基于LSTM-SAFCN 模型的生物质锅炉NOx 排放浓度预测①
2024-02-13何德峰刘明裕孙芷菲王秀丽李廉明
何德峰 刘明裕 孙芷菲 王秀丽③ 李廉明
(∗浙江工业大学信息工程学院 杭州310023)
(∗∗嘉兴新嘉爱斯热电有限公司 嘉兴314016)
构建清洁低碳、安全高效的能源体系是我国实现碳中和目标的关键举措。与化石能源相比,使用生物质燃烧发电是一种更经济环保的选择[1-2]。生物质能的燃烧过程是一个碳闭环过程,生物质通过光合作用吸收的CO2能够中和生物质燃烧产生的CO2,从而很好地实现碳中和。然而,生物质燃烧过程产生的烟气仍包含大量其他污染物,其中氮氧化物(NOx)是占比最大的一种污染物[3-4],过量的NOx排放会导致酸雨、光化学烟雾、臭氧层破坏和温室效应等严重的环境问题[5-8]。因此,准确预测NOx 排放浓度是实现生物质锅炉燃烧过程有效监测的关键步骤,同时也为燃烧过程优化、节能减排提供重要的科学参考依据。
由于生物质锅炉运行机理复杂,生物质燃烧过程具有高度非线性、强耦合的特点,导致NOx 排放浓度受多种复杂因素影响。生物质燃烧机理分析方法因为具有强大的可解释性,常用来预测NOx 排放浓度,但该方法建模难度大、计算复杂度高,用于预测NOx 排放浓度成本较高[9-12]。近年来,数据驱动的方法在预测领域逐渐流行,特别是,人工神经网络(artificial neural network,ANN)作为一种通用函数逼近器已率先用来预测NOx 排放浓度[13-14]。例如,周昊等人[15]利用ANN 预测大容量煤粉锅炉中的NOx 排放浓度;谷景丽等人[16]应用ANN 模型实现了NOx 浓度等参数的软测量。然而,ANN 只能建立从输入到输出的静态映射,不能很好地提取时间序列数据的动态特征。
受不同工况影响,生物质锅炉燃烧过程具有较强的动态特性,循环神经网络(recurrent neural network,RNN)在ANN 的基础上为处理时间序列数据而提出。RNN 以时间序列进行顺序输入,通过隐藏层实现递归输出。然而,受梯度消失和梯度爆炸问题的影响,RNN 并不能解决长距离依赖问题。于是长短期记忆(long short-term memory,LSTM)网络应运而生,并广泛应用于预测领域[17]。例如,Yang 等人[18]利用LSTM 网络建立燃煤锅炉的预测模型,用来预测NOx 排放浓度,实验结果充分表明LSTM 网络优于ANN。Xie 等人[19]基于LSTM 网络动态模拟并预测出选择性催化还原系统出口的NOx 排放浓度。
卷积神经网络(convolutional neural networks,CNN)具有强大的局部特征提取能力,能够广泛用于序列数据处理。Facebook AI 团队充分利用CNN 的并行优势实现了序列到序列的任务[20],然而,CNN网络结构的全连接层参数数量庞大容易导致计算效率低下。为了解决上述问题,Long 等人[21]将全连接层替换成卷积层,提出全卷积神经网络(fully convolutional networks,FCN)模型,该网络与其他类型的神经网络广泛结合可实现精良的实际应用效果。Karim 等人[22]将LSTM 网络与FCN 结合实现了多元时间序列分类。胡丹等人[23]进一步利用LSTMFCN 模型实现了船舶轨迹预测,得到了良好的预测结果。
然而,基于LSTM-FCN 构建的预测模型往往存在着因计算效率和信息利用率不高引起的预测精度有限的问题。为了进一步解决这一问题,本文在LSTM-FCN 框架中引入自注意力机制(self-attention,SA),提出基于长短期记忆-自注意力机制全卷积神经网络(long short-term memory-self attention fully convolutional network,LSTM-SAFCN) 的预测模型。自注意力机制可以有效减少对外部信息的依赖,更好地捕捉数据或特征之间的内部相关性,使得数据中的重要特征得以突出显现,从根本上起到提高预测精度的作用[24]。
基于上述问题,本研究首先根据完全自适应噪声集合经验模态分解[25](complete ensemble empirical mode decomposition with adaptive noise,CEEMDAN)方法对时间序列数据进行预处理,以消除数据中的噪声对预测精度的影响;然后,融合SA 与LSTM-FCN 方法,解决计算效率和信息利用率不高导致的预测精度低下问题;接着,将预处理后的数据用于训练LSTM-SAFCN 模型;最后,将训练好的模型应用于生物质流化床锅炉中来提高NOx 排放浓度的预测准确度。SA 引入FCN 而非LSTM 中是因为SA 是并行结构,LSTM 是串行结构,二者难以结合。将SA 与同是并行结构的FCN 结合,可弥补FCN 无法反映时间序列的时变特点、缺乏全局视野的缺陷。
1 生物质锅炉燃烧过程
本文研究对象为生物质循环流化床锅炉,其燃烧产生能量用于热电联产流程供电与供暖。如图1所示,生物质热电联产过程包括生物质储运、生物质燃烧、汽水循环、蒸汽发电、供汽供热、烟气处理和烟气排放等工艺环节。生物质燃料通常由专门的运输车运输至炉前仓进行储存,需使用时通过传送带运送至锅炉内进行燃烧,燃烧所需的一次风和二次风分别从炉膛的底部和侧墙送入,炉膛四周布置有水冷壁,用于吸收燃烧所产生的部分热量。由气流带出炉膛的大部分固体物料在分离器内被分离和收集,再次通过返料装置送回炉膛,进行多次循环燃烧。燃烧过程中产生的大量高温烟气流经由过热器、再热器、省煤器等处理后,大部分用于推动汽轮发电机供电,以及起到加热冷凝塔中冷水的作用,少部分用于供汽供暖。燃烧产生的高温烟气则进入除尘器进行除尘,最后由引风机排至烟囱进入大气。

图1 生物质循环流化床热电联产流程图
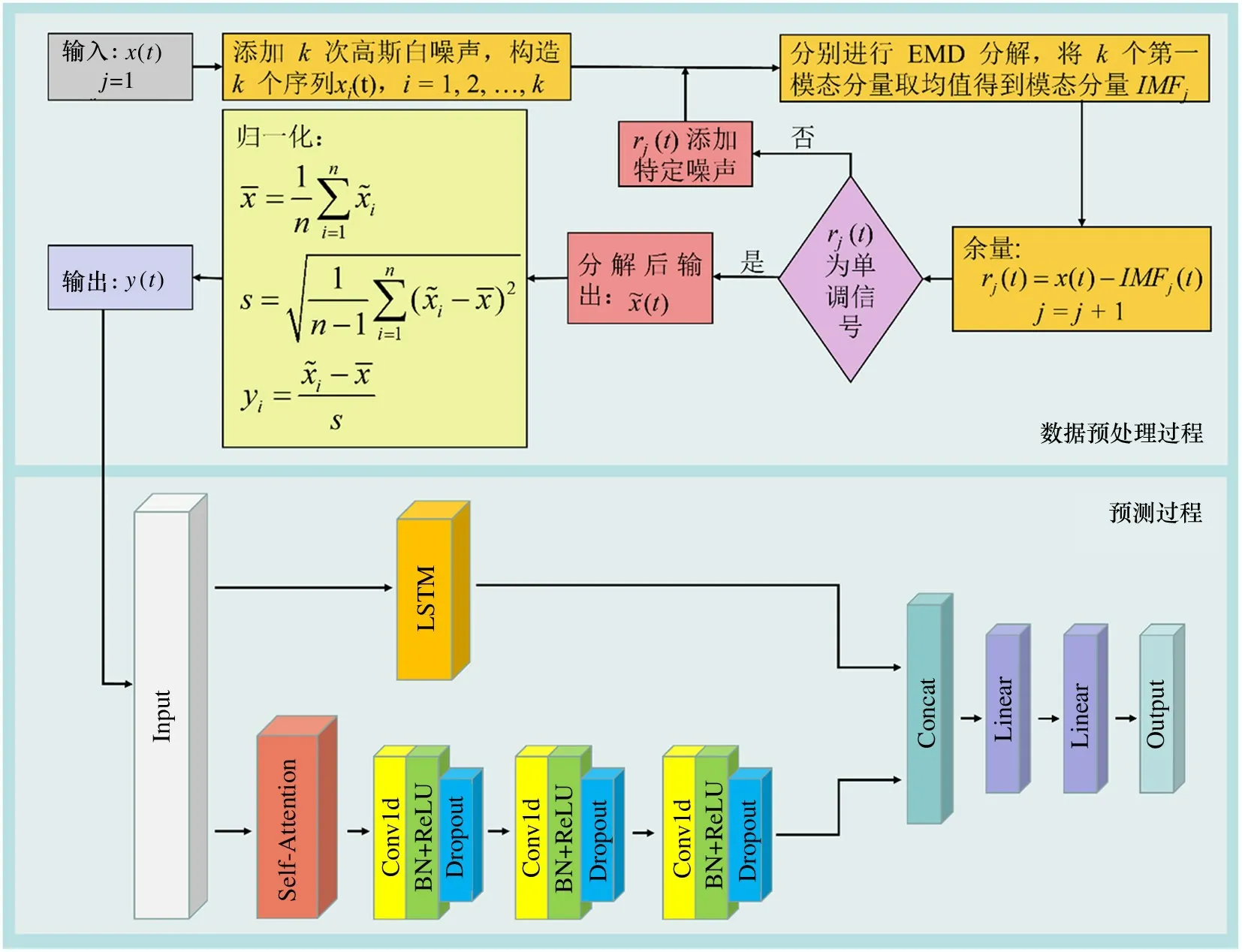
图2 LSTM-SAFCN 模型流程图
2 NOx 排放浓度预测
基于LSTM-SAFCN 方法实现NOx 浓度预测,其过程包括以下步骤。
(1)数据集获取:在循环流化床锅炉中进行燃烧实验,通过传感器获取数据集,并将数据集划分为训练集和测试集。
(2)数据预处理:对传感器获得的数据集进行预处理,利用CEEMDAN 消除原始数据中的噪声干扰,并对数据进行归一化。
(3)LSTM-SAFCN 模型训练:融合SA 与LSTMSAFCN 建立NOx 排放浓度预测模型,利用训练集对其进行训练。
(4)NOx 排放浓度预测:利用训练好的LSTMSAFCN 模型,基于测试集预测NOx 排放浓度。
2.1 数据预处理
锅炉实际运行过程复杂,传感器采集的数据蕴含噪声数据,传统的数据预处理方法本质上从数据拟合的角度抑制噪声,实际上没有去除噪声,这也直接影响了预测结果的精度。本文利用改进的经验模态分解方法——CEEMDAN 去除数据中的噪声,同时解决传统经验模态分解方法的模态混叠现象,保证了数据的平稳性和有效性,为精准预测NOx 排放浓度提供有力的数据保障。
CEEMDAN 在经验模态分解法的基础上从以下2 个方面进行改进:(1)摒弃将高斯白噪声信号直接添加在原始信号中的方案;(2)CEEMDAN 在得到的第一阶IMF 分量后进行总体平均计算,得到第一阶IMF 分量。CEEMDAN 算法的主要步骤如下。
(1)在初始时间序列信号x(t) 中添加k次均值为0 的高斯白噪声,共构造k个添加了高斯白噪声的时间序列,具体如式(1)所示。
其中,xi(t) 表示第i次加入高斯白噪声的时间序列;ε表示高斯白噪声权值系数;δi(t) 为第i次所添加的高斯白噪声。
(2)对初始时间序列x(t) 进行经验模态分解(empirical mode decomposition,EMD)分解,得到k个模态分量(intrinsic mode functions,IMF),取其均值作为CEEMDAN 的第1 个IMF,具体如式(2)所示
其中,表示第i个时间序列进行EMD 分解得到的第1 个IMF;IMF1表示CEEMDAN 分解得到的第1 个IMF。
(3)初始时间序列x(t) 减去CEEMDAN 分解得到的第1 个IMF,定义为时间序列余量,计算公式如式(3)所示:
其中,r1(t) 表示原始信号相对第1 个IMF 的余量。
(4)重复上述步骤,得到其他IMF 分量,具体公式如式(4)、(5)所示:
式中,Ej(·) 表示利用EMD 分解得到的第j个IMF分量;rj-1表示第(j-1)个余量,由式(5)计算得到;εj-1表示第(j -1) 次的高斯白噪声对应的权值系数。
(5)当满足EMD 停止条件,即第n次分解的余量信号rn(t) 为单调信号,则迭代停止,CEEMDAN算法结束。
锅炉燃烧过程的各种运行参数拥有不同属性的数据取值范围,为了消除量纲对NOx 排放浓度的影响,对数据进行归一化处理。本文使用Z-score 标准化对数据进行归一化,计算公式如下:
其中,xi表示变量的原始测量值,n表示数据采集次数,¯x表示n次采样均值,s是对应的标准差,yi表示归一化后的变量值。归一化后的数据yi一般服从均值为0、标准差为1 的正态分布。
2.2 LSTM-SAFCN 预测模型
LSTM-FCN 方法在处理时间序列预测问题时,由于不能兼顾时间序列数据的局部细节与长期趋势特征,预测精度有限。因此,本文将LSTM-FCN 与SA 结合提出改进的LSTM-SAFCN 方法,以提高NOx排放浓度预测精度。改进的LSTM-SAFCN 模型预测结构如图3 所示,主要包括LSTM 模块、Self-Attention 模块和FCN 模块。LSTM 模块解决了传统循环网络无法处理较长序列数据信息的弊病;FCN 模块可以进一步减少参数数量,且更好地实现对局部信息的提取;Self-Attention 模块对数据进行全局关联和时间关联,使得数据中的重要特征得以突出显现,从根本上起到提高预测精度的作用。

图3 LSTM-SAFCN 模型结构图
利用LSTM-SAFCN 预测NOx 排放浓度时,首先将预处理后的数据同时输入LSTM 模块和SAFCN模块分别提取特征,然后,融合2 个特征输入线性层进行NOx 排放浓度预测。
LSTM 是一种门控神经网络,利用门控机制控制数据流以提取特征,如图4 所示。同时,LSTM 引入了一条贯通首尾的通路保存长期信息,即单元状态,它将梯度直接注入底层以实现长距离依赖。
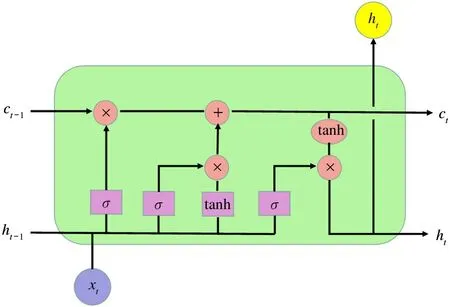
图4 LSTM 网络结构
FCN 模块由3 个时序卷积模块构成,每个模块由1 个一维卷积层、1 个批量归一化(batch normalization,BN)层、1 个ReLU 激活函数以及1 个Dropout层组成。
一维卷积层的卷积核只沿着一个维度进行。一维卷积主要起着调整通道数的作用,在保证特征图不变的同时能够表征系统非线性。并且,一维卷积可实现跨通道通信,在升、降维时实现通道间信息交互。
BN 层主要用在批处理方法中,每批数据在卷积操作之后进行标准化处理。BN 操作将每层数据的分布进行统一,加快网络训练和收敛速度。同时,BN 层归一化后,保证激活层输出不会过大,使得梯度不会过小,避免梯度消失。最后,由于BN 层将各小批量的样本进行关联,减小了单一样本对训练的影响,避免了过拟合。
因为Dropout 层中所有神经元的激活值都有一定概率输出为0,网络由确定的状态变为不确定的状态,可以有效避免过拟合情况。
上述的模块只是一种局部的编码方式,构建了输入数据的局部依赖关系,因此本文加入Self-Attention 模块,充分关注数据中的重要特征。SA 模块以时间维度进行数据关联,可以提取时间序列的时间相关性,利于后续CNN 的局部特征提取。
3 实验验证
实验数据来源于2021 年8 月9 日生物质流化床锅炉燃烧实验数据,采样周期为5 s。根据热效率的不同,采集2 组不同工况的数据,其中工况1 热效率平均值为97.77%,工况2 热效率平均值为95.52%。本实验利用改进的LSTM-SAFCN 方法对NOx 排放浓度进行预测,并与传统的预测模型在不同工况下进行对比实验。
本文模型中FCN 模块由3 个时序卷积模块构成。根据输入数据的特征数量,设置第1 个卷积层的输入通道数为23,输出通道数为32,卷积核的大小为3,填充为2;第2 个卷积层的输入通道数为32,输出通道数为64,卷积核的大小为3,填充为2;第3个卷积层的输入通道数为64,输出通道数为32,卷积核的大小为1,无填充。上述操作最终实现了对数据特征数量的扩充,能够提取出时序数据中存在的深度特征。
LSTM 模块由1 个LSTM 层构成。其中,LSTM的循环层设置为10,隐藏层为32,可将以时序形式输入的数据映射为32 维的特征向量。
上述模块的输出最终通过Concat 层合并为64维向量,最后通过2 个全连接层映射为一维向量,即实现NOx 排放浓度的预测。
3.1 数据预处理
数据预处理作为实验中的重要一环,其处理结果将直接影响预测的精度。本文采用改进后的CEEMDAN 算法对数据进行预处理,并将其与传统的EMD 方法进行比较,实验结果如图5 所示。

图5 EDM 与CEEMDAN 处理数据结果图
从图5 明显可以看出,CEEMDAN 方法无论是整体的趋势还是局部的细节,其拟合度均优于EMD方法。这是因为EMD 方法本身存在模态混叠问题,CEEMDAN 方法通过加入白噪声消除了这类问题,使得模态的分解十分清晰,产生了良好的拟合效果。此外,从图中还可以观察到经过CEEMDAN 处理后的数据拟合出的曲线是光滑的,而真实数据的曲线是阶梯状的。这是由于真实数据中存在噪声,导致数据不光滑,CEEMDAN 方法可以消除数据中存在的噪声,使处理后的数据变得光滑。
3.2 NOx 排放浓度预测对比实验
为了进一步验证模型的有效性,将LSTM-SAFCN 模型与LSTM、LSTM-FCN 模型进行预测结果的对比。图6 是不同模型的真实值与预测值之间的结果对比图,结果表明LSTM-SAFCN 能够更好地跟随真实值的变化。为了更加直观地反映各个模型的预测精度,从图6 中截取了1000~1300 时间步长曲线用于更好地观察拟合程度,见图7。从图7 可以看出LSTM-SAFCN 模型的预测值较其他几种模型对真实值的拟合程度更好,这说明LSTM-SAFCN 模型能够更加准确地预测NOx 的浓度。
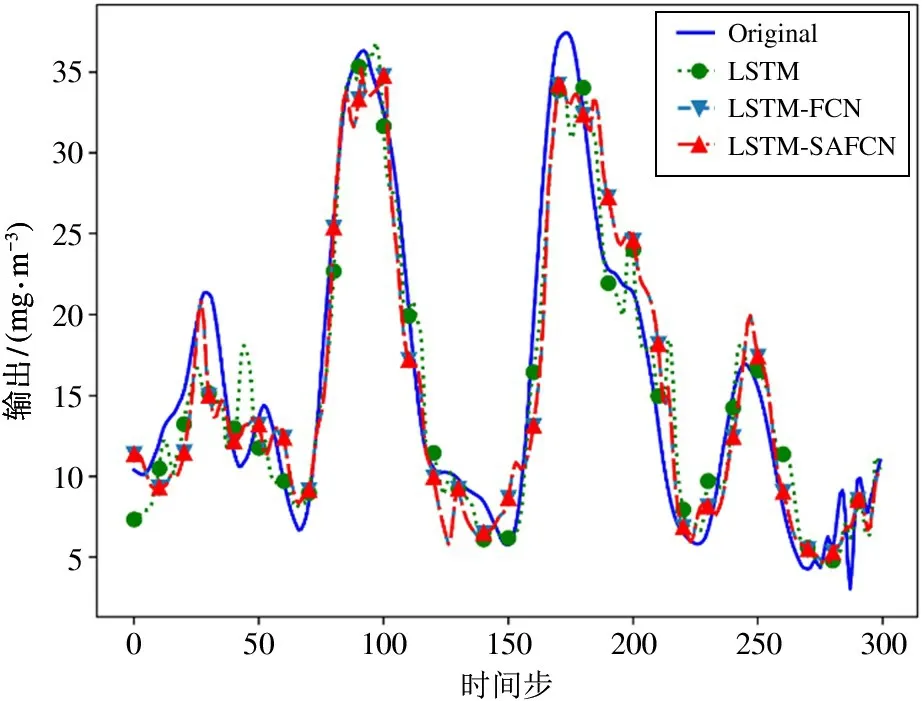
图7 3 种预测模型预测结果对比图
LSTM-SAFCN 的预测效果优于LSTM-FCN,是因为引入SA 后,可以减少对外部信息的依赖,更好地捕捉到数据之间的内部相关性,使得数据中的重要特征得以突出显现。与这2 种方法相比较,基于单LSTM 的预测模型预测效果更差,这主要是模型对于数据中特征提取的效果不好,没有提取到有效的重要信息用于预测,直接导致实验结果精度较差。
为了评估预测模型的性能,使用均方根误差(root mean square error,RMSE)、平均绝对误差(mean absolute error,MAE)和确定系数(coefficient of determination,R2)来作为预测结果的评价标准。其计算公式分别为
其中,N为测试集样本数,Yi为实际测量值,为模型的预测值,为样本均值。RMSE 反映测量值和预测值之间的总体偏差,MAE 揭示测量值和预测值之间的相似性,R2考虑观测值和预测值之间的相关程度。RMSE 和MAE 值越低,预测性能越好;R2值越高,预测精度越高。
表1 是不同预测模型在不同评价指标下的预测结果。对比发现,LSTM-SAFCN 模型预测效果明显优于其他2 种模型,与LSTM、LSTM-FCN 相比指标RMSE分别下降了66.06%、36.65%;指标MAE 分别下降了81.61%、53.68%;指标R2上升了65.59%、40.86%。

表1 不同预测模型实验结果对比
3.3 不同工况下NOx 排放浓度预测
为了进一步验证模型的有效性,在不同工况下使用相同的预测模型进行实验。上述3 种模型在工况2 的预测结果对比图如图8 所示。可以看出,在工况2 中LSTM-SAFCN 模型仍旧是最贴合预测曲线的。这说明在不同工况下,LSTM-SAFCN 模型依然能够准确地预测NOx 排放浓度。

图8 工况2 下3 种预测模型预测结果对比图
表2 是在工况2 下不同预测模型的预测结果对比。对比发现,LSTM-SAFCN 模型依然明显优于其他2 种模型,其中,与LSTM、LSTM-FCN 相比指标RMSE 分别下降了25.45%、9.42%;指标MAE 分别下降了23.58%、12.22%;指标R2上升了13.75%、5.00%。
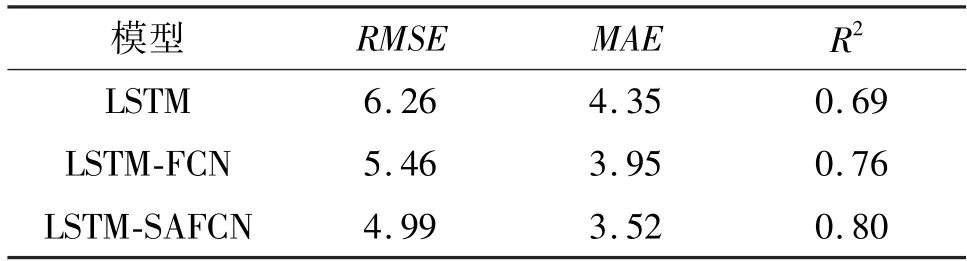
表2 工况2 下不同预测模型实验结果对比
不同模型、不同工况的预测结果充分说明,LSTM-SAFCN 模型由于加入SA 对输入数据实现了全局关联,与其他2 种预测模型相比具有更高的预测精度。
4 结论
针对生物质燃烧机理复杂且NOX排放受多方面因素影响的问题,本文在采用CEEMDAN 方法进行数据预处理的基础上,提出了一种改进的长短期记忆-自注意力机制全卷积神经网络(LSTM-SAFCN)模型用于预测NOX排放浓度,该模型可以同时兼顾时间序列数据的局部细节与长期趋势特征。实验结果表明,LSTM-SAFCN 模型与其他2 种传统模型相比预测精度更高。
考虑到LSTM 模块计算速度慢,后续工作将致力于改变并行结构,加深网络深度,进一步提高网络预测精度。
