基于单调排序与并行选择的连续删除堆栈译码器的硬件实现
2024-03-04曾文坦叶龙建翟雄飞韩国军
曾文坦,叶龙建,翟雄飞,韩国军
(广东工业大学 信息工程学院, 广东 广州 510006)
信道极化概念在文献[1]中首次被提出,是目前唯一能够被严格证明在二进制无记忆信道中可达到信道容量上限的一种编码方式。基于这一原理,文献[1]提出一种全新的编码方式,命名为极化码。经过逐步完善,极化码被选定为5G标准中控制信道的信道编码方式。
文献[1]中同样提出了极化码编码相对应的译码算法,连续删除(Successive Cancellation, SC) 译码算法,由于SC具有低复杂度的特点,所以SC译码算法成为最主流的一类极化码译码算法之一。然而SC译码算法同时也面临着纠错性能较差、吞吐率较低等问题。为了解决这些缺陷,文献[2-3]中引入了多路径度量竞争的思路,提出连续删除列表(Successive Cancellation List, SCL) 译码和连续删除堆栈(Successive Cancellation Stack, SCS) 译码算法。SCL译码算法基于广度优先的原则对最优路径搜索,同时扩展多条译码路径。而SCS译码算法基于深度优先原则,对最优路径进行扩展。这两种改进算法具有相近的纠错性能且相较于SC译码算法有着显著的提升,而SCS在高信噪比(Signal-to-Noise-Ratio, SNR)时对比于SCL译码算法具有更低的复杂度。除此之外,部分其余的改进算法也值得关注,文献[4]提出循环冗余校验(Cyclic Redundancy Check, CRC) 级联的方法,在SC译码中加入CRC从而提高纠错性能,这一方法易于实现且未对SC算法本身做出改动,因此可以与其他许多的优化算法叠加使用,例如在文献[5-6]将CRC推广到SCL与SCS译码中,提出CRC辅助SCS(CRC Assist-SCS, CA-SCS) 译码算法和CRC辅助SCL译码算法(CRC Assist-SCL, CA-SCL) 。在非SC类译码算法中,目前关注度较高的是置信度传播(Belief Propagation, BP) 译码算法[7],并且在文献[8-9]中加入比特翻转(Bit-Flipping) 使其纠错性能得到进一步提升。BP算法本身具有高度并行性,在吞吐率方面具有较大优势,但这同样也造成了较高的运算复杂度和空间复杂度,因此在硬件实现中BP算法的应用场景较窄,并没有在硬件实现中成为一种主流的译码算法。
而极化码译码算法能否进行高效硬件实现,是以上算法得以实际应用的前提。根据SC类译码算法的递归运算原理可知,其递归运算由基本的运算单元组成。文献[10]提出了树形结构,将运算单元以树形连接。然而该结构的硬件利用率低,每个周期仅有一层的运算单元被激活。而文献[11]在这一基础上提出平行结构与半平行结构,以极小的时延为代价,将运算单元数量减少至原来的1/4,同时提高了硬件利用率。此外,提高译码器吞吐率也是在硬件设计中所面临的另一项挑战。文献[12-14]主要在硬件吞吐率上做进一步的改进,例如引入2-bits判决策略,提出矢量交叠架构实现帧间流水线等方式。文献[15]针对SCL译码提出低延迟列表译码(Reduced Latency List Decoding, RLLD) 算法,通过减少节点的访问来提高译码速度。文献[16]考虑了架构的灵活性提出可配置的SCL译码器,扩展了SCL译码器的应用场景。文献[17]则针对SCS译码排序提出双堆栈结构实现路径排序功能。然而这种双堆栈结构受到读写与比较策略的限制,其路径选择过程效率较低并且受SNR影响。而且,堆栈存储的结构使得同一路径的不同类型的数据必须进行捆包打包,对于不同类型的路径信息读写不灵活。另外,对于SC类译码算法,文献[18-19]提出的部分和更新的结构,通过寄存器存储的方式可以用较少的硬件资源实现部分和的层内并行、层间串行的更新。
针对当前SCS译码在路径选择中效率较低与路径信息存储信息不够灵活的问题,本文针对SCS译码算法提出一种基于并行比较和升调排序的路径选择方式,利用存储器组代替堆栈结构。相较于目前的SCS路径存储策略,该策略更具备灵活性,通过对不同路径值(Path Value, PV) 的独立存储,实现单条路径中不同类型的信息单独读写。 另外,本文在部分和更新结构上,充分利用FPGA的并行性,直接利用组合逻辑进行运算,能够实现多层并行,提高了部分和更新的效率。
1 SC类译码算法

1.1 SC译码算法
利用接收端所接收到的信息序列y1N与部分已经译出的码字序列uˆi1-1对当前比特uˆi进行判决。判决函数为
式(3)中,当i∈A表明该索引位属于信息比特,根据LLR值作比特判决,当LLR值大于等于0时,比特判决为“0”,若小于0则判为“1”。而当i∈Ac时,则表明该索引位为冻结比特,冻结比特不包含任何信息,通常固定为比特“0”。

部分和值传递至上一层节点后,上层节点继续向其他未被激活的节点进行LLR值递归运算与比特判决,直至二叉树中所有叶子节点都完成比特判决即完成译码。
1.2 SCS译码算法
SCS算法的主要思路是通过引入路径度量值(Path Metric,PM)计算,通过PM值大小来对每个路径的优劣程度进行度量,每次只对当前最优路径进行扩展,其余次优路径存储于堆栈中,一直扩展至路径长度(Path Length, PL) 值等于码长N结束。用p表示当前出栈的路径。PV值与比特索引值等价,可用i表示,当前出栈路径的LLR值递归运算结果用Lip表示,PM值定义为
式中:B={i|(-1)uˆi=sign(Lip)}。
图2为N=4的SCS译码算法的译码过程演示图,向左扩展为比特“0”扩展,向右为比特“1”扩展,实线箭头表示被激活的路径,虚线则表示未被激活的路径,节点下方的数值为当前路径的PM值。与SCL算法中通过对多条路径同步扩展的策略不同,SCS译码算法仅对堆栈中的最优路径进行扩展,其余候选路径存于堆栈中。相当于将整个搜索过程合理“串行化”,这样做的最大好处在于可以节省大量的不必要的路径搜索,降低计算复杂度。
SCS译码过程中涉及两个重要参数,堆栈深度和搜索宽度,分别用D和L表示,两者都对SCS译码算法的性能起到重要影响,堆栈深度D表示最多能保留下来的候选路径数量,而搜索宽度L则表示等长路径可以保留的最大数。
译码器在接收到信息矢量y1N解调后得到长度为N的LLR值矢量用L1N=[L1,L2,···,LN]表示。另外,用bi1=[b1,b2,···,bi]和ci1=[c1,c2,···,ci]表示当前译码的最优路径矢量和一个计数器矢量,用于记录在堆栈中同等长度的路径数量。堆栈中当前存储的路径数量为s,完整的算法流程如算法1所示。
1.3 算法复杂度分析
SCS译码算法的时间复杂度取决于当前信道的S NR值,但是相较于SCL译码算法,SCS译码算法避免了大量的不必要的路径扩展,特别是在高SNR的场景下,时间复杂度可以减少至O(Nlog2N),而SCL的时间复杂度为O(LNlog2N)。在低SNR的情景下,SCS译码算法的时间复杂度至多为O(LNlog2N)。
而对于空间复杂度来说,SC译码算法的空间复杂度为O(N), SCL和SCS的空间复杂度分别为O(LN)和O(DN) 。 一般情况下D>L,所以SCS相较于SCL拥有更高的空间复杂度。
在现有的SCS译码算法的硬件实现架构中,在路径排序部分,通常使用双堆栈结构进行路径排序与路径选择,一个作为候选路径存储的堆栈,另一个则作为排序过程中临时存储的数据,通过遍历堆栈中原有路径与新路径逐一比较的方式进行排序。这种排序方式在一个时刻内只能进行一次比较,效率较低,特别在堆栈存储数据量大时会造成大量时延,在最坏的情况下,排序的时延等于2D。
2SCS译码器的硬件架构
为了优化上述所提到的问题,本文提出一种新的SCS译码器硬件架构,如图3所示,总共包含4个模块:SC译码单元(SC Decode Unit) 、路径度量单元(Path Metric Unit) 、路径选择单元(Path Selection Unit)和控制单元(Control Unit) 。下面对主要单元进行进一步详细说明和介绍。
2.1 SC译码单元
SC译码单元主要包含:LLR存储器、部分和更新模块和计算单元模块。信道LLR值经过定点量化后存入LLR存储器中,在进行递归运算时根据当前路径长度读出相应LLR值。根据SC译码算法原理,SC递归运算主要包含f运算和g运算。在硬件实现中,将这两种运算功能合并成一个模块,成为运算单元(Process Element, PE) ,如图4所示。
图4中,上半部分实现f运算功能,下半部分实现g运算功能,LA, LB为LLR值输入,P_SUM为部分和值。在进行LLR递归运算时。根据选通信号FG_SEL来决定选通具体运算功能。在硬件实现中的LLR值需要经过定点量化,由于量化位宽有限,在计算完成后必须对LLR值进行溢出判断以及数据溢出后的操作。因此在计算单元中引入饱和截断功能,使得LLR值在溢出后数据固定量化为最大值,从而保证LLR值的符号不会失真。判定原则如式(8)所示,其中Lg为g运 算后的LLR值结果,Lmax为预设最大值。
在递归运算结构上,基于硬件开销与运算时延的综合考虑,本文使用半平行架构实现递归运算,其结构示意如图5所示。
图5以码长为8的递归运算结构为例,左侧CH_LLR为初始LLR值,右侧MID_LLR则为中间运算的LLR值。根据SC译码算法的递归运算原理,层内并行运算,所以每个周期内最多有N/2个PE被激活。然而继续分析可知,仅有在uˆ1和uˆN/2时才会有N/2个PE被激活,其余比特至多激活N/4个PE。所以,N/4个PE已经可以满足绝大部分情况,在uˆ1和uˆN/2索引位置上,对N/4个PE复用两次即可实现相同效果。这种结构在时延上比传统平行结构多出两个周期的时延,却可以将PE数量减少50%。
传统的部分和模块都是对前一比特的部分和数据进行暂存,在暂存的部分和数据的基础上进行更新,并且这种策略每一层数据都依赖上一层的更新结果,在策略上无法实现层间并行。同时,根据SCS译码算法的特点,SCS译码算法在译码过程中由于路径不等长,存在路径回溯的情况,所以该策略不适用于SCS译码。本文的部分和更新中,利用当前最优路径的PV值,直接对下一索引的部分和进行更新,不再对前一索引的部分和数据进行暂存。同时在层间使用组合逻辑的方式进行运算,充分利用硬件的高并行性的特点,实现层间并行运算。图6为N=8的部分和更新模块,左侧ESI_U0~ESI_U7为输入PV值,PATH_LEN为路径长度值,PS_OUT为部分和输出,部分和输出选择器根据当前PL值来判断输出的对应长度值。
2.2 路径选择单元
在经过路径值度量单元对路径进行扩展及计算出对应的PM值后,两条新路径将被输入至路径选择模块,向“0”和“1”扩展的两条新路径分别用PATH0和PATH1表示。路径选择单元包含候选路径存储器组和路径选择模块,每条候选路径都包含3种信息:路径度量值PM、路径值PV及路径长度值PL。在传统的路径选择单元中,每条候选路径的这3种信息会被打包然后送入堆栈中。在进行路径选择时,根据SCS译码原理,进行路径选择操作仅需要使用PM值数据。然而因为数据在堆栈中被打包的缘故,所对应的PV值及PL值都会被读出,造成了大量的不必要读写,增加了路径选择过程中的复杂度。针对这一问题,本文中的路径选择单元对这3种不同的信息进行单独存储,通过统一的地址读写控制来保证其信息的对应性。而在进行路径选择过程中,仅需要对PM值存储器进行单独的操作即可,在最后完成路径选择后才对其余对应的PL值和PV值进行读出,减少了在中间过程中大量不必要的读写。
在路径选择模块中,本文采用分组单调排序与并行比较相结合的方式。这种方式相较于传统的SCS译码器效率更高,其结构图如图7所示,在完成新路径写入后,将度量值存储器中所有PM值读出,读出的PM值与所对应的地址值拼接,送入路径选择模块中。在s<D-1时,路径选择模块仅返回最优路径地址,用POP_ADDR表示。而当存储器组即将存满或已经存满,即s≥D-1时,地址控制模块使能路径值选择模块中的最劣路径选择功能,此时路径选择模块返回最优路径地址与最劣路径地址。最劣路径即PM值最大的路径,在存储器存满的情况下,最劣的路径成为最优先被淘汰的路径,用DEL_ADDR表示。
新路径写入存储器组的策略分为存储器存满和未存满两种情况,如图8所示。图8(a)为未存满情况下的存储策略,由于每次路径选择完成后,最优路径必然读出,这就意味着该最优路径POP_ADDR地址在下一次译码时处于空闲状态,所以将POP_ADDR作为下轮译码中PATH0的写入地址。同时定义一个计数器指针CNT_ADDR,该指针一直指向最小的空闲地址,该地址作为PATH1的写入地址,将PATH1按顺序存入存储器,直至存储器存满。而在存储器即将存满时,如图8(b)所示,地址控制器将使能路径选择模块中的最劣路径选择功能,此时路径选择模块则会返回两个地址值:最优路径地址POP_ADDR和最劣路径地址DEL_ADDR,设上一个译码周期返回的最优地址和最劣地址分别为a1和a2。PATH0依然以POP_ADDR作为写入地址,PATH0写入a1。而CNT_ADDR由于存储器存满后将失效,所以此时应使用DEL_ADDR作为PATH1的写入地址,PATH0写入a2。通过直接覆盖原有的最劣路径数据的方式实现PATH1的写入与最劣路径的淘汰。
3 实验结果及分析
在硬件实现上,本文所有硬件设计均在Xilinx系列xc7v585tffg的FPGA平台中进行,时钟频率Fclk设定为200 MHz。对码长结构(N,K) =(256, 128) 进行实现,堆栈深度D=64和搜索宽度L=16。并对文献[17]的架构在同样码长下在同平台进行复现对比,码率R均为0.5。均使用高斯近似(Gaussian Approximation, GA),仿真场景使用加性白高斯信道模型,并使用二进制相移键控(Binary Phase Shift Keying, BPSK) 调制方式。
3.1 基于MATLAB的LLR值量化分析
由于LLR值为浮点数,在硬件实现中都需要将数据进行定点量化才能进行处理,而具体的量化方案将直接影响到硬件的性能以及硬件开销,所以在方案上需要做出合理的选择,使得硬件开销和性能损失都在可接受的范围内。
用 (Qc,Qf)表示初始LLR值和小数位的量化位宽。图9为 SCS译码算法在比特信噪比(Eb/N0) 在1~3.5 dB范围内,不同量化方案下的误比特率(Bit Error Ratio, BER) 对比,对(8,1) 、(8,3) 、(6,1) 、(6,3) 这4种量化方案进行性能仿真对比。通过(Qc,Qf)=(8,3)与(Qc,Qf)=(6,3)的对比,两者小数位宽相等,而整数位宽被压缩造成了 (Qc,Qf)=(6,3)的性能损失明显,所以整数位宽应当设定为大于等于5 bits。而(Qc,Qf)=(8,3)和 (Qc,Qf)=(6,1)拥有等长的整数位宽,小数位宽的压缩并未造成明显的性能损失。最后对比(Qc,Qf)=(8,3) 和 (Qc,Qf)=(8,1)可以说明整数位宽大于5 bits的情况下没有明显增益。因此,基于性能和资源开销综合考虑,本文选择 (Qc,Qf)=(6,1)作为最后的量化方案。
3.2 基于FPGA的硬件平台仿真
本文所提出的硬件结构资源消耗如表1所示。与文献[17]相比较,本文译码器整体资源消耗在查找表(Look Up Table, LUT)、寄存器(Register) 和块随机存储器(Block Random Access Memory, BRAM) 上分别减少了24.06%、56.42%和39.29%。特别地,将路径选择模块与部分和模块的资源消耗进行单独比较,本文的方案在路径选择模块上,LUT和Register平均多出40.65%和18.32%的开销。然而在部分和模块中,本文的方案在LUT和Register则平均减少了7.68%与77.98%的开销,并且由于没有使用到存储模块,因此BRAM消耗为0。在吞吐率方面,根据译码器吞吐率公式:
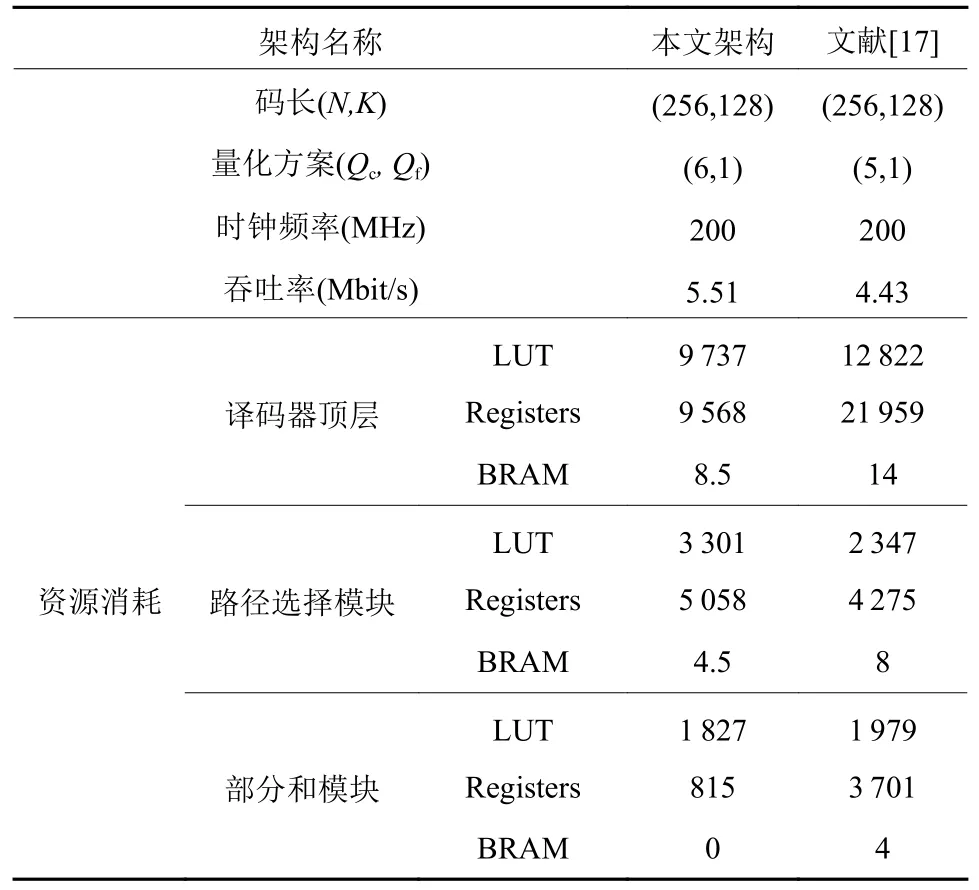
表1 不同架构的性能对比情况Table 1 The comparisons of different structures
在200 MHz的工作频率下,本文译码器的平均时延为0.046 ms,因此在此情况下吞吐率T=256/(0.046×10-3)=5.51 Mbit/s,相较于复现的译码器提高了约24.38%。
除了硬件性能外,本文进一步验证了译码器的纠错性能,图10为本文设计的SCS译码器与同码长的SC译码器在硬件实现和MATLAB仿真中的误比特率性能对比。其中黑色线为MATLAB的仿真结果,其余为FPGA实现结果。从结果对比图可得知在FPGA上的实现与仿真结果相近,这得益于量化比特数的合理选择,从而在实现过程中未造成明显性能损失。而对比SC与SCS的FPGA实现结果可知,相较于SC译码算法,本文所提出的SCS译码器有0.6 dB的性能增益。
图1 SC译码过程图Fig.1 The process of SC decoding
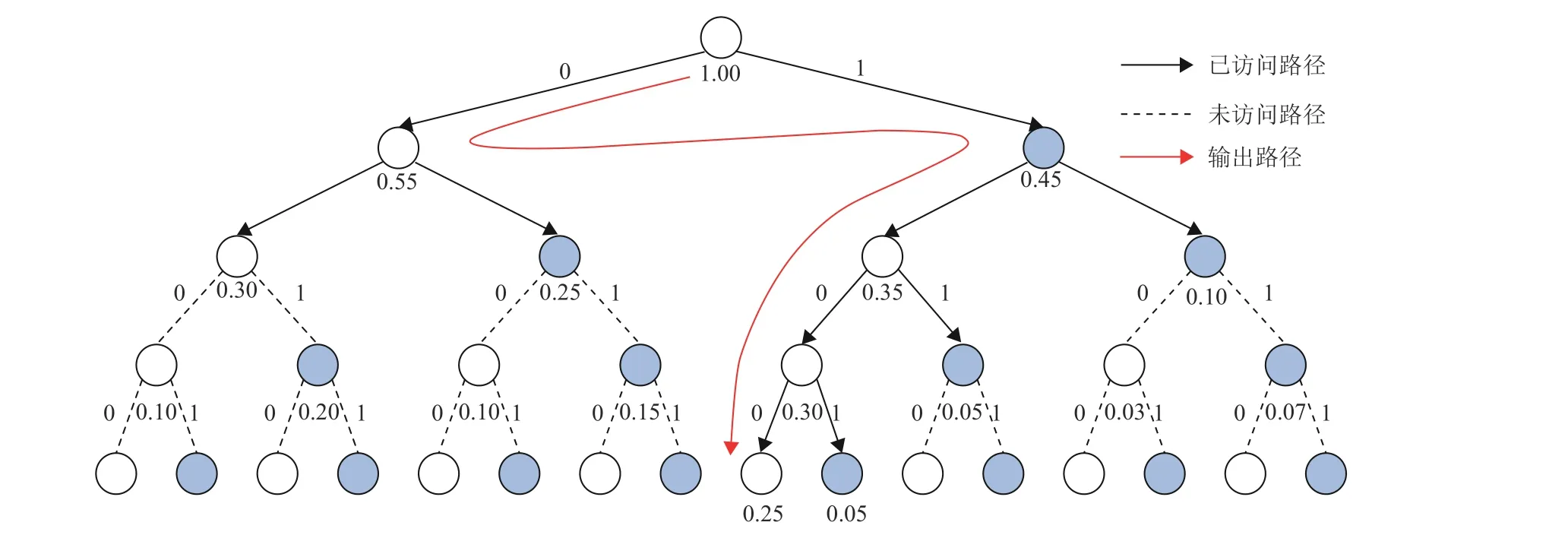
图2 N=4下SCS译码流程图Fig.2 The process of SCS decoding with N=4
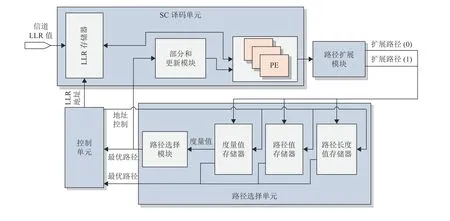
图3 SCS译码器顶层架构Fig.3 The top architecture of SCS decoder
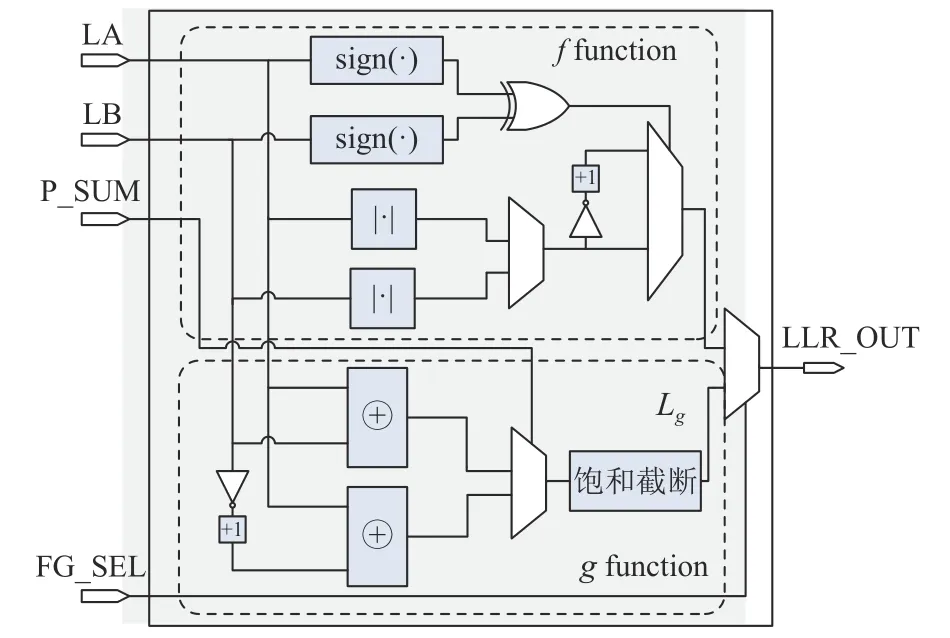
图4 PE运算单元Fig.4 The architecture of PE

图5 N=8半平行结构Fig.5 The architecture of semi-parallel with N=8
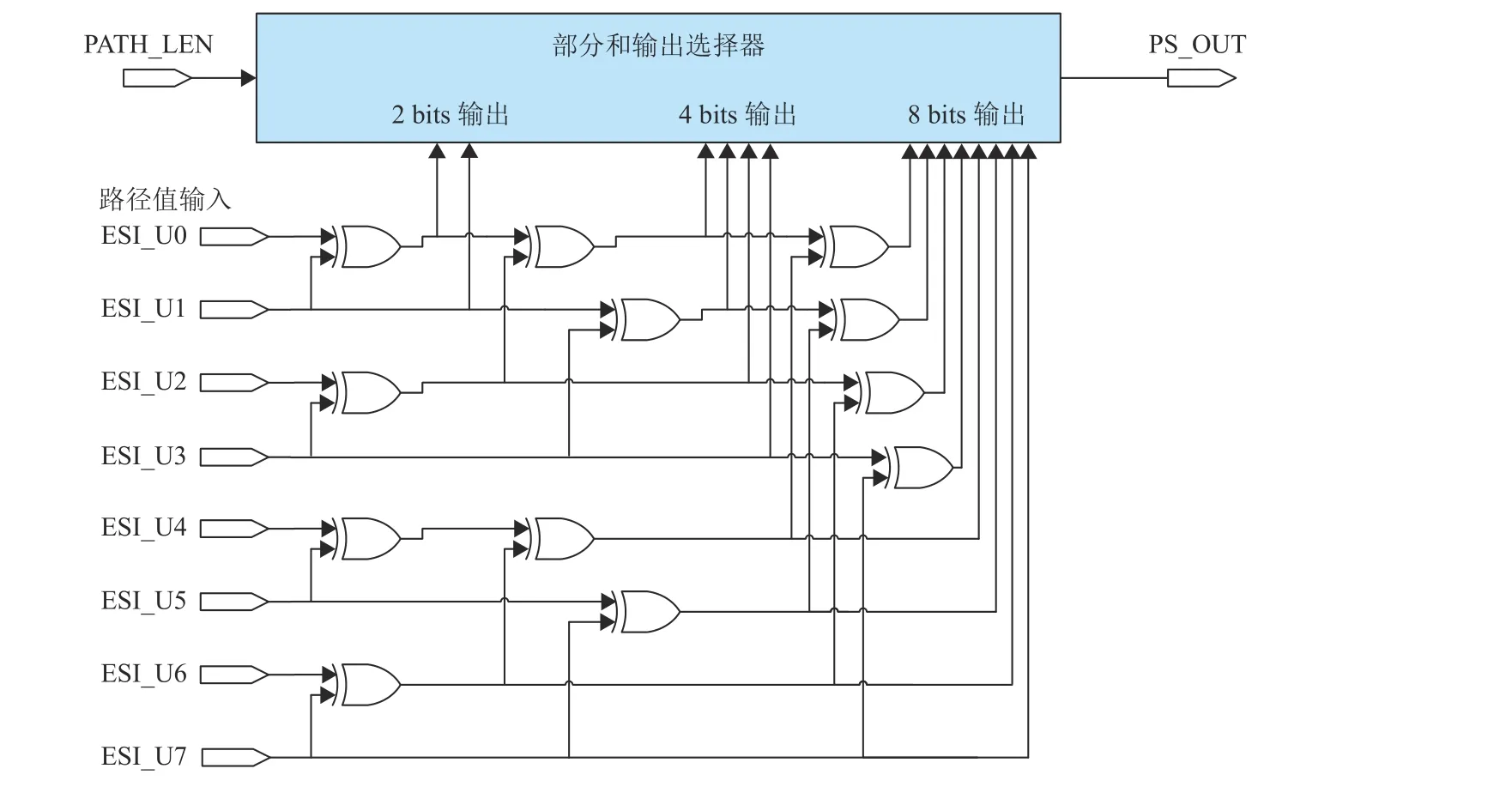
图6 N=8 的部分和更新模块Fig.6 The architecture of partial sum module with N=8
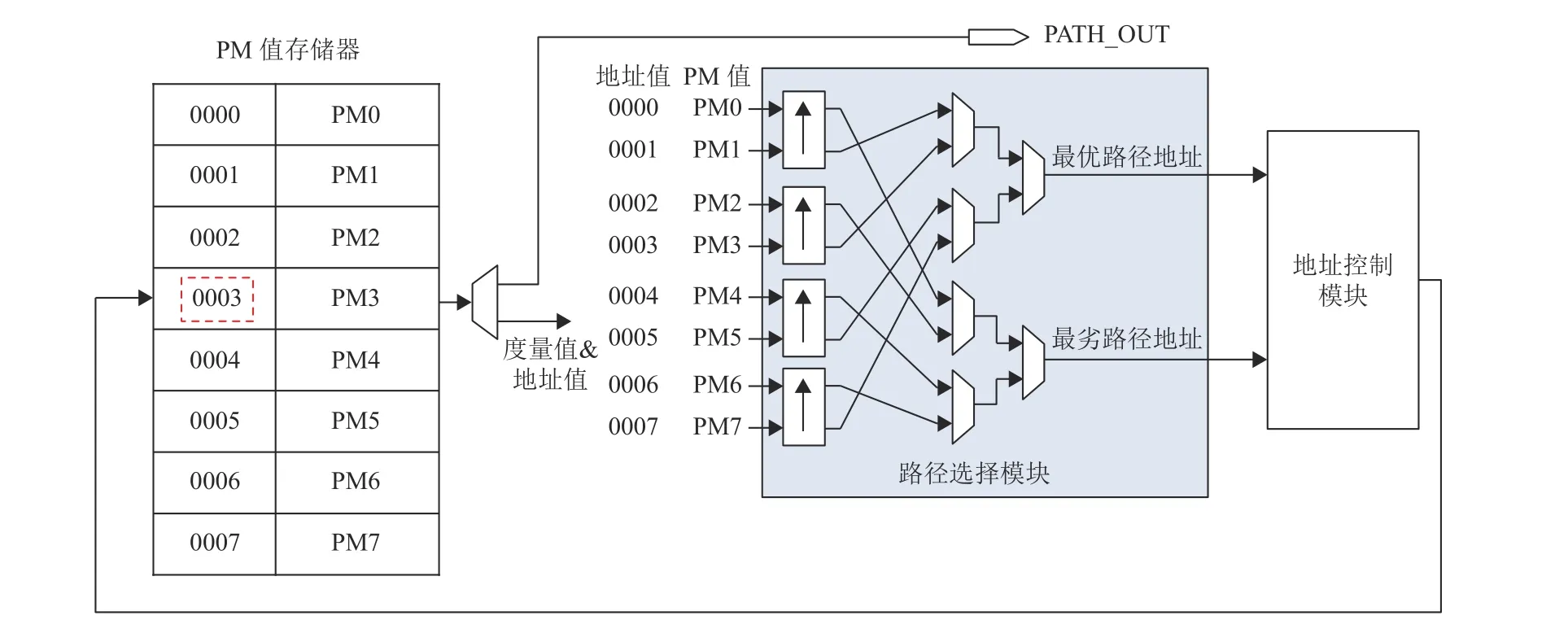
图7 路径选择模块结构图Fig.7 The architecture of path selection
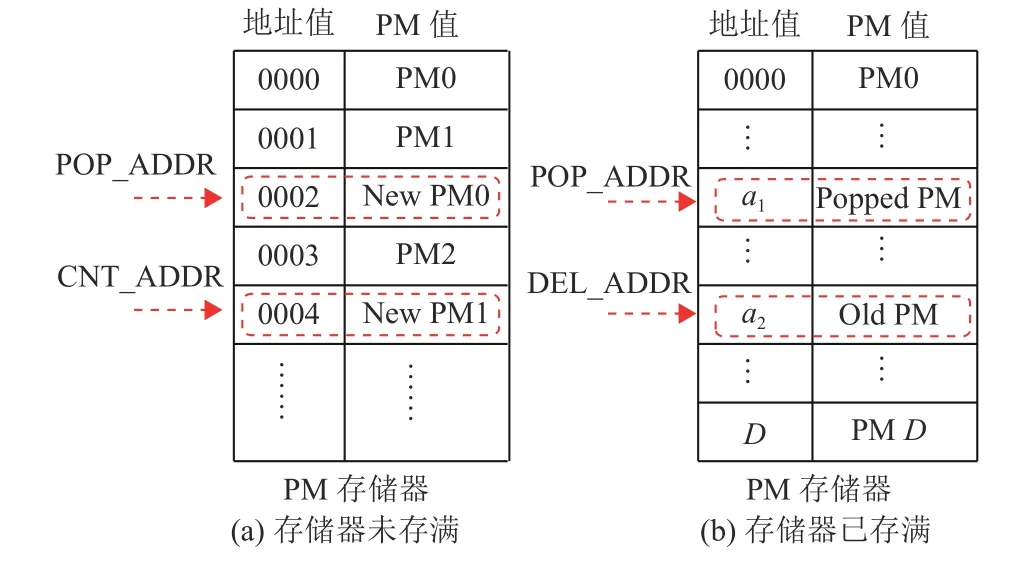
图8 路径写入策略示意图Fig.8 Examples of paths writing strategy
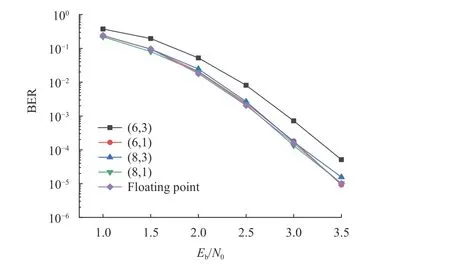
图9 在不同( Qc,Qf)下的BER比较Fig.9 The comparisons of BER with different(Qc,Qf)
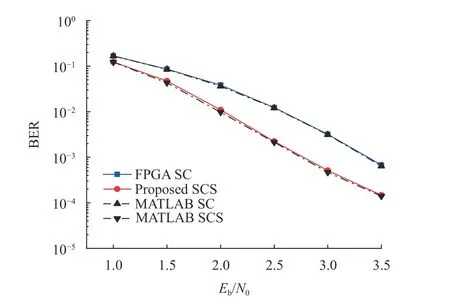
图10 SCS译码器与SC译码器码长为(N,K) = (256,128) 性能比较Fig.10 The comparison of SCS and SC with (N,K) =(256,128)
从硬件平台实现结果看出SCS译码器在性能上明显优于SC译码器。同时合理的量化比特选取也使硬件实现中的性能损失非常小。
4 结论
本文主要针对SCS译码器的路径选择模块提出了一种新的架构,从而提升路径选择模块的性能。通过硬件实现验证,本文所提出的架构通过对堆栈存储策略的改善,不同种类的路径信息读写变得更加灵活。在路径选择上利用分组单调排序与并行比较相结合的策略使得最佳路径搜索更加高效。另外,在部分和模块中本文提出用路径值实时计算部分和的方法,部分和反馈更加高效,充分利用了FPGA强大的并行性。实验结果表明,本文中所提出的硬件架构的整体资源消耗降低且吞吐率有小幅提升,在路径选择模块中需要更多的LUT和Registers,但在部分和模块中需要更少的资源。同时,本文提出的结构纠错性能优于SC译码器并与SCS译码算法的理论结果接近。
然而,SCS译码器在低SNR时会频繁出现路径回溯现象,这一现象主要由LLR量化精度损失所造成。文献[20]中所提出的通过算法模型来动态调整量化参数的策略具有一定启发性,在SCS译码中根据SNR与PL值通过一定算法来动态调整量化参数也许可以进一步提升译码器性能。
