技术主题动态演化分析的一种新方法:DPL-BMM模型
2024-02-04宋凯,陈悦
宋 凯,陈 悦
(大连理工大学科学学与科技管理研究所暨WISE实验室,大连 116024)
0 引 言
新兴技术在市场、技术和管理等方面不确定性的根源在于人的有限理性与认知风险,监测技术发展态势和捕捉创新早期信号是提升认知和增加理性的重要活动,是减少新兴技术不确定性的根本所在。尽管技术的发生与发展有不确定性,但宏观的发展轨道和脉络还是有势可循的。揭示技术演化脉络是把握技术发展规律的前提,基于专利信息的主题挖掘是基于技术发展微观机制而呈现宏观规律的重要研究内容,对技术超前布局和指导创新活动具有重大意义。
专家经验是构建技术演变脉络中不可忽视的知识[1-2],但新兴技术的快速涌现使得专家意见的主观倾向、时间和人力成本等局限性呈现出来。为突破这些局限,学界在实证定量方面进行了大量探索,尤其是基于专利文献,已产生了引文分析、共现分析、文本挖掘和主题模型等多种方法用于揭示技术演化的特征及规律。譬如,文献[3-5]通过特定的引文权重指标识别专利引文网络的知识流动轨迹以绘制技术演化路径,这种引文分析方法能在一定程度上刻画技术发展的历史脉络,但因侧重于高显示度指标(如高被引)文献而存在时滞性;基于专利分类号的时序统计分析和共现分析[6]可以改善这一不足,只是这种方法识别的技术主题粒度较粗,且难以识别新的技术主题。
与引文分析和共现分析相比,基于主题模型分析的文本挖掘侧重于文本内容特征[7],不受引文时滞影响,能够提升技术演化趋势的精确性和即时性。在情报学领域,许多学者[8-12]结合LDA(latent Dirichlet allocation)模型及其各种改进模型识别技术主题及主题之间的关系,从而分析技术的演化趋势,这些研究为基于主题模型开展技术演化分析提供了丰富的方法基础,但尚未解决在时间序列下技术主题数目动态变化的问题,也疏忽了技术主题的标识工作。学者们更多关注的是如何选取最优主题数目,而这通常需要较多的人工干预和阈值判断。事实上,技术在连续性、累积式的发展过程中,每个时间窗口的最佳技术主题数目具有动态变化的特性[13]。针对上述问题,本文以专利数据作为分析对象,提出了一种能够自动提取标签的技术主题动态演化分析方法,该方法能够自动获取时间序列下的技术主题数量和内容,并对技术主题进行标识,从而分析技术的动态演化趋势。
1 基于DPL-BMM的技术主题动态演化模型构建
随着新专利的不断加入,技术主题会动态变化,某个技术主题下的单元技术也会存在时序变化。区别于静态的LDA,增量主题模型更能够反映技术主题随时间的更替、增加和消失[14]。已有研究表明,增量主题模型DP-BMM(Dirichlet process bitermbased mixture model)[15]与k-means[16]、LDA[17]和其他改进模型相比,能够提升主题探测效果。但是DP-BMM 模型无法自动标记文档聚类,对于探测到的主题没有明确的标签列表说明。针对上述不足,本文构建了DPL-BMM (Dirichlet process bitermbased mixture model with labelling)模型,该模型不仅能识别动态主题,还可以自动获取每个主题的表征词列表。本文设计了基于DPL-BMM 的技术主题动态演化分析框架(图1),包含3 个步骤:①数据预处理;②动态技术主题识别与标注;③技术主题热度测度与可视化。其中,动态技术主题识别涉及DPLBMM 构建、文本数据特征表示、自动化文本聚类动态更新、技术主题标识等。
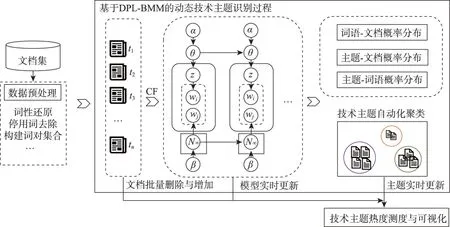
图1 基于DPL-BMM的技术主题动态演化分析框架
1.1 动态技术主题识别的DPL-BMM模型
DPL-BMM 是一种自动标签的、基于双项的狄利克雷过程混合模型,是DP-BMM 的变体。该模型随时间序列自动化生成主题聚类的数目,并对所生成的聚类主题进行标记,解决了以往主题模型需要预先设定聚类数量等问题,因此,更适用于动态技术主题识别。
1.1.1 专利文本特征表示
专利文本特征表示是将专利的标题和摘要信息转化为特征向量的过程。为更好地反映专利特征,参照文献[18]使用词频表示专利文档特征的方法,本文使用集群特征(cluster feature,CF)向量表示集群特征。每个聚类簇z的CF 向量定义为一个元组其中表示聚类簇z中的词共现列表,mz表示聚类簇z中的文档数量,nz表示聚类簇z中的词数量。从聚类簇z中增加或者删减文档d时,CF 向量可以实时更新,即
其中,d代表一篇文档;b表示一篇文档的词对(双项)集合;bwi和bwj分别表示单词wi和单词wj在一个词对b中出现的频次;和分别表示词wi和词wj在聚类簇z中出现的频次;表示一篇文档d中双项集合的单词总数。
1.1.2 专利技术主题生成
一篇文档中的每个单词通常是通过“以一定概率选择了某个主题,并从这个主题中以一定的概率选择某个词语”的过程得到的,而DPL-BMM 主题模型依据这个原理反推每个专利文档的技术主题分布,其主要过程包括:①对全局主题的比例分布进行采样,G|γ~GEM(γ)[19];②对主题分布进行采样,θ~DP(α,G);③对于每一个主题z∈{1,2,3,…},计算特定主题的词分布ϕz~Dirichlet(β);④对于每一个文档d∈{1,2,3,…},计算主题分布z~Multinomial(θ)和词对分布b~Multinomial(ϕz)。据此,可以得到在聚类簇z中词对-主题概率分布以及文档-主题概率分布,公式分别为
其中,α和γ是狄利克雷过程中的超参数;β是狄利克雷分布中的参数;ϕz表示主题-单词概率分布;p(wi|ϕz)和p(wj|ϕz)分别表示单词wi和单词wj在特定主题z的狄利克雷概率分布。
对于超参数α和β的设置,本文采用网格搜索方法找出平均性能最佳的参数。文档-主题分布对应超参数α,α越大,表示主题差异越小,主题分布越均匀;词对-主题分布对应超参数β,β越大,表示这个主题拥有的词汇越多。在获得每个专利文档技术主题分布的基础上,使用吉布斯采样(Gibbs sampling)[15]统计每个词和每篇文档的最终主题。
此外,DPL-BMM 制定了新文档与已形成聚类之间的概率分布,即每批或者每个新的专利文档要么被添加到现有聚类集群z中,即
要么创建一个新的集群K+ 1,即
据此,可以捕捉新技术主题产生的信号。其中,mz,¬d表示聚类簇z中剔除文档d后剩余文档数量;表示聚类簇z中剔除文档d后词对b中的单词wi数量;D表示当前记录文档的总量;V表示当前记录文档中的单词数量;αD表示新集群中文档的伪计数量,γ=αD。
1.1.3 聚类主题的标识
已有研究中通常将出现概率较高的词视为表征词,再通过人工判读来确定聚类的技术主题标签[20],这些表征词往往以单个词汇而非词组的形式出现,因此对判读人员的技术专业程度要求很高,且当技术主题数量很多时,会消耗大量的人力和时间成本。为解决这个问题,本文提出一种自动化标记聚类主题的方法,即生成词组形式的技术主题标签,从而辅助人工对技术主题的研判和标识,如图2 所示。首先,使用RAKE (rapid automatic key‐word extraction)算法[21]从每个聚类的专利文本中抽取技术主题候选词组。其次,根据公式

图2 聚类标签表示流程
计算技术主题候选词组的权重分值并排序,用于衡量每个候选词组的重要程度。其中,Sk表示技术主题候选词组k的权重分值;ϕz,w表示词w的分布概率;n表示组成技术主题候选词组k的单词数量。最后,结合专家判读从排名前20 位的技术主题候选词组中挑选最能代表该聚类的技术主题标签。
1.2 技术主题热度量化与可视化
根据1.1 节可以得到专利数据集中的主题-文档分布、主题-单词分布和每个聚类的技术主题标签,通过公式
测度每个技术主题z在第t个时间窗口的热度H(zt)。其中,zt表示在时间切片t∈{1,2,…,T}中的技术主题z;nz,t表示在时间切片t中技术主题z所涉及的专利数量;Kt表示在时间切片t中的专利总数。基于此,计算出整个时间序列的技术主题热度。为了更加直观地表达技术主题热度随时间的变化趋势,本文使用主题河流图[22]对其进行可视化。
2 实证案例:人工智能技术
人工智能作为第四次工业革命的引领性技术和颠覆性技术,正在释放科技革命和产业变革积蓄的巨大能量,是世界各国竞争角逐的焦点技术。人工智能技术经过60 余年的发展,拥有大量的专利数据,具有技术主题更新迭代速度较快和应用领域不断拓展的特点。基于DPL-BMM 的技术主题动态演化分析框架适用于识别和追溯这些快速发展的技术主题,进而为人工智能技术领域政策制定、产业布局以及技术创新发展提供决策支撑。因此,本文选择人工智能技术领域作为实证研究对象。
2.1 数据收集和预处理
综合考虑查全率与查准率,参照文献[23],从德温特专利数据库中收集了98828 条人工智能专利数据作为实证分析对象①检索式:TI = ("artificial intelligence*" OR "intelligence artificial*" OR "expert system*" OR "Deep learning*" OR "Machine learning*" OR"Human-computer interaction*" OR "emotion analysis*" OR "Natural language processing*" OR "Speech Recognition*" OR "Computer vision*" OR"Gesture control* "OR "smart robot*" OR "Video recognition*" OR "Voice translation*" OR "Image Recognition*" OR “Data mining*"),时间跨度为1965年至2021年。。提取所有专利的标题和摘要信息,依照表1 展示的数据预处理过程生成每一篇专利的词对集合,使用公式(1)对词对集合进行特征表示,构建专利文本的特征向量。

表1 专利数据预处理过程
2.2 人工智能技术主题的动态变化趋势
技术是呈现体系化发展趋势的,往往早期的初级技术数量较少,但随着实践需求的不断出现,不同技术会组合或融合成新的技术,从而替代原有技术或独立发展并更新迭代。为展示人工智能技术主题的动态演化趋势,本文从技术主题数量年度变化和技术主题内容年度变化两个方面进行探究。
2.2.1 人工智能技术主题数量动态变化趋势
本文使用DPL-BMM 模型对1965—2021 年发表的人工智能专利文档数据集进行技术主题提取,时间切片设置为1 年,在这一步骤中,尝试研究超参数α和β对模型性能的影响,以期获得最佳的参数设置;采用广泛用于无监督文本聚类评价的主题连贯性指标对聚类结果进行评价。图3 展示了具有不同α值和β值的DPL-BMM 的主题连贯度分数(coeffi‐cient of variance,CV),分数越高,模型的主题挖掘能力越好。因此,在模型中设定α= 0.6,β= 0.02。
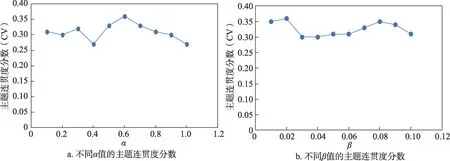
图3 超参数对DPL-BMM模型性能的影响
图4 展示了人工智能技术主题数量和专利数量的年度变化趋势。其中,专利数量从1965 年开始缓慢增长,从2010 年开始呈现指数增长态势,大致可以划分为3 个发展阶段,即基于符号逻辑的推理证明阶段(1965—1976 年)、基于人工规则的专家系统阶段(1977—2006 年)和大数据驱动的深度神经网络阶段(2007—2021 年);技术主题数量总体呈现上升态势,大致可以划分为4 个发展阶段,即缓慢增长期、快速增长期、短暂衰减期和爆发期。1965—1986 年,人工智能技术处于缓慢增长期,专利申请数量较少,技术主题的数量也很少;1987—2000 年,是人工智能技术的快速增长期,专利申请数量持续上升,尽管专利数量不多,但技术主题数量增长快速,这与前一阶段的技术积累密不可分,“专家系统”(1980 年提出)得到了广泛应用,同时人工智能相关的数学模型取得了一系列重大成果,如1986 年提出的“反向传播算法”和1989 年提出的“卷积神经网络”等,这些算法催生了“机器学习”;2001—2011 年,是短暂衰减期,每年申请的专利数量较为稳定,但技术主题的数量却逐年减少,这与当时的硬件计算能力和数据资源有限息息相关;2012 年开始,进入爆发期,人工智能技术主题数量在动态波动后爆发至顶峰,特别是在2015 年之后呈现指数型增长趋势。在这一时期,计算机硬件和大数据的发展促进了人工智能的加速发展,尤其是GPU(graphics processing unit) 在机器学习中的应用,计算机可以从海量的数据中学习各种数据特征,从而很好地完成人类分配的各种基本任务,人工智能强大的赋能性使其在不断地与其他领域的技术发生渗透和融合。
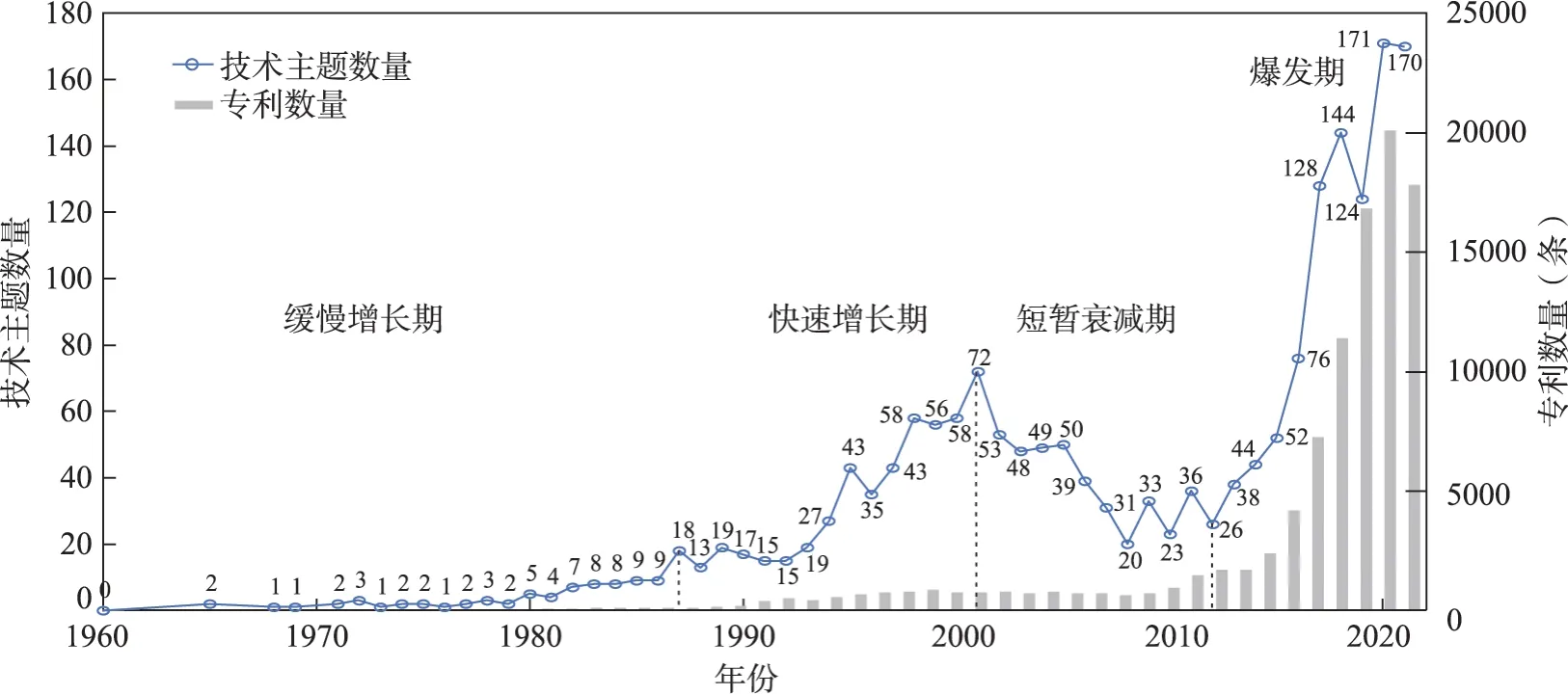
图4 人工智能技术主题数量和专利数量的年度变化趋势
2.2.2 人工智能技术主题内容演化
依据“技术主题-文档”概率分布,进一步统计每年的专利数据集聚类结果。聚类簇的数量即技术主题的数量,根据1.1.3 节所提出的自动标签聚类的方法,使用河流图的形式呈现人工智能领域的技术主题演变趋势,探究随时间变化每一个技术主题的出现、变迁和消亡的全过程。图5 展示了1965—2021 年每年的技术主题热度变化,对于超过10 个技术主题的年份,仅展示每年热度排名前10 位的技术主题流动情况。在图5 中,每一条色带表征一个技术主题,其纵向宽度表征该技术主题在当年的热度,与当年该分支领域的专利数量呈正相关关系;各技术主题在每一年份中按照其热度进行排序,热度越高的则越靠上。
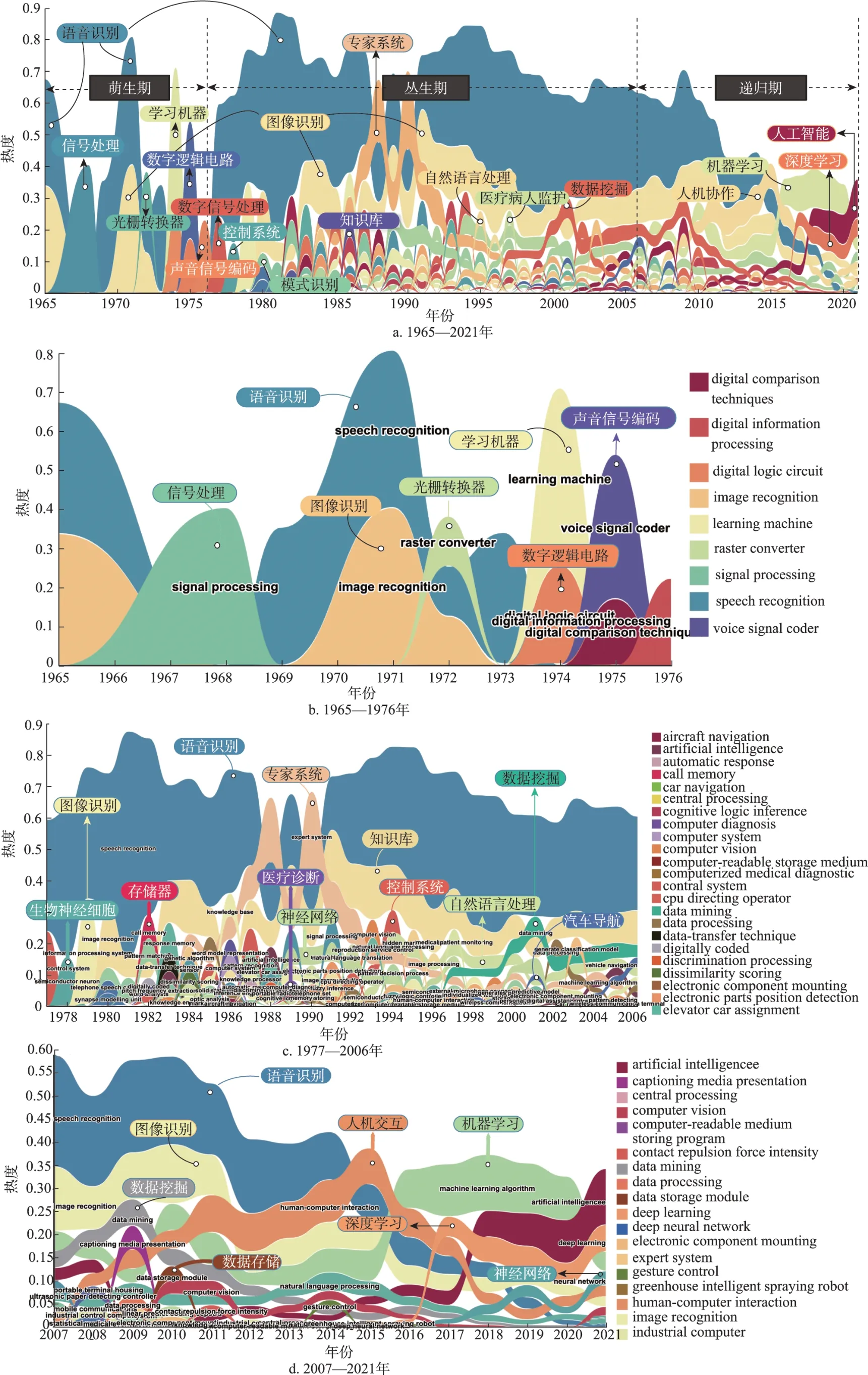
图5 人工智能技术发展趋势(彩图请见https://qbxb.istic.ac.cn)
综合图4 和图5a 可以发现,人工智能技术主题的演变经历了技术主题萌生、技术主题丛生和技术主题递归3 个发展阶段。1965—1976 年,每年的人工智能技术主题相对单一,且具有差异性,即“点”状发展,相互间关联度低,这是人工智能技术的萌生阶段。1977—2006 年,人工智能技术主题丛生,并表现出一定的连续性,这种丛生是域内技术主题与域外技术主题的融合或内部形成的分支,这时呈现“线”性演变状态。2007 年至今,在大数据和深度神经网络的驱动下,人工智能技术主题趋于递归,即主要技术的主导性增强,赋能于多种场景,具有“面”的特征,或许在酝酿着新一轮的技术主题丛生。总体而言,人工智能技术经过60 多年的发展,经历了从“点”到“线”再到“面”的技术主题演变过程。
(1)人工智能技术的萌生期(1965—1976 年)
这是人工智能发展的第一个黄金时期,科学家将符号方法引入统计方法中,解决了若干通用问题,初步萌芽了自然语言处理和人机对话技术,许多重要的基础算法也在这一时期被提出,如深度学习模型的雏形贝尔曼公式。根据图4 和图5b可以看出,这一阶段的专利申请量和技术主题的数量非常少,人工智能技术应用尚处于萌芽阶段,最早兴起于语音识别和图像识别领域,信号处理、光栅转换器、数字信息处理、语音信号编码器等技术陆续得到应用,并促进了语音识别和图像识别的发展。
(2)人工智能技术的丛生期(1977—2006 年)
这一时期是人工智能技术分支和技术应用迅速延伸的时期(图5c)。在应用领域方面,人工智能技术逐渐在数字助理、汽车导航、飞机导航、计算机化医疗诊断、人脸识别和电子元件安装等方向得到了广泛应用;在硬件研究方面,传感器、存储器和中央处理器曾一度处于较高的技术热度。
事实上,人工智能各种技术并不是孤立存在的,其中渗透性强、关联度大的主导技术[24],如语音识别、图像识别和专家系统,在人工智能技术主题共现图谱(图6)占据核心地位。与主导技术相配套的辅助技术,如与语音识别技术紧密关联的自然语言处理技术、计算机程序技术和存储技术等,以及用于存储领域专家知识的知识库、分析处理专家知识的数据挖掘技术等,也相继涌现并发展起来。这些相互关联的各种技术共同构成的技术体系不断发展,应用需求导向也使各个行业产生变革,新技术替代旧技术。
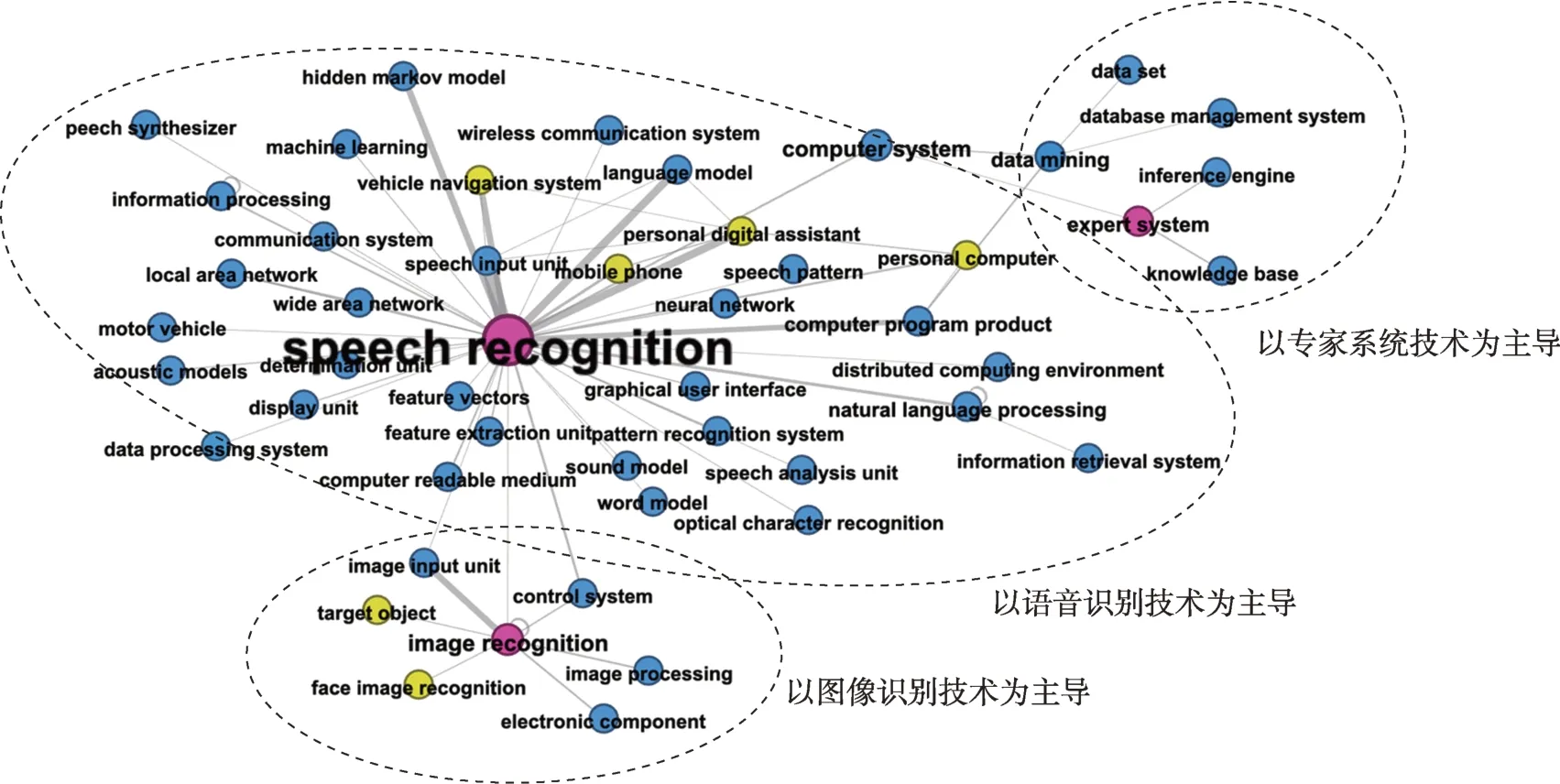
图6 人工智能技术主题共现图谱(1977—2006年)
(3)人工智能技术的递归期(2007—2021 年)
2007—2021 年是人工智能的一个黄金时期,专利申请量急速上升,2017 年是一个显著的拐点。人工智能的大发展主要得益于互联网、社交媒体、移动设备和传感器的大量普及,便携式设备和移动通信在2006 年和2007 年成为热点技术(图5c、图5d)。全球产生并存储的数据量急剧增加,海量的数据为人工智能算法模型提供了源源不断的素材,机器可以学习的数据越多,发现的规律越多,使得数据挖掘技术主题一直处于较高的热度。为支撑大规模数据的处理和计算,数据存储模块、计算机可读介质存储程序和工业计算机是这一时期专利申请中重要的技术主题,与其他技术主题密切相关的人机交互技术主题也有新的突破。尽管语言识别和图像识别的研究仍然占据主导地位,但神经网络、机器学习和深度学习等算法主题日益突出,并与其他技术组合应用于多种场景。人工智能的又一次突破得益于深度卷积神经网络模型的提出和发展,其中李飞飞及其举办的ImageNet 大赛为深度卷积神经网络模型的应用做出了不可磨灭的贡献,ImageNet 改变了以往只关注模型而忽视数据的人工智能研究思维[25]。2012 年,Hinton 与其两名学生Alex 和Su‐tskever 提出了AlexNet 卷积神经网络模型,借助Im‐ageNet 数据取得了令人瞩目的结果,驱动了新一代人工智能的加速发展[26]。
进入21 世纪,海量化的数据、持续提升的运算力、不断优化的算法模型以及结合多种场景的新应用已构成了相对完整的闭环,使许多先进的机器学习技术成功应用于经济社会中的许多问题的解决,推动了新一代人工智能技术的发展。
2.3 模型评估
为了评估本文方法的聚类效果,在人工智能数据集上将DPL-BMM 模型与文档聚类领域中的经典模型LDA 和DTM (dynamic topic models) 进行比较。关于主题挖掘能力的评估,使用主题连贯度指标(topic coherence,TC)[27]评估主题模型的性能,即一个技术主题中的主题词应该具有密切的相关性,可以有效地描述一个研究方向。经实证检验,LDA 和DTM 的主题连贯度分数(CV)分别为0.27 和0.31,DPL-BMM 模型的CV 值为0.36,这证明了DPL-BMM 模型具有较好的主题挖掘能力。
3 结 语
建构特定领域技术体系的整体演化过程、把握技术发展的宏观规律与微观机制、捕捉新技术产生的早期信号,对于新技术布局和创新资源配置具有重要决策价值。
本文提出了一种能够自动标签的技术主题动态演化分析方法,即DPL-BMM 模型,该模型具有两点特性。①解决了以往使用主题模型进行技术主题挖掘时需要预设固定数目的问题[12,20]。本文方法可以对专利信息实现高效的无监督聚类,快速挖掘时间序列下的技术主题分布,且可以有效标记每个聚类的技术主题,在科技情报分析工作中具有实际应用价值。②适用于动态数据流的处理,实现了数据处理效率和聚类结果性能之间的有效平衡。实证研究中使用一年作为时间窗口对专利进行划分,DPLBMM 可以批量删除上一个时间窗口的数据,只保留当前年份的数据内容,有效平衡数据规模庞大和计算存储资源有限之间的问题。
实证研究结果表明,DPL-BMM 模型可以较好地实现对技术主题的挖掘和演化分析,人工智能技术发展在总体上呈现出技术由“单一性”到“连续性”再到“递归性”的发展特点,主导技术、辅助技术和支撑技术等构成的群体技术逐渐涌现,共同构筑了人工智能技术体系。
