社会福利的测度与比较
——基于不平等厌恶系数的研究方法
2024-02-21吴晴静章贵军王开科
吴晴静,章贵军,王开科
(1.福建师范大学 数学与统计学院,福建 福州 350177;2.山东财经大学 统计学院,山东 济南 250011)
一、引言
社会福利是指一个社会为其成员提供的各种公共服务和福利保障,这些公共服务和福利保障能减缓不平等程度(岳经纶等,2020)[1]。当社会福利由抽象的美好状态具化为实现美好生活的具体措施时,测度社会福利水平、揭示发展不平衡的短板、提出增进社会福利水平的政策建议将有利于促进共同富裕和现代化建设。
社会福利是一个综合性概念,涉及到人们的物质生活水平、精神生活状态和生活环境等多个方面,涵盖的领域相对比较宽泛。目前,对于如何准确、全面地测量社会福利水平并没有统一的标准。以往研究表明,社会福利水平的测度方法大致分为三类,即经济指标法、社会指标法和综合指标法(吴姚东,2000)[2]。经济指标法主要通过衡量经济活动对社会福利的影响来评估社会福利水平,常用的经济指标包括国内生产总值、人均收入和人均消费等(吴姚东,2000;Jones and Klenow,2016)[2,3]。社会指标法关注社会领域的各个方面,如教育、健康、住房和社会保障等(夏宇,2020)[4]。综合指标法则试图将经济指标和社会指标进行综合考量,以获得更准确和更全面的测度方法(王圣云、姜婧,2020)[5]。近年来,一些综合指标如人类发展指数(HDI)、可持续发展指数(SDI)和基于可行能力理论(Sen,1982)[6]构建的福利指数得到了广泛应用(UNDP,2010;王圣云、姜婧,2020)[7,5]。具体而言,三种测度方法各有其优势和局限性。经济指标法虽然易于计算和比较,但忽视了居民主观公平感受和生态可持续性等非经济因素;社会指标法能够提供更全面的信息,但是容易受主观判断和数据资料不全的影响;综合指标法虽然可以综合考虑多方面的因素,弥补上述两个方法的部分缺陷,但是对指标的权重和计算方法有较高要求。为克服这三种方法的不足之处,参考Schmidt 的模型(Schmidt and Wichardt,2018)[8],本文在经济指标的基础上考虑主观层面的因素,基于不平等厌恶系数构建测度社会福利水平的新方法,并对比社会指标法,以期获得一个具有较高效度的福利水平指数。
当前关于社会福利水平的研究已经形成了相对完整的理论框架和实证方法,而基于不平等厌恶系数的测度研究还在探索阶段。不平等厌恶系数用于评估人们接受不平等的程度,在Atkinson(1970)[10]提出的“不平等厌恶”(inequality aversion)的社会福利函数支撑下,可以通过福利函数测度出不平等厌恶水平,从而量化不平等程度。不平等厌恶系数作为衡量个体对不平等程度敏感度的指标,可以用于评估社会不平等水平,还可以用于社会政策制定、税收改革、公平待遇提升、激励机制设计等方面,为决策者提供重要的参考依据(王熹等,2022)[9]。
关于不平等厌恶系数的估计,学者们提出了一系列具有代表性的方法。例如Atkinson 模型(Atkinson,1970)[10]和Fehr-Schmidt 模型(Fehr and Schmidt,1999)[11],分别从收入再分配和博弈论的角度对其进行测度。在实证研究方面,对于不平等厌恶系数的测度目前主要有三种经验方法,分别是税收结构倒推法(Stern,1977;Christiansen and Jansen,1978)[12,13]、实验方法(郑万军等,2023)[14]和阿特金森 福 利 函 数 测 度 方 法(Laydard et al.,2008;Gandelman and Hernández-Murillo,2011;汪毅霖、张宁,2021)[15-17]。前两种方法的测度依赖于主观投票结果,第三种方法虽然具有较强的外部有效性,以微观调查数据为基础,但是依赖于个人对收入或财富的评估,因此会导致测度结果存在较大的偏误。由于确定不平等厌恶系数和选择经济指标存在主观性,并且阿特金森社会福利函数本身也有一些局限性。因此在实际应用中,需要综合考虑其它因素,并结合具体情境和目标综合评估不平等厌恶系数测度方法的有效性和准确性。
在不平等视角下评估社会福利水平,为研究社会福利提供了新视角。联合国开发计划署(UNDP)制定的“人类发展指数”是基于Sen(1985)[6]的可行能力评估框架构建的综合指数,国际公认可用于衡量人类的发展水平,反映人类福祉水平(王圣云、姜婧,2020)[5]。由于不平等厌恶系数反映了人们对社会财富分配公平程度的态度,因此将这一系数纳入社会福利测度可以更全面地反映人们的福利水平。汪毅霖和张宁(2021)[17]利用客观估算出的各省级行政区的不平等厌恶系数值和阿特金森不平等指数,得到调整的人类发展指数(NIHDI)。Oishi 和Kesebir(2015)[18]认为收入不平等可以解释经济增长并不总是导致幸福感提高的原因,刘自敏等(2018)[19]认为主观社会公正感受能够显著提升居民认知幸福感。因此,在社会层面上,有效衡量社会福利应同时关注绝对指标(如GDP)和相对指标(如不平等指数)。Sen于1976 年提出了一个福利测度的“粗方法”,在测度时考虑收入的绝对水平和分配的平等程度,即W=μ(1-G),其中W表示福利水平,μ 表示收入水平,G表示基尼系数。Schmidt 和Wichardt(2019)[8]基于Fehr和Schmidt(1999)[11]的不平等厌恶模型,提出了新的测度社会福利的方法,该方法考虑了不平等厌恶对福利函数的影响,同时使用Gini 系数衡量社会公正性,从而为评估社会福利提供了一个更为全面的指标。
改革开放以来,中国城市与乡村、沿海和内陆地区的资源禀赋、政策环境、发展起点均存在差异,导致城乡和区域发展不平衡(约翰逊,2004;Long et al.,2011;Liu et al.,2020)[20-22]。在过去几十年里,中国东南沿海地区的经济水平及发展速度长期高于中西部地区,并逐渐形成了显著的经济差距,影响居民收入水平(赵志君、庄馨予,2023;阎大颖,2007)[23,24]。地区之间经济发展差距的扩大,逐渐衍生出福利水平差距的扩大(孙志燕、侯永志,2019)[25]。具体而言,居民福利水平受区域经济发展、地区特征、政府政策、资源分配以及历史社会文化等多种因素的影响(江求川,2015)[26],存在城乡差异和区域差异。在城乡差异方面,城镇居民相对于农村居民其整体社会福利水平更高,城镇化道路固化了原有城乡二元公共服务体制下的差异化福利分配结构(王伟同,2011)[27];在区域差异方面,区域内差异呈现“东→西→中→东北”递减趋势,东部地区与西部地区之间的差异较大(张文彬、郭琪,2019;李雯等,2021)[28,29]。地区之间发展差异持续扩大,不平等现象长期存在,社会福利无法避免地形成马太效应(刘煜、刘跃军,2021)[30],而当前研究并没有对这一现象进行分析。部分学者(张文彬、王赟,2021)[31]采用熵值法测度了中国福利水平,并通过Dagum 基尼系数探究区域差异。邓婧和宋一弘(2018)[32]采用经济福利指数研究发现,居民的经济福利水平在总体上呈现沿海与内陆、市区与县区的二元特征,即沿海地区和市区居民显著高于内陆地区和县区居民。在此结合经济指标和居民公平感受构建测度社会福利水平的新方法,深入探究社会福利不平衡的现状及原因。
本文的边际贡献主要在于:(1)利用五期CGSS数据分别对优势不平等厌恶系数和劣势不平等厌恶系数进行测度;(2)在不平等视角下测度社会福利水平,基于不平等厌恶系数构建测度社会福利的新方法,将测度结果与熵值法测算的综合指数进行比较;(3)在不平等视角下比较社会福利水平的区域差异,使用机器学习算法对区域之间和城乡之间的福利水平进行探究,测度地区间的马太效应,并剖析东西部地区存在福利差异的原因。
二、理论分析
(一)不平等厌恶的理论分析
不平等厌恶是指人们对社会经济不平等的情感反应,其理论基础可以追溯到社会心理学和行为经济学领域。传统经济学中人们常被假定为具有同质性和利己特征的理性经济人,实验经济学家和行为经济学家则更多地采用具有异质性和利他特征的社会偏好理论来解释现实个体的合作行为。Fehr 等实验经济学家的实验结果表明,被试者不仅有利己动机,还会考虑其他个体的福利,即有社会偏好。在诸多社会偏好模型中,Fehr 和Schmidi(1999)[11]的不平等厌恶偏好理论应用最为广泛。该模型基于人类固有的嫉妒和内疚情感分别构建个体劣势和优势不平等厌恶系数,表示无论个体物质收益比其他人差还是比其他人好,个体都会感觉到由于不平等带来的负效用(连洪泉等,2016)[33]。相关研究则表明个体通常会将自己的财富、地位和成就与他人进行比较,并根据这种比较来评估自己的满意程度。若发现自己所得相对于他人处于优势位置,则为优势不平等;若发现自己所得相对于他人处于劣势位置,则为劣势不平等。优势不平等和劣势不平等都会产生不平等厌恶的情感反应,即两种不平等都会产生负的效用。一般情况下,人们希望分配的结果有利于自己,因此通常认为优势不平等的厌恶程度低于劣势不平等(吕小康等,2018)[34]。人们也会因为同情、羞耻和其他道德感受而希望减少不平等即优势不平等,甚至会牺牲自己的经济利益追求平等(连洪泉等,2016)[33]。从经济收入的角度来看,个人的主观幸福感会受到收入公平感知的影响。如果个人认为自己的收入与其他人相比是公平的,那么其主观幸福感会更高。不平等厌恶被认为是影响个人收入公平感知的重要因素,因为当个人感受到收入分配不公平时,就会对不平等产生厌恶情绪,从而对收入分配做出更为负面的主观判断。也就是说,收入公平感知是影响个人主观幸福感和收入分配主观判断的重要因素(曹大宇,2009)[35]。
(二)不平等厌恶系数的估算
阿特金森社会福利函数(Atkinson,1970)[10]是不平等厌恶的福利经济学的理论基石,其函数形式为:
其中:i=1,2,…,n;n为样本单位的个数;ρ 为不平等厌恶系数,ρ=0 时表示边际效用不变,ρ>0 时表示边际效用递减。阿特金森社会福利函数主要基于以下三个假设:第一,个体平等享有相同的社会权利,即所有个体的社会福利权重是相同的;第二,社会中所有个体偏好相同但个体效用ui不同,ui不同由收入的不同导致;第三,所有个体的边际效用递减。基于这三个假设,不平等厌恶系数ρ 会给个体效用ui带来负面影响,这意味着个体对于不平等的厌恶程度越高,为了消除不平等而愿意承担更高效率成本的主观意愿就越强。
参考汪毅霖和张宁(2021)[17]的方法,基于阿特金森社会福利函数,利用微观调查数据进行估算,该方法利用了微观调查数据中受访者幸福感与收入的关系。这里对个体幸福感、效用函数与收入做出三个假设。
其一,受访者汇报的幸福感Hi与其感受的效用Ui之间有函数关系,Hi=f(Ui)。该线性函数关系适用于全部受访者,且H不是U的凹函数,即幸福感随着效用的增加而增加,不会出现效用增加幸福感下降的情况。
其二,个体i的效用可描述为:
其中:yi为个人i的收入;收入变量的系数α 对于所有个人都一致;xji为控制变量;βj为控制变量的回归系数;εi′为误差项,该误差项与效用或幸福感无关。在这一假设基础上代入CGSS 中对应的数据,即可测算出不平等厌恶系数。
其三,在特定的样本集合内,基于Rawls(1971)[36]的“无知之幕”理论,假设不平等厌恶系数ρ 对全部个体一致,测度优势不平等厌恶与劣势不平等厌恶的两组数据可以近似认为是同一群体。Rawls 认为,在一个正义社会中,个体应该在不知道自己将来具体情境的情况下,选择一个公正的原则来规定社会的基本结构和资源分配。这样,个体在决策时不会受到自身特定利益或地位的影响,而是以公正和公平的原则进行决策。
结合以上假设,使用微观数据测度不平等厌恶系数。调查数据提供了关于个人对不平等的态度和偏好的详细信息,能较好地反映个人对社会公平性的期望和价值观,可用来分析不同群体之间的不平等厌恶程度。相较而言,实验数据无法满足测度多期社会福利水平的需求,使用CGSS 微观数据测度不平等厌恶系数则有利于克服时限问题。
三、研究方法与变量测度
(一)研究方法
Schmidt 和Wichardt(2018)[8]在Fehr 和Schmidt(1999)[11]测度模型的基础上,构造了一个含有人均国内生产总值和基尼系数的函数,用来测度社会福利水平。该模型假设个体对不平等具有厌恶感,通过聚合个体的效用函数从而得到社会福利函数的近似表达形式。
首先,假设一个社会由n个个体组成,每个个体的收入为yi,其中i=1,…,n,收入按增序排列,即yi>ym对于i>m成立。个体i的效用定义如下:
其中,α 表示劣势不平等厌恶系数,β 表示优势不平等厌恶系数。与功利主义方法一致,将社会福利定义为个体效用之和。结合Harsanyi(1955)[37]的观点,由于个人不知道自己(后来)在社会中的地位,因此每个人以相同的份额(1/n)平分社会总福利,并且社会中个体偏好即参数α、β 的值会趋于一致。将式(3)个人效用以个人分配概率为权重加权求和,得到社会福利W的表达式为:
通过简单的求和计算与重新排列,整理得到:
结合基尼系数的定义式,取n→∞的极限,可得:
进一步简化之后,得到福利函数的近似表达式为:
其中,y为居民收入。显然,相对于Sen(1976)[38]的福利测度公式,式(7)综合考虑了个人对社会不平等的感受。若控制其它变量,则个人对社会不平等厌恶程度越高,社会福利水平越低,反之亦然。
在此基础上,基于K-means 算法和Apriori 算法开展关联规则挖掘。K-means 算法是一种常见的无监督聚类算法,传统的断点方法不适用于熵值法结果,依据K-means 算法聚类划分各个子指标的水平特征更合理有效,同时可以达到将熵值法结果离散化的目标,便于进一步提取指标特征。作为挖掘频繁项集的经典算法,Apriori 算法基于先验知识剪枝搜索空间,具备更高的频繁项集的挖掘效率。其核心思想是利用候选项集的特性,通过逐层筛选来得到所有频繁项集。
本文通过Apriori 算法挖掘社会福利水平的关联规则。第一步,设定最小支持度阈值(即min support),根据数据集中的事务和经K-means 离散化的社会福利特征构建出所有可能的项集。第二步,统计每个项集出现的次数,剔除支持度低于阈值的项集。第三步,对剩余的项集组合生成更长的项集,并重复第二步与第三步,直到不能再生成更多的频繁项集。Apriori 算法能通过将挖掘目标设置为1 实现定向挖掘,既能挖掘福利水平整体特征又能挖掘高水平福利特征,并详细到具体地区的具体福利水平子指标特征。
在社会福利不平等测度方面,参考张和平等(2021)[39]的研究,通过构造序位波动系数与马太系数,重构马太指数。首先,构建序位波动性指标,用于度量积累优势。定义序位差绝对值之和ΔRt与最大序位差绝对值之和ΔRmax(n)的比值为序位波动系数(Fluctuation Coefficient,FC),形式如下:
其中,rij为各期数值对应的等级序位。在此基础上,融合离散指标和序位波动性指标,将马太系数(Matthew Coefficient,MC)②定义为:
其中,CVt为该期变异系数。
其次,通过确定基期以横向对比分析马太效应的变化趋势,并最终构建马太指数(Matthew Index,MI)为:
为进一步探究造成福利水平马太效应的成因,此处将地区划分为东部与非东部两组,通过Oaxaca-blinder 分解③阐释两个分组间的平均差异。
其中,e表示东部地区,ne表示非东部地区。式(11)表示因变量Y在两个群体之间的差异分别是由特征回报差异和个体特征差异带来的。
(二)变量选取
1.基于不平等厌恶系数的社会福利水平测度。测度不平等厌恶系数时,被解释变量是主观幸福感(happiness)。CGSS 关于幸福感的调查采用的是五级量表式调查问题,主观幸福感由低到高设置为“非常不幸福”“不幸福”“一般”“幸福”和“非常幸福”,被调查者在五个选项中选择自己的幸福感受,用1 至5的整数对五级幸福感受由低到高进行赋值。
处于优势不平等厌恶的个人对社会中存在的不平等现象感到不满和反感,相比之下,处于劣势不平等厌恶的个人对自己所处环境感到不满和反感。因此,控制变量的选取来自个人公平感和和社会公平感两个部分,个人公平感由CGSS 中关于“阶层自我评价”的问题反映,社会公平感由“社会公平评价”的问题反映。CGSS 关于调查阶层自我评价的问题分为当前、十年前、十年后三种类型,为保证评价的时效性,选取调查者对当前的自我评价数据进行计算。由于调查问题采用的是十级量表式问题,具体问题为“您自己目前在哪个等级上”,对于十个回答等级按照问卷中的“1”至“10”10 个选项进行赋值。选“1”赋值为1,表示调查者认为自己处于最底层;选“10”赋值为10,表示调查者认为自己处于最顶层。CGSS 对社会公平评价调查的问题采用五级量表式问题,具体问题为“总的来说,您认为当今的社会公不公平?”,回答选项为“完全不公平”“非常不公平”“说不上公平但也不能说不公平”“比较公平”和“非常公平”,用1 至5 的整数对五级公平感受由低到高进行赋值,其中“完全不公平”赋值为1,“非常公平”赋值为5。为便于计算,并且避免非理性回答带来的干扰,将阶层自我评价为1 至5 分且社会公平评价为1 至3 分的人群计算所得的不平等厌恶系数归类于劣势不平等,将阶层自我评价为6 至10 分且社会公平评价为1 至3 分的人群计算所得的不平等厌恶系数归类于优势不平等。
以往研究中常选取个人年收入计算不平等厌恶系数,然而老人、家庭主妇、青少年等这类人群无收入、占比大,不能忽略,故本文以家庭为单位,将被调查者的人均家庭年收入设置为模型中的收入变量。考虑到性别、年龄、受教育年数、婚姻状况、政治面貌、户籍、就业情况和健康状况对个体幸福感影响较大,在计算过程中设置为个体特征变量并控制。性别方面,女性赋值为1,男性赋值为0。受教育年数方面,根据受学校正规教育的年数测算。婚姻状况方面,有配偶赋值为1,无配偶赋值为0。政治面貌方面,中共党员赋值为1,非中共党员赋值为0。户籍方面,城镇户籍赋值为1,农村户籍赋值为0。就业情况方面,当前就业赋值为1,当前失业赋值为0。健康状况方面,将选项“很不健康”“比较不健康”“一般”“比较健康”“很健康”分别由低到高赋值为1 至5 分。
2.传统社会福利水平测度的变量选取。为检验结合不平等厌恶系数建立的福利水平指标体系的效度,构建如1 所示的社会福利水平指标体系。该指标体系主要借鉴李胜会和邓思颖(2020)[40]的做法,并参考其他研究,从经济环境、文化教育、就业和社会保障、医疗卫生、生态环境五个方面构建传统的社会福利水平评价指标体系。
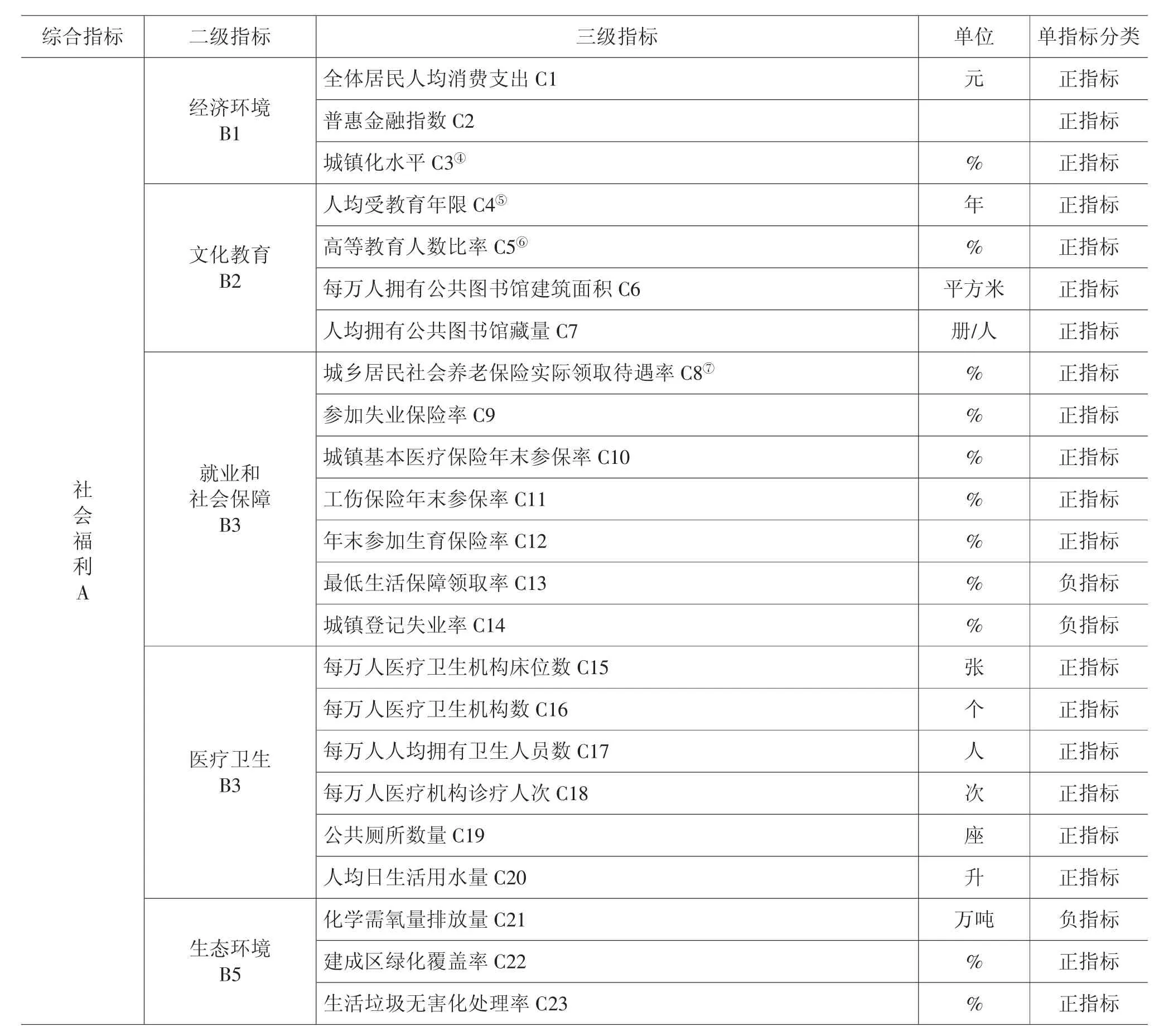
表1 社会福利水平评价指标体系
本文测算涉及的微观数据来源于2014—2020年共五期的中国综合社会调查(CGSS),宏观数据主要来源于2010—2020 年《中国统计年鉴》和各省份统计年鉴,以及中国劳动、卫生、科技等方面的官方统计年鉴。
四、实证分析
(一)基于不平等厌恶系数的福利水平测度
1.优势不平等系数β 和劣势不平等系数α 的测算结果。采用准牛顿法(BFGS)和共轭梯度法(CG)对式(2)中的幸福感效用函数进行迭代优化,使得模型误差最小。将CGSS 数据代入幸福感效用函数式(2)中,并使用BFGS 算法和CG 算法对损失函数进行迭代优化,找到使得误差最小的参数。通过迭代,可以优化参数,使模型的拟合程度不断提高,从而获得更准确的预测结果。基于五期CGSS 数据测算得到优势不平等系数β 和劣势不平等系数α,如表2 所示,模型系数均显著,且两种算法结果具有一致性。

表2 不平等厌恶系数的测算结果
不平等厌恶系数是社会福利水平测度的重要依据,整体上优势不平等厌恶系数略微大于劣势不平等厌恶系数,两者在2012—2020 年保持稳定,说明中国社会经济结构较为稳定。
2.类五折交叉验证。为充分利用样本数据信息,提高测度的准确性,在此借助交叉验证思想,采用机器学习算法对测度结果进行分析,验证数据使用的合理性和结果的准确性。研究发现,同一期CGSS 数据经问题筛选出的两组测算数据,其性别比例和人口年龄结构一致,但教育结构差异较大。根据CGSS问卷问题“a7a:您目前的最高教育程度是?”进行筛选,学历为技校及以下的定义特征为“非高等教育”,反之定义特征为“受高等教育”。表3 按照教育水平分组的测度结果表明,受高等教育样本在测度优势不平等厌恶系数中比例更高,非高等教育样本在测度劣势不平等厌恶系数中比例更高。
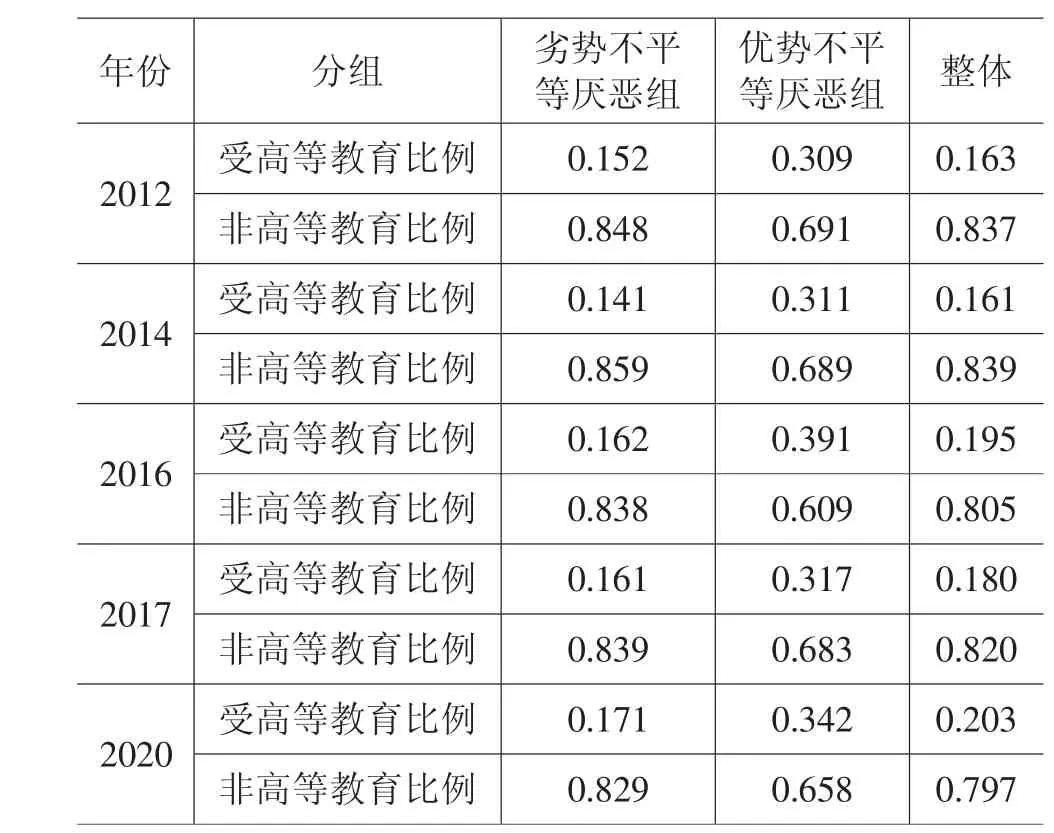
表3 按教育水平分组的样本比例
根据机器学习中的交叉验证方法,对两组数据分别进行抽样,以两组数据全样本中的受高等教育与非高等教育的比例调整样本数据结构。每次按全样本比例抽取该组总数一半的样本测度不平等厌恶系数,进行五折交叉验证,从而遍历样本数据不损失信息。根据Rawls(1971)[36]的“无知之幕”理论,全部个体的不平等厌恶系数一致。经分层抽样的类五折交叉验证后发现,分两组抽样后五次结果的均值基本一致,其中2014 年、2020 年劣势不平等厌恶组为0.92,优势不平等厌恶组为0.93。
3.基于不平等厌恶系数的福利水平测度结果。考虑到2010—2020 年时间跨度较大,个人获得的收入和所处的生活环境会发生较大变化,不同年份下等值的收入和消费支出变化也不同,因此未对不同年份数据进行合并以测算综合的不平等厌恶系数。具体而言,分年度测度的不平等厌恶系数取值如表4 所示。
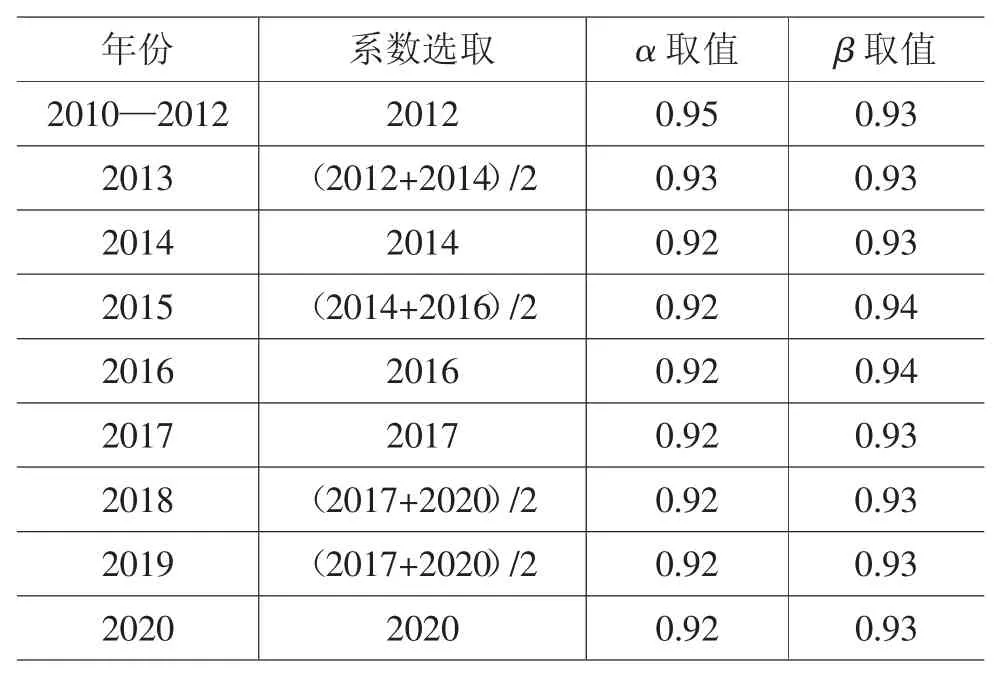
表4 2010—2020 年分年度不平等厌恶系数取值
将表4 结果代入式(5)计算2010—2020 年各省份社会福利水平及其均值,生成社会福利水平条形图,图1 呈现由东到西社会福利水平逐渐下降的趋势。根据图1 显示的趋势特征,结合我国不同地区经济发展的特点,将31 个省、自治区和直辖市划分为高、中、低三个地带,高水平地带包括北京、天津、河北、辽宁、上海、江苏、浙江、福建、山东、广州、海南,中等水平地带包括山西、吉林、黑龙江、安徽、江西、河南、湖北、湖南,低水平地带包括内蒙古、广西、重庆、四川、贵州、云南、陕西、甘肃、青海、宁夏、新疆、西藏。
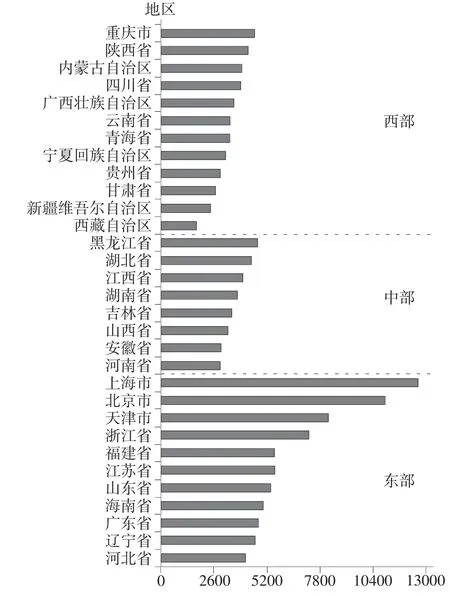
图1 2010—2020 年各省平均福利水平
4.社会福利水平的特征。根据不平等厌恶系数测算的社会福利水平,绘制2010—2020 年间各省份城镇居民社会福利水平、农村居民社会福利水平、域乡福利水平差距、综合社会福利水平箱线图,如图2所示。居民社会福利水平方面,城镇地区明显高于农村地区,且地区间城镇居民社会福利水平差异大于农村地区。分区域来看,东部地区居民福利水平分布最为分散,显示社会福利水平差异高于其他地区。整体来看,城镇居民社会福利水平与农村居民社会福利水平皆表现为由东部至西部逐渐降低的趋势,这与陈明华等(2020)[41]的研究结论一致。就整体社会福利水平而言,东部地区高于中西部地区,但高社会福利水平同时伴随着较大的城乡差异。城乡福利水平差距为负数意味着农村福利水平高于城镇福利水平,即农村高福利水平这一现象更高频率地发生在东部地区。这一测度结果在刻画地区福利水平差异的基础上,进一步反映出福利的不平等。
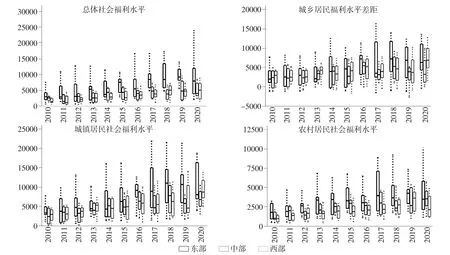
图2 2010—2020 年各类福利水平箱线图
2010—2020 年各维度皆呈现逐步增长的趋势,城镇居民社会福利水平增长速度高于农村居民。张文彬和王赟(2021)[31]认为2007—2017 年福利水平两极分化的极值逐渐弱化。与之不同的是,本文构建的测度方法能更好地拆解城乡福利差距,克服数据信息“被平均”的问题。实际上,2010—2020 年城镇和农村社会福利水平两极分化的极值逐渐强化,且无论在地区间还是地区内,逐步提高的福利水平往往意味着逐步扩大的福利差距。
(二)效度检验
为检验基于CGSS 微观调查数据测度的社会福利水平指数是否能够全面真实地反映居民社会福利水平,这里参考李胜会和邓思颖(2020)[40]的研究,根据宏观经济数据构建的指标体系,采用熵值法从经济环境、文化教育、就业和社会保障、医疗卫生、生态环境五个层面构建社会福利水平综合指标体系(简称“参照指标”)。
对参照指标与社会福利水平指标以及子指标进行冗余分析,⑧子指标对综合评价指标的贡献度显示,其对参照指标与社会福利水平指标均有较好的解释力度。各个子指标对参照指标和社会福利水平指标的贡献度较大且一致,其中经济环境贡献度最高,之后依次为就业和社会保障、文化教育、医疗卫生和生态环境,进一步说明基于不平等厌恶系数和基尼系数构建的综合评价指标具有较好的信度。总体来看,冗余分析结果显示社会福利水平受经济环境指标影响最大,即社会福利水平与当地经济水平高度相关。整体上城镇的居民福利水平高于农村,且城镇区域之间的福利差异高于农村区域之间,东部地区总体社会福利水平显著高于中西部地区。
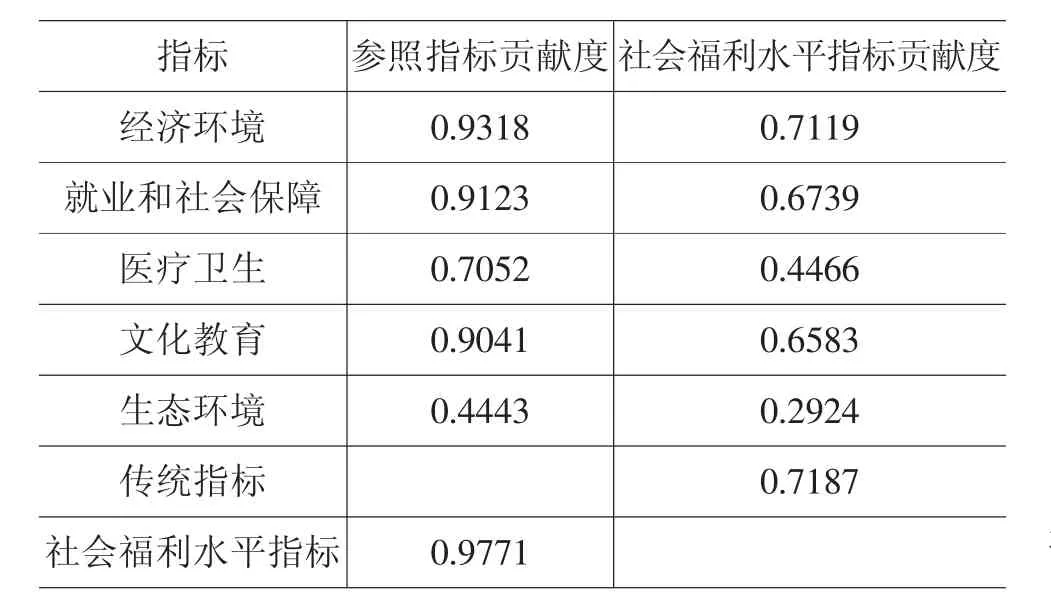
表5 冗余分析
(三)挖掘过程与结果分析
1.整体福利水平特征挖掘。社会福利水平特征分析涵盖福利水平子指标、区域特征、城乡特征等,关联规则能实现大量特征间的全面挖掘。因此初步对整体福利水平特征进行分析,利用熵值法得到的传统指标及其子指标结果为连续型数值,将其经Kmeans 聚类离散化后的结果划分为高、中、低三个水平,对样本数据进行特征挖掘,结果如图3 所示。经济环境子指标与其他指标存在明显差异,近74%的样本处于经济环境为中等的区域,处于高水平区域及低水平区域的样本相对较少。
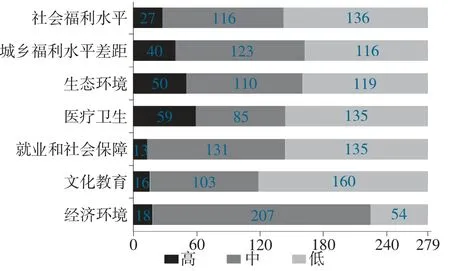
图3 K-means 离散化的福利特征
挖掘前10 条具有最高提升度的规则, 从前10 条规则和K-means 聚类结果可以得出:(1)多数地区的经济环境为中等水平;(2)西部地区的经济环境普遍为中等水平,农村居民福利水平较低;(3)整体呈现马太效应,中等经济环境伴随着中等及以下水平的医疗保健和文化教育。受子指标高水平少的特征影响,这一挖掘结果与频繁项集高度相关。

表6 三水平-关联规则
2.高福利水平特征挖掘。为进一步探索高水平社会福利特征,这里使用K-means 算法将子指标划分为“高水平”和“非高水平”两类,计算分析得到6条关联规则,如表7 和图4 所示。规则1、2 出现“东部”“西部”两个特征,说明社会福利的地区特征明显。其中:规则1 置信度为0.78,说明西部地区在生态方面的社会福利较好;规则2 显示东部地区经济环境较好;规则3、4 说明高水平的城市福利往往伴随着较大的城乡福利水平差距,与图2 箱线图结果具有一致性。

表7 区域-福利关联分析
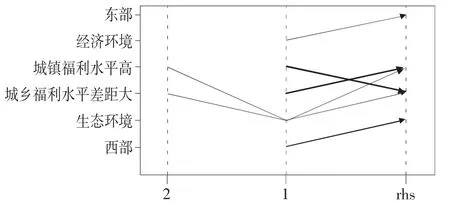
图4 关联规则的平行坐标图
(四)马太效应测度及探究
1.测算马太指数MI和马太系数MC。关联规则挖掘显示,2010—2020 年经济水平较高的东部地区福利水平也较高,整体呈现马太效应。刘煜和刘跃军(2021)[30]从空间关联视角出发,发现生态福利绩效网络中心集中在东部沿海地区,形成显著的马太效应。张和平等(2021)[39]研究表明,科技、经济和教育领域均存在一定程度的马太效应。在关联规则的基础上,测度马太指数、马太系数以量化社会福利水平的马太效应。
表8 结果表明,全体居民社会福利水平与农村居民社会福利水平测度的马太效应变动趋势基本一致,其中全样本数据的变异系数较大。随着时间的推移,序位波动系数没有较大变化。2010—2020 年期间,不论是离散系数、马太系数,还是马太指数,均呈现均值波动,且一直处于较高位置。

表8 2010—2020 社会福利水平的马太效应
全体居民福利水平、农村居民福利水平、城镇居民福利水平均存在不同程度的马太效应。城镇居民福利水平的马太系数小于农村地区居民和全体居民。农村居民福利水平的波动显著小于其他两个水平,表明虽然短期内可能有少数农村居民由低福利水平过渡到高福利水平(或者由高福利水平下降至低福利水平),但是在样本区间福利水平的跨阶层移动可能性较小。相对于城镇居民而言,农村居民从低福利水平向高福利水平转移的可能性更小。
2.Oaxaca-blinder 分解。社会福利的马太效应是加剧还是减弱了区域之间福利水平的不平等?对基于不平等厌恶系数构建的福利水平测度结果与基于熵值法所得的福利水平测度结果进行Oaxacablinder 分解。结合Kmeans-Apriori 算法,将样本划分为东部和非东部两个区域。考虑熵值法结果的特殊性,对其乘以10 处理。表9 结果表明,东部地区和中西部地区福利水平均值的差值随时间逐步扩大,表明马太效应作用加强,福利水平较高的地区在经济发展中获得的福利更多。

表9 2012—2020 年Oaxaca-blinder 分解差值
表10 显示东部地区和非东部地区的均值差异为-3 521.593,其中,-3 176.652 9 来自经济环境、就业和社会保障、医疗卫生、文化教育、生态环境的水平差异,-2 163.839 8 归因于系数的差异,即纵使非东部地区各领域建设达到了东部地区的水平,也仍然无法达到东部地区的总体福利水平,因此认为东部地区和非东部地区间存在“福利鸿沟”。

表10 2012—2020 年Oaxaca-blinder 分解系数
五、结论与启示
本文综合利用CGSS 微观数据和宏观经济统计数据,借助不平等厌恶系数对2010—2020 年社会福利水平进行测度,得到了四点主要结论。第一,在2010—2020 年共计5 期的不平等厌恶系数中,劣势不平等厌恶系数α 均值为0.92,优势不平等厌恶系数β 均值为0.93。第二,社会福利水平与经济水平高度相关,且存在马太效应,经济环境较好的地区拥有的医疗保健和文化教育等公共服务资源也较好。社会福利存在地区不平等、城乡不平等,呈现“东部>中部>西部、城镇>农村”的特点,且随着福利水平升高,城乡福利水平差距逐渐增大。不同于其他社会福利,西部地区的生态环境福利较好。第三,马太指数、马太系数皆呈现围绕均值波动的趋势,表明城乡居民从低水平福利向高水平福利转移比较困难。第四,Oaxaca-Blinder 分解结果表明,东部和中西部地区的回报系数不同,促使地区间产生了“福利鸿沟”。
本文主要的政策启示是:首先,农村居民福利水平相对城镇居民而言有更大的提升空间,改善全社会福利水平、促进共同富裕,首要的是改善农村居民福利水平;其次,改善马太效应,降低公共服务的地区差距和城乡差距,减少城乡之间和区域之间的“福利鸿沟”;最后,大力支持中西部落后地区的经济发展与社会福利建设,通过经济发展解决区域之间的福利差异问题。
注释:
①参考田卫民(2012)[42]的方法测算基尼系数。
②马太系数综合考虑了离散性和稳定性两个方面。
③Oaxaca-blinder 分解是一种经济学方法(Hlavac and Marek,2014)[43],用于解释个群体之间的平均差异,并将这些差异分解为两个主要成分,即解释性因素和不可解释性因素(系数差异)。该方法通常应用于性别、种族或其他群体之间的工资差异研究中。
④由城镇人口占总人口的比重衡量。
⑤根据“小学人口×6+初中人口×9+高中人口×12+大学专科人口×15+大学本科人口×16+研究生人口×19)/6 岁及以上人口”测算。
⑥由“大学专科人口+大学本科人口+研究生人口)/6 岁及以上人口”衡量。
⑦由“城乡居民社会养老保险实际领取待遇人数/年末常住人口”衡量,C8 至C12、C14 至C17 同理。
⑧冗余分析(Redundancy analysis,简称为RDA 分析)用于测度典型变量分析过程中每组变量提取的典型变量所能解释的该组样本总方差的比例,即测度典型变量包含原始变量信息的多少(朱建平,2021)[44]。
