个性化学术论文推荐研究综述
2024-02-04张晓娟刘怡均
张晓娟,刘怡均,刘 杰,陈 卓
(1. 四川大学公共管理学院,成都 610065;2. 西南大学计算机与信息科学学院,重庆 400715)
0 引 言
学术论文是某一领域或学科的研究者在进行科学研究后,以文章的形式对自己的研究内容、方法、实验结果以及结论等的总结与凝练。学术论文可以帮助研究者了解某个学科或领域的最新研究进展、研究现状等,激发其科研动机的出现以及学术灵感的涌现。用户获取学术论文的最初方法是跟踪其所感兴趣论文中的引文,但该方法将研究人员局限于特定的引用群体,偏向于被大量引用的论文,且只能对所感兴趣论文发表之前的论文进行跟踪。作为该方法的补充,基于关键词的论文搜索方法旨在通过关键词检索获取相关论文,但该方法只适合于定向探索,并且用户总是困扰于如何为查找新文献形成恰当的查询,因此,很难为用户返回新的且有趣的文献。在此背景下,学术论文推荐技术应运而生,即在用户不需要提供查询请求的情况下,主动地为用户推荐潜在感兴趣的论文,满足用户对学术论文的多元性与新颖性的需求。由于此技术能有效地化解学术大数据时代下信息过载与用户获取论文之间存在的矛盾,近年来引起了学界的广泛关注与探讨。
学界对学术论文推荐给出了不同的定义,一般会根据所指定推荐系统的输入、推荐结果的目标受众以及推荐结果类型加以概念界定[1]。纵观已有研究发现,学术论文推荐的输入主要包括初始论文[2-4]、关键词[[5-7]、用户[8-9]、用户与论文[10],或者更加复杂的信息,如用户构建的知识图[11]等,所面向的对象是单个用户[12-16]或者多个用户[17-19],推荐所返回的结果类型可能是单篇论文[8]或者论文列表[20-21]。本文所探讨的推荐是输入中至少包含了用户因素的个性化学术论文推荐,最终推荐结果所面向的对象是单个用户而非多个用户,且返回的结果是满足用户个性化需求的论文列表。需要指出的是,本文所探讨的个性化学术论文推荐包括以下两种主要应用场景[22]:一是通过学习用户和项目特征,向用户推荐其潜在感兴趣的学术论文,供用户实现浏览、阅读、收藏等操作;二是在论文撰写过程中,通过学习作者写作内容和风格,向其推荐密切相关的引文论文,又被称为引文推荐。
本文以检索词“学术论文推荐”“论文推荐”“学术文献推荐”“科技论文推荐”“引文推荐”“academic paper recommendation”“scholarly paper recommendation”“scientific paper recommendation”“research paper recommendation”“citation recommen‐dation”等,在Web of Science、Springer、中国知网、维普等数据库以及Google 学术中,不限时间范围地进行标题、主题、关键词的逐步扩展检索,总共获得相关文献160 余篇,通篇阅读每篇文献,最终筛选出与本文高度相关的121 篇文献。对这些文献归纳总结后发现,已有个性化学术论文推荐研究主要注重用户个性化模型构建以及如何将用户模型融合到学术论文的推荐排序中。根据已有的对用户个性化兴趣的不同建模方法,本文将个性化学术论文推荐研究主要分为基于协同过滤的方法、基于内容的方法以及基于图的方法。基于此,本文对3 类方法进行概括与梳理,在此基础上对其数据集、评价方法和评价指标进行总结。最后,对个性化学术论文推荐的未来发展方向进行展望。当前已有相关文献[1,23-25]对学术论文推荐的相关工作进行了综述,相对于已有文献,本文的不同之处在于:①本文只探讨个性化学术论文推荐的相关技术,且重点探讨已有研究如何对用户个性化信息建模以及将其融入论文推荐模型中;②从不同视角对已有研究进行归纳与总结。
1 基于协同过滤的个性化学术论文推荐
任何协同过滤算法的有效性均基于人类偏好是相关的这一基本假设[26]。作为个性化学术文献推荐领域常用的实现方法,基于协同过滤的方法是基于群体智慧,在利用用户群体偏好所暗含关联的基础上建立用户模型,实现个性化推荐。根据对用户个性化信息的不同建模方法,此类方法的实现主要有基于用户的协同过滤与基于模型的协同过滤。
1.1 基于用户的协同过滤方法
作为一种矩阵内预测方法(in-matrix predic‐tion),基于用户的协同过滤方法的目标是为用户推荐其并未交互过但是至少被其他一个用户交互过的文献,这也是传统协同过滤探讨的问题。如图1a 所示,在为用户1 推荐相关论文时,候选论文只能是出现在评分矩阵中的论文,即应是被用户2、3、4、5 曾交互过的论文。具体而言,该方法根据用户的一些人工显式标注数据或一些隐式用户行为数据,如引用行为、下载行为、阅读行为、查阅行为等,来构建表征用户兴趣的用户-论文矩阵,再利用余弦相似度或者皮尔逊系数等计算用户相似度,最后将与目标用户相似度高的其他用户所喜欢的且目标用户并未交互过的论文推荐给目标用户。
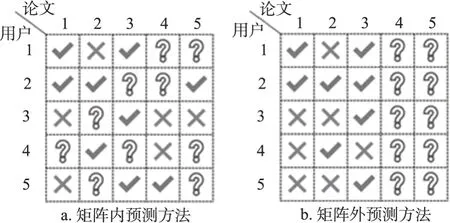
图1 两类协同推荐方法的示例
因在实际场景中用户对论文进行显式评价的参与度很低,故已有研究中主要是基于用户隐式评价信息构建用户-论文相似性矩阵。根据在构建此类矩阵时所考虑的隐式数据,此类研究主要归为以下两种方法。
(1)基于简单隐式数据的方法
作为学术论文推荐的早期方法,基于简单隐式数据的方法主要采用用户阅读文献的页数[27]、用户下载论文次数[26]、用户对文献资源的学习次数[28]、用户对文献的引用次数[29-31]等隐式评分来构建用户-论文矩阵,实现个性化推荐。此方法简单、容易实现,但只采用了少量可以表明用户偏好的可观测数据,容易为推荐过程带来数据稀疏或冷启动的问题。
(2)融合用户之间信任关系的方法
考虑到协同过滤中用户之间并非完全独立,而存在一定关联关系,有些学者尝试在计算用户相似度时,除考虑用户评分相似性之外,也融合用户之间的信任关系,以此来融合具有间接邻居的排序信息。例如,Liu 等[32]构建了基于序列的信任模型,并将该模型融合到协同过滤推荐系统中;Jamali等[33]提出在用户信任网络中的游走方法,该方法不仅考虑目标项目的评级,还考虑类似项目的评级,最终实现基于信任和基于项目的协同过滤;李默等[34]在协同过滤中融合相似性评价、信任度与社会网络的方式,并采用AHP (anlytic hierarchy pro‐cess)方法分析了3 种推荐策略对不同类型用户的相对重要性权重。
从整体来看,基于用户的协同过滤在无需知道待推荐论文内容的情况下就可实现推荐,并且考虑了用户对项目的真实质量评估信息,推荐结果也具有一定新颖性。但此类方法存在如下问题:①需利用所有的用户数据来进行计算,当数据量大时存在计算复杂度大的问题,也会使推荐系统面临严重的模型可扩展性低的问题;②存在着冷启动问题,即难以为新入门学术用户或者对新发表论文实现推荐,如图1b 中的文献4 和文献5 并未出现在用户评分矩阵中,即未被任何用户评分过,若采用传统协同过滤方法,则难以将这两篇文献推荐给用户。
1.2 基于模型的协同过滤方法
为了解决基于用户协同过滤模型中的问题,例如,将图1b 中的文献4 和文献5 向用户进行有效推荐,学者们提出了基于模型协同过滤方法,借助用户与论文之间的部分评分数据,预测用户对论文的偏好[35-40]。该方法是一种矩阵外预测(out-matrix prediction)方法,即为用户推荐并未出现在用户的评分矩阵中的文档,以此来解决新发表论文的冷启动问题。其中,常用的矩阵分解方法主要有基于隐因子矩阵分解的方法、基于概率矩阵分解的方法以及基于神经矩阵分解的方法。
1.2.1 基于隐因子矩阵分解的方法
隐因子矩阵分解的实现原理如图2 所示。其中,R表示用户对论文的评分矩阵,U和V分别表示矩阵分解模型后得到的用户和论文的隐式特征因子。具体而言,在矩阵分解中,首先将用户和论文表示为一个共享的低维隐式的K维向量,ui表示用户i的向量,vj表示文献j的隐式向量。用户i对论文j的偏好主要是通过计算两个向量的内积进行预测,即

图2 隐因子矩阵分解的原理
论文推荐系统中全部用户和项目的隐式向量组成了隐式特征矩阵U与V,故用户的评分预测矩阵为
此类模型的求解就是如何利用已知的用户评分数据R͂训练出用户和项目隐式因子特征矩阵U和V。即先初始化向量U和V中的值,再最小化给定的损失误差函数,目标是将训练集中预测评分和实际评分之间的均方误差最小化。
基于此方法的主要研究如下。戴大文[35]构建了包含用户浏览信息的用户-偏好矩阵、包含引用关系的论文-论文引用矩阵、包含论文摘要信息的论文-论文相似度矩阵,并进行矩阵分解同时优化求解,获得用户潜在特征矩阵、论文潜在特征矩阵、论文因子矩阵,再对这3 类矩阵进行优化求解得到基于用户偏好的学术论文排序。考虑到学术论文领域每年大量新文献产生了协同过滤中用户排序数据稀疏的问题,Mohamed 等[36]采用层级注意力模型(hierarchical attention network),通过对论文中的标题和摘要进行嵌入式表示来实现标签预测,然后将标签感知的文档表示合并到矩阵分解框架中,以此为用户获得文档排序。马慧芳等[37]在经典矩阵分解算法的基础上,融合作者与文献影响力来实现推荐。吴燎原等[38]进一步通过科研社交网站中的好友列表生成用户矩阵,再根据论文的主题分布得到论文之间的相似矩阵,然后分别以用户和论文正则化项的形式融合到改进后的like-wise 方法中实现个性化推荐。Zhao 等[39]首先利用用户的历史行为(收藏夹记录)构建用户-文献评分矩阵,并对该矩阵进行分解得到用户和文献的初始潜在特征向量,再将传统隐式因素模型与双向门递归神经网络结合,深入挖掘文本非结构化内容中的潜在语义,生成新的文献潜在语义向量,并用于替换从最初用户评分矩阵中分解得到的初始的文献潜在特征向量,生成一个新的评分矩阵,最后根据用户的隐式因子变量生成推荐列表。李志[40]利用深度学习中的BiLSTM(bidirectional long short-term memory)网络学习论文中的文本信息,获得论文项目隐表式,然后结合隐因子矩阵分解模型拟合用户评分矩阵,提升用户对论文隐式反馈评分预测的准确度。吴俊超等[41]提出基于卷积协同过滤的学术论文推荐,即在矩阵分解的基础上,利用三维卷积神经网络学习用户与论文不同特征的高阶交互关系来实现推荐。Ren 等[42]利用张量和矩阵对论文链接关系以及研究者之间的社交网络多重关系建模,并在此基础上提出了一种联合多种关系的因子分解算法,以此来预测用户对新发表文献的偏好。
与传统的协同过滤方法相比,基于隐因子矩阵分解的方法能融入更多的用户和文献的特征,提升最终推荐的准确度。但该方法存在如下缺陷:在该方法中获得的用户隐因子与论文隐因子中每个维度并不能与任何一个可解释的语义关联,因此,该模型是一个黑箱模型,相对于传统协同过滤方法,此方法的预测结果缺乏可解释性。
1.2.2 基于概率矩阵分解的方法
概率矩阵分解的原理如图3 所示。该模型将协同过滤过程建模为概率模型,假设用户潜在特征矩阵和项目潜在特征矩阵均服从某一分布,从概率生成角度解释用户和论文隐式因子。其中,Ui表示用户i的隐式特征向量,Vj表示项目j的特征向量,Rij表示用户i对项目j的评分值,σU和σV是Ui和Vj对应的参数。

图3 基于概率矩阵分解的模型图
根据在模型中所融合的信息类别,此类方法主要分为两类。
(1)融合深度挖掘的文献内容的方法。该方法中的常用模型是Wang 等[20]提出的协同主题回归模型(collaborative topic regression,CTR),即利用潜在主题空间将协同过滤和主题模型融合到一个概率模型中,获得用户和项目的可解释的潜在结构,并以此实现对已有以及新发表文献的推荐。为了在此模型中进一步融入用户对研究热点的偏好,李冉等[43]提出一种基于频繁主题集偏好的协同主题回归模型,即利用LDA(latent Dirichlet allocation)主题模型,从用户阅读文献挖掘出论文-主题概率矩阵,并筛选论文中概率较高的主题,进而得到主题-频繁主题概率矩阵;利用基于频繁主题集偏好的主题回归模型预测未知评分时,对包含频繁主题的论文给予偏重,以此实现推荐。Purushotham 等[44]利用社交矩阵分解方法将用户之间的社交网络信息融合到CTR 模型中。Wang 等[45]对其进行扩展,提出了关系协同主题回归模型(relational collaborative topic regression),即将用户-项目之间反馈、论文内容和网络结构信息合并到一个分层贝叶斯模型中,且该模型包含的一系列关系概率函数可用于模拟论文之间的关系;实验证明,该模型在预测精确度以及计算成本方面均优于CTR 模型。刘智超[46]根据研究人员收藏的论文信息提出一个主题模型ACTOT(au‐thor conference topic over time),先计算其兴趣主题特征,再将用户的主题向量和论文的主题向量与概率矩阵分解模型中用户隐式因子向量和论文的隐式因子向量结合,最后实现论文推荐。考虑到以上拓展的CTR 模型均难以为评分数据较少的用户进行预测,也无法生成与特定任务相关的推荐,黄泽明[47]根据用已读论文的评分来获得用户对不同主题的需要程度,并以主题的评分构建用户特征,提升推荐结果的惊喜度。除了以上基于CTR 及其拓展模型的相关研究外,有学者尝试利用深度学习方法挖掘文本内容,并将其融合到概率分解模型中。例如,Alfarhood 等[48]利用联合概念矩阵分解时综合考虑了文献的内容信息,并且提出利用协同注意力自动解码器(collaborative attentive autoencoder) 学习文献中的隐式因素;屈冰洋等[49]首先利用堆叠自动编码机(stacked denoising autoencoder,SDA)模型提取用户特征,再融合注意力机制的BiLSTM 网络提取文献特征,最后在概率矩阵分解中,融合用户特征矩阵和文献特征矩阵,从而实现预测学者的学术文献偏好。
(2)融合文献外部信息的模型。除了文献主题外,有些学者尝试将文献信息(如研究员标签信息、社交信息等)融合到概率协同过滤模型中。例如,吴磊等[50]根据科研人员标签与未读论文之间的相似度抽取添加负例数据,然后融合论文相似度以及科研人员标签信息进行联合概率矩阵分解,在概率矩阵分解阶段融合科研人员-标签关联矩阵以及论文相似度信息进行约束,以缓解数据稀疏对最终结果的不利影响;Wang 等[51]提出了将朋友关系信息融合到协同过滤方法中,以解决由于数据稀疏而导致的推荐精度低的问题,改进的协同过滤方法在3 个阶段实现——研究者文章-矩阵形成、社交朋友-矩阵形成和统一概率矩阵分解,最终实现个性化推荐;吴燎原等[52]认为,科研社交网络中存在大量兴趣爱好相同且研究领域相似的群组,在联合概率矩阵分解的基础上,融入了用户给论文所添加的标签信息以及用户加入的科研群组信息,提出一种科研社交网络中基于联合概率矩阵分解的论文推荐方法。
总之,概率矩阵分解方法是当前个性化学术文献推荐的主流矩阵分解方法。相对于隐因子矩阵分解方法,概率矩阵分解方法能够处理更大规模且失衡的数据集,还能更容易地应对评价信息较少的用户。但概率矩阵分解模型存在如下问题:①该模型的内部工作原理难以理解,推荐结果缺乏可解释性,仍是一个黑盒模型;②概率矩阵分解模型的执行通常以假设用户的评分数据服从正态分布为前提,然而实际所获取的数据并不完全满足此前提条件,因而影响着模型的最终推荐准确度。
1.2.3 基于神经矩阵分解的方法
神经矩阵分解的方法是将传统矩阵分解中的内积操作与神经网络结构结合,可以进一步捕捉非线性特征和更多特征组合。该方法的基本原理如图4所示。其中该模型每层的输出层均可以作为下一层的输入层,最开始的输入层分别是由表示用户和项目(文献)的向量组成;用户与文献之间的交互关系体现在神经协同过滤层。目前,此方法在学术文献推荐中的应用还不够广泛,有限的相关研究主要有:陈雨民等[53]通过预训练BERT 模型获得论文标题摘要中的向量表示,并且提出标题摘要注意力机制捕捉标题摘要之间的语义关系,最后结合改进的神经协同过滤模型处理用户-论文隐反馈信息实现推荐;马骁烊等[54]提出了基于标签卷积神经网络的推荐模型,结合神经网络和协同过滤技术的同时,将标签加入神经网络的设计中,以此辅助特征提取,从而实现用户对论文偏好的预测。
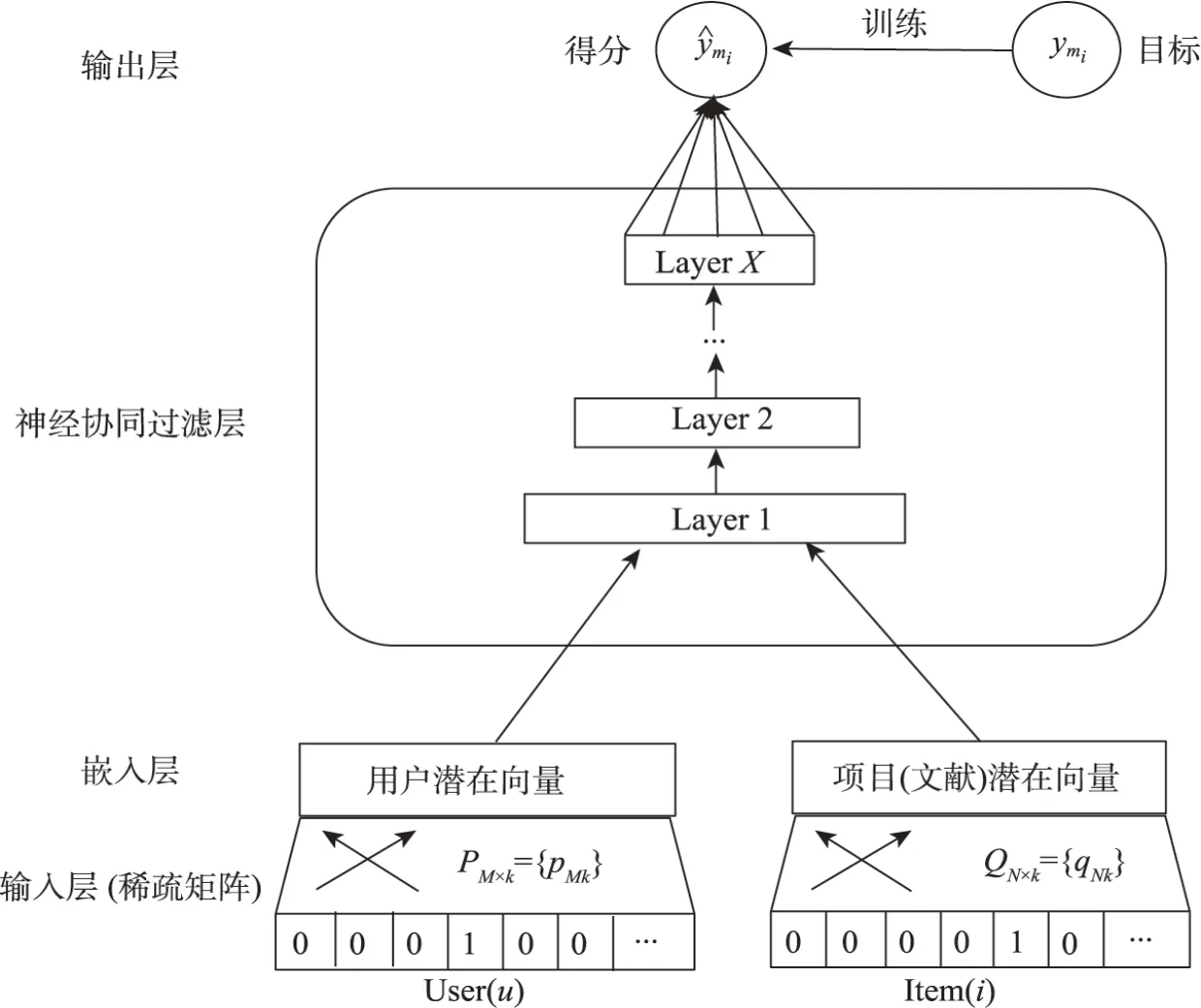
图4 神经矩阵分解的基本原理
虽然神经矩阵分解方法在当前个性学术文献推荐领域应用较少,但因其在融合海量的多模态数据(如文本数据、图片数据)、高阶复杂的交互关系、时序建模等方面所体现出的优势,将会是未来个性化学术文献推荐领域考虑的主要协同过滤技术。
2 基于内容的个性化学术文献推荐
该方法主要根据用户与系统交互过(如阅读、引用或者收藏等)的项目内容特征来构建用户兴趣模型,再根据候选学术论文与用户兴趣之间相似度来实现个性化推荐。根据构建用户兴趣模型时采用的不同特征,此类研究又可细分为基于词向量特征、基于文本语义特征、基于用户知识背景特征以及基于时态特征的方法。
2.1 基于词向量特征的用户模型构建
作为基于内容的最早期方法,此方法主要借助用户发表或者引用文档内部或其他外部信息中的词表征用户偏好,利用TF-IDF (term frequency-in‐verse document frequency)方法将其表示为向量空间模型(vector space model,VSM),再通过计算用户与候选论文之间的向量相似度实现个性化推荐。根据个性化信息的不同来源,此类方法又可分为两类。①基于文档中词的方法。通过用户所发表[55-57]或引用[58]文档中论文标题、关键词、摘要等信息,构建用户伪文档与候选论文的向量,再根据余弦相似度获得个性化推荐。②融合其他外部数据的方法。为了进一步丰富用户个性化信息,有些学者尝试利用多种外部数据,如用户标签[59-60]以及其他外部资源[61-62]等来表征用户偏好向量并实现推荐。
基于词向量表示的方法能在一定程度上表征用户和论文特征,但此类方法中单词通常被视为孤立元素,不能较好地表达用户兴趣和文献的语义内容,忽略了多义词以及概念之间关系对推荐结果的影响。
2.2 基于文本语义特征的用户模型构建
为发现文档间的潜在语义关联,并解决一词多义、异形同义等问题,也有学者尝试利用主题模型或者深度学习模型,如word2vec、doc2vec 等对用户伪文档进行潜在主题(语义)分析,即将文档高维的词频空间映射到低维的主题(语义)空间,以提升个性化推荐的准确度。
2.2.1 基于主题模型的方法
此类方法主要是借助LDA 模型对文献与表征用户兴趣的文本进行潜在主题分析并实现推荐。根据实现的推荐目的,此类方法又可细分为基于主题相似度的推荐、满足用户惊喜(serendipity)的推荐和跨领域的推荐。
(1)基于主题相似度的推荐。此类研究主要探讨如何返回与用户偏好主题相似的学术论文。例如,杜永萍等[63]利用LDA 模型,将候选文献与用户所发表文献表示成潜在主题向量,再利用Apriori算法挖掘出频繁出现的高效能主题集合,即研究热点,然后根据候选文献与用户所发表文献中高效能主题的分布相似度来返回用户感兴趣的学术论文;Amami 等[21]利用已发表或合作发表论文中的摘要来构建用户伪文档,并利用LDA 模型获得该文档中每个主题下的词的概率分布,进一步将待推荐论文利用语言模型来表示为词概率分布,通过计算论文中词概率分布以及伪文档中主题下词概率分布的相似性来实现推荐;李晓敏等[64]分别利用TF-IDF 算法、TextRank 算法和LDA 模型得到学术论文和核心作者的特征词,利用word2vec 对特征词进行向量化,计算核心作者和学术论文的余弦相似度。以上研究只为学者构建了单一的用户模型,未考虑学者有多个兴趣的情况,于是陈金鹏[57]提出基于频繁模式的学者兴趣模型,利用LDA 处理用户兴趣集,采用FP-growth(frequent pattern - growth)算法从处理结果中挖掘一个频繁模式集,通过简化该频繁模式集来建立相应兴趣模型。
(2) 满足用户惊喜(serendipity) 的推荐。此类研究在对文献集进行主题分析基础上,借助一些主题多样方法为用户推荐相关且具有惊喜(出乎其意料之外)的学术论文[65-66],以此提升推荐结果的吸引力与有用性。例如,黄泽明[47]利用CTM(cor‐related topic model)关联主题模型挖掘不同主题间的关系,根据主题间的关联程度实现推荐,从而提升推荐结果的惊喜度;为了提高推荐论文中知识的多样性和惊喜度,李响等[67]提出一种基于潜在语义分析(latent semantic analysis,LSA)和最大边缘相关性的方法,从学者研究兴趣与待推荐文献的语义相关性、待推荐文献集合的主题多样性以及影响力3 个维度为用户推荐具有惊喜的论文;刘旭晖[68]先获得特定专家所发表论文的摘要数据,然后利用LDA 模型获得文献与用户兴趣之间的主题相关性,并进一步考虑待推荐文献的主题多样性以及影响力,最终得到具有惊喜的推荐结果列表。
(3)跨领域的推荐。此研究在对文献进行主题分析的基础上,构建不同(学科)领域之间语义关联性,以此实现为学者推荐不同领域的文献。例如,Xie 等[69]提出了利用层级监督式生成模型(hi‐erarchical supervised latent Dirichlet allocation) 来学习词与现有学科分类(领域语义)之间的概率关联,利用影响函数、相关性指标以及排序机制表示领域之间的语义相关性,最后将待推荐论文内容与用户兴趣表示为目标领域中的概率分布,并实现跨领域的学术论文推荐;Ravi等[70]构建了一个基于用户正在阅读的新闻文章内容进行学术论文推荐系统,即利用RNN-LSTM(recurrent neural network - long short-term memory)模型,通过测量推荐论文与输入文档之间潜在的语义相似度,向用户推荐相关论文。
LDA 模型虽然在一定程度上提升了用户偏好或者论文的特征表示的准确度,并且能实现推荐结果的惊喜度以及跨领域推荐等,但LDA 模型是以忽略了词序的词袋数据作为输入,忽略了词的上下文信息,故只能发现文本的浅层次语义,影响最终推荐的准确度。基于此,一些学者在LDA 模型的基础上,结合学术论文的作者、发表时间、发表期刊、会议等信息提出了诸多拓展的模型,相关模型的具体信息以及在个性化学术文献推荐中的潜在应用如表1 所示。
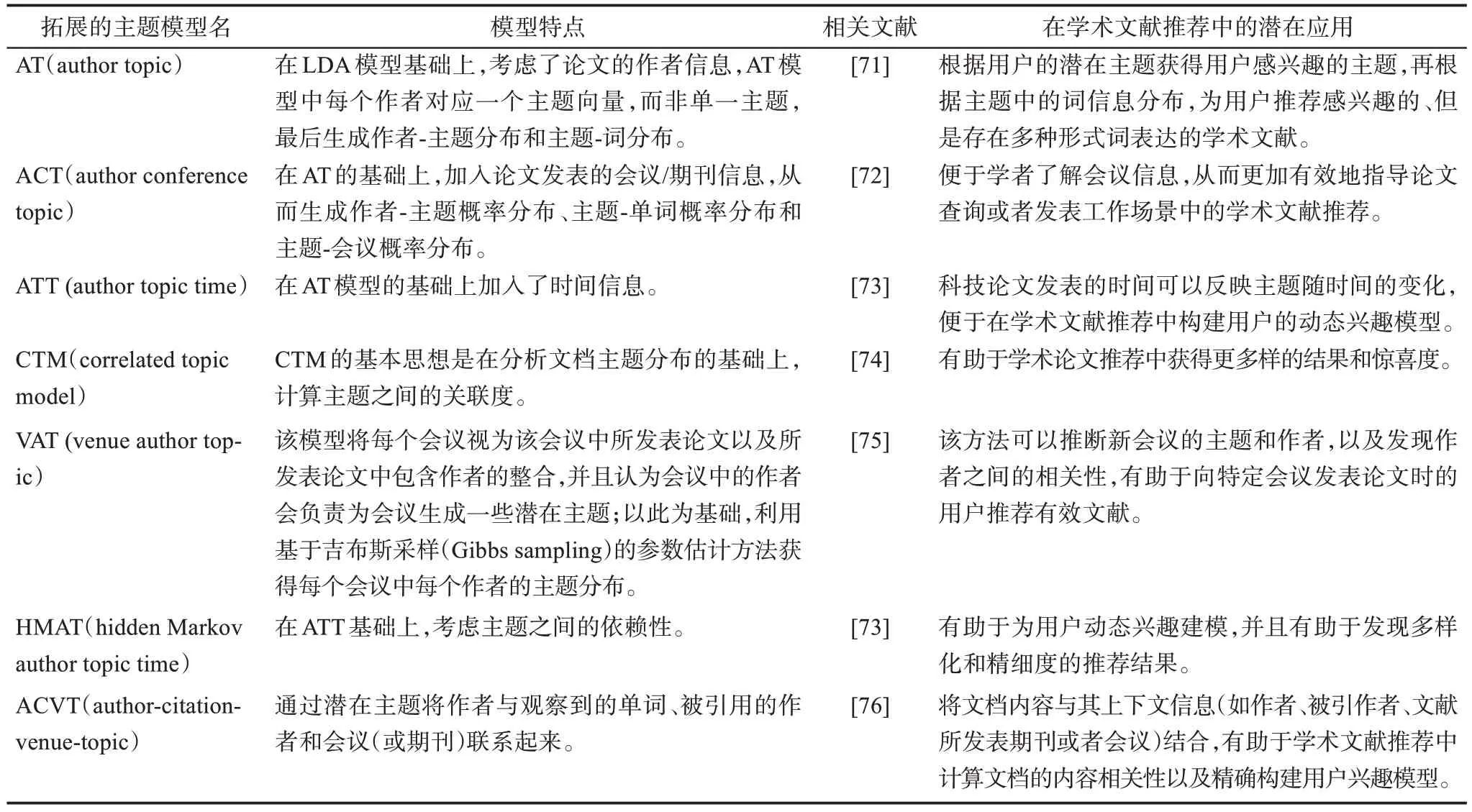
表1 基于LDA的拓展模型
2.2.2 基于深度学习模型的方法
为突破主题模型中存在的瓶颈,学者们借助深度学习模型对学术论文的文本序列进行挖掘,融合上下文关系,增强用户与论文特征的提取。例如,Hassan[77]在构建用户伪文档时,综合利用用户明确指定的感兴趣论文的标题和摘要信息,以及用户在PubMed Central 查询时浏览的摘要与点击的全文信息,分别利用递归神经网络(recurrent neural net‐work,RNN)发现论文中连续和潜在语义特征,获得候选论文和用户伪文档向量,最后根据向量相似度实现推荐;王妍等[13]融合深度学习方法,引进了词向量模型,将论文和用户转换为词向量空间,并利用WMD (word mover distance) 计算两者相似度,进而实现个性化推荐;Guo 等[8]利用研究者发表的论文构建伪文档,认为论文标题和摘要之间存在语义关联,基于此,提出了标题-摘要注意力记忆网络,该网络可以从句子级别和单词级别捕捉摘要与标题之间的语义关联,并通过连续句子模式对用户和候选论文进行建模,从而实现个性化推荐;Yang 等[78]提出了基于注意力的编码器-解码器(at‐tention-based encoder decoder,AED)模型,实现了局部引文推荐,该模型先建立了一个编码器,并将引文上下文表示为低维向量空间,然后构建了一个发表论文的期刊(或会议)信息和作者信息的注意力机制,再利用递归神经网络(RNN) 构建解码器,最后将解码器的输出映射到softmax 层,根据给定的引文上下文、作者信息和期刊(或会议)信息等对候选论文进行评分。
总体来说,深度学习强大的语义表征能力为提取用户和学术论文深层次特征提供了支持,但目前此类方法仍将学术文本视为普通文本,未考虑到学术论文的特殊篇章结构信息。另外,此类方法通常只采用用户历史发表文献信息来表征用户兴趣,如何利用深度学习挖掘更多表征用户偏好信息(如用户行为序列、用户社交关系等) 是后续的研究重点。
2.3 基于用户知识背景特征的用户模型构建
与其他资源不同的是,学术论文是用户获取知识的目标知识源,因此,学术用户一般根据其背景(领域)知识即知识储备来获取相关文献[79],于是有些研究者认为用户背景知识特征也是个性化论文推荐时需要考虑的重要用户因素。其中,此类研究主要根据用户研究目标描述、用户阅读记录或者发表论文表征用户背景知识,利用领域类目体系、本体或者概念网络形式对用户领域背景知识与文献中的知识进行建模,通过计算学术文献中的新知识与用户背景知识的关联程度来实现推荐。例如,Zhao等[80]在实现论文推荐时,为了减少研究者背景知识与研究目标之间的知识鸿沟,先将领域知识表示为概念地图的形式,从领域语料中抽取核心概念,构建知识之间关联,再通过分析学习者的阅读记录对其领域知识进行建模,且从研究者的研究计划中抽取目标知识,最后从知识地图中抽取这两类知识之间的最短距离,以此实现推荐;刘康[81]先根据用户阅读文献和研究目标的描述,构建包含用户背景知识和研究目标知识的两层用户知识模型,利用LDA和CTM 模型对学术论文进行主题(知识) 分析,并在知识图谱中加入概率模型形成了不确定知识图谱,构建知识之间的关联程度并实现推荐;谭红叶等[82]提出一种基于知识脉络的学术文献推荐,即以论文中的关键词为核心,分别从字形以及语义层面抽取关键词之间的同义关系、上下位关系以及共现关系等,以关键词为节点,并以关键词之间的语义关系构建论文知识脉络,最后以论文关键词作为用户兴趣的显著标识,将用户和论文资源分别表示为关键词向量,借助论文知识网络计算用户与论文之间关键词向量的语义相似度,从而实现个性化论文推荐;Kuai 等[79]提出了一种知识驱动的个性化文献推荐方法,即在深层学术论文语义辨析的基础上,先利用主题词聚类和领域标签实现对文献的概念分析与知识推理,构建了跨领域知识地图,再利用深度语义识别算法计算用户知识需求(利用用户提交关键词所返回文档与所构建的知识地图分析主题信息而获得)与文档之间的知识相似性,最后实现个性化推荐。
此类方法能在一定程度上提升用户对推荐结果的满意度,但目前研究对文档的知识抽取主要来源于论文关键词和摘要。摘要和关键词虽然能对文献高度概括,但并非一定能体现文献的核心知识。未来研究需通过挖掘文本中句子复杂的语义关联,构建句子之间的复杂文本语义网络识别其核心知识,并在此基础上,通过构建用户、核心知识与学术文献之间语义关联来实现推荐。另外,此类研究对用户背景知识建模主要停留在单一的历史行为,后续研究可考虑如何进一步结合学习理论中的建构主义观以及认知学习理论[83]对用户知识背景建模。例如,从建构主义观,考虑如何对用户已掌握的知识与文献中的新知识建立逻辑关联,促进学术用户进行有意义的学习;从认知学习理论,考虑如何从心理角度对用户认知需求、认知风格进行测量,以此来丰富用户知识背景。
2.4 基于时态特征的用户模型构建
此类方法主要是借助用户伪文档中的时态特征(如文献发表时间、用户历史行为发生时间等)实现满足用户动态需求的个性化推荐的目的。主要采用的方法有基于时间衰减函数的方法和基于序列模型的方法。
(1)基于时间衰减函数的方法:该方法认为用户的兴趣会随时间而动态变化,且最近的用户历史行为更能体现其当前偏好,故采用时间衰减因子对不同时间段用户历史行为进行加权,从而实现个性化推荐。常用的时间衰减函数信息如表2 所示。

表2 个性化学术论文推荐中常用的时间衰减函数
(2) 基于序列模型的方法:根据用户历史行为,利用序列模型对序列中项目的相对顺序以及时间间隔和持续时间进行建模,预测用户的未来兴趣。例如,Chaudhuri 等[22]为了对用户的动态意图建模,先利用由LDA 和word2vec 组成的混合模型为每篇论文确定一个主题,再利用序列LSTM(long short-term memory)模型,根据用户历史所交互论文的主题以及用户连续点击两篇论文之间的时间差对用户的动态意图进行建模;Wang 等[89]提出了融合嵌入层、耦合输入与遗忘门的LSTM 模型(inter‐val- and duration-aware LSTM with embedding layer and coupled input and forget gate,IDLSTM-EC),该模型能感知序列行为中的间隔和持续时间,能利用时间间隔和持续信息来准确捕获用户的长期和短期偏好,且该模型结合了输入层中序列的全局上下文信息,可以更好地利用长期记忆;Ma 等[90]为了实现按时间顺序的引文推荐,利用多层感知器模型对不同时间片段中用户引用文献的概率分布建模来预测用户对引文的时间偏好,然后利用时间偏好信息对基于内容过滤获得的初始引文列表进行重排序,从而生成最后的引文推荐列表。
由以上文献分析可知,已有对学术用户动态需求建模的研究主要依赖于用户历史数据。随着新技术和新主题的发展,学术用户可能随时产生与历史偏好不同的兴趣,仅借助历史数据难以对用户新兴兴趣进行建模。因此,未来研究需考虑如何选取能捕捉用户新兴兴趣的外部资源,并建立用户与其之间的关系,以此对用户潜在的新兴兴趣进行探测,并将预测结果融合到推荐模型中。
3 基于图方法的学术论文个性化推荐
基于图的方法尝试利用图中节点关系和知识关联,如科研者之间合作关系、引用关系等,来发现学术论文之间以及用户与学术论文之间的多维关系,提升个性化推荐的准确度。根据图中捕捉用户个性化信息所采用的不同方法,此类研究可细分为基于重启式随机游走的方法、基于元路径的方法以及基于图嵌入式的方法。
3.1 基于重启式随机游走的方法
在构建异构网络图的基础上,将用户信息融合到表示重启式随机游走(random walk with restart,RWR)起点来实现个性化推荐。其中,RWR模型的计算公式为
其中,M表示图中各类实体之间的转移概率矩阵;q0表示初始矩阵;β表示重启概率;r(t)表示随机游走到第t步时访问节点i的概率。如式(3)所示,迭代应用RWR 模型中的随机游走器直至收敛,即下一状态r(t+1)和最后状态r()t之间的差值小于给定的收敛值阈值,此时达到了收敛的稳态c。最后,对r(c) 中论文节点的稳态值进行降序排列,将排名靠前的论文视为查询q0返回的推荐结果列表。其中,如何设置转移概率矩阵M和初始矩阵q0,是此类方法需探讨的重点问题。已有文献对这两个问题的研究汇总如表3 所示。
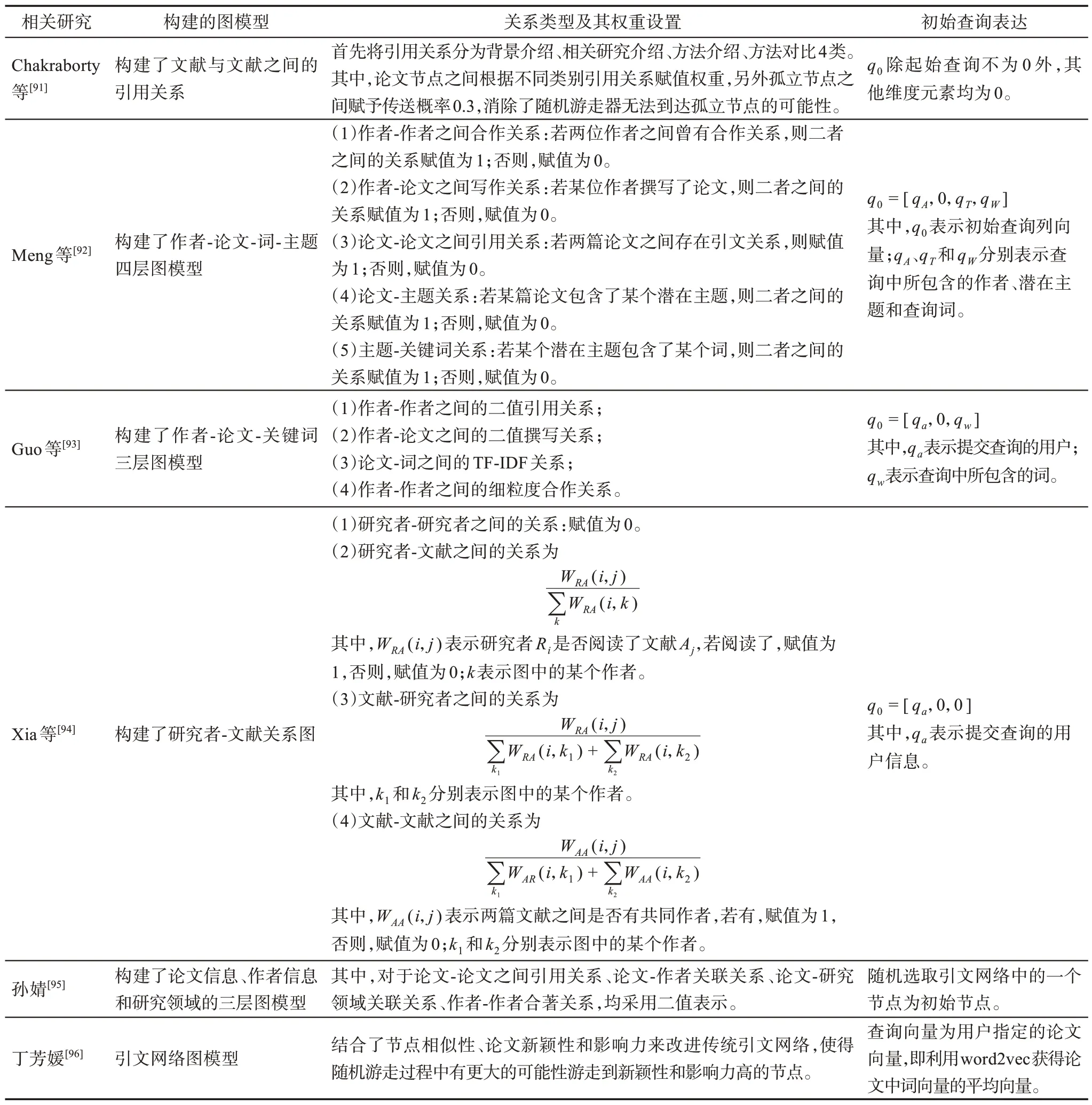
表3 基于随机游走的相关方法
整体来说,随机游走方法能获得丰富的交互网络,并且利于发现用户与文献之间的间接联系。但是,随机游走方法存在如下缺陷:往往存在对发表年限较长论文赋予过高权重的问题,难以实现对新文献的推荐;随机游走在大规模图中存在效率低的问题,由于需要参数优化推荐流程,会面临由参数原因导致推荐结果差的问题。
3.2 基于元路径的方法
元路径(meta path)是定义在网络模式TG=(A,R)中的一条路径表示节点类型Ai和Ai+1之间建立关系R,其中R=R1°R2°…°Rl表示关系上的组合操作。在图5中,作者与主题的关系,可以通过author →writespaperm→ethodstopic (APT) 以及 au‐两条路径链接。在异构网络中两个对象能够通过不同类型的属性类型相互连接,不同的属性路径具有不同含义,因此,两个对象的相似度计算依赖于异构信息网络的元路径。异构学术网络图示例如图5所示。
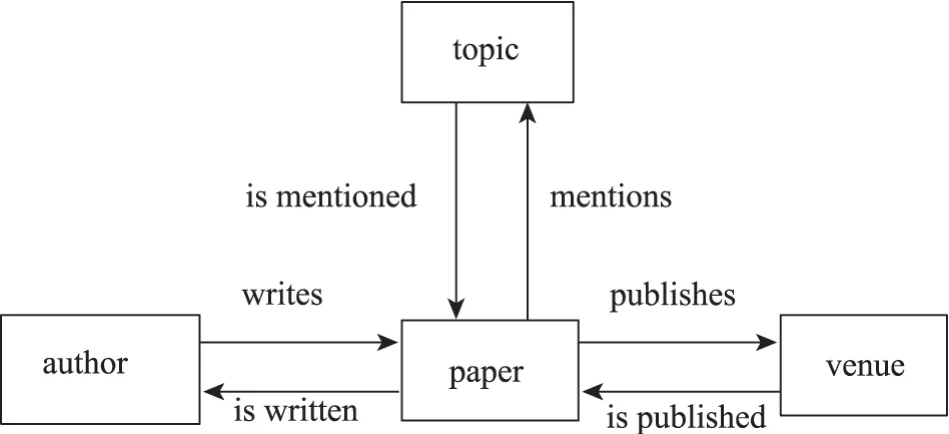
图5 异构学术网络图示例
其中,基于元路径的个性化学术论文推荐是基于人工在异构网络中创建一些元路径(两个节点之间的不同路径类型),再根据元路径中相关信息来实现推荐。根据所采用元路径不同的信息类别,此类研究的方法主要分为基于元路径的相似度计算和基于元路径中特征挖掘的推荐。
(1)基于元路径的相似度计算。将元路径中起点设为用户,终点设为候选论文,再通过计算从用户到候选论文两个节点之间的路径数和源节点的度与目标节点的度计算两个节点之间的相关性,从而实现个性化推荐[97]。例如,王勤洁等[98]选取了两条元路径:author→paper→terms→paper(APTP;与某位作者发表的论文含有相关关键词的论文)与au‐thor→paper→journal→paper (APJP;与某位作者发表的论文在同一个期刊的论文);采用作者偏好为异构信息网络中的不同元路径加权,然后利用DPRel(meta-path based relevance measurement)算法计算作者-文献相关度,结合权重得到加权作者-文献相关性矩阵,从而实现推荐;朱祥等[99]利用元路径理论和DPRel 相关性度量算法构建作者-文献相关性矩阵,依据相关性排名实现学术文献推荐。
(2)基于元路径中特征挖掘的推荐。根据元路径的拓扑或者序列特征挖掘用户偏好信息,利用随机游走或者机器学习方法实现个性化推荐。Ma等[100]为了实现对新论文的个性化推荐,首先,构建了研究者、论文、论文发表的期刊或者会议以及主题的异构图,基于训练数据选择前K个最感兴趣的元路径;其次,提出了一种贪婪方法来选择通过合并元路径生成的最重要的元图,该方法可以描述研究人员和论文之间比简单元路径更复杂的语义;同时,从网络中提取元路径和基于元图的拓扑特征;最后,在决定研究者的新论文推荐时,使用监督模型来学习与不同拓扑特征相关的最佳权重。Li等[101]提出了利用论文、地点、作者、关键词和用户实体以及这些实体之间的关系构建异构图,以网络中的元路径来捕捉用户偏好,并利用基于元路径的随机游走方法计算候选论文与目标论文之间的相关性,最后使用贝叶斯个性化排序(Bayesian per‐sonalized ranking,BPR)作为目标函数来学习不同元路径上的个性化权重。Xiao 等[102]利用多语义路径融合的异构网络为研究生实现了个性化论文推荐,即先构建异构教育网络(heterogenous educa‐tional network,HEN),利用投影子网络生成不同的语义元路径,再通过多语义路径融合提出一种HEN嵌入方法,以此生成丰富的HEN 节点序列,最后通过目标路径相似性为研究生推荐个性化的论文列表。为了避免太多较长的元路径可能导致较高的计算成本,并将噪声信息带入推荐模型,Xu 等[103]利用信息增益方法筛选有价值的元路径,然后在每个用户所包含的元路径中借助基于正则化的优化方法来学习个性化权重,最终实现个性化推荐。
总之,基于元路径方法能有效利用图结构来挖掘用户与论文之间的高阶关系,但此方法需要领域知识定义元路径类型与数量,人工所定义的简单元路径难以捕捉到图中所有描述研究人员如何发现有趣论文的可能拓扑特征,也难以实现跨领域推荐。
3.3 基于图嵌入式的方法
作为近年来学者们积极尝试的方法,图嵌入原理是使用基于神经网络的网络嵌入式方法为图中节点学习低维向量[104],以此获取表征用户兴趣或者论文等的低维度潜在向量,再利用向量相似度来获得个性化推荐。根据采用的嵌入式方法的不同,又可细分为基于随机游走的嵌入式方法和基于深度学习的嵌入式方法。
(1)基于随机游走的嵌入式方法。该方法主要应用于研究者只需要采用部分学术异构图的拓扑图数据或者图太大而无法测量其整体的情况,即利用图上的随机游走来获得节点表示的嵌入技术。例如,Cai 等[105]提出了一种基于书目网络表示的个性化引文推荐方法,该方法结合了书目网络结构以及不同类型对象(如论文、作者和地点)构建异构网络,利用有偏的随机游走(biased random walk)序列学习图中结构关系,再将图结构关系以及图中节点中的文本信息作为神经网络的输入,经过训练为每个节点生成向量,最后,根据节点向量之间的相似度实现个性化推荐;Chen 等[106]在构建学术异构网络时,在文献引用关系中考虑了作者引用倾向,设计了一个有偏见的随机行走程序有效地探索文献的特征和引用信息,采用skip-gram 模型学习游走序列中节点的邻域关系,并将节点映射到向量空间,最终通过向量相似度实现个性化推荐。
(2)基于深度学习的嵌入式方法。该方法主要借助深度学习模型(如自动编码器等)对学术异构图中的高度非线性结构进行建模,以此来获得节点嵌入式向量。例如,Cai 等[107]利用生成式对抗网络(generative adversarial network) 结合异构数据网络(如论文、作者、论文初稿以及初稿作者)节点内容与网络结构来实现对不同实体的嵌入式表示,并实现个性化推荐;Ali 等[108]提出了一种异构图嵌入式模型PR-HNE(paper recommendation based on het‐erogeneous network embedding),该模型将来自6 类信息网络的信息(作者-作者图、作者-论文图、作者-主题图、论文-论文图、作者-机构图、论文-标签图)嵌入一个联合潜在空间中,共同学习研究人员和论文的嵌入式向量,从而生成个性化的论文推荐;Zhu 等[10]提出一种基于异构知识嵌入的注意力RNN 模型来实现论文推荐:先以论文、作者、机构、地点、出版年份为实体,并根据引用、出版关系等构建异构网络,再采用TransD 将图中所有实体和关系转换为便于计算的嵌入式向量,进一步地,利用PV-DM (distributed memory model of paragraph vectors) 模型为每篇论文标题生成文本特征,最后,基于所生成的实体嵌入式向量与论文标题文本特征构建一个注意力双向RNN,实现能根据用户身份和查询文本返回的个性化推荐;李锴君等[109]利用知识图谱构建论文与实体之间关系,再利用不同嵌入方法将实体关系以及论文主题文本结构数据进行向量化表示学习,在此基础上,构建一个基于知识嵌入的编码-解码模型,从用户历史写作和引用行为中挖掘研究偏好,并实现个性化推荐;Ali等[110]提出了一种异构网络嵌入方法,对个性化引文推荐时的动态用户兴趣进行建模,所提出的嵌入模型通过使用与作者、时间、上下文、研究领域、引文和主题相关的语义来联合学习节点表示;Xi等[111]利用标题、摘要、标签和引文来构建异构图,利用基于注意力的双自动编码器(attention-based dual-autoencoder),结合协同过滤,充分捕捉论文的特征嵌入,并使用概率矩阵分解更新相关性和论文特征嵌入,从而执行最终推荐任务。
基于图嵌入式的方法能较好地利用图结构中多种语义信息来表达用户兴趣,但在整个推荐中需在图中不断进行迭代,因此,面对不断增长的海量学术数据,图的计算任务是论文推荐中亟待解决的问题。另外,目前主要是基于静态的异构网络进行嵌入式表示并实现推荐,而现实中学术网络中节点之间关系,如作者与文献之间的引用关系等常常呈现为动态变化,如何对动态异构网络进行嵌入式表示是未来的一个研究方向。
4 个性化学术论文推荐的结果评价
个性化学术论文推荐的结果评价最关键的因素是数据集构建、评价方法以及评价指标的选取。已有研究采用的数据集主要有公开数据集[12,14,36,56]与自创数据集[6,62,98]。考虑到研究方法的复现性,学界积极鼓励研究者们采用公开数据集,故本文对已有公开数据集的主要特征、应用场景等进行了归纳总结,如表4 所示。当前主流评价方法是显式人工评价信息的方法和基于隐式用户交互数据的方法。①基于显式人工评价信息的方法。通过构建体验实验室模拟现实应用场景邀请用户对推荐结果进行显式评价,或者通过发问卷形式要求用户推荐结果的相关性进行评价[4,34,58,112]。此类方法虽然能较为真实地展现用户对推荐结果的兴趣,但是缺点在于人工成本较高,且难以实现对大规模数据进行评价。②基于隐式用户交互数据的方法。主要借助用户隐式交互数据,根据为用户所推荐的论文未来是否被用户引用[99,112-113]、是否被阅读[38,43,50-52]、是否被点击[40,53]等情况,判断其推荐结果的相关性。相较于人工评价方法,此方法能对大规模数据进行评价,是当前个性化学术论文推荐采用的主流评价方法。
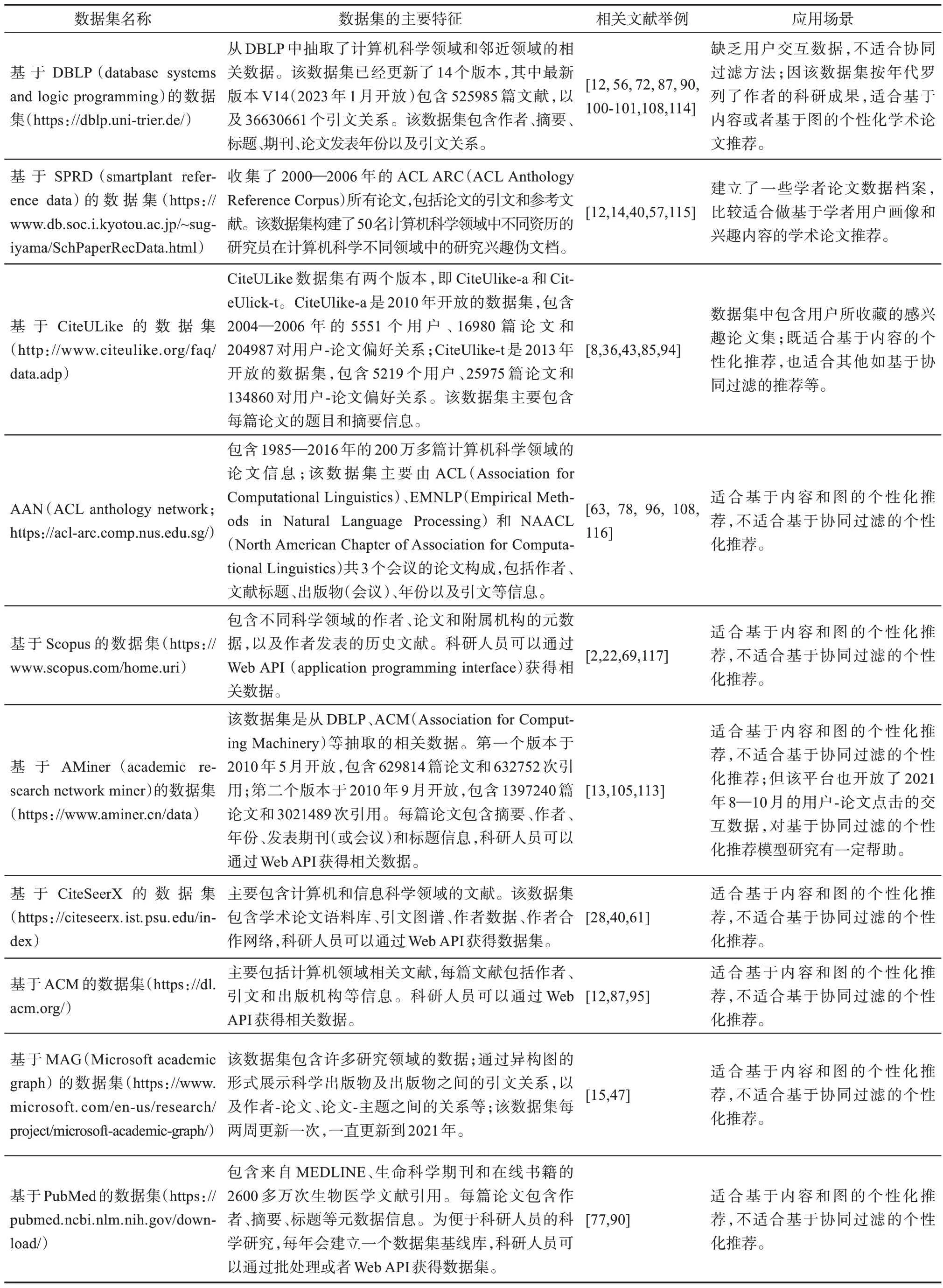
表4 个性化学术论文推荐的主要公开数据集
个性化论文推荐最初的目的是推荐与用户相关的文献,因此,判断结果准确度指标,如recall、precision、MAP(mean average precision)等,常被应用于结果评价中。随着后期研究工作的深入开展,一些学者尝试提出如何深入地从用户兴趣、结果质量、多样性以及惊喜度角度对推荐结果进行评价,相关评价指标的具体信息如表5 所示。

表5 个性化学术论文推荐的主要评价指标
总体来说,目前个性化论文推荐评估已创建了公开数据集,但已有数据集只是记录了用户有限的个性化偏好信息,如用户历史发表文献或者阅读文献等,从而使得已有公开数据集制约着个性化论文推荐模型的发展。因此,在保护用户隐私的情况下,如何构建一个记录用户全面偏好信息的公开数据集将是后续工作需要探讨的重点问题。虽然当前个性化论文推荐评价中除了考虑结果的准确度指标外,也积极提出了针对用户兴趣、结果多样化以及结果惊喜度的相关评测指标,但是现实中除了以上指标之外,用户可能还从稳健性、隐私性等方面对推荐系统性能进行评价。因此,如何构建更全面的评价指标也是未来研究需要致力的方向。
5 总结与展望
纵览国内外相关研究,个性化学术论文推荐研究近年来得到了广泛关注,并取得了较大进展。根据对用户兴趣的不同建模方法,此研究主要分为基于协同过滤、基于内容与基于图模型的方法。学界已经创建了用于个性化论文推荐评价的公开数据集,且已经创建了较为成熟的评价方法与评价指标体系。尽管如此,已有研究中存在以下不足:①缺乏对研究者兴趣的全方位建模,已有方法主要采用用户所发表、引用文档或者部分行为数据,忽略了研究者如情感关系、认知风格等其他重要个性化特征对个性化推荐结果的影响;②缺乏个性化学术论文推荐结果的可解释研究,限制了用户对推荐结果的满意度与可信度;③对面向用户惊喜的推荐的相关探讨不足,已有方法主要停留在借助主题多样性这个单一特征来实现个性化论文推荐结果的惊喜,限制了最终推荐的效果;④个性化推荐方法中常常需借助用户的个性化信息,这些信息可能涉及用户隐私数据,但已有研究中缺乏对用户隐私保护的相关研究;⑤已有评价指标体系尚不能根据现实用户的真实需求对论文推荐结果进行评估。针对已有研究中的不足,未来个性化学术论文推荐的研究趋势可能主要体现在以下5 个方面。
(1)基于多源异构大数据的动态学术用户画像构建
个性化推荐系统服务将呈现精细化和智能化的趋势,如何通过构建动态的、细粒度的用户画像来洞察用户行为需求演化是提升未来推荐系统精准服务的重要方式。为了能精准地捕捉到学术用户的个性化需求,未来研究可考虑创建基于多模态大数据的动态学术用户画像。具体而言,设计一个深度信息融合的模型,以此来集成不同来源、不同结构、不同模式的用户数据(不仅包括用户与论文之间的交互数据,还包括用户的时空列数据、图像信息、项目数据等)来表征用户兴趣,并且实现从时间维度、情感维度、认知维度和内容维度来勾勒立体化与全方位的学术用户画像。其中,画像可具体描述包括用户的基本信息、行为、学术人格(认知风格)、学术影响力、情感关系(如学术观点、合作竞争)、社交关系等不同维度特征。在此基础上,基于知识图谱和深度神经网络的协同学习、多通道模型等扩展了不同维度特征之间的语义关联,最终实现既能从心理维度精确理解用户的需求,也能从时间维度感知用户偏好的动态变化、社会关系变化以及项目特征动态变化等的目标。
(2)个性化论文推荐模型的可解释性研究
推荐模型的可解释性是当前推荐系统领域探讨的热点话题。为了提升个性化论文推荐模型的透明度以及实际应用效果,未来研究需要考虑对推荐结果的可解释性(explainability)进行研究。根据个性化学术论文推荐的特性,未来可解释性模型研究的主要方向有3 个。①动态可解释性研究。如上文所述,学术用户的需求常呈现动态变化趋势,已有个性化推荐系统的可解释性模型主要是基于用户静态需求的,因此,如何对用户动态个性化需求建模,将是未来个性化论文推荐模型的可解释研究中的一个重要研究方向。其中,未来研究可考虑在构建动态知识图谱的基础上,结合强化学习技术等,建立不同时间点知识之间的多重依赖关系,并提供研究者与论文之间的多关系推理,实现动态可解释性研究。②基于多源异构信息的可解释性研究。未来的学术论文推荐系统将利用异构信息源来对用户兴趣建模,以此提高推荐性能,因此,未来研究需要探讨如何对齐两个或者多个不同类别信息资源的多模态解释,即在异构信息源上进行迁移学习,以此获得可解释推荐,以及如何实现学术论文跨领域推荐的可解释性。③可解释性模型的统一框架构建。目前,大多数可解释性模型都是针对特定的推荐模型而设计的,可扩展性较差。未来研究可考虑如何在个性化论文推荐中构建一个与模型无关的可解释性模型框架,避免为不同的个性化论文推荐系统构建不同的可解释模型,从而提升可解释性模型的可扩展性。
(3)面向用户惊喜的个性化学术论文推荐
面向用户惊喜的推荐是近年来推荐系统领域探讨的热点问题,此类推荐方法能有效避免过度个性化论文推荐结果给学术用户带来的“信息茧房”以及用户视野缩小等问题,这也是未来个性化学术论文推荐的关注点,其中值得探讨的问题主要有3 个。①多类惊喜特征的挖掘。除了考虑主题多样性外,未来研究可进一步借助图结构中节点之间的路径以及借助迁移学习等技术挖掘更多可能为用户带来惊喜的推荐特征,发掘用户潜在感兴趣的论文。②基于用户好奇心(curiosity)的惊喜推荐。用户好奇心是惊喜推荐的主要诱因之一[66],且好奇心不同的用户对推荐结果的惊喜度要求不一样:好奇心强的用户更喜欢惊喜推荐,反之,则排斥惊喜的推荐结果。因此,未来研究中需要考虑如何根据用户历史信息,借助数学模型对用户好奇心建模,并将其融合到惊喜推荐结果的排序中。③跨领域的惊喜推荐。未来学术论文推荐的趋势可从多个学科领域中产生以惊喜为导向的论文推荐。为了实现此目的,未来学者可以考虑将不同领域信息进行融合,实现对实体的多维描述,补全实体信息,以实现跨领域的惊喜推荐。
(4)个性化学术文献推荐模型的联邦化研究
已有学术文献推荐系统的实现主要基于系统对用户与论文之间的关系信息以及论文内容特征信息等的集中式存储。然而,海量数据背后存在大量的用户个人信息以及敏感数据,因此,如何在保证用户隐私与数据安全的前提下获得用户个性化特征信息,将是未来个性化学术文献探讨的热点问题。其中,联邦学习作为新兴的隐私保护范式,可以协调多个参与方通过模型参数或者梯度等信息共同学习无损的全局共享模型,同时保证所有的原始数据保存在用户的终端设备,相对于传统的集中式存储与训练模式,实现从根源上保护用户隐私的目的。因此,如何将联邦学习融合到个性化学术文献推荐模型中将是此领域未来重要的研究内容,未来可以尝试的主要方向有2 个。①基于协同过滤模型的联邦化。将表征用户偏好的数据保留在用户本地,尝试如何采用数据匿名化、差分隐私技术以及同态加密技术等对用户特征向量进行处理,并对用户特征向量和物品特征向量进行梯度计算,然后将物品特征向量的梯度上传到服务端进行物品特征向量的更新,服务端再推断出该用户对这一物品的评分信息。②基于深度学习模型的联邦化。为解决深度学习模型中论文特征矩阵通常非常庞大,以及大规模的神经网络会给客户端的资源存储带来负担的问题,未来研究可以探讨如何对客户端采样来参与深度学习模型的训练,同时各个客户端共享权重参数、模型参数或梯度等中间参数,然后对这些客户端上传的模型参数进行安全聚合,以此加速深度模型收敛,从而实现最终的个性化推荐。
(5)个性化论文推荐的性能评测研究
虽然当前已有大量研究对个性化论文推荐的评价方法与评测指标进行了研究,但是已有研究大多未能完全清楚地描述推荐的应用场景(如帮助用户阅读、引用或为患者提供治疗策略等)以及推荐结果的受众类型(如资深研究者、初级研究者或学生等)。一般情况下,不同的应用场景以及不同的受众类型对推荐结果的需求可能不一样,因此,未来研究需要在对用户实践场景以及受众类型清晰描述的基础上,实现对推荐结果的准确度、相关性以及用户满意度等方面的评价,作为以人为中心的人工智能研究前沿,值得信赖的推荐系统将会是未来学界努力的方向。其中,推荐系统的可信性主要是从系统的公平性、准确性、可解释性、稳健性和隐私性等方面进行评估。因此,未来个性化学术论文推荐研究还需考虑如何从这些方面构建新的评价指标体系。已有个性化推荐评测方法中常常忽视了系统需要满足多方利益相关者的需求,不同的利益主体可以有自己的利益需求和衡量方法,未来研究需要建立能权衡多方利益相关者需求的评价方法与评价指标。
