边缘场景下动态联邦学习优化方法
2024-02-21王志良俞文心
王志良,何 刚,2*,俞文心,许 康,文 军,刘 畅
(1.西南科技大学 计算机科学与技术学院,四川 绵阳 621010;2.国家卫生健康委核技术医学转化实验室(绵阳市中心医院),四川 绵阳 621010)
0 引 言
随着物联网和智慧城市等应用的快速发展,越来越多的设备(如传感器、摄像头和智能手机等)加入到无线网络中。然而,云计算已经无法满足海量边缘数据爆炸式增长[1-2]。为了解决这一问题,边缘计算[3]作为一种新的计算形式出现,通过在网络边缘的边缘端服务器上处理数据,避免了将数据发送到远程云端所需的长传播延迟。然而,由于通信资源和数据隐私安全等限制,将用户数据发送到云端的方法通常被认为不切实际。因此,Google提出了一种分布式的机器学习方法,称为联邦学习(Federated Learning,FL)[4-5]。在传统的集中式机器学习模型中,通信成本相对较小,计算成本占主导地位。然而,在联邦学习中,通信成本占主体地位。综合以往的研究,可以总结出以下三个挑战:
(1)通信问题:服务器与客户端之间的网络连接相对较慢。
(2)设备异构:不同参与者的计算资源可能不同。
(3)数据不均衡:不同客户端之间的数据分布不一致[6]。
为了解决通信问题,已有研究者提出了模型压缩和模型蒸馏来降低链路通信成本[7-8]。许多文献着重于处理数据特征分布不均衡,以减少通信回合来提高联邦学习的测试准确率[9-11],但每个回合的计算时间也很重要。针对数据类别不平衡,可以修改训练数据或调整学习策略[12]。而样本总数在参与者之间分布不均衡会影响每回合联邦学习的时间消耗。
该文重点解决每回合时间消耗大导致整体训练效率低的问题。联邦学习中,每回合的时间消耗由耗时最长的参与者决定,而参与者的时间消耗差异通常由设备异构和数据不均衡引起。已有国内外研究关注如何缩短每回合的通信时间,其中基于博弈论的优化研究较多[13-15]。Sarikaya等人[15]基于斯塔克伯格博弈模型提出了一项研究,在预算有限的情况下,通过权衡参与者多样性和完成训练的延迟来选择参与者。然而,这种选择方式使得某些参与者无法参与联邦学习,不公平。贾云健[16]提出了一种基于博弈论的激励机制,在分层联邦学习框架下考虑了连接终端设备数量差异。该机制设计了两层主从博弈,分配激励预算,刺激终端设备更积极参与联邦学习任务,减小“掉队效应”,最小化全局模型训练时间。然而,仍存在不公平行为和某些参与者需要贡献更多计算资源的问题。
综上所述,设计一种方法以充分考虑每回合中参与者的设备异构和数据不均衡,缩短每回合时间消耗并确保公平性变得重要。为此,该文提出了FlexFL算法,旨在缩短联邦学习每回合的时间消耗。主要贡献如下:
(1)引入联邦学习训练服务动态缩放策略,通过两层联邦学习架构,在同一参与者上部署多个联邦学习训练服务和一个联邦学习聚合服务。通过动态缩放服务,加快计算速度。
(2)提出FlexFL算法,将本地数据集平均分配给各联邦学习训练服务,并每回合激活一定数量的训练服务。未激活的服务休眠,不占用计算资源,并将计算资源平均分配给激活的服务,加快训练速度。
通过以上贡献,FlexFL算法能有效解决参与者设备异构和数据不均衡导致的训练时间差异问题,提高整体训练效率。
1 相关工作
1.1 服务动态缩放
服务动态缩放常常在互联网高并发架构中使用,其本质是通过合理配置资源以及增加或缩减服务来提高服务吞吐量和降低服务延迟[17-19]。目前,尚未有研究者考虑将服务动态缩放与联邦学习相结合。该文旨在将服务动态缩放与联邦学习相结合,以平衡每回合参与者在设备异构和数据不均衡性带来的时间消耗差异。
1.2 联邦学习算法
时间消耗的优化一直是FL的主要研究方向之一。McMahan等人[20]提出了一种名为FedAvg(Federated Averaging)的联邦学习算法,该算法通过对各参与方的局部模型进行平均来更新全局模型,并通过增加聚合期间局部模型的训练次数来减少通信开销。然而,该算法忽略了减少每回合时间消耗的问题。
田有亮[21]提出了一种基于激励机制的联邦学习优化算法,利用博弈论和拍卖理论设计了拍卖机制。参与者通过向雾节点拍卖本地训练任务,并委托高性能雾节点训练本地数据,以提升本地训练效率并解决客户端间性能不均衡的问题。然而,这种方案破坏了联邦学习的隐私性,因为本地数据被发送到其他节点。程帆[22]提出了一种基于动态权重的联邦学习优化方法。在极端情况下,计算时间消耗较大的参与者可以选择不参与聚合。尽管这种方案可以减少每回合的时间消耗,但对于部分计算时间消耗较大的参与者来说存在不公平性的问题。现有的研究常常通过剔除训练延迟大的参与者来提高效率,但这对某些参与者不公平。为解决这个问题,该文提出了FlexFL算法,能够平衡参与者设备异构和数据不均衡性对训练时间的影响,提高整体训练效率。实验结果表明,FlexFL算法在减少时间消耗的同时,不降低模型性能。
2 动态联邦学习优化方法
在本章中,首先提出了联邦学习训练服务动态缩放策略,并引入了两层联邦学习架构来实现该策略。随后,基于联邦学习训练服务动态策略,提出了FlexFL算法,旨在降低联邦学习每回合的时间消耗。
使用的符号解释如表1所示。
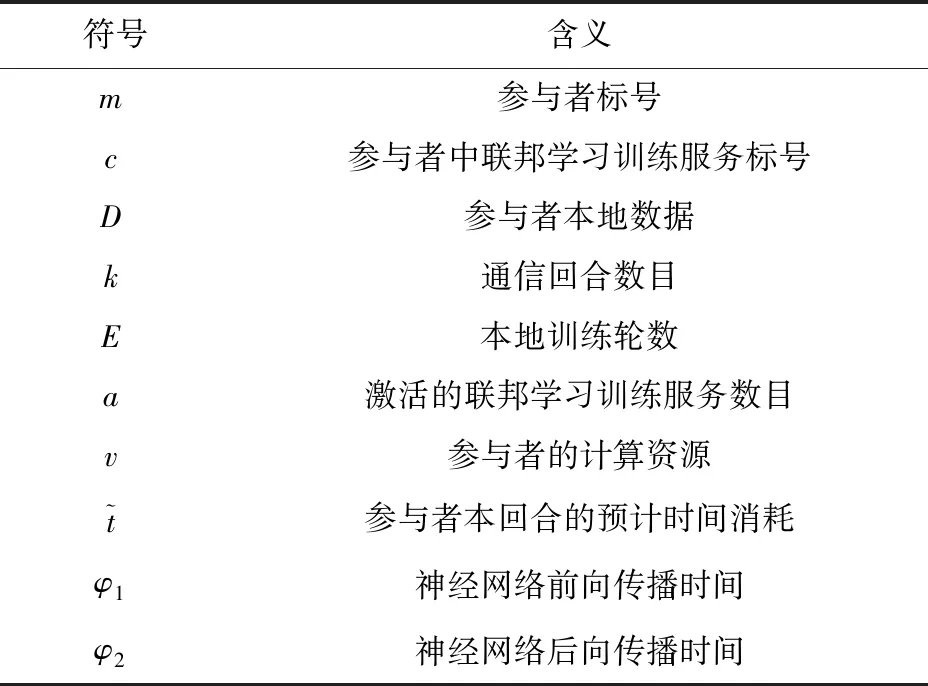
表1 符号解释
2.1 联邦学习训练服务动态缩放策略
针对联邦学习中每回合不同参与者由于时间消耗不同而导致全局模型聚合时间长,从而影响整体联邦学习训练效率的问题,重点考虑设备异构和数据不均衡这两个因素,因为它们在实际环境中是主要影响参与者时间消耗的因素。基于实际环境的考虑,提出以下设定:
设定一:参与者的设备异构主要通过模拟计算资源的不同来实现,而数据不均衡主要通过模拟数据分布的不均衡来实现。
设定二:参与者在训练开始之前能够收集到自身的数据量和计算资源的情况,并且对中央服务器具有信任,能够将这些信息上传至中央服务器。
设定三:参与者的数据量不均衡,并且在联邦学习过程中不再发生变化,即不会增加或减少本地数据量。
设定四:参与者的计算资源因复杂的环境而处于动态变化中,例如参与了其他计算任务,占用了计算资源。
基于以上设定,并结合服务动态缩放的思想[17],提出了联邦学习训练服务动态缩放策略。该策略在每个参与者上部署了多个联邦学习训练服务和一个联邦学习模型聚合服务。首先,将参与者的本地数据平均划分给对应的联邦学习训练服务进行训练,得到本地模型。然后,参与者的模型聚合服务将本地模型聚合后上传到中央服务器进行进一步的模型聚合。中央服务器完成模型聚合后,将更新后的模型发送回参与者的联邦学习训练服务,进行下一回合的训练。在每回合训练中,根据参与者计算资源的变化,随机选择激活参与者部署的联邦学习训练服务参与下一轮的训练,未被选中的服务将休眠并释放计算资源,而被选中的服务将获得分配的计算资源,从而加快计算速度。图1展示了该策略的结构。
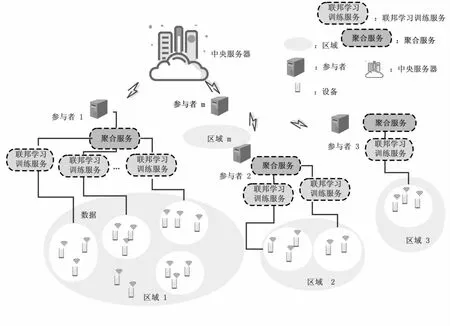
图1 联邦学习训练服务动态缩放策略
如图1所示,m个参与者在一个中央服务器的协助下共同训练一个全局模型。在该设定中,参与者的本地数据是非独立同分布(Non-IID)且不均衡的,这符合大多数真实场景的情况。参与者的本地数据用集合{D1,D2,…,Dm}表示,参与者的联邦学习训练服务数目cm为:
(1)
然后,参与者m将本地数据集随机平均划分成cm份,对应cm个联邦学习训练服务。接着,每回合重复以下步骤直至模型收敛。
(2)
步骤二:确定参与者选择激活的参与者的数目为:
(3)
步骤三:随机激活a个联邦学习训练服务,并将计算资源平均分配给这些激活的联邦学习训练服务,使其参与本回合的计算。未被激活的服务不进行计算,不占用计算资源。
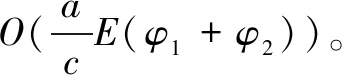
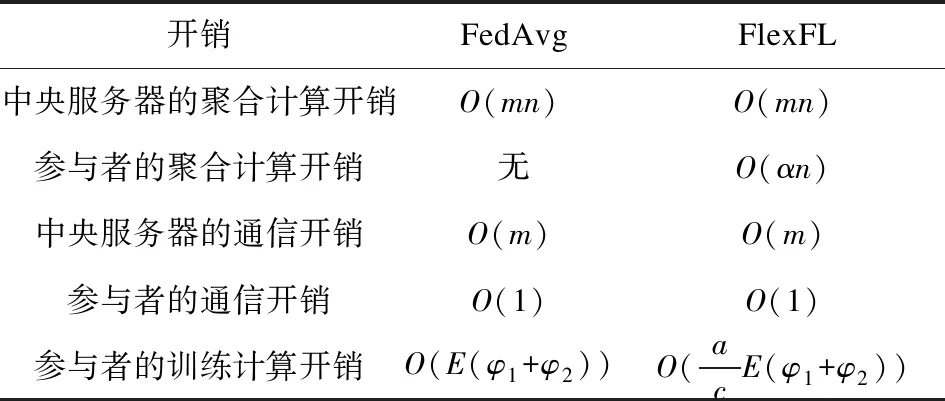
表2 通信开销和计算开销
2.2 动态联邦学习训练算法FlexFL
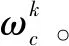
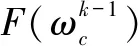
(4)
(5)
其中,∇F是损失函数,g是梯度,ω表示回合k中的模型参数,μ表示学习率,c是联邦学习训练服务标号。
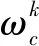
(6)
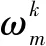
(7)
如图2所示,在开始训练之前,参与者需进行本地数据划分以对应联邦学习训练服务。中央服务器需要进行一些初始化工作,包括选择算法,超参数,初始化全局模型等,然后重复下述步骤直至模型收敛。
第1步:训练开始,中央服务器下发本轮全局模型给参与者。
第2步:参与者接收到中央服务器的全局模型ωk-1,并将其发送给联邦学习训练服务。

第6步:参与者将其本地模型发送到中央服务器。
第7步:中央服务器收到所有本轮参与训练的参与者的本地模型后,聚合更新后得到全局模型ωk。
第8步:返回第1步,直至模型收敛。
3 实验结果及分析
3.1 数据集与模型
为了验证提出的FlexFL算法的性能,设计了一个由200个参与者和1个中央服务器组成的网络。每个回合中央服务器随机选择20%的参与者参与训练。
在深度学习中使用了两个常见的基准数据集来实现算法。第一个数据集是MNIST手写数字识别,包含60 000个训练样本和10 000个测试样本。每张图片代表0到9中的一个数字,位于中央。为了每个参与者被随机分配训练样本,并且反映出联邦学习数据非独立同分布的特点,数据集划分采用了非平衡方式,首先按数字标签进行随机打乱,然后分为3 000个分片,每个分片包含20张数据。这种划分方式确保可以通过控制分片数目来控制样本数量差距。第二个数据集是CIFAR-10,包含50 000个训练样本和10 000个测试样本,共有10个类别。每个类别包含6 000个32×32像素点的彩色图像。CIFAR-10将识别任务迁移到普适物体,具有大量噪声和不同比例的物体识别,因此对图像识别更具挑战性。数据集的划分方式与MNIST类似,采用了非平衡划分。该文使用全连接神经网络(也称为多层感知机)进行训练。
3.2 实验设置
FlexFL算法是基于Pytorch 的客户端/服务器端联邦学习架构框架实现。该文主要考虑由于设备异构和数据不均衡的影响,为了排除参与者和中央服务器中之间网络通信时间的影响,实验中的中央服务器的聚合和客户端的本地训练都在同一台具有NVIDIA1080Ti的机器上进行。实验相关参数设置如下:本地训练中,学习率为0.01,batch设置为50,epoch设置为5。设备的异构性通过给予设备不同的计算资源来模拟,并在每一回合随机、动态地更新不同参与者的计算资源。数据的不均衡通过设置不同的环境来实现:
环境A:随机选取5%的参与者平均分得50%的数据。其余参与者平均分得50%的数据。
环境B:随机选取10%的参与者平均分得50%的数据。其余参与者平均分得50%的数据。
环境C:随机选取30%的参与者平均分得50%的数据。其余参与者平均分得50%的数据。
3.3 性能比较和结果分析
(1)准确率上升速率。
为了对FlexFL算法的性能有直观的认识,图3比较了两种算法在不同环境设置下的性能表现。可以观察到,在通信初始阶段,FedAvg以较少回合达到了同样的准确率,这是因为,当数据分布不均衡、参与者计算资源随机变化的时候,FedAvg在通信初期,每回合能够有较多的数据参与训练,所以准确率上升较快。而FlexFL对本地数据进行划分,对联邦学习训练服务随机激活,每次参与训练的数据比FedAvg少。当通信回合大于150的时候,FlexFL以较少的通信回合达到同样的准确率,并且在相同的通信回合中,其准确率优于FedAvg。这证明了FlexFL相较于FedAvg性能并没有降低。
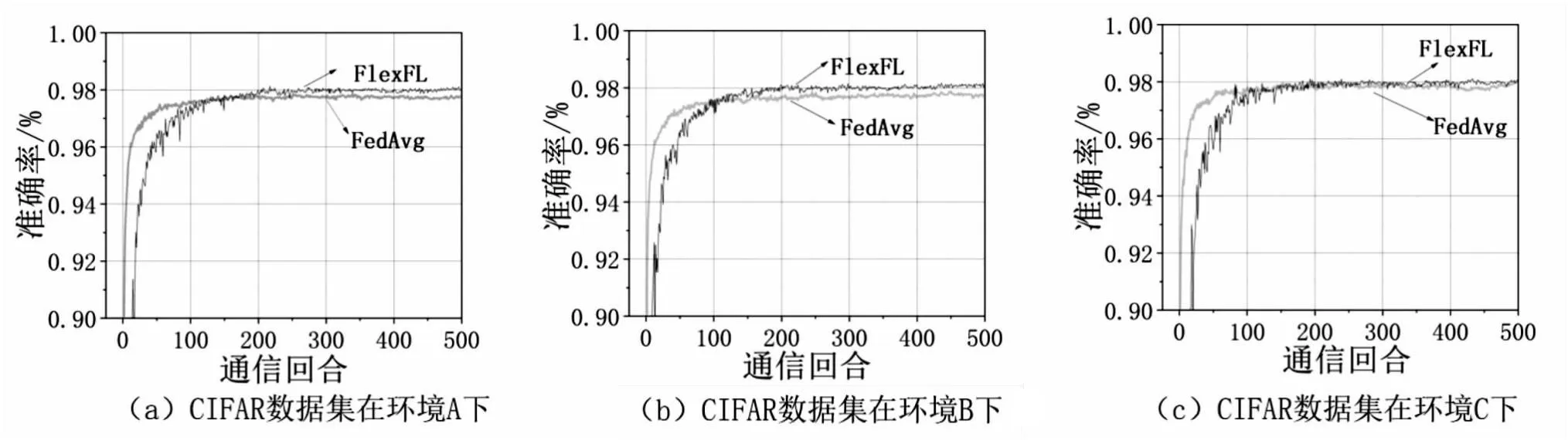
图3 不同设置下测试集准确率和通信回合的关系
(2)平均时间消耗。
时间消耗在评价联邦学习算法的性能上也是一个重要指标。如图4所示,FlexFL算法无论是准确率还是最后收敛时间都优于FedAvg算法。

图4 不同设置下测试集准确率和时间消耗的关系
表3列出了不同环境设置下(对应图4中(a)~(f))使用两种算法达到目标准确率97.5%所需要的通信回合,平均每回合所需时间和总的时间消耗。在表3中几组实验均显示,FlexFL的每回合平均时间消耗和达到目标准确率总的时间消耗均比FedAvg的低。
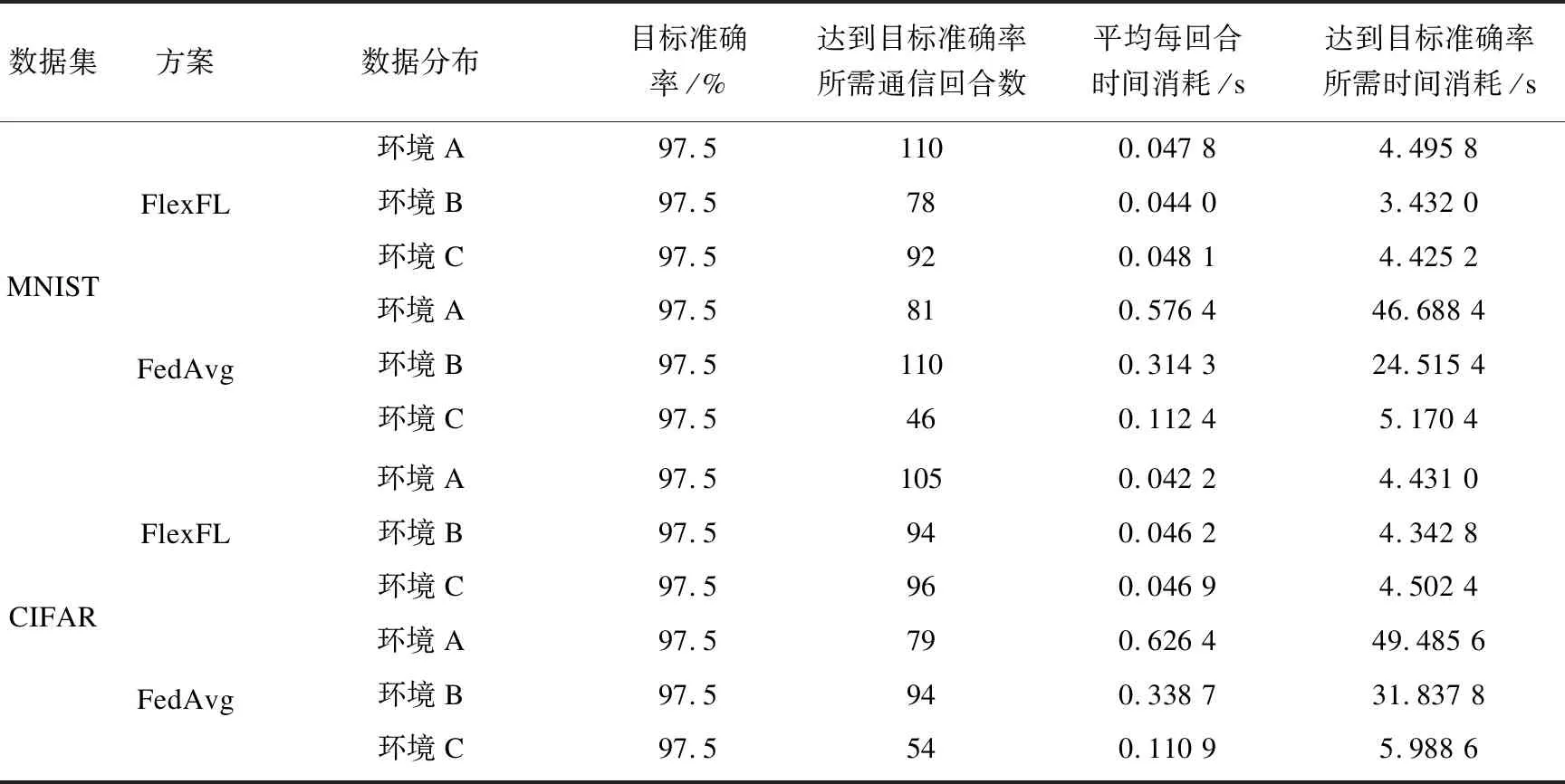
表3 不同环境下FlexFL算法与联邦学习算法FedAvg在测试集上的表现对比
由表4显示,所提算法在不同环境下,用MNIST数据集测试,分别将训练时间消耗降低了90.37%,96.00%和14.41%。用CIFAR数据集测试,分别将训练时间消耗降低了91.04%,86.35%和24.82%。这证实了在参与者数据分布不平衡、计算资源动态变化的时候,FlexFL具有较低的时间消耗。

表4 不同环境下FlexFL达到目标准确率(97.5%)以FedAvg为基准的时间消耗减少率
值得说明的是,当数据分布均衡的时候,FlexFL算法对本地数据不进行划分,参与者仅仅部署一个联邦学习服务,这本质上与FedAvg算法没有区别。
4 结束语
提出了一种基于动态缩放策略的联邦学习算法FlexFL,旨在减少联邦学习每回合的时间消耗。该算法引入了两层联邦学习架构,通过将本地数据进行划分,并对应部署联邦学习训练服务,结合每轮参与者的计算资源变化,对部署在该参与者的联邦学习训练服务进行动态激活,使得参与者的每回合的时间消耗减少。实验结果表明,与联邦学习算法FedAvg相比,该算法有效降低了联邦学习的训练时间消耗。不足之处在于,需要在参与者部署多个联邦学习训练服务和一个聚合服务,这会带来一些额外的资源消耗;FlexFL每一回合都需要对联邦学习服务进行动态激活,在复杂实际环境中,可能会有部分激活失败的情况。
在接下来的工作中,将对该算法进行改进。例如,在联邦学习训练服务进行缩放和本地数据集进行划分的时候不够细致,可能并没有达到最好的效果。其次,在中央服务器选择参与者的过程中采取的随机的方式,这可以结合其他研究进行优化。
