基于类型矩阵转移的汉越事件因果关系识别
2024-02-26高盛祥余正涛黄于欣
高盛祥,熊 琨,余正涛,张 磊, 黄于欣
(1.昆明理工大学 信息工程与自动化学院,昆明 650500;2.昆明理工大学 云南省人工智能重点实验室,昆明 650500)
0 引 言
因果关系识别是自然语言处理(natural language processing,NLP)的重要主题之一,其目标是识别出自然语言文本之间的因果关联信息。从汉越相关新闻文本中判断出新闻事件间的因果关联关系,能够帮助人们了解局势的变化,把握汉越动态并及时应对,支撑相关交流及合作。

因果关系属于深层语义问题,通过跨语言建模因果关系的方法,超出了传统深度神经网络模型的浅层语义理解范畴,这导致汉越跨语言文本之间的相关性计算难度较大。文献[4]提出新闻事件句对类型的转变对因果关系有一定的约束作用,这是因为汉越双语新闻事件句对之间的因果关系通常依赖于事件句对之间隐含的深层次因果语义信息。
针对以上问题,本文通过跨语言训练以统一跨汉越语言的文本语义空间,然后使用树形长短期记忆网络(Tree-LSTM)处理得到更多的无关汉越句法的相似语义特征向量,最后建立注意力机制挖掘含因果逻辑的事件类型相关性约束,提出了基于类型矩阵转移的汉越新闻事件因果关系识别方法。
1 相关工作
事件因果关系抽取可以依据语言类型分为2类:①基于单语的因果关系抽取的方法,这类方法不存在语义空间不统一的情况;②基于跨语言的因果关系识别的方法,这类方法通常是在富资源文本中进行识别抽取。
因果关系的研究工作在单语言方面主要可以分为以下3类方法:基于规则的方法;基于机器学习的方法;基于深度学习的方法。基于规则的方法[5-6],它是利用语言学上的规则知识构建模式匹配约束进行因果关系的推断,包括语法时态、修辞手法、语义特征、词汇符号特征等方面定义好规则模板。这类方法的缺点是由于自然语言语义表达包括词汇、形态和句法等的变化灵活性,无法将因果关系的语言模式都穷尽,因而其准确性和召回率较低。基于机器学习的方法[7-9]从大量的标注数据中自动提取有用特征,并推断因果关系。然而由于其特征是针对特定的模式和领域进行设计的,该类方法移植性较差且设计耗时等原因,在越南语上可用性极低。
随着深度学习的流行,研究人员开始使用基于深度神经网络的方法。基于深度学习的方法搭建数层隐含层来学习文本表示,具有强大的学习表征能力,不再限制于浅层特征且无须复杂的特征工程就可以直接捕捉文本深层次的隐含语义特征,因此,近年来因果任务多使用采用深度神经网络的模型。Nguyen等[10]使用卷积神经网络从句子中自动提取特征进行关系分析。Santos等[11]重新选择了一种新的损失函数使用卷积神经网络实现关系分类。Li等[12]提出了一种面向知识的卷积神经网络提取因果关系。Li等[13]基于一种新的因果关系标记方案将因果关系抽取表述为一个序列标记问题,提出一种神经因果关系提取模型(SCITE)。
新闻事件因果关系的研究在汉、英等富资源语言平台下环境下进行,研究已经趋于成熟,并取得了不错的成果[14-16]。Zhao等[17]提出了一种新的限制隐藏朴素贝叶斯模型来从文本中提取因果关系,优点在于能够处理特征之间的部分交互,从而避免了模型的过拟合问题。Dasgupta等[18]提出了一种基于语言学的递归神经网络架构,能自动从文本中提取因果关系。这些方法的前提是此类语料较为丰富,通过大量的跨语言富资源语料文本,可以嫁接起跨语言文本之间的语义鸿沟。
2 汉越跨语言新闻事件因果关系识别模型
本文模型由3部分构成:基于双向长短时记忆网络(Bi-LSTM)提取汉越文本语义特征的汉越联合编码器F;结构化特征提取器C和结合文本特征;文本结构特征和文本事件类型特征的Attention层。此模型如图1所示。

图1 基于事件类型转移注意力的因果关系识别模型Fig.1 Causal relationship identification model based on event type diversion
模型使用F模块作为汉越跨语言的主要特征提取层,将左右文本中单词嵌入F,获得左右2个文本最终的隐藏状态HL、HR。其中,使用Bi-LSTM对输入的汉越词嵌入向量提取特征,输出2个方向的隐藏状态向量序列,越南语和汉语都存在与之相反的序列,不同于主流的正逆序列拼接再计算,注意力机制将分别依据2个事件类型嵌入矩阵对2个方向的隐藏状态序列计算注意力权重,减小2种语言的差异。使用Tree-LSTM网络作为语义增强的特征提取层, 在提取句子特征时按照句子的句法结构,利用语法信息增加模型的分类能力。将文本L和文本R中所有的单词表示成汉越跨语言词向量,然后将句对文本对特征进行结构化表示,使用Tree-LSTM网络计算根节点的隐藏状态htree-L、htree-R。文献[19]的方法计算左右文本的基于句法的相似度信息向量hs。
h×=htree-L·htree-R
(1)
h+=|htree-L-htree-R|
(2)
hs=σ(W(×)·h×+W(+)·h++b(h))
(3)
(3)式中:W(×)、W(+)为对应的权重参数;b(h)为偏置项。
针对汉越的新闻事件句对,利用新闻事件的文本事件类型到另一新闻事件的文本事件类型这一转变过程,建立注意力机制。在汉越跨语言的新闻事件因果关系分析中,该注意力机制充分考虑到一条新闻事件文本在与另一条新闻事件文本存在因果关联时的事件类型的转换知识。模型在处理汉越双语事件句对时,针对事件类型建立注意力机制,为当前句子融入事件类型转移相关的因果逻辑信息。同时,整合Bi-LSTM提取的线性序列语义和Tree-LSTM提取的句法树信息,就更容易对长距离节点之间的语义搭配关系进行学习。

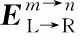
给定左边汉越新闻文本词嵌入序列的隐藏状态向量输出矩阵HL,其中,hL,k为第k个隐藏状态向量,HR、hR,k同理。
(4)
(5)
α=softmax(Wα[ββ′])
(6)
(6)式中:Wα(Wα∈R2d*2d)为β、β′相互融合的权重参数矩阵;α(αi∈Rn)为注意力机制的权重向量。αi的值决定了对应新闻文本词嵌入序列的第i个词的隐藏状态向量hL,k能保留多少信息。所以,α剔除了序列中模型认为不重要的部分,筛选并保留对最终损失函数有利的信息。
基于事件类型转移的因果交互注意力机制下,注意力权重α加权得到的因果事件类型转移逻辑相关的语义特征向量为
S=αHL+[Wαα]HR
(7)
模型将上述得到的向量经过平均池化(average pooling,ave)和最大池化(max pooling,max),转换为固定长度的向量V,计算式为
(8)
vs,max=maxSi,i=1,2,…,s
(9)
V=[vs,ave;vs,max]
(10)
将V输入最终的多层感知器(MLP)分类器以确定最终的因果关系。实验中,MLP是tanh激活和softmax输出层,若代价函数为J(w,b),则因果关系概率p可由下式求得
y=softmax(WV+b)
(11)
p(y|P)=softmax(WV+b)
(12)
2.1 基于Bi-LSTM的汉越联合编码器F
本文参照文献[4]中的方法训练汉越联合编码器F。F旨在学习跨语言提取汉越词嵌入向量的特征,并抑制语言鉴别器Q,而训练有素的Q无法分辨出F提取特征的语种,这个特征可以看作是语种无关而事件类型相关的。在F和Q之间有一个梯度反转层,使F的参数在Q中都参与梯度更新。Q试图为汉语输出更高的分数,为越南语输出更低的分数,因此,Q是对抗性的。训练F的模型如图2所示。

图2 基于汉越语言鉴别器的跨语言对抗训练Fig.2 Cross-language adversarial training based on Chinese-Vietnamese language discriminator

(13)
(14)

(15)

(16)
2.2 结构化特征提取器C
Tree-LSTM在树结构上递归,但依然保留了LSTM的遗忘机制,可筛选出句法结构中对结果有用的子树,剔除仅仅是一些可能没有语言学意义的子序列,从而更容易对长距离节点之间的语义搭配关系进行学习,以取得更好的分类性能。
采用中文哈工大的LTP工具和越南语开源句法分析工具VnCore NLP来构建句法关系,汉越例句的句法表示如图3所示。

图3 越南语与中文例句句法图Fig.3 Syntax diagram of Vietnamese and Chinese example sentences
图3中,词性标签用于辅助语义表示,如表1所示。

表1 句法关系标签
语法解析信息有助于模型获取信息之间的交互关系,得到句法关系以后,将汉越句子的句法树输入Tree-LSTM,Tree-LSTM模型只在根节点上受到Label的监督。Tree-LSTM子节点的状态会不断累加,给定一个Tree,对于节点j,cj表示其子节点的集合, Tree-LSTM的公式为
(17)
(18)
(19)
(20)
(21)
hj=oj⊙tanh(cj)
(22)
(17)—(22)式中:σ代表sigmoid函数符号;b是偏置项;U为子节点隐含值的权重;l表示第k个子节点的第l个子节点;W表示不同单元内的权重;⊙表示对应元素相乘,模型中的任意一单元的子节点采用不同的参数矩阵。
当输入是一个语义重要的词时,参数W( j)下的输入门ij接近于1;而当输入是一个语义相对不重要的词时,输入门ij接近于0。Tree-LSTM中第j个节点包含记忆单元cj、隐藏单元hj、输入门ij和输出门oj。Tree-LSTM根据语法分析树结构构建,每个节点依赖其他多个叶节点。
对于任意一个子节点k,其父节点j都有一个对应的遗忘门fjk。Tree-LSTM网络经过逐级计算将树根节点的隐含输出作为句子的向量表示。
2.3 事件类型转移
从自然语言的因果关系中,可以发现事件类型对因果关系模型的约束作用。如果事件e1是因事件,事件e2是由事件e1造成或引起的果事件,那么事件e1和e2之间除了语义关联外还会存在不对称性。因为事件e1和e2是时间流水上的某些一连串动作,所以存在先后之分。因事件必须发生在果事件之前,由事件e1导致了e2,即e1到e2存在一个时间的指向性,如表2所示。
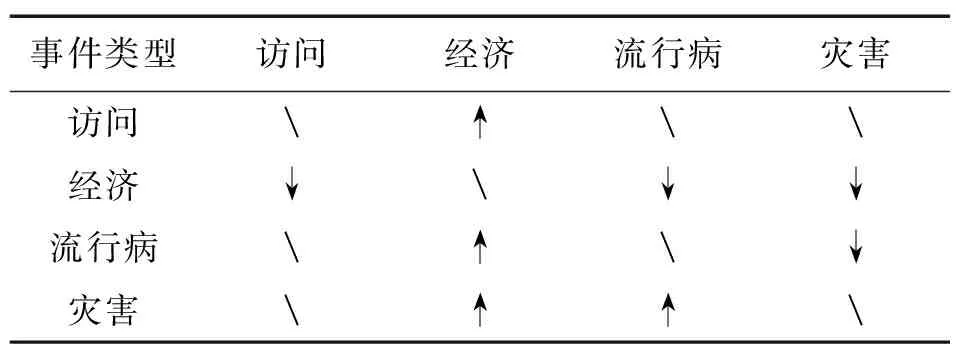
表2 部分事件类型对因果关系的影响
同时,e1和e2作为事件也存在一个事件本身的指向性,表2中,访问事件极有可能引起经济上升事件,但与疾病、争端冲突无关;灾害事件极有可能引起经济的衰退下降、疾病发生等事件。依此,推断由因到果的关系指向包含了一种事件类型到另一种类型的转变,通过检测到的事件类型等信息,使因果关系分析模型更好地利用事件类型转移分析因果关联关系。
表2中,“↑”表示引起;“↓”表示被引起;“”表示无关项。观察表2,含有访问事件类型的新闻文本与另一含交易事件类型的新闻文本存在因果关系,外交访问易导致双方经济贸易的上升,前者为因,后者为果,不可颠倒。
构建由访问事件类型到交易事件类型的转移矩阵,该矩阵预先定义的访问事件类型矩阵与交易事件类型矩阵通过矩阵运算得到。每个事件类型转移矩阵,都代表了从一种事件类型转移到另一种事件类型的某种因果逻辑信息,包含与当前事件句对可能存在的前因后果事件指向性。这使得模型在识别事件句对的因果关系中能够考虑到一条新闻事件文本在与另一条新闻事件文本存在因果关联时,所蕴含的事件类型的转换知识。
3 实验及结果分析
3.1 数据集介绍
1)语种对抗训练。在中国和越南新闻网站基于相似主题和板块爬取大量的汉越可比语料。汉语数据约21万条和越南语数据约11万条用于语言对抗训练。
2)汉越因果识别。汉越跨语言新闻数据集含有10个标签(9种预设事件类型和1种其他)下的44 612条短文本事件句,其中,含因果关系的有24 528条,其余被视为不存在因果关系,作为训练集,2 736对因果事件作测试集,如图4所示。预设事件类型分别为访问(Visit)、会晤(Meet)、社会(Contact)、经济(Economic)、改革(Change)、交易(Transaction)、冲突(Conflict)、流行病(Epidemic)、灾难(Disaster)。

图4 汉越新闻语料统计Fig.4 Statistics of Chinese-Vietnamese news corpus
3.2 实验设置
实验配置为window10、Python3.7、Pytorch0.4.0。Bi-LSTM网络权重值的初始scale为0.05,学习率的初始值为1.0,梯度的最大范数为5,初始学习率可训练的epoch数为6,总共可训练的epoch数为10,随机失活率为50%,学习速率的衰减速度为0.8。
Tree-LSTM网络在参数设置方面, 隐藏层大小为50, 学习率为0.05、批尺度为25。模型参数以L2正则强度为10-4进行正则化。为缓解过拟合现象,引入dropout用于事件检测器的全连接层。采用自适应矩估计Adam训练模型进行优化。
为验证本文方法的有效性,分别采用对比基线模型实验、预训练模块消融实验、注意力机制的对比实验、事件类型反向训练和句法消融实验进行设计验证。
3.3 评价标准
准确率(Precision,P)、召回率(Recall,R)和F1值是因果关系任务的常用评价指标。准确率是所有的文本中正确检测出事件类型的比例,召回率是正确检测出事件类型的占实际含有事件类型的文本的比例,F1是准确率和召回率的综合度量值,公式为
(23)
(24)
(25)
(23)—(25)式中:TP是所有含事件的文本中被正确检测出数量;FP是检测出事件的文本中错误的和实际不含事件的数量;FN是检测出不含事件而实际含事件的数量。
3.4 模型对比实验
实验评估4个模型,如表3所示。

表3 基线模型对比实验结果
表3中,各模型介绍如下。
Ours:本文提出的基于事件类型转移的汉越新闻事件因果关系识别模型;
TextCNN:Yoon K等[23]首次将卷积神经网络应用到文本分类任务,能够较好地捕捉局部相关性。
BiGRU:BiGRU 是输出由2个单向、方向相反 GRU 的状态共同决定的神经网络模型[24],有利于文本深层次特征的提取。
Bi-LSTM-ATT:Zhou等[25]根据位置特征扩充字向量特征,通过多层注意力机制,提高LSTM 模型输入与输出之间的相关性。
文本是天然的时序信息,循环神经网络更擅长捕获时序特征,通用的BiGRU网络取得59.89%的因果关系准确率。卷积神经网络擅长空间特征的学习,集中于局部特征,而TextCNN模型较BiGRU提高了0.9百分点的准确率,这表明TextCNN模型可能适合汉越双语事件句对之间找到交互的信息。对于梯度消失和梯度爆炸有一定缓解。BiLSTM-ATT可以利用上下文相关信息捕获句子的语义信息,额外的注意力机制为不同的特征分配不同权重,获得了3.02百分点的准确率提升。
近日,由全国打黑办挂牌督办的孟庆革等10人黑社会性质组织团伙案二审宣判:对孟庆革以组织、领导黑社会性质组织罪等8项罪名数罪并罚,判处有期徒刑20年,同时领刑的还有其前妻、与其同居多年的小姨子,儿子、外甥、舅舅、前妻侄女等一帮手下干将。(2018年7月8日央视报道)
该场景中,本文模型在3项评价指标中均取得最优值,准确率比次优模型提升2.08百分点。这是因为BiLSTM-ATT的注意力机制没有利用事件相关信息,输入文本的词向量之间的权重分配依据文本自身;而本文中注意力机制基于事件类型转移整合句子的各部分权重,获得不同语言新闻事件之间可能存在的因果关联关系特征以及树形LSTM提取的句法结构化特征,强化了语义建模能力,准确率达到了65.89%。这证明本文因果关系判别模型能够获取新闻事件深层次的语义信息,同时利用更多事件类型特征信息判断因果关系。
3.5 实验验证分析
3.5.1 对抗训练的汉越共享嵌入层对模型的影响
为了验证预训练的汉越共享嵌入层对事件因果的影响,设计实验,将汉越共享嵌入层Bi-LSTM的参数随机初始化(模型Ⅰ),实验结果如表4所示。

表4 预训练消融实验实验结果
表4显示,去除预训练的参数块后,因果关系的判断性能在3项指标上均出现下滑。这证明通过语种对抗训练后的共享特征提取器可以有效地拉近汉越文本表示的距离,对下游的任务有较好的提升。
3.5.2 类型转换注意力机制的对比模型
考虑通过由因到果的事件类型变化来判断关系是否具有起因和结果无关系,设置没有类型转换注意力机制的对比模型(Ⅱ),实验结果如表5所示。

表5 注意力机制消融实验结果
表5表明,不含类型转换注意力机制的情况下,3项指标均大幅下降,尤其是准确率P,明显不如类型转换注意力机制的模型。这证明,基于因果事件句对本身的事件类型转变信息建立注意力机制,可以捕获跨越语言的句子间因果逻辑关系,使汉越跨语言新闻事件因果关系识别模型效果进一步得到提升。
3.5.3 因果关系识别受正确事件类型影响
为了验证模型的因果关系识别受到正确的事件类型信息的指导,设计实验,输入模型的事件句对A、B,A为B的因事件,B为A的果事件,给模型错误的事件类型标签,也就是使用事件句对集合输入汉越跨语言新闻因果关系模型(Ⅲ)。实验结果如表6所示。

表6 事件类型调换对比实验结果
表6表明,即使句对确实存在因果关系,接受错误事件类型标签训练后模型(Ⅲ)的因果关系识别各项指标也低于接受正确事件类型标签的模型。这种差异强化了A和B之间的因果关联信息表征,再次说明了正确的事件类型标签信息有助于因果关系的识别。
3.5.4 树结构网络对模型的影响
本文的因果关系模型可以只基于循环神经网络和注意力机制,在删除树结构网络后,重新实验得到未利用句法信息的因果关系判断模型(Ⅳ),对比结果如表7所示。

表7 句法消融实验结果
表7表明,在删除树结构网络后,因果关系模型只基于Bi-LSTM的特征提取和注意力机制,因果关系的判断性能在准确率、召回和F1值上均出现下滑,证明不论汉语还是越南语的句法信息都加强了模型对句子语义的理解能力,有助于模型因果关系识别能力的提升。
每个消融模块去掉后,F1都明显下降,这是因为F1的值是由准确率及召回率决定的,部分消融实验的结果是准确率下降较多,召回率下降相对较少导致的F1值下降,如模型(Ⅱ)、(Ⅲ)结果所示,部分消融实验是由于准确率下降,但召回率下降相对更明显导致的F1值下降,如模型(Ⅰ)、(Ⅳ)结果所示。从结果上来看,给模型错误的事件类型标签会导致准确率下降最多,召回率下降些许而导致F1下降到0.613 7,因此,在本文的因果关系识别中,正确事件类型的重要程度最高。
4 结束语
本文提出了基于类型矩阵转移的汉越新闻因果关系识别的神经网络模型,有效地结合了基于对抗训练汉越共享嵌入层获取的语义特征、树形LSTM提取并计算出相似度语义信息分类事件句对的因果关系对。其中,基于对抗训练所获取的语义特征缓解了汉越语义空间不统一的问题,具有相似度语义信息分类事件句对的因果关系对也能较好缓解汉越语法结构上的差异性和局限性。实验结果表明,提出的方法在汉越跨语言新闻事件因果关系的识别上取得了较好的效果,且所加的每个模块均对模型性能有所提升。
