基于改进PatchSVDD 的田间异常区域检测方法
2024-02-22陈祖强庞立欣郭娜炜蔡金金
陈祖强,庞立欣,郭娜炜,蔡金金,么 炜,刘 博
(1.河北农业大学 信息科学与技术学院,河北 保定 071001;2.河北省农业大数据重点实验室,河北保定 071001;3.河北农业大学 科学技术研究院,河北 保定 071001;4.河北农业大学 机电工程学院,河北 保定 071001)
农业在国家经济发展中占据着重要地位,2020年全国农业及相关产业增加值占国民生产总值(GDP)的16.47%[1]。随着精准农业建设的稳步推进,农用遥感无人机被广泛应用农田勘测任务中[2,3],如地块划分[4],出苗检测[5]、路径规划[6]等。然而,田间状况多变,如杂草、积水、病害、建筑等异常区域具有形状不规则、大小不确定、边界不清晰等特点[7],特别是相对大量的正常样本,异常样本具有收集困难,标注不完备等问题,使得田间异常检测成为1 项富有挑战性的工作。
目前,针对遥感图像的田间异常检测的研究主要分为两类。一类是传统方法,一类是基于深度学习的方法。其中传统的异常检测主要是通过手动提取特征,采用阈值分割、回归和分类等模型实现对异常的检测。例如刘晓霞等[8]通过分离无人机影像的各通道,使用最大类间方差法实现异常区域的检测。孙瑞琳等[9]通过无人机获取小麦冠层多光谱图像,通过植被系数与病情指数(DI)的相关性进行建模,对小麦叶片叶锈病进行异常监测。赵静等[10]则混合植被指数、主成分波段特征和纹理特征,通过支持向量机、随机森林等监督模型对玉米田中杂草区域进行定位。Fang H 等[11]采用遥感技术获取的农田RGB 图像,通过模板匹配法对农田中的障碍物进行检测。
另一方面,随着深度学习的发展,大量基于卷积神经网络的模型用于田间异常检测任务。如薛金利等[12]采用YOLO(You Only Look Once)目标检测方法,对棉花田中的杂草异常进行检测。杨蜀秦等[13]采用DeepLabv3+(Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation)语义分割算法,对麦田中的倒伏异常区域进行分割。Hong S 等[14]采 用SSD(Single Shot Multi Box Detector)、FasterR-CNN(Faster Region-based Convolutional Neural Network)与YOLO 算法,对田间等场景下的野生鸟类进行检测,并比较不同算法的优劣。这些工作都采用了较为成熟的目标检测或语义分割框架,相比传统方法,异常定位的准确性有了显著提升。然而,这些方法具有两个方面的不足,其一,其工作在完全监督的情况下,即需要预先对大量的正常和异常数据进行标注,但很多异常区域难以收集足量数据进行模型搭建和训练;其二,已有方法只能对于预定义的异常类别进行识别,无法检测未知的异常[15]。
针对这些问题,本文提出了1 种基于改进PatchSVDD (Patch-level Support Vector Data Description)[16]的农田异常区域检测方法,其在不依赖异常样本的基础上只针对正常样本进行建模,通过构建鲁棒的正常区域特征表示比对筛选异常区域。首先,田间的异常区域及种类具有小样本特性,其在整个农田区域中占比过小,正常与异常样本严重不平衡,因此难以收集足量的异常数据,故本文方法仅对正常区域进行鲁棒性学习,通过把测试样本仅与正常样本进行比对从而给出异常评分;此外,田间异常具有开放性、无法预先观测等特性,本文仅对正常样本建模的方式也对该类异常的识别提供了解决思路;最后,本文可以作为数据预处理方法,通过对田间异常区域进行定位,并在此基础上对相应异常区域进行人工确认,从而减轻人工搜寻异常区域的负担,也为后续的相关工作提供高质量的异常样本支撑。综上所述,本研究采用无人机遥感数据,针对农田中的异常区域进行检测并定位,符合现代精细农业的发展趋势,对于农田信息监测、作物的估产、营养预警等方面具有重要意义。
1 数据采集
1.1 数据获取
为了验证所提模型的有效性,本文使用无人机在河北省张家口市张北县的马铃薯种植基地进行周期性的遥感图像采集。该基地覆盖区域约13.33 hm2,地 理 坐 标 为(114°56′01′′ E, 41°25′37′′ N)。无 人 机为多旋翼型,轴距492 mm,频段5.725 ~5.850 GHZ。由于农田内出现的异常区域具有随机性,常常与天气、种植环境和人类活动相关。因此,为了保证图像采集的真实性,本研究根据马铃薯生长周期,在2020—2021 连续2 年内的7—8 月进行了数据采集,同一年份采集时间间隔为7 d。
为了保证所拼接的农田全景图像的质量,本文选择天气晴朗、无风的时间进行拍摄。无人机路径规划采用等高垂直的方式,按划分区域自动航行拍摄。最终得到TIF 格式的农田无人机全景图像12幅。拍摄的农田内异常包括杂草簇、苗圃缺失、障碍物等异常类型。为了丰富数据集,本文补充了Agriculture-Vision[17]大型农业异常航空农田语义分割数据集的原始TIF 图像4 幅,其中含有2 幅积水异常,2 幅含有双倍种植异常。部分全景图像如图1所示。

图1 全景遥感图像实例Fig.1 Examples of panoramic remote sensing images
1.2 数据集构建
由于所获得的TIF 图像分辨率过高,为了便于深度模型处理,本文在保留RGB 通道的基础上,将每幅无人机图像切分为256×256 大小的图像。此外,该数据集中共包含杂草簇、种植缺失、障碍物、双倍种植、农田积水等5 类异常,部分异常样例如图2 所示。

图2 农田异常样例Fig.2 Examples of anomaly regions in farmland
为了更加符合农田异常检测的真实场景,本文建立的训练集中只包含正常图像,而测试集则包含正常及异常图像用以指标比对。5 个类的样本量如表1 所示,训练集与测试集之间的图像不重叠,测试集中正常与异常图像样本的比例为1∶1。由于模型训练过程中并不需要标注异常信息,因此仅标注测试集中的异常区域以计算相关评价指标。
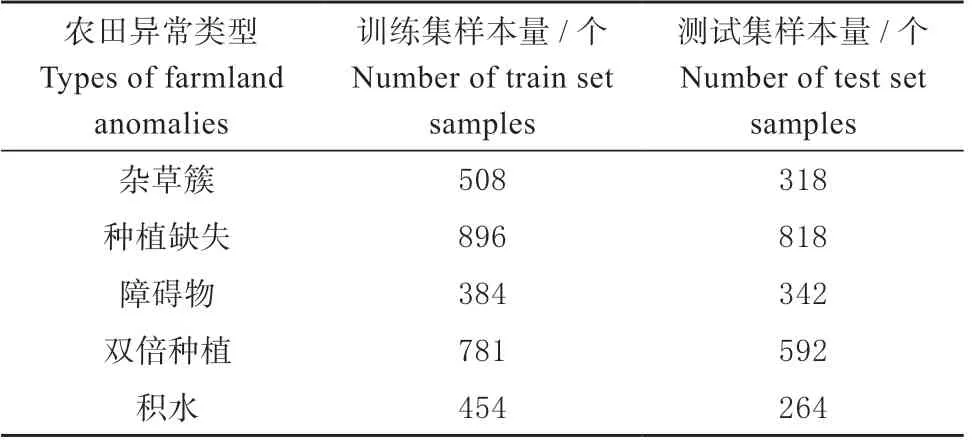
表1 数据集样本量Table 1 Number of datasets samples
2 改进的PatchSVDD 方法
2.1 农田异常检测问题描述
本文模型在训练阶段仅依赖无人机航拍的正常农田图像,并在推理阶段对农田中的异常区域进行识别和定位。对异常检测的分类问题定义如下,使用Xtrain用表示正常图像数据,使用Xtest用来表示测试集所有数据。由于训练集中只包含正常数据,而测试集中既有正常数据又有异常数据,可得xi∈Xtrain∶yi=0,xi∈Xtest∶yi∈{0,1},其中xi代表对应数据集的第i张图像,yi代表该图像对应的分类,0 代表正常,1 代表异常。对于异常检测的定位问题定义如下,对每个测试图像xi,图像中每个像素pj,满足pj∈xi∶yj'∈{0,1},其中yj'代表像素的分类,0 代表正常,1 代表异常。
2.2 PatchSVDD 模型
PatchSVDD[16]源于DeepSVDD[18](Deep Support Vector Data Description),其通过学习1 个最小半径,从而将训练集中所有正常图像映射在1 个超球面上,具体如图3(a)所示。给定个超球体中心为c,模型的损失函数为映射后的图像特征与c的欧式距离,具体如公式 (1) 所示。在测试阶段,测试样本产生的特征与超球面中心的距离作为该样本的异常评分,根据给定的阈值即可划分出正常和异常图像。
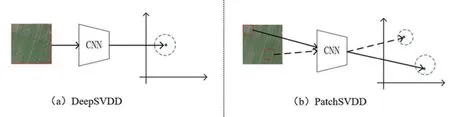
图3 DeepSVDD 与PatchSVDD 的比较Fig.3 Comparison of DeepSVDD and PatchSVDD
为了实现图像中的异常定位,PatchSVDD 模型将DeepSVDD 模型进行改进,通过重叠的滑窗,将每张图像分割为多个图像块,并在图像块的尺度上进行异常检测,具体如图3(b)所示。此外,当模型输入由图像转化为图像块后,数据差异性增大,因此采用单个超球面并不合适。因此PatchSVDD 不再显式地定义超球体中心的个数,而是采用相邻的图像块特征之间的欧式距离作为损失函数,如公式 (2)所示。其中bi是输入的图像块,bij是与其相邻的图像块。在测试阶段,将所有正常样本进行存储,测试样本产生的特征与正常样本的最近邻距离作为该样本的异常评分。
2.3 改进的PatchSVDD 模型
PatchSVDD 模型存在2 个问题,首先对于纹理类图像进行异常检测时,由于纹理间的相似性,模型学习到的正常特征缺乏判别性;其次模型存储所有正常特征并求最近邻距离作为异常评分,虽然此种做法提升了算法的检测及定位精度,但大大增加了算法在实际使用时的推理时间。针对以上问题,本文从异常检测损失函数与有外部记忆模块构建两方面进行改进,整个流程如图4 所示。
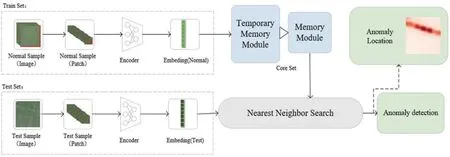
图4 改进的PatchSVDD 方法的框架Fig.4 The framework of improved PatchSVDD
2.3.1 损失函数改进 农田遥感图像多数属于纹理图像,农田内的作物普遍使用农用机械种植,并由于自然生长的原因,其分布具有一定的规律性和差异性。原模型在训练过程中,损失函数的设计是为了利用图像块间的相似性学习正常类别边界,但没有充分考虑图像块间差异性,导致对异常识别下降。针对上述问题,本文在建模相邻块的相似性的基础上,引入不相邻块之间的差异性,并通过引入三元损失函数[19]来同时学习相邻图像块的相似性,以及不相邻图像块间的差异性,具体如公式 (3) 所示。其中bij为bi的第j个相邻图像块,b'ij为bi的与第j个不相邻图像块,α为边界参数。通过新增的边界损失,使模型能够识别不相邻图像块之间的差异性。总的损失函数如公式 (4) 所示。
2.3.2 特征存储改进 在模型训练完成后,PatchSVDD 将全部正常图像块特征存入内存中,用以进行异常查询与匹配。但数据的冗余性会造成空间和时间上的浪费。为了解决这一问题,提升异常匹配效率。本文采用核心集选取策略用以压缩正常特征集的容量。即对于所有的正常特征库Mall,学习得到1 个子集特征库Msub,其Mall中的特征ei距离Msub的最近邻距离中的最大距离取得最小。其表达公式如下所示,Δ 表示特征之间的距离。
对于核心集的选取算法,文献[20-21]提供1种具有最大代表性的方法CORE-SET,该方法能够保留特征中那些具有代表性的特征。本文通过设置1 个超参数β∈[0,1],表示Msub在Mall的采样比例以控制核心集的容量。
2.4 图像级别与像素级别异常评分
在测试阶段,测试图像块在特征库Msub中的最近邻距离作为其异常评分。评分函数如公式(6)所示。其中bi代表测试图像块,bnormal代表Msub中的正常图像块,Spatch代表每个图像块的异常评分,采用的距离为欧式距离。
由于采用有重叠的滑窗,每张图像xi可以产生多个图像块,从而构成图像块集合Bi,模型选取所有图像块异常评分中的最大值作为图像xi的异常评分,记做Simage,计算方式如公式(7) 所示。
此外,每个像素pi可能存在于多个图像块中,该图像块集合记为Ci。将包含像素pj在内所有图像块的异常评分均值作为像素pj的异常评分,记做Spixel,计算方式如公式 (8)所示。
根据图像和像素的异常评分,不仅可以对异常图像进行识别,还可以对图像的异常区域进行定位。
3 实验效果及结果分析
3.1 实验环境与主要参数设定
本文所使用实验平台的硬件环境为Intel(R)Core(TM) i9-9900X CPU,NVIDIA GeForce RTX 2080Ti GPU;软件环境为 64 位 Ubuntu 20 系统,PyTorch 深度学习框架。实验部分所有算法在训练阶段均使用初始学习率为0.000 01 的Adam 优化器,批处理大小为64。在模型参数设置方面,代表性子集的采样率为0.2,三元组损失函数的边界参数α设置为10-5,图像块的尺寸K=32。
3.2 评价指标及方法
本文实验中采用的评价指标是AUC(Area Under Curve),即ROC曲线下的面积(Receiver Operating Characteristic Curve),该曲线的横坐标是假阳率FPRate(False Positive Rate),纵坐标是真阳率TPRate(True Positive Rate),是分类任务中常用的综合指标,如公式(9)与公式(10)所示。
其中TP表示预测结果与真实结果均为正常数据的数量;FP表示预测结果为正常数据,但真实结果为异常数据的数量;TN表示预测结果与真实结果均为异常数据的数量;FN表示预测结果为异常数据,真实结果为正常图像数据的数量。为获得AUC值,首先需要计算ROC曲线。本文通过分别计算不同阈值下的FPR和TPR,将FPR作为横轴,TPR作为纵轴,连接对应点以构建ROC曲线。通过计算ROC曲线下方与坐标轴围成的面积可得到AUC值。本文根据图像的分类和像素分类结果,可以构造2 条ROC曲线,分别对应检测AUC值和定位AUC值。
3.3 模型效果验证与分析
为验证模型的有效性,本文在含有5 种异常类型的自建数据集上,对比了AE[22-23](Auto Encoder)、CutPaste[24](CutPaste: Self-Supervised Learning for Anomaly Detection and Localization)、DeepSVDD[18]和PatchSVDD[16]等4 种异常检测算法。AE 模型是基于图像重构的方式进行异常检测,模型由正常样本训练,其假设异常样本的重构误差比正常样本更大。CutPaste 模型是基于分类的方式来进行异常检测。各个算法的结果如表2 和表3 所示。其中表2 展示了不同方法针对农田异常图像的检测AUC值,结果说明5 种方法对农田图像异常区域的检测均有较好的表现,平均AUC值可保持在91 % 以上,其中本文提出的改进PatchSVDD方法取得了最好的结果。表3 则展示了不同方法的异常定位效果,结果说明5 种异常检测方法对于异常区域的定位效果差异较大,表现最好的改进PatchSVDD 算法与较差的DeepSVDD 算法差距达到约10%。通过综合比较检测和定位的实验结果,改进后的PatchSVDD 模型在平均检测AUC值和平均定位AUC值上分别达到了96.9 %和94.6 %,相比于原始PatchSVDD 模型分别提升1.2 %和1.6 %。
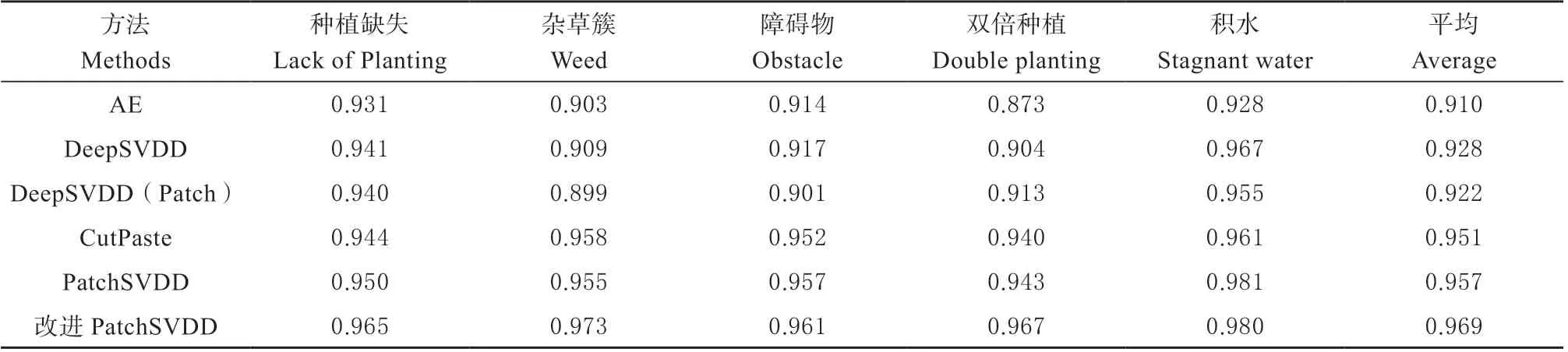
表2 不同异常检测方法的检测AUC 对比Table 2 Comparison of detection AUC values of different anomaly detection methods

表3 不同异常检测方法的定位AUC 值对比Table 3 Comparison of localization AUC of different anomaly detection methods
3.4 消融实验
由于本文提出了组合损失函数和核心集压缩策略,为了验证相关改进的效果从而进行了消融实验,异常检测的实验结果如表4 所示,异常定位的实验结果如表5 所示。其中衡量算法的效果采用AUC值,衡量算法的效率采用单张图像的平均推理时间,推理时间主要由图像预处理(生成图像块)、图像块编码以及异常匹配三部分的耗时组成。

表4 异常检测消融实验Table 4 Ablation experiment of anomaly detection

表5 异常定位消融实验Table 5 Ablation experiment of the anomaly location
由表4 ~5 可以看出:(1) 在未采用核心集压缩策略的前提下,模型的改进损失较原损失在平均异常检测AUC值和平均异常定位AUC值分别提升1.3 %和1.6 %。原因在原损失函数上添加了边界损失函数LSEP,其能够同时学习图像块之间的相似性以及不相邻图像块之间的差异性,增加了模型的判别能力。(2)采用核心集压缩策略后,模型的检测和定位效果没有明显变化,这符合实验预期。主要原因在于,核心集压缩策略是为了在保证算法的效果下,减少内存中的特征冗余,进而减少异常匹配过程中的时间消耗。引入核心集策略后(采样率取0.2),单张图像异常检测平均推理时间从29.65 ms 减少到19.98 ms,节省了32.6 %的推理时间;单张图像异常定位平均推理时间从31.43 ms 减少到21.78 ms,节省了30.7 %的推理时间,从而验证了核心集有效性。
3.5 特征可视化实验
为了进一步探究改进算法的有效性,本文将1张异常图像通过间隔为1 像素的滑窗生成多个图像块,并将每个图像块特征通过t-SNE[25]进行降维可视化,结果如图5 所示。

图5 t-SNE 特征可视化Fig.5 Feature Visualization of T-SNE
图中分对原始输入特征、PatchSVDD 获得的特征和改进后的PatchSVDD 获得的特征进行可视化对比,其中包含异常区域的图像块标记为蓝色,不含异常区域的图像块标记为红色。相比于原始输入特征,经过学习后的特征可分性更强。特别是本文提出的改进后的PatchSVDD 算法,相比于原始PatchSVDD 算法进一步增加了类间的间隔与类内的紧凑性,从而提升算法的检测和定位效果。
3.6 主要参数分析
本文的模型中存在采样率、边界损失的边界值α、图像块的尺寸K等超参数,本节将通过实验分析不同超参设置对模型的影响。
3.6.1 特征库采样分析 本文通过采样的方式以构建具有代表性的样本特征子集以解决PatchSVDD算法在计算异常分数时存储空间大,近邻搜索时间长的问题。下面将对采样率的设置进行分析。图6与图7 分别展示不同采样率下的异常检测与定位的AUC值。
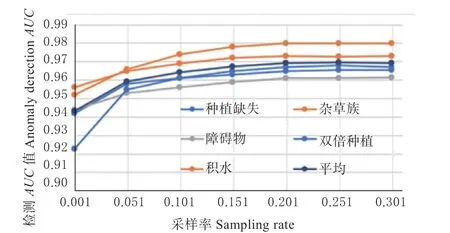
图6 不同采样率的异常检测AUC 值比较Fig.6 Comparison of anomaly detection AUC with different sampling rates
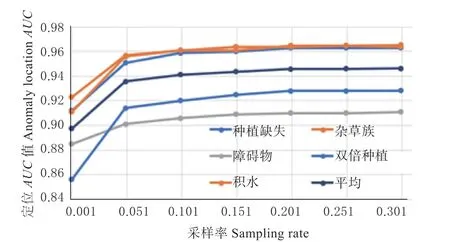
图7 不同采样率的异常定位AUC 值比较Fig.7 Comparison of anomaly location AUC with different sampling rates
其中采样率分别设置为0.001、0.05、0.10、0.15、0.20、0.25 和0.30。从图中可以看到,随着采样率的增加,出现异定的数值。原因在于过小的采样率无法保证样本子集足够的代表性,而过大的采样率则会引入冗余信息。
3.6.2 三元组损失的边界值的影响 根据本文第3.5节描述,本文使用三元损失函数以增加类别判别性。为了衡量该边界值α对结果的影响,本节对不同α取值下的检测和定位的AUC值进行比较,结果如图8 与图9 所示。
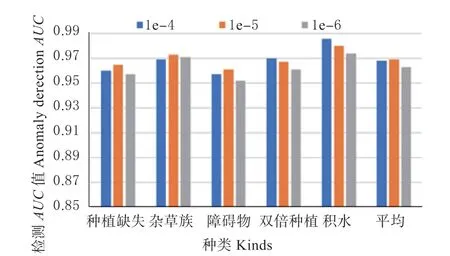
图8 不同边界值的异常检测AUC 值比较Fig.8 Comparison of anomaly detection AUC for different margins
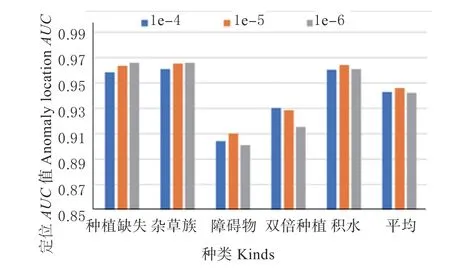
图9 不同边界值的异常定位AUC 值比较Fig.9 Comparison of anomaly location AUC for different margins
从图中可以看到,当α 取值10-5时,平均检测和定位的AUC值均达到较好结果,主要原因较大边界值将导致模型难以收敛;而较小边界值将使模型易于收敛,但也减少了类间距离导致分类难度增加。3.6.3 图像切块大小的影响 为了验证不同图像块大小K对模型的影响,本文分别使用K=64、K=32和K=16 不同图像切块尺寸进行实验,结果如图10与图11 所示。
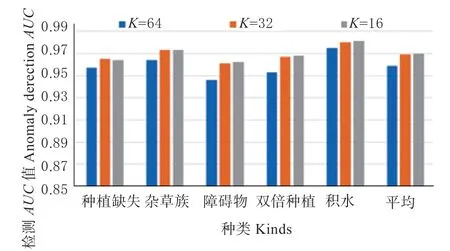
图10 不同切块大小的异常检测AUC 比较Fig.10 Comparison of anomaly detection AUC with different patch sizes
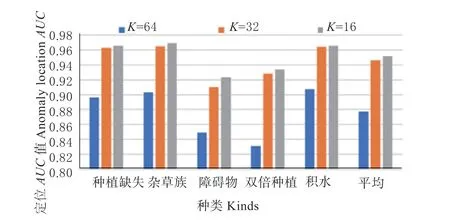
图11 不同切块大小的异常定位AUC 值Fig.11 Comparison of anomaly location AUC with different patch sizes
从图中可知:(1)随着图像块尺寸的减小,算法AUC值不断提升。(2)随着图像块尺寸的减小,检测和定位AUC值提升速率逐渐变慢。产生上述现象的原因在于尺寸越小,异常图像块更容易与正常图像块进行区分。然而,随着图像块尺寸的减少,图像块的总数量也会增加,导致模型效率降低。当K=32 时达到了性能与效率的平衡。
3.7 异常定位可视化
为了进一步验证算法的定位效果,本文对部分异常图像的定位结果通过热力图进行可视化,效果如图12 所示。

图12 异常区域的热力图样例Fig.12 Example of heat maps of anomaly regions
热力图由像素的异常评分值构造,图像中颜色越深,代表该区域异常程度越高。从图中可以发现,改进后的PatchSVDD 算法相对于原算法,图像中噪点更少,边界更加清晰,证明改进后的算法异常定位的效果更精确。
4 结论
本文的主要贡献如下所示:(1) 提出1 种改进PatchSVDD 的农田异常检测方法。改进主要包括如下两个方面。一是在特征提取引入不相邻图像块之间的边界损失函数,从而提升了算法的检测和定位效果;二是引入外部记忆组件,通过压缩存储正常区域特征,从而在保证检测精度的基础上有效减少了检测匹配阶段的时间和空间消耗。(2) 通过结合自建数据集与公开数据集,构建了含有杂草簇、种植缺失、障碍物、双倍种植和积水共5 类异常的农田异常数据集,从而验证了本文方法的有效性。同时也为相关后续研究提供了数据支撑。实验结果表明,改进后的模型平均分类AUC值达到96.9 %,定位AUC值达到94.6 %,从而验证了算法的有效性。后续工作将从定位精度、检测效率等方面进行进一步的改进,从而为高效的农田异常检测提供必要的决策支持。
