知识嵌入深度强化学习的6G网络决策算法
2024-02-26张亚林
张亚林,高 晖,粟 欣,刘 蓓
(1.重庆邮电大学 通信与信息工程学院,重庆 400065;2.北京邮电大学 信息与通信工程学院,北京 100876;3.清华大学 北京信息科学与技术国家研究中心,北京 100000)
0 引 言
随着第五代移动通信向下一代移动通信发展,网络新兴业务不断产生,网络设备不断激增,业务对网络时延[1]的要求也越来越高,因此,移动边缘计算[2](mobile edge-computation,MEC)成为一种新的网络赋能要素,能够极大提升通信系统的计算能力,实现对6G网络资源的高效利用。无线设备能够将较大计算任务卸载到端侧服务器,利用服务器的计算优势进行快速计算,从而减少系统执行时延。
新一代网络将是万物互联的网络,6G网络中的工业自动化、触觉互联网、智能物联网等通信场景下,无线设备不仅起到通信作用,还需要对网络中的数据进行计算,在深度神经网络最新突破的推动下,机器学习算法被认为是实时资源管控实现技术很有前途的方法。
在上述趋势下,深度强化学习(deep reinforcement learning,DRL)方法有助于构建6G网络典型场景下的资源管理决策框架而备受关注[3-4]。传统的无线通信场景利用复杂的数学建模,通过解决优化问题的方式进行资源管理,但是,在新一代无线通信场景下的问题通常是多目标优化问题[5]和非凸问题,传统的建模及求解方法存在很多局限,不能保证用户的实时资源分配需求。为了解决这些问题,动态规划[6]和分支定界[7]的方法被提出来,然而,这些算法具有极高的计算复杂度,特别是在大型6G网络中表现更加明显。相比于传统资源管理方法,机器学习决策算法可以借助自身的学习特性实现决策系统的自学习、自优化,并且可以满足用户对时延的更高层次需求,因此,学术界利用机器学习算法技术[8]代替传统的建模方式成为一种趋势。
利用DRL技术能够在训练完成后更好地减少资源决策系统的端到端时延[8-9],文献[10]利用深度强化学习技术进行频谱和计算资源调度,但是深度强化学习算法应用在通信系统中需要较长时间进行训练,收敛速度较慢。为了解决深度强化学习算法收敛时间过长的问题,学者提出用知识辅助[11]强化学习,从而缩短收敛时间。例如,利用QoS知识初始化强化学习的参数[12],将系统所有用户长期的奖励划分为多个用户长期的奖励进行评估;利用专家知识对DRL的奖励进行构建[13],定义特殊函数对奖励产生瞬时奖励反馈,对用户状态进行重要性抽样等。这些方式一定程度上能够加速DRL的训练速度,但是,DRL决策算法在6G典型网络场景下仍然存在资源分配收敛速度过慢的问题。在利用知识辅助强化学习方面学者已经做了有关研究,研究表明,知识嵌入强化学习能够有效地缩短训练时间,更快地达到系统收敛状态。与此同时,无线通信系统运作的过程就是一个知识累积的过程,经过无线通信系统长时间的发展,系统本身已经构建出一套完整的知识体系,有效地提取出这些无线通信的知识[14-17],并且合理地再利用到与机器学习结合的智能无线通信系统,将会为资源决策从训练到收敛的时间实现阶段性的提升。
知识和DRL算法的融合有望解决新型网络中的频谱资源、计算资源、缓存资源的实时分配难题。目前,学者已经对无线通信网络中多域资源分配展开研究,文献[18]主要利用DRL对频谱资源进行建模以及二进制计算卸载[19]的方式实现近似最优的计算速率,文献[8]主要考虑利用DRL实现工业互联网的多维资源管理建模,从而实现最大的推理精度。但是,在6G网络典型场景下仍然存在局限性,新型场景下是感知、计算、通信的融合,知识与机器学习结合的资源决策方式将会保证在新型网络智能的基础上实现各方面服务质量(quality of service,QoS)的提升,针对新型网络场景仍然需要对资源决策作进一步研究。
本文考虑在信道时变的云-边-端架构下的6G网络分配频谱与服务器计算资源,网络中存在一个基站和多个无线设备,其中服务器部署在基站侧,用于接收来自无线设备的计算任务。无线设备能够将较大计算任务卸载到服务器端,我们的主要目的是在时变的无线通信系统中联合优化卸载决策、服务器与无线设备之间的传输时间、服务器的计算资源。利用DRL的方式解决多目标优化问题,嵌入无线通信知识减少收敛时间,保证QOS的时延需求。
相比于存在的DRL和无线通信知识结合的方法,本文的主要贡献如下。
1)针对6G新型网络下的资源决策,提出了多评论家深度强化学习(multi-criticist deep reinforcement learning,MCDRL)框架。相比于传统的深度强化学习框架,增加了多评论家机制,能够保证用户对资源分配的实时需求,提升用户的QoS时延。
2)在MCDRL框架内,提出了无线通信知识嵌入多评论家深度强化学习(knowledge-embedded multi-critic deep reinforcement learning,KE-MCDRL)算法。系统映射知识与DRL的融合有效地解决了多目标优化问题,实现原地优化,相比于传统的无知识的无线通信系统有效缩短收敛时间。
3)在MCDRL框架内,提出了网络评估以及数据反馈方法,对网络资源状态进行评估,及时调整网络资源结构,优化用户资源分配决策行为,提高资源利用率。为了使得收敛更加迅速,训练数据更加优质,训练数据根据反馈结果对数据原型进行调整。
1 系统模型


图1 云边端计算网络Fig.1 Cloud-edge computing network
为了防止6G无线设备获得能量与无线通信之间的干扰,每个无线设备采用时分复用电路。系统时间被划分为若干相同长度T的连续时间帧,其设置小于信道相干时间,例如,在静态物联网中T以几秒为尺度[20]。时间帧T内无线设备获得计算任务请求,将分配其卸载时间τi∈[0,1],τi为第i个无线设备所占用的卸载时间。无线设备卸载到基站的通信速率与信道增益有关,hi表示在时间框架内基站到无线设备之间的信道增益,其中信道的上行链路和下行链路是相互作用的,无线设备能够将计算任务卸载到基站服务器端进行计算。第i个无线设备拥有的能量为Ei=μPihiT,其中,μ为能量获取效率,μ∈(0,1),P为第i个无线设备的功率。

由于每个无线设备处理的计算任务的重要性是不一样的,为了缩短收敛时间,保证无线设备的QoS时延需求,为每个无线设备初始化权重,其权重集合表示W={w1,w2,…,wi,…,wN|i∈N}。评估方面对重要的计算任务进行适当放大,加速神经网络的学习,在一定程度上保证重要计算任务的QoS时延需求。

1.1 网络评估模型
由于大数据量的增加,网络资源状态可能不满足用户的资源状态请求,从而需要对网络的资源状态进行评估,避免无效的计算任务卸载。利用效用需求指数对当前网络的资源状态进行评估。
(1)
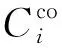
1.2 本地时延模型

(2)
由本地的计算速率可以得到本地可实现的最小计算时延。
(3)
1.3 卸载时延模型

(4)
(4)式中:B为信道所占用的带宽;N0为接收的高斯白噪声的功率。由计算速率可以得到卸载到边缘服务器最小的执行时延为
(5)
1.4 问题描述

(6)
满足约束条件
(7)
传统的求解方法主要对目标函数进行二阶Taylor近似,然后采用Newton method求解卡罗需-库恩-塔克条件(Karush-Kuhn-Tucker,KKT)最优条件。KKT条件是非线性规划最佳解的必要条件。对于最复杂的带不等式约束问题,则引入对数障碍函数,转化为带等式约束的凸优化问题,从而利用梯度下降或者Newton method进行求解[8]。传统的求解方法,复杂度极高,在计算资源有限的网络中难以实现原地优化,不适宜应用于实时决策的网络中。
本文将多目标优化问题转化为马尔可夫决策(MDP)过程进行求解,将信道无线设备的信道增益作为DRL的输入,很明显,R*(h)是一个多目标优化问题,很难实现原地优化,这里采用深度神经网络解决这个问题,这里的数据是经过专家知识构建好的系统状态和卸载决策之间的映射。因此,如果a给定,多目标优化问题就会转换成频谱资源和计算资源权衡的问题,极大地减少了计算复杂度。
2 知识嵌入多评论家深度强化学习算法
2.1 算法概述


图2 算法结构框图Fig.2 Block diagram of the algorithm

(8)
经过奖励函数R的评估。
(9)
(10)

2.2 无线通信知识
无线通信系统长期采取适合用户的资源决策行为,因此,构建出系统状态与决策行为映射关系知识体系,很多情况下并没有被AI赋能的6G网络利用(例如、信道状态与卸载决策之间的权重关系),仍然还有很多无线知识需要进行挖掘。另外,AI智能算法本身具有一定的特点,存在一定的缺陷(例如,收敛时间很长、决策时延不能满足用户QoS实时需求)。知识作为通信系统长期运作以及专家对知识普遍认知的规则结合体,有利于解决AI算法收敛速度慢,将知识与AI算法结合能够有效地解决当前AI算法存在的缺陷问题。本论文将无线通信系统中有利的知识抽象出来,形成有效的知识体系,分析深度强化学习自身特点,针对资源决策问题下适配深度强化学习算法规则。通过不同形式的知识与深度强化学习结合的方式解决缺陷问题,突出学习以及收敛性能。知识主要划分为2类:①AI方面。例如agent学习哪种数据的效率更高、模型与应用场景之间的匹配关系、奖励与策略的构建方式;②无线通信方面。例如系统数据之间的映射关系、无线设备所接受计算任务的重要性。这里的无线通信专家知识主要包括无线通信系统所积累的数据映射关系、用户QoS时延需求。KE-MCDRL可以有效地减少收敛时间,能够达到与现有决策方法接近最优的QOS时延需求。
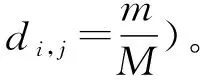

图3 卸载行为示意图Fig.3 Diagram of offload action
2.3 映射关系用于通信系统初始化
2.4 多评论家的决策行为QOS评估
图3a中,在DNN的输出端可以得到一个卸载决策行为向量(a=[a1,a2,…,aN]),但是系统初期得到的单个卸载决策行为在当前网络状态下性能往往不是最优的,因此借助量化函数[19]将DNN的输出量化为K个量化行为(a1,a2,…,ak),图3b中,再利用critic的奖励函数(公式(9))对卸载行为做QoS评估,从而选出最优的决策行为存放在replay buffer中。由于Replay buffer的空间有限,策略按奖励函数的取值大小进行排列,遵从先进先出的规则,每产生一个最优的决策行为就要将性能表现最差的策略剔除。DNN能够从replay buffer中进行抽样从而进行学习,从而使得学习到的都是最优的决策行为,在一定程度上保证了用户的QoS时延需求,相比于传统决策方法大大缩减了收敛时间。
3 性能分析

本文将知识嵌入深度强化学习算法中的DNN考虑1个输入层、2个隐藏层和1个输出层进行学习,其中,隐藏层分别有150和100个神经元,将整个算法放在python tensorflow1.2框架下进行学习。
本文希望通过调节参数使得当前的算法取得最佳效果,因此,分别对batch size、学习率、memory的大小以及训练间隔进行设置。每一种参数设置5种不同的情况进行对比。通过对比可以得出学习率为0.01,训练间隔设置为16,batch size 设置为128,replay buffer的大小设置为1 024为最佳状态设置。数据集采用系统状态与卸载行为映射知识数据,对传统数据集进行信息提取得到,共10 000条数据。数据集按照比例8∶2划分,其中,80%为训练集,20%为测试集。在以上环境下,进行KE-MCDRL算法的训练从而得到的无线设备的平均执行时延,如图4所示。从图4可以看到,无线设备在5~10时,每个无线设备的平均时延为10~20 ms,这样处理时延在网络中处于一个实时决策的状态。
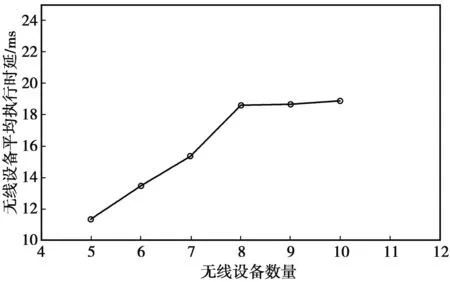
图4 不同无线设备数下的平均执行时延Fig.4 Average execution latency of different wireless devices
在仿真过程中对memory sizes、batch sizes、learning rate、训练间隔进行调参,如图5所示。本算法取到最好的memory sizes=1 024,如果设置过小,容易引起收敛性能较大的波动,设置过大则需要更多的数据收敛到最优性能。在训练过程中随机在replay buffer中进行抽样,因此,batch sizes要小于memory sizes,这里取到效果最佳的train batch sizes=128,设置较小的batch sizes对于replay buffer的作用没有明显作用;设置较大的batch sizes则意味着用很多老数据进行训练,降低收敛性能,并且要消耗更多的时间。Learning rate如果设置过大容易发生梯度爆炸,模型难以收敛,较小的learning rate损失函数的变化情况过慢,容易过拟合,本算法采取最佳的learning rate为0.01。训练间隔越小收敛越快,但是对于训练来说,太频繁地更新是不必要的,这里选择相对当前场景下的最佳训练间隔为16。
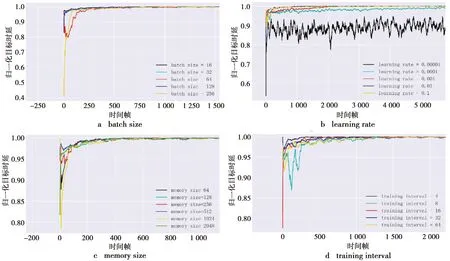
图5 调参变化曲线Fig.5 Parameter change curve
图6给出了不同算法的训练损失变化的曲线,考虑了深度强化学习本身随机选择行为的情况,即蓝色曲线Actor-Critic算法,在文献[19]中提出的知识辅助强化学习的情况,即绿色曲线K-DDPG算法,以及本文所提出的无线知识嵌入多评论家深度强化学习算法,即红色曲线KE-MCDRL算法。从图6中可以明显看出,KE-MCDRL曲线的训练损失明显低于其他2个曲线,并且在时间帧为2 000左右时能够到最佳水平;K-DDPG在时间帧为7 000~8 000才能看出抵达最佳水平,但是其损失减少情况并不是很明显;Actor-Critic算法在损失上一直处于0.5上下波动,并没有很好地减少损失。可见,提出的KE-MCORL算法在损失上获得最小值,相比于其他2种算法能够达到更高的系统准确性,达到近似最优的系统性能。

图6 不同算法的训练损失变化曲线Fig.6 Training loss curves for different algorithms
图7给出了不同算法的归一化目标QoS时延曲线,为了观察更加明显,将得到的目标QoS时延做归一化处理。从图7可以明显看出,所提出的KE-MCDRL算法在系统初期的波动变化很大,在600时间帧左右时能够达到稳定状态,即满足无线设备的QoS时延。K-DDPG算法在系统初期处于一个稳定上升的阶段500时间帧左右时达到相对的稳定状态。而对于Actor-Critic算法随机选择行为进行训练时,在系统初期能够获得较大的优势,但是一直处于上下波动状态,不能很好地收敛到无线设备满意的状态。相比于其他2种算法,提出的KE-MCDRL算法收敛性能与K-DDPG算法的差距不大,所提出算法在牺牲系统初期的收敛性能获得了更好的训练准确度。因此,所提出的算法无论在训练损失还是收敛性能上都表现出近乎最优的性能。系统的主要参数如表1所示。

表1 系统的主要参数
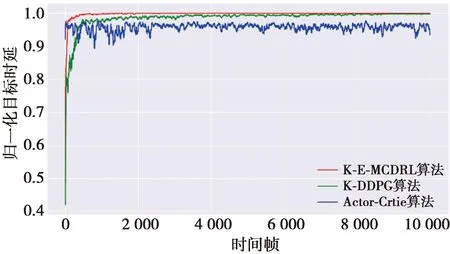
图7 不同算法的归一化目标QoS时延Fig.7 Normalized target QoS latency for different algorithms
4 结束语
本文从提高网络资源利用率,减少无线设备的执行时延角度出发,研究了云-边-端6G无线通信场景下用户执行时延最小化的频谱资源和计算资源分配问题。考虑主要用无线网络节点计算资源、信道的频谱资源以及无线设备的能量作为约束,构建了信道增益、计算资源、频谱资源、卸载行为的多目标优化问题,利用深度强化学习技术实现原地优化。实现对频谱资源和计算资源的权衡,降低了计算的复杂度、机器学习模型的收敛时间以及系统的总执行时延。仿真结果表明,本文提出的方法有较好的收敛性能,以及能够达到近似最优的系统执行时延,因此能够在6G网络下实现实时资源决策。
