结合图卷积网络的多模态仇恨迷因识别研究
2024-02-05刘旭东张冬瑜林鸿飞
刘旭东,杨 亮,张冬瑜,林鸿飞
(1.大连理工大学 计算机科学与技术学院, 辽宁 大连 116024;2.大连理工大学 软件学院, 辽宁 大连 116620)
0 引言
随着社交媒体的快速发展,人们之间的交流变得更加便捷,梗图作为一种辅助情感表达的交流方式备受欢迎,尤其受到年轻人的喜爱。学术上,梗图被称为“迷因图”,即图片格式的迷因,在本文中,“迷因”特指“迷因图”。迷因一词源自希腊语mimema,意为“被模仿的东西”,也被称为“模因”或“谜母”。Dawkins R最早仿照基因(gene)一词创造出了“meme”这一概念,指人与人之间复制传播的基本文化单位[1]。这种基于网络而得到广泛传播的微型内容包括数字、文字、图片、视频等,都可被归入迷因的范畴。
仇恨言论是基于种族、国籍、宗教、种姓、性别等特征对人进行直接或间接攻击的言论[2]。由于社交媒体用户生成内容不受监管的特点,社交媒体已成为传播仇恨言论的重要渠道之一。在社交媒体中,迷因是一种表达情感的重要手段,因此识别迷因形式的仇恨对于识别社交媒体中的仇恨言论十分重要。尽管需要人工努力,但这个问题的范围过大,单纯依赖人工方式难以解决,因此需要设计一种自动化的技术,在仇恨言论产生有害影响之前检测并删除它们。仇恨迷因识别有助于净化网络平台环境,促进多样性和包容性,帮助建立更加和谐的社会。同时,仇恨作为一种消极的情感表达方式,准确识别这一情感可以提高情感分析和意见挖掘的效果[3]。
现有的迷因识别方法将仇恨迷因识别视为一个图像文本双模态任务,通常使用经典的VLP(vision and language pretraining)模型进行处理。然而,这些模型没有充分考虑迷因识别和其他图文下游任务的区别,即迷因经常使用具体的人物或者事件来表达自身的情感,这些实体称作网络实体。网络实体指历史人物、热点事件、知名地点等在社交媒体交流中能够辅助情感表达的实体。据常江等[4]的研究,明星、网络红人和各种知名大V等往往扮演着迷因传播过程中的重要角色,处在关键的传播节点上。这些行为领袖以及他们的行为也经常成为迷因变异的源泉,并成为迷因的一部分来表达情感。
目前,已有多项研究致力于仇恨迷因识别。例如,Kiela等[5]将仇恨迷因识别当作一个图像-文本-知识三模态的任务并使用扩展的VLBERT进行识别,在Hateful Memes数据集上取得了出色的成果。Zhang等[6]同时使用CLIP和UNITER对迷因进行编码,并在仇恨迷因相关领域进行领域预训练。但他们的研究要么只关注迷因本身的图片和文字而忽视了网络实体在迷因情感表达中的作用,要么只是对来自不同域的信息进行简单的拼接,没有考虑不同域表达之间的差异,导致降低了模型识别仇恨迷因的效果。
针对上述问题,提出一种结合图卷积神经网络的模型HMGCN (hateful meme recognition model based on graph convolutional network)。研究的主要贡献如下:
1) 针对迷因经常借助网络实体表达情感的特点,将网络实体引入仇恨迷因识别任务中,并使用图卷积神经网络对文本域和网络实体域的信息进行跨域融合,增强仇恨迷因识别的效果。
2) 结合仇恨情感的特点,使用Wordnet[7]和SenticNet[8]等外部资源,从文本相似度和情感极性2个角度评估网络实体和迷因文本之间的联系,构建跨域图,进行图卷积,并使用注意力模块来融合增强的文本模态和图像模态。
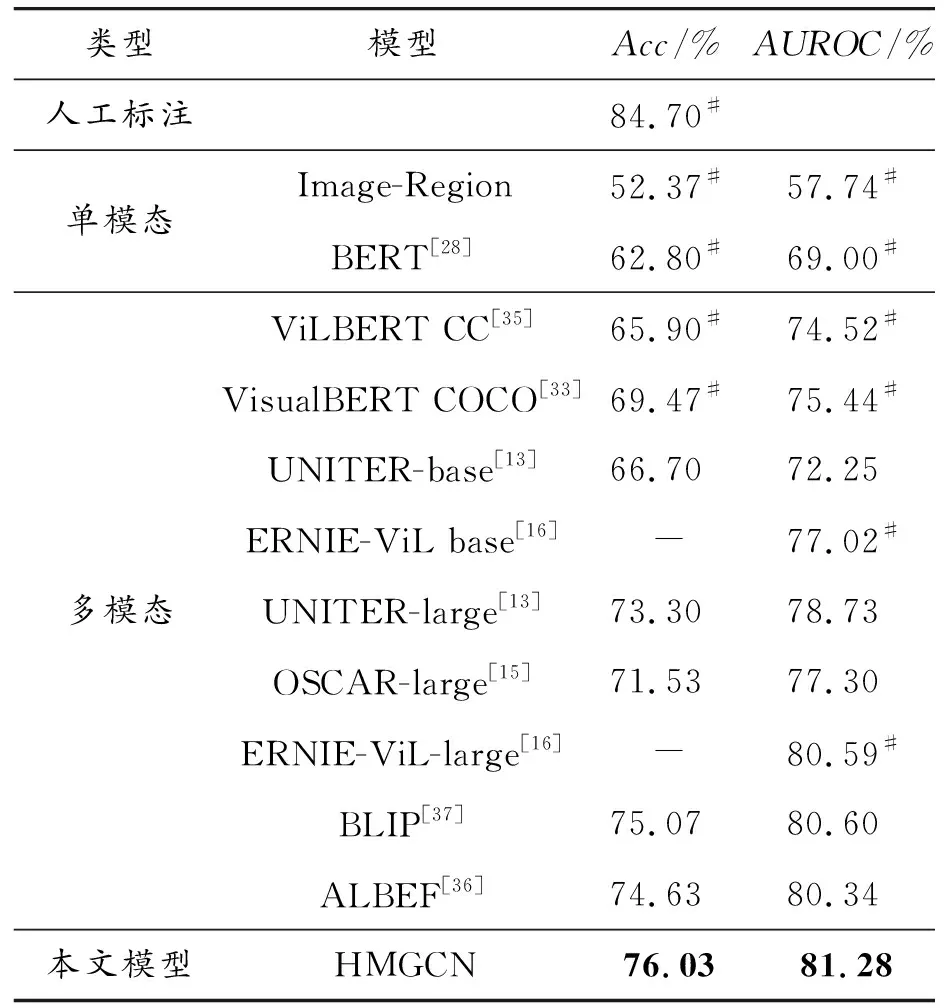
3) 为验证添加网络实体和图卷积神经网络对跨域融合的效果,在2个仇恨迷因识别数据集上进行一系列实验。在Hateful Memes数据集上,准确率和AUROC分别达到76.03%和81.28%。在MAMI数据集上,准确率和F1值分别达到73.9%和73.3%。实验结果表明,所提出的模型在性能上优于现有SOTA模型。
1 相关工作
1.1 迷因研究
迷因是一种通过模仿或者其他非遗传行为从一个人传递给另一个人的文化元素[3]。Dawkins认为迷因是通过复制变异而传播的基本文化单位。 Gilbert[9]将迷因的概念进一步发展为“知因”。这些学者都是从社会科学的角度(例如生理学、心理学等)来解释迷因。
随着互联网的发展和社交平台的普及,互联网高交互、低门槛、高自由度和碎片化的特点为迷因这种微型文化的复制、变异传播提供了便利条件和丰厚土壤。然而,迷因创作良莠不齐,因此如何使用计算机对迷因进行解释和分类引起了研究人员的关注。He等[10]提出了一种模因提取算法,使用聚类算法从反疫苗接种运动等事件期间发布的迷因数据中提取特征。Drakett等[11]使用主题分析的方法,从语言心理学的角度解释仇恨迷因问题。
1.2 视觉文本预训练模型
多模态迷因检测通常被视为一个视觉文本双模态任务,近年来受到研究人员的广泛关注。目前,大多数现有的视觉语言表示学习都基于图文预训练模型,这些模型大体分为2类。
第一类是使用Transformer[12]结构的多模态编码器对文本和图像特征进行建模,例如Uniter[13]使用Faster-Rcnn[14]提取图像特征,使用Transformer模型对图像和文本进行跨域融合;
Oscar使用目标检测器得到的box标签作为连接图像和文本的瞄点[15];Ernie-ViL将场景图信息加入视觉文本预训练任务中[16]。这类方法适合给定目标框的任务,在VQA等[17]任务上取得了很好的性能,但这类方法需要高分辨率的图像和预训练性能好的目标检测器,同时实验结果受目标检测器性能的影响[18]。
第二类是对图像和文本训练一个统一模态的编码器。Radford等[19]使用文本作为引导使用对比学习来进行图文表示学习,ALIGN使用传统图文模态预训练任务和对比学习结合的方式进行图文预训练,在海量嘈杂的网络数据上进行预训练得到一个统一编码视觉文本的模型[20]。
1.3 仇恨迷因识别
仇恨迷因识别和仇恨言论检测有很多相似之处,都是检测一条数据中是否包含对特定群体的直接或间接攻击。仇恨言论检测已被证明是困难的,因为存在不必要的偏见[21]。
仇恨迷因识别相较于典型图文多模态任务的不同,在于典型多模态任务中,输入的图片和文本通常有直接关联,且文本常只包含对于图片的简短描述。但meme中只有一部分图片和文字有直接关联,在大多数情况下,Meme 的仇恨表达比较隐晦,需要额外的现实世界信息才能理解迷因表达的仇恨情感。例如,在图1(a)中如果不能准确识别希特勒这一特定历史人物,就很难准确理解图片表达的感情。在MAMI(multimedia automatic misogyny identification)[22]训练集中,经统计有196张图片使用了希特勒的形象,有207张图片使用了特朗普的形象来表达自己的情感,说明网络实体对于情感表达的重要作用。由于经典的VLP模型通常无法充分利用迷因中的网络实体,因此可能会导致模型性能的下降。

图1 仇恨迷因示例
对于如图1(b)所示的多模态仇恨迷因的识别,不仅需要对文本和图像2种单一模态的理解,还需要将2种模态联合起来进行推理,才能得出正确的结论。如果只看图片,可能只看到一群大猩猩;如果只看文本,可能得到奥巴马的支持者,两者均无法表达仇恨的情感。只有将两者结合起来才能意识到这是对奥巴马支持者和黑人的攻击,表达了对他们的仇恨。
相较于经典多模态任务涉及的对象,迷因涉及的对象很多都是新生事物、历史人物等,这些网络实体目标检测器很难识别,也影响了经典图文多模态模型在仇恨迷因识别的效果。
随着预训练模型的广泛应用,人们开始尝试采用图文预训练模型来解决仇恨迷因识别问题。在此领域,Kiela等[5]将仇恨迷因识别当作一个图像-文本-知识三模态的任务,将种族、面部表情等信息添加到模型中,使用扩展的VLBERT进行仇恨迷因识别,在Hateful Memes数据集上取得了很好的效果。Miller等[7]同时使用CLIP和UNITER的对迷因的图像模态进行编码,并进行领域预训练,在MAMI数据集上取得了SOTA的效果。
1.4 图神经网络
图神经网络 (graph neural networks) 模型包括Kipf等[23]提出的图卷积网络 (graph convolutional network) 和Velickovic等[24]提出的图注意力网络 (graph attention network)等。
近年来,一些研究者探索了图神经网络在单模态和多模态任务上的应用。单模态方面,Wu等[25]使用CNN提取图像特征,使用图卷积神经网络加强视觉表示的效果。Yao等[26]提出了TextGCN模型,通过TF-IDF和滑动窗口机制构建文档-单词异构图,并成功应用于文本分类任务中。多模态方面,Yang等[27]在多模态讽刺检测任务中使用GCN(graph convolutional network)将VIT编码的图像表示和BERT[28]编码的文本表示进行融合,取得了很好的效果。另一方面,Zhang等[29]将图注意力神经网络应用于多模态命名实体识别任务中。
2 模型
本节主要介绍HMGCN的模型结构和跨域图的构建方式。模型主要包括4个部分:迷因文本特征提取模块、迷因图像特征提取模块、跨域图卷积模块、交叉注意力多模态融合模块。模型整体结构如图2所示。
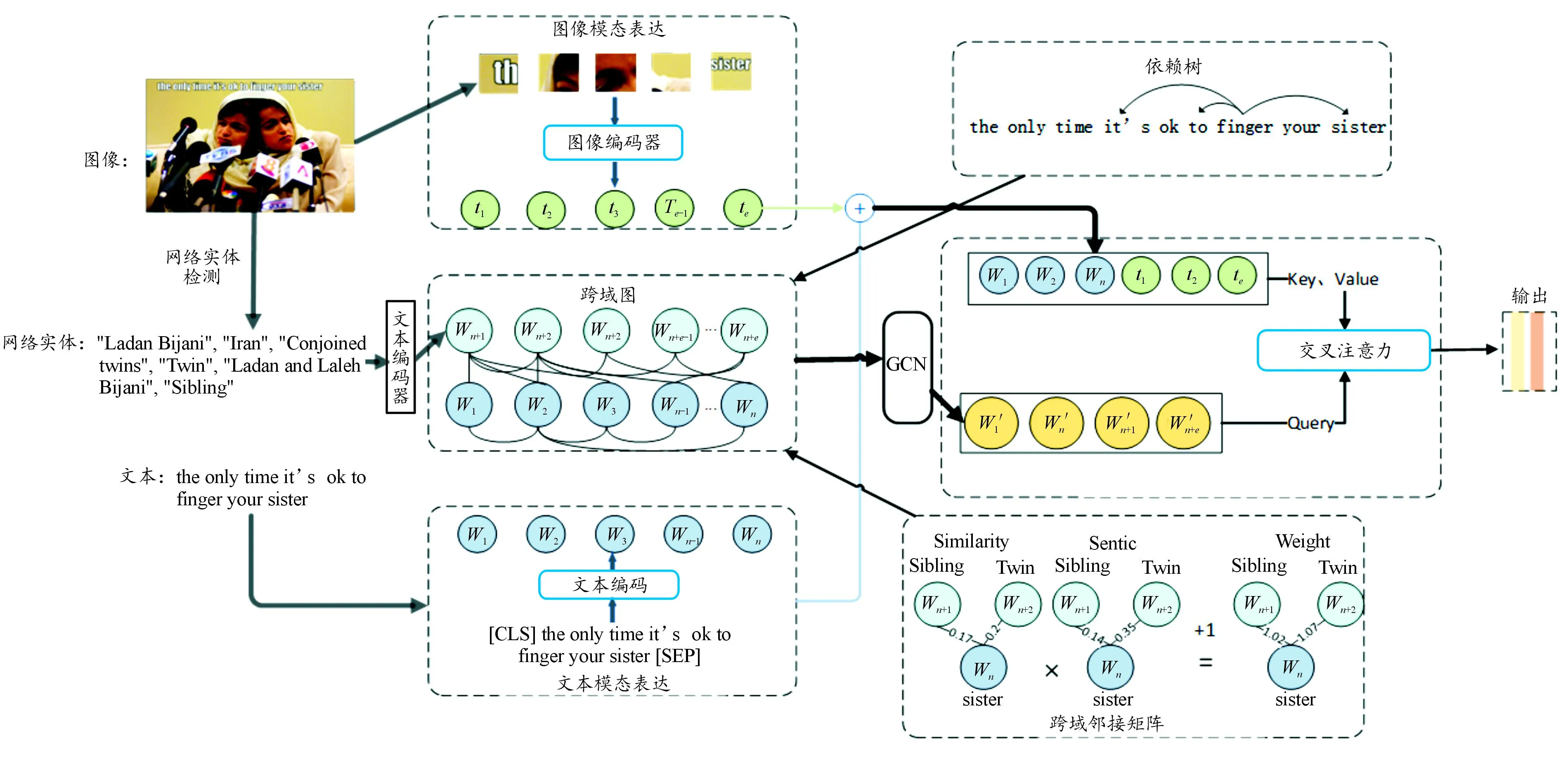
图2 模型整体结构
为了充分利用仇恨迷因中的信息,分别使用BERT和Vision Transformer (ViT)提取图像和文本的特征来获取更充分的迷因仇恨特征。针对迷因文本中网络实体信息缺失的问题,借助谷歌网络实体检测API获取网络实体信息。对于来源于不同领域的信息,结合外部知识构建一个跨域邻接矩阵从而评估两者中的对齐关系,使用图卷积网络充分利用这种对齐关系来更好地融合2个领域的信息。此外,针对图像和文本特征分布不一致的问题,借助交叉注意力模块来将文本模态与图像模态进行融合,以获取包含网络实体信息的多模态仇恨特征表示,最后用于仇恨迷因分类任务。
2.1 文本模态表示
对于每个迷因对应的文本使用BERT的分词器(Tokenizer)进行分词,并在首尾分别加入[CLS]和[SEP]得到S,数学描述为
S=[xcls,x1,x2,x3,…,xlen(S),xsep]
(1)
其中:xi∈RV,V是BERT的词表大小;len(*)表示文本进行Bert分词处理得到的token总数。设定文本最大长度为l,对于长度超过l-2的句子使用截断策略:
通过词表得到token对应的序号并利用预训练的BERT嵌入层对输入的单词序列进行词嵌入,将每个单词映射成一个d维的向量wi,数学描述为
Semb=Emb[xcls,x1,x2,x3,…,xlen(S),xsep]=
[wcls,w1,w2,w3,…,wlen(S),wsep]
(3)
其中:wi∈Rd表示第i个单词上下文无关的词嵌入。将词嵌入wi送入基于多头注意力机制的BERT编码器,得到上下文相关的文本隐层表示,使用最后一层的隐层向量SH作为文本隐层表示,数学描述为
SH=BERT[wcls,w1,w2,w3,…,wlen(S),wsep]=
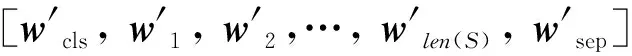
(4)
最后,将一个batch内的句子堆叠起来得到文本模态的输出,描述如式(5)所示。其中,N为输入的batch大小,d为Bert base隐藏层输出大小。对于长度不够最大长度的迷因文本以[PAD]补齐。
Remb=[SH,1,…,SH,N]∈RN×l×d
(5)
Remb作为文本模态的特征表示用于2.4节的多模态融合部分。
2.2 图像模态表示
对于给定的图片I,首先重整图片大小将图片分辨率保持一致。参考Xu等[30]的做法,将图片像素设置为224×224,即I∈RLh×Lw×C。其中,Lh和Lw分别为图像纵向和横向包含的像素点数;L=Lh=Lw=224;C=3为图片的通道个数。
对于每个重整后的图片按照区域切分为相同大小的图像块,图像块大小为p×p,得到图像块序列I′,数学描述为
I′=[p1,p2,…,pr]
(6)
其中:pi∈Rp*p*C,是第i个图像块展成的一维向量;r=(L/p)*(L/p)为图像块的个数。在序列前加入[class],对pi进行线性变换并加入位置信息得到图像的嵌入表示Z,数学描述为
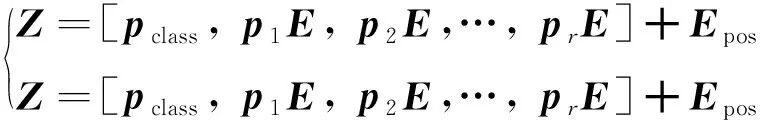
(7)
其中:E∈R(p*p*C)×D;E为可训练的参数;D为图像隐层表示大小;Epos∈R(r+1)×D为图像的位置编码。
将Z输入到ViT的编码器中,并使用最后一层的隐层表示作为图像各部分特征,经过线性变换得到图像模态的表示V,数学描述为:
V=ViT(Z)WV={vclass,v1,v2,…,vr}
(8)
其中:vclass为图像的全局表示,vi为第i个图像块的表示;WV∈RD×d,为可训练的线性层,使图片的隐层表示维度和文本保持一致。V作为图像模态的特征表示用于2.4节的多模态融合部分。
2.3 跨域图的构建
为了更好地表示迷因文本和网络实体之间的关系,采用图结构将两者联系起来。图中的节点是文本和网络实体的隐层表示,采用邻接矩阵A来描述节点之间关系,本小节主要介绍邻接矩阵的构建方式。受Liang[31]的研究启发,在文本模态中依据文本的语法依赖树来设置权重,而跨域边计算则使用词相似性和消极情感系数。与Liang不同的是,本文引入了网络实体信息并在仇恨迷因识别中更注重消极情感因素对仇恨情感表达的影响,而非情感不一致性。
基于GCN的方法已经证明边的权重在图信息融合中至关重要[32]。因此,构建跨域图重点是邻接矩阵中边权重的设置。对于域内的边使用语法依赖树构建,对于跨域的边则从相似度和消极情感表达2个角度评估结点之间的联系来构建。使用Wordnet计算单词之间相似度,使用Senticnet中的情感极性分数计算2个单词的消极情感系数。通过2个单词间的相似度和消极情感系数得出跨域边的权重,图的邻接矩阵A∈R(n+m)×(m+n)可定义为:
ξi, j=γ|ω(wi)|+|ω(wi)|+1×|ω(wi)-1|×|ω(wj)-1|
(10)
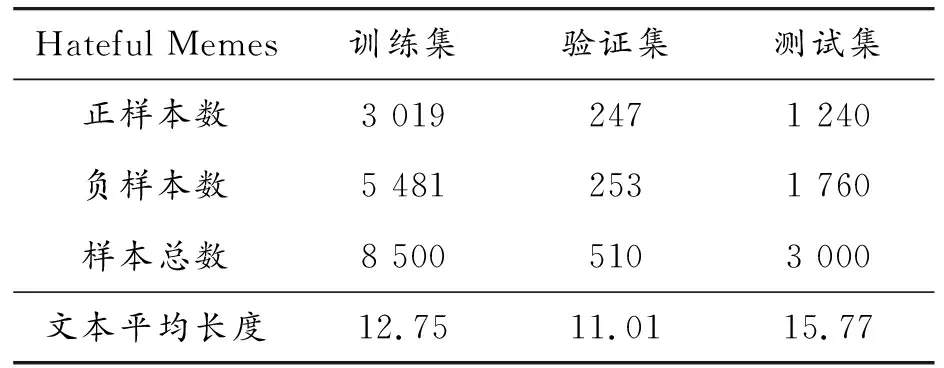
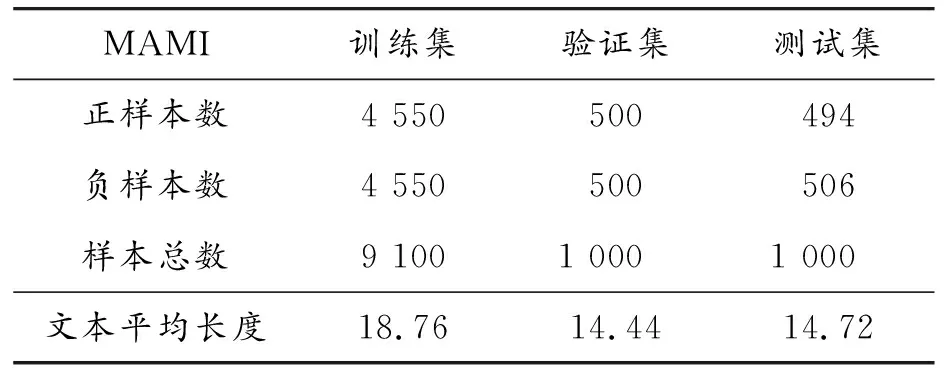
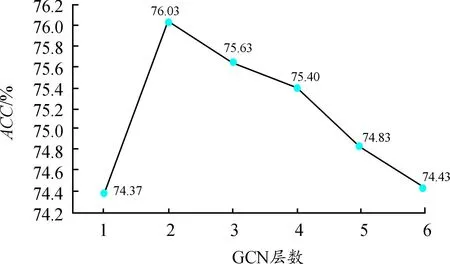
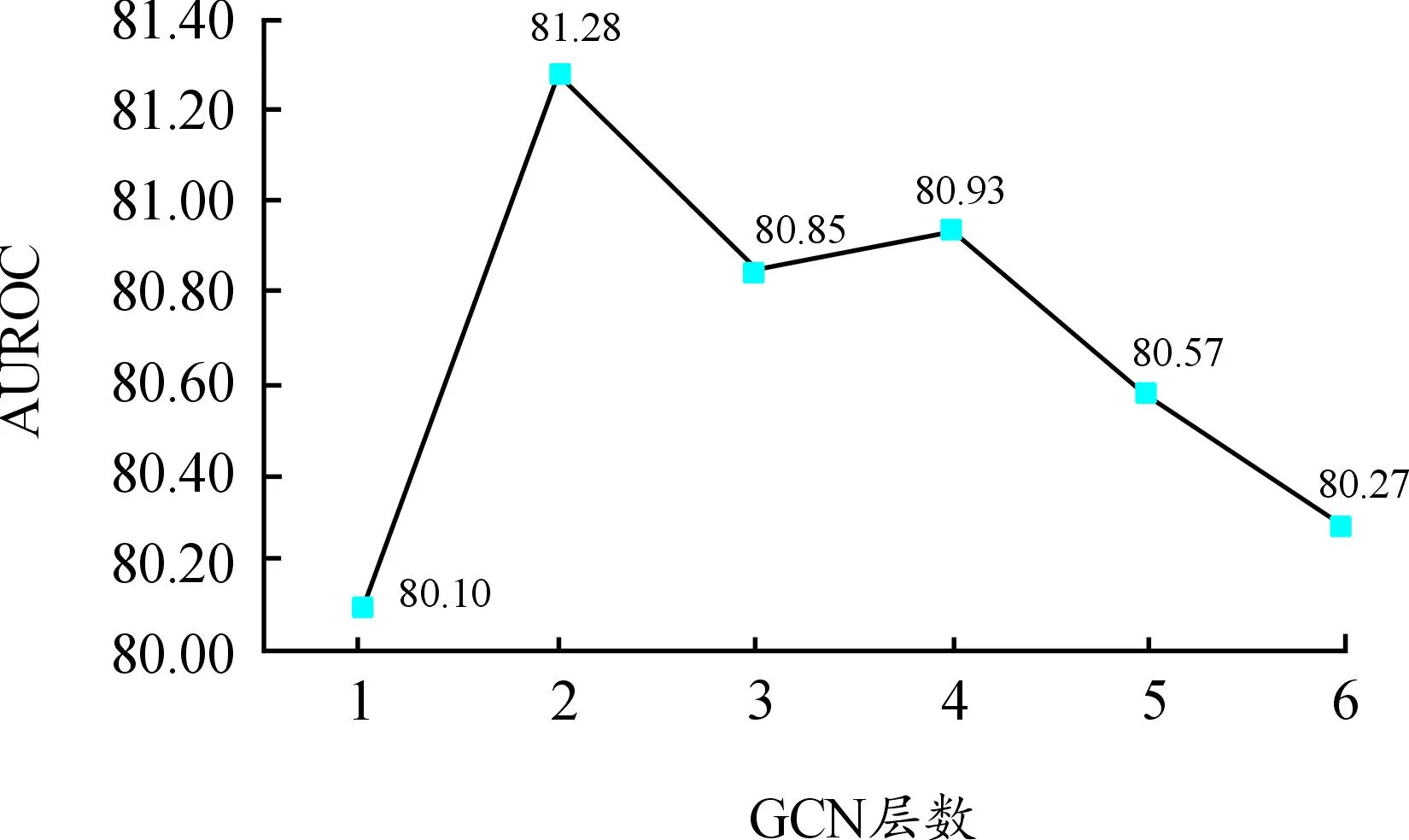
其中:n=len(S),表示迷因文本的长度,当i 综上所述,跨域图构建主要包括3个方面: 1) 对于文本模态,一些仇恨情感是通过多个单词组合表达的,所以通过句法依赖树来建模这种关系。 2) 设计了2个指标来评估跨域联系。用Sim衡量2个单词之间的相似度,相似度越大,边的权重越大。ξ描绘2个单词的消极情感表达,其中γ>1,如果2个单词情感越消极,情感系数越大,模型更关注消极情感。 3) 为了增强模型对于迷因文本模态和网络实体模态之间的跨域联系的关注,在邻接矩阵的跨域边上加1,使得跨域边的系数大于域内边的系数。用于描述文本和网络实体关系的跨域邻接矩阵A输入到2.4节的图卷积网络跨域融合部分。 本小节包括2个部分,第一部分使用2.1节的迷因文本隐层表示和网络实体隐层表示作为跨域图的节点,使用邻接矩阵A进行跨域图卷积;第二部分将融合了网络实体信息的文本表示与2.2节的图像模态表示通过交叉注意力机制进行跨模态融合。 对于每个迷因,使用图卷积来整合网络实体模态和迷因文本模态,利用跨域图中节点的联系来提取仇恨信息。具体地说,将每个实例对应的跨域图邻接矩阵A和特征表示R送到多层GCN中得到图表示。 GCN中第一层结点利用迷因文本和网络实体的隐层表示进行初始化,GCN中第l层节点的隐层表示根据跨域图的邻接矩阵和第l-1层结点的隐层表示得到,数学表达为: G0=R={w1,…,wn,wn+1,…,wn+e} (11) (12) 对于图像模态和增强的文本模态之间的交互,使用基于检索的注意力机制来从图像模态和增强文本模态中捕获仇恨信息,数学描述为: (13) 其中:m为图像中包含的图像块个数;gi作为交叉注意力的Q;rt作为交叉注意力的K、V。计算加权特征表示得到仇恨特征表示为: (14) 仇恨特征表示经过一个全连接层和Softmax归一化得到仇恨标签的分数,数学描述为: y=softmax(Wof+bo) (15) 其中:y∈Rdh是模型的最终输出结果,dh为仇恨识别任务包含的标签个数;Wo∈Rd×dh,bo∈Rdh是可训练参数。 3.1.1数据集合评估指标 使用2个仇恨迷因评测的数据集:一个是Hateful Memes数据集,包含了12 140条迷因和迷因中出现的文本;另一个是Semeval2022评测任务五的MAMI数据集,包含了11 100条数据。Hateful Memes数据集使用评测时的数据集划分方式对MAMI数据集、训练集和验证集进行了重新划分。表1和表2分别给出了2个数据集的统计信息。 表1 Hateful Memes数据集统计信息 表2 MAMI数据集统计信息 评估指标:使用评测发布时的评估指标作为实验评估指标。Hateful Memes数据集使用准确率Acc和AUROC(receiver operating characteristic)作为评估指标,MAMI数据集使用准确率和Macro-averageF1值作为评估指标。 3.1.2 基线模型设置 选取多个单模态和多模态模型进行对比实验,验证所提出模型的有效性。主要对比模型如下: Image-Region模型:使用Faster-RCNN提取目标特征,然后经过一个全连接层和softmax函数获取分类结果。 BERT模型:使用基础的Bert-base对输入序列获取词嵌入,通过自注意力机制获取上下文相关的语义表示,使用句首CLS位置向量作为句向量,将句向量送到分类器进行分类。 多模态模型:使用多个近年来经典的VLP模型及不同大小的变体。VisualBERT[33]和Uniter都是经典的单流模型,均使用预训练的语言模型获得语义表示和使用目标检测器获取图像特征表示,2种模态的隐层表示同时输入到多层的Transformer中。 DeVLBert[34]是基于因果的去混淆模型,将后门调整方法融入到多模态预训练模型中,缓解了预训练过程中的偏差问题。 ViLBERT[35]是典型的双流模型,图像和文本在各自的数据流中进行处理,图像使用目标检测器获取图像隐层表达,文本使用BERT获取文本隐层表示,这2个流通过Co-attention模块进行交互。其中,ViLBERT CC和Visual BERT COCO的后缀分别表示预训练模型时所用的数据集。 OSCAR使用目标检测器检测出的目标名称作为图像和文本对齐的锚点,从而简化图像和文本的语义对齐任务。 Erine-ViL加入场景图信息到模型预训练过程中,设定了多个针对场景图信息预测的预训练任务,并加入经典的VLP预训练任务,包括图文是否匹配、掩码预测等。 ALBEF[36]与CLIP类似,使用对比学习的方式进行模型预训练,使模型拉近正样本间距离,增大负样本间距离。 BLIP[37]使用多模态混合的编码器-解码器结构,相较经典的VisualBERT增加了基于图像的文本编码器和基于文本的图像编码器,并使用标题和过滤机制提高文本语料库的质量。 3.1.3 实验参数设置 使用交叉熵(CrossEntropy)作为训练过程中的损失函数,优化器选择adamW。为了降低模型的过拟合程度,采用权重衰减策略,权重衰减系数为0.02。学习率设置为2×10-5,drop out设置为0.1。采用学习率衰减策略,使用余弦衰减,学习率以cosine函数曲线进行衰减,最小学习率设置为1×10-6。为了防止初期的mini-batch学习率较高使得模型提前过拟合,使用warm up策略,warm up的学习率设置为1×10-5。模型训练时,epoch设置为8,batchsize设置为4,图像的分辨率设置为224*224。使用bert base来获取文本的特征表示,隐藏层大小为768,使用截断策略使分词后文本长度不大于512,自蒸馏参数alpha设置为0.4。 3.2.1 实验结果 表3和表4分别展示了所提出的方法在2个数据集和基线模型上的结果。其中,#表示从其他论文中获取的结果。本文提出的结合网络实体的多模态仇恨迷因识别模型优于所有使用的基线模型。 表3 Hateful Memes数据集实验结果 表4 MAMI数据集实验结果 从表3和表4的实验结果可以看出,本文模型在性能方面大幅度领先于Uniter、Oscar等近年来多模态预训练的SOTA模型,并优于这几个模型的large变体,说明加入网络实体和使用图卷积神经网络融合能有效提高模型仇恨迷因识别效果。从表3实验结果可以看出,ERNIE-ViL模型在仇恨迷因识别任务上优于Oscar和UNITER模型。原因在于ERINE-ViL使用场景图获取更多信息改善了语言表征,同时场景知识包含的实体关系有利于模型对图像和文本进行推理,从而得到更好的分类效果。 从表3中Uniter和ERNIE-ViL两个模型不同变体的实验结果可以看出,通过增大预训练语料规模、提高模型参数的方式能够提高预训练模型的特征表示能力,从而提高仇恨迷因识别性能。BLIP和本文模型的性能优于Uniter、ERNIE-ViL,说明基于Transfomer的图像特征提取方式优于基于目标检测的图像特征提取方式。这是由于目标检测提取特征时缺失了背景信息,并且重采样和噪音等问题会影响特征提取的效果。 对比模型在2个数据集上的结果。在Hateful memes数据集上,本文模型较BLIP模型在Acc性能上提高了0.96%;在MAMI数据集上,本文模型较BLIP模型在Acc性能上提高了2.2%。这是因为,在MAMI数据集中使用网络实体表达厌女情感的比例更高,所以模型对厌女类型的仇恨迷因识别提升更大。 从表3和表4的实验结果可以看出,单独使用文本模态效果优于单独使用图像模态,因为迷因的文本情感表达更丰富且信息密度较大,模型更容易识别文本模态出现的情感。单模态模型与多模态模型差距较大,仅依赖单一模态不能准确识别仇恨迷因,需要2种模态的信息并进行合适推理才能取得较好的识别结果。 3.2.2 消融实验 为进一步验证本文所提出方法各个部分在仇恨迷因识别任务上的有效性,对图卷积神经网络、网络实体信息和自蒸馏模块3个部分进行消融实验。实验结果如表5所示。 表5 Hateful Memes数据集消融实验结果 表5的实验结果显示,去掉GCN实验中使用直接拼接的方式进行融合,模型效果有一定下降,这是由于直接拼接的方式进行融合忽略了不同域文本隐层表示的差距,而使用GCN的方式进行跨域融合能够更好地建模文本间和文本与网络实体间的联系,获取更好的文本模态隐层表示,从而提高模型仇恨识别的能力。 当去掉自蒸馏模块之后,模型的识别性能再次下降。这可能是由于使用自蒸馏模型强迫单个模型学习多个视图[38]后,模型可以利用已经被正确分类的数据对少数不能正确分类的预测结果进行优化。 将模型的网络实体信息和自蒸馏模块去掉后,模型与ALBEF一致。对比消融实验中第3个和第4个实验,两者之间的性能差距源于网络实体信息的加入,说明加入网络实体信息能够提高仇恨迷因识别的效果。 3.2.3 图卷积神经网络参数分析 对于跨域融合部分,进行定量实验来分析图卷积神经网络不同层数对实验结果的影响,实验结果如图3和图4所示。 图3 GCN层数对Acc的影响 图4 GCN层数对AUROC的影响 实验结果显示,在所有不同层数的模型变体中,模型的整体性能随层数的增加整体呈先上升、后下降的趋势,因此在本文模型中GCN 层数设置为2。单层的GCN模型效果较差,表明过浅的图结构不能很好地学习仇恨相关特征;当层数大于2时,模型性能趋于下降,可能是由于图的稀疏程度较低,导致很快出现过平滑现象。 针对现有迷因识别方法经常忽视网络实体信息而导致模型仇恨迷因识别性能下降的问题,将网络实体信息引入仇恨迷因识别模型来增强迷因文本表示。为了更好地融合不同域的信息,对于域内节点使用词法分析树构建邻接图的边,对于跨域节点,从文本相似度和消极情感表达多角度评估节点之间的联系,构建图卷积神经网络的邻接矩阵。运用自蒸馏模块来学习数据多个视角的特征,以提高模型对数据的利用率,提高模型对仇恨迷因识别的效果。通过对比试验和消融实验证实了所提出的仇恨迷因识别方法各个部分的有效性。 下一步研究中,将探索把其他仇恨相关信息如种族、人物表情等融入到模型的可行性,并探究使用其他图神经网络(如图注意力神经网络)跨域融合的效果。2.4 多模态融合
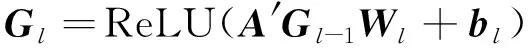
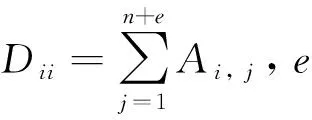
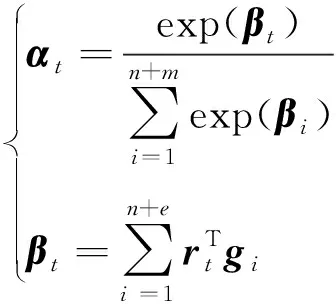

3 实验
3.1 实验设置
3.2 实验结果和讨论


4 结论
