融合Transformer和卷积LSTM的轨迹分类网络
2024-02-26夏英,陈航
夏 英,陈 航
(重庆邮电大学 计算机科学与技术学院,重庆 400065)
0 引 言
移动互联网的普及使得基于位置的服务日益丰富,同时也促进了位置感知和轨迹聚类[1]分析技术的发展。充分利用全球定位系统(global positioning system,GPS)的轨迹数据,分析出行者的交通方式,能够为智慧城市、智能交通、智慧旅游等领域的管理服务提供有力支撑。由于GPS轨迹数据并不能直接反映不同的交通方式,因此有必要通过轨迹分类等方法[2]对GPS轨迹数据进行分析挖掘。
近些年来,基于轨迹数据的交通模式分类算法主要基于统计方法、机器学习方法和神经网络方法,其中基于神经网络方法的分类算法得到学者广泛关注。Dabiri等[3]对轨迹数据中无效和不准确的轨迹点进行检测和删除,然后采用Savitzky-Golay滤波器对轨迹数据进行平滑处理,消除随机误差,再基于过滤后的轨迹计算出运动特征,建立四通道神经网络模型,并使用分类交叉熵作为损失函数和Adam优化器,对交通方式进行分类。Liu等[4]提出了基于双向长短期记忆网络(bi-directional long-short term memory,Bi-LSTM)模型,该模型直接将轨迹数据作为网络的输入提取得到高级特征,并通过嵌入时间间隔作为外部特征,将两类特征相融合对交通方式进行分类。Nawaz等[5]提出了基于深度学习的卷积长短期记忆(convolutional LSTM,ConvLSTM)模型,对GPS轨迹数据进行预处理,删除由设备错误等原因引起的轨迹异常点,然后利用卷积神经网络提取高层特征,并利用LSTM学习GPS和天气特征数据中的序列模式用以分析交通方式。Endo等[6]将轨迹数据转换为网格图像,使用自动编码器从网格图像中提取出高级特征,并与距离和速度等特征进行拼接用以进行轨迹分类。Zhang等[7]也将轨迹数据映射到网格中,并使用自注意力(self-attention, SA)机制和残差网络构建深度多尺度学习模型(deep multi-scale learning model,DMSLM)提取出轨迹高级特征用以轨迹分类。Yang等[8]提出了基于卷积自注意力机制的轨迹时间序列分类算法,进一步提高多维轨迹特征提取能力和分类精度。Bae等[9]利用Transformer[10-11]在笔划轨迹输入序列较长的情况下,提取笔划轨迹特征并成功分类。Lu[12]提出了基于双卷积自动编码器的神经网络(dual convolutional neural networks based supervised autoencoder,Dual-CSA)。该网络首先对GPS轨迹数据进行初步预处理(如过滤错误时间戳、经纬度等);其次基于停留点进一步划分轨迹段;然后对划分后的轨迹段计算运动特征后进行噪声深度过滤并线性填充使每段轨迹段包含的轨迹点数相同;之后采用特征段(feature segment,FS)自编码器提取轨迹的空间特征,同时通过递归图(recurrence plots,RP)自编码器提取轨迹的时间特征,并利用停止状态和转向状态来增强轨迹数据的空间特征;最后将轨迹特征和时间特征融合后输入预定义质心(predefined class centroids,PCC)分类层进行轨迹分类。该方法具有一定优越性,但对于轨迹数据的噪声处理不够完善,且其提取的时空特征也不够充分。
上述基于轨迹的交通模式分类模型均取得了良好效果,但轨迹的时间特征和空间特征提取不够充分,同时仍有必要考虑原始轨迹数据中的噪声对分类精度的影响。本文在Dual-CSA网络的基础上,提出一种融合堆叠降噪自编码器、Transformer和卷积LSTM的网络结构(networks fusing stacked denoising auto-encoder, Transformer and ConvLSTM,SDAETC),有效去除噪声并增强时空特征提取能力,进一步提高基于GPS轨迹数据的交通方式识别的精度。
1 相关技术基础
1.1 降噪自编码器
现有针对轨迹分类的深度学习模型对噪声比较敏感,使得噪声对轨迹分类的精度有所影响。降噪自动编码器(denoising auto-encoder,DAE)[13]可以用于去除原始轨迹数据中的噪声,其原理是以一定概率分布来随机丢弃部分原始输入数据,然后将处理后的数据作为网络的输入进行训练。经过这一过程训练出来的网络能从原始数据中重构出质量更好的数据,并学习到更为有效的特征数据,从而达到去除噪声,提升网络鲁棒性的效果。
1.2 卷积长短期记忆网络
全连接LSTM(fully connected LSTM,FC-LSTM)[14]在处理时间相关性方面具有良好性能,但计算过程中存在空间数据缺失等问题,因此,虽能保持时间依赖,但容易失去空间依赖。ConvLSTM[5]由FC-LSTM扩展而来,如图1所示。
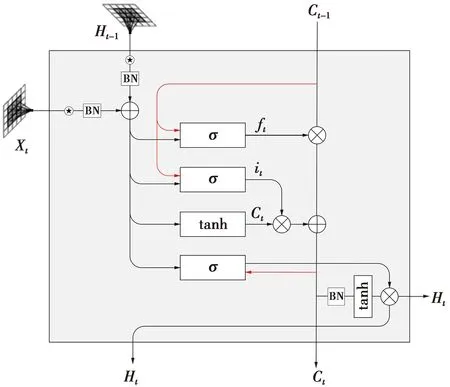
图1 ConvLSTM内部结构Fig.1 Structure of ConvLSTM
ConvLSTM的核心功能可以看作嵌入在LSTM中的卷积层。在输入到状态(input-to-state)和状态到状态(state-to-state)的转换中,ConvLSTM都涉及卷积运算,而不是LSTM中的矩阵乘法。ConvLSTM还可以通过当前输入和相邻单元的过去状态来确定单元的未来状态,因而能够捕获时间依赖。ConvLSTM可以通过处理空间依赖来达到卷积神经网络(convolutional neural networks,CNN)[15]的效果,也可以通过处理时间依赖来达到LSTM的效果。ConvLSTM的关键方程如下。
(1)—(5)式中:it表示t时刻的输入门;sigmoid表示激活函数;WXI表示输入门的输入权重;·表示卷积运算;Xt表示t时刻的输入;WHI表示输入门t-1时刻的隐藏权重;Ht-1表示t-1时刻的隐藏状态;WCI表示输入门的记忆单元权重;∘表示Hadamard积;Ct-1表示t-1时刻的单元状态;bI表示输入门偏置;ft表示t时刻的遗忘门;WXF表示遗忘门的输入权重;WHF表示遗忘门t-1时刻的隐藏权重;WCF表示遗忘门的记忆单元权重;bF表示遗忘门偏置;Ct表示t时刻的单元状态;WXC表示单元状态的输入权重;WHC表示单元状态t-1时刻的隐藏权重;bC表示单元偏置;ot表示t时刻的输出门;WXO表示输出门的输入权重;WHO表示输出门t-1时刻的隐藏权重;WCO表示输出门的记忆单元权重;bO表示输出门偏置;Ht表示t时刻的隐藏状态。
1.3 Transformer
Transformer[10]是一种基于自注意力机制的神经网络,具有良好的特征提取能力。Transformer由编码器和解码器两部分组成,其网络结构如图2所示。编码器由N层堆叠而成,每部分有2个子层:①一个多头自注意力模块;②一个按位置排列的全连接前馈网络。每个子层中采用了一个残差连接,并进行层的归一化。解码器也是由N层堆叠而成,解码器每层包含3个子层,其中后2个子层结构与编码器子层结构相似,第1个子层对编码器部分的输入进行处理。与编码器类似,每个子层都采用了一个残差连接,并进行层的归一化。
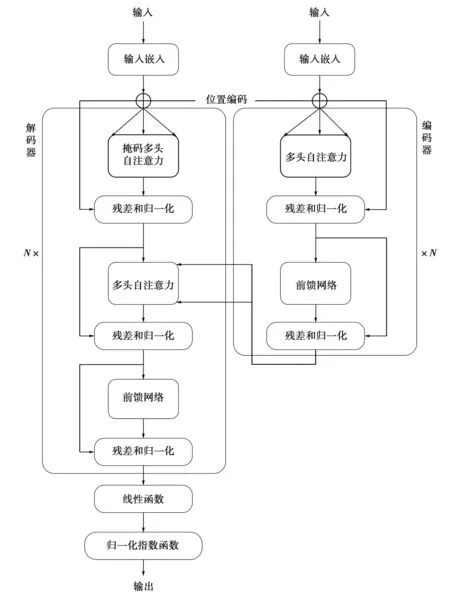
图2 Transformer网络结构Fig.2 Structure of Transformer
2 SDAETC网络结构设计
为减小数据集噪声对神经网络模型的影响,更加充分地提取轨迹数据中的时间特征和空间特征,从而进一步提升轨迹分类性能,本文基于Dual-CSA模型,融合了堆叠降噪自编码器(stacked denoising auto-encoder,SDAE)模块、TC-Transformer(trajectory classification Transformer)模块以及TC-ConvLSTM(trajectory classification ConvLSTM)模块,提出一种用于交通方式识别的轨迹分类网络SDAETC。该模型主要包括数据集降噪、特征提取与融合等过程,总体流程如图3所示。本模型先对数据进行初步预处理去除掉错误时间戳等类信息,然后使用SDAE作为数据噪声处理器。为充分提取轨迹的时空特征,将降噪处理过的轨迹数据分别传入Dual-CSA模型中的FS自编码器和结合了TC-Transformer的RP自编码器,分别得到轨迹的空间特征和时间特征,再与TC-ConvLSTM提取得到的时空特征相融合,三者融合后的特征通过PCC分类层就可以得到交通方式识别的分类结果。

图3 SDAETC网络结构Fig.3 Structure of SDAETC
2.1 堆叠降噪自编码器的构建
传统的DAE[13]不仅在模型训练时会对输入数据进行随机丢弃,还会在训练完成后进行相应的处理,这会一定程度上影响分类效果,而且单个DAE的效果有限,不能很好地对轨迹数据集进行降噪。本文设计堆叠降噪自编码器SDAE,将若干层DAE进行堆叠,只有在训练的时候才对输入数据进行随机丢弃操作;每层DAE单独进行训练,以最小化输入与重构结果之间的误差为训练目标。SDAE训练过程如图4所示。

图4 SDAE的训练过程Fig.4 Training process of SDAE
图4a表示单层DAE的训练过程。图4a中,原始输入数据为X,经过随机丢弃的数据为X′,○表示原始的轨迹数据,表示经过随机丢弃后的轨迹数据。利用编码函数fθ对输入进行降噪编码得到Y,公式为
Y=fθ(X′)=sigmoid(WX′+b)
(6)
(6)式中:参数集合θ={W,b};W为连接权值矩阵;b为神经元的偏置向量。得到输出Y之后再经过解码函数gθ′,得到重构后的解码输出Z,公式为
Z=gθ′(Y)=sigmoid(W′Y+b′)
(7)
(7)式中:参数集合θ′={W′,b′};W′为连接权值矩阵;b′为神经元的偏置向量。
X与Z之间的最小化重构误差LH(X,Z)为
LH(X,Z)=‖X-gθ′(fθ(X′))‖
(8)
图4b表示两层DAE的堆叠计算过程,第一层的轨迹X经过编码函数fθ得到第二层的输入,第二层经过图4a中类似训练得到重构后的解码输出Z′。整体网络训练过程堆叠多层DAE同时训练,参数集合θ和θ′等通过梯度下降法不断调整,当训练完成,即可得到最小的重构误差和经过降噪处理后的数据。
2.2 TC-ConvLSTM网络的构造
传统的ConvLSTM不能直接用于面向交通方式识别的轨迹分类,这是因为ConvLSTM要求其输入数据是具有时间步长、行、列和通道维度的四维张量。为将轨迹输入格式转换为ConvLSTM结构可以接受的格式,采用如下两个步骤进行处理:第一步,将整个轨迹划分为若干个具有相同轨迹点数量的子轨迹段。由于ConvLSTM和Transformer通常需要固定大小的输入,假设网络接收的子轨迹段输入大小为S,大于S的子轨迹段需要进一步分割,小于S的子轨迹段则对其应用线性插值进行填充。由于S的大小影响到后续步骤的特征提取,因此每段S包含的轨迹点数量不能太小,否则提取的特征会不够全面;也不能太大,否则提取的特征出现冗余。轨迹均匀分割得到的子轨迹段的个数表示为时间步长,每个子轨迹段转变成一个一维向量。第二步,将每个一维向量进一步划分为大小相等的两部分,作为ConvLSTM的行、列两个输入维度,并且将输入轨迹特征的数量作为通道维度,这样就形成了一个四维张量,以此作为TC-ConvLSTM模型的输入。
ConvLSTM层执行卷积以提取轨迹的时空特征,其中包含若干ConvLSTM子层,每个子层后接一个批次规格化层,用于小批量输入的规格化,保证在各单元之间流动的数据保持相同的维度。最后在ConvLSTM层的末端接一个嵌入层,将其提取到的特征嵌入到一维向量中,以便与提取到的其他特征进行融合。TC-ConvLSTM的结构如图5所示。
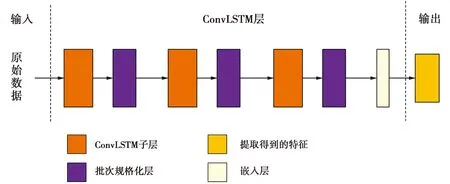
图5 TC-ConvLSTM的结构Fig.5 Structure of TC-ConvLSTM
2.3 TC-Transformer的设计
RP自动编码器的卷积层能获取RP中相邻像素点之间的关系特征,但不能获取RP中所有像素点之间的关系特征[12]。Transformer能获取输入数据时间序列整体的关系特征[11]。因此本文设计trajectory classification Transformer(TC-Transformer),并选择将其添加在RP自动编码器的编码阶段之后,用来获取RP所有像素点之间的关系特征,使得RP的整体时间特征能够被获取,且局部时间特征也能得到更多的关注,从而有利于提升分类精度。TC-Transformer的结构如图6所示。
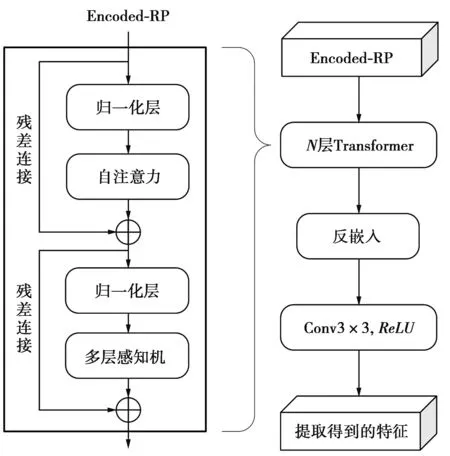
图6 TC-Transformer的结构Fig.6 Structure of TC-Transformer
由图6可见,在TC-Transformer中,以编码后的RP数据(Encoded-RP)作为Transformer的输入,通过Transformer来提取RP数据的整体时间特征,采用反嵌入将处理后的数据恢复成解码器的输入格式,并通过二维卷积和ReLU进一步提取其局部时间特征。Transformer由两个子层构成,其中,自注意力和多层感知机作为两个子层的主要算子,能提取到RP数据的时间特征。每个子层通过归一化层来规范化数据,减少因网络过深导致的梯度消失带来的影响,残差连接使得每一层网络至少不能退化,保证了Transformer的特征提取能力。
3 实验与结果分析
3.1 实验环境与设置
实验运行在Ubuntu 18.04操作系统上,CPU为Intel Xeon W-2133@3.6 GHz和W-2123@3.6 GHz,内存96 GB,GPU为RTX 2080 Ti 11 GB×3,GTX 1070 Ti 8 GB×1。网络模型搭建以及训练采用深度学习平台Pytorch 1.6.0、Keras 2.3.1以及scikit-learn 0.23.2。
考虑到尺寸太大的RP会消耗大量的内存和增加训练时间,而每个子轨迹段的轨迹点数S决定RP的尺寸,因此将S最大值设置为200,最小值设置为10。所采用的轨迹特征为速度、加速度、航向变化率、停止态和转向态[12]。SDAETC网络相关的其他参数和方法包括:SDAE的层数设置为3[6],数据的批处理大小(batch size)为64,采用Adam优化器作为优化技术,使用泄漏整流线性单元(LeakyReLU)作为激活函数,为了防止模型过拟合,采用早期停止(early stopping)的方法[12]。TC-ConvLSTM中采用了3个ConvLSTM子层,每个子层的过滤器个数依次为32、64和128,为了适应一维行向量,将过滤器大小设置为1×3,将200个轨迹点转换为时间步长为8、列数为25的一个行向量[5]。TC-Transformer中将Transformer层数设置为12,深度设置为4,多头数设置为4,多层感知机的数量设置为8[10]。为了防止实验偶然性,所有实验结果均为5次实验得到的平均值。
3.2 数据集
GeoLife数据集[16-17]出自微软亚洲研究院,包含2007年4月至2012年8月期间182个用户的17 621个轨迹数据,总距离为1 292 951公里,总持续时间为50 176小时。每一个轨迹点包含经纬度、海拔等信息。记录了用户在家和在工作地点的位置轨迹,以及购物、旅游、远足、骑自行车等户外活动轨迹。
SHL数据集[18]由3位参与者记录,他们在现实生活中参与了8种不同的交通方式,总距离为17 562公里,生成2 812小时的带标签数据,有28种注释类型。每位参与者同时携带4部智能手机,每部手机记录了惯性传感器、GPS、环境压力传感器、环境湿度等15个传感器的数据。
实验只考虑地面交通方式。用到的交通方式类别为步行、自行车、公共汽车、小车、轨道,其中小车类别包含私家车和出租车,轨道类别包含火车和地铁。数据集按照8∶2的比例被随机分为训练集和测试集。
图7总结了两种数据集中经过预处理后每种交通方式的分段数量[12]。图7中,GeoLife数据集拥有更多的样本,但数据分布不平衡,而SHL数据集的样本较少,但分布则相对平衡。
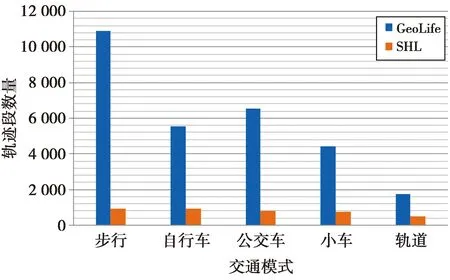
图7 GeoLife和SHL数据集经过预处理后的交通方式分布图Fig.7 Histogram of transportation mode after preprocessing on GeoLife and SHL datasets
3.3 评价指标
轨迹分类作为一个分类问题,一般使用准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1、混淆矩阵来评价模型性能。
准确率表示预测正确的样本在所有样本中占的比例,计算公式为
(9)
(9)式中:NTP为真正类(true positive,TP)的数量;NTN为真负类(true negative,TN)的数量;NFP为假正类(false positive,FP)的数量;NFN为假负类(false negative,FN)的数量。
精确率表示在预测为正的样本中真实类别为正的样本所占比例,召回率表示在真实为正的样本中模型成功预测出的样本所占比例,计算公式为
(10)
(11)
F1是精确率和召回率的调和平均值,计算公式为
(12)
F1综合了精确率和召回率的结果,F1较高则说明模型效果比较理想。
3.4 实验与分析
3.4.1 数据样本及分布对轨迹分类结果的影响分析
表1和表2分别是本文模型SDAETC在GeoLife和SHL数据集上的分类结果,由表1—表2可见,SDAETC在2个数据集上的准确率分别为91.3%和91.6%。对于GeoLife数据集,分类误差主要出现在自行车和步行模式之间,比如有51个步行样本被错误分类为自行车,而有180个自行车样本被错误分类为步行,这主要是因为样本分布不均衡,且两者的移动行为模式较为相似。SHL数据集也有类似结果,导致公交车和轨道的F1值相对较低。另外, SDAETC在2个数据集上步行的F1值相对较高且稳定,而轨道的F1值则相对最低且不稳定,这主要与两者的样本数量多少有关。
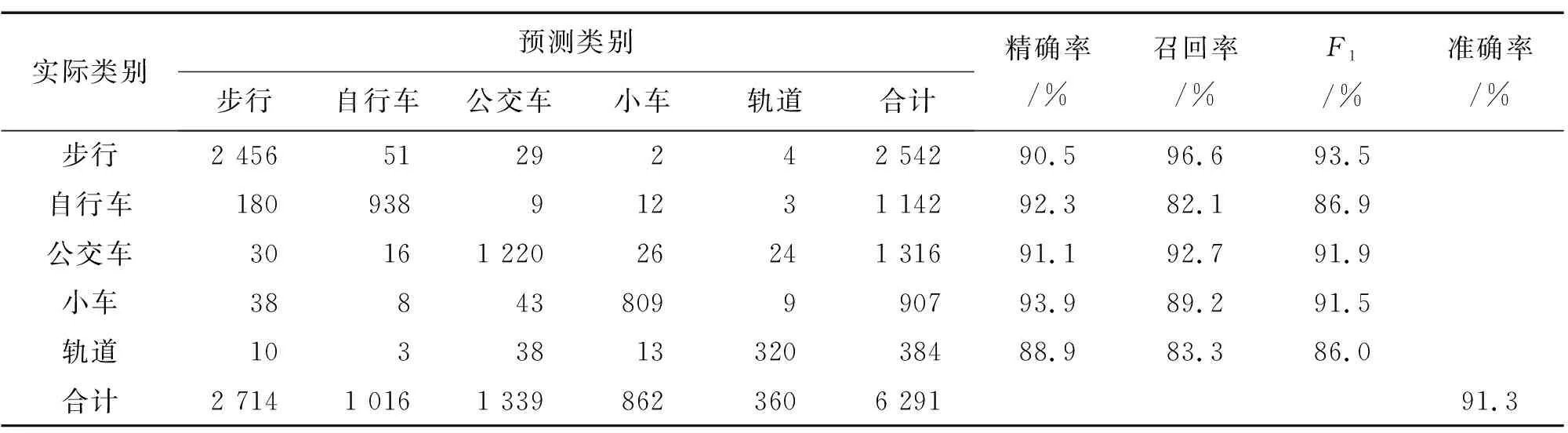
表1 SDAETC在GeoLife数据集上的分类结果

表2 SDAETC在SHL数据集上的分类结果
3.4.2 轨迹分类方法的性能对比
将SDAETC与同样采用深度学习方法和相同数据集的以下4项研究工作进行对比分析。
SDNN[6]:从生成的轨迹图像中使用自动编码器提取出轨迹的高层特征。
DMSLM[7]:将轨迹映射到一个多尺度时间和空间粒度的网格中,使用残差学习和注意力机制构建神经网络。
Dabi-CNN[3]:构建了一个具有四通道GPS轨迹段的CNN(包括速度、加速度、加加速度和承载率)。
Dual-CSA[12]:将分别提取轨迹的时间信息和空间信息的自编码器结合起来进行分类。
表3展示了SDAETC在GeoLife和SHL数据集上与SDNN、DMSLM、Dabi-CNN以及基线模型Dual-CSA等方法的分类准确率对比情况。由表3可见,其在GeoLife数据集上准确率分别提升了23.4、18、6.5、1.8个百分点,在SHL数据集上准确率分别提升了26.3、16、6、2个百分点。表3说明,SDAETC通过SDAE降噪结合TC-Transfomer和TC-ConvLSTM能够提取到更加全面的轨迹时空特征,因此更有优势。

表3 各分类方法在两个数据集上准确率的对比
3.4.3 各模块贡献度分析
为了进一步分析各模块对SDAETC网络模型的贡献,在GeoLife和SHL数据集上开展消融实验,结果如表4—表5所示。由表4—表5可见,本文设计的SDAE、TC-ConvLSTM、TC-Transformer对分类性能提升均有贡献。TC-ConvLSTM模块贡献最大,不仅能提取出空间特征,还适用于处理时间特征,对应获得的准确率和平均F1值均有较大提升;TC-Transformer模块贡献其次,提取了轨迹数据的整体时间特征,对于分类精度的提升有一定帮助;另外,SDAE模块对轨迹数据进行降噪后,数据质量得到一定提升,有助于分类精度的提高。

表4 GeoLife数据集消融实验结果
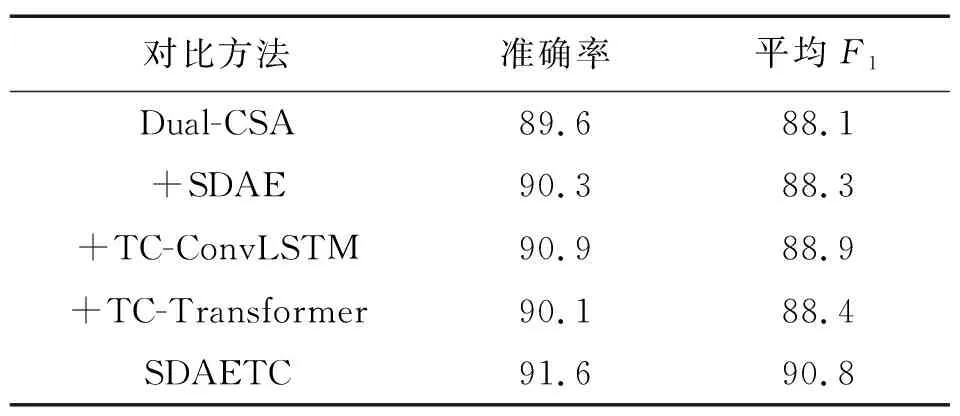
表5 SHL数据集消融实验结果
3.4.4 模型训练时间分析
为验证各模块对处理速度的影响,分别在GeoLife和SHL数据集上对训练时间进行验证,结果如表6所示。由表6可见,TC-Transformer模块对推理速度影响最大,训练消耗时间最长,这主要是因为其处理的RP数据是需要更多内存和计算的二维数据;TC-ConvLSTM模块影响其次,不仅需要提取空间特征,还需要提取时间特征;SDAE模块消耗时间相对最少,只需要对数据集进行降噪处理。整体来看,尽管SDAETC与基线模型Dual-CSA相比模型复杂度较高,训练时间较长,但是精度有相应的提升,在对分类精度要求更高且可以牺牲少量实时性要求的情况下,SDAETC能带来更好的表现。

表6 在两个数据集上的训练时间对比
4 结束语
为进一步利用轨迹数据提高交通方式识别的分类精度,本文提出一种融合堆叠降噪自编码器SDAE、TC-ConvLSTM和TC-Transformer的面向交通方式识别的轨迹分类网络。该网络通过堆叠降噪自编码器对轨迹数据进行降噪处理,然后将处理后的数据通过FS自编码器提取得到空间特征,与通过RP自编码器结合TC-Transformer提取得到的时间特征以及TC-ConvLSTM提取得到的时空特征相融合,用以进行轨迹分类。实验结果表明,SDAETC在分类精度方面优于对比方法,取得了良好的交通方式识别效果,且模型中的SDAE、TC-ConvLSTM和TC-Transformer均可以在牺牲少量训练时间的情况下对分类精度带来积极贡献。考虑到轨迹数据标识具有一定的难度,未来的工作将在网络模型的无监督、半监督或弱监督训练[19]方面做进一步探索。
