基于自校准机制的时空采样图卷积行为识别模型
2024-02-22吴伟官张小勇高清源
曹 毅,吴伟官✉,张小勇,夏 宇,高清源
1) 江南大学机械工程学院,无锡 214122
2) 江南大学江苏省食品制造装备重点实验室,无锡 214122
骨架行为识别是通过提取骨架序列中的动作特征,进而实现对人体行为的理解与描述的方法,是计算机视觉领域的热点研究方向之一,近年来由于行为识别在视频理解[1]、康复训练[2]的重要作用而被广泛研究.基于图像的方法一般使用RGB数据作为输入,通过提取图像特征进行动作识别.基于骨架的方法使用人体骨架数据作为输入,通过特征提取对动作进行分类.由于骨架数据具有鲁棒性和对光照条件变化不敏感等特点,在给定精确的关节点坐标的情况下,基于骨架数据的动作识别方法的表现会更加出色和优异,本文主要研究的是基于三维人体骨架的动作识别技术.
针对骨架行为识别,国内外学者分别基于卷积神经网络和Transformer 网络开展了大量的理论与实验研究.基于卷积神经网络,Xia 等[3]提出了一种基于全局和局部注意力的卷积神经网络,从骨架数据中提取具有鉴别力和鲁棒性的时空特征来识别动作.Zhu[4]提出了一种新颖的立方体排列策略来描述骨架序列,并结合注意力机制和卷积神经网络来提高动作识别的准确率.基于循环神经网络,Jiang 等[5]在时空域上使用去噪约束和稀疏性约束,提出了一种基于去躁和稀疏的长短时记忆网络,用于捕获骨架序列中帧与帧之间的相关性.Zhang 等[6]设计了一种基于长短时记忆(Long short-term memory,LSTM)结构的自适应递归神经网络来自动调节行为发生时的观察视点.基于Transformer 网络,Plizzari 等[7]通过构建空域自注意力模块来建立不同关节之间的连接关系,以及时域自注意力模块来捕获同一关节在不同帧之间的相关性.Zhang 等[8]提出一种图像感知变换器网络,通过充分利用速度信息并以驱动的方式从骨架序列图中获取关键行为动作的时空特征.
图卷积网络的发展使得直接在非欧几里德结构的骨架图上进行建模,更有效地表示关节之间的依赖关系,从而被广泛应用于骨架行为识别中并取得了优异的成绩.Yan 等[9]提出了一种时空图卷积网络,将骨架序列构建为堆叠的无向图,采用空域图卷积和时域卷积分别用于提取骨架序列的空域和时域特征.Shi 等[10]提出一种双流自适应图卷积网络,将人体的关节点信息作为第一阶信息,骨骼信息作为第二阶信息,同在这两种信息上进行建模来实现不同模态数据的信息互补.Cao 等[11]将二维图卷积核改进为三维图卷积核,提出一种三维图卷积方法,通过聚合空间与时间维度上的邻居节点信息,实现了骨架序列中时空信息的有效提取.Bai 等[12]设计了一种基于关节全连接的双流图卷积网络模型,以端到端的训练方式获取所有关节的潜在依赖关系,以更好地适应动作识别.Fan 等[13]提出了一种多尺度时空图卷积网络来提取不同尺寸的时空特征,同时采用注意力机制选择性地融合不同尺寸的特征.
尽管上述图卷积神经网络相较于其他深度学习网络有了较大的改善,但其仍存在以下不足:(1)这些图卷积网络在时空特征提取过程中不能有效建立局部和全局时空上下文依赖关系;(2)时域卷积层仅采用固定的卷积核提取时域特征,缺少多层次的感受野来捕获更具判别力的时域特征;(3)在图卷积过程中每个时空位置缺乏远程时空与通道的相互依赖关系.
针对上述问题,本文提出一种基于自校准机制的时空采样图卷积网络行为识别模型.首先,介绍ST-GCN 和3D-GCN、Transformer 和自注意力机制的工作原理,其次,提出一种时空采样图卷积网络以时序连续多帧作为时空采样,通过构建时空邻接矩阵参与图卷积来建立局部和全局时空上下文依赖关系.然后,为了有效地建立时空与通道之间的依赖关系并增强多层次的感受野来捕获更具判别力的时域特征,提出了一种时域自校准卷积网络在两个不同的尺度空间中进行卷积并特征融合:一种是原始比例尺度的时空,另一种是使用下采样具有较小比例尺度的潜在时空.再者,结合时空采样图卷积网络和时域自校准网络构建基于自校准机制的时空采样图卷积网络行为识别模型,在双流网络下进行端到端的训练,在骨架数据集上进行大量的实验,验证了该模型的有效性和优越性能.
本文的研究贡献为:(1)提出一种时空采样图卷积网络以时序连续多帧作为时空采样,通过构建时空邻接矩阵参与图卷积来建立局部和全局时空上下文依赖关系;(2)提出一种时域自校准卷积网络在原始比例尺度的时空和使用下采样具有较小比例尺度的潜在时空中分别进行卷积并特征融合,以有效建立时空与通道之间的依赖关系并增强多层次的感受野来捕获更具判别力的特征.
1 相关工作
1.1 ST-GCN 和3D-GCN
时空图卷积网络(ST-GCN)包含空域图卷积和时域卷积,分别用于提取骨架序列的空域和时域特征.如图1(a)所示,ST-GCN 先通过空域图卷积提取人体空域结构特征,再通过时域卷积提取时域行为特征.
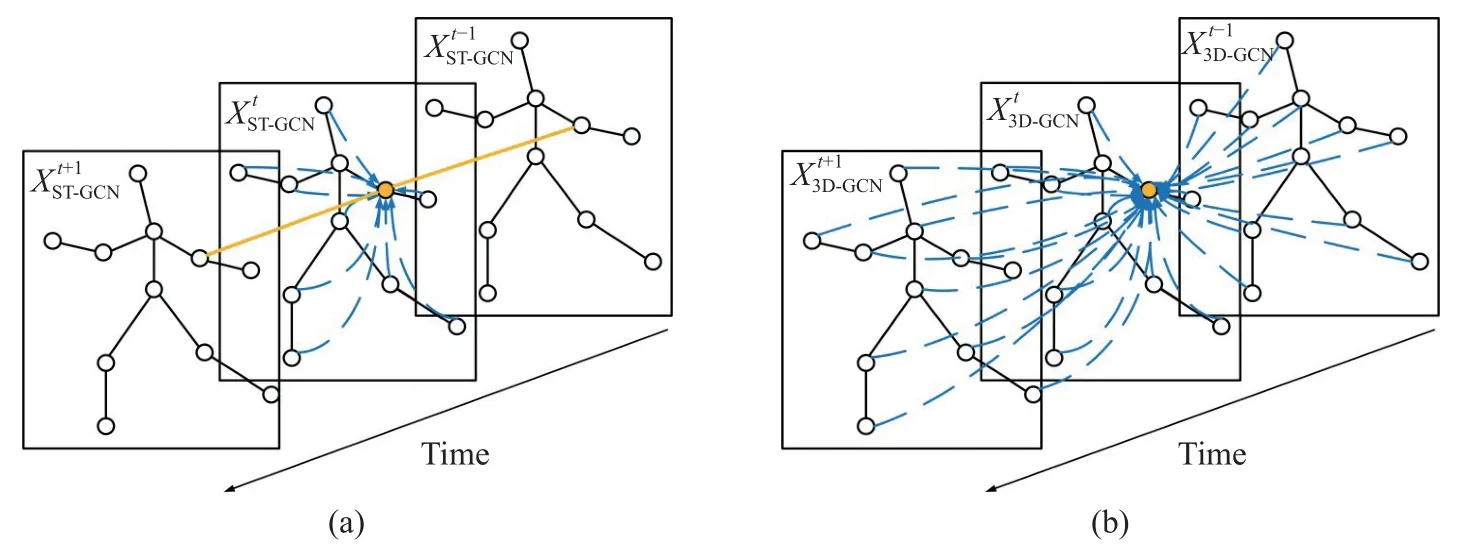
图1 ST-GCN (a)和3D-GCN (b)Fig.1 Spatiotemporal sampling graph convolutional network (ST-GCN) (a) and 3D-GCN (b)
设骨架序列由T张连续骨架帧构成,从第1 帧到第T帧记作G1,G2,···,GT,则第t帧的骨架特征用ST-GCN 提取可表示为:
其中,σ表示sigmoid 激活函数,b表示偏置值,C、V表示通道关节数,A表示连接关系的邻接矩阵,Gk,j表示第k通道、第j个邻居节点的特征值,Wk,j表示二维卷积核函数.
ST-GCN 采用二维卷积核提取时空特征,虽能有效提取骨架序列的时空特征,却阻断了空域和时域信息的相关性.3D-GCN 是基于ST-GCN 提出的一种变体图卷积网络,如图1(b)所示,其通过引入三维图卷积核来替代二维卷积核进行时空特征提取,则3D-GCN 的特征提取可表示为:
值得指出的是:3D-GCN 相比于ST-GCN,通过引入三维卷积核来替代二维卷积核进行时空特征提取,其虽能建立空域和时域信息的相关性,然而这种相关性仅仅是局部跨时空依赖关系,不能建立远程时空上下文的相互依赖关系,因此缺乏全局跨时空依赖关系.
1.2 Transformer 和自注意力机制
Vaswani 等[14]提出一种被广泛应用于自然语言处理领域的Transformer 模型,其与传统的RNN和LSTM 相比,在处理长序列和并行化句子方面均表现更为优秀,同时也在计算机视觉领域得到了广泛的应用.
自注意力是一种能将序列中各位置信息联系起来并计算序列表示的注意力机制.Transformer编解码架构是由多个自注意力模块堆叠构成,自注意力模块的计算过程包括以下步骤:首先,通过对输入数据使用线性嵌入计算得到query 向量、key 向量和value 向量;然后,对query 向量和key 向量进行矩阵乘法运算得到相似度得分矩阵,再对相似度得分矩阵进行Softmax 操作生成权重矩阵;最后,再将权重矩阵与value 向量相乘并加权求和生成自注意力模块的输出.可以将自注意力模块计算过程表示为矩阵形式:
其中,Q,K,V均为矩阵,分别表示query,key 和value向量,dk是key 矩阵的维数,除以为了防止梯度爆炸.
在骨架行为识别工作中,自注意力机制被广泛应用于骨架序列的空域和时域来建立远程连接,如图2 所示.图2(a)表示帧内关节之间的连接,可以理解为捕捉同一帧内每个关节与所有关节的协作关系;图2(b)表示当前帧与所有帧之间的连接,用来捕捉同一关节在不同时域内的运动趋势,可建立骨架序列远程时空的相互依赖关系.
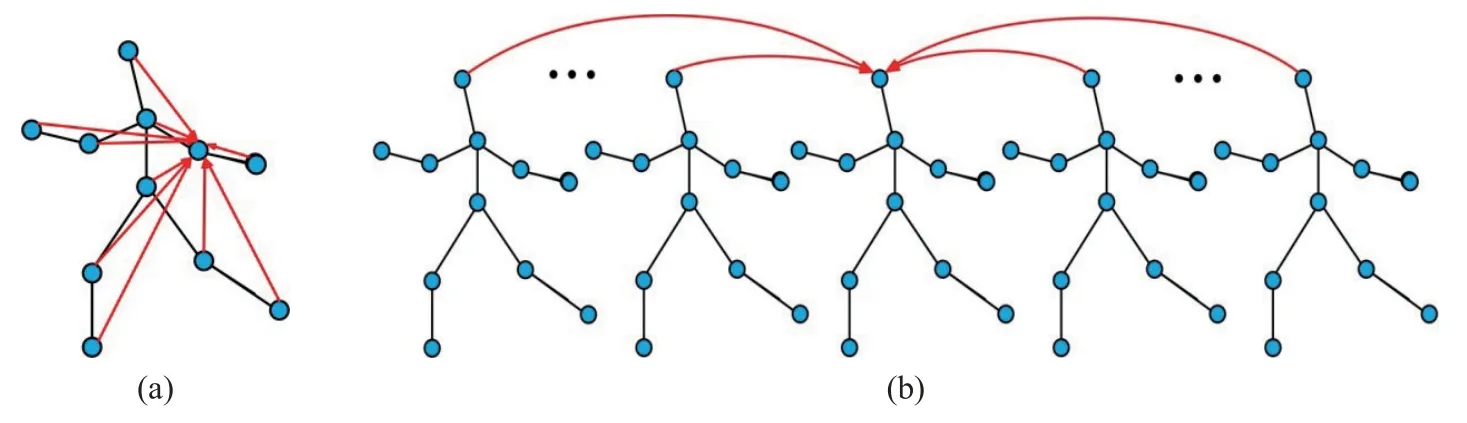
图2 时空Transformer 网络.(a)空域自注意力;(b)时域自注意力Fig.2 Spatiotemporal transformer network: (a) spatial self-attention;(b) temporal self-attention
值得指出的是:Transformer 相比于3D-GCN 虽能建立远程时空的相互依赖关系,却切断了骨架序列的空域和时域信息的相关性,因此不能建立局部跨时空的相互依赖关系.
2 基于时空自采样图卷积网络的行为识别模型
针对现有行为识别算法忽视时空信息上下文的依赖关系,例如3D-GCN 不能建立远程时空上下文的依赖关系,Transformer 忽视空域和时域信息的相关性,不能建立局部时空的依赖关系,本文提出一种基于自校准机制的时空采样图卷积网络的行为识别模型,其包括时空采样图卷积网络和时域自校准卷积网络.
2.1 时空自采样图卷积网络
为了建立骨架序列的跨时空依赖关系,将单帧的人体关节数量为V的拓扑图扩展到时间窗口τ帧的体积图,并在时间窗口的所有连接之间构建跨空域-时域边缘.如图所示,在以τ帧为时域窗口的体积图中,共有τV节点,单一节点其不仅与当前帧内节点存在关联,并与其余τ-1 帧内所有节点存在联系.
通过将单帧的人体拓扑图邻接矩阵扩展到时间窗口τ帧的体积图邻接矩阵,该体积图邻接矩阵表示为:
式中,Ak∈R(N×N)为单帧的人体拓扑图邻接矩阵,Bk∈R(τN×τN)代表以τ帧作为采样的体积图邻接矩阵.
以相邻τ帧作为时空采样,可将骨架序列的全局动作分为各个子动作,每个子动作可视为局部跨时空交互,为建立局部跨时空依赖关系,采用非局部网络[15]将采样频率τ帧内所有节点与当前节点关联,为建立局部跨时空和全局跨时空依赖关系,如图3 所示,提出了一种时空自采样图卷积网络.该时空自采样图卷积网络结构如图3 所示,其主要实现步骤如下:
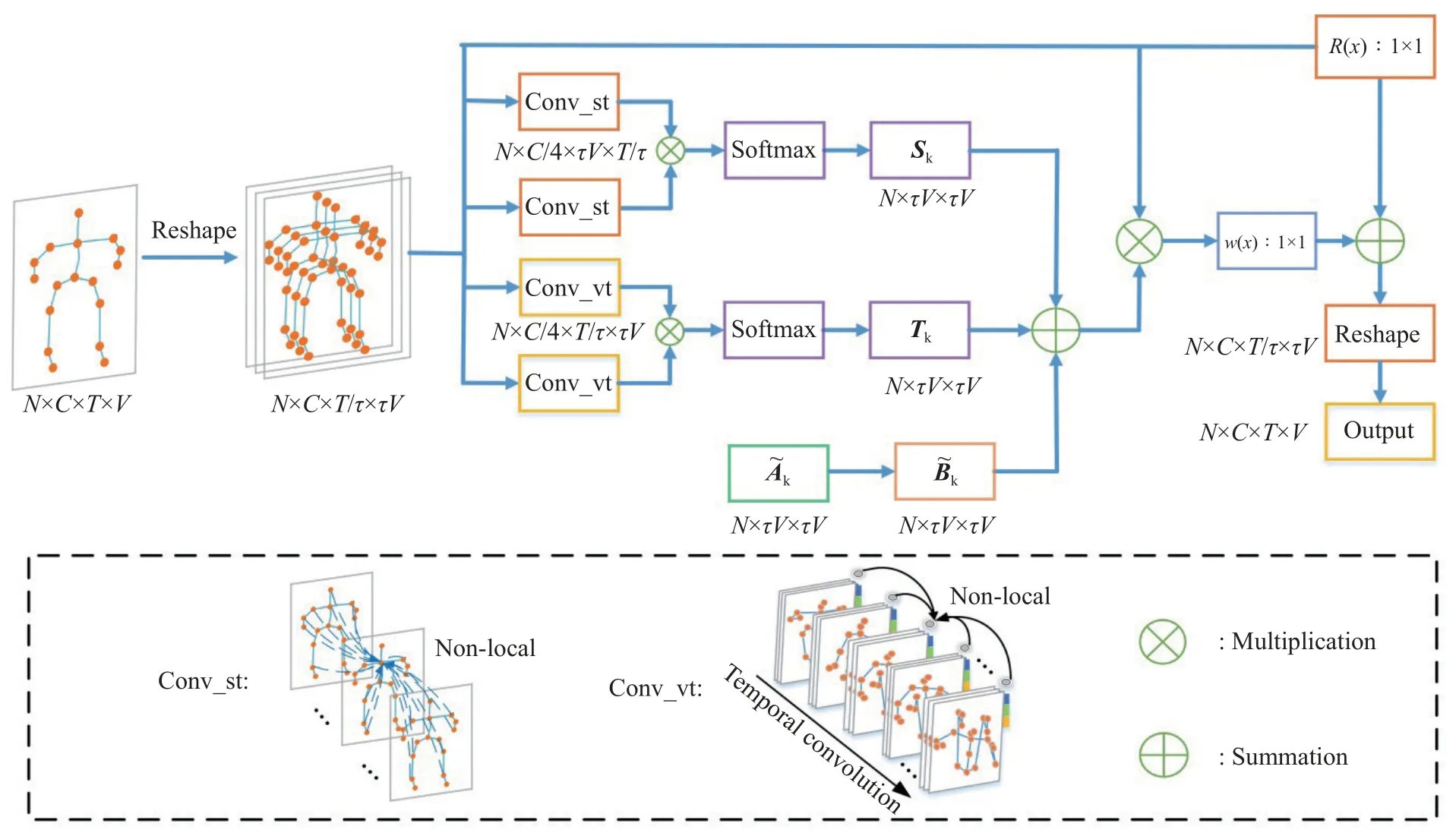
图3 时空采样图卷积网络Fig.3 Spatiotemporal sampling graph convolutional network
步骤1 特征输入Xin.其尺寸为N×C×T×V,分别代表批次、通道数、帧数和关节数;
步骤2 时空采样操作.以τ帧作为时空采样频率,从时域将全局动作分为T/τ个子动作,转换后特征尺寸为N×C×T/τ×τV.
步骤3 空域邻接矩阵Sk的生成.为建立局部跨时空依赖关系,通过非局部网络计算单一节点与采样频率r帧内所有节点的相关性,并使用Softmax函数归一化得到Sk;
步骤4 时域邻接矩阵Tk的生成.为建立全局跨时空依赖关系,结合非局部网络和9×1 时域卷积计算单个采样的子动作与全局子动作的相关性,并使用Softmax 函数归一化得到Tk;
步骤5 时空邻接矩阵的生成.为建立局部跨时空和全局跨时空依赖关系,将Bk、Sk、Tk相加融合为时空邻接矩阵.
步骤6 基于图卷积提取时空特征.以时空邻接矩阵参与图卷积提取时空特征,第n层图卷积操作即:
其中,Xn、Xn+1分别为第n层的输入和输出特征,Wk为卷积核函数,Kmax代表最大距离,设置为3,如图3 所示,R(x)为残差连接,w(x)为1×1 卷积.
综上所论:为建立局部跨时空和全局跨时空依赖关系,提出一种时空自采样图卷积网络:(1)以连续多帧作为时空采样频率,从时域将全局动作分为多个子动作;(2)为建立局部跨时空依赖关系,通过非局部网络的高斯嵌入函数计算单一节点与采样频率r帧内所有节点的相关性;(3)为建立全局跨时空依赖关系,结合非局部网络和时域卷积计算单个采样子动作与全局子动作的相关性.
2.2 时域自校准卷积网络
时空采样图卷积网络虽能有效建立远程时空和局部时空的相互依赖关系,却忽视了时空与通道的依赖关系.同时现有的基于图卷积网络的行为识别模型,其仅仅采用Kt×1 卷积核进行时域特征提取,其中Kt代表卷积核大小,然而这种传统的卷积方式并未差异化各个通道的特征,并且卷积核的大小都是固定的,缺少多层次的感受野来捕获更具判别力的时域特征.因此,如图4 所示,本文提出一种时域自校准卷积网络来建立时空与通道的相互依赖关系,并采用双分支的特征提取方式增强多层次的感受野来捕获更具判别力的时域特征.
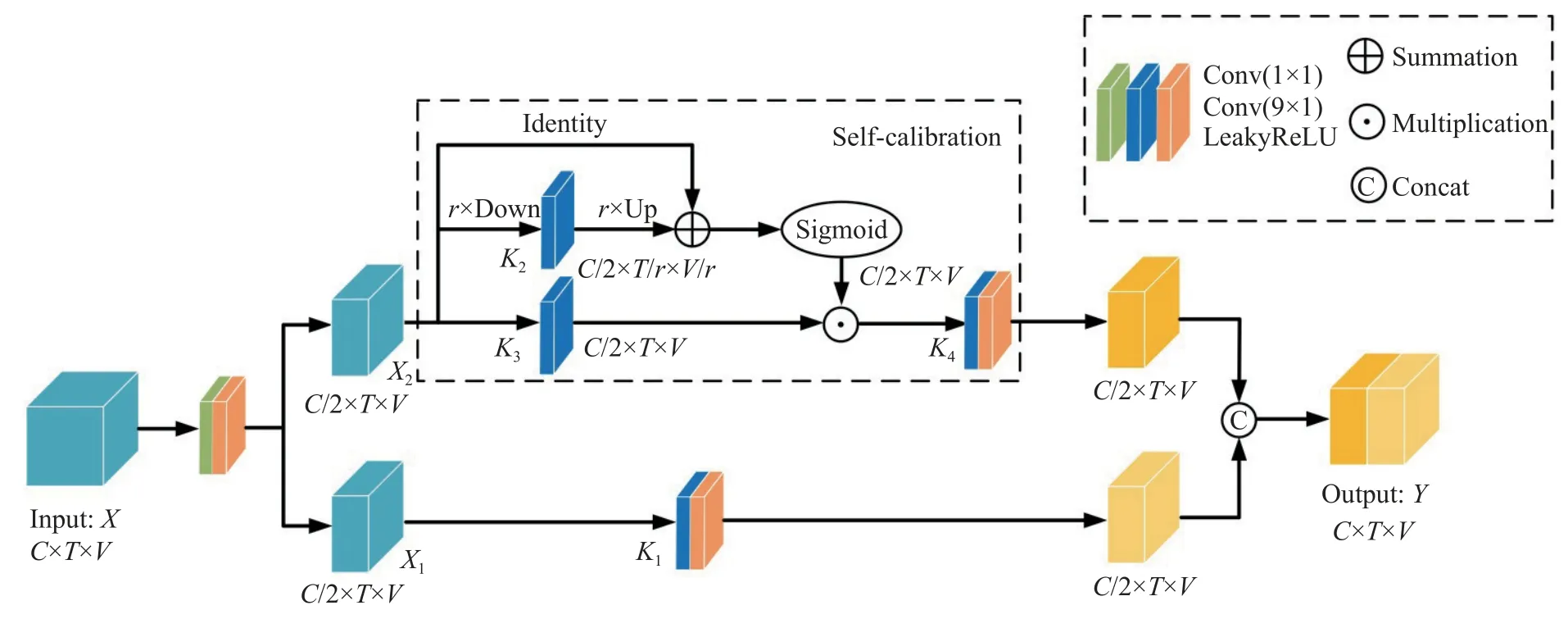
图4 时域自校准卷积网络Fig.4 Temporal self-calibrating convolutional network
为更清楚地阐述时域自校准网络结构,通过以下步骤展开:
步骤1 特征输入.其尺寸为N×C×T×V,经1×1卷积将其拆分为两个N×C/2×T×V大小的X1和X2;
步骤2 时域卷积操作.对于特征X1,采用9×1 卷积核提取行为特征,再进行LeakyReLU 函数激活
其中,F1为卷积核函数,*为卷积操作,Y1为原始比例尺度时空下卷积后的特征.
步骤3 时域自校准卷积操作.可细分为以下子步骤:
首先,对于特征X2,采用滤波器大小为r×r和步长为r的平均池化进行下采样操作
其中,r是池化过程的下采样频率和步长,T2为X2进行下采样操作后的特征.
然后,基于T2进行9×1 卷积和上采样操作
其中,UP 代表上采样操作,是一个双线性插值运算符,将小比例时空尺寸映射到原始时空尺寸.
最后,时域自校准卷积操作可定义为
其中,F3(X2)=X2*K3,,⊗为矩阵相乘,Sigmoid 为激活函数,为采用自校准机制进行下采样后具有较小比例尺度的潜在时空特征,Y2为在潜在时空下进行卷积后的特征.
步骤4 特征输出.为增强多层次的感受野来捕获更具判别力的时域特征,将两分支特征按通道维度进行特征融合
其中,Concat 为特征拼接操作,dim=1 代表按通道维度进行特征拼接.
综上所述,相比于仅采用单一卷积核进行特征提取的时域卷积网络,时域自校准卷积网络具有以下优势:(1)自校准操作自适应地在每个时空位置周围建立了远程时空和通道间的依赖关系,通过差异化各个通道的特征来对通道间依赖性进行建模;(2)自校准卷积网络在两种不同的尺度时空下进行时域特征提取,一种是原始比例尺度的时空,另一种是使用下采样具有较小比例尺度的潜在时空,两者相结合可增强多层次的感受野来捕获更具判别力的时域特征;(3)自校准卷积网络设计简单,与传统时域卷积相结合,增强特征输出的同时而不会引入额外的参数和复杂性.
2.3 基于自校准机制的时空采样图卷积网络模型
如图5 所示,本文提出一种基于自校准机制的时空采样图卷积网络(Spatiotemporal-sampling graph convolutional network based on self-calibration,SSCGCN),该网络模型由一些基本块构成,其分为两个阶段,浅层阶段由ST-GCN 卷积块构成,在空域和时域维度上交替进行空域图卷积和时域卷积以提取空域特征和时域特征,深层阶段由本文提出的SSC-GCN 卷积块构成,SSC-GCN 将时空采样图卷积与时域自校准卷积结合,建立全局和局部时空、时空与通道之间的相互依赖关系,并增强多层次的感受野来捕获更具判别力的特征,以提高行为识别的准确率.

图5 基于自校准机制的时空采样图卷积网络结构Fig.5 Structure of the spatiotemporal sampling graph convolutional network based on the self-calibration mechanism
该网络由10 个基本块(L1~L10)堆叠而成,如图5 所示,输入数据的通道数为3,前4 个基本块的输出通道数为64,中间3 个基本块的输出通道数为128,最后3 个基本块的输出通道数为256,并且将第5 和第8 个基本块的步长设为2,其余为1.在将骨架数据输入到基本块之前,首先对数据进行归一化操作,使数据更加规范和便于处理,该操作在批标准化层执行,经过10 个基本块后,将输出特征送入到池化层进行全局平均池化来得到一个固定大小的特征向量,并与Softmax 分类器相连,实现对动作的分类并预测最终的结果.
3 实验结果与分析
3.1 数据集
NTU-RGB+D[16]数据集是目前规模最大、应用最广泛的室内捕捉动作识别数据集之一.它包含从RGB+D 视频样本中采样的56880 个RGB 视频、深度序列、骨架数据和红外帧.骨骼信息由25 个身体关节的三维坐标组成,代表60 种不同的动作类别.每个动作序列由一到两个被摄体完成,并由三台Microsoft Kinect-V2 相机同时从不同的视角拍摄.评估基准包括交叉对象(X-Sub)和交叉视角(X-View).在交叉对象中,训练数据来自20 个对象,测试数据来自其他20 个对象.在交叉视角中,训练数据来自摄像机视角2 和3,测试数据来自摄像机视角1.
李老鬼认定,他侄儿落到这一步,全是付玉害的。这天,他决定给付玉联系一下,打了几个号,终于有一个是通的。他说,我是李叔和的叔,有个大人物想见你。另外,我有一包东西要送你。
NTU-RGB+D120[17]是目前最大的基于人体骨骼的动作识别数据集,是NTU RGB+D 数据集的扩展,总共有113945 个动作序列和120 个动作类.这些动作序列由106 名志愿者执行,用三个摄像头拍摄,包含32 个设置,每个设置代表不同的位置和背景.评估基准包括交叉对象(X-Sub)和交叉设置(X-Setup).在交叉对象中,训练数据来自53 个对象,测试数据来自其他53 个对象.在交叉设置中,训练数据来自设置ID 为偶数的样本,测试数据来自设置ID 为奇数的样本.
3.2 实验细节
骨架行为识别算法是基于pytorch 深度学习框架下进行的,其优化策略采用随机梯度下降(Stochastic gradient descent,SGD),Nesterov 动量设为0.9,迭代周期设为50,学习率设置为0.01,同时为克服训练时过拟合问题,选择交叉熵作为损失函数并将权重衰减设置为0.0001,衰减周期设在第30 和40 个周期,batch size 设为10.
3.3 消融对比实验
3.3.1 时空采样频率对比实验
如图3 所示,时空采样图卷积通过扩展相邻τ帧内相同位置节点的邻居节点,实现了时空采样操作.而时域维度上的邻居采样范围会影响模型时空特征提取能力,长采样范围无法关注短时重要信息,短采样范围则无法提取上下文信息.为探究最优的采样范围,本文分别设置了3 类采样范围在NTU-RGB+D 数据集的X-View 下进行对比实验研究,实验结果如表1 所示.

表1 不同帧采样范围的识别准确率对比Table 1 Comparison of the recognition accuracy of different sampling ranges %
由表1 对比可知,以3 帧和5 帧进行时空采样的图卷积网络相比于未进行时空采样的图卷积网络(1 帧采样),双流合成的识别准确率均有所提升,验证了时空采样机制对于特征提取的有效性.同时当τ=3,即以3 帧作为采样范围,模型的性能达到最优,其关节流和骨架流的识别准确率达到了最高,分别为93.2%和92.7%,双流合成后识别准确率为94.6%,故该模型选择3 帧作为时空采样频率.
3.3.2 时域自校准倍率对比实验
如图4 所示,时域自校准卷积采用滤波器大小为r×r和步长为r的平均池化进行下采样操作,r为下采样倍率,代表每个时空位置所接受的长距离范围,r越大,接受的长距离范围越大,反之则越小.而不同的长距离范围关系到时空与通道之间的关联程度,从而影响到时空特征提取的能力.为探究最优的下采样倍率,本文分别设置了5 种倍率下采样在NTU-RGB+D 数据集的X-View 下进行对比实验研究,实验结果如表2 所示.

表2 不同倍率下采样的识别准确率对比Table 2 Comparison of the recognition accuracy of different magnifications %
由表2 对比可知,当r=6,即6 倍下采样频率时,模型的性能达到最优,即双流合成的识别准确率达到最高,故自校准倍率设置为6.
3.3.3 SSC-GCN 层数对比实验
如图5 所示,本文的模型分为两个阶段.浅层阶段由ST-GCN 卷积块提取时空特征,深层阶段由本文提出的SSC-GCN 卷积块提取时空特征.因此,本文对如何划分这两个阶段进行了消融实验,并将网络第2 阶段的SSC-GCN 层数设置为不同数量来寻求最佳的划分方式,本文分别设置了4 种不同层的SSC-GCN 在NTU-RGB+D 数据集的X-View下进行对比实验研究,实验结果如表3 所示.

表3 不同层SSC-GCN 的识别准确率对比Table 3 Comparison of the recognition accuracy of different SSC-GCN layers %
由表3 可知,当SSC-GCN 为4 层时,模型的性能达到最优,即该模型的识别准确率达到最高.可以观察发现,随着SSC-GCN 层数的增加,识别准确率先升高后降低,即在浅层之后刚添加SSC-GCN块,使网络具备新层次的特征提取方式,弥补了ST-GCN 在时空上下文依赖方面、多层次特征提取方面的不足,提升了模型的性能,因而精度得到一定的提升.然而SSC-GCN 相较于ST-GCN 参数量较大,一味增加SSC-GCN 层数的方式使得网络发生了过拟合现象,精度反而发生了下降.因此,最终将SSC-GCN 层数设置为4.
3.3.4 模型有效性验证实验
为验证基于时空采样机制的图卷积网络、基于自校准机制的时域卷积网络的有效性,以TEGCN 原始模型[18]作为Baseline,分别结合时空自采样机制和时域自校准机制,基于关节流和骨架流组成的双流网络,在NTU-RGB+D 数据集的XView 下进行消融对比实验,实验结果如表4 所示.

表4 NTU-RGB+D 数据集X-View 下消融实验的识别准确率Table 4 Recognition accuracy of ablation experiment under the X-View of the NTU-RGB+D dataset %
由表4 可知,在NTU-RGB+D 数据集的X-View 下:
(1) 基于时空采样图卷积网络的Baseline 相比于Baseline,其关节流和骨架流识别准确率分别提高了0.6%和0.6%,双流合成后识别准确率提高了0.4%,可知以连续多帧作为采样的时空采样图卷积相比于空域图卷积网络识别准确率均有所提升,验证了通过时空自采样机制建立全局和局部时空上下文依赖关系对于模型性能提升的有效性;
(2) 基于时域自校准卷积网络的Baseline 相比于Baseline,其关节流和骨架流识别准确率分别提高了0.5%和0.2%,双流合成后识别准确率提高了0.2%,可知以多层次特征提取的时域自校准网络相比于仅采用单一卷积核进行特征提取的时域卷积网络识别准确率均有所提升,验证了通过时域自校准机制进行多层次特征提取对于模型性能提升的有效性;
(3) 结合时空采样图卷积网络和时域自校准网络的Baseline 相比于Baseline,其关节流和骨架流识别准确率分别提高了0.8%和1.1%,双流合成后识别准确率提高了0.6%,可知结合时空采样机制和时域自校准机制的模型识别准确率得到了更大程度的提升,从而进一步验证结合时空采样机制和时域自校准机制对于模型性能提升的有效性.
3.4 识别准确率对比实验
3.4.1 NTU-RGB+D
为验证SSC-GCN 模型的优越性能,以Shi 等[19]提出的多流网络为框架,基于X-View 和X-Sub 划分的NTU-RGB+D 数据集上,开展骨架行为识别研究并与国内外先进的CNN、RNN 和GCN 方法进行对比,具体的实验对比结果如表5 所示.

表5 NTU-RGB+D 数据集上不同模型的识别准确率对比Table 5 Comparison of the recognition accuracy of different models on the NTU-RGB+D dataset %
由表5 可知,在以X-View 和X-Sub 划分的NTURGB+D 数据集上:
(1) SSC-GCN 模型相比于其他方法均取得了最高的效果,即识别准确率达到了最高,分别为95.2%和88.8%,验证该模型具有优秀的识别准确率;
(2) 基于多流网络的SSC-GCN 模型相较于基于关节流和双流的SSC-GCN 模型,识别准确率有了明显的提升,验证了多流网络的优越性;
(3) SSC-GCN 模型相比于GCN 代表方法STGCN,识别准确率分别提高了6.9%、6.3%,验证该模型相较于传统GCN 方法在性能上的改善;
(4) SSC-GCN 模型相比于基于CNN 和RNN的最新方法LAGA-Net 和DS-LSTM,识别准确率分别提升了2.0%、1.7%和7.9%、11.0%,验证了该模型相比于传统的深度学习网络有较大的优势;
(5) SSC-GCN 模型相比于GCN 最新方法PGCNTCA 和Co-ConvT,识别准确率分别提升了1.6%、0.8%和0.9%、0.7%,验证了该模型相比于最新的GCN 方法有较大的优势.
3.4.2 NTU-RGB+D120
单一数据集不能充分体现SSC-GCN 模型在不同数据集上的泛化能力,为进一步地验证该模型在不同数据集上的优越性能,从而证明该模型的泛化能力,以多流网络为框架,基于NTU-RGB+D120数据集对SSC-GCN 模型进行了实验,并与国内外先进的CNN、RNN 和GCN 方法进行对比,其具体实验结果及对比结果如表6 所示.

表6 NTU-RGB+D120 数据集上不同模型的识别准确率对比Table 6 Comparison of the recognition accuracy of different models on the NTU-RGB+D120 dataset %
由表6 可知,在以X-Sub 和X-Setup 划分的NTURGB+D120 数据集上:
(1)SSC-GCN 模型相比于其他方法均取得了最高的效果,即识别准确率达到了最高,分别为81.7%和84.0%,进一步验证该模型具有优秀的识别准确率;
(2)基于多流网络的SSC-GCN 模型相较于基于骨架流和双流的SSC-GCN 模型,识别准确率有了明显的提升,进一步验证多流网络的优越性;
(3)SSC-GCN 模型相比于GCN 的代表方法STGCN,识别准确率分别提高了9.3%和12.7%,进一步验证该模型相较于传统GCN 方法在性能上的改善;
(4)SSC-GCN 模型相较于CNN 和RNN 的代表方法LAGA-Net 和GCA-LSTM,识别准确率分别提高了0.7%、1.7%和23.4%、245.8%,进一步验证了该模型相比于传统的深度学习网络有较大的优势;
(5) SSC-GCN 模型的识别准确率相较于基于GCN 的最新方法ST-GDNs 和SGN,其分别提高了0.9%、1.7%和2.5%、2.5%,进一步验证了该模型相较于最新的GCN 方法具有良好的竞争力.
综上实验结果表明:(1)论文提出的SSC-GCN模型,在NTU-RGB+D 和NTU-RGB+D120 数据集上均取得了优越的性能,验证了该模型具有优秀的识别准确率和泛化能力;(2)SSC-GCN 模型相较于其他的行为识别方法,其既能有效建立局部和全局时空的依赖关系,又能增强时域多层次的感受野来捕获更具判别力的特征,实验结果验证了该模型提取时空特征的有效性.
4 结论
基于现有的人体骨架行为识别方法忽视时空信息上下文的依赖关系和时空与通道之间的依赖关系的问题,论文提出了一种基于自校准机制的时空采样图卷积网络行为识别模型.首先,选时序连续多帧作为时空采样,构建时空采样图卷积网络来建立局部和全局时空上下文依赖关系.然后,提出一种时域自校准卷积网络在原始比例尺度的时空和使用下采样具有较小比例尺度的潜在时空中分别进行卷积并特征融合,以有效建立时空与通道之间的依赖关系并增强多层次的感受野来捕获更具判别力的特征.同时结合时空采样图卷积网络和时域自校准网络构建基于自校准机制的时空采样图卷积网络行为识别模型,在多流网络下进行端到端的训练.
实验结果表明,基于时空特征增强图卷积网络模型相较于其他方法,具有更好的时空特征提取能力和更高的识别准确率,验证了该网络模型的优秀性能.值得指出的是,该模型当前仅应用于识别骨架数据集中的行为动作,尚未在现实场景中进行应用.后续的工作中,将在现实中尝试加入场景、物体和交互信息更复杂的行为动作,并进一步探索出挖掘时空特征性能更优越的行为识别模型.
