采用改进被囊群算法的多冷水机组负荷分配优化
2024-02-29王华秋秦思危
王华秋,秦思危
(重庆理工大学 两江人工智能学院,重庆 401135 )
0 引言
中央空调系统广泛应用于建筑领域,是建筑最主要的耗能单位之一,可占总能耗的60%[1]。多冷水机组是中央空调系统的核心部件,系统的大部分能耗也由其产生。由于中央空调系统一般按照建筑需求的最大负荷设计,大部分时间段多冷水机组都是以部分负荷的状态运行,存在能效低下、耗能增加的问题[2]。因此在满足制冷需求的前提下,对多冷水机组的运行进行优化控制,以达到降低能耗的目的,是建筑节能的重要课题。
多冷水机组由大于或等于2台的冷水机组组成,往往存在各冷水机组型号、性能和容量各不相同的情况,同时冷水机组在不同负荷率下的运行能效也各不相同[3]。因此在讨论系统最优运行方式之前,需要对冷水机组的能效关系进行建模。当前冷水机组能效模型的建立主要有经验模型和数据模型两种方法[4]。经验模型包括基于物理规律的Gordon-NG模型[5]、Lee模型[6]等;以及以统计分析为基础的二次线性BQ模型[7]、多元多次回归MP模型[8]等。此类经验模型的结构相对复杂,在实际运行数据上拟合精度较低,因此近年来学者们的研究更倾向于以数据挖掘、机器学习为代表的数据模型,如Chen等[9]应用BP神经网络针对冷冻水供水温度和冷却水进出水温度建立机组的能耗预测模型;周璇等[10]使用粒子群算法改进的SVR对冷水机的运行能效进行预测;王香兰等[11]使用Apriori算法挖掘冷水机组运行参数和最低能耗的关联规则。
建立能效模型之后,需要解决多冷水机组在目标制冷需求下的最优负荷分配(OCL,optimal chiller loading)问题,以达到节省能耗的目的。Chang[12]使用拉格朗日乘数法求解OCL问题,但该算法在末端制冷需求较低时存在无法收敛的情况。为了避免此类情形,一系列智能优化算法被应用于OCL问题,如遗传算法(GA,genetic algorithm)[13]、粒子群算法(PSO,particle swarm optimization)[14]、布谷鸟搜索算法(CS,cuckoo search)[15]等。经典的智能优化算法虽然能够克服无法收敛的问题,但也存在寻优精度低、收敛速度慢和容易早熟等缺点。
综合上述情况,本文使用一种随机森林(RF,random forest)特征优选结合极限学习机(ELM,extreme learning machine)的方法搭建冷水机组能效的回归预测模型;并提出一种混合策略改进的被囊群算法(ITSA,improved tunicate swarm algorithm),在能效模型的基础上,优化多冷水机组的启停状态和负荷分配,使系统以最佳运行状态满足末端的制冷需求,降低中央空调系统运行能耗。
1 冷水机组能效预测模型
1.1 研究对象
本文研究对象为某卷烟厂生产车间的中央空调水循环系统,包括4台并联离心式冷水机组、冷冻水循环系统、冷却水循环系统、冷却塔以及末端空调设备,系统结构如图1所示。
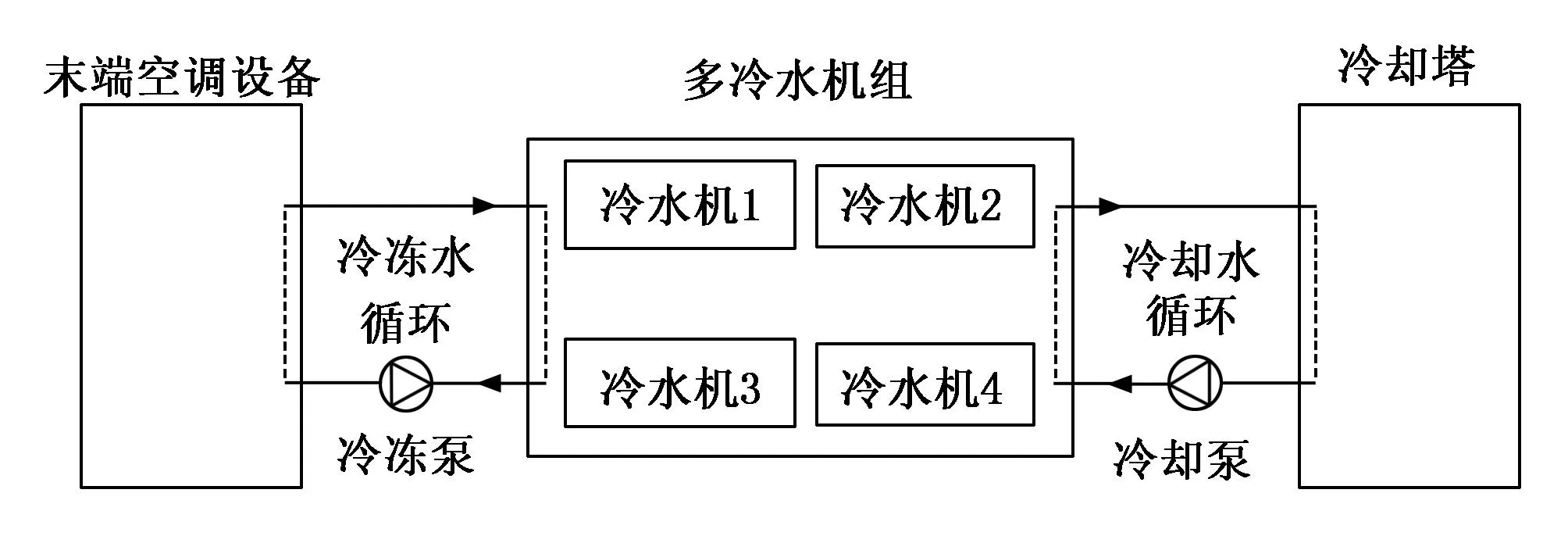
图1 中央空调水循环系统结构
能效比(COP)是评价冷水机组性能的重要指标,即制冷量与运行功率的比值。表达式如下:
(1)
其中:Q为制冷量;p为运行功率。冷水机组运行时的COP越大,制冷效率越高,相同制冷量下消耗的能量越低。
1.2 随机森林的特征优选
文献[16-17]研究表明,COP最主要受机组负荷率(PLR)影响,同时也可能受如冷冻水循环、冷却水循环内的其他运行因素的影响。如表1所示中央空调系统有诸多运行参数,具有复杂性、非线性的特点,同时各参数之间存在复杂的交互关系,因此建立针对COP的回归预测模型之前需要对原始数据进行特征优选。

表1 中央空调系统运行参数
随机森林(RF)是一种多棵决策树组成的集成学习算法,利用Bagging方法随机可重复地抽取约占总数三分之二的样本用于训练构建决策树,剩余三分之一的样本称为袋外数据(OOB),用以误差估计以及计算各特征的重要程度MDA[18]。针对特征X计算以决策树i为起点的OOB误差ε1,随后将噪声随机添加到OOB数据样本的特征X中,重新计算每棵树的OOB误差ε2,则特征X在第i棵决策树的MDA值为:
MDAi(X)=ε2-ε1
(2)
具有N棵决策树的随机森林中特征X的重要性程度可以表示为:
(3)
在冷水机组能效预测模型中,通过特征的MDA值进行重要性排序,剔除冗余特征,构建新的低维有效特征集。
1.3 核函数极限学习机
极限学习机[19](ELM)是一种前馈式的单隐层的神经网络模型,结构如图2所示,数学模型如下:
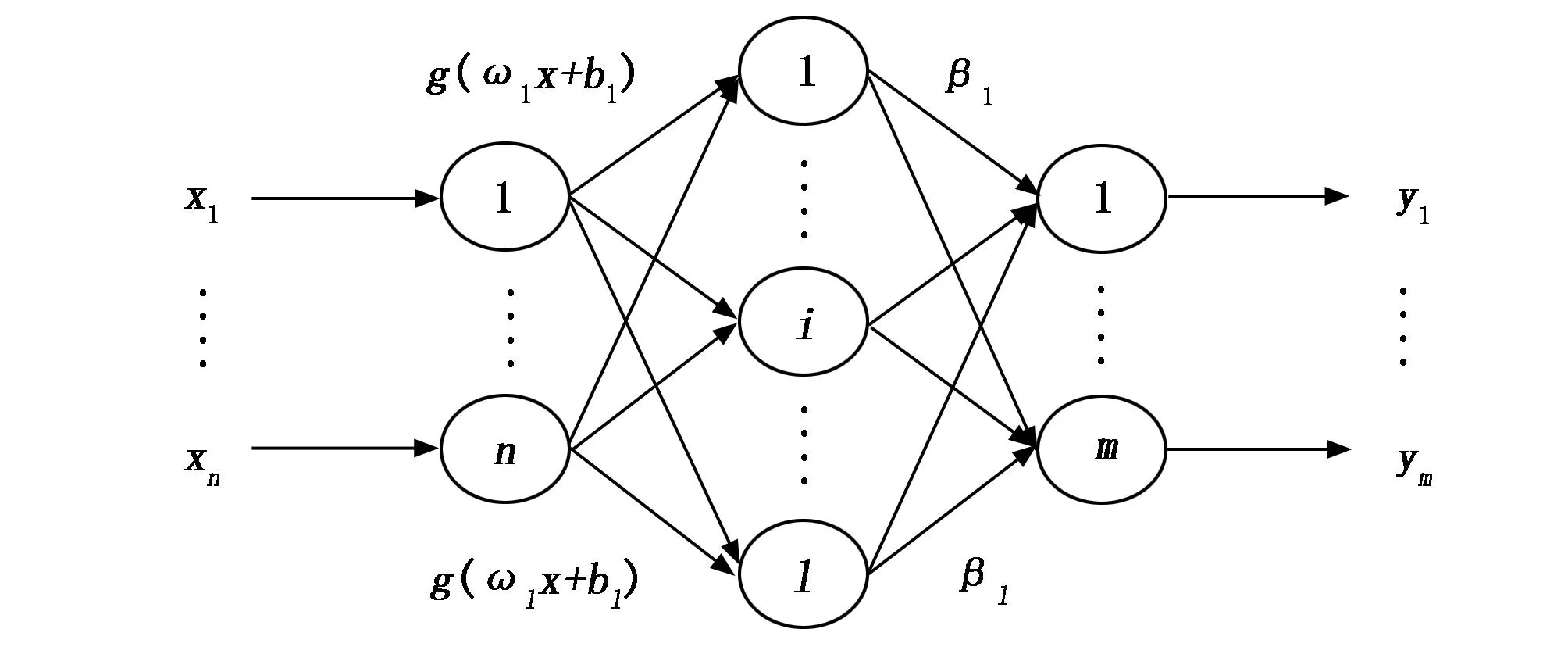
图2 极限学习机结构图
f(x)=h(x)β
(4)
给定ELM数量为N的训练样本(X,Y),X为输入矩阵,Y为对应的期望输出矩阵。
(5)
则输入层神经元数量为n,输出层神经元数量为m,隐含层神经元数量为l以及激活函数为g(x)的极限学习机可表示为:
Hβ=T
(6)
其中:
(7)
wi=[wi1,wi2,… ,win]T为输入层神经元与第i个隐含层神经元的连接权值;bi为第i个隐含层神经元的偏置;β=[β1,β2,… ,βl]T为隐含层与输出层之间的连接权值;T为输出矩阵。
极限学习机的训练目标是计算系统Hβ=T的最小二乘解β,使得输出T和期望输出Y之间的误差趋近于0。
β=H⊕O=HΤ(HHΤ)-1O
(8)
核函数极限学习机[20](KELM)通过引入核函数替代原激活函数进一步提高模型的泛化能力和稳定性,模型的输出如下:
f(x)=h(x)HΤ(1/C+HHΤ)-1O=

(9)
其中:K为所选的核函数,C为惩罚系数。
本文选取RBF函数作为KELM的核函数,定义如下:
(10)
1.4 冷水机能效预测模型训练流程
1)冷水机组的原始运行数据归一化处理。
2)使用随机森林算法对各特征进行MDA重要性排序。
3)根据重要程度依次递增特征个数构建特征子集。
4)将不同特征数量的特征子集输入到KELM中,训练以能效比COP为输出的回归预测模型。
5)比较KELM测试集精度选取最优特征子集作为模型输入,从而建立冷水机组的能效预测模型。
2 混合策略改进的被囊群算法
2.1 基本被囊群算法
被囊群算法(TSA)[21]是一种启发自海洋被囊动物觅食行为的新型优化算法,通过模拟被囊动物觅食过程中的喷气推进过程和种群交互行为来达到求解最优的目的。
被囊动物在喷气推进前需避免与其他相邻个体之间的搜索冲突,通过向量A计算位置:
(11)
其中:c1、c2、c3是[0,1]范围内均匀分布的随机数。Pmin和Pmax为被囊动物个体相互作用的最小速度和最大速度,一般取值为1和4。
在避免搜索冲突之后被囊动物向最优个体靠近:
PD=|Pbest-rand·P(t)|
(12)
(13)
其中:PD为当前个体与食物的距离,Pbest为最优值的位置,P(t)为个体的位置,rand为[0,1]范围内均匀分布的随机数。最后算法从数学上模拟被囊种群的群体行为,根据前一代最优解和当前最优解更新个体位置:
(14)
2.2 被囊群算法的改进
2.2.1 鲸鱼搜索策略
鲸鱼优化算法(WOA)[22]的鲸鱼个体通过螺旋前进的方法靠近猎物,表达式如下:
X(t+1)=Xbext+|C·Xbext-X(t)|·eblcos(2πl)
(15)
其中:Xbest为猎物位置;b为常数,控制螺旋前进的形状;l为分布在[-1,1]的随机数;C为矩阵系数。
被囊个体的搜索方式相对单一,觅食活动缺乏机动性和灵活性。本文将WOA的螺旋前进方式引入被囊群算法中的式(13),使个体在向食物靠近时能以一定概率螺旋前进,改进后的式(13)如下所示:
(16)
通过引入WOA的螺旋前进方法,可以增加算法搜索方式的多样性,减少出现早熟收敛的风险,同时扩大了搜索范围,提高算法的搜索能力。
2.2.2 非线性动态权重
被囊群算法中的群体行为是单次迭代中个体更新位置的主要方式之一,更新步长越大,算法的全局探索能力越强;步长越小,算法的局部开发能力越强。从式(14)可以看出,其步长大小主要受随机数c1的影响,因此算法在种群行为阶段具有一定的盲目性。本文引入一种在[0,1]范围内非线性递增的动态权重来代替c1,平衡算法的全局探索性和局部开发性,如下式所示:
(17)
其中:t为当前迭代次数;T为最大迭代次数;a为调节因子,控制权重的上升速度。更新后的式(14)如下所示:
(18)
引入动态权重之后,迭代初期w偏小,个体更新步长大,全局探索能力较强;迭代中后期w增大,个体更新步长减小,局部开发能力增强。
2.2.3 空翻扰动策略
针对被囊群算法在迭代中后期易陷入局部最优解的问题,受文献[23]启发,引入一种空翻的觅食策略对被囊动物个体进行扰动,表达式如下:
(19)
其中:S为空翻因子,控制个体空翻的相对距离;r1和r2是范围为[0,1]的随机数。
在被囊群算法种群行为之后,按照0.5的概率对被囊个体进行空翻扰动,让个体空翻到当前最优解的对面,保留更优的位置。与反向学习策略[24]类似,空翻策略扰动当前解的位置,寻求一个新的更优搜索域,以达到跳出局部最优解的目。但与反向学习单一的变化方向不同,空翻策略是围绕最优解进行空翻,有更强的寻优能力,同时随着个体和最优解之间的距离减少,空翻扰动的范围也在缩小,有更强的收敛性。
2.3 改进被囊群算法的运行流程
本文融合鲸鱼算法的螺旋搜索改进个体更新方式,提高算法搜索能力;使用动态权重平衡全局探索与局部开发;应用空翻扰动策略避免算法陷入局部最优。混合策略改进的被囊群算法流程如图3所示,具体流程如下:
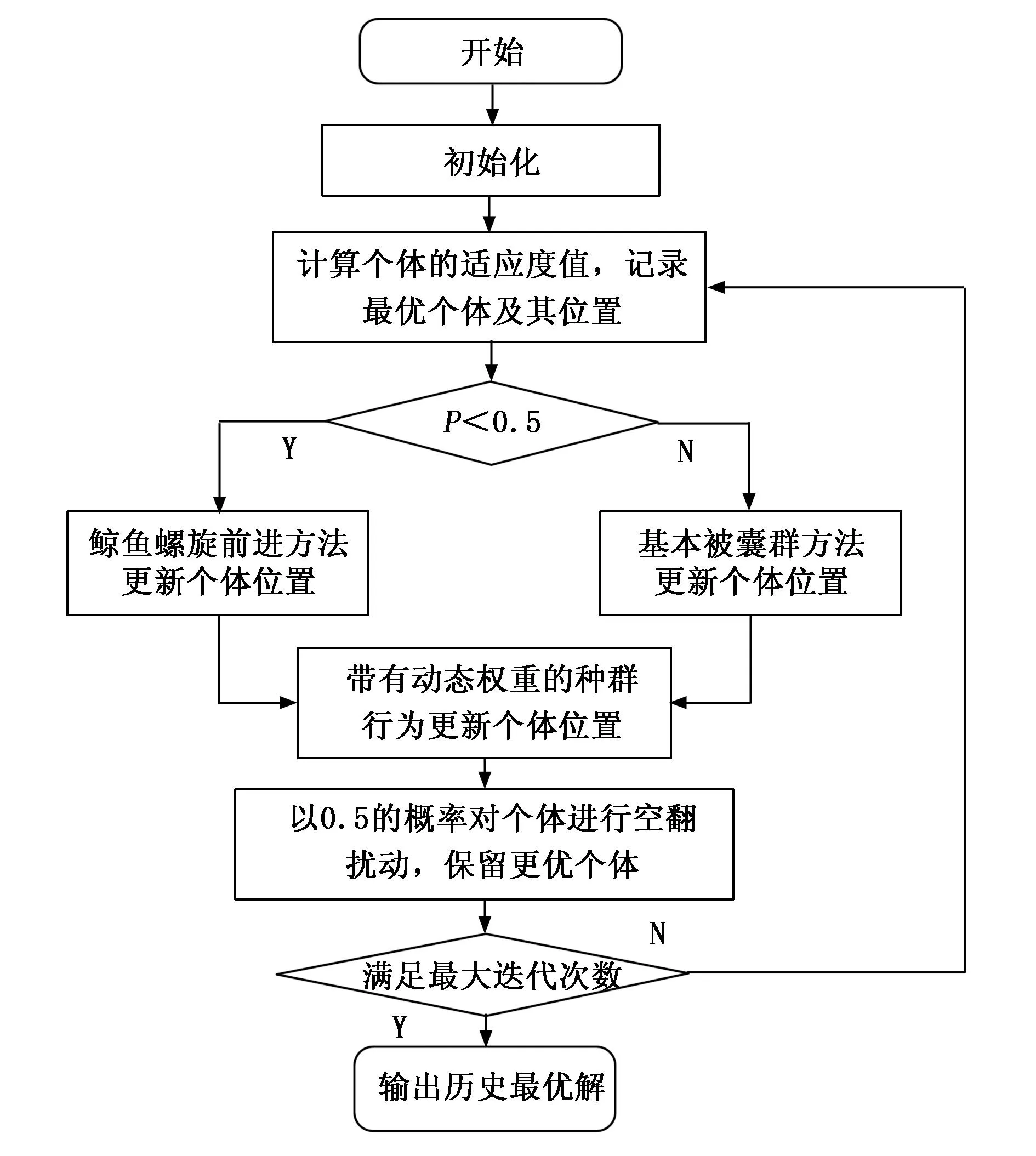
图3 混合策略改进被囊群算法流程图
1)参数初始化。初始化种群规模、最大迭代次数、解空间维度、边界条件等。
2)种群初始化。
3)计算个体的适应度值。
4)根据式(16)融合螺旋搜索的方式更新个体位置。
5)根据式(17)、(18)种群行为更新个体位置。
6)根据式(19)进行空翻扰动,保留更优个体。
7)如果满足停止条件则输出历史最优解,否则返回步骤3)。
3 多冷水机组负荷分配优化
中央空调系统中OCL问题的优化对象为冷水机组的负荷率PLR,即在满足中央空调末端制冷需求的条件下,求解一组最优的冷水机组负荷率使系统总能耗最低。为了避免机组在低负荷率运行下的不稳定性以及超负荷运行造成的损害,将PLR的下限设置为0.3,上限设置为1,则优化的目标函数如式(20)所示:
s.t. 0.3≤PLRi≤1 orPLRi=0,
(20)
其中:P为系统总功率,Q0为冷水机组的额定制冷量,Qneed为中央空调系统末端需求的总制冷量,N为并联冷水机组的总台数。
分析式(20)可知,目标函数存在非凸约束,直接对其求解无法保证得到收敛解。因此将惩罚函数引入其中,构建凸约束目标函数:
s.t. 0.3≤PLRi≤1 orPLRi=0,i=1,2,3,…,N
(21)
其中:ρ为惩罚参数。惩罚函数可以衡量违背约束程度,违背约束越大,惩罚函数值越大;违背约束越小,惩罚函数值越趋近于0。
对多冷水机组进行负荷分配时,系统当前的运行工况参数均为已知,因此仅需要向各机组的能效预测模型提供负荷率PLR,即可求得机组在当前工况下该PLR对应的COP,进而计算出系统的总能耗和总制冷量。本文利用ITSA以式(21)为目标函数对各机组的PLR进行寻优,优化多冷水机组的负荷分配,使系统以最优功耗的运行状态满足制冷需求,运行流程如图4所示。
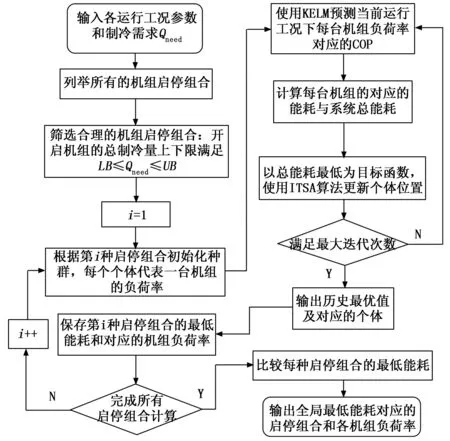
图4 负荷分配优化流程图
首先向算法输入系统的当前运行工况参数以及末端制冷需求Qneed;然后使用穷举法列举出机组启停组合的所有情况,判定每种情况中开启的冷水机组总制冷量的上下限是否满足制冷需求,从而筛选出合理的机组启停组合;之后在KELM能效预测模型的基础上,利用ITSA求解每种合理组合下的最优负荷分配及能耗;最后比较各种启停组合的最低能耗,按照贪心原则选出全局最优,输出对应的启停组合和机组负荷率,即可作为系统的控制参数。
4 实验结果及分析
4.1 实验环境设置
仿真实验软件为Matlab R2021b;操作系统为64位Windows 10系统;处理器为Intel® CoreTMi7-11800H,主频为2.30 GH。
4.2 冷水机组能效预测模型
本文以该卷烟厂生产车间并联多冷水机组中1号冷水机组为例,采集机组运行参数2 150组,并随机打乱。使用随机森林算法计算每种运行参数的MDA值,评价其在能效比COP回归预测中的重要性程度。为了避免实验的偶然性,独立运行50次,取MDA的平均值为最终的特征重要度,结果如图5所示。
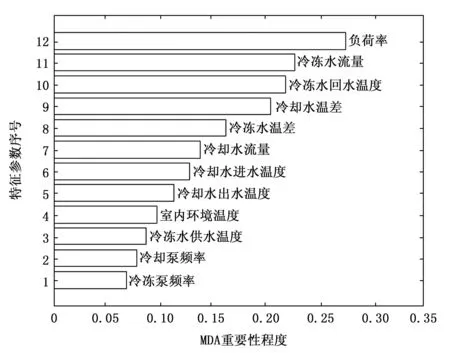
图5 特征参数重要性排序
按照特征重要性程度优先的顺序,依次递增的方式增加特征个数构建特征子集,输入到KELM中训练模型。按照9∶1的比例分配训练集和测试集,选用均方根误差RMSE、平均绝对百分比误差MAPE两个指标进行评价:
(22)
(23)
各特征数量的特征子集训练的KELM在测试集上预测误差结果如图6所示。
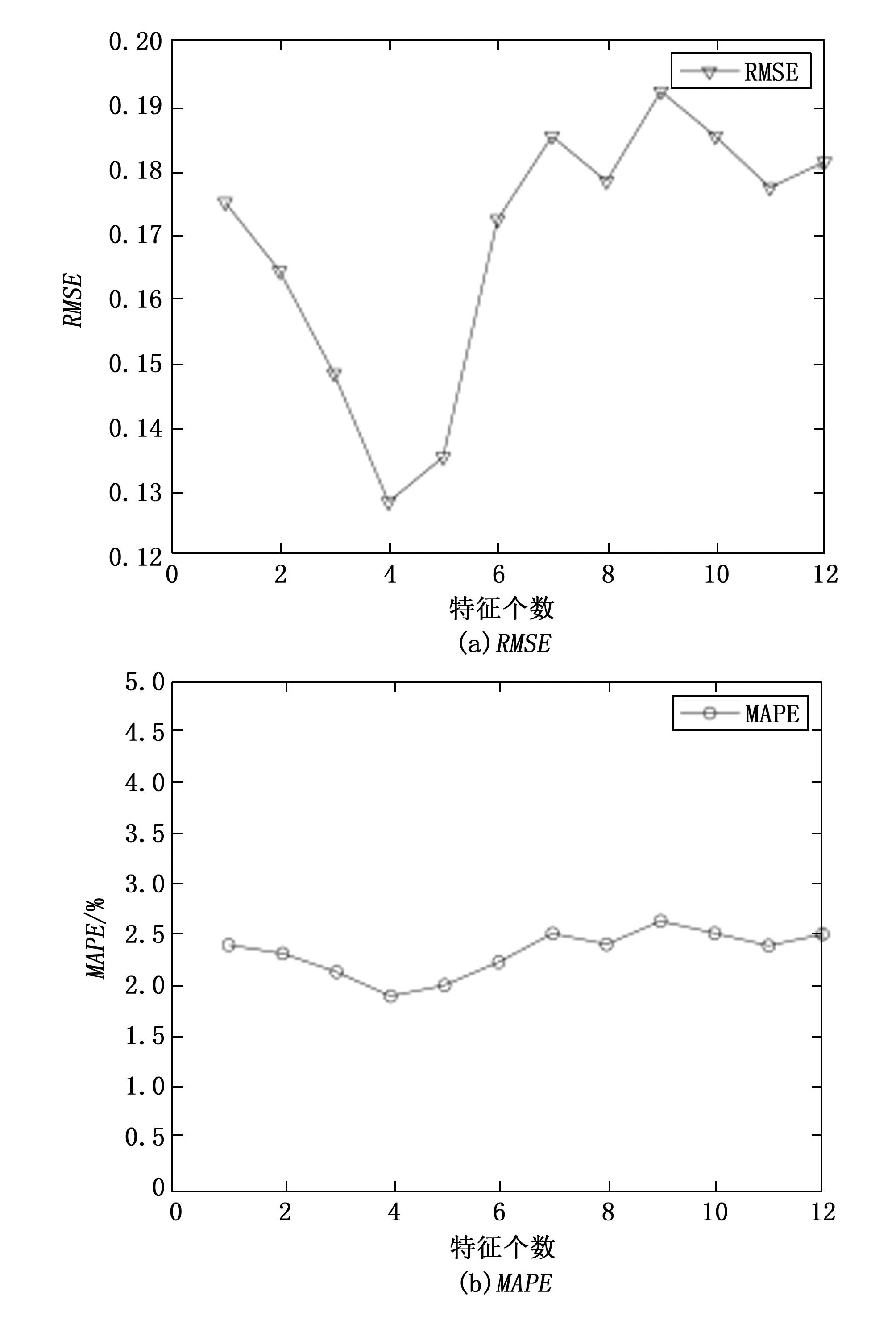
图6 不同特征数量的特征集测试集误差
由图6可知,特征数量为4的特征子集在KELM的预测误差最低。由于冗余特征影响,回归预测的误差不会因为特征集中的特征个数增加而持续降低,甚至由于输入维度变高导致模型复杂性升高、稳定性下降。因此冷水机组的能效预测模型选用特征重要性程度前4位的运行参数作为模型输入,即负荷率、冷冻水流量、冷冻水回水温度及冷却水温差。
为了验证KELM在冷水机能效预测中的先进性,以构建的最优特征集为数据集,将ELM、文献[10]中的PSO-SVR以及长短期记忆网络LSTM模型[25]与KELM做出对比。ELM和KELM的神经元个数设置为20;PSO-SVR参数与引文一致;设置LSTM隐含层数为1,隐含层节点个数为20。4种模型的测试集的RMSE、MAPE以及预测耗时结果如表2所示。

表2 预测模型测试集实验结果
从表2可以看出,KELM相比其他模型在测试集上预测误差更低。同时相比精度接近但结构更为复杂的LSTM网络,极限学习机网络的预测用时明显更少。由于后续负荷分配算法迭代的过程中需大量调用模型预测各机组的能效比COP,因此速度更快、精度更高的浅层网络KELM更能适配系统控制的需求。
4.3 被囊群算法改进的有效性验证
验证针对基本被囊群算法改进策略的有效性,如表3所示,选用6个不同特点的基准测试函数作为目标函数,验证算法的寻优精度、收敛速度和跳出局部最优能力。其中F1~F3为单峰函数,F4~F6为多峰函数。各测试函数的理论最优值均为0。
同时检验改进算法的先进性,将ITSA与TSA、PSO[26]、GWO[27]和WOA等算法做出对比,各算法的主要参数如表4所示。

表4 算法主要参数设置
统一设置种群数量N=30,最大迭代次数T=500,解空间维度D=30。每种算法针对各目标函数独立运行50次,使用平均值、标准差和最优值等指标评价。运行结果如表5所示,其中加粗的表示最优结果;同时为了直观地表现出各算法的寻优精度和收敛速度,画出每种算法的收敛曲线,如图7所示。

图7 基准测试函数收敛曲线
从表5可以看出,ITSA的寻优能力总体上要优于其他4种算法,无论是单峰函数还是多峰函数,ITSA的各项评价指标均较为理想,均优于其余4种算法。在单峰函数中,ITSA能够直接求解到F1和F3的理论最优值,同时对于F2,ITSA相比改进之前的TSA在最优解数量级上有了明显的提升;在多峰函数中,虽然ITSA、TSA、WOA等算法的最优值在F4和F6达到了理论最优,但ITSA的平均值和标准差要远优于其他算法,说明ITSA具有更强的寻优能力和稳定性;而对于F5,5种算法均陷入局部最优,但ITSA仍具有数量级上的优势。
从图7收敛曲线可以看出,ITSA有更优的收敛速度和收敛精度,其收敛曲线下降得更快,而其他算法均明显出现了不同程度的停滞,表明ITSA有更强的跳出局部最优的能力。
综上,ITSA相比改进前的TSA及其他3种算法在寻优精度、收敛速度、稳定性和跳出局部最优等多方面均有明显优势,说明本文提出的混合策略改进方法有效。
4.4 多冷水机组负荷分配优化
该卷烟厂生产车间的多冷水机组系统负荷分配方法为平均负荷法(AVL),即每台机组负荷率始终保持相同。本文以该车间4台并联离心式冷水机组实际运行数据为例,对比平均负荷法与本文提出算法在目标制冷需求下的运行能耗,验证本文提出算法的有效性,多冷水机组的额定性能参数如表6所示。首先从样本数据中选取4组运行数据作为算法输入,分别为制冷需求占系统最大制冷量90%、80%、70%、60%情况下的运行工况,然后使用平均负荷法和本文提出算法对这4种情况下的多冷水机组进行负荷分配,计算系统的总能耗。仿真实验结果如表7所示,系统总COP如图8所示。
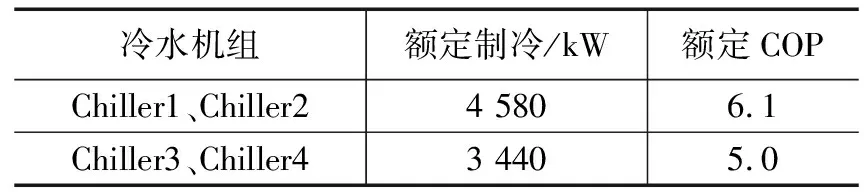
表6 冷水机组额定性能参数
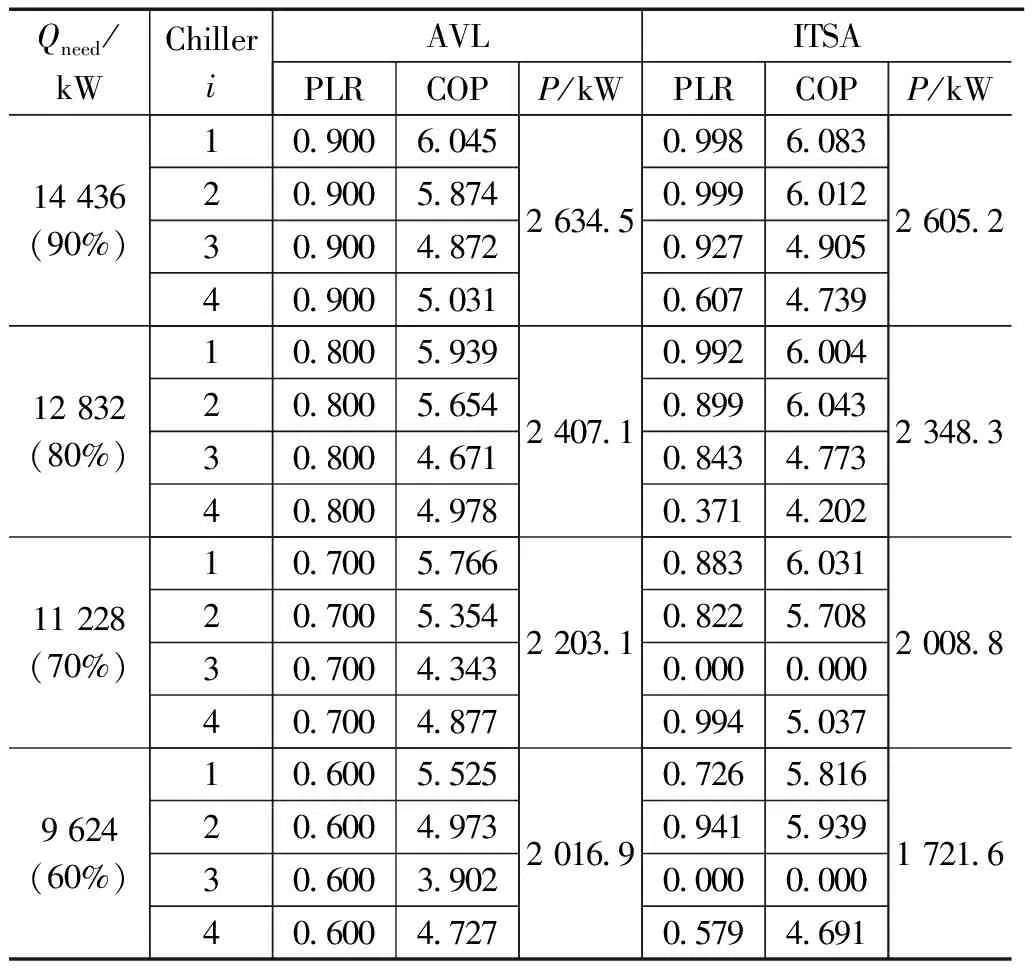
表7 负荷分配优化仿真实验结果

图8 系统总COP
从表7可以看出,本文算法相比平均负荷法在各种制冷需求下均能节省一定的能耗,可以有效发掘多冷水机组的节能潜力。在90%和80%的高负荷需求下,算法开启全部4台机组,并将负荷更多的分配于制冷量更大、COP更高的1号机组和2号机组,从图8可以看出此时的系统总COP有明显提升。
而当制冷需求处于70%和60%的较低水平时,机组负荷率降低导致各机组的COP降低,平均负荷法中系统总COP明显下降,此时的系统能耗浪费较大。而本文算法选择关停制冷量和COP相对较低的3号机组,再对剩余3台机组进行负荷分配优化,使各机组在COP相对较高的状态下承担负荷,从而提升系统总COP,达到节约能耗的目的。从图8可以看出,关停低负荷率下COP相对较低的3号机组,同时提高剩余机组的负荷率,系统总COP有明显提升。
结合表7,优化后的多冷水机组在较高制冷需求下的运行能耗降低约1%~2%,在较低的制冷需求下的运行能耗降低约8%~14%,平均能耗降低可达约6%。表明本文提出的负荷分配优化方法通过调控各机组的启停组合和负荷分配能够达到良好的节能效果。
5 结束语
本文建立一种随机森林结合核函数极限学习机的冷水机组能效预测模型,并以能效模型为基础,提出一种采用改进被囊群算法的多冷水机组负荷分配方法,以某卷烟厂生产车间的中央空调系统为对象进行实验,得到以下结论:
1)通过随机森林特征优选剔除冗余特征,构建新的有效特征集,可以提高核极限学习机对冷水机能效的预测精度,同时对比其他模型,核极限学习机在精度和速度上更能适配负荷分配控制的需求。
2)混合策略改进的被囊群算法相比改进之前在寻优精度、收敛速度和跳出局部最优的能力上具有明显的提升,说明改进方法具有一定的有效性。
3)采用改进被囊群算法的冷水机组负荷分配方法通过优化多冷水机组的启停状态和负荷率,能够有效提升系统的总COP,相比平均负荷法降低能耗约6%,说明该方法具有良好的节能效果。
