More Than Lightening: A Self-Supervised Low-Light Image Enhancement Method Capable for Multiple Degradations
2024-03-04HanXuJiayiMaYixuanYuanHaoZhangXinTianandXiaojieGuo
Han Xu , Jiayi Ma ,,, Yixuan Yuan ,,,Hao Zhang , Xin Tian , and Xiaojie Guo ,,
Abstract—Low-light images suffer from low quality due to poor lighting conditions,noise pollution,and improper settings of cameras.To enhance low-light images,most existing methods rely on normal-light images for guidance but the collection of suitable normal-light images is difficult.In contrast, a self-supervised method breaks free from the reliance on normal-light data,resulting in more convenience and better generalization.Existing self-supervised methods primarily focus on illumination adjustment and design pixel-based adjustment methods, resulting in remnants of other degradations, uneven brightness and artifacts.In response, this paper proposes a self-supervised enhancement method, termed as SLIE.It can handle multiple degradations including illumination attenuation, noise pollution, and color shift, all in a self-supervised manner.Illumination attenuation is estimated based on physical principles and local neighborhood information.The removal and correction of noise and color shift removal are solely realized with noisy images and images with color shifts.Finally, the comprehensive and fully self-supervised approach can achieve better adaptability and generalization.It is applicable to various low light conditions, and can reproduce the original color of scenes in natural light.Extensive experiments conducted on four public datasets demonstrate the superiority of SLIE to thirteen state-of-the-art methods.Our code is available at https://github.com/hanna-xu/SLIE.
I.INTRODUCTION
DUE to low photon counts, images captured in low-light environments usually suffer from multifaceted degradations, e.g., low contrast, poor visibility, complex noise, and color shift/distortion.These degradations result in low signalto-noise ratio (SNR) and undesirable image quality, causing poor visibility of objects.Low-light image enhancement aims to remove these degradations and generate high-quality normal-light images, which are more conducive to subsequent applications, e.g., surveillance, human and object recognition,and automated driving [1], [2].Thus, enhancement performance is a critical challenge in image processing [3], [4].
To remove these degradations, traditional methods have been proposed over the past years.Value-based methods are based on pixel values while failing to consider local consistency, resulting in uneven-exposed and unrealistic results.Model-based methods are limited by the capacity of models and cannot deal with extreme/challenging situations,e.g.,wide illumination variation and extremely dark illumination.In this case, they tend to generate under- or over-exposed results.
To ameliorate these drawbacks, learning-based methods have been proposed.These methods can be roughly divided into three categories, including supervised, unsupervised, and self-supervised methods shown in Fig.1.Supervised methods require paired low-light and normal-light images for supervised learning or Retinex decomposition[5]-[9].Unsupervised methods use unpaired low-light and normal-light data for training [10], [11].By comparison, self-supervised methods merely utilize low-light images for training, eliminating the need for external information from normal-light images.
A more specific overview and analysis of each type of methods is then performed.As illustrated in Fig.1(a), supervised methods require paired low-light and normal-light images.However, it is challenging to capture paired images of the same scene: i) Simultaneous shooting is a troublesome problem as it is hard for a scene to be completely static; ii)Ground truth does not always exist.Even with appropriate exposure settings, images still exhibit a variety of exposure levels.As shown in Fig.2, images where all the regions are well-exposed are not always available.
To reduce dependence on paired data, some unsupervised methods use unpaired low-light and normal-light data, as illustrated in Fig.1(b).For example, generative adversarial networks (GANs) are applied to pull enhanced results close to normal-light data from the perspective of probability distribution.Even if they overcome the need for static scenes and simultaneous shooting,they still rely on normal-light data.The capture and selection of normal-light images are still timeconsuming and laborious and the performance is determined by the distribution of selected normal-light images.

Fig.2.Examples of images with normal light at different exposure levels.
To completely obviate the need for normal-light images,several self-supervised methods have been proposed.These methods approach enhancement by estimating curve parameters [12], mapping matrices of the image-to-curve transform [13], or adjusting the histogram distribution [14].While these methods only employ a self-supervised approach to brighten low-light images, they do not address other degradations to achieve higher image quality.Even if noise is considered,denoising is achieved by established operations rather than a self-supervised network.As illustrated in Fig.3, they cannot handle severe noise well and seldom account for color shifts, leading to poor visual outcomes.Primarily focusing on self-supervised brightness adjustment and overlooking other degradations, these methods primarily rely on pixel values and neglect local consistency, resulting in uneven exposure.Consequently, developing a self-supervised low-light image enhancement method that can comprehensively address multiple degradations to produce evenly-exposed, high-quality enhanced results remains a formidable task.
In this paper, we propose a self-supervised low-light image enhancement method capable in the face of multiple degradations.Firstly,as illustrated in Fig.1 c),it only utilizes low-light images for training,eliminating the need for external information from normal-light images.Secondly, it comprehensively addresses various degradations, including low light, noise,and color shift, with each being handled by self-supervised networks.For each specific degradation,a self-supervised illumination adjustment block considers light distribution, object geometry and local smoothness.It estimates an illumination attenuation map and brightens an image for evenly-exposed outcome.A self-supervised denoising block only looks at bad noisy images without clean reference data while handling complex noise.A self-supervised color correction module trains a network to estimate and then correct color shifts, ensuring that the original colors under natural light are faithfully represented.The contributions are summarized as follows:
1) We propose a self-supervised low-light image enhancement method.Compared to existing self-supervised methods,this method considers and addresses multiple degradations(including low illumination, noise, and color shift) to achieve more comprehensive enhancement performance.
2) For illumination adjustment, different from pixel-based methods, the proposed self-supervised adjustment network considers physical basis (including light distribution, object geometry, and local smoothness).It shows better adaptability and more even and natural adjustment results.
3) A self-supervised color correction block is designed.It performs color correction based solely on images with color shifts, breaking free from the reliance on white balanced images.
4) The proposed method overcomes limitations imposed by supervised/unsupervised learning and is better generalized to various low-light conditions.Its results on four publicly available datasets demonstrate superiority over state-of-the-art methods.Moreover, it achieves a balance between parameters and performance.
The remainder of this paper is organized as follows.Section II discusses related work.Section III provides problem formulation, loss functions, and network architectures.Section IV compares SLIE with state-of-the-art methods on four datasets.Intermediate results, ablation study, and parameter analysis are also conducted.Section V points out the limitations of the method and the future direction of work.Section VI summarizes the whole paper.
II.RELATED WORK
A. Traditional Methods

Fig.3.Enhancement results of state-of-the-art supervised method KinD++ [9], self-supervised method DUNP [15] and the proposed SLIE.
Typical traditional methods include value-based mapping and model-based optimization methods.Value-based mapping methods directly increase the dynamic range by mapping the low pixel values to higher values with nonlinear transformations, such as histogram equalization [16], gamma correction,and some variants [17], [18].Most model-based optimization methods adopt Retinex theory, assuming that an image can be decomposed into reflectance and illumination.Some early methods treat the decomposed reflectance as the enhanced image[19].Afterward,some methods multiply the reflectance by adjusted illumination to make the enhanced image natural[20],[21].
B. Deep Learning-Based Methods
1)Supervised/Unsupervised Methods With Paired/Unpaired Normal-Light Images: In deep learning-based methods,Retinex theory is widely applied.The deep models usually use paired data to decompose images into reflectance and illumination.For instance, DeepUPE [22] uses under-exposed image pairs to estimate an image-to-illumination mapping and then takes the illumination map to light up the under-exposed image.RetinexNet [7], LightenNet [23], RDGAN [24], and KinD++ [9] also estimate illumination based on Retinex theory.In these methods, the decomposition accuracy inevitably needs multi-exposed images of the same scene.Some methods perform other forms of decomposition.For instance, Renet al.decomposed images into scene information and edge details [25].Some methods directly use paired images with ground truth for supervised learning.EnlighenGAN [10] uses unpaired data for training.It trains the dual-discriminator to direct global and local information.Besides, a self feature preserving loss is applied to maintain textures and structures.However, the dependence on normal-light data in these methods sets high requirements for training data and limits network performance.Moreover, most of these methods are only applicable to a specific type of noise.In this work, we comprehensively consider Gaussian and Poisson noise to better deal with the noise in noisy images.Specifically, we adopt a self-supervised mechanism which only looks at bad noisy images and then performs denoising well.
2)Self-Supervised Methods Without the Need for Normallight Images: These methods apply a self-supervised manner to get rid of the reliance on normal-light data.Zero-DCE [12]reformulates the enhancement as a pixel-wise and high-order curve estimation problem by training a network to learn the adjustable parameters of curves.The dynamic range is adjusted through multiple iterations while its effectiveness is limited in some extreme scenarios.Garget al.[14] assumed that the enhanced histogram distribution of the maximum channel should follow that of a histogram-equalised low-light image.Wuet al.[13] executed the image-to-curve transform by learning mapping matrices.[14] and [13] are based on pixel values and ignore local consistency, resulting in unevenexposed results.Zhaoet al.[26]proposed Enlighten Anything,which can enhance and fuse the semantic intent of SAM segmentation with low-light images to obtain fused images with good visual perception.In some other research fields,some self-supervised methods are also proposed.For example,Liet al.proposed a method for image super-resolution (SR)with multi-channel constraints.It integrates clustering, collaborative representation,and progressive multi-layer mapping relationships to reconstruct high-resolution color images [27].They also employed the geometrical structure of an image and the statistical priors based on clustering and local structure priors [28].In summary, these low-light image enhancement methods only focus on self-supervised brightness adjustment but can not handle other degradations such as noise.In addition to the aforementioned shortcomings, color correction is not considered and still remains a challenging task to be solved.The color shifts in low-light images still remain in the final results.
In SLIE, firstly, to address the issue of uneven brightness caused by pixel-wise adjustment with existing methods, we formulate the illumination degradation by considering physical basis (light distribution, object geometry and local smoothness).Secondly, the self-supervised manner is not only used for brightness adjustment, but also for denoising and color correction,which are not considered in existing self-supervised enhancement methods.
III.PROPOSED METHOD
In this section, we provide the problem formulation and details of three blocks in the proposed method, including loss functions and network architectures.
A. Problem Formulation
Given a low-light image of sizeH×W×3, the goal is to generate an enhanced image.When deriving the proposed model, column-vector forms are tentatively applied for convenience.Denoting the low-light and enhanced images asIandE ∈RHW×3respectively, according to Retinex theory [29],the low-light image can be decomposed as
whereR,L,Z ∈RHW×3stand for reflectance, illumination,and noise,respectively.⊗denotes element-wise multiplication.Ris related to intrinsic properties of objects, e.g., materials,textures, and colors.It is not influenced by external light conditions and remains the same in multi-exposure images.Lis independent from reflectance and is determined by factors such as the color of light source,the light intensity distribution and the geometry of objects.From the perspective of shooting equipment, a camera has onboard integrated signal processor(ISP).It applies a series of color rendering manipulations to generate standard RGB images.White balance is one of these manipulations to ensure that objects appear as the same color under different illumination conditions [30]-[33].However,low light and SNR may cause improper rendering parameters,resulting in color shifts in processed images.Some works aim to process RAW camera images captured in night scenes to produce a photo-finished output image encoded in the standard RGB (sRGB) space [34]-[36].In this work, the degradations in low light conditions are modeled separately by type.The color shifts caused by not only ISP but also the color of light source are summarized as the total color shift inL.
From the above formulation,the degradations of a low-light image exist inLandZ.The degradation ofLcomes from two aspects.i) The low light results in the attenuation of pixel intensity.Denoting the normal illumination byLE∈RHW×3,the degraded illumination is formulated asLE⊗A, whereA ∈RHW×3denotes the intensity attenuation map.When formulating the intensity attenuation, the color shift is not considered for the time being.A gray-scale attenuation map is concatenated in the channel dimension to attenuate RGB channels identically.ii) The color of the light source and improper rendering parameters in ISP jointly cause the color shift inL.Considering that color cast is consistent in an image and independent of scene content and the rendering color correction process in image signal processor (ISP), the color shift is formulated as a diagonal matrixC ∈R3×3
whererR,rG,rB >0 scale RGB channels to varying degrees,respectively.By disassemblingL, (1) can be rewritten as:
AsCis a diagonal matrix, we rewrite the formula as
The element-wise multiplication of reflectanceRand the normal illuminationLEis the enhanced imageEto be solved.Thus, (4) becomes
whereZ= ~Z ⊗A.We aim to solve ~Zin the enlightened image rather thanZin the low-light image to avoid erroneously filtering valuable signals in the case of low signal values.Then,the enhancement problem is decomposed into illumination adjustment, denoising, and color correction, corresponding to the solution ofA, ~ZandC, respectively.The proposed SLIE aims to solve the three subproblems progressively.The overall framework of the proposed method is summarized as Fig.4.We present the details of each block in the following.
B. Illumination Adjustment Block
The illumination adjustment block with the low-light imageIas input, estimates the intensity attenuation mapA.The framework of this block is summarized as Fig.5.According to the Retinex theory, the degradation of illumination is related to light intensity and scene geometry.The light intensity is proportional to the pixel intensity.On the one hand, the attenuation map should be correlated with the pixel intensity.When the region shows poor pixel intensity, the attenuation map should also exhibit dark, indicating strong attenuation.After division, the image can be brightened to a greater extent.On the other hand,the attenuation map should consider the actual situation of texture smoothness under different illumination levels.For instance,the regions with appropriate pixel intensity are well-textured due to appropriate light intensity while the dark regions usually exhibit smoother textures.It motivates us to estimate the attenuation mapAaccording to original pixel values ofI.
1)Loss Function: Either considering the light intensity or scene geometry, the attenuation map should be independent of surface textures and be locally consistent.A smoothness constraint is defined to ensure the regional smoothness of the attenuation mapA,which is the channel-dimension concatenation result of the output of the attenuation net.Jointly considering the self-supervised reference information and smoothness,it is defined as
whereθAdenotes the parameters in the attenuation network.g(I) denotes the gray version ofI.αis a hyper-parameter to control the trade-off between the two terms.
Considering the smoothness constraint, the regions with different illumination should be treated with distinction.More concretely,the dark regions suffer from tiny and inconspicuous textures due to the limited dynamic range.In this case, the intensity loss (first term in (6)) is expected to dominate and enlighten the textures hidden in the low dynamic range.By comparison, the regions with relatively appropriate illumination can exhibit clearer textures with a higher dynamic range.In this situation, the introduction of obvious textures in the generatedAwill cause the distortion of textures in the illumination-adjusted image.Thus, for the regions with rich textural details benefiting from appropriate illumination, the main task is to improve the overall brightness as a whole.To this end, the smoothness loss should be strictly minimized to ensure the regional consistency.Thus, the smoothness loss is concretized as
whereApdenotes the value of pixelpinAandN(p)is a set of neighbors ofp.HandWare height and width, respectively.φ(Ap) denotes the weighted function according to the pixel intensity ofp.
In this work, we employ a sigmoid-like function to model the correlation between weight and pixel intensity.The parametric form ofφ(x) is defined
As shown in Fig.6,kdetermines the length of transition interval andbcontrols the central pixel intensity of transition interval.We empirically setk= 20 andb= 0.2.According to (5), we define the image after illumination adjustment asIA, formulated as
where⊘is the element-wise division.c(·) denotes concatenating the image along the channel dimension.
2)Network Architecture and Operations: The network architecture is shown in Fig.5.The deep network and large kernel size in the third to seventh layers are used to expand the receptive field and produce a smooth result independent of surface details.As the division operation directly raises the whole image to a bright interval,the results suffer from limited light and shadow variations and low saturation.We decay the result as a whole and apply an exponential transformation to stretch variations between different brightness.Moreover, going back to its definition, saturation is decided by achromatic and chromogenic components as
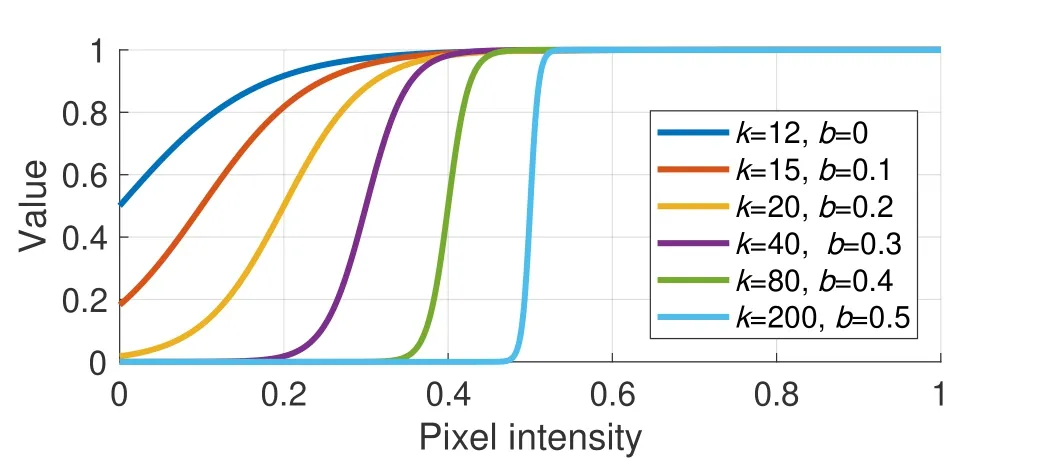
Fig.6.The behavior of function φ(x) with x denoting the pixel intensity.
wherer,g,bdenote RGB channels.The subscripth,wrepresents the position in theh-th row andw-th column of this channel.When different channels are attenuated identically,the saturation is the same as the original limited saturation.Hence, we focus on reducing the achromatic component and increasing the chromogenic component.We generate an achromatic maskmby removing the chromogenic component asm=1-g(c(r-g(IA),g-g(IA),b-g(IA))).RGB channels are adjusted with the same operation to avoid introducing chromatic aberration.
With a ratior ∈[0,1] controlling the adjustment level, the adjusted red channel is represented asr′=r ⊗(1+r·m)-g(IA)⊗(r·m).Other channels are processed in the same way.The ratioris adaptively set according to the original saturation asr=(1-ls)/2.The finalIAis adjusted toIA=c(r′,g′,b′).
C. Denoising Block
This block aims to remove the noise in brightened images,as in Fig.7.There are several types of noise in real-world noisy images, produced both in image acquisition and signal transmission.In terms of noise distribution, the stochastic noise can be modeled with a Gaussian distribution.In practice,the signal has fluctuations in time due to the discrete nature of photons [37].The number of photons affects the shot noise.The variance of noise in dark regions is usually higher than that in bright regions.As the arrival of photons is not a steady stream, the shot noise can be modeled with a Poisson distribution.In this block,we take Gaussian and Poisson noise into account and focus on denosing the brightened resultIA.
1)Loss Function: As only noisy images are available, it prompts us to perform an unsupervised denoising approach.As a representative unsupervised denoising method, Noise2Noise(N2N) [38] can infer clean images from noisy images.When there are a large number of samples, as the noise is unpredictable and randomized, to minimize the denoising loss function, the network tends to output the expectation of all possible outputs, i.e., the clean signal.However, for different types of noise,N2N needs to redefine loss function and retrain network, lacking generalization to mixed complex noise.To solve this problem, similar to N2N but different from it, we corruptIAwith four independent noise{Z1,...,Z4}, which are random combinations of Gaussian and Poisson noise.Then, it is more suitable for realistic scenes compared to N2N.Moreover, we introduce a total variation regularization to further remove noise.With the denoising function denoted asD(·), the loss function is:

Fig.7.Framework of the denoising block (kernel size: 3×3, stride: 1).Once the denoising network has been optimized, we apply it to denoising IA.
whereβis a hyper-parameter.θDrepresents parameters in the denoising network.N(·,·) denotes corrupting the signal by noise.For each sample, the standard deviation/parameter of Gaussian/Poisson noise is sampled from uniform distribution in [0,40] or [5,40].The output of this block isIZ=EC=D(IA).The overall framework is summarized as Fig.7.
2)Network Architecture: The network architecture of the denoising block is shown in Fig.7.We adopt the U-Net architecture [39] as the denoising network, followed by a convolutional layer without an activation function to generate an estimated noise map.The kernel size of all convolutional layers is set to 3× 3 and the stride is set to 1.Once the denoising network has been optimized with multiple types of uncorrelated noisy data, we apply it to denoisingIA.
D. Color Correction Block
It aims to obtain the achromatic estimation for color correction.The achromatic estimation is removed from the denoised image to obtain the final enhanced result.The framework is summarized in Fig.8.Inspired by[40],we train a color weight network to yield a weight mapW.It represents the contribution weight of each pixel in the input image to determine the achromatic estimation.However, [40] is quasi-unsupervised and requires many balanced images without color cast for training.In our method, due to lack of balanced data, we realize color correction in the unsupervised manner and train the color weight block on unbalanced images with color cast.

To train the color weight network, we assume that the brightest pixel is most likely to derive the color shift.If the image is white-balanced, this pixel should no have chromogenic component.In other words, the RGB values of the brightest pixel should be as identical as possible.Thus, we depend on the divergence between the estimated color vector c and the gray axis for optimization.Denoting the parameters in this block asθC, the loss function can be defined as
whereϵ=10-6is used to makes the equation stable.pr,pg,andpbare the RGB values of the brightest pixel, respectively.
2)Network Architecture: The network architecture of the color weight block is shown in Fig.8.It consists of seven convolutional layers.In these layers, the kernel size is set to 3×3 and the stride is set to 1.The final layer is activated by the sigmoid function to generate a weight map representing contribution.Each pixel of the weight map corresponds to the weight assigned to the corresponding pixel in the input image.
IV.EXPERIMENTS AND ANALYSIS
In this section, we report the implementation details, compared state-of-the-art methods,and publicly available datasets.Then, qualitative and quantitative comparisons with state-ofthe-art methods on several low-light image datasets are performed to validate the effectiveness of the proposed method.Besides, the intermediate results are shown to show the specific functions of three blocks.Finally, the ablation study,hyper-parameter analysis, and parameter comparison are conducted.

Fig.8.Framework of the color correction block.Achromatic estimation in this figure is the tile version of c by tiling it along the width and height of IZ.

Algorithm 1: Overall description of SLIE Notation: I: low-light image, A: attenuation map, IA:image after illumination adjustment, ~Z: noise in IA,IZ: image after removing the noise in IA, C: color shift, E: enhanced image 1.Model I as I=IA ⊗A=(EC+~Z)⊗A.2.Initialize parameters, i.e., attenuation network (θA),denoising network (θD), and color weight network(θC).3.Update θA by minimizing Lillu(θA) defined in (6) to generate A.4.Generate the brightened image IA =EC+~Z based on A and operations defined in Section III-B.5.Update θD by minimizing Lden(θD) defined in (11)to solve the denoising function D(·).6.Generate IZ =EC=D(IA).7.Update θC by minimizing Lcolor(θC) defined in (13)to generate the achromatic estimation c.8.Make color correction according to Section III-D to obtain E.
A. Implementation Details
The hyper-parameters are set toα=80 andβ=0.03.The batch size is 16.We use part of images in the AGLIE, SID,and LOL datasets for training,including 200 low-light images.These low-light images from several datasets are clustered together as a whole to build the training dataset.Patches of size 256× 256 are randomly cropped from images and flipped as training data.The steps to train the attenuation,denoising, and color weight networks are 5000, 3000, and 600, respectively.We use the AdamOptimizer with a learning rate exponential decaying from 0.0002 to 0.0001.The specific training procedure is summarized as Algorithm 1.Experiments are performed on an NVIDIA Geforce GTX Titan X GPU and 2.4 GHz Intel Core i5-1135G7 CPU.
B. Competitors and Datasets
We compare SLIE with state-of-the-art competitors, including three traditional methods (SRIE [20], LIME [41] and Robust Retinex [42]) and ten deep learning-based methods(RetinexNet [7], Zero-DCE [12], EnlightenGAN [10], CSDNet UPE [43], KinD++ [9], RUAS [44], DUNP [15], Diff-Retinex [45], CLIP-LIT [46], and NeRCo [47]).In these methods, Zero-DCE and DUNP are self-supervised methods.
To validate their generalization to various brightness, noise,and color shifts, we test them on four publicly available datasets, including AGLIE [48], See-in-the-Dark (SID) [5],MEF [49], and LIME [41].AGLIE is a synthetic dataset with a diverse exposure curve distribution and severe noise.SID contains indoor and outdoor raw short-exposure low-light images,which are darker due to less light during shooting and are contaminated by real noise.These images are illuminated by moonlight or street lights at night or taken in enclosed rooms with lights turned off and with faint indirect illumination.AGLIE and SID provide paired low-light and realistic reference images while MEF and LIME do not.
C. Qualitative Comparison
Qualitative comparison results on four datasets are shown in Figs.9-12.For each dataset,two intuitive examples are specifically reported.Compared with the competitors, SLIE shows three distinctive advantages corresponding to three blocks,i.e.,illumination adjustment, denoising, and color correction.
1) SLIE outperforms the competitors with more appropriate illumination.With the appropriate brightness, our results present more scene information which is more natural than the competitors.Specifically, as shown in the second examples in Figs.9 and 11, although some competitors can brighten the whole images to some extent, some dark regions have not yet been properly adjusted.The contents of these regions are still difficult to recognize and not conducive to the human visual system.In more extreme cases,for some images in the AGLIE dataset which are darker than images in other datasets, most competitors fail to brighten these images.As shown in the second example in Fig.10, for this extreme example, only a small number of competitors and our method can properly adjust the illumination.In these examples,our results are most similar to the ground truth.The reason is that when low-light and normal-light images are used for training, the network usually aims to learn the mapping from low illumination to normal illumination.The learned mapping is determined by the training data and may suffer from overfitting, resulting in inapplicability to various low light.In some decomposition methods, the accuracy of decomposition also influences the enhancement performance and details in enhanced results.By comparison, our self-supervised method only relies on the information in low-light images.It avoids the influence of overfitting, decomposition accuracy, and inappropriateness of selected reference images on the enhanced results.

Fig.9.Qualitative comparison on three images in the AGLIE dataset with state-of-the-art low-light image enhancement methods.For more intuitive comparison,some regions are highlighted and shown below the images.

Fig.10.Qualitative comparison on two images in the SID dataset with state-of-the-art low-light image enhancement methods.

Fig.11.Qualitative comparison on two images in the MEF dataset with state-of-the-art low-light image enhancement methods.

Fig.12.Qualitative comparison on two images in the LIME dataset with the state-of-the-art low-light image enhancement methods.
2) SLIE is more effective in suppressing noise in low-light images, whether real or synthetic noise.As shown in Fig.9,for severe synthetic noise in images of the AGLIE dataset,our results contain significantly less noise than other results.Also shown in the first examples in Figs.10 and 12, the low-light images suffer real noise, which is hidden in the dark and is more obvious after illumination adjustment.Some methods such as RetinexNet, EnlightenGAN, RUAS, and CLIP-LIT fail to remove the noise.Even compared with competitors consisting of denoising operations, such as RetinexNet and KinD++, our results still show smoother scenes and higher similarities with the ground truth.
3) Our results can remove the degradation caused by color shift.As shown in the first example in Fig.9, the second examples in Figs.10 and 12, and the first example in Fig.11,the low-light images suffer from color shifts.Some are caused by the improper settings in the camera’s ISP (e.g., Figs.9 and 10) and some are caused by the light color (e.g., Figs.11 and 12).By comparison, SLIE can correct the color shifts and represent the original color of the scenes at normal color temperature.Specifically, the colors of examples in Figs.9 and 10 are similar to those of ground truth.It should also be emphasized that the formulation of color correction module assumes that the color shift is caused by improper rendering parameters in the ISP or wide range of ambient lighting and thus,is globally consistent.The color shifts shown in Figs.9-12 illustrate this situation.When the color cast is caused by local ambient lighting,the assumption and formulation are not entirely in line with the actual situation.
4) As a self-supervised method, the comparison results of the proposed SLIE and the self-supervised competitors (i.e.,Zero-DCE and DUNP) are further analyzed.As shown in the results in Figs.9 and 10, Zero-DCE can brighten low-light images through its estimated set of light-enhancement curves.However, the estimated curves depends on the quality of lowlight images.When the input image is extremely dark, the curves fail to adjust the illumination well, as shown in its results in Fig.10.Besides,the noise and color shift are ignored in Zero-DCE, resulting in residual degradations in the results.DUNP exploits untrained neural networks priors for enhancing low-light images with noise.The enhancement is done by jointly optimizing the Retinex decomposition and illumination adjustment.However, it introduces artifacts in Fig.11 and uneven illumination adjustment in Fig.10.By comparison,our method shows better enhancement performance in a selfsupervised mechanism.
Remark 1: Low-light images captured by mobile phone.The low-light images in the above datasets are captured by professional cameras.In real scenarios, there are also situations where the low-light images are captured by mobile phones in dark environments, such as during nighttime.We also compare the effectiveness of different methods on these images.The low-light images provided in the LSRW dataset[50], which are captured by the Huawei mobile phone are used for evaluation.The results on two scenes are shown in Fig.13.As can be seen from the results, our results exhibit more uniform brightness than the results of other methods.In this case, more scene content can be reflected in our results.Moreover,the colors of our results are more vibrant and bright,which is evident in the second group of results.The results on low-light images captured by a mobile phone further confirm the generalization of our method and its applicability in actual scenarios.
D. Quantitative Evaluation
We use both full-reference and no-reference metrics for objective evaluation.The AGLIE and SID datasets contain corresponding normal-light images that can be taken as ground truth.Full-reference metrics include peak signal-to-noise ratio(PSNR), structural similarity index measure (SSIM), visual information fidelity (VIF) [51] and lightness order error(LOE) [52].These metrics measure the similarity between the result and ground truth.PSNR is the ratio of peak value power and noise power by measuring the intensity differences between the enhanced image and ground truth.Thus, it can reflect distortions.SSIM denotes the structural similarities by measuring three components, including distortions of correlation and luminance and contrast distortion.VIF measures the information fidelity of the result and is consistent with the human visual system.LOE uses the relative lightness order to measure the naturalness of the enhanced image.The larger PSNR, SSIM and VIF are, the closer the result is to the ground truth.The lower the LOE, the more the enhanced image preserves natural lightness.

TABLE I QUANTITATIVE RESULTS ON THE AGLIE AND SID DATASETS WITH FULL-REFERENCE METRICS.MEAN AND STANDARD VARIATION ARE SHOWN(RED: OPTIMAL,BLUE: SUBOPTIMAL)
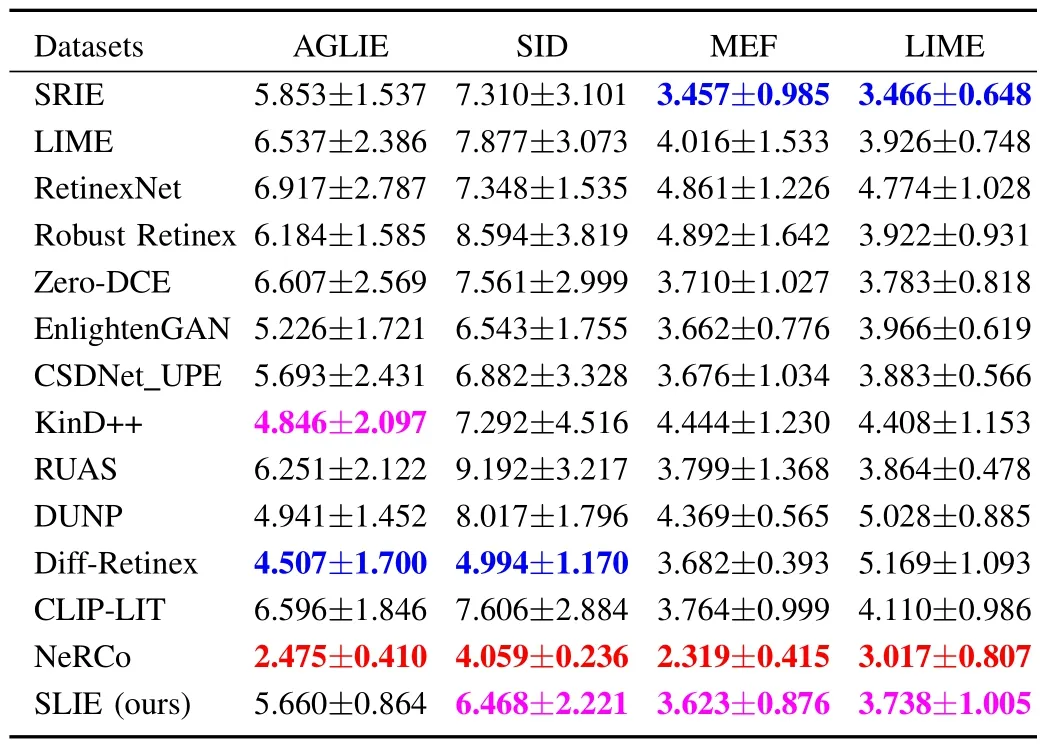
TABLE II QUANTITATIVE COMPARISON ON THE AGLIE, SID, MEF AND LIME DATASETS EVALUATED BY NIQE (RED:OPTIMAL, BLUE: SUBOPTIMAL,PINK: THIRD-OPTIMAL)
The statistic results tested on the AGLIE and SID datasets are reported in Table I.From this table, it can be concluded that SLIE outperforms other methods with obvious superiority in most cases.It is consistent with the visual effects in Figs.9-10 as our results show less noise and color distortion.
For the MEF and LIME datasets, there are no available normal-light images for reference.In this case, we adopt the natural image quality evaluator (NIQE) [53] to evaluate the enhancement performance.NIQE calculates the distance between the multivariate Gaussian (MVG) model parameters of the enhanced result and the pre-obtained model parameters of natural images.A lower NIQE indicates better image quality.This metric is additionally used to evaluate the results on the AGLIE and SID datasets.The results on the metric are reported in Table II.For the metric NIQE, our method achieves the third-optimal results on the SID, MEF, and LIME datasets and comparable results on the AGLIE datasets.These quantitative results show that our results can exhibit satisfactory natural qualities.The comparable results of our method on multiple datasets also demonstrate comparable generalization of the proposed SLIE.
E. Effectiveness of Each Block
1)Intermediate Results: Qualitative intermediate examples are presented in Figs.14-16 to show the effectiveness of the three blocks.As shown in Fig.14, the estimated attenuation maps contain few texture details.The edges mainly exist at the junctions of bright and dark regions of low-light images.In the attenuation maps, the dark regions help brighten the under-exposed regions and its smoothness avoids textures being weakened after adjustment.The bright regions avoid the overexposure of corresponding regions in low-light images.Fig.15 and 16 validate the effectiveness of the denoising and color correction blocks, respectively.Their results are in accordance with the human visual perception system.

Fig.14.Qualitative intermediate results to validate the effectiveness of the illumination adjustment block.

Fig.15.Qualitative intermediate results to validate the effectiveness of the denoising block.

Fig.16.Qualitative intermediate results to validate the effectiveness of the color correction block.
2)Ablation Study: In order to validate the effectiveness of each block,we compare the enhanced results with and without each block.The qualitative results are shown in Fig.17.Without the illumination adjustment block, the result still suffers from poor visibility due to low brightness while noise is significantly alleviated.Without the denoising block, the result shows brighter illumination while the visual effect is still affected by the noise.Without the color correction block,even though the image quality has been greatly improved, the overall tone of the image is still abnormal, appearing reddish.Under the combined effect of all the three blocks,the enhanced result exhibits optimal image quality and visual effect.
3)Application of the Proposed Denoising/Color Correction Block(s)to Previous Methods: We further validate the effectiveness of the proposed denoising and color correction blocks by applying them to some state-of-the-art enhancement methods.As for the competitors mentioned in Section IV-B,if some competitor fails to consider image denoising, we incorporate this method with the proposed denoising block.Similarly, if color correction is not considered, the proposed color correction block is also incorporated.For these competitors, the details of incorporation are reported in Table III.For methods such as SRIE and EnlightenGAN which consider both image denoising and color correction, we use their original version for comparison and do not apply incorporation.
Some qualitative results are shown in Fig.18 where the first row shows the original results of some competitors.The second row provides the results by applying the denoising/color correction block(s) to these competitors.By incorporating the denoising block, LIME and Zero-DCE show clearer scenes and less noise.Moreover, there is obvious red color cast in the original results of LIME,RetinexNet,Robust Retinex,and RUAS compared with the result of Zero-DCE.It is inconsistent with the tone that this scene should have.By applying the color correction block to these methods, their results shows more normal colors then the original results.
The quantitative experiment is performed on the AGLIE dataset which contains the ground-truth enhanced images.The quantitative results before and after incorporating our block(s)are reported in Table III.By applying the denoising/color correction block(s), all the incorporated competitors show improvements in SSIM and PSNR, demonstrating better enhancement performance.On this basis,the proposed SLIE still shows better performance than the incorporated competitors.It further illustrates the effectiveness and superiority of the proposed illumination adjustment block.
F. Ablation Study and Hyper-Parameter Analysis
We regularize the illumination adjustment loss withLsmooth(θA) in (6).We perform the ablation study to verify its impact and setαto 10,30,50,80 and 120 for hyper-parameter analysis.As shown in Fig.19(a), when not introducing the smoothness loss(α=0),the maps are similar to original gray low-light images.The abundant details in the maps smooth the brightened results.Asαincreases, the attenuation maps only retain large luminance differences and its local smoothness enables brightened images to present more details.However,whenαis large enough to makeLsmooth(θA) dominant, the maps are almost globally consistent,resulting in inappropriate adjustment in some local regions.For the results ofα= 30,50 and 80, the differences between the brightened images are unnoticeable, so we also report quantitative comparison as in Fig.19(b).Through quantitative analysis, we setα= 80 in our method.
G. Efficiency and Parameter Comparisons
The running time of methods tested on the four publicly available datasets are reported in Table IV.The traditional methods are tested on a desktop with 2.4 GHz Intel Core i5-1135G7 CPU.The deep learning-based methods are tested on an NVIDIA Geforce GTX Titan X GPU.The reoptimization of each image and the large iteration number in DUNP [15]brings a main computational burden.Thus, the computational cost of DUNP for each image is over ten minutes or up to tens of minutes, significantly longer than other methods.Similarly,Diff-Retinex requires a few seconds of inference time for each image.As shown in this table,even though the proposed SLIE consists of three main blocks,it still performs with suboptimal efficiency, only second to CLIP-LIT.

Fig.17.Qualitative results with only two blocks active.

Fig.18.Qualitative results of state-of-the-art enhancement methods before and after incorporating the proposed denoising or/and color correction block(s).

TABLE III QUANTITATIVE COMPARISON OF INCORPORATING DENOISING/COLOR CORRECTION BLOCK(S) WITH COMPETITORS ON THE AGLIE DATASET

TABLE IV MEAN COMPUTATIONAL COST COMPARISON ON FOUR PUBLICLY AVAILABLE DATASETS(S)
For all deep learning-based enhancement methods, we plot the corresponding relationship between parameter numbers and performance in Fig.20 to visualise the impact of increased parameter numbers on performance improvement.The proposed method shows the fifth least parameter number, which is more than those of RUAS, DUNP, Zero-DCE, and CLIPLIT.Slightly more parameters in our method are caused by three blocks for different purposes.However, in the vertical dimension, SLIE exhibits significant performance advantages over these methods.Therefore, our method realizes a better balance between computational complexity and performance.
V.LIMITATIONS AND FUTURE WORK
The proposed method performs color correction based on the assumption that the brightest pixel in an image should not contain color shift.The RGB values of this pixel should be as identical as possible.However, the individual pixel has randomness.It can largely but not completely accurately represent color shift.In future work, it is expected to improve the stability of color correction through statistical values.Moreover, the computational complexity of the proposed method is higher than some competitors and the reason is that the proposed method contains three different networks to address different types of degradations.From the perspective of reducing complexity, it may be possible to use a backbone to extract various features.On this basis, degradation/taskspecific headers can be connected to achieve output for different degradations, thereby reducing the parameter numbers.
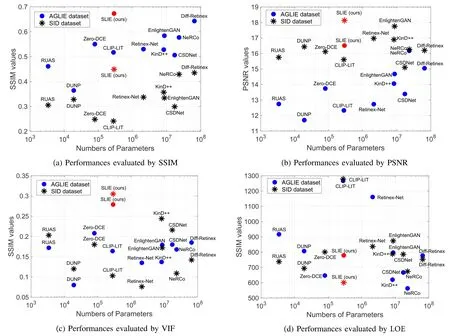
Fig.20.Performance and parameter comparisons of deep learning-based methods.
VI.CONCLUSION
We propose a self-supervised network for low-light image enhancement, termed as SLIE.It is a self-supervised network which only relies on low-light images for training and does not require external information from paired/unpaired multiexposed images.Specifically, we model the degradation in low-light images as illumination attenuation, noise pollution,and color shift and design three blocks to remove these degradations.An illumination adjustment block estimates attenuation maps based on the light intensity, scene geometry,and local smoothness of low-light images for illumination adjustment.A denoising block copes with complex and severe noise.A color correction block corrects color shifts and restores the original color in natural light.Extensive experiments conducted on four publicly available datasets demonstrate the superiority of SLIE over twelve state-of-theart competitors.Finally, SLIE achieves a balance between parameters and performance as it shows better enhancement performance while using fewer parameters than most existing deep enhancement networks.
杂志排行

IEEE/CAA Journal of Automatica Sinica的其它文章
- A Dual Closed-Loop Digital Twin Construction Method for Optimizing the Copper Disc Casting Process
- Adaptive Optimal Output Regulation of Interconnected Singularly Perturbed Systems With Application to Power Systems
- Sequential Inverse Optimal Control of Discrete-Time Systems
- Set-Membership Filtering Approach to Dynamic Event-Triggered Fault Estimation for a Class of Nonlinear Time-Varying Complex Networks
- Dynamic Event-Triggered Consensus Control for Input Constrained Multi-Agent Systems With a Designable Minimum Inter-Event Time
- A Novel Disturbance Observer Based Fixed-Time Sliding Mode Control for Robotic Manipulators With Global Fast Convergence