node2vec-side模型的表现有了显著提升,表明node2vec-side模型在个性化推荐领域中具有较高的应用价值,并且可以为推荐系统提供更加准确、多样和可解释的推荐结果。 3.4 结果分析 通过表7发现,node2vec-side在精确预测方面(hits@1)的处理效果都优于其他模型。对于推荐数据量较大、关系较多的推荐数据集,如MovieLens-1M,链接预测对全局特征的要求更高,而node2vec-side知识表示更能把握全局特征,擅于挖掘一些较远的节点间的关联关系,相比而言,Last.FM中推荐知识图谱的规模较小,RGCN的聚合速度和表示效果更好,但是node2vec-side在精准预测(hits@1)上仍较为突出。同时由表8可知,node2vec-side在MRR和MR上都优于Trans系列和RGCN,各模型在MovieLens-1M中的MR均较大,而在Last.FM中则较小,其主要原因是MovieLens-1M中三元组数量较多,预测难度更大。 各训练集的推荐知识图谱网络结构如表9所示,其中网络传递性是表示一个图形中节点聚集程度的系数,可以衡量网络的关聯性,其值越大表示交互关系越大,同时网络也越复杂;互惠性是指在有向图中双向连接的边占所有边的比例。FB15K是基于Freebase抽取得到的大众知识图谱,通过对比可以发现,推荐系统领域中的知识图谱相比于传统知识图谱而言,网络密度更小、节点间的交互较少、节点的聚集程度较低,往往是以物品为核心,物品属性为节点的图谱结构。不同类型的推荐知识图谱可能又会存在不同的网络差异,在MovieLens-1M、Book-Crossing推荐知识图谱中,互惠性较高、网络密度较低,综合node2vec-side在三个推荐领域知识图谱上的表现可知,当图谱的聚集程度越高时,其链接预测的效果更好。传统的Trans系列模型应用效果不佳,同时由于节点间交互较少,网络结构更多体现稀疏性,基于图神经网络的模型RGCN在处理大型图数据时受复杂度限制,不能有效聚合邻居节点,存在训练成本大的问题,导致模型在实际应用中效果不尽如人意。然而,在这种网络结构中,基于随机游走的方式更能够发现物品间的关联关系,这种方法不仅训练速度更快,而且效率更高。通过随机游走可以在图数据中生成大量的训练样本,这些样本可以被用来训练模型,从而提高模型的准确性和效率。因此,基于随机游走的方法在处理大型图数据时具有广泛的应用前景,并且可以在个性化推荐领域发挥重要作用。 3.5 超参数分析 本节主要探讨了参数a对实验结果的影响,通过对图10的观察可以发现,不同数据集对参数a的适应性不同。当参数a较小时,各数据集的hits@值随着参数变化的波动较大,而当参数a的值变大时,各数据集的hits@值趋于稳定。此外,针对不同的数据集,参数a的最佳取值也有所不同。在Book-Crossing数据集中,当a在0.2附近时hits@值达到峰值;在MovieLens-1M数据集中,当a在0.1附近时hits@值达到峰值;在Last.FM数据集中,当a在0.1附近时hits@10达到峰值,而a在0.01附近时hits@1达到峰值。相较而言,模型在Book-Crossing数据集下的hits@值表现更好。这表明在不同的数据集上,参数a的取值对模型的性能有着不同的影响,需要根据具体的数据集进行调整。 4 結束语 目前基于高阶信息聚合的知识图谱推荐算法[27~29]旨在利用知识表示将语义信息与路径结合起来,通过周围邻居节点丰富用户和物品的表示,而本文针对推荐系统知识图谱特点,通过改进node2vec模型提出node2vec-side融合知识表示模型,可以应用于推荐数据的知识表示领域,将推荐领域的知识图谱进行重构后,再通过节点表示、关系聚合以及多元游走策略等得到知识表示形式,为个性化推荐提供数据挖掘、用户潜在偏好发现等提供支撑。在本文研究成果的基础上,文献[30]对RippleNet推荐模型进行改进,利用node2vec-side进行物品画像和用户画像建模,挖掘物品潜在关联关系,多元化游走策略兼顾知识图谱中节点的同质性和同构性,降低原有模型用户画像更新局部性影响,模型在推荐准确率和多样性方面有显著提升。相比于目前应用较多的Trans系列模型,本文模型通过对知识图谱进行有偏向游走的方式学习网络结构,在建模时更多考虑三元组周围的邻域信息和全局网络结构信息,有利于挖掘发现距离较远的实体间关联关系,复杂度更低、可解释性更强,但是在面对小规模推荐系统知识图谱中的知识表示能力还有所欠缺,在未来工作中,将重点研究提升小规模推荐系统知识图谱中链接预测的能力,增强现有基于知识图谱的推荐算法的准确性和多样性。 参考文献: [1]Singhal A.Introducing the knowledge graphi things,not strings [EB/OL].(2012-05-16).https://www.blog.google/products/search/introducing-knowledge-graph-things-not1. [2]Bordes A,Chopra S,Weston J.Question answering with subgraph embeddings[EB/OL].(2014).https://arxiv.org/abs/1406.3676. [3]Nguyen D Q,Nguyen T D,Phung D.A relational memory-based embedding model for triple classification and search personalization[EB/OL].(2019).https://arxiv.org/abs/1907.06080. [4]Zhou Kun,Zhao W X,Bian Shuqing,et al.Improving conversational recommender systems via knowledge graph based semantic fusion[C]//Proc of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining.New York:ACM Press,2020:1006-1014. [5]Nickel M,Tresp V,Kriegel H P.A three-way model for collective learning on multi-relational data[C]//Proc of the 28th International Conference on Machine Learning .2011:809-816. [6]Yang Bishan,Yih W,He Xiaodong,et al.Embedding entities and relations for learning and inference in knowledge bases[EB/OL].(2014).https://arxiv.org/abs/1412.6575. [7]Socher R,Chen Danqi,Manning C D,et al.Reasoning with neural tensor networks for knowledge base completion[C]//Proc of the 26th International Conference on Neural Information Processing Systems.2013:926-934. [8]Bordes A,Weston J,Collobert R,et al.Learning structured embeddings of knowledge bases[C]//Proc of the 25th AAAI Conference on Artificial Intelligence.2011:301-306. [9]Schlichtkrull M,Kipf T N,Bloem P,et al.Modeling relational data with graph convolutional networks[C]//Proc of European Semantic Web Conference.Cham:Springer,2018:593-607. [10]Zhang Fuzheng,Nicholas J Y,Lian Defu,et al.Collaborative know-ledge base embedding for recommender systems[C]//Proc of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.New York:ACM Press,2016:353-362. [11]Wang Hongwei,Zhang Fuzheng,Xie Xing,et al.DKN:deep knowledge-aware network for news recommendation[C]//Proc of World Wide Web Conference.2018:1835-1844. [12]Kipf T N,Welling M.Semi-supervised classification with graph convolutional networks[EB/OL].(2017).https://arxiv.org/abs/1609.02907. [13]Wang Hongwei,Zhao Miao,Xie Xing,et al.Knowledge graph convolutional networks for recommender systems[C]//Proc of World Wide Web Conference.2019:3307-3313. [14]Li Lu,Wang Wei,Yu Shuo,et al.A modified node2vec method for disappearing link prediction[C]//Proc of the 15th International Conference on Dependable,Autonomic and Secure Computing.Piscata-way,NJ:IEEE Press,2017:1232-1235. [15]Bordes A,Usunier N,Garcia-Duran A,et al.Translating embeddings for modeling multi-relational data[C]//Proc of Neural Information Processing Systems.Massachusetts:MIT Press,2013:2787-2795. [16]Rossi A,Barbosa D,Firmani D,et al.Knowledge graph embedding for link prediction:a comparative analysis[J].ACM Trans on Know-ledge Discovery from Data,2021,15(2):1-49. [17]Wang Zhen,Zhang Jianwen,Feng Jianlin,et al.Knowledge graph embedding by translating on hyperplanes[C]//Proc of the 28th AAAI Conference on Artificial Intelligence.2014:1112-1119. [18]Lin Yankai,Liu Zhiyuan,Sun Maosong,et al.Learning entity and relation embeddings for knowledge graph completion[C]//Proc of the 29th AAAI Conference on Artificial Intelligence.2015:2181-2187. [19]Ji Guoliang,He Shizhu,Xu Liheng,et al.Knowledge graph embedding via dynamic mapping matrix[C]//Proc of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing.2015:687-696. [20]Feng Jun,Huang Minlie,Wang Mingdong,et al.Knowledge graph embedding by flexible translation[C]//Proc of the 15th International Conference on the Principles of Knowledge Representation and Reasoning.2016:557-560. [21]Xiao Han,Huang Minlie,Hao Yu,et al.TransA:an adaptive approach for knowledge graph embedding[EB/OL].(2015).https://arxiv.org/abs/ 1509.05490. [22]Mikolov T,Chen K,Corrado G,et al.Efficient estimation of word re-presentations in vector space[EB/OL].(2013).https://arxiv.org/abs/1301.3781. [23]Perozzi B,Al-Rfou R,Skiena S.DeepWalk:online learning of social representations[C]//Proc of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.New York:ACM Press,2014:701-710. [24]Grover A,Leskovec J.node2vec:scalable feature learning for networks[C]//Proc of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.2016:855-864. [25]Feng Yanlin,Chen Xinyue,Lin B Y,et al.Scalable multi-hop relational reasoning for knowledge-aware question answering[C]//Proc of Conference on Empirical Methods in Natural Language Processing.2020. [26]Nickel M,Tresp V,Kriegel H P.A three-way model for collective learning on multi-relational data[C]//Proc of International Confe-rence on International Conference on Machine Learning.[S.l.]:Omnipress,2011. [27]崔煥庆,宋玮情,杨峻铸.知识水波图卷积网络推荐模型[J].计算机科学与探索,2023,17(9):2209-2218.(Cui Huanqing,Song Weiqing,Yang Junzhu.Knowledge water wave graph convolutional network recommendation model[J].Computer Science and Exploration,2023,17(9):2209-2218.) [28]Wang Ze,Lin Guangyan,Tan Huobin,et al.CKAN:collaborative knowledge-aware attentive network for recommender systems[C]//Proc of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval.New York:ACM Press,2020. [29]罗承天,叶霞.基于知识图谱的推荐算法研究综述[J].计算机工程与应用,2023,59(1):49-60.(Luo Chengtian,Ye Xia.Review of research on recommendation algorithms based on knowledge graph[J].Computer Engineering and Applications,2023,59(1):49-60.) [30]Ni Wenkai,Du Yanhui,Ma Xingbang,et al.Research on hybrid re-commendation model for personalized recommendation scenarios[J].Applied Sciences,2023,13(13):7903.
