Unsupervised Multi-Expert Learning Model for Underwater Image Enhancement
2024-03-04HongminLiuQiZhangYufanHuHuiZengandBinFan
Hongmin Liu , Qi Zhang , Yufan Hu , Hui Zeng , and Bin Fan ,,
Abstract—Underwater image enhancement aims to restore a clean appearance and thus improves the quality of underwater degraded images.Current methods feed the whole image directly into the model for enhancement.However, they ignored that the R, G and B channels of underwater degraded images present varied degrees of degradation, due to the selective absorption for the light.To address this issue, we propose an unsupervised multiexpert learning model by considering the enhancement of each color channel.Specifically, an unsupervised architecture based on generative adversarial network is employed to alleviate the need for paired underwater images.Based on this, we design a generator, including a multi-expert encoder, a feature fusion module and a feature fusion-guided decoder, to generate the clear underwater image.Accordingly, a multi-expert discriminator is proposed to verify the authenticity of the R, G and B channels, respectively.In addition, content perceptual loss and edge loss are introduced into the loss function to further improve the content and details of the enhanced images.Extensive experiments on public datasets demonstrate that our method achieves more pleasing results in vision quality.Various metrics (PSNR, SSIM, UIQM and UCIQE) evaluated on our enhanced images have been improved obviously.
I.INTRODUCTION
UNDERWATER images are particularly significant for marine engineering and aquatic robotics, which are widely contributed to numerous applications such as marine resource exploration [1], underwater environmental monitoring [2], marine archaeology [3], and more.However, underwater images present varied degrees of color casts due to the selective absorption of water for the light.In addition, underwater images also show low contrast and blur, because of light scattering caused by suspended substances in the water [4].These degraded underwater images lack valid information and severely affect the performance of underwater vision tasks[5]-[7].
To address this challenge, many methods have made efforts.Physical model-based methods [8]-[12] recover the clear image by inverting the imaging model.Model-free methods[5], [13]-[16] directly adjust the pixel values of the degraded image.Nonetheless, they tend to under-enhance or overenhance.In recent years, deep learning has achieved encouraging results on various vision tasks [17]-[20], and researchers have applied it for underwater image enhancement[21]-[25].Although these methods can learn the mapping between the degraded and clear images, they need to obtain a large number of pairs of the degraded image and its corresponding clear one for training, which is difficult in practice and limits the development of deep learning-based methods.To deal with this issue, researchers synthesize paired images artificially [24] or select the best enhanced image manually as the reference image [22], and utilize these paired images to perform supervised learning.However, models trained with synthetic data do not perform well in real-world situations,while using the manually selected image as the reference image usually introduces artificial casts.Inspired by Cycle-GAN [26], some methods [27]-[29] use the cyclic consistency framework to achieve unsupervised underwater image enhancement.Unfortunately, their performance remains unsatisfactory.
Light decays exponentially as it travels through the water[30], [31].Red light with the long wavelength has the weak penetrability and is the first to disappear down to 3-4 meters depth of water.Blue light and green light have shorter wavelengths.Their absorption rates in water are small and the transmission distances are larger.Therefore, the red component of the underwater image is attenuated severely, while the information in the blue and green channels is maintained relatively adequately, as shown in Fig.1.Obviously, the challenges of image enhancement for R, G or B channels are different, while existing methods feed the whole image into the model for learning, treating the three channels equally and neglecting the differences in degradation of different channels.

Fig.1.Visualization of R/G/B channel images.
Based on the above, we propose an unsupervised multiexpert learning model to enhance the underwater image.In detail, for generator, we design a multi-expert encoder that uses multiple experts to extract effective feature representations of the R, G and B channels independently.Then, considering the relevance of the contents among the three channels,the extracted three specific features are further fused by a feature fusion module.Subsequently, this fused feature is fed into a feature fusion-guided decoder to obtain a clear image.For discriminator, in addition to the discriminator to verify the truthfulness of the whole enhanced image, we also introduce a multi-expert discriminator to discriminate whether the R/G/Bchannel image is an enhanced image or a clear one.Compared to existing methods, which treat the degraded underwater image as a whole, we take into account the difference in attenuation rates for different channels, and introduce multiple experts to improve the image quality of different channels independently, enhancing the underwater image in essence.
We summarize the main contributions of this paper as follows:
1) Based on the fact that the attenuation rates of R, G and B channels of the underwater image are different, we propose a multi-expert learning model, which introduces a multi-expert encoder and corresponding multi-expert discriminator to enhance the underwater image channel by channel in an unsupervised manner.
2) We enhance the loss function of traditional unsupervised methods via adding content perceptual loss and edge loss,which retains the content and edge texture effectively and improves the quality of the enhanced image.
3) The effectiveness of the proposed method is demonstrated by comparison with other methods on UIEB [21],UIEB-challenging [21], U45 [32] and UCCS [31] datasets.More importantly, the application assessments show that the enhanced images can significantly improve the performance of underwater visual perception tasks.
The remainder of the paper is organized as follows: Section II provides an overview of underwater image enhancement.Section III details the proposed method.Section IV discusses the results of our method compared to other competing methods, analyzes each key component, and verifies the effectiveness of our method for visual perception tasks.Finally, the conclusions are given in Section V.
II.RELATED WORK
Currently, underwater image enhancement methods can be broadly categorized into three main groups: physical modelbased methods, model-free methods and deep learning-based methods.
Physical Model-Based Methods: The physical model-based methods estimate the transmission parameters and then invert the underwater imaging model to restore the clear image.The classical Jaffe-McGlamey imaging model [33] is expressed as
whereIcis the degraded underwater image,Jcis the expected restored image.Acandtcdenote the global back-scattered light and transmission map respectively, and need to be estimated.
Drewset al.[8] extended the dark channel prior by considering only the blue and green channels, to estimate the parameters of the underwater imaging model.Galdranet al.[9] proposed the red channel prior method to recover the shortwave related underwater image color, which uses the reverse red channel and blue-green channel to obtain the dark channel map.Peng and Cosman [10] estimated transmission map and underwater scene depth based on image blur and light absorption.Considering the strong dependence of underwater light on wavelength, Akkaynak and Treibitz [11] proposed a modified imaging model to remove water from raw images.Carlevaris-Biancoet al.[12] utilized the attenuation difference between the three channels of the underwater image to estimate the scene depth, and then used this estimation to reduce degradation in the image.In general, the results of these methods rely on the imaging model heavily.Whereas, since the underwater environment is complex and variable, it is difficult to fully account for various underwater environments only through theoretical underwater imaging models.
Model-Free Methods: The model-free methods do not consider the underwater imaging process and adjust image pixel values directly to improve the visual effect of the underwater image.Iqbalet al.[13] stretched the contrast to equalize image color in RGB color space, and adjusted the saturation and intensity in HSI color space to increase the true color.Ghani and Isa [14] utilized the Rayleigh distribution to stretch the histogram, which reduces over-enhancement.Ancutiet al.[15] performed color correction and contrast enhancement on the degraded image respectively, and then fused the processed image with the weight guidance map.Similarly, Marques and Albu [5] generated a detail-highlighted image and a darkness-removed image respectively, and further utilized multi-scale fusion to combine them.Fuet al.[16] proposed a Retinex-based variational framework, which enhances underwater images through three steps: color correction, image decomposition to obtain reflectance and illumination, and post-processing for blurring and under-exposure.These methods can improve the image contrast and correct the color cast to some extent.However, they are less robust and prone to under-enhancement or over-enhancement.In addition, they may introduce noise and lose image details.

Fig.2.Overview of the proposed unsupervised multi-expert learning architecture.The top process shows that the degraded image x is transformed to an enhanced one G (x) by generator G, and then through F to the reconstructed image F(G(x)).The image discriminator Dy and multi-expert discriminator Dcy are used for adversarial training.In the figure, yc and xc , c ∈{R,G,B} denote the R/G/B channel of the clear image y and the degraded image x, respectively.Three channel images are input into Dcy to identify the authenticity of each channel.The bottom process is similar for a clear input image.
Deep Learning-Based Methods: Recently, deep learningbased methods have significantly outperformed in underwater image enhancement.It learns the mapping relationship between underwater degraded images and clear images.Generally, these methods can be classified into supervised methods and unsupervised ones.
For supervised methods, Fabbriet al.[24] proposed a generative adversarial network UGAN, introducing L1 loss and gradient loss on Wasserstein GAN basic to realize underwater image enhancement.Liet al.[21] proposed WaterNet, which fuses the results of three traditional image processing methods with the predicted confidence maps to achieve the enhanced result.Considering the diversity of underwater degradation, Liet al.[22] proposed UWCNN, which is designed to enhance various underwater scenes by training with corresponding degraded underwater datasets respectively.To reduce the model complexity, Naiket al.[23] proposed Shallow-UWNet using only convolution blocks and skip connections, which not only maintains performance but also has fewer parameters.More recently, Xueet al.[25] proposed a multi-branch aggregation network to jointly predict the coarse result, veil map, and compensation map to achieve color correction and contrast enhancement.The existing methods either generate degraded underwater images from clear underwater or natural images, or manually select the best results of multiple traditional methods as reference images.When applied to real scenarios, the supervised methods trained on generated data may not work well due to the domain shift.And the model trained by manually selected paired data can produce unexpected artifacts.
With regard to unsupervised methods, the cyclic consistency architecture is usually adopted.Liet al.[27] proposed an unsupervised underwater color transfer model UW-Cycle-GAN based on the cyclic consistency framework and multiterm loss function, which regards underwater image enhancement as a conversion from underwater style to air style.Islamet al.[28] proposed Funie-GAN, using five encoder-decoder pairs with skip connection to build a simpler model, which allows the model to enhance the underwater images in real time.Honget al.[29] designed a new objective function by exploring the depth information of underwater images to make the method more sensitive to depth.Differently from these methods, Hanet al.[34] deprecated the cycle-consistent framework, and utilized contrast learning and generative adversarial networks to improve the mutual information between the original and recovered images.Unsupervised methods do not rely on corresponding clear underwater images and avoid the problems of domain shift and artifact.However, due to the lack of effective supervision information, these methods are poor in terms of detail retention and tend to produce low-quality images.Therefore, it is necessary to develop an underwater image enhancement method that does not require paired data but also produces clear images of high quality.
III.PROPOSED METHOD

Fig.3.The detailed structure of the proposed generator G.Here we only display one stream from x to G (x).The G includes the following three parts: 1) The multi-expert encoder, exploiting multiple experts to separately extract the feature of each channel image of the degraded image, fR, fG, and fB are features extracted by each expert; 2) Feature fusion module (FFM), fusing the three features learned by the experts and matching up the channel numbers with the corresponding layer of the decoder, f1, f2 , f3 denote the features corresponding to R, G and B channel image respectively; 3) The feature fusion-guided decoder,upsampling and then restoring the clean underwater image.
Due to the difference of absorption rates for different wavelengths of light in water, the degradation degrees for R, G and B channels of underwater images are different, resulting in obvious color casts.To address this issue, we present a multiexpert learning model to convert the degraded image into a high-quality clear image using an unsupervised training framework, as Fig.2 shows.To be specific, the cyclic consistency framework is adopted to perform unsupervised learning.A clear image generatorGusing three channel images as inputs is constructed to convert an underwater degraded imagexinto an enhanced imageG(x).The latter is reconverted to a degraded imageF(G(x)) by degraded image generatorF, andF(G(x))is expected to be close toxin terms of the content.The image discriminatorDyis used to make the generated image close to its counterpart.In addition, a new multi-expert discriminator is introduced into the framework to constrain the generation of the channel images.Another loop converting a clear image into a degraded one and then restoring it to a clear image is also shown in Fig.2.In the following, we first state the problem and then describe the components of our network architecture in detail.Finally, the loss functions helpful for improving the content and details of the enhanced image are introduced.
A. Problem Statement
Given a source domainX(underwater degraded images) and a target domainY(clear images), our goal is to learn a nonlinear mapping betweenXtoY.The inputs to the network are unpaired training samplesx∈Xandy∈Y.Two generators,the enhanced image generatorGand the degraded image generatorF, are included in our model.The former learns to transfer an underwater degraded imagexinto an enhanced oneG(x), and the latter aims to transfer a clear imageyinto a degraded oneF(y).Two image discriminatorsDxandDyare constructed.TheDxaims to distinguish between the imagexand the degraded imageF(y), andDyaims to distinguish between the imageyand the enhanced imageG(x).Moreover,differently from existing methods, two multi-expert discriminatorsDcxandDcyare introduced.TheDcxdiscriminatesxandF(y) in thecchannel, and theDcydiscriminates thecchannel foryandG(x), wherec∈{R,G,B}.
B. Generator Network Architecture
The proposed generator structure is presented in Fig.3, and three main modules are contained and will be described in detail.
1)Multi-Expert Encoder: Traditional image enhancement such as dehazing [35], [36] or deblurring [37], [38] only encounters one kind of degradation.In contrast, underwater images suffer from various degradations, including blue, yellow, or green color casts caused by the varied degrees of attenuation for each channel, resulting in the inconsistent degradations for R, G and B channels.Therefore, in this paper, a multi-expert encoder is designed to extract the feature of each channel with different experts.Compared to common encoders, which extract features for the whole image and thus treat the three channels equally, our method can efficiently encode the features of different channels and obtain more specific information for each channel.
Specifically, for R, G and B channel images, three encoder experts named R-expert, G-expert and B-expert respectively are constructed.The three experts have the same structure,namely two downsampling modules performing 2× downsampling operation and another two shared weights modules extracting features further.The first two modules are independent of each other to encode features of the channel image especially.The last two modules share weights, considering the relevance of the contents among the three image channels.With this multi-expert encoder, the generator can learn differential representations from the three channels.
2)Feature Fusion Module(FFM): The feature fusion module fuses features acquired by multi-expert encoder, which allows the model to take account of both channel differences and image integrity.Here, we concatenate features output from the R-expert, G-expert, and B-expert in the channel dimension sequentially, and then reduce the dimension by 1×1 convolution to align with the channel dimension of the corresponding layer of the decoder.Three FFMs are used to bridge the encoder and the decoder.In detail, one FFM fuses the features output by each expert encoder and then feeds the fused features into the decoder.The other two FFMs fuse the firstlevel and second-level features of the R-expert, G-expert and B-expert respectively, and feed the fused features into the corresponding layers of the decoder.With this multi-level fusion,the channel-specific features are retained and used to generate the reconstructed image.
3)Feature Fusion-Guided Decoder: The role of the feature fusion-guided decoder is to decode and upsample the features obtained by the encoder to the original image size for reconstructing the enhanced clear image.It consists of 6 residual blocks and 2 upsampling modules.In each residual block, all convolutional layers have the same kernel size, which is 3×3 and stride 1.For upsampling modules, since deconvolution can produce checkerboard artifacts, we adopt PixelShuffle[39] and convolution to perform the upsampling operation here.The PixelShuffle was originally proposed to solve the problem of image super-resolution.It can obtain high-resolution feature maps from low-resolution ones by convolution and multi-channel recombination.By using 2× upsampling twice, a reconstructed clear underwater image is generated.
C. Discriminator Network Architecture
1)Image Discriminator: In the original generative adversarial network [40], the discriminator distinguishes the authenticity of the whole image, resulting in the loss of local information [41].To deal with this issue, multi-scale discriminator[42], [43], which uses multiple discriminators to identify images at different scales, is proposed.It can increase the receptive field of the model and improve the quality of the generated images.
Due to the lack of mandatory supervision information,images generated by unsupervised methods will lose critical details and generate low-quality images.Therefore, in this work, a multi-scale discriminator adopted in NICE-GAN [44]is used as the image discriminator to distinguish generated images from real ones at multiple scales.Differently, we use the discriminator as an independent module, yet in NICEGAN [44] the generator and image discriminator share an encoder.Specifically, this multi-scale image discriminator contains three scales: local scale (10×10 receptive field),medium scale (70×70 receptive field) and global scale(286×286 receptive field).The global scale has the largest receptive field, guiding the generator to focus on global information of the image.The medium and local scales encourage the generator to generate finer details.
2)Multi-Expert Discriminator: In view of the degradation difference among underwater image channels, we design a multi-expert encoder in generator to extract the specific features of the R, G and B channels separately.Accordingly, a multi-expert discriminator, which is designed to distinguish the authenticity of the generated R, G and B channel images respectively, is introduced into the proposed model.This can make the generator not only focus on the overall image, but also consider the restoration of each degraded channel.This multi-expert discriminator consists of three independent expert discriminators with the same network architecture but for different channels.Since discrimination on global scale may loss detailed information, and the receptive field of local scale is too small, leading to a loss of global information, the medium scale discriminator in the above image discriminator is used as the expert discriminator.Fig.4 illustrates the structure of one expert discriminator.Specifically, thec-expert discriminator consists of an expert encoder and a classifier.Thec-channel image of the enhanced image and the clear one are input into the expert encoder.Here, the expert encoder is same as thec-expert encoder in the multi-expert encoder (Section III-B-1)) and is trained with the decoupling training strategy proposed by NICE-GAN [44].Immediately after, the featurefcextracted by expert encoder is input into the classifier to identify and output a prediction map in which each value indicates the authenticity of a 70×70 patch corresponding to the original image.Using the multi-expert discriminator, we can determine whether the generated images are sufficiently recovered in each channel, and thus can effectively correct various color casts and obtain clear underwater images.

Fig.4.The structure of a c-expert discriminator for the c channel, where c ∈{R,G,B}.The multi-expert discriminator consists of three identically structured discriminators that distinguish the authenticity of the R, G and B channel images, respectively.
D. Loss Function
The loss functions used for our training can be classified into two groups: unsupervised training related and image enhancement related.Below, we just present the loss functions of the forward network and vice versa for the backward network.
1)Unsupervised Training: With these loss functions, the model is constrained to generate the expected images without paired images.Below, we describe each loss function in detail.
a)Image adversarial loss: We apply the least squares adversarial loss to train the generator and image discriminator,which is beneficial to more stable training and higher generation quality.For the forward mapping functionG:X→Yand its discriminatorDy, the image adversarial loss is expressed as
where the generatorGtries to minimize LGANimg, while the discriminator tries to maximize it.
b)Channel adversarial loss: In this paper, a channel adversarial loss is applied to make the generator and the multiexpert discriminator perform the min-max game, so that the degraded underwater images are effectively enhanced on each channel.
whereDcydenotes the expert discriminator of thec-channel for clear image discriminating,c∈{R,G,B}.Gtries to generate imageG(x) similar to the domainY, whileDcyaims to distinguish the generated sampleG(x) and the real sampleyon thec-channel.
c)Cycle-consistency loss: The adversarial loss does not guarantee that the network maps the input to our desired output.Therefore, we apply a cyclic consistency loss to reduce the space of possible mapping functions.For the forward cycle consistency, eachxin the domainXis back to the original image, i.e.,x→G(x)→F(G(x))≈x, and the equation is formulated as
d)Identity loss: We make use of the identity loss to ensure consistency in the color composition of the input and output images.For the input imagey,Gshould ensure that the output image remainsy, i.e.,y→G(y)≈y.
The total loss function for the unsupervised training part is as follows:
2)Image Enhancement: The quality of images generated by the generator just under the constraint of the above unsupervised training related loss functions is low.Here, more loss functions, content perceptual loss, edge loss and total variation loss, which are helpful for improving image quality, are introduced to make the model pay more attention to image details during the training stage.
a)Content perceptual loss:The degraded imagexand the enhanced imageG(x) should have the same content.We utilize a high-level semantic-aware model VGG16 [45] as a feature extractor to capture content information.The VGG16 model has powerful feature representation capability due to its pre-training on the large benchmark dataset ImageNet.Supervised methods usually use it to constrain the perceptual information between enhanced imageG(x) and its ground truth[46].In contrast, we use it to constrain the contents of the degraded imagexand the enhanced imageG(x) to be consistent.The imagexis directly fed into the semantic-aware model to extract features, then the output of the fourth blockϕis represented as content information.
b)Edge loss: Due to the complex underwater environment,the acquired underwater images usually lose more edge information.To better restore details in the enhanced image, the model should pay more attention to the edge texture.Thus, an edge loss is designed to constrain the original imagexand the reconstructed imageF(G(x)), ensuring that the enhanced image conserves more edge textures.
whereφis the Sobel filtering operator.
c)Total variation loss:The image enhancement process may amplify noise, weakening the effect of enhancement.Total variation loss is commonly used in low-level visual tasks [47] as a regularization term to smooth the image and reduce noise.Here, we introduce it to reduce noise and further improve the appearance of the enhanced image.
wherei,jrepresent the horizontal and vertical coordinates of image, respectively.We also apply this loss forF(y) in the backward network.
Therefore, the total loss function of the image enhancement part is
3)Full Loss Function: Overall, two categories of loss function are introduced in this paper.The full loss function is as follows:
in which the two have the same weight empirically.
IV.EXPERIMENT
In this section, we first introduce the experiment settings and then describe our implementation in detail.We compare our model with current underwater image enhancement models qualitatively and quantitatively, and subsequently perform the ablation study on key components, such as multi-expert encoder, skip connections, image/multi-expert discriminator and loss functions, to verify their contributions.Finally, application assessments are performed, which show the effectiveness of the proposed model for advanced tasks.
A. Experiment Settings
1)Underwater Image Enhancement Datasets: Our method is conducted in an unpaired framework.To train our model,we select 5000 underwater degraded images and 5000 clear images from the EUVP dataset [28].Our method was tested on the UIEB [21], UIEB-challenging [21], UCCS [31] and U45 [32] datasets.The UIEB [21] dataset consists of 950 realworld underwater images collected from different underwater scenes.Among them, 890 images have the corresponding ground truth derived from prolific methods.The other 60 are challenging images called UIEB-challenging for which the authors did not obtain satisfactory ground truth.We selected 90 images with ground truth and 60 challenging underwater images as the test sets.UCCS [31] contains three 100-image subsets of the bluish, blue-green and greenish cast, which are captured during underwater catching.It is used to evaluate the ability of models for various real-world underwater degradation.U45 [32] collects 45 underwater images, including color casts, low contrast, and haze-like effects of underwater degradation.
2)Underwater Application Datasets: VDD-C (Video Diver Dataset) [48] dataset contains over 100 000 annotated images of underwater divers from videos, which aims to develop diver detection algorithms for autonomous underwater vehicles.Unaligned underwater image enhancement (UUIE) [29]dataset has 4096 degraded images and 5848 clear images,which collects various underwater degraded images and unpaired clear images.We select the images that contain humans for testing.Underwater salient object detection (USOD) [49]dataset contains 300 underwater images with corresponding ground truth labels, which cover a variety of object categories and distortions.
To evaluate the effectiveness of the proposed method, we enhance the images in the above three datasets, and then perform the applications on the enhanced images.
3)Metrics: We adopt four commonly used image quality evaluation metrics.Peak signal to noise ratio (PSNR) [50] and structural similarity (SSIM) [51] are used as the full-reference evaluation metrics.A higher PSNR indicates that the output image is closer to the ground truth.And a higher SSIM indicates that the enhanced image is more similar to ground truth in structure and texture.
Underwater color image quality evaluation (UCIQE) [52]and underwater image quality measurement (UIQM) [53] are used as the no-reference image evaluation metrics.UCIQE uses a linear combination of chroma, contrast and saturation.It is used to quantitatively evaluate color cast, blur and low contrast in underwater images.UIQM is a human-vision-system-inspired underwater image quality measure, which reflects the color balance, sharpness and contrast of the image.A higher UIQM score means that the image is more consistent with human visual perception.
For underwater human detection, we adopt mean average precision (mAP) as the evaluation metric.For underwater image saliency detection, we measure mean absolute error(MAE) for quantitative comparison.
4)Comparison Methods: Our method is compared with 8 underwater image enhancement methods, including physical model-based methods: UDCP [8]; model-free methods:ICM [13]; supervised deep learning-based methods: Water-Net [21], Shallow-UWNet [23] and MBANet [25]; unsupervised deep learning-based methods: Funie-GAN [28], CWR[34] and CycleGAN [26].
B. Implementation Details
For the multi-expert encoder, the downsampling layers consist of a convolutional layer with 4×4 kernel size and 2×2 stride, LeakyReLU layer and Instance Normalization.Shared weights modules include a convolutional layer with 3×3 kernel size and 1×1 stride, LeakyReLU layer and Instance Normalization.In the feature fusion-guide decoder, we make use of a 3×3 convolutional layer to expand the feature channel by a factor ofr2, whereris the upsampling factor.And PixelShuffle is used for upsampling.For image discriminator and multi-expert discriminator, each downsampling module consists of convolutional layers with 4×4 kernel size and 2×2 stride, LeakyReLU layers and Spectral Normalization.The last layer of classifier uses convolutional layers with 4×4 kernel size and 1×1 stride.
In training process, we conduct experiments using PyTorch deep learning framework on NVIDIA GeForce RTX 3090 GPU with 24 GB RAM.The Adam optimizer is adopted to minimize the objective function.Set the learning rate to 0.0001.We keep the same learning rate for the first half of iterations and decay for the next half with a 0.001 weight decay rate.The batch size is set up to 1 in the experiment.For loss functions of unsupervised training, the trade-off weights were set to λ1=λ2=1, λ3=λ4=10.We set trade-off weights for loss functions of image quality to η1=10 , η2=0.01 and η3=1e-3.Besides, for data augmentation, we flip the images horizontally with a probability of 0.5, resized and randomly cropped them to 256×256.The models are trained with 50K iterations.
C. Comparison With State-of-the-Art Methods
Tables I and II show our results compared with existing methods on four datasets.Among them, the UIEB [21] dataset has reference images, so PSNR, SSIM, UCIQE and UIQM are adopted as the evaluation metrics.The rest three datasets have no reference images, and only UCIQE and UIQM are measured.
For UIEB [21] dataset, our method achieves the best scores in all evaluation metrics.Especially on UIQM, our results are significantly better than the second one.The higher PSNR and SSIM indicate that our method can generate sharper images and the results are closer to the reference image.In addition, a higher UIQM and UCIQE score show that our method has better color restoration and contrast correction capabilities.On the remaining three datasets without reference images, our method has achieved the best performance on UIQM and UCIQE, which also indicates that our results are more in line with human subjective feelings.The above results show that our method outperforms existing underwater image enhancement methods obviously.

TABLE I THE EVALUATION OF DIFFERENT METHODS ON UIEB.THE BEST RESULT IS RED, AND THE SECOND BEST RESULT IS BLUE UNDER EACH CASE

TABLE II THE EVALUATION OF DIFFERENT METHODS ON UIEB-CHALLENGING, U45 AND UCCS
D. Visual Comparisons
We first show the results of our model and other models on the UIEB [21] dataset.As shown in Fig.5, compared with other methods, our model achieves satisfactory visual results.UDCP [8] aggravates the blue-green effect.ICM [13], Cycle-GAN [26] and MBANet [25] incompletely recover the underwater image, in which some color cast still exists.The results of WaterNet [21] are darker and have poor contrast.Shallow-UWNet [23] and Funie-GAN [28] bring unnecessary yellow casts.CWR [34] has an unsatisfactory effect on some images and introduces noise.In contrast, our method can effectively restore a clear appearance for yellow, blue and hazy degraded images.At the same time, there is no significant overenhancement or under-enhancement.
We then present the results of different methods on UIEBChallenging dataset [21] in Fig.6, which has more severe degradation.For these images, UDCP [8] does not bring improvement to the visual effect of the image and even accentuates the color deviation.ICM [13] only restores color balance and does not improve contrast.The results of WaterNet[21] are under-enhanced or over-enhanced.Shallow-UWNet[23] and Funie-GAN [28] introduce unnecessary color casts,which make the enhanced image blurry.Due to the influence of artificial labels, the overall results of MBANet [25] are greenish.The unsupervised methods, CWR [34] and Cycle-GAN [26], cannot completely remove the color casts, which leads the images to still show the green cast.Our method not only eliminates color casts but also improves the visibility of low-brightness images.It indicates that the proposed model is effective for underwater image enhancement.
We show the results of different methods on U45 dataset[32] to further verify the visual enhancement of our method.As shown in Fig.7, none of the other methods achieved satisfactory visual results.Some of these methods work well only for some degradation types, such as UDCP [8] and ICM [13],which effectively enhance haze-like images.In addition, some methods introduce hues leading to worse images, such as Shallow-UWNet [23] and Funie-GAN [28] bring red hues.In contrast, our method removes color casts and haze, with clearer content and significant contrast.
The experimental results on UCCS dataset [31] with severe color degradation are also provided.As shown in Fig.8, the results of most methods are under-enhanced, still contain color residuals, and do not show a significant improvement in contrast.For example, the results of UDCP [8] are even worse than the original image.On the contrary, our method eliminates color bias and significantly enhances the visual effect.
Fig.9 gives the results of our method and other unsupervised methods, which presents the visual comparison of the recovered images for each channel.Obviously, the proposed method can restore the image of each channel better and therefore obtain a better enhanced underwater image.
Based on quantitative and visual comparisons, we have two interesting findings:
1) The supervised methods generate high-quality images and achieve good scores for the full-reference metrics.Nevertheless, due to the influence of the synthetic dataset, they introduce artificial color, which is not superior for metrics without reference.Our method directly learns the mapping of degenerate image domain to clear image domain through unsupervised training, enhancing realistic underwater images without introducing artificial color casts, and achieves the best values on metrics.
2) Although MBANet [25] performs well on UIEB [21]dataset, it does not perform well on the other datasets.Water-Net [21] and Funie-GAN [28] win second place in U45 [32]and UIEB-Challenging [21] datasets respectively for UIQM metric, but they did not have good performance in other datasets.It indicates that our method is robust and stable,which can achieve satisfactory results on different datasets.
E. Ablation Study
We perform extensive ablation studies to understand the roles of key components in our model, including processing for RGB channels, image discriminators and skip connections.In addition, we also analyze the roles of introduced loss functions.

Fig.5.Visual comparisons on real underwater images from the UIEB [21] dataset.

Fig.6.Visual comparisons on underwater images from the UIEB-challenging [21] dataset.
● w/oDmeans without image discriminatorsDxandDy.
● w/o skip-1, w/o skip-2, and w/o skip-1 + skip-2 mean generator without skip connection 1, skip connection 2, and all skip connections, respectively.
● w/o ME, w/oDc, and w/o ME +Dcmean that the model extracts features for the whole image, the model without multi-expert discriminatorsDcxandDcy, and the model extracts features for the whole image and without multi-expert discriminators, respectively.
● w/o Lcyc, w/o Lide, w/o Lcont, w/o Ledge, and w/oLtvmean training without Lcyc, Lide, Lcont, Ledge, and Ltv,respectively.
We conduct tests on UIEB [21] dataset using PSNR [50],SSIM [51], UCIQE [52] and UIQM [53] as evaluation metrics.As presented in Table III, overall, the full model achieves the best quantitative performance, which indicates that each key component contributes to the good performance of our method.The conclusions of the ablation study for each module are as follows:
1) As shown in Fig.10, just processing the whole image can not completely remove the color casts.The multi-expert encoder extracts feature for each channel separately, which is helpful for the recovery of each channel image.In addition,the multi-expert discriminator is able to further enhance degraded images, resulting in significant improvements in both metrics and visual effects.The full model achieves the most pleasing results.
2) From the results in Table III, we can conclude that the image discriminator makes the model generate higher quality images and removing it will severely affect the performance of the model.

Fig.7.Visual comparisons on real underwater images from the U45 [32] dataset.

Fig.8.Visual comparisons on real underwater images from the UCCS [31] dataset.
3) As shown in Fig.11, the model without skip connections results in blurred and poor-quality images.Images generated by adding only skip connection 1 show an over-exposure problem.And images enhanced by adding only skip connection 2 show under-enhancement.The best visual effect is achieved for the complete model.As shown in Table III, the complete model obtains highest metrics.
4) As shown in Table III, each of the multi-term loss functions is indispensable, and removing anyone of them will lead to performance degradation.Specifically, cycle-consistency loss can significantly improve all metrics, which shows that it is crucial for unsupervised training.Identity loss is beneficial to restore colors and removing it will affect UIQM and UCIQE metrics.The content perceptual loss and edge loss effectively improve PSNR and SSIM, indicating that they constrain the texture and details of the image.The total variation loss smooths the images to reduce noise, which further improves the performance of the model.
Furthermore, we analyze the weights of different loss terms.We change the values of η1, η2while keeping η3unchanged.Table IV shows quantitative results for different weights,where setting λ2=1.0 , η1=10, and η2=0.010 performs better than other weight settings.
F. Application Assessments
Underwater image enhancement devotes to promoting the performance of underwater vehicles in high-level visual tasks.To further demonstrate the effectiveness of the proposed method, the enhanced image is considered as the input of some advanced vision tasks.The details are as follows.
1)Underwater Human Detection: It can help underwater robots to perform search and rescue, etc.We utilize YOLOv3[54] to detect underwater humans and selected 300 images randomly from VDD-C dataset for validation.As shown in Fig.12, the enhanced image is more favorable compared to the original one.The proposed method can detect more humans, and has higher confidence compared to most methods, proving its effectiveness for underwater object detection.In addition, we perform a quantitative comparison in Table V,in which using the enhanced images has a higher mAP than using the raw images.

Fig.9.Visual comparisons of each channel for enhanced images with different methods.
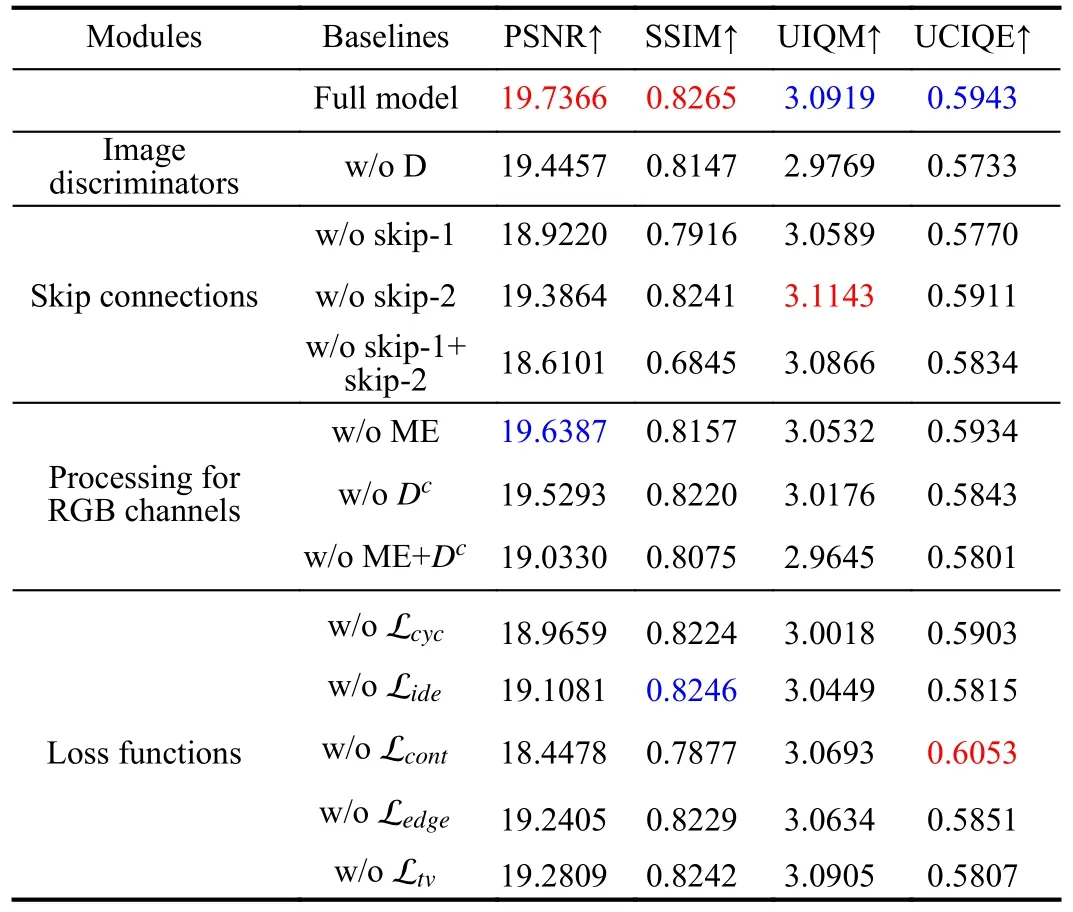
TABLE III QUANTITATIVE RESULTS OF THE ABLATION STUDY.THE BEST RESULT IS RED, AND THE SECOND BEST RESULT IS BLUE UNDER EACH CASE

Fig.10.The ablation study on processing for RGB channels are (a) raw images; (b) the results without the multi-expert encoder and multi-expert discriminators; (c) the results without the multi-expert encoder but with multiexpert discriminators; (d) the results with the multi-expert encoder but without multi-expert discriminators; (e) our results.

Fig.11.The ablation study of skip connections are (a) raw images; (b) the results without all skip connections; (c) the results without skip-1; (d) the results without skip-2; (e) our results.
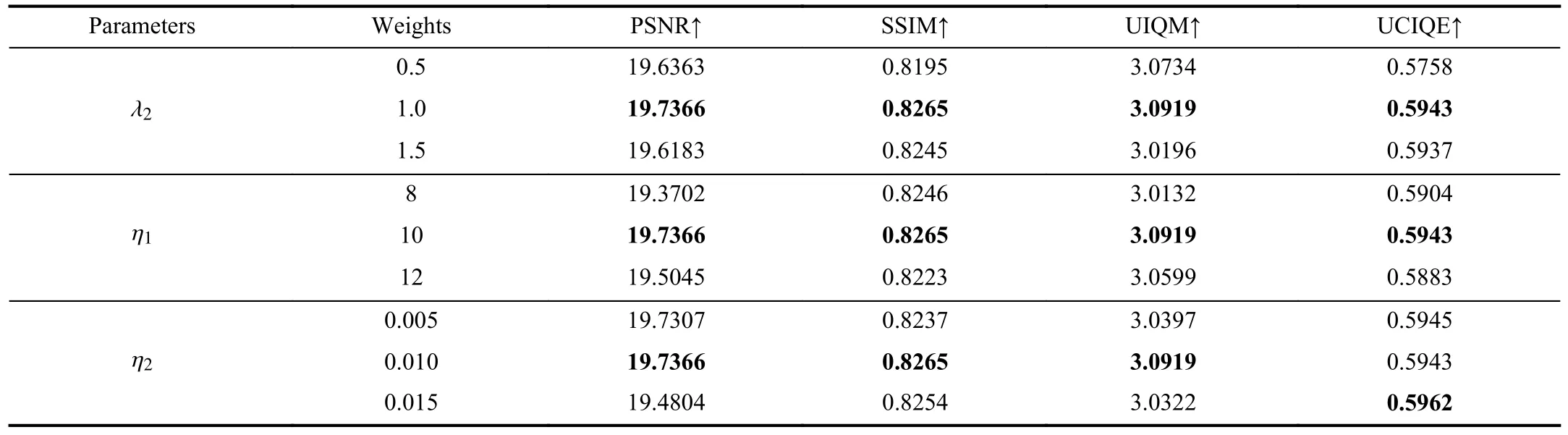
TABLE IV RESULTS OF THE LOSS WEIGHTS ANALYSIS.THE BEST RESULTS ARE IN BOLD

Fig.12.The results of human detection on enhanced images.
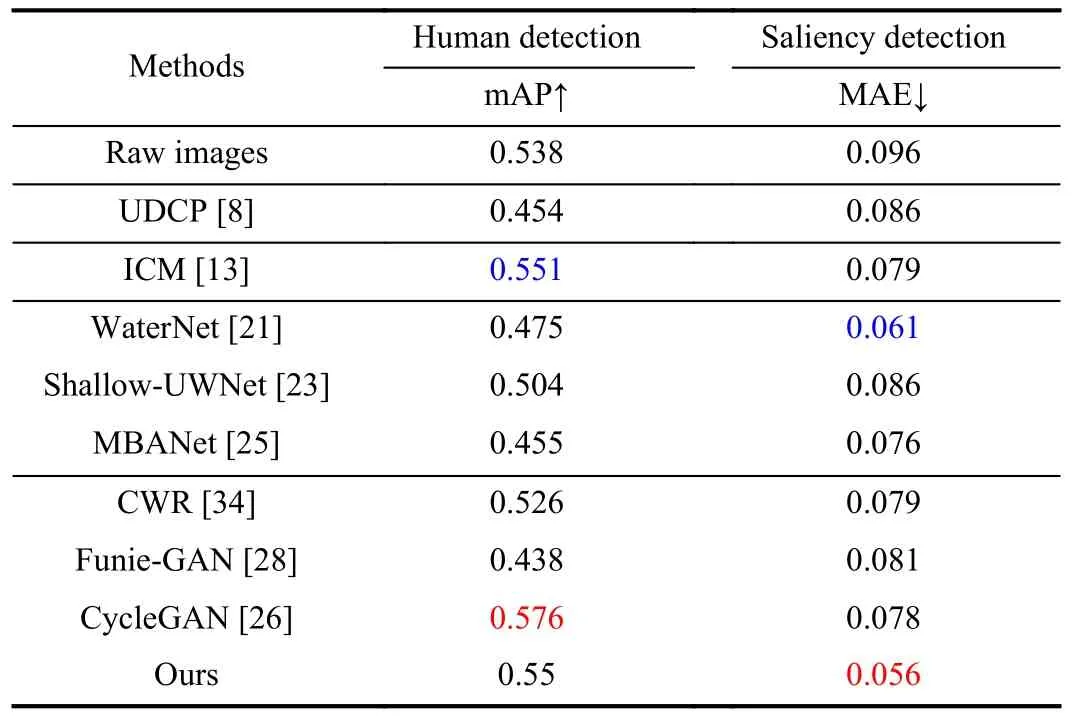
TABLE V QUANTITATIVE RESULTS OF UNDERWATER DOWNSTREAM TASKS.THE BEST RESULT IS RED, AND THE SECOND BEST RESULT IS BLUE UNDER EACH CASE
2)2-D Human Pose Estimation: The purpose of human pose estimation is to estimate the current pose of the underwater human, which facilitates the interaction between the diver and the underwater robot.We utilize the method proposed by Caoet al.[55] for human pose estimation in the UUIE [29]dataset.From Fig.13, we can see that the human pose is not accurately estimated on the raw images, and even some people cannot be detected.On our enhanced images, more accurate estimation results are obtained.
3)Underwater Image Saliency Detection: This task aims to map out the most attractive regions in the image.We use the method proposed by Qinet al.[56] for saliency detection, and randomly selected 35 images on USOD dataset as validated data.As shown in Fig.14, it is difficult for using the raw images to detect the salient regions.As a comparison, the enhanced image can significantly improve the performance of this task.Compared to other methods, our method is able to detect salient regions more accurately.Furthermore, as shown in Table V, the best MAE metric is obtained on our enhanced images.
V.CONCLUSION
Inspired by varied attenuation rates of different color channels, we propose an unsupervised multi-expert learning model for underwater image enhancement, which considers the R, G and B channel images of the underwater image independently.To do this, a multi-expert encoder and its corresponding multi-expert discriminator are proposed.They make the model enhance each channel image better.In addition, to balance the whole image appearance, multi-level fusion is considered.Moreover, a multi-term loss function is designed to retain the details in the enhanced image.The results on four datasets demonstrate the effectiveness and robustness of the proposed method.What’s more, the effectiveness of the proposed method is demonstrated on high-level underwater visual tasks,such as underwater human detection, human pose estimation and saliency detection.
Due to the complex underwater imaging environment, various types of degradation coexist in underwater images, such as color casts, motion blur, hazing, etc.Some degradations have same causes with those in in-air degraded images.So, in the future, we will consider the knowledge transfer [57] or reassembly model [58], [59] to deal with the underwater image enhancement, so as to harvest from the fast development of the in-air image enhancement.

Fig.13.The results of human pose estimation on different enhanced images.

Fig.14.The saliency detection on images produced by different enhancement methods.
杂志排行

IEEE/CAA Journal of Automatica Sinica的其它文章
- A Dual Closed-Loop Digital Twin Construction Method for Optimizing the Copper Disc Casting Process
- Adaptive Optimal Output Regulation of Interconnected Singularly Perturbed Systems With Application to Power Systems
- Sequential Inverse Optimal Control of Discrete-Time Systems
- More Than Lightening: A Self-Supervised Low-Light Image Enhancement Method Capable for Multiple Degradations
- Set-Membership Filtering Approach to Dynamic Event-Triggered Fault Estimation for a Class of Nonlinear Time-Varying Complex Networks
- Dynamic Event-Triggered Consensus Control for Input Constrained Multi-Agent Systems With a Designable Minimum Inter-Event Time