高光谱图像结合卷积神经网络的马铃薯干腐病潜育期识别
2024-02-06王文秀王春山孙剑锋
张 凡, 王文秀, 王春山, 周 冀, 潘 阳, 孙剑锋*
1. 河北农业大学食品科技学院, 河北 保定 071000 2. 河北农业大学信息科学与技术学院, 河北 保定 071000 3. 河北农业大学植物保护学院, 河北 保定 071000
引 言
马铃薯是主要粮食作物之一, 中国的马铃薯种植面积和产量位于世界第一位。 然而, 马铃薯属于生鲜食品, 容易感染干腐病, 造成巨大的经济损失。 在贮藏过程中, 马铃薯常被多种镰刀真菌侵染, 首先病原菌附着在马铃薯表面, 经历潜育期后不断生长繁殖, 病症从隐性变为显性, 最终导致马铃薯外部和内部发生病变。 该病害易感染周边正常个体, 造成极大的经济损失。 因此, 实现马铃薯干腐病的快速检测和早期识别具有重要意义。
目前, 马铃薯干腐病检测方法主要包括人工目测或实验室生化检测, 人工目测存在主观性强、 准确率低等问题, 生化检测方法存在滞后、 效率低等问题。 此外, 早期马铃薯干腐病症状较轻, 肉眼难以观察和识别, 因此急需一种快速实时的检测方法对马铃薯干腐病进行早期识别。 高光谱成像(hyperspectral imaging, HSI)技术可有效利用图像和光谱信息, 在果蔬病害检测方面具有明显优势[1-3], 目前已在桃子根霉软腐病[4]、 马铃薯环腐病[5]、 库尔勒香梨黑斑病[6]等病害检测方面上取得了有效的进展, 证实了该方法的可行性。 但大部分文献仅仅对果蔬病害的显性病症进行诊断, 对染病未发病的潜育期研究仍需要深入。
化学计量学算法是高光谱分析技术中不可或缺的组成部分, 定性模型的建立是实现病害程度判别的关键。 常规算法包括最小二乘支持向量机(least squares-support vector machines, LS-SVM)、 K-近邻算法(K-nearest neighbor algorithm, KNN)、 随机森林(random forest, RF)和线性判别分析(linear discriminant analysis, LDA)等。 深度学习是近些年备受关注的机器学习算法, 与常规方法相比, 其自主学习的能力较强, 可以处理大量的数据, 获得更好的性能和更高的精度。 其中卷积神经网络(convolutional neural network, CNN)可以自动学习输入信息的深度特征, 进而用于后续的分类和回归任务。 将CNN与光谱技术结合, 可用于食品品质分析与评价。 孙海霞等[7]结合CNN与HSI对鲜枣黑斑病进行无损检测, 模型的准确率为90%。 Zhang等[8]以CNN作为监督特征提取方法, 建立了枸杞干中营养成分含量的高光谱预测模型, 预测相关系数均达到90%以上。 研究表明CNN的特征表达和集成学习能力较高, 能够充分挖掘高光谱图像中的深度特征信息, 将其与HSI技术结合有望实现马铃薯潜育期干腐病样品的正确识别。
以健康和不同病害程度的干腐病马铃薯为研究对象, 结合HSI和深度卷积神经网络方法, 构建干腐病早期诊断模型。 此外, 还构建了LS-SVM、 RF、 KNN和LDA模型, 对比分析进一步验证CNN模型的预测性能。 研究结果为深度学习结合高光谱成像技术在果蔬病害早期识别方面提供参考方法。
1 实验部分
1.1 样品制备
实验用马铃薯购于河北省保定市农贸市场。 挑选149个成熟度、 大小相近且无明显缺陷、 疾病的新鲜马铃薯, 立即运输至河北农业大学实验室, 用2%(v/v)次氯酸钠溶液洗涤5 min, 用自来水冲洗, 自然风干后备用。
接骨木镰刀菌种购买于中国微生物菌种保藏中心。 将购买的真菌接种于PDA培养基上培养7天, 待三代培养结束后, 将真菌孢子从PDA培养基表面去除, 悬浮在无菌生理盐水中, 最后将孢子浓度调整至1×106个·mL-1左右。
制备干腐病马铃薯样品时, 先用75%的酒精擦拭表面, 再用无菌水淋洗3次。 待表面干燥后, 使用注射器注射20 μL孢子悬浮液进行真菌侵染, 每个样品选取3个位置进行接种, 另注射20 μL无菌生理盐水作为对照样品。 接种后的果实放入人工气候箱中, 保证环境湿度为90%, 温度为(25±2) ℃。 为获得不同腐败程度的马铃薯样品, 每天接种6个样品, 整个试验持续21 d, 最终获得126个不同腐败程度的马铃薯样品和23个健康样品进行后续实验。 培养过程中, 采用十字交叉法记录每个薯块的病斑直径, 结合马铃薯平均表面积, 根据马铃薯干腐病分级标准[9]将全部马铃薯样品划分为4个等级, 如表1所示。
1.2 高光谱图像的采集与校正
采用的高光谱成像系统由CCD相机(GEV-B162M)、 成像光谱仪(ImSpector V25E)、 镜头、 位移平台、 光源、 计算机及暗箱组成。 光谱范围为920~2 528 nm, 分辨率为8 nm, 共288个波段。 相机分辨率为320×256, 光源选用一对150 W卤钨灯面光源。 经过前期实验, 将位移平台移动速度、 相机曝光时间和样品采集距离分别设置为7.5 mm·s-1, 10 ms和300 mm。 将样品按病斑朝上的方式放置在位移平台上, 相机连续线扫描进行图像的采集。 为了消除CCD相机暗电流和光源不均匀亮度造成的影响, 原始高光谱图像需进行黑白板校正, 得到校正后的图像。
1.3 感兴趣区域的分割和光谱数据的提取
感兴趣区域(region of interest, ROI)的选取是一个关键步骤, 可以减少处理时间, 增加模型精度, 提高模型的预测性能。 如图1所示, 以马铃薯三个损伤接种点为中心, 分别选择方形感兴趣区域(总像素点在10 000~12 000), 然后计算ROI内所有像素的平均光谱, 将其作为该样品的光谱信息。 利用ROI内多个点的平均光谱代替单个点的光谱能够减少偶然性和差异性, 从而提高模型的准确率和稳定性。 由于光谱的后端波段噪音较大, 对2 014~2 528 nm部分进行了截取, 将920~2 013 nm波段(196个)的光谱数据作为模型输入变量。 以上操作均在ENVI classic 5.2软件中进行。

图1 感兴趣区域选取示意图
1.4 数据处理
1.4.1 光谱数据增强
深度卷积神经网络中嵌入了大量的参数, 因此需要大量数据学习, 进而对神经网络进行充分的训练。 然而, 受样本数量、 采集环境、 设备等限制, 一般较难获取大量带有标签的样品光谱数据, 故采用数据增强的方式扩充样本[10]。 参照专利[11]所述方法, 对原始数据增加一定范围内的光谱扰动, 在此基础上添加噪声模拟数据。 将光照模拟添加的扰动程度分别设置为0.8、 0.9、 1.0、 1.1、 1.2, 将添加的噪声等级分别设置为-0.25、 -0.5、 0、 0.25、 0.5、 0.75, 由此得到扩增30倍后的高光谱数据。 经过数据增强, 得到包含四类样品光谱的数据集共4470条。
1.4.2 光谱预处理
由于原始光谱中不可避免地存在一些干扰如: 光的散射、 随机噪声等因素, 造成光谱不重复及基线漂移。 预处理可以在一定程度上降低噪声等冗余信息, 并对基线进行修正, 提高模型的鲁棒性和可预测性。 二阶导数可以消除高频噪音及组份间的相互干扰, 利用二阶导数(second derivative, SD)方法对原始光谱进行预处理, 但导数处理也会引入不必要的噪声降低信噪比, 因此先经Savizkg-Golay平滑滤除随机噪声再进行了二阶导数预处理。
1.4.3 常规方法建模
利用Kennard-Stone(KS)方法将数据按3∶1分为训练集(3 353)和测试集(1 117), 其中训练集中四个等级样品分别包括518、 405、 2 205和225个, 测试集包括172、 135、 735和75个。 以LS-SVM、 RF、 KNN和LDA作为分类器构建干腐病马铃薯的诊断模型。 其中, LS-SVM是对经典支持向量机算法的改进, 具有线性和非线性多元校正的能力。 RF是机器学习研究中常用的决策树方法之一, 不容易过度拟合, 计算需求较低, RF中随机树的数目设置为500。 KNN算法计算未知样本与所有已知样本之间的距离, 根据多数表决的方法, 将未知样本和k个近邻样本归为一类,k值设置为9。 LDA通过确定特征的线性组合, 将一个组合划分为两个或多个组合, 这种多变量方法有效地使两组间的比例最大化, 使组内的比例最小化。
1.4.4 卷积神经网络建模
CNN是人工神经网络的衍生产物, 旨在建立一个类似于人脑的特征学习网络, 对海量数据进行分析和处理, 可以自动从原始数据中提取线性和非线性特征, 实现端到端建模方法。 采用经典的LeNet作为CNN的结构, 可以理解为输入层、 卷积层、 池化层、 全连接层和输出层的串联。 卷积层主要用于通过过滤器以特征映射的形式提取和保存有用的特征。 池化层对卷积层提取的特征进行选择, 最终实现降维。 全连接层将池化层的所有特征矩阵转化为一维特征向量, 作为“分类器”对特征信息进行有效分类。
1.4.4.1 卷积神经网络框架
搭建的卷积神经网络为Pytorch中nn.Conv2d, 模型结构如图2所示, 包括1个输入层, 3个卷积层(C1、 C2、 C3), 3个池化层(P1、 P2、 P3), 3个全连接层(F1、 F2、 F3)和1个输出层。 首先给定原始马铃薯高光谱图像, 利用ENVI进行ROI分割和多个波长处反射率信息的提取; 然后对原始光谱数据进行平滑+SD处理得到Td, 一维CNN的处理分析往往难以挖掘光谱数据的深度特征信息, 因此将一维数据重组为14×14维度的二维数据, 如图3所示。 并且复制四次后得到网络的输入变量Ti, 其维度为14×14×4。 最后将人工标记的标签Li(样品等级)作为输出变量建立CNN训练模型。 利用卷积神经网络C进行分类的过程如式(1), 其中分类的结果为输出类别的概率值P。

图2 CNN模型的基本结构

图3 二维矩阵转换图
P=Softmax(C(Ti),Li)=
(1)
由于在网络前向传输过程中, 每一层卷积的卷积核是随机产生的, 导致最后一层卷积层的特征输出并不相同, 经过全连接层后得到的最终分类概率值并不能实现准确的预测。 因此在训练过程中整个网络需要不断迭代, 根据网络的预测值与标签值之间的损失优化训练过程中的随机量, 最终达到模型拟合, 并保存最优的模型参数。 采用交叉熵损失函数作为模型更新的衡量指标, 如式(2)所示。
(2)
1.4.4.2 网络层数选择及优化
在卷积神经网络训练中, 不同网络层结构对模型识别效果有巨大影响。 设计了9种实验方案, 即: 卷积层数设置为1、 2、 3, 全连接层数设置为1, 2, 3, 在此基础上进行不同层数之间的组合, 包括: Model_1_1、 Model_1_2、 Mode_1_3、 Model_2_1、 Model_2_2、 Model_2_3、 Mode_3_1、 Mode_3_2、 Mode_3_3。 对不同层数网络结构进行训练, 然后对测试集进行预测得到模型识别率, 从而确定最优模型结构, 此时学习率设置为0.000 1。
1.4.4.3 超参数选择及优化
在深度学习建模过程中需设定一些超参数, 包括学习率、 批大小、 激活函数、 迭代次数、 卷积核大小、 种子大小、 填充值、 步长、 丢弃率等。 其中学习率是最重要的一个超参数, 具有加快模型收敛和避免陷入局部最优的优点。 选择0.000 1、 0.000 5、 0.001、 0.005、 0.01共5个学习率进行优化选择。 表2为CNN模型的参数设置。 对于卷积层来说, 卷积核大小为1, 步长为1, 填充大小为0。 对于池化层, 采用了Pytorch中的AdaptiveAvgPool2d, 其在参数中只指定了输出的大小为1×1, 使得池化后的每个通道上的大小为1, 即每个通道上只有一个像素点。 对于全连接层, 神经元个数分别设置为3 136、 1 152和288。 最后, eropout层的丢弃率设置为0.1, 代表随机丢弃全连接层的神经元个数占总个数的10%。 对于激活层和池化层, 采用Relu激活函数。 模型训练的批大小设定为32。 上述模型训练所用计算机的配置如下: Ubuntu18.04环境、 Intel core i9 9820X处理器、 64 G内存、 GeForce RTX 2080Ti 11G DDR6显卡、 Pytorch学习框架。
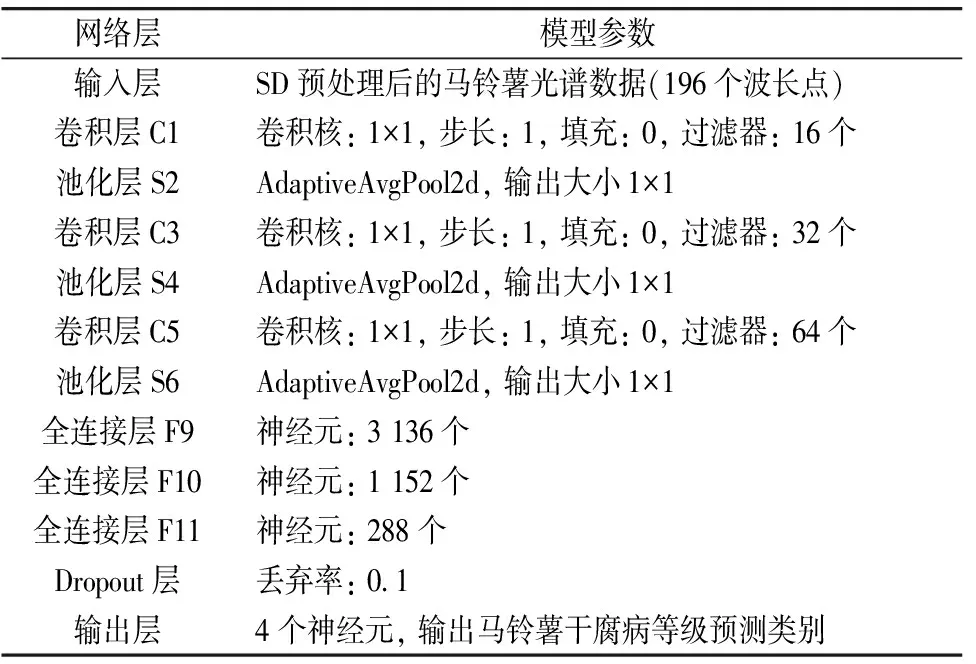
表2 CNN模型网络参数
1.4.5 模型评价
为准确地评价模型, 综合运用准确率、 精度、 灵敏度和特异性对模型性能进行分析。 表3为4种评价指标的公式及意义, 其中正例代表目标预测类别(positive,P), 负例代表其他非目标预测类别(negative,N)。TP为实际为正例但被分类器划分为正例的实例数;FN为实际为正例但被分类器划分为负例的实例数;FP为实际为负例但被分类器划分为正例的实例数;TN为实际为负例且被分类器划分为负例的实例数。

表3 模型评价指标的公式及意义
2 结果与讨论
2.1 干腐病马铃薯分析
健康和接骨木镰刀菌侵染不同时间的马铃薯及病斑面积如图3和表4所示。 病原菌起初侵染马铃薯块茎时, 分泌了一系列细胞壁降解酶如多聚半乳糖醛酸酶、 果胶甲基半乳糖醛酸酶、 纤维素酶、 β-葡萄糖苷酶等造成寄主细胞壁溶解和质壁分离[12], 此时块茎表面与健康样品无差别, 并未出现明显的可见症[图4(a1)、 (b1)]。 接着病原菌进入寄主细胞, 释放特异性毒素破坏寄主的防御系统, 扰乱寄主正常的生理活动, 造成块茎淀粉、 直链淀粉、 支链淀粉、 还原糖、 蔗糖和总可溶性糖等碳水化合物含量的变化[13], 最终影响其品质属性, 此时块茎表面和内部出现肉眼可见的褐色圆形小斑点[图4(c1)、 (c2)], 斑点呈水浸样或皱状。 随着侵染时间的延长, 马铃薯块茎的病斑逐渐扩大并干瘪, 且发生下陷, 此时薯皮成同心圈状折叠, 菌丝体紧密的交汇在腐烂部位, 并着生了白色的孢子团, 且病部薯肉坏死变褐, 并向四周扩展, 较老的死亡组织中出现真菌孢子, 空腔内长满菌丝[图4(d1)、 (d2)]。 表4为不同腐败程度马铃薯病斑面积统计数据, 病斑面积范围为0.22~15.40 cm2, 占整个马铃薯表面积比例为0.14~10.20%。

图4 不同病害程度马铃薯

表4 不同病害程度马铃薯病斑面积统计信息
2.2 原始光谱曲线及预处理
健康和不同病害等级马铃薯的平均光谱如图5(a)所示, 其中紫色、 黄色、 红色和蓝色线条分别代表等级3、 2、 1和健康样品。 在整个波段范围内, 健康薯与干腐病薯的反射光谱在光谱形态特征方面相似, 但反射率值存在明显差异。 在1 020、 1 223和1 582 nm左右处出现了最强的局部吸收峰, 其中1 020 nm源于N—H基团的第二倍频伸缩振动吸收、 1 223 nm代表马铃薯水分的O—H键合频吸收, 1 584 nm与N—H基团的一级倍频有关。 位于1 370和1 820 nm附近的波谷主要源于C—H的二级倍频和一级倍频。 在920~1 810 nm波段范围内, 病害马铃薯光谱反射率显著高于健康马铃薯。 其中潜育期样品与健康样品反射率值较为相似, 主要源于潜育期样品的腐败程度较低, 光谱上未有明显变化。 与健康马铃薯相比, 干腐病马铃薯组织变黑, 细胞组织失水, 等级2、 3样品可能会出现粉状的皮质组织, 导致马铃薯颜色加深, 组织对光的吸收随之增大, 并且样品组织水分减少也会导致光散射增强, 最终使吸光度升高。 预处理光谱如图5(b)所示, SD处理强化了原始光谱中隐藏在较宽吸收频带的微小特征峰, 提高了分辨率和灵敏度。

图5 不同等级马铃薯样品光谱
2.3 CNN模型训练与测试
2.3.1 网络层数寻优分析
网络层的优化对获得理想的分类性能起着至关重要的作用。 采用Model_1_1、 Model_1_2、 Mode_1_3、 Model_2_1、 Model_2_2、 Model_2_3、 Mode_3_1、 Mode_3_2、 Mode_3_3进行网络结构优化。 图6表示准确率[图6(a)]和损失值[图6(b)]随不同层数组合和迭代次数的变化, 随着模型的训练, 其准确率均呈增加趋势, 损失值呈下降趋势。 随着网络层数的增加, 准确率增强的斜率越来越大, 即增大速度越快。 当迭代次数为25时, 准确率变化趋于平稳且逐步达到最高值, 损失值达到最小值。 这是因为在网络操作开始时, 由于损失值最初很高, 网络必须通过APN模块来学习ROI。 但随着APN模块参数的重新更新, ROI精度逐渐提高, 损失值急剧下降, 最终达到最低水平。 不同层数组合之间准确率和损失值有所差异。 所有模型的准确率大小顺序为: Model_3_3>Model_3_2>Model_2_2>Model_2_3>Model_2_1>Model_1_3>Model_1_2>Model_1_1>Model_3_1。 在所有模型中, Model_3_1训练准确率最低, Loss值最高, 可能是由于卷积层较多, 全连接层较少。 Model_3_3训练准确率最高, Loss值最低, 因此, 在卷积层为3层的情况下, 采用3层全连接层能更好地提升模型的性能。

图6 训练准确率与损失变化
为进一步评价模型的稳健性和泛化性, 利用测试集对深度模型进行评估。 将测试数据分别代入9个CNN模型中进行测试, 结果如表5所示。 除了Model_3_1预测准确率较低以外, 其他模型预测准确率均达到80%以上, 且Model3_3模型的分类效果最好, 与上述模型训练结果一致。
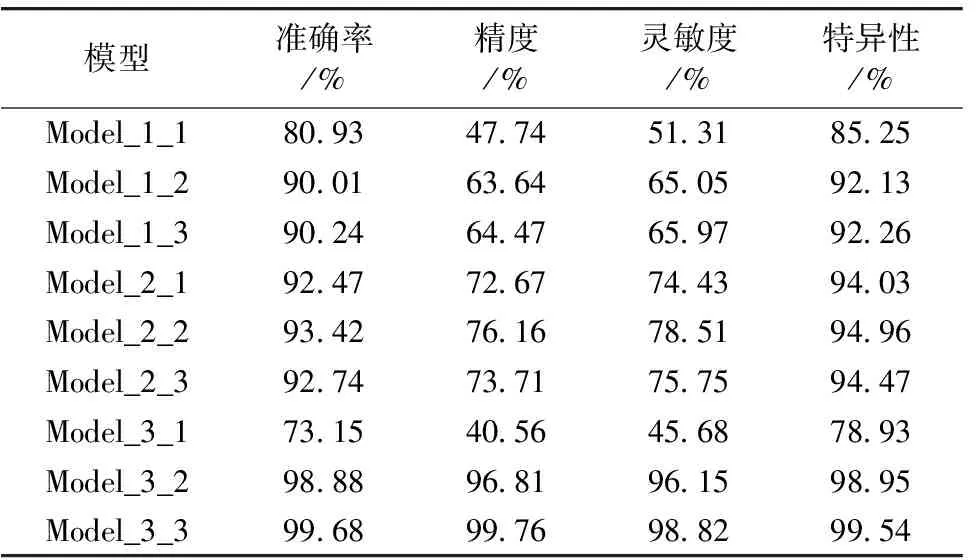
表5 基于不同网络层的测试集预测结果
2.3.2 学习率参数寻优分析
基于以上最优网络结构Model3_3, 设计了5种学习率优化实验方案, 并分别命名为Model_0.0001、 Model_0.0005、 Model_0.001、 Model_0.005和Model_0.01。 随着迭代次数的增加, 训练模型的准确率和损失值变化如图7所示, 随着训练运行, 准确率呈一定趋势增加, 损失值不断下降。 此外, 学习率越大准确率越低, 损失值越大, 主要由于学习率越小学得越仔细, 从而模型识别率越高。 因此, 确定0.000 1为最优的学习率。

图7 训练准确率与损失变化
利用测试集对训练模型进行评估, 结果如表6所示。 随着学习率的降低, 测试集准确率显著增加, Model_0.0001模型预测准确率达到98.12%, 精度、 灵敏度和特异性分别为91.88%、 94.99%和98.78%。 而Model_0.01预测准确率仅为76.77%, 说明学习率过大导致模型学习粗糙, 最终造成准确率较低。

表6 不同学习率模型的预测结果
为了进一步分析Model_0.0001模型的分类性能, 计算最优模型的混淆矩阵。 如图8所示, (a)、 (b)分别代表训练集和测试集的预测结果, 其中对等级0(健康)样品预测准确率分别为99.94%和99.73%, 表明此模型可以对健康和干腐病马铃薯进行较好的区分。 0级和1级分类过程中出现一些错分现象, 其中1级样品属于潜育期阶段, 感染腐败菌但表面未出现病斑, 样品表面与健康样品相似, 因此很容易发生误判。 此外, 对2级样品和3级样品预测准确率分别达到了99.97%、 99.97%和100%、 100%, 主要源于随着贮藏时间的延长, 腐败程度越大, 病斑部位颜色变化明显, 误判次数也减少。 综上所述, 使用CNN模型能够精确地对马铃薯干腐病进行早期识别, 对马铃薯干腐病的及时防治具有重要意义。

图8 Model_0.0001混淆矩阵
2.4 CNN与常规方法对比分析
为进一步验证CNN模型的有效性, 利用LS-SVM、 RF、 KNN和LDA四种算法建立干腐病马铃薯不同腐败程度的定性分类模型, 测试集预测结果如表7所示。 四种方法所建立模型的总体准确率均达到90%以上, 表明模型分类效果较好。 为了进一步分析常规模型的分类性能, 计算其混淆矩阵, 结果如图9所示。 四种模型存在较多对1级样品的预测错误, 分类准确率分别为91.00%、 85.58%、 94.18%和90.33%, 相较于CNN模型结果来说较低。 这可能是由于马铃薯被真菌侵染后, 在储存时间较短的情况下, 外观变化不明显, 从而导致被误判为健康样品的次数较多。 此外, 存在2级样品和3级样品之间的误判现象, 可能由部分马铃薯个体差异造成。 总得来说, 常规方法所建模型总体识别效果较好, 能实现马铃薯干腐病腐败程度的分类, 但对潜育期样品的识别能力有待提高。

图9 常规方法的混淆矩阵

表7 LS-SVM、 RF、 KNN和LDA分类模型结果比较
综合比较, CNN所建定性模型的预测性能优于其他分类模型, 尤其对1级(潜育期)样品的识别准确率达到99.73%, 较好地实现了马铃薯干腐病的早期检测。 CNN算法通过优化每个滤波器的权值参数, 在预处理和特征选择过程中减少了人为的工作量, 完全探索了特征信息。 同时, 最大池化策略、 退出策略和批处理归一化策略的共同作用有效减少了特征维数, 将可能出现的过拟合问题规避。 因此, 高光谱与深度学习相结合能更好的实现马铃薯干腐病潜育期样品的识别。
3 结 论
采用高光谱成像技术结合CNN实现马铃薯干腐病潜育期样品识别分类。 分别建立了CNN、 LS-SVM、 RF、 KNN和LDA分类模型, 并比较其分类结果。 结果可得, 五种算法分类模型的总体准确率分别为99.68%、 90.77%、 92.30%、 93.10%和92.34%, 其中CNN建立的模型最优, 其精度、 灵敏度、 特异性达到99.76%、 98.82%、 99.54%, 对潜育期样品识别率高达99.73%, 较几种常规方法提高了5.55%~14.15%。 该结果表明, CNN更有利于提取和挖掘光谱数据深层信息, 进一步提高了马铃薯干腐病腐败程度分类精度。 本研究为马铃薯干腐病早期防治、 精准施药及检测仪器开发提供科学依据, 后续可利用CNN提取更多的高光谱图像信息加以利用, 进一步提高建模预测结果。
