MFE-YOLOX: 无人机航拍下密集小目标检测算法
2024-02-26马俊燕常亚楠
马俊燕,常亚楠
(1.广西大学 机械工程学院,南宁 530004; 2.广西大学 广西制造系统与先进制造重点实验室,南宁 530004)
0 引 言
无人机航拍具有视角宽、拍摄范围广、灵活性高等优点,可以从不同位置和角度采集数据信息[1]。无人机捕获物体场景下的目标检测技术已经被广泛应用于城市监测、农业生产和交通检测等领域[2-3]。无人机航拍图像存在两个问题:目标排列密集[4],导致物体之间的遮挡严重;目标尺寸变化大,但无人机航拍图像中往往含有大量的小物体。这些问题使得对无人机捕获图像进行目标检测非常具有挑战性。
随着深度学习的快速发展,卷积神经网络在目标检测领域取得了显著效果。相较于其他自然场景,无人机图像中包含了许多密集小物体,不利于现有网络的检测。文献[5]将Fast R-CNN和Faster R-CNN用于航空图像中的车辆检测,通过调整锚框大小等方法来提升小目标检测效果,但是没有注意细节信息丢失严重的问题,这对小目标检测十分不利;文献[6]提出一种基于YOLOv3[7]的可堆叠重校准特征金字塔模块,通过将深层特征与浅层特征融合来加强目标的分类与定位;文献[8]设计了一种特征融合金字塔(feature pyramid network,FPN)模型用来丰富特征层细节;文献[9]指出,普通的特征融合结构在通过不同特征层融合时起到的作用有限,同时还可能使得网络检测速度下降;文献[10]提出了一种基于浅层空间特征融合与自适应通道筛选的目标检测方法,合理地复用了每个下采样阶段内的子空间信息,在保证实时检测速度的条件下,达到与拥有较深主干网络的检测模型同级别的性能;文献[11]使用改进的多尺度空洞卷积提取特征,扩大了特征层的感受野,有效地提高了无人机航拍下复杂背景的检测效果;文献[12]指出,将不同大小感受野的特征层融合可能会带来混叠效应,使定位和识别任务混淆;文献[13]利用更大分辨的输入获取更多的可利用信息,为小目标检测带来了显著的性能提升,但计算量激增,不利于实际工程应用。近年来,基于无锚的算法[14-16]在理论上对无人机图像中小目标的检测有着更好效果,并且在计算速度上也有提升,是较为热门的一个研究方向。
基于上述研究分析,本文针对无人机航拍图像的特点,设计了4个模块。首先,受超分辨率亚像素卷积[17]的启发,本文设计了一种轻量化的可提高小目标分辨率以及增强小目标信息提取的模块。其次,本文提出了一个增强特征融合的混合特征结构,并设计了一种新的自适应融合算法。通过以上2个模块,可以缓解因卷积层和池化层带来的信息损失以及普通的特征融合层融合效果较差的问题。最后,本文设计了一个上下文增强模块和通道信息指导模块,用于获取更多的目标位置信息,对遮挡物体进行定位、提高尺度不同的目标检测识别的精度并缓解了混叠效应。本文将整个模型命名为混合特征增强(mix feature enhancement,MFE)结构MFE-YOLOX。实验证明,该结构对无人机航拍检测有着显著的提升效果。本文MFE-YOLOX总体结构如图1所示。

图1 MFE-YOLOX总体结构Fig.1 Overall architecture of MFE-YOLOX
图1中,输入图片经过骨干网络进行信息提取后,其后3个特征层分别通过亚像素注意力增强融合(sub-pixel attention fusion,SAF)模块进行信息增强,并分别输入到特征混合融合(mix feature transfer,MFT)结构中,将特征层中所提取信息互相融合,然后再经过尾端多尺度感受野扩大层(multi-branch dilated convolution layer,MDL)和通道注意引导模块(channel attention guided module,CAG),最后输入到Head层得到最终处理。
1 算法介绍
1.1 YOLOX网络
YOLOX[15]网络是旷视科技公司于2020年提出的目标检测网络。该网络将目标检测领域多个模块的最新进展与YOLO集成(比如解耦头、数据增广、标签分配、Anchor-free机制等)得到YOLOX,性能提升的同时,仍保留了YOLO系列速度快的特点。YOLOX是可缩放网络,有YOLOX-s、YOLOX-m、YOLOX-l、YOLOX-x和YOLOX-nano等5种不同型号,总体架构一致,区别主要在于层数不同。经过实验对比,在对网络的整体参数量、计算量、准确率和运算速度进行综合考量后,本文采用YOLOX-m作为基线网络。
1.2 SAF
YOLOX特征层输出通道为{256,512,1024}。图1中,相对高级的特征{C4,C5}包含丰富的语义信息,由于经过多次处理,小目标位置信息丢失严重,而低级特征{C2,C3}则包含丰富的小目标原始信息。为了能够将高级与低级特征信息更好地结合,本文引入超分辨率模块(super-resolution,SR)并开发了SAF模块,以更好地对小目标进行定位检测。SR直接从低分辨率图像生成高分辨率特征来进行小目标检测,同时保持较低的计算成本。为了保留更多原始特征信息,本文对较低特征层使用了SE注意力模块[18]。
SAF整体结构如图2所示。SAF将相对较低特征层与高特征层中的信息进行重新整合,新特征层在保留了丰富语义信息的同时,获得了位置信息,有利于后续网络对小目标进行检测。

图2 SAF结构Fig.2 SAF structure
1.3 MFT
MFT结构如图1实线框内所示。为了加强不同大小特征层之间的融合效率[9],并解决不同特征层在融合时对结果影响作用相同的问题,本文提出了MFT结构。与FPN在改进结构特征层使用对应位置求和或直接叠加的方法来集成多层次特征不同,MFT的关键点在于可与骨干网络保持相同大小以及可自适应学习不同特征层的空间权重。同比缩放使MFT结构与骨干网络的大小宽度可始终保持一致;自适应融合使特征层进行融合时,网络通过自动学习为不同大小的特征层分配合适的权重。
1)同比缩放。YOLOX网络属于能够自适应调整网络大小的结构,在设计MFT时对这一特性进行了保留。本文将SAF的输出特征层表示为X、Y、Z,其权重分别为x、y、z。经过SAF处理得到的3个级别特征层,具有不同分辨率和通道数,因此本文采用了不同的上采样和下采样策略。对于上采样,先使用1*1的卷积层将特征的通道数压缩至n(n∈{X,Y,Z}层的通道数,然后通过插值方法提高分辨率。对于2∶1倍的下采样,本文使用一个步长为2的3*3卷积层来对其进行调整;对于4∶1的下采样,加入最大池化层,先将其调整至中间层大小,再调整为目标层大小。
2)自适应融合。当融合不同分辨率的特征层时,通常是将他们调整到相同的分辨率,然后相加。由于不同的输入特征具有不同的分辨率,他们对输出特征的贡献通常是不平等的。在Bi-FPN[19]中,基于Softmax和快速标准化融合方法虽然最终效果相似,但是快速标准化融合方法的推理速度更快,训练时所占用显存空间更小。本文将快速标准化融合方法和空间注意力机制结合,提出了一种新的加权方式把在X层融合作为示范,即
(1)
X*=αX·X+αY·Y+αZ·Z
(2)

1.4 MDL
由于无人机在飞行时高度时常变化,导致航拍物体图像的尺度不确定,并且在对市中心等地进行高空拍摄画面时容易出现密集流目标,经常出现遮挡的情况。针对这个问题,本文开发了MDL模块,其整体结构如图3所示。MDL模块由两部分组成:多分支卷积层和CAG结构。多分支卷积层利用不同大小的扩张卷积为输入特征映射,提供了3种大小不同的感受野,后续采用平均池化层来对3个分支接收域的信息进行融合,融合后输入至检测层,为后续的检测层结构提供了丰富的输入信息。通过多分支卷积层可使得检测层在检测时可以利用上下文信息对物体的位置进行更为精确的定位,从而对重叠物体进行更好区分。多分支卷积层由扩张卷积层、BN层和conv卷积层组成。扩张卷积是针对下采样会降低图像分辨率、丢失信息而提出的一种卷积思路[20],通过在标准卷积中加入空洞,以此来增加感受野,因此又名空洞卷积。扩张卷积多了一个超参数d(通常又称之为扩张率),该参数定义了卷积核处理数据时各值的间距。与标准卷积不同,经扩张后的卷积核的元素是间隔的,感受野的大小取决于扩张率。本文扩张卷积的核大小为3*3,不同分支的扩张率d分别取值为3、5、7。有关卷积核经扩张后的感受野计算式为

图3 MDL结构Fig.3 Multi-branch dilated convolution layer
F=k+(k-1)(d-1)
(3)
(3)式中:d为扩张率;k为原卷积核大小;F为经扩张后卷积核的实际感受野大小。标准卷积可看作扩张卷积的一种特殊情况,在标准卷积中d=1。
为减轻混叠效应[12]的影响,本文在SE[18]的启发下,提出了一种通道注意引导模块(CAG),引导尾端的每一层缓解混叠效应。CAG提取通道权值,将权值乘到每个输出特征上。CAG的结构如图4所示。本文先分别使用自适应平均池化和自适应最大池化来聚合空间上下文信息,然后将两个池化后的结果通过一个卷积组合模块求和,并通过Sigmoid对输出进行合并。这个过程可以表述为
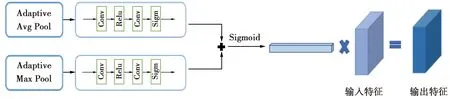
图4 CAG结构Fig.4 Channel attention guided module
C(x)=σ(Conv1(AvgPool(x)+Conv2(MaxPool(x)))
(4)
Z=Sigmoid(C(I))
(5)
(4)式中的Conv并非一个单独的卷积模块,而是由conv-relu-conv-sigmoid组成。
将使用CAG模块提取的通道权重应用于原特征层Fi,从而使得Fi每一通道被赋予不同的权值,得到特征层Fi*。Fi经过不同扩张后,统一输入至池化层中对其进行调整,得到新特征层Di,Di混叠效应严重,此时将Fi*与Di结合,使用Fi*的信息来对Di进行指导,从而减轻混叠效应,保留更多的Fi信息。
2 系统模型
2.1 实验数据与参数设置
本文实验平台使用Ubuntu20.04系统,所有实验环境均为Python3.8,Pytorch1.10.1,Cuda11.5,利用NVIDIA RTX3070 GPU进行训练和测试。学习率设置为1e-2,权重衰减设置为5e-4,动量设置为0.937,使用基线网络权重,冻结骨干网络权重预训练为80轮,再解冻骨干网络训练220轮,共300轮。
数据集采用VisDrone,这是由天津大学机器学习和数据挖掘实验室的Aiskyeye团队收集的。基准数据集由288个视频剪辑、261 908帧动态和10 209张静态图像组成。VisDrone数据集由各种无人机安装的摄像机捕获,涵盖了各个方面,包括位置(跨越中国数千公里的14个不同城市)、环境(白天,黑夜,街头和校园等)、物体(行人,车辆,自行车等)和密度(稀疏和拥挤的场景)等因素,手动标注了超过260万个目标,例如行人、汽车、自行车和三轮车等。
实验中采用平均精度均值(mean average precision,mAP)、AP50、参数量和计算量等评价指标来评估算法性能。AP50表示交并比(IoU)阈值为0.5时所有目标类别的平均检测精度;mAP代表以步长为0.05计算IoU阈值从0.5~0.95的所有10个IoU阈值下的检测精度平均值。在MS COCO 数据集[21]中,将图像中像素点小于32*32的目标称为小目标,32*32到96*96为中等目标,大于96*96为大目标。计算量对应算法的时间复杂度,参数量对应空间复杂度。
2.2 对比实验分析
为了验证改进方法的有效性,本文在数据集VisDrone2021上对MFE-YOLOX算法进行了评估。为了与相应基线进行公平比较,本文在同一标准下计算实验结果。在使用MFE结构取代PANet后,mAP达到25.03%,AP50达到了47.78%,比基线网络分别提升了4.22、9.43个百分点。本文还进一步与其他先进的检测器[22-27]进行了比较,结果如图5所示。
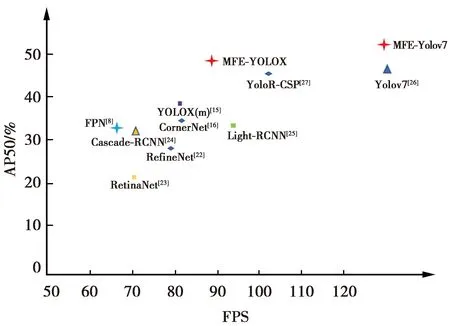
图5 实验结果对比Fig.5 Comparison of experimental results
图5中,纵坐标为AP50,横坐标为在GPU3070下的推理结果,使用FPS来衡量,算法坐标越靠近右上角结果越好。本文还将MFE结构加入到YOLOv7中进行比较,2个标红的四角星即为本文方法的结果。与其他的主流算法相比,本文方法具有十分明显的优势。MFE加入到YOLOX与YOLOV7上均呈现了较好结果,说明本文方法具有一定的泛化性。由于对象可能太小或超出特征层的感受野,传统的FPN模型偶尔会遗漏一些对象,导致网络出现漏检。本文MFE方法通过SAF结构可以挖掘丰富的小目标信息,并通过引入扩张卷积构建MDL结构来扩大网络输出特征层的感受野,从而可以利用更为丰富的上下文信息对物体进行定位检测,很好地缓解了这一问题。
2.3 消融实验
本文还分析了MFE-YOLOX各新增结构对网络性能的影响,以及各模块加入后对VisDrone数据集上各个子项的具体表现(AP50结果),消融实验结果如表1所示。
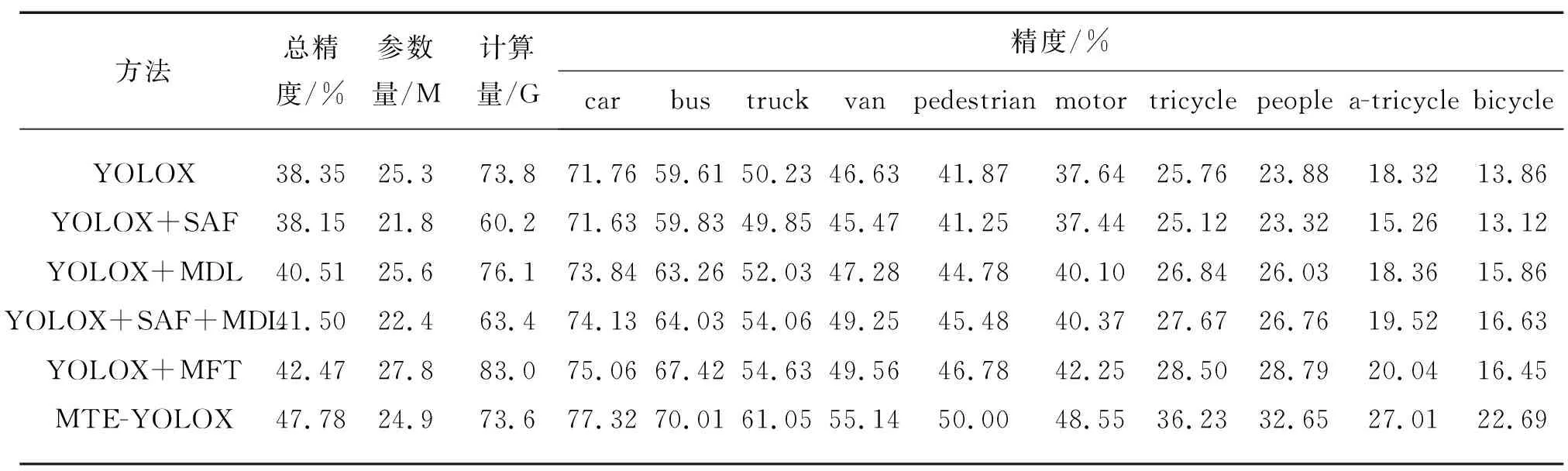
表1 消融实验
本文在YOLOX网络上逐步添加SAF、MDL、MFT模块。消融实验采用的参数均为原版YOLOX网络默认参数。Neck层由上采样和下采样2个部分组成。使用SAF结构替代上采样,使用MDL结构替代下采样。实验结果表明,如果在YOLOX中使用SAF替代其上采样,性能会出现略微下降,但是网络整体的参数量和计算量出现了大幅下降,说明SAF结构在更轻更小的同时保证了性能。在其他结构分别加入YOLOX网络时,均出现了不同程度的性能提升,说明本文结构均对无人机检测有一定效果,且在将Neck层完全替换为MFE结构后,出现了较为明显的精度提升。
2.4 算法可行性分析
由实验结果可以看到,改进后的网络拥有更好的精度。本文所采取的方法利用SAF扩张了高级特征层信息,并对低级特征层中较为重要的信息赋予了更大的权重,更好地对信息进行了利用与整合,虽然精度有一点下降,但网络整体计算量也下降较多,并且可以更好地与后续改进网络相结合;由融合实验可以看到,MFT结构对网络整体精度提升较大,这是因为将不同大小的特征层中的信息进行融合时,由自适应融合系数自动分配信息比重,使得重要信息可以发挥更大作用;MDL层扩大了感受野,充分利用了上下文信息对物体的位置进行更为精确的定位,提高了对于小目标以及重合目标的检测精度。3个结构相互结合,产生了良好的检测效果。
为了验证MFE-YOLOX算法在实际检测场景中的效果,选取VisDrone数据集中实际检测较为困难的图像进行对比测试,部分检测效果对比如图6所示。

图6 检测效果对比Fig.6 Comparison of object detection results
图6中,第1、第3行为原网络结果,第2、第4行为改进网络结果。图6中包含了大量密集遮挡小物体图片以及光线不足的夜间图片。在第1张和第2张图片中,街道和篮球场实际拍摄场景下存在大量密集小目标,可以看出,改进后的算法可以很好地对重叠物体进行区分并检测出更远处的小目标,而原网络往往对远处小目标以及密集物体检测较差。图6图像中存在大量遮挡目标,改进后的算法可以很好地对其进行检测。而在夜间场景中,原网络会对模糊且清晰度不足的物体漏检,而本文网络则可以很好地检测出来。路上的车辆极小且存在运动模糊,但都能被准确地检测出来,说明本文的模型对存在遮挡以及清晰度不足的小目标的检测能力突出。
3 结束语
本文针对无人机航拍场景中的难点,基于YOLOX网络,提出了可以增强小目标分辨率以及区分密集物体的4个模块。结合超分辨率与注意力机制,在精度几乎不受影响的情况下构建了一种轻量化的提高小目标物体信息的模块;提出了一种具有同比缩放和自适应融合系数的全新特征融合方式,增强了不同大小特征层间的融合效率;在Neck层末尾,设计了一种可以扩大特征层感受野并加强了上下文信息联系的模块,提高对无人机拍摄不同尺度目标检测识别的精度。实验结果表明,与其他无人机检测算法相比,本文算法具有较好的检测性能,在不增加计算量和参数量的前提下,显著提高了检测精度。
