基于再感知双模型联合训练的散焦模糊检测
2024-02-26朱智勤李嫄源齐观秋李华锋
朱智勤,孟 骏,李嫄源,齐观秋,李华锋,姚 政
(1. 重庆邮电大学 图像认知重庆市重点实验室,重庆 400065; 2.布法罗州立学院 计算机信息系统系,美国 纽约 14222;3.昆明理工大学 信息工程与自动化学院,昆明,650031)
0 引 言
受光学成像系统的物理限制,当被摄物体超出相机景深范围时,图像就会发生光学散焦。散焦模糊检测(defocus blur detection, DBD)旨在区分给定图像聚焦区域和散焦区域。实现聚焦/散焦区域的准确检测在许多应用中都很重要,例如多聚焦图像融合[1-2]、图像恢复[3]、图像质量评价[4]、图像深度估计[5-6]、显著性对象检测[7]等场景。
根据所使用的图像特征,散焦模糊检测可以分为基于手工特征和基于学习特征两大类方法。基于手工特征的方法通常利用物体的梯度和频率等特征区分聚焦/散焦区域。这些方法不利用全局语义信息,无法区分低对比度对焦区域和杂乱的背景,对焦区域和模糊区域之间的边缘信息也没有得到很好的保留。
深度卷积神经网络(convolutional neural network, CNN)因其强大的特征提取和学习能力,应用在了各种计算机视觉任务中并取得了显著的效果。基于深度学习的方法逐渐成为散焦模糊检测的主流。文献[8]在包含强边缘的图像块中提取深度网络特征和手工特征,但低对比度的聚焦区域没有很好地被区分。文献[9]提出了名为BTBCRL的检测模型,利用低级空间信息和高级语义信息整合以改善预测结果,同时利用多流策略来应对散焦度对图像尺度的敏感性。文献[10]提出了一种新颖的散焦模糊检测网络DeFusionNet,将特征分组为浅层特征和语义特征,在网络前向计算过程中以跨层的方式相互拼接这两组特征,然后反复迭代细化深度和浅层的判别深度特征。图1展示了源图像、Ground Truth(GT)、基于手工特征的方法(SS[11]和HiFST[12])和基于深度学习方法(EFENet[13]和本文模型)的对比图。由图1可以看出,EFENet和本文模型的预测图像更接近GT,体现了基于深度学习的方法的优越性。

图1 源图像、GT图像和不同的预测图像Fig.1 Source image, GT image and different predicted images
基于深度学习的方法虽然已经取得了显著的检测效果的提升,但仍然存在一些问题[14]。
一方面,如何在训练阶段针对模型响应错误的区域进行优化,是当前待解决的一个问题。传统基于深度学习的散焦模糊检测模型,利用复杂的模块设计提升了检测效果,但在训练阶段只利用原始标签监督模型优化,导致未能针对性地在学习训练过程中响应错误区域的图像特征,而这些区域通常都是难以预测的对象场景。因此,在训练过程中针对这些未响应区域进行再感知,能改善模型的预测性能[15]。此外针对散焦模糊检测结果的互补性,构建对焦和散焦两个预测模型,其中一个模型做出响应时,另一个模型就不响应[16]。在训练阶段将错误分类的经验反馈到互补模型上,互补模型根据该经验进行微调校正。
另一方面,如何利用不同尺度的特征信息也是一个待解决的问题。基于深度学习的方法的优势在于利用深度结构来学习不同尺度语义或高级信息。文献[9]虽然通过对不同尺度的结果利用残差学习进行逐步微调细化,但由于缺少对检测结果图原始语义信息的利用,在细化过程中模型没有依据判别上一尺度检测结果的正确与错误,导致预测误差持续积累进而影响最终的预测效果。文献[10]将多尺度特征图利用双线性插值算法采样到和输入原图像相同的大小,然后利用一系列的卷积层回归得到检测结果。然而来自不同级别的特征具有不同的尺度和维度,对特征图的直接插值缩放将引入额外的噪声,因此最终的预测结果还可优化。
为了解决上述问题,本文提出了一种新颖的散焦模糊检测方法,描述如下。
1)再感知双模型联合训练方法。在训练过程中为了针对输入图像中未成功响应的区域进行优化学习,本文将模型的原始输出结果中未正确响应的对焦区域的原始空间位置和视觉信息映射到完全模糊的图像中去,产生有足够清晰/模糊区分度的合成图像,然后利用损失项驱动模型学习未响应区域的特征信息,实现对未响应区域的再感知。为了优化模型响应多余的区域,本文利用互补特性进行监督,构建了两个互补的预测模型,当其中一个模型出现多余响应时,通过损失项将当前模型的错误分类经验反馈到互补的预测模型上,随后互补模型根据该经验进行微调校正,提升预测结果的质量。
2)新颖的散焦模糊检测模型,即基于注意力机制多尺度语义融合散焦模糊检测网络(multi-scale semantic fusion defocus blur detection network with channel attention, MSFCANet)。其中包含全局通道注意力模块(global channel attention module,GCAM)和多尺度语义融合模块(multi-scale semantic fusion,MSF)。本文模型在计算每一个尺度的预测结果前,利用MSF引入了所有前序结果的原始语义特征作为参考,再利用残差学习的方式逐步细化预测结果;级联卷积和反卷积模块对特征图进行调整,以模型学习的方法调整不同阶段特征图的维度和大小使其能相互适应;同时,进一步增强输入特征的表达能力,以筛选出最值得关注的特征图。
1 相关工作
1.1 基于手工特征的方法
图像切分为图像块后,景深内的图像块通常具有很强的梯度,而景深外的图像块这一特性却不明显。因此,大多数传统的散焦模糊检测方法利用梯度或频率特征来区分清晰图像块和模糊图像块[17]。文献[18]提出使用高斯核对散焦图像进行二次模糊,利用原始图像与二次模糊图像的梯度之比判别散焦区域。文献[19]发现图像块在进行高斯核模糊后该图像矩阵的秩会降低,而且随着高斯核模糊量的增加,矩阵的秩会单调递减。针对这一现象,文献[19]提出了一种在梯度域估计图像散焦模糊信息的方案。考虑到相机传感器导致的噪声和失真,文献[12]提出了一种高频多尺度融合和梯度大小排序变换的方法,用于实现鲁棒的图像散焦模糊检测。文献[20]重点研究了在图像梯度域、傅立叶域和数据驱动的局部滤波器中的判别性特征,以构建能适应各种模糊尺度的散焦特征。虽然清晰的图像区域能产生明显的梯度信息,但某些模糊区域在某些情况下也可能会产生平滑的纹理。为了克服这个问题,文献[21]研究了一种多尺度奇异值分解融合方法。该方法证明,通过融合来自多尺度图像块的单值的各种子带,可以有效地防止模型对模糊区域的误判。除了基于梯度或频率的方法外,文献[11]引入了基于对数平均频谱残差的度量。根据该度量,在替代优化中从粗到细获得模糊图。
1.2 基于学习特征的方法
尽管手工制作的基于特征的方法对散焦模糊检测有很大贡献,但当图像包含复杂场景时,它们的鲁棒性不能满足要求。因此,构建更具判别力的特征对于进一步提升检测模型的效果具有重要意义。由于具有强大的特征表示能力,深度卷积神经网络[22-24]被广泛用于散焦模糊检测。文献[8]设计了2个特征:①鲁棒性强的手工特征;②基于卷积神经网络提取的深度特征。作者首先稀疏地选择具有强边缘的图像块,提取这些块的深度特征和手工特征;然后,使用神经网络分类生成稀疏结果图;最后,利用边缘保留引导稀疏结果图,得到最终的检测结果。
与文献[8]输入图像块进行处理的方法不同,文献[25]通过端到端的深度卷积神经网络实现散焦模糊检测,设计了名为BTBNet的全卷积网络用于整合低层次的线索和高层次的语义信息;在输出结果的部分,设计了一个融合和递归重建网络来完善模糊检测图;此外,为进一步提高性能,将最后的融合递归重建网络替换为级联的残差学习网络[9],以逐步调整预测结果图。为了解决高计算和内存的问题,文献[9]通过增强网络模型的多样性而不是扩展网络宽度和深度的方式,设计了一个交叉集成网络。为了探索多种编码特征的多样性以及这种多样性特征的集成策略,文献[13]在文献[9]的基础上,通过构建一个编码器来产生多组卷积特征。文献[10]将来自各个层的特征融合为浅层和语义特征,然后用于细化细节并获得更好的模糊区域位置。文献[26]提出了残差学习策略来学习预测图和Ground Truth之间的残差图,构建了一个循环结构以进一步有效地结合低级和高级特征。为了解决用于散焦模糊检测的训练数据精细标注时费时且易错的问题,文献[27]提出了不使用像素级标签就可训练的深度检测模型,通过利用生成对抗网络的思想,隐式地引导预测结果的生成。
2 本文方法
2.1 总体结构
本文利用基于注意力机制的多尺度语义融合散焦模糊检测网络来提取多尺度的图像特征和预测散焦模糊结果,方法的整体架构如图2所示。VGG16网络的前5层卷积层构成提取不同尺度图像特征的骨干网络,本文在每一层的特征输出前设计了GCAM。同时,为了使模型关注预测结果图中的有效特征信息,本文利用MSF构建了一系列重建模块/多尺度特征融合重建模块(reconstruction-prediction/reconstruction-prediction muilt-scale semantic fusion,RP/RPMSF)组成结果预测部分。本文在多尺度特征融合重建模块中,利用多尺度特征融合模块以学习的方式将前序的原始语义特征逐步细化到输出尺寸,引入所有前序结果的原始语义特征作为参考;在训练阶段设计了再感知过程,通过将未正确响应位置的信息映射到新图像中,构造有足够区分度的合成图像,然后利用该合成图像优化模型的学习效果引导模型学习响应失败的区域;此外,为了进一步利用互补特性进行监督,构建了互补预测模型。在训练过程中,当其中一个模型出现多余响应时,利用损失项将错误的分类经验反馈到另一预测模型上,此模型根据该经验进行微调校正,提升预测结果的质量。

图2 总体结构Fig.2 Overall structure
2.2 再感知双模型联合训练
在传统的散焦模糊检测模型的训练过程中,模型的输出在每一次优化时都采用相同方式处理,而不是针对性地对响应错误位置的图像特征进行监督学习。设计再感知双模型联合训练过程的目标是设计一个更有效的训练方式。该方式包含对缺失区域的再感知和对多余响应区域的抑制两部分。预测模型根据输入图像计算得到预测结果OF,然后根据输入图像的真实标签将OF中未响应的区域映射到全模糊的图像上去得到合成图像Ima。之后图像Ima进入网络计算得到预测结果O′F,利用O′F计算损失LF,2使得预测模型针对从合成图像Ima中学习未响应区域的图像特征,实现对未响应区域的再感知。本文构造了另一个预测模型DBDNetD(·),其预测结果和之前的预测模型DBDNetF(·)互补。DBDNetD(·)进行和DBDNetF(·)类似的计算过程,区别在于合成时使用全清晰图像,预测得到结果OD、O′D。通过联合互补模型的预测结果计算损失LF,3,从而实现对模型预测结果中响应多余区域的优化。在训练过程中的损失函数具体数学表示为
(1)
(1)式中:Lt表示训练过程中模型的总损失;gi代表缩放到和Oi相同分辨率的标签图像。本文使用BCE[28]、SSIM[29]和IoU[30]组合形成Loss(·),用来在训练过程中衡量预测结果和真实标签间的差异,计算式为
Loss(a,b)=LBCE(a,b)+LIoU(a,b)+LSSIM(a,b)
(2)
OF,OD,O′F,O′D的定义如下。
(3)
(2)—(3)式中:DBDNetF(·)表示对焦预测模型;DBDNetD(·)表示散焦预测模型;IfullBlur代表完全模糊的真实图像;IfullFocus表示全焦图像;Ima表示合成的模糊图像;Imb表示合成的清晰图像。
在模型的训练过程中,DBDNetF(·)进行预测得到OF时,由于OF,1中缺少了对正确区域的响应,输入图像Iim的(1-OF,1)部分将包含没有被预测到的清晰图像区域,将该区域与全模糊图像进行合成得到图像Ima,即图像Ima中保留了模型未正确响应区域的原始空间位置和视觉信息。将图像Ima输入DBDNetF(·)中进行再感知得到OF′。为了使LF,2更小,DBDNetF(·)需要利用图像Ima进行特征提取和预测,尽可能地将缺失区域在OF′响应。通过这个过程使得模型学习到未响应部分的有效信息。
上述过程只考虑了未得到响应的部分,没有考虑出现多余响应的情况。由于DBD任务的互补性,在DBDNetF(·)模型中需要响应的区域不应出现在DBDNetD(·)的预测结果中,对于DBDNetD(·)模型同理。因此,当预测结果中出现了多余的响应时,为了使得LD,3更小,DBDNetD(·)就会驱动OF′根据图像a对OD、OD′中多余响应位置做出响应,即DBDNetF(·)模型在训练过程中能根据DBDNetD(·)模型的错误经验优化自身的预测结果。对于DBDNetD(·)同理。
此外,互补网络的结构仅在训练阶段负责监督其对应的互补模型,从而更好地学习到结果预测能力。推理测试过程仅使用清晰区域预测网络DBDNetF(·)进行计算,故互补网络结构不会给模型的实际使用带来额外的时间、空间开销。
2.3 全局通道注意力模块
本文选择在ImageNet[31]上预训练的VGG16[32]作为基础模型,它是一个拥有大量先验知识的通用特征提取模型,对应图2中的Layer01-Layer05。为了使模型关注预测结果中的有效特征信息,忽视不重要甚至不利于预测的特征信息,本文在每一层的特征输出前设计了GCAM。与常用的通道注意力使用卷积聚合特征图的特征不同的是,本文的全局通道注意力模型使用双层感知机来根据聚合后的最大池化和平均池化向量得出通道注意力权重。这是因为卷积是一种局部连接,缺少对模糊区域的大小和散焦强度特征的全局抽象能力。

(4)
(4)式中:w,h表示特征图上的横坐标和纵坐标;n表示特征图的编号;N表示特征图的总数。在通道方向上将两组特征描述符堆叠在一起,然后输入双层感知机进行预测,得到通道权重w为
(5)
(5)式中:σ表示全连接层,σ1的输入大小为2×N,σ2的输入大小为N;ReLU(·)表示非线性整流激活函数;Cat[·]表示沿通道方向拼接特征。最终,将权重进行映射后得到的加权通道特征图可以写为
F*=F*Sigmoid(w)
(6)
2.4 多尺度语义融合模块
得到输入图像的多尺度特征图后,利用多尺度特征融合重建模块RPMSF/RP预测对应尺度的结果图。RPMSF/RP的整体结构如图3所示。

图3 RPMSF/RP的结构Fig.3 Structure of RPMSF/RP

(7)
具体而言,MSF的计算过程如算法1所示。
算法1MSF的计算过程
输入:
di←当前RPMSF模块第一部分计算得到的原始语义特征
{dL,dL-1,…,di+1}←前序所有RPMSF/RP模块计算的原始语义特征
输出:
1. 初始化输入特征D1=di
2. fort= 2;t≤L-i+1 do
3.Dt=CBP(Dt-1),尺度由大到小计算调整中的特征图
4. end for
5. 初始化微调细化特征u1=DBP(Cat[DL-i+1,dL-i+1,DL-i+1-dL-i+1])+D4
6. foru= 2;u≤L-ido
7. 尺度由小到大计算细化调整后uu=DBP(Cat[uu-1,dL-u+1,uu-1-dL-u+1])+DL-u得到的特征图
8. end for

算法1中,L表示RPMSF/RP模块的总个数,在本文中L=5;CBP(·)由步长为2、核大小3×3的二维卷积,批归一化,ReLU函数3部分组成;DBP(·)由步长为2、核大小3×3的二维反卷积,批归一化,ReLU函数组成。在MSF中,利用一系列的卷积和反卷积,先将当前尺度结果图对应的语义特征的尺寸逐步卷积缩小,进而得到变换后的语义特征D1、D2、…、Dt,其中Dt的大小和最小尺度的语义特征图d5相匹配,然后将Dt和d5、Dt-d5拼接在一起,进行反卷积放大尺度,将得到的结果和d4、d4的差拼接后再进行反卷积,重复上述过程直到语义信息重新回到原始大小,完成对原始语义特征的微调细化。
3 实验与分析
3.1 数据集
本文使用DUT、CUHK、CTCUG等3个数据集完成实验。①DUT数据集[9]。该数据集总共包含1 100对场景图像-标注图像,其中600对用于训练网络模型,其余500对用于评价模型性能。②CUHK数据集[20]。该数据集由704对散焦图像-标注图像组成,其中604对用于训练,100对用于测试。具体的分类列表可以在文献[9]中找到。③CTCUG数据集[10]。该数据集仅包含150对用于测试的图像。与前两个数据集不同,该数据集着重于背景聚焦而前景散焦的情况,进一步增加了散焦模糊检测的难度。
3.2 训练设定
本文利用DUT数据集中的600对训练图像和CUHK数据集中的604对训练图像,共1204对图像联合训练模型。全清晰图像和全模糊图像数据来自文献[33]。模型使用PyTorch 1.6实现,在NVIDIA RTX TITAN 24 GB图形处理器上基于CUDA10.2运行。如前所述,本文利用VGG16[32]的前5组卷积层作为模型的特征提取骨干,第1-5层权重使用ImageNet上预先训练的参数进行初始化[31],其余层权重执行随机初始化操作。在训练过程中,所有图像尺寸统一缩放为256×256,以RGB格式读取后将像素值标准化到[-1,1]。模型训练时的批次大小设定为4,学习速率为1×10-4,使用Adam优化方法[34]更新网络模型参数。为了提升模型的训练速度,本文将优化方法中的初始梯度衰减速率β1∈[0,1]和β2∈[0,1]分别设定为0.9和0.999,该两项参数越大模型初期收敛越迅速。模型总共训练了230个周期。训练过程中模型的损失变化如图4所示。从图4可以看出,在训练过程的前100个epoch,模型的损失值快速降低到2以下,之后模型损失继续缓慢下降并趋于稳定,模型成功收敛。

图4 训练过程总损失变化图Fig.4 Change in total loss during training
3.3 实验结果
本文方法和基于手工特征及基于学习特征的方法进行对比如下。所有方法在DUT、CUHK和CTCUG数据集上使用S-Measure[35]、F-Measure[36]、mean absolute error (MAE)[37]、准确率、召回率、AUC值和PR曲线对模型的结果进行客观评价。所有指标的参数设定和结果计算均使用文献[38]提供的源程序完成。
定量比较的结果如表1所示。从表1可以看出,本文模型在这3个数据集上的性能始终优于对比方法。对比SG[33]和EFENet,本文方法在F-Measure上分别提升了0.259、0.168、0.435和0.082、0.051、0.264,在MAE指标上分别降低了0.111、0.076、0.144和0.032、0.018、0.144,这验证了本文所提出方法的优越性。图5展示了不同方法在所有数据集上的准确率、召回率和AUC值。从图5可以看出,本文提出的方法同样优于对比方法。
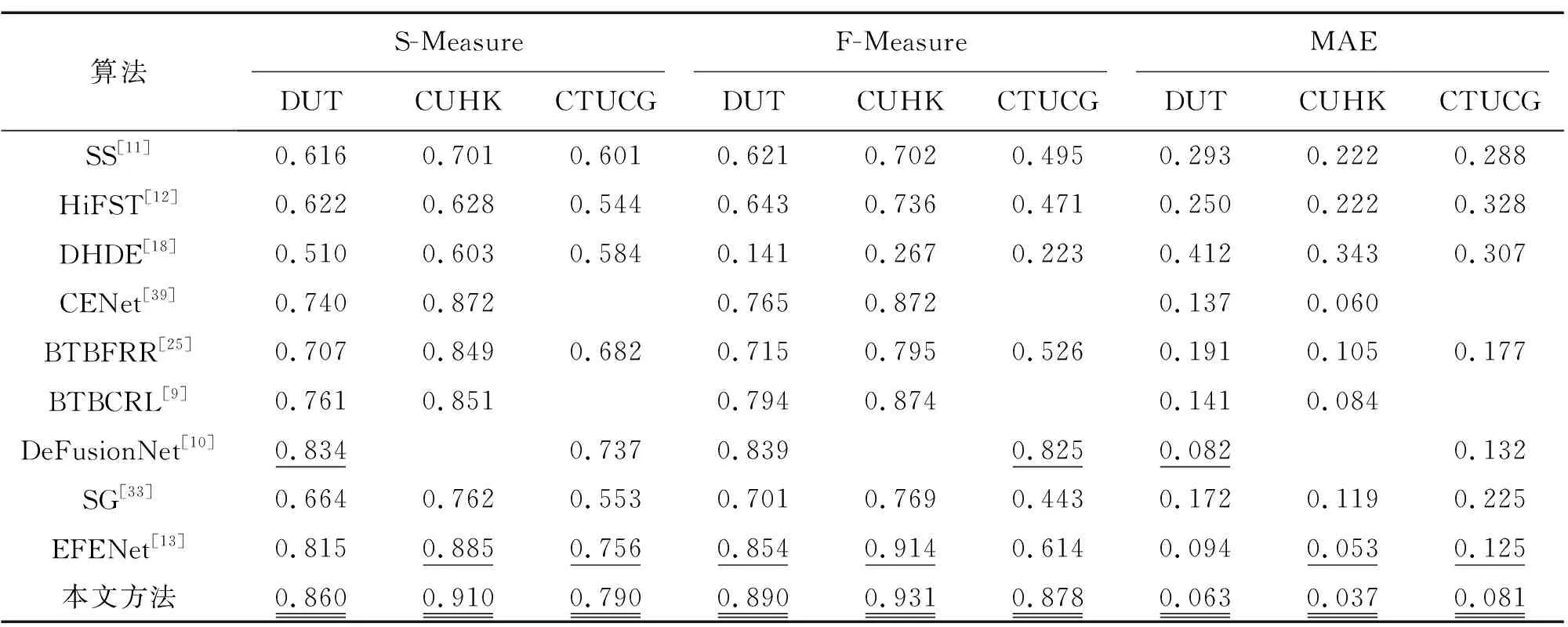
表1 客观评价指标对比表

图5 准确率、召回率和AUC值对比图Fig.5 Comparison chart of precision, recall and AUC values
图6展示了DUT数据集上的视觉结果。从图6可以看出,当输入图像存在聚焦范围内平滑区域时,本文方法能够正确地预测出区域的属性,并在过渡区域产生最清晰的边界,如第一行和第二行所示;SG和EFENet的预测结果虽然符合真实结果的大致形状,但是对于细节区域的判断比较粗糙,出现了较多的误判,如第三行所示。

图6 DUT数据集上的实验结果Fig.6 Results on DUT dataset
图7显示了在CUHK数据集上的视觉结果。从图7可以看出,虽然所有方法都能正确判别大概的区域,但本文方法的预测结果更加准确,对于焦点区域的误判更少,散焦/聚焦区域的边缘分割更加清晰,如第二行和第三行所示;在GT图像中标注错误的区域本文方法也成功地将其预测了出来,如第一行所示。

图7 CUHK数据集上的实验结果Fig.7 Results on CUHK dataset
相较于DUT和CUHK数据集,CTCUG数据集更多是前景模糊背景清晰的场景,因此更具挑战性,如图8所示。从图8可以看出,本文模型在该数据集上同样表现优秀。相较于SG和EFENet,本文方法能够更加准确地区分出模糊的前景和清晰的背景,而前者在这种场景下在背景区域出现了大量的误判。

图8 CTCUG数据集上的实验结果Fig.8 Results on CTCUG dataset
3.4 消融实验

表2 主要模块的消融结果

图9 主要模块消融实验的一些视觉图像Fig.9 Some visual images of the main module ablation study
从表2和图9可以看出,每个模块在网络性能中都起着重要作用。AS3模型中,GCAM在特征提取网络根据特征的重要性自动赋予特征不同的权重,帮助后续模块关注关键的特征图,提升了模型的预测效果。通过引入MSF,AS4预测结果时可以参考前序结果的原始语义特征,帮助模型适应不同尺度的预测区域,使得预测效果进一步提升。DBD结果中客观存在互补特征,为了利用其提升训练时对模型进行的监督来提升预测效果,在AS2中用再感知双模型联合训练方法对baseline的网络模型进行训练。由于互补信息和未响应区域被充分利用,因而本文所提出的损失函数配合双模型训练方法可以显著改善模型的训练效果。所有模块的联合最终使本文的模型达到了优秀的散焦模糊图像检测效果。
为了更进一步验证本文损失函数在训练过程中的有效性,本文还进行了3个额外的实验。将损失函数中的Loss2去除得到模型AS6;将损失函数中的Loss3去除得到模型AS7;去除Loss3中的+Ox′得到模型AS8,如表3所示。从表3可以看到,其他模型在3个数据集的所有定量指标中都出现了性能下降,表明每一个损失项都有其重要性。图10进一步显示了本文模型的结果和消融模型结果之间的一些示例比较。只靠互补信息进行学习的AS6模型缺少对响应失败区域的约束,会在某些前景模糊背景清晰的情况下漏检区域。AS7模型缺少了互补信息的监督,面对图像中某些复杂区域会出现未响应的情况。AS8模型因OF′和OD′为互补关系而缺少了互补结果的参照,导致AS8模型的检测效果还有待改善。相比之下,本文提出的训练方法可以达到良好的视觉效果。
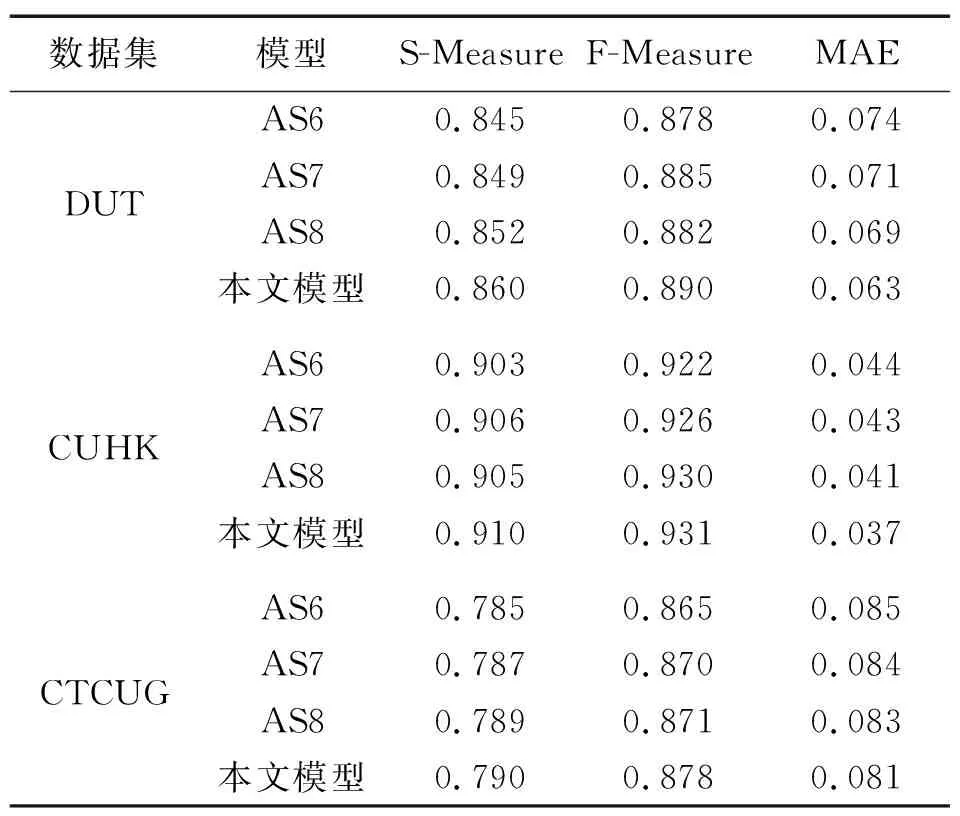
表3 损失函数的消融实验
4 结束语
本文提出了再感知双模型联合训练方法和基于注意力机制的多尺度语义融合散焦模糊检测网络,将未正确响应的预测区域映射到全新的合成图像中,实现对输入图像的再感知,使得预测模型可以学习错误位置的图像特征;将网络中多余响应的区域反馈到另一个互补模型上,随后互补模型根据该经验进行微调校正,提升训练模型质量。考虑到散焦模糊程度对不同尺度的图像特征敏感,预测模型在计算过程中通过MSF逐渐整合学习尺度从小到大的特征。此外,为了增加网络在不同输入场景下的灵活性,本文在特征提取时设计了GCAM。对比实验表明,本文方法在性能方面显著优于对比方法。
