融合标签语义嵌入和图卷积的短文本特征扩展及分类方法
2024-03-04李荣臻
张 灵,李荣臻,郑 苏
(1.广东工业大学 计算机学院, 广东 广州 510006;2.宁夏大学 教育学院, 宁夏 银川 750001)
随着众多社交媒体平台的蓬勃发展,如新浪微博和微信等被大量用户使用。社交平台带来的便利丰富了用户生活,但短文本数据也在疯狂地增长。因为短文本有着易于阅读、内容简短的特性,能提取的特征也比较稀疏且很容易不准确,如何更好地处理短文本数据,挖掘其中存在的商业价值是长期被关注的焦点,因此,对海量数据进行正确分类有一定必要性。
在文本分类任务中,有很多人为了更好地捕获文本语义信息,使用循环神经网络[1]、长短期记忆网络[2]、门控循环单元[3]和卷积神经网络[4]等结构,如长短期记忆网络能够根据文本数据的序列关系建模,把生成的新特征作为文本的最终特征投入训练任务进行学习。类比图像处理方法,Kim[5]使用卷积来捕捉文本内部单词间的局部语义关系,将最后一层网络的特征代表整个文本特征进行预测分类任务。近年来,图卷积网络(Graph Convolution Network,GCN)[6]在处理文本任务上的出色能力受到广泛关注,是一种可以通过连接节点的边传递信息来捕获图节点之间的全局依赖关系[7]的模型。Kipf等[8]提出的基于图卷积进行半监督分类方法,正式成为GCN的开山之作,之后Yao等[9]正式将GCN用于文本分类,取得了很好的效果。由于图结构的特性相对于传统神经网络模型更有利于文本处理,词节点能够通过不同的搭配来学习更准确的表示。
虽然图结构能通过捕获长距离词节点交互,但直接应用于短文本分类时,性能也会不可避免地下降,这是因为短文本分类中的瓶颈问题就是文本中的关键词存在严重的稀疏性和特征表达模糊。
针对上述问题,本文首先为短文本数据集构建了一个包含局部及全局关系的大型文本图,其中包含作为节点的文档和单词,考虑到单词对整个数据集的重要性,对于文档节点和单词节点的关系权重,在传统算法上做了改进;之后考虑到文本与标签存在的语义相关性,构建了特征空间对文本进行特征选择,将得到的新特征嵌入到文本图中的文档节点,增强了文档节点的特征表示,单词节点则利用了预训练模型捕捉上下文语义学习得到,有效地缓解了短文本存在的语义表达不充分、模糊的问题。
本文的贡献概括如下:基于传统的词频统计(Term Frequency-Inverse Document Frequency,TFIDF)算法,提出了改进方法来定义文本图中文档节点和单词的关系,重新考虑了单词对所属文本及全局语料库的重要性。提出了融合标签语义嵌入的图卷积网络的方法,利用文档与标签存在的近义关系进行特征选择,联合标签语义和提取的近义词嵌入作为文本图中文档节点特征表示。根据4个英文短文本数据集上的实验结果显示,本文提出的方法与对比模型相比,达到了最好的分类效果。
1 相关工作
文本分类是自然语言处理(Natural Language Processing,NLP) 的一项核心任务,主要体现在文本特征表示和分类模型上,已经被用于许多现实应用,如垃圾邮件检测[10]和意见挖掘[11]。有很多深度学习模型被广泛应用于文本分类,但在长文本数据分类领域上效果相对更好,短文本分类上未能得到特别满意的效果。
针对短文本特征不足的问题,Bouaziz 等[12]用维基百科语料训练主题模型,然后通过得到主题以及主题在词语上的分布来作为扩展短文本的语料库,之后用来进行特征扩展的选择。方澄等[13]为了丰富微博数据的特征,将数据集中的表情和颜文字等按照设置的词表进行替换,但是纯文字形式的句子存在无法扩展的局限性。崔婉秋等[14]在利用微博数据做搜索任务的研究中,使用了超大型的知识密集型网络仓库,将短文本标题生成一些相关的地点、时间或事件等关键词词集来扩展特征,以达到用户能够搜索到更多相关话题的目的。Wang等[15]提出了标签嵌入注意模型,该模型将标签和单词引入到同一个联合空间中,使用注意力机制[16]作为标签与单词向量沟通的桥梁进行文本分类。张万杰[17]用一维卷积取代了Wang等[15]模型中的注意力机制,并去掉了之后的加权求和,使文本内每个词表达独立化,用于多标签文本分类的预测任务。
以上方法一定程度上虽能对短文本的稀疏特征有所优化,但其效果主要还是受外部语料库质量以及只能捕捉到文本局部特征的影响。
最近,图神经网络[18]的研究热潮引起广泛关注,在短文本分类任务中,首先将文档数据转为图数据,不仅包含着文本局部信息,还包含了多文档之间的全局信息,获得了较好的效果。之后郑诚等[19]提出将双项主题模型应用于短文本数据,把训练出的文档集潜在主题作为一种节点嵌入到图结构中用于辅助分类。辛媛[20]根据数据集分别构建了包含整个数据集的文本图和将文本图拆解后的子图集两种文本图,分别使用同构图神经网络和异构图神经网络算法进行文本分类。申艳光等[21]针对文本分类任务中标注数量少的问题,提出了一种基于词共现与图卷积相结合的半监督文本分类方法,用词共现方法统计语料库中单词的词共现信息并采用了过滤。郑诚等[22]针对文本上下文信息和局部特征不足的问题,提出了利用双向长短时记忆网络和卷积神经网络提取文本信息丰富图卷积网络的文本表示。除了利用词共现关系,为了探索来自不同类型图的异构信息的效果,Liu等[23]提出的文本图张量模型还引入了语义与句法关系,由此构建了3种规则下的文本异质图,分别经过图卷积网络学习单图中节点的信息后再聚合特征,效果相较于只使用共现图有所提升,但是这种多图的方式同时也占用了很大的存储资源。
随着图神经网络的发展,陆续出现了通过改变网络内部结构和计算方式的一些图神经网络的变种。Wu等[24]提出了简化的图卷积模型,消除了隐藏层之间的激活操作,将中间过程转换为简单的线性变换。Zhang等[25]提出的归纳型图卷积模型,减少了模型学习过程中的遗忘,将门控机制添加进图神经网络[26]来学习文本图信息。也有人认为不同的节点具有不同的影响力,提出采用一层前馈神经网络来计算节点间注意力分数作为节点间的邻接权值的图注意力网络(Graph Attention Networks,GAT) 模型[27],由于单层注意力关注力度不够,Ding等[28]提出了超图注意力网络模型,使用双重注意力机制的方式学习文本图上的多方面的特征表达,其中,模型使用的归纳型文本图一定程度上减少了计算消耗。
以上方法在短文本分类上都取得了很不错的效果,但是只考虑短文本自身特征是不够的。区别于其他图神经网络在文本分类上的研究,本文首先在建模数据集时,综合考虑了文档与单词之间和单词在全局语料库中的重要性,改进了文本图边权值的计算方式;然后利用文本与所属标签之间存在的相关性信息,对所有训练集对应的文档节点做特征增强,在更新了文本图的信息后再送入模型中去;最后,学习Lin[29]的做法,结合预训练模型和图卷积网络模型学习到的特征做分类预测。
2 基于标签语义嵌入的图卷积网络
最初定义的图神经网络,是通过边连接来捕获图节点之间的信息。因此,在图神经网络训练工作中,需要将数据集转为一种图数据的形式,文本数据可以根据各文档之间的关系来构造一个文本图。
整体实现流程主要包括文档-单词共现文本图的构造、标签信息的嵌入、短文本特征扩展,整体流程如图1所示。
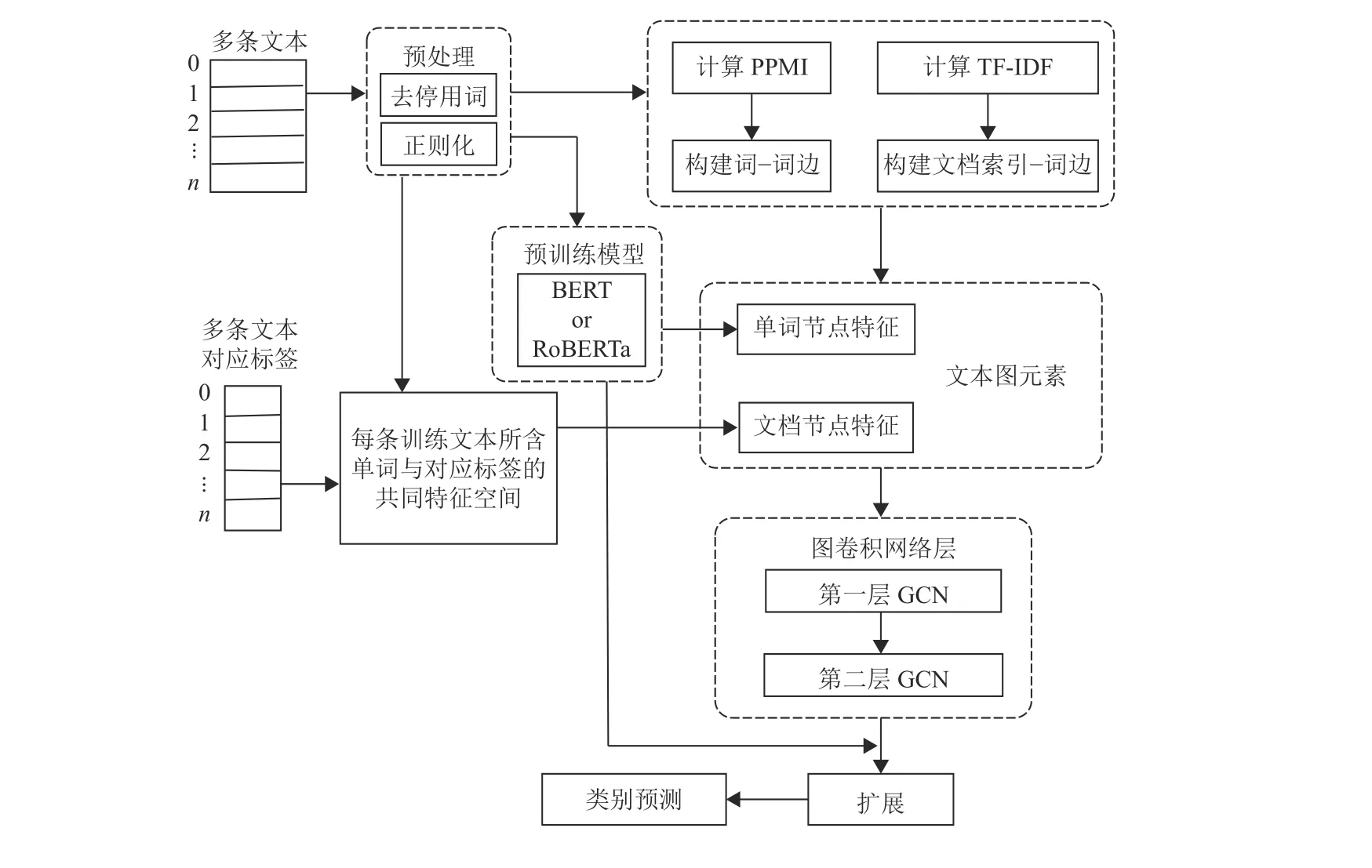
图1 融合标签语义嵌入和图卷积的短文本特征扩展与分类的整体框架Fig.1 The whole framework of short text feature extension and classification based on semantic embedding and graph convolution
2.1 文档-单词共现文本图的构造
图神经网络的数据输入是一种图数据,因此需要根据数据集构造文档-单词文本图,图中包含文档节点和单词节点,文本构图的方法首先会参考TF-IDF和正点互信息(Positive Pointwise Mutual Information,PPMI) 算法。
对于构建单词与单词之间的关系,PPMI与点互信息(Pointwise Mutual Information,PMI)都使用词关联度量来计算单词与单词之间的相关程度,并将其作为单词与单词之间的边的权重,两个单词之间的PMI值越小,说明单词对的语义关联度就越低。PPMI为避免出现负无穷的情况,执行判断最大值的操作,将小于0的PMI值都设为0。
在构建文档与单词之间的关系时,传统的TFIDF方法中,单词的重要性会随着它在文本中出现的次数呈正向增加,但也会随着它在整个数据集中出现的频率反向下降,往往不能有效地反映单词的重要程度和特征词的分布情况。对于短文本数据来说,这种判断并不是完全正确的,而且还会存在关联特征丢失的问题。因此,为了降低语料库中同类型文本对单词权重的影响,提出了词频统计加权(Term Frequency-Inverse Document Frequency- Weighting,TF-IDF-W)方法,一定程度上解决了权值过小的问题,如式(1) 所示。

2.2 标签信息的嵌入
在传统的文本分类模型中,标签信息的使用只出现在输出层之前,构建好的文本图进入图卷积神经网络之前,文档节点使用只含有0和1的one-hot向量作为初始特征,文本图中的单词节点最初没有特征表示,之后本文会通过预训练模型赋予其基于上下文的唯一表达。
在大部分情形下,对全部特征进行采集将会是极其耗时耗力高开销的或者是不可能的,而且有些特征判别性并不强且存在冗余,导致选择的特征不具有较强的代表性,在为节点增加更多邻域信息的同时也会引入与分类无关的噪声信息,影响模型的性能。因而,为了充分利用标签与文本信息,将使用合适的先验数据赋予文本及标签初始特征,之后以更合适的相似度阈值进行近义词性质上的特征筛选及融合,再将新的特征嵌入到文档节点增强特征表达并参与到后续的神经网络训练。这种设定下,只针对可选择的特征进行采集,减少待处理的数据量的同时降低冗余特征的影响,有助于进一步分析处理数据。
为了在相同的向量空间中学习单词和标签,需要得到单词-标签的相似度,利用单词和标签之间的相似性构建另一个新的嵌入向量,即由图1中的每条训练文本所含单词与对应标签的共同特征空间模块得到。
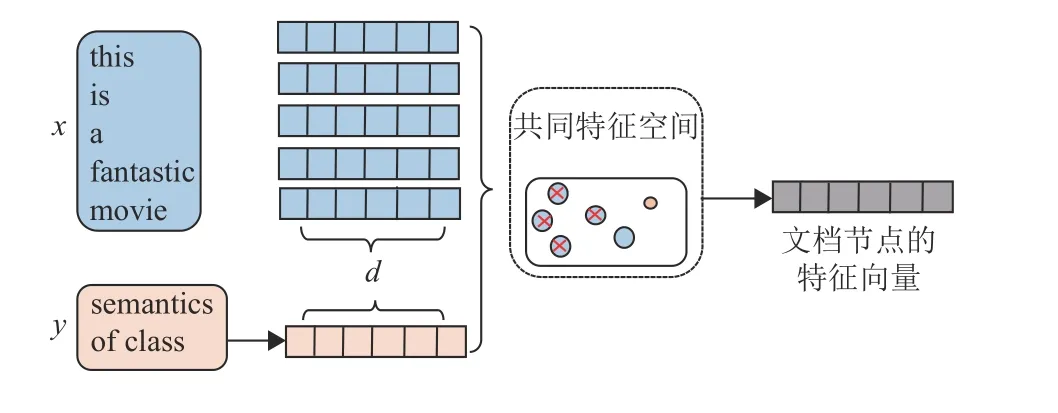
图2 单词-标签特征空间Fig.2 Feature-space of word-label
图2中,首先使用大规模数据集下预训练好的静态词向量包赋予文本内所有单词与标签单词初始特征,之后将文本和标签特征放入共同的特征空间内,近义词性质的特征筛选工作采用注意力机制中余弦相似度的方法。
计算方式概括如下:如某条训练文本可以表示为一个向量集合S(J) ={w1,w2,···,wj},J为某条文本的索引,j为文本内单词索引,取值范围从0到文本长度-1。赋予文本中单词预训练词向量之后,以同样的词嵌入,使用预先训练的词向量赋予标签语义信息,作为初始输入向量集合Y(J) ={Y1,Y2,···,YJ},J的定义同上,wj∈Rd、YJ∈Rd意味着单词和标签特征都是一个d维向量。有些标签是多个单词组成的,数据集“web_snippets”中的一种类别标签,如文化艺术类“culture-arts-entertainment”就是由3个单词组成,这时可以先对3个单词的单词向量取平均值,再作为标签的特征进行表示。在相同的向量空间中得到单词和标签的融合特征的方法如式(2) 所示。
式中:E[c]为第c条文本对应标签的特征向量,Q[c,b]为第c条文本中第b位置的单词的特征向量,similarity()为计算向量相似度的函数,文本内所有单词都要与所属标签向量通过循环语句进行计算,k为相似度筛选阈值,取值范围为[0.5,0.9],超过所选阈值后融合这些特征。最后还需根据聚合的关键词数目,对所得的E[c]采取均值之后再嵌入到文本图中对应的文档节点。
2.3 图卷积网络(GCN)
在图神经网络的应用中,文本数据是以文本图的形式进入图卷积神经网络的。如图3所示,以D为文档节点,以W为单词节点,R(X) 为X经过“hidden layers”的嵌入式表示。为了避免类别之间的混乱,选取了不同颜色装饰。

图3 图卷积内文本图消息传播方式Fig.3 Message propagation mode of text graph in graph volume
第1层GCN的输出特征矩阵计算为
式中:L为输入到图卷积网络的特征矩阵,W(1)为第1层图卷积的权值矩阵,A~为式(4) 中归一化拉普拉斯矩阵,ReLU() 为激活函数。
房地产金融行业健康稳定的发展对整个金融行业的稳步发展有着重要作用,房地产行业的发展又直接影响着房地产金融行业的发展,发展房地产离不开政府的宏观调控政策。所以,政府对房地产行业有力的宏观调控对房地产金融行业发展同样十分重要。然而,当前的政府宏观调控政策与当前的房地产市场发展还存在不适应的情况。如房地产行业相关法规建设还不完善,市场资源配置不够优化,供求两端调控效果存在差异等。这些都在很大程度上抑制了房地产行业的发展,并为其发展带来一定的风险。另外,政府对于房地产金融行业的潜在风险的预判能力还不足,还需要加强对房地产金融市场的有效监管以及其发展状况和趋势的掌握。
式中:A为图的邻接矩阵,D为图的度矩阵,I为单位矩阵,A+I为图中节点增加自连接,A~为归一化拉普拉斯矩阵。
图4中所示的图结构,A为图的邻接矩阵,0和1代表有无连接关系,对应所有节点之间连接信息,D为图的度矩阵,每个数字对应A中行的和,代表着对应顶点的度总数。

图4 图结构、邻接矩阵及度矩阵示例Fig.4 Examples of graph structure, adjacency matrix and degree matrix
第h层GCN的输出特征矩阵计算为

GCN的输出被视为文档的最终表示,然后它被输入到softmax层进行分类。两层GCN的相关计算为
式中:L包含文本图所有节点信息,W(1)为第1层图卷积的权值矩阵,W(2)为第2层图卷积的权值矩阵,A~为式(4)中归一化拉普拉斯矩阵。输入一个GCN模型得到的最终表示会被输入到softmax层,softmax函数表示如式(7)所示。
式中:Z为一个矩阵向量,e,p为元素索引,Zp和Ze都是其中的一个元素,exp() 为指数函数。softmax第一步就是将模型的预测结果转化到指数函数上,这样保证了概率的非负性。为了确保各个预测结果的概率之和等于1,将转化后的结果除以所有转化后结果之和,可以理解为转化后结果占总数的百分比,这样就得到近似的概率。
2.4 特征扩展
本文虽然使用了词频改进算法、嵌入标签信息等方法筛选出最有效的特征,但图卷积神经网络在表示文本时往往会忽略掉单词的上下文信息,而经过预训练模型提取的特征信息,语义上的表达相对会更好,因此,本文参考了Lin等[29]提出的融合不同模型的方法,选择了Bert风格(如Bert和RoBerta)的预训练模型的辅助分类器来优化图卷积网络,然后通过融合多个特征,使得这种网络所提取的特征更具有表征能力,模型也能拥有更好的泛化能力。
最后得到的特征有带标签嵌入的信息、通过图卷积网络得到的ZGCN和Bert风格的辅助分类器获得的输出ZB。为了融合这两个部分,设置了一个平衡参数ε,用来平衡两种特征。
式中:Z'为最终特征,ε=1为只使用结合了标签信息的图卷积神经网络模型,而ε=0为只使用Bert风格的预训练模块。当ε∈(0,1) 时能够平衡不同方法的预测。最终输入结果为经过式(7) 的激活层之后再利用损失函数计算的损失,模型所用的损失函数为交叉熵损失函数,具体如式(9) 所示。
式中:b'为批次的样本数,i',j'为序列号,n'为类别数,T为相应的标签指示矩阵,Z'为来自式(8) 的结果,softmax为激活函数。通过计算神经网络每次迭代的前向计算结果与真实值的差距,指导下一步的训练向正确的方向进行。
3 实验
3.1 数据集
本文在4个英文数据集上分别进行了实验,参数包括类别、总数、训练集数、测试集数以及平均长度。详细如表1所示。
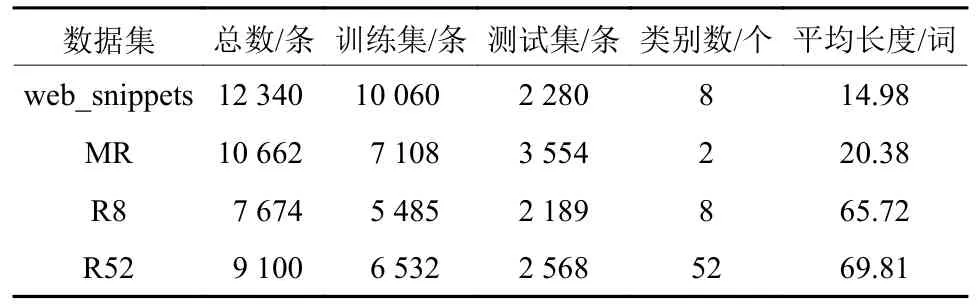
表1 本文采用的数据集Table 1 Datasets in this paper
3.2 实验环境及相关参数
所有的实验是在Inter(R) Xeon(R) CPU E5-2690 v4和P40 GPU上运行,本实验基于PyTorch框架实现,基线模型使用的是相应的原始论文和复现中的默认参数设置。
实验中,Bert类预训练模型学习率为0.00 001,GCN学习率为0.001,dropout率为0.5,平衡参数ε范围为[0,1],epochs范围为[30,50],相似度阈值范围在[0.5,0.9]。
3.3 对比模型
本文所采用的的对比模型包括:(1) 根据共现规则使用图结构的文本分类模型(TextGCN)[9];(2) 基于词共现并结合注意力机制的图卷积模型(Word Cooccurrence and GCN,WC- GCN)[21];(3) 利用双向长短期记忆网络(Bi-directional Long Short-Term Memory,BiLSTM) 和卷积(Convolutional Neural Network,CNN) 丰富GCN的文本表示的分类方法(BiLSTM+CNN+GCN)[22];(4) 通过挖掘文档级潜在主题特征并结合图卷积网络的模型(Biterm Topic Model GCN,BTM_GCN)[19];(5) 采用子图形式的图卷积模型(InducGCN)[20];(6) 插入了标签节点的图卷积网络(Label-incorporated GNN)[20];(7) 构建了含有句法依赖、语义与句法关系的3种异质图的文本分类模型(TensorGCN)[23];(8) 隐藏层之间的激活操作转换为简单的线性变换的图卷积网络模型(Simple Graph Convolution,SGC)[24];(9) 添加了门控机制的图神经网络(TextING)[25];(10) 基于双重注意机制进行归纳分类的超图神经网络(HyperGAT)[28];(11) 采用静态掩码的Bert预训练模型辅助的图卷积网络模型(Bert_GCN)[29];(12) 采用动态掩码的RoBerta辅助图卷积网络模型(RoBerta_GCN)[29];(13) Bert_GAT[29];(14) RoBerta_GAT[29]。
3.4 本文的模型算法
本文提出的融入标签嵌入的图卷积网络模型算法:(1) LBGCN(Label-embedding+Bert Graph Convolution Network) :采用类标签嵌入和Bert预训练模型。(2) LRGCN(Label-embedding+RoBerta Graph Convolution Network) :采用类标签嵌入和RoBerta预训练模型。
3.5 实验结果
表2~表5展示了本文算法与对比模型在短文本数据集上的评估结果,分类的评价标准采用了3种方法:准确率a、召回率r和F1,表中加粗项表示最优结果。

表2 数据集web_snippets测试集上的结果Table 2 Result of web_snippets on test set %
从表2 中可以得出如下结论:(1) 本文提出的模型从3个评估指标整体来看性能最佳。(2) 在所有模型中,SGCN结果表现最差, 可能原因在于激活函数改为线性后,虽然计算速度会有提升,但降低了神经网络的表达能力,不能更好地拟合目标函数,所以不能达到很好的效果。(3) 在考虑标签特征的算法中,LBGCN模型的性能优于BTM_GCN和Label-incorporated GNN,可以看出图结构和特征初始化手段的不同因素对分类效果会有一定程度的影响。(4) 融合了预训练模型的图神经网络的整体性能优于其他模型,证实预训练模型在提取大规模数据集的特征信息上确实具有较强的优势。
表3展示了本文模型和其他对比模型在MR数据集上的表现。从表中可以看出,本文模型通过捕捉文本与文本标签之间存在的近义关系得到新的文档节点的嵌入以及通过预训练模型得到单词节点关系后,再结合图卷积网络的方法,比其他方法获得了更好的预测性能,也显示了其在大规模情感数据集的情感标签关系建模上面也具有一定的优势。另外,从表3中可以看出,加入了BiLSTM和Bert类模型的图卷积神经网络的性能整体优于Text GCN,其可能原因在于序列型神经网络在识别和提取大规模数据集的语义特征上具有较大的优势。
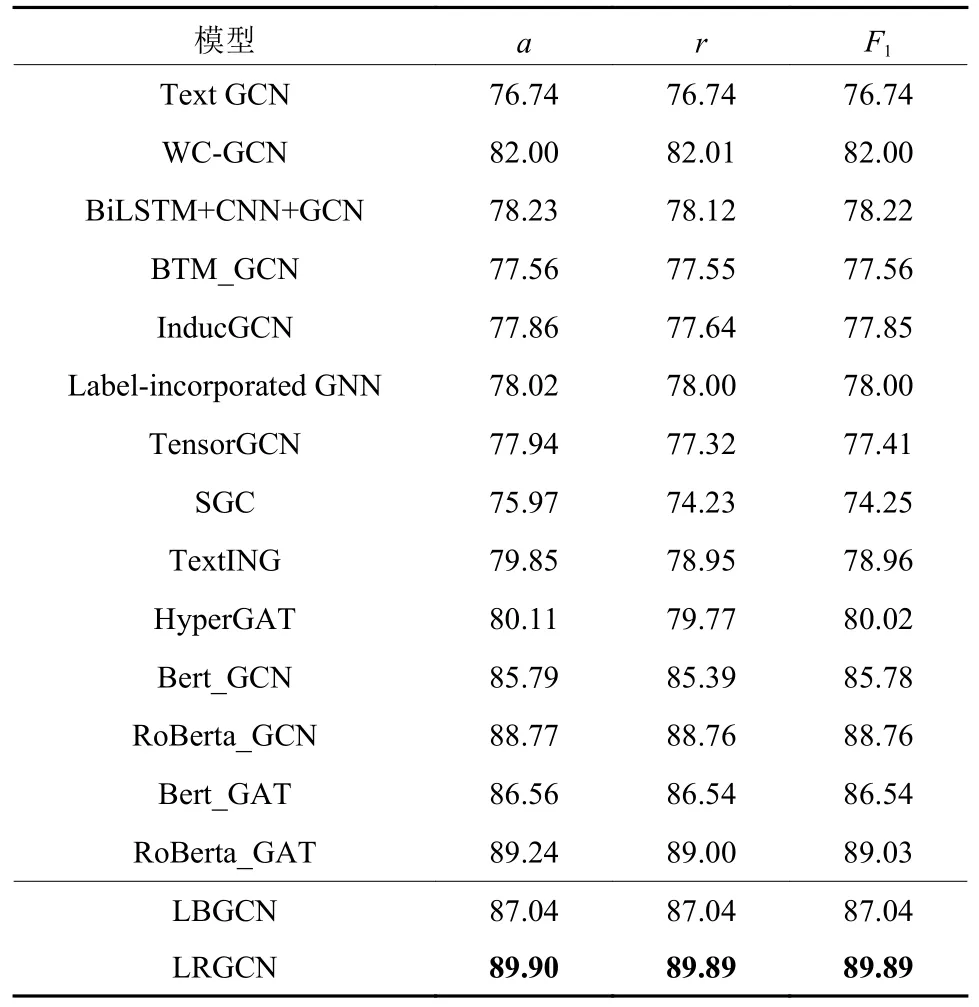
表3 数据集MR测试集上的结果Table 3 Result of MR on test set %
表4展示了LBGCN和LRGCN模型与其他对比模型在R8数据集上的表现。从表中可以看出,相对于前两个数据集,所有模型算法在这个较长的数据集上都能发挥出较大的优势。其中,TensorGCN模型,不同于其他只使用共现规则下的文本图的模型,还基于语义和句法规则另外构建了两种文本图,效果相对于Text GCN较好,但在模型训练上存在内存消耗大以及训练效率变慢的问题,因此,在这3种规则文本图的应用方面值得进一步优化。
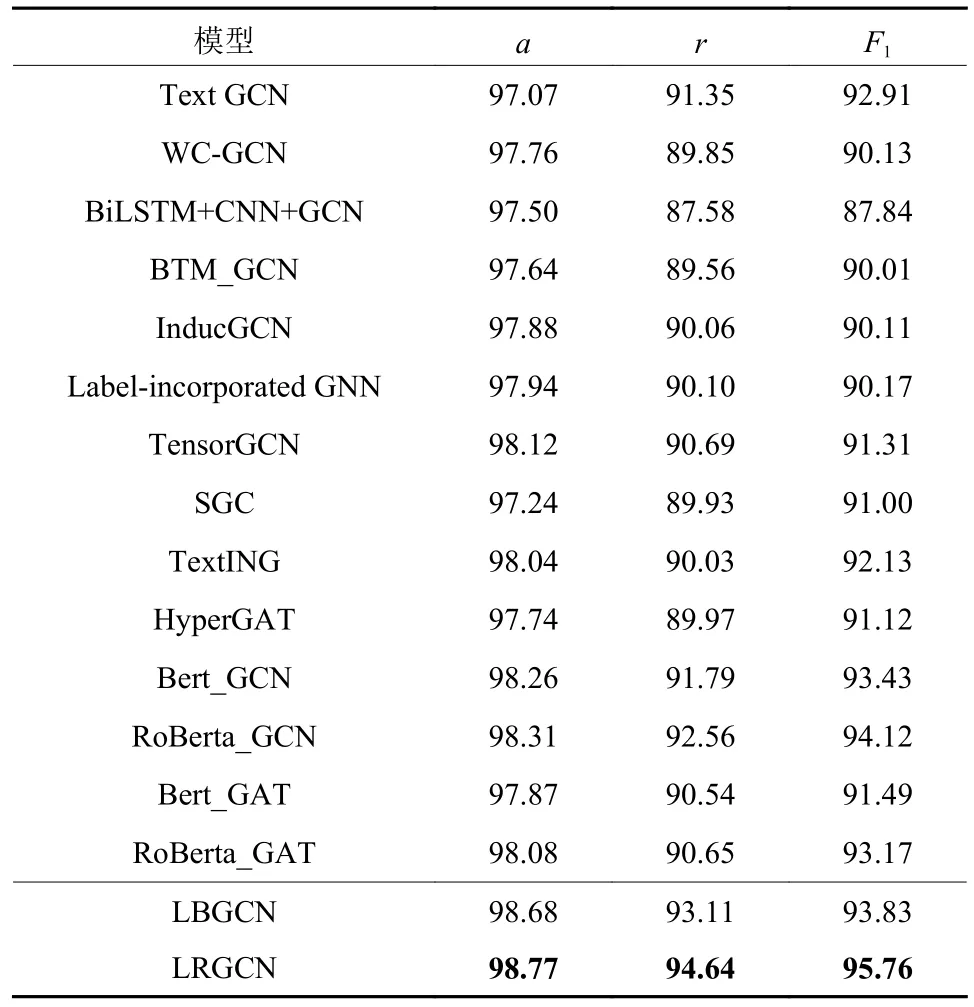
表4 数据集R8测试集上的结果Table 4 Result of R8 on test set %
由表5的数据可以看出,本文提出的模型的分类结果均为最高,并且相较于TextGCN模型有着明显的提升。从评估方法来看,可能因为在所有实验数据集中,R52包含的类别最多以及各类别的数量存在不太均衡或采用数据量较少,虽然数据集平均长度最长,但分类准确率与召回率和F1值一直相差很大。另外,基于图的归纳式文本分类的模型有InducGCN、TextING和HyperGAT等基本都有着不错的结果,归纳式文本图在一定程度上减少了内存的消耗,但由于欠缺对词关系的进一步考虑,性能受到了一些限制。除此之外,HyperGAT使用了基于双重注意力机制的方法,只关注了节点之间的连接关系,并没有考虑边权值初始关系,很大程度忽视了整体文本中的结构特征。通过实验表明,使用了RoBerta模型融合图卷积网络的模型效果普遍比使用了Bert模型的效果要更好,并且在所有的对比模型中达到最好的效果。

表5 数据集R52测试集上的结果Table 5 Result of R52 on test set %
3.6 消融实验
为了进一步验证本文所提出的融入了标签嵌入的图卷积模型的有效性,进行了消融实验,其结果如表6所示,其中“/”表示删除了模型中的该模块。
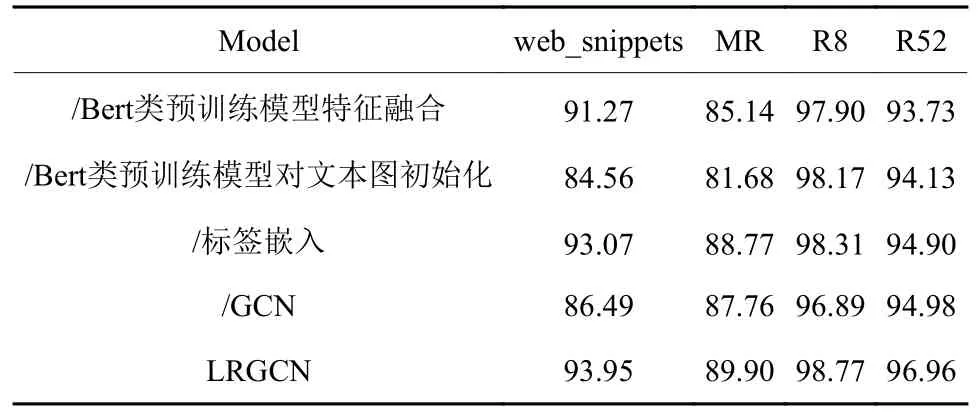
表6 所有数据集在测试集上的准确率Table 6 Accuracy of all datasets on test set %
由表6可知,删除相应模块后的模型的实验效果相较于总模型均存在一定程度的下降,这恰恰说明了模块之间的作用是相辅相成的,从中还可以观察到不同的模块在不同的数据集中有着不同的作用。例如,在不使用Bert类预训练模型和图卷积神经网络模型对文本进行初始化的情况下,基本上都取得了最坏的分类结果。这是因为Bert类预训练模型能够捕获文本的上下文语义信息进而提取到更具体的特征信息,从而帮助模型更好地分类预测。对比消融实验中LRGCN总模型实验和删除标签嵌入实验的结果,可以看出删除标签嵌入实验的准确率比总模型低,引入标签数据模块,在定义相似度阈值以筛选标签与文本特征融合的设定下,可为标签节点选取较优的特征表示并嵌入到文本图中作为网络的一部分一起参与训练,说明了融合多个特征可以取得更好的效果,从而说明了该模块的有效性。
3.7 参数分析
为了探究特征扩展模块中两个不同模型的融合参数ε、图卷积网络层数layer的变化和引入标签特征模块中相似度阈值k对分类效果的影响,以测试集准确率为指标,在各个数据集上,使用LRGCN模型分别进行实验。
图5为平衡参数ε对测试准确率的影响。由图5可知,本文所用方法在不同数据集上,融合参数的最优取值是变化的。例如,对于R52数据集来说,ε最优值约为0.7,表示式(8)中图卷积模块和Bert风格的模块在分类决策中的比例约为7:3。而对于R8数据集来说,其平衡参数ε基本保持不变。说明不同数据集的特征表现不同,但通过使用双信息模型,特征之间的相关性得到了补充,更加具有表征能力。

图5 基于平衡参数变化的测试准确率Fig.5 Test accuracy based on feature fusion parameter changes
图6为图卷积层数layer对测试准确率的影响。在图卷积为2层的情况下,所有数据集上基本都达到最好的效果。随着层数的增加,有数据集的分类效果出现一直下降的现象,原因为训练过程中出现过平滑现象,所有节点与邻域节点会变得特征相似而降低了模型对文本准确分类的能力。
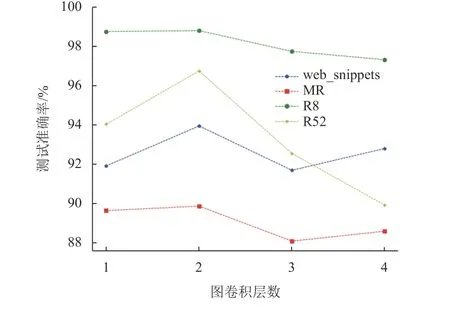
图6 基于图卷积层数变化的测试准确率Fig.6 Test accuracy based on the change of layers number of GCN
图7为相似度阈值k对测试准确率的影响。数据集R8和R52,因为文本内容相对较长,影响波动不大。短文本数据集web_snippets在相似度阈值设为0.7后,模型分类效果达到最好,超过0.7后,训练结果和测试结果趋于零。
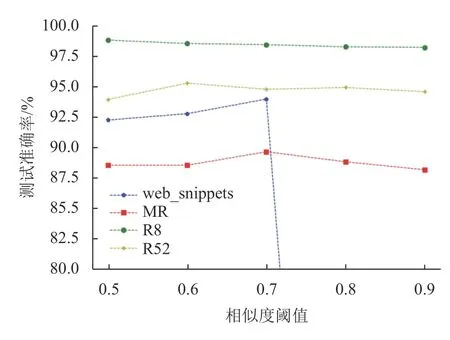
图7 基于标签数据相似度阈值变化的测试准确率Fig.7 Test accuracy based on tag similarity threshold
为了增加模型分类结果的可信度,图8为MR数据集在迭代训练过程中,2种类别在测试集上所得的精确率变化图。随着迭代次数递增,2种类别预测结果不相上下。
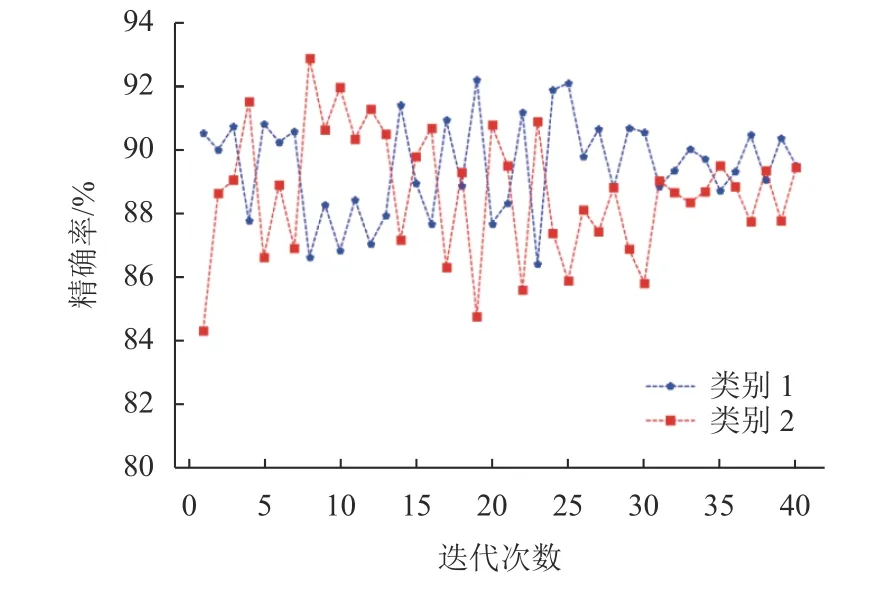
图8 MR测试集中各类别的精确率Fig.8 Precision of two different categories in MR dataset
4 结论和展望
本文提出了一种融入标签嵌入的图卷积网络模型进行文本分类的方法,将所用的数据集构建成一个文档-单词图,从而使文本分类问题转化为一个文档节点分类问题。本文综合考虑了单词对所属文本及全局语料库的重要性,在传统的TF-IDF 算法基础上,提出了新的词频统计方法定义文档-单词的边权值;在不考虑外部资源的情况下,综合考虑标签的贡献,通过计算得到一种近义词嵌入到文本图中,解决由于信息传播导致节点的特征表达变弱的问题,一定程度上减少了节点特征表达的语义模糊性,提高最后文本分类结果的质量,最后使用图卷积网络并选择性地融合预训练模型所得特征,利用有限的有标签文本对无标签文本进行分类预测。
总体而言,本文提出的融入标签嵌入的方法在短文本数据集web_snippets、MR、R8和R52上优于TextGCN、HyperGAT、Bert_GCN、Bert_GAT等分类方法。基于平滑的影响,未来针对文本分类的研究将会考虑在语义层面和更深层的图卷积网络上对文本中更多有价值的信息进一步探索。
