基于语义相似关系的学科交叉主题识别方法
2024-02-04王卫军宁致远乔子越周园春
王卫军,宁致远,董 昊,乔子越,杜 一,周园春
(1. 河南财经政法大学图书馆,郑州 450046;2. 中国科学院计算机网络信息中心,北京 100190;3. 中国科学院大学,北京 100049)
0 引 言
学科交叉地带的科研活动通常被认为是科技创新的重要来源[1]。识别学科交叉地带的科研活动,对于引导相关科学研究、促进交叉学科形成具有重要作用。近年来,深度学习技术在自然语言处理领域相关任务场景的不断成功应用,为利用相关技术深入挖掘科技文献内容,识别学科交叉知识、主题或方向,实现学科交叉研究的预测预警,提供了新的技术实现路径。学科交叉研究主题的识别可通过对分布在不同学科科技文献中的相同研究内容进行分析来实现[2]。在科学计量学中,通常会使用关键词术语来分析不同学科之间的知识扩散活动,一方面,是因为关键词术语作为知识的最小粒度,能够以直接、清晰的方式代表相关概念;另一方面,关键词术语可更加有效、及时地跟踪不同学科之间的知识交流[3]。因此,研究人员会通过获取高频词在不同学科的分布情况,或者利用高频词的共现关系等进行学科交叉主题发现研究。但是,由于基于高频词的跨学科分析对关键词出现的频率进行粗暴的界定,会丢失一些重要信息,并不能保证结果的准确性[4-6]。同时,上述方法在涉及学科交叉主题预测预警系统的设计时也会存在一定的不足。在科学研究中,为解决单学科的研究问题,会借用其他相关学科的方法、手段等进行相关研究,此类研究更多的是不同学科间知识的简单移植、借用,被称为借用研究[7-9],如生物学领域运用了物理学的技术、有机分子化学中运用了数学工具等。学科交叉研究则是在借用研究的基础上,不同学科间的知识进一步深入扩散、融合,其具有独特的价值和作用。基于此,本文认为将分布在不同学科中上下文信息相近、语义相似的关键词术语作为学科交叉研究的内容,更能体现出不同学科间的知识融合情况。
在对学科交叉性进行测度时,余弦相似度可被用于衡量两门或两门以上学科交叉融合程度或知识整合程度的指标[10];科学研究中的关键词会因其所存在的上下文、作者用词习惯等方面的不同而产生歧义,影响及阻碍学科交叉主题发现的有效性和准确性[11-13]。基于此,本文认为不同学科的关键词术语之间的语义相似关系的强弱可体现学科间的知识整合程度,将学科间语义相似的关键词术语作为学科交叉知识或主题,可避免相关模型获取的是学科间的简单知识借用研究,同时也可降低关键词术语的歧义问题对结果有效性的影响。因此,本文将研究问题定义为,如何快速发现不同学科科技文献中具有相似语义的学科交叉研究主题;具体的关键技术问题为,如何获取科技文献及其包含的关键词术语之间的语义相似关系,如何评估本文模型获取语义相似学科交叉主题的有效性。针对上述问题,本文提出,通过无监督对比学习方法进行文本语义相似分析任务(semantic textual similarity,STS),进而提取科技文献及其关键词术语的语义相似关系。本文同时提出相应算法构建科技文献相似研究数据集,认为利用对比学习模型在科技文献相似研究数据集上进行STS 任务时,Spearman 相关系数越高,科技文献及其关键词术语在向量空间中的分布越趋于合理,获取的语义相似学科交叉主题准确性越佳;即将STS 任务在科技文献相似研究数据集上的Spearman 相关系数作为评估本文提出的学科交叉主题识别模型性能的间接指标,从而解决在学科交叉研究时难以提供标准的学科交叉主题数据集验证模型性能的问题。学科交叉研究中,学术论文[4]、基金项目[14]等均是其重要的数据分析来源。由于学术论文、基金项目等通常包含题目、关键词、摘要等信息,为了构建具有一定通用性的学科交叉主题识别模型,本文将学术论文、基金项目等具有相似组成部分的数据统一表述为科技文献。本文的主要贡献如下。
(1)本文提出将在科技文献相似研究数据集上进行STS 任务时的Spearman 相关系数作为判别模型获取科技文献向量表示数据分布是否合理的依据,进而作为本文模型获取语义相似学科交叉主题有效性的判别标准。该思路可有效解决学科交叉研究中难以定义标准的学科交叉研究数据集的难题。同时,本文还提出一种基于共词理论[15]快速标注科技文献相似研究数据集的算法。
(2)本文认为不同学科之间具有相似语义的研究主题能更好地呈现不同学科之间的知识融合交流,可避免提取出的学科交叉主题只是简单的知识移植借用。基于此,本文提出,利用对比学习模型完成科技文献的语义相似分析任务,获取科技文献之间、关键词术语之间的语义相似关系,进而将分布在不同学科中具有相似语义的学科交叉研究主题提取出来。
(3)本文模型是一种无监督的技术思路,为模型从海量科技文献数据中挖掘学科交叉主题提供了可能,也可为学科交叉主题的识别及预测预警提供可行的技术研发思路与方案。同时,模型基于STS任务还可获取科技文献及其包含的关键词术语的语义相似关系,进而实现关键词术语的歧义问题的自动优化。
本文在第1 节对相关工作进行总结,第2 节对研究中涉及的概念及问题进行描述与定义,第3 节对本文模型及关键算法原理、关键技术等进行论述,第4 节选用实验数据对本文模型的有效性进行验证及分析,第5 节对研究工作进行总结。
1 相关工作
1.1 表示学习及动态词向量相关模型
表示学习(representation learning)是指将研究对象的语义信息表示为稠密的低维实值向量,在该向量空间中,研究对象的距离越近,语义相似度越大[16]。在自然语言处理领域,将研究对象作为知识实体对其进行表示学习,可通过数值计算发现知识间新的关系、潜在及隐式知识;同时,基于向量的知识表示方法,可直接对接深度学习等模型,在链接预测、实体对齐、信息推荐等领域均有重要的应用场景[17]。在基于向量的知识表示方法中,Firth[18]于1957 年提出了分布式语义假设的思想,即词的含义由其上下文的分布进行表示,其常见表示方法有点互信息、奇异值分解等。随着深度学习模型在自然语言处理领域的不断应用,知识表示方式又可进一步划分为静态词向量和动态词向量两种。词只有唯一的向量表示的模型,称为静态的词向量表示方式, 如word2vec (word to vector)[19-20]、 GloVe(global vectors for word representation)[21]等。静态词向量无法解决词的多义问题。词的向量随其出现的上下文的不同而发生变化的模型,称为动态的词向量表示方式,如ELMo (embeddings from lan‐guage models)[22]、BERT (bidirectional encoder rep‐resentations from transformers)[23]、GPT (generative pre-trained transformer)[24]等。动态词向量被认为是词的强大、灵活表示方式,如“苹果”出现在不同文本中分别表示手机和水果时,可将其映射为不同文本环境中的向量数据,进而通过计算词向量之间的相似度来区别语义异同。
1.2 文本语义相似度分析与对比学习模型
文本语义相似度分析是判断一对文本的语义相似程度的自然语言处理任务。文本语义相似计算的研究是自然语言处理领域的热点问题,其在信息检索、信息推荐、智能问答等领域均具有极其重要的应用。文本语义相似度计算方法包括编辑距离、Jaccard 相似度、VSM (vector space model)、LSA(latent semantic analysis)、PLSA(probabilistic latent semantic analysis)、 LDA (latent Dirichlet alloca‐tion)、基于深度学习模型的方法等。目前,对比学习模型可以将语义上相近的文本分布在相对接近的语义空间内,将不相似的文本分布在相对远离的语义空间内,从而能被较好地用于文本语义相似度分析任务。在对比学习模型中,构建样本实例对数据集其中为语义相关的实例对,可通过对同一个文本xi进行数据增强(如删除词汇、重新排序、替换词语等)实现实例对的构建。在文献[25-26]中,研究人员发现在自然语言的表示学习中存在Anisotropy 的问题,即模型学习到的嵌入在向量空间中占据一个狭窄的圆锥,严重限制了向量的表现能力。为了衡量向量表示的质量,文献[27]提出了Alignment 和Uniformity 两个衡量向量表示质量的指标;文献[28]提出了一个简单的对比学习框架,该框架通过一个简单的Dropout 数据增强方法,可以在Alignment 和Uniformity 两个指标上表现优异,同时在句子向量表示及文本语义相似度分析任务方面取得了较好的效果。使用Alignment和Uniformity 两个指标衡量对比学习模型中句子的向量表示质量,有助于正样本实例在嵌入空间中保持接近,随机实例分布在超球体上。在评价STS 任务的指标中,Reimers 等[29]通过研究证明,STS 任务采用Spearman 相关系数作为评价指标更为适合。Spearman 相关系数关注的是两个序列的单调性是否一致。在本文中,模型训练完成后,可对数据集中每条记录中的每一对文本进行余弦相似度计算,然后利用所有记录的余弦相似度数值和标签值,计算获取Spearman 相关系数的数值,并将该数值用于评估相关模型在STS 任务上的效果优劣。因此,本文认为对比学习模型在科技文献相似研究数据集上进行语义相似度分析时,Spearman 相关系数越高,模型在STS 任务上的效果越佳,而依据该STS 任务形成的科技文献及其关键词术语在向量空间的分布情况会更加趋于合理,相关知识向量表达的语义信息会更为精确,最终通过聚类算法获取的语义相似学科交叉主题的准确性也会更优。不同学科的科技文献中具有相似的核心研究主题或内容,即具有相似语义的知识分布在不同学科的科技文献中,是不同学科间的知识流动扩散现象。本文认为,利用STS任务获取知识之间的语义相似关系,可为探索获取语义相似学科交叉主题提供新的解决思路。
2 问题定义
本节对科技文献、科技文献的学科、科技文献的文本等进行描述及定义,并提出问题定义。
定义1. 科技文献。给定科技文献数据集L=其中,Ln为数据集L中的科技文献,包含题目、关键词、摘要、学科分类、年份等信息。本文通过3.2 节提出的方法构建科技文献相似研究数据集,定义为LS。
定义2. 科技文献的学科。科技文献的学科定义为集合D,M为D中学科的数量, 定义D=的学科属性可为集合D中的一个或多个元素。学科交叉研究中通常会将Ln划分到某一学科之下,然后识别不同学科科技文献共有的文本内容。本文设定科技文献被划分到某一个学科之下,并定义Ln的学科属性为Dmn,表示Ln具有的一个学科属性为Dm。同时,定义L中各科技文献的学科属性为
定义3. 科技文献的文本。科技文献Ln的文本内容通常包括题目、关键词、摘要、正文等信息。其中,Ln的关键词通常为3~5 个,来源于科研人员撰写Ln时提供的描述科技文献主题的关键词术语,本文定义为关键词集合不同Ln中I值可能不同。本文对科技文献Ln中的题目和摘要进行分词、停用词删除等数据预处理。将题目中包含的关键词定义为题目关键词集合不同Ln中Q值可能不同。在摘要中使用TF-IDF(term frequencyinverse document frequency)算法提取前20 个重要关键词,并定义为摘要关键词集合将Ln表示为Ln经过特定任务的表示学习模型训练后,获取Ln中关键词的向量集合, 分别定义为和同时将L中的科技文献的向量集合定义为本文模型中,关键词采用的是动态的向量表示方式,即相同的关键词出现在不同的科技文献Ln时,其向量值是不同的。
问题定义. 本文将语义相似学科交叉主题识别问题定义为,发现具有不同学科Dm属性的Ln之间的语义相似研究主题。
同时,将针对该问题所构建的模型称为语义相似学科交叉主题识别模型(semantically similar inter‐disciplinary topics,SSIT),即
其中,Θ表示模型S涉及的参数。SSIT 模型的输入为L中的Ln包含的关键词数据(摘要使用TF-IDF 算法提取前20 个重要关键词)以及对应的学科SSIT 模型的输出为语义相似学科交叉主题,将其定义为ST,其包括科技文献层面和科技文献关键词术语层面的语义相似学科交叉主题,即聚类簇中包含了多个不同学科属性的科技文献或关键词。
3 模型及实验方法
本节分别对SSIT 模型的实现原理、科技文献相似研究数据集构建方法、科技文献及关键词的表示学习技术以及语义相似学科交叉主题的获取与评价方法等进行论述。
3.1 语义相似学科交叉主题识别模型
本文构建的语义相似学科交叉主题识别模型如图1 所示,其原理及步骤如下。
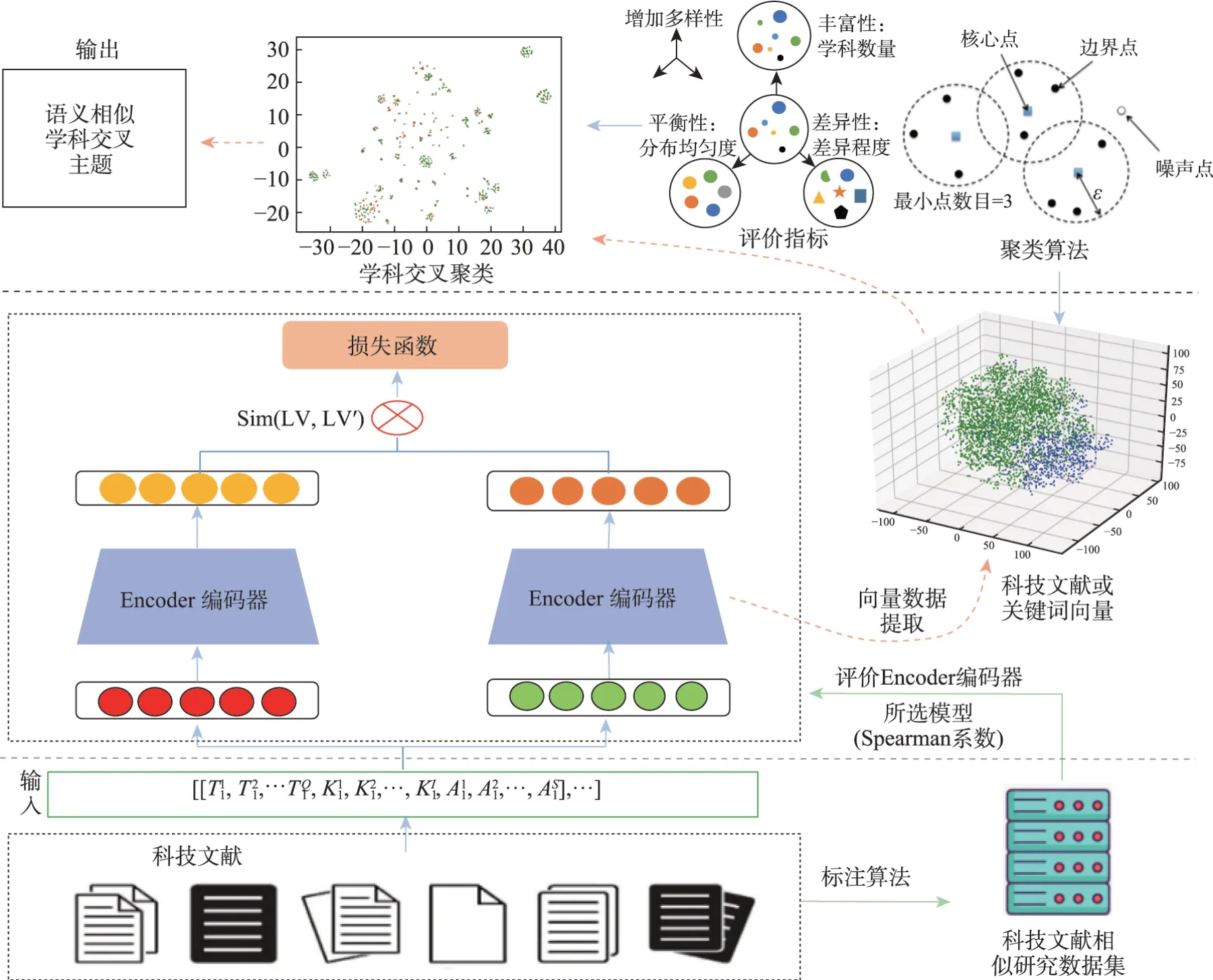
图1 语义相似学科交叉主题识别模型
Step1.将Ln处理为的形式并输入SSIT 模型,同时构建科技文献相似研究数据集LS,详见3.2 节。
Step3.为选择合适的Encoder 部分的预训练模型,本文选取了BERT、RoBERTa 和SimBERT 这3 种预训练模型进行无监督对比学习的训练,然后在LS 数据集上分别获取Spearman 相关系数。最终,选取Spearman 相关系数最佳的预训练模型,并将最佳的完成训练的模型保存为EncoderBest。
Step4.将L输入模型EncoderBest,提取科技文献向量集合科技文献中包含的关键词向量集合
Step5. 利用DBSCAN (density-based spatial clustering of applications with noise)聚类算法,从L_V中提取科技文献聚类簇集合Clus_L,从LK_V中提取关键词聚类簇集合Clus_K。以RS(Rao-Stirling)指标评价排序各个聚类簇(聚类结果只包含1 个学科的数据时,RS 值为0,模型会将此类聚类簇剔除掉),获取具有相似语义的学科交叉主题聚类簇集合Cross_L和Cross_K。
依据Step1~Step5,将Cross_L和Cross_K作为模型的输出ST(语义相似学科交叉主题)。
3.2 科技文献相似研究数据集
本文认为学科交叉研究中,具有较为相似研究的不同学科科技文献是语义相似学科交叉研究主题识别的数据来源。通过构建科技文献相似研究数据集,本文认为STS 任务在数据集上的Spearman 相关系数越高,科技文献及其关键词术语在向量空间中分布越合理,在此基础上,通过聚类算法对向量数据进行聚类,其获取的语义相似学科交叉主题的准确性也会越佳;即可采用构建科技文献相似研究数据集间接进行模型性能的评估,以解决学科交叉研究时难以提供学科交叉研究数据集验证模型性能的难题。共词理论认为,同一科技文献中不同的术语之间的关系是被作者认可和要求的,如果有足够的作者对同一种关系认可,那么这种关系所关联的科学领域具有一定的意义[15]。基于该理论,本文提出,若不同的Ln中包含相同数量的代表性关键词,则可认为不同的Ln在某种程度上具有相似的主题或语义。据此,本文提出了一种快速构建科技文献相似研究数据集的算法。
针对数据集中相似研究数据部分的构建,本文使用结巴分词对Ln的题目、摘要文本进行处理,并自建停用词词典、分词词典。其中,题目部分使用预处理后的全部关键词摘要部分使用TFIDF 算法获取前20 个(依据当前语料特点选定)关键词将不同Ln标注为具有相似语义或主题的文本对时,需要同时满足以下两个条件。
C1:不同Ln的中具有相同关键词的数量为大于等于TX(本文取TX=1)。
C2:不同Ln的和中具有相同关键词的数量为大于等于TY(本文取TY=3)。
针对数据集中不相似研究数据的构建,4.1 节有相关描述。两个部分的数据共同组成科技文献相似研究数据集LS。
3.3 科技文献及关键词的表示学习
将科技文献及关键词通过表示学习方法映射到语义向量空间中合适的位置,是本文模型提取学科交叉主题的前提。学科交叉主题识别的目标是发现不同学科间具有相似语义的研究主题。从语义相似角度对文中的学科交叉主题识别进行解析,可以认为是将科技文献映射到向量空间后,需要完成具有相似研究主题的科技文献在向量空间中尽量接近、不相似研究主题的科技文献则尽量远离的任务。对比学习模型的基本思想是“正样本尽量接近,负样本尽量远离”。基于无监督对比学习可通过自动构建相似和不相似的实例训练知识的表示学习模型,使相似的样例投影到向量空间时尽量接近,不相似的样例投影到向量空间时尽量远离。文献[28]将对比学习思想引入句子Embedding 中,在语义相似度计算的研究中取得了较好的效果。基于上述研究工作,本文采用无监督的对比学习方法对中文科技文献进行文本语义相似度分析。具体思路为,对于科技文献数据集合将N个文本经过带Drop‐out 的Encoder 模型得到向量LV1,LV2,…,LVN;然后,让该N个文本再次经过带Dropout 的Encoder 模型得到向量将作为正样本,其训练损失函数为
其中,r的值在本文模型中取为正样本,为负样本。
本文模型分别选用BERT[23]、RoBERTa[30]、Sim‐BERT[31]作为对比学习模型的Encoder 部分。其中,BERT 模型是一种上下文双向编码模型,主要使用Transformer 模型的Encoder 部分;RoBERTa 模型是在BERT 模型基础上进行简单改动后构建的模型,其使用更多的训练语料,采用动态MASK 和更大的Batch-size 参数等;SimBERT 是以BERT 模型为基础,基于微软的UniLM 思想[32],融检索与生成为一体的模型。模型获取科技文献及其关键词向量的原理如下:
(2)选用训练完成的Encoder 部分的模型,在本文构建的LS 数据集上计算Spearman 相关系数;
(3) 本文模型对比BERT、 RoBERTa、 Sim‐BERT,选取Spearman 相关系数最佳的预训练模型作为Encoder 部分;
(4)将L输入训练完成的Encoder 部分最佳预训练模型,将模型输出的向量数据作为科技文献Ln的向量LVn,从模型输出的、未进行池化操作前的向量数据中,提取科技文献Ln包含的关键词向量实现科技文献及其关键词术语到向量的映射。
上述(1)~(4)是3.1 节模型中Step2~Step4 的详细实现过程。
3.4 学科交叉主题的获取与评价
为从训练获取的科技文献及关键词向量数据中提取学科交叉主题,本文模型使用DBSCAN聚类算法对科技文献向量和关键词向量分别进行聚类,然后通过学科交叉评价指标RS 对各个聚类簇进行计量排序,提取学科交叉主题。
本文模型借鉴Stirling[33]提出的RS 指标从学科丰富性、平衡性和差异性3 个维度衡量聚类簇的学科交叉程度。Rao-Stirling 指标值越高,表明学科差异性越大,学科交叉性越强。其公式为
其中,pDi和pDj是不同学科的分布概率;dDi,Dj是不同学科之间的距离;α和β是计量参数,通常设置为1。
以关键词聚类簇为例,pDi和pDj分别为某聚类簇中属于学科Di和Dj的关键词数量与聚类簇中关键词总数量的比值,如果聚类簇中某学科的关键词数量为0,那么其RS 值也为0,该聚类簇不具有学科交叉性质。dDi,Dj衡量的是不同学科之间的差异性。由于余弦相似度衡量的是向量间的相似性,本文借鉴文献[34]通过余弦相似度对学科之间的差异性进行测度的方法,将学科之间的差异性定义为聚类簇中学科Di与Dj的距离dDi,Dj,计算公式为
将聚类簇中学科Di的关键词向量相加,然后求均值KVDi,用于表示学科Di的知识,计算公式为
将聚类簇中学科Dj的关键词向量相加,然后求均值KVDj,用于表示学科Dj的知识,计算公式为
4 实验及分析
4.1 实验数据
本文选用国家自然科学基金立项项目数据进行实验分析,其包含题目、关键词、摘要等信息,与本文模型所需的输入数据具有一致性,因此,不会影响本文模型的有效性。实验数据选取2011—2019年“F06 人工智能”“G0114 信息系统与管理”“G0414 信息资源管理”对应的项目数据(学科代码依据2019 年公布的申请代码数据)。其中,G0114、G0414 对应的620 项数据涉及“信息系统及其管理”“决策支持系统”“数据挖掘与商务分析”“图书情报档案管理”“社会与政府信息资源管理”等研究方向,本文将其学科属性统称为“G 信息管理”学科;F06 对应的2657 项数据涉及“人工智能基础”“机器学习”“机器感知与模式识别”“自然语言处理”“知识表示与处理”“智能系统与应用”“认知与神经科学启发的人工智能”等研究方向,本文将其学科属性统称为“F 人工智能”学科,两个学科共涉及3277 个项目。在上述数据中,F 学科的项目偏重于人工智能技术的研究,而G 学科的项目则偏重于从管理学角度展开研究。本文获取两者之间的交叉融合主题,对揭示人工智能技术与信息管理研究领域的相互影响及演化具有一定的价值,在引导信息管理领域不断融入人工智能技术、助力其科学问题逐步完善与解决方面具有积极作用。
依据3.2 节的方法获取相似研究项目数据1603条,将其涉及的项目称为集合SL,然后计算包含所有项目的集合L与SL 的差集NL。使用随机函数从SL 中选取任意一项目,分别与NL 中的项目生成不相似研究数据,并随机从中提取1068 条记录(2×1603/3 计算结果的整数值部分);从NL 中随机挑选两个项目Ln组成不相似数据,并随机从中提取1068 条记录(2×1603/3 计算结果的整数值部分),最终形成表1 所示的数据集。数据集标签为1 的记录中(1603 条),每条记录中的两个项目均属于F 学科的记录为1439 条,两个项目均属于G 学科的记录为97 条,两个项目分别属于F 学科和G 学科的记录为67 条。由于本文模型仅在从项目及关键词的向量数据中提取语义相似学科交叉研究主题时涉及项目的学科属性,因此,可以认为数据记录中的项目学科属性分布情况对模型的有效性没有影响。

表1 相似研究数据集
4.2 参数设置
本文模型采用无监督对比学习的思路,数据训练时,在同一个mini-bach 中,同一项目与自己建立正例关系,与其他项目建立负例关系,完成模型训练。利用训练完成的Encoder 部分预训练模型,在文中标注的LS 数据集上,计算Spearman 相关系数,进行Encoder 部分不同预训练模型的评价与选取。实验中,选取对比了BERT、RoBERTa 和SimBERT 共3种模型,每种模型分别采用4 种pooling 方式进行训练:CLS,使用Encoder 的最后一层的[CLS]向量;Pooler,使用Pooler 对应的向量;last-avg,使用En‐coder 的最后一层的所有向量取平均;first-last-avg,使用Encoder的第一层与最后一层的所有向量取平均。
本文Encoder 部分使用的不同模型的性能如表2所示,表中数据为对比学习模型在相似研究数据集上的Spearman 相关系数值。由表2 可知,RoBERTa模型和SimBERT 模型采用的一些池化方法的Spear‐man 相关系数可达0.80 以上。因此,结合first-lastavg 方法在本文模型及数据上的良好表现,最终选取SimBERT 模型结合first-last-avg 方法完成模型训练,参数如表3 所示。
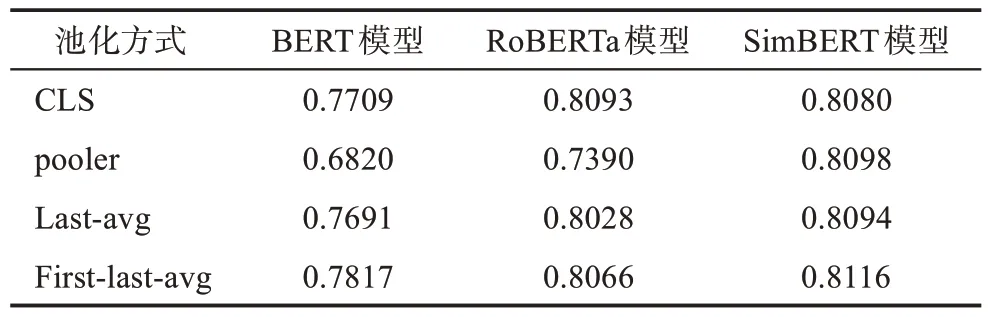
表2 Encoder选用的预训练模型性能对比

表3 模型中Encoder部分相关参数设置
本文实验中,将项目数据输入训练完成的Sim‐BERT 模型,将经first-last-avg 池化后生成的向量数据提取出来作为项目向量从池化之前的向量数据中获取每个项目的中每个关键词包含的每个字的向量,通过向量相加求均值的方法提取关键词向量实验通过t-SNE(t-dis‐tributed stochastic neighbor embedding) 算法对数据进行降维,并获取项目及项目包含的关键词在向量空间中的分布,如图2 所示。
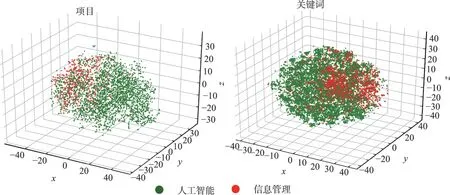
图2 项目及其关键词在向量空间中的分布(彩图请见https://qbxb.istic.ac.cn)
为提取语义相似学科交叉主题,本文模型采用DBSCAN 聚类算法对项目向量和项目关键词向量分别进行聚类,参数如表4 所示。然后,使用公式(4)分别对项目和关键词层面的聚类簇进行评价。同时,借鉴科学计量学领域依据年份信息划分并进行结果分析的方法,将项目实验数据划分为3 个时间段:2011—2013 年、2014—2016 年、2017—2019 年。
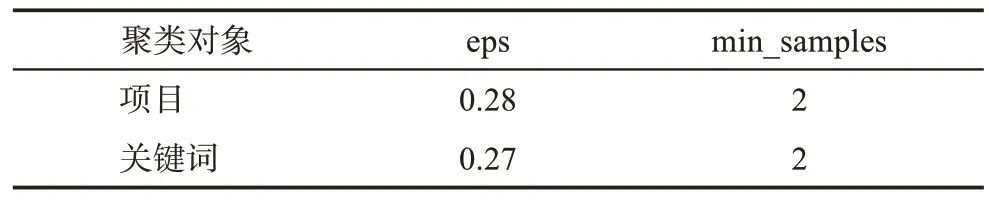
表4 模型中聚类部分参数
4.3 实验结果与分析
为利用时序信息分析语义相似学科交叉主题的变化,将实验结果分为3 个时间段。以2011—2013年结果为例,F 学科和G 学科的项目中共有的关键词数量为79 个。本文模型对各项目中的关键词向量聚类后获取67 条结果,表5 显示了部分具有代表性的学科交叉主题。表5 中每一行为一个聚类簇,即语义相似学科交叉主题,表中的“RS”列表示RS 指标对各个聚类簇进行学科交叉性测度后的数值,“项目”列表示聚类簇中的关键词涉及的项目数量。表6 是对项目向量进行聚类后,获取的项目粒度的聚类结果。图3 为项目中的关键词向量聚类后,获取的67 条聚类簇(语义相似学科交叉主题)中涉及的所有关键词向量降维后的可视化呈现。可以发现,语义较为相近的聚类簇在空间中也会较为接近。此方法可在一定程度上辅助相关人员获取更为宏观层面的语义相似学科交叉研究主题。

表5 2011—2013年关键词层面的学科交叉主题

表6 2011—2013年项目层面的学科交叉主题
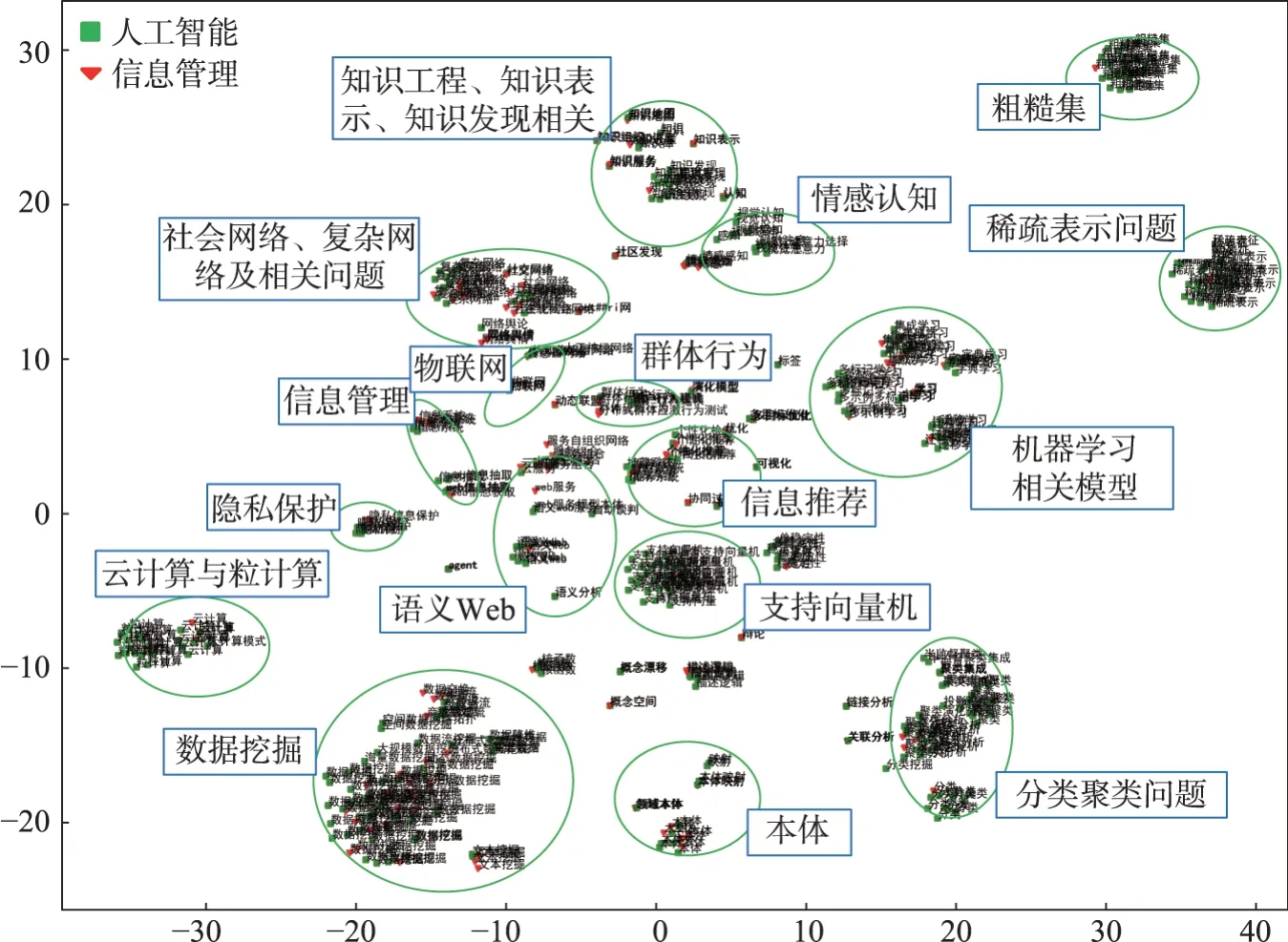
图3 2011—2013年学科交叉主题(关键词)分布
本文对2011—2013 年、2014—2016 年、2017—2019 年3 个时间段的语义相似学科交叉主题(关键词聚类结果、项目聚类结果) 做进一步解读。
由于本文模型是将语义相似的科技文献或关键词术语聚类为同一个簇,相关聚类结果中的科技文献或关键词术语代表的含义较为一致。因此,在提取某聚类簇的主题标识时,直接通过人工方式获取能代表该聚类簇的主题。以2011—2013 年为例,关键词层面的语义相似学科交叉主题包括群体行为、超图模型、链接分析、语义分析、可视化、概念空间、Web 服务、人工神经网络、协同过滤、自动谈判、演化模型、情境感知、关联分析、属性约简、信息系统、领域本体、动态联盟、知识组织、社区发现、视觉及情感感知、知识表示、传感器网络、本体映射、文本挖掘、知识地图、网络舆情、多模态信息、隐私保护、多目标优化、概念漂移、用户行为模型、知识服务、信息抽取、Petri 网、知识库、核函数、Agent、物联网、描述逻辑、推荐系统、组合云服务、云计算、多示例多标记学习、个性化信息推荐、字典学习、高维数据降维、集成学习、社会网络、语义Web、知识发现、复杂网络、本体、分类算法、迁移学习、聚类算法、支持向量机、数据挖掘与分析、粗糙集、稀疏表示等。但存在一些关键词术语表达的含义较为笼统的问题,如“优化”“认知”“知识”“协同”等,无法较好地表达学科之间的交叉主题。另外,本文模型由于词的语义来自其上下文,少数学科交叉主题会存在不准确的问题,如表5 中序号47 的结果等。本文认为上述从关键词层面呈现学科交叉研究主题时存在的问题,并不影响模型思路的有效性。项目层面的语义相似学科交叉主题包括数据流挖掘、社会网络用户行为研究、机器学习中的高维数据聚类等。从项目层面获取学科交叉主题时,不同学科间非常相似的研究较少,并不能较好地反映两个学科间的学科交叉研究主题。
为更好地呈现各种语义相似学科交叉主题,本文将关键词层面的语义相似学科交叉主题中的关键词向量降维到二维空间进行可视化呈现。其中,2011—2013 年的结果见图3,2014—2016 年的结果如图4 所示,2017—2019 年的结果如图5 所示。从上述可视化结果中可以发现,一些语义上较为接近的学科交叉主题在向量空间中会分布在相对较为接近的位置,这为快速获取较为宏观的学科交叉方向提供了帮助。对结果进行进一步解析,发现在关键词层面,2011—2019 年的3 个时间段中,机器学习相关技术(核函数、多示例多标记学习、高维数据降维、集成学习、分类算法、迁移学习、聚类算法、多模态信息、多目标优化、支持向量机、深度学习、机器学习等)、用户行为分析(群体行为、用户行为模型、隐私保护、情境感知、用户信任问题、视觉及情感感知等)、信息服务(信息系统、Web 服务等)、信息管理、信息推荐、社会网络科学相关研究、云计算、语义本体、文本知识挖掘、舆情监控等,在两个学科的研究中一直受到较多共同关注。其中,2014—2016 年,在已有学科交叉研究方向的基础上,出现了人机交互、医疗健康(临床决策支持系统、健康管理) 等新的研究方向;2017—2019 年,依旧在人机交互、医疗健康(临床决策支持、PM2.5空气污染、食品质量安全)方向给予关注,同时金融风险识别与防范(欺诈识别、欺诈与反欺诈、互联网金融、P2P 借贷)方向上的研究也逐渐受到关注。在项目层面,2011—2013 年(见表6,共3 个聚类结果)的相关学科交叉研究有数据流挖掘、社会网络用户行为研究、机器学习中的高维数据聚类问题等,2014—2016 年(如表7 所示,共7 个聚类结果)的相关学科交叉研究有社会网络影响力问题、社交网络个性化推荐、数据流挖掘相关问题、社会化媒体数据管理与分析相关问题、微博舆情监测与跟踪、社交网络社区发现相关问题、社会网络及用户行为相关问题研究等,2017—2019 年(如表8 所示,共4 个聚类结果)的相关学科交叉研究有社会网络中主体对象的行为分析、用户情感分析、云服务中的定价问题、金融领域个人信用风险评价相关问题等。在3 个时间段中,社会网络及用户相关研究一直是两个学科之间交叉的重要研究地带。

表7 2014—2016年项目层面的学科交叉主题

表8 2017—2019年项目层面的学科交叉主题
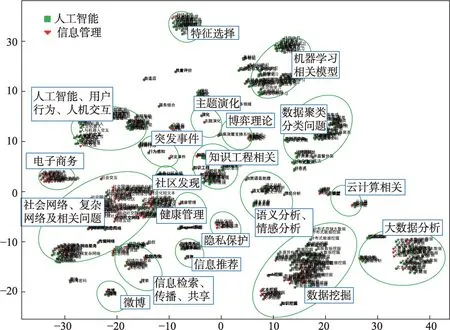
图4 2014—2016年学科交叉主题(关键词)分布
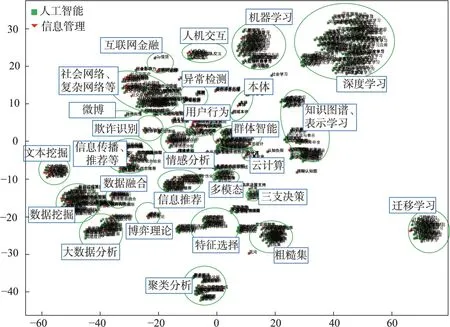
图5 2017—2019年学科交叉主题(关键词)分布
分析语义相似学科交叉主题在不同时间段的分布情况,可为研判学科交叉研究发展方向提供帮助。从上述结果可知,两个学科之间的交叉研究主题如机器学习、用户行为、社会网络科学等,是两个学科之间持续关注的热点问题,此类问题与近年来两个学科的交叉研究情况基本保持一致,其作为两个学科在较长时间持续关注的研究方向,具有形成相关交叉学科的潜力。人机交互、医疗健康、金融风险识别与防范等方向上新出现的学科交叉研究主题,与近年来人工智能技术的兴起密不可分,基本反映了信息管理学科的研究急需融入更多的有效技术,以实现有效解决相应科学问题的需求。这些新出现的研究方向基本与现有的重要学科交叉研究相一致,也需要在未来的项目资助中予以关注及引导。
4.4 模型评价
通过对相关结果进行解析,可认为本文模型可以较好地捕获不同学科之间的语义相似学科交叉研究主题,具有应用于学科交叉主题预测预警系统研发的可行性。本文模型的优势:①相同的关键词术语出现的上下文环境差异较大时,会因语义不同而被区分开,本文认为此类研究更多的是知识(关键词术语)在不同学科的移植,还未进行不同学科知识的深入渗透与融合。例如,“数据挖掘”是一个较为宽泛的概念,只有当其关联的两个不同学科具有较为相近的上下文时,将相应项目聚类到同一学科交叉主题中(同一聚类簇)才更为合理和有效。②本文模型在实现语义相似学科交叉主题发现的同时,对关键词术语的同义现象也有较好的鉴别能力,如表5 中序号24 的结果难以通过编辑距离方式获取,但是本文模型能将其列为两个学科之间的情感与感知方面的交叉研究方向。③对本文模型获取的关键词向量进行降维后,获取了如图3~图5 所示的结果,可以发现,一些相关的聚类结果会分布在较为靠近的向量空间,这可为研判较为宏观的学科交叉方向提供帮助。
同时,本文模型的一些不足需要在后续研究中予以关注:①本文模型提取的一些学科交叉主题聚类结果存在一定的误差,虽然在整体上不会影响模型思路的有效性,但需要在后续的研究中对此类问题进行完善及解决。例如,对于表5 中序号47 的结果,本文模型未能较好地获取关键词“服务组合”的语义信息。②从模型结果可知,相比于项目层面,模型在关键词层面获取的学科交叉研究主题更能反映出合理的、细化的学科交叉主题或研究方向,但一些关键词术语表达的含义较为笼统,如“优化”“认知”“知识”等,会影响相关人员研判交叉主题的有效性,需要在后续研究中从规范关键词术语方面展开研究。
总体来看,本文模型的不足可在后续的研究中通过优化模型进行完善,并不影响模型思路的合理性及有效性。同时,本文模型揭示的两个学科的学科交叉研究主题与现有及未来的学科交叉研究方向与发展趋势较为一致,因此,可认为模型获取的最终结果科学有效。在模型应用方面,本文模型提取及呈现学科交叉主题的方式可为学科交叉预测预警系统的研发提供技术思路。模型借助RS 指标对相关结果进行排序的方法,也可为系统研发中分析与评价相关研究主题提供参考。本文现有研究中,主要关注科技文献及关键词语义相似关系的表示学习,以及如何评价模型获取语义相似学科交叉主题的有效性等问题的解决,现有模型也主要关注两个学科之间的语义相似学科交叉主题识别的应用场景,后续研究需要关注模型在更大数据量、更多学科场景下的学科交叉主题识别验证研究。
5 总结与展望
本文提出了一种语义相似学科交叉主题识别模型,并通过相关实验证明了模型的有效性。实验结果表明,通过本文提出的语义相似学科交叉主题识别模型获取的主题,基本上与两个学科的特点相一致,即人工智能学科为信息管理学科提供技术支撑,信息管理学科的一些科学问题为人工智能技术的应用落地提供了更加丰富的应用场景。本文实验虽然存在少数结果不准确的问题,但认为可在后续研究中通过对模型的进一步完善予以解决。同时,结合目前的研究情况,本文认为需要在后续研究中对以下问题进行深入关注,以更好地优化现有的研究工作:①在大规模的、多学科领域的科技文献数据上进行模型有效性的证明实验,以探索模型揭示更为有意义和价值的学科交叉融合主题的能力。为了便于验证模型的有效性,本文选取了较为熟悉的2 个学科进行验证,但最终仍需要在相关学科领域专家的指导下,在更多的、不同的多个学科之间检验模型的有效性和应用价值。②科技文献主题词的规范以及代表性关键词术语的抽取问题。现有模型选取的是基金项目申请人员通过系统辅助选取或自己填写的关键词,基于此类关键词的数据挖掘虽然可有效减轻模型识别学科交叉融合主题时的复杂性,但是也为后续的结果解读带来一定的困扰。构建规范的主题词进行研究,会面临大规模的、复杂的科技文献数据处理带来的各种挑战。因此,如何基于文本机器学习技术有效识别能代表科技文献有效研究内容的关键词或主题词依旧是学科交叉融合研究的重要问题。③针对科研领域的中文预训练模型的训练。科学研究中的科技文献有其自身的用词、语法等特点,因此,需要收集大量不同学科科技文献数据训练模型,进而提升模型的有效性,实现学科交叉主题识别的准确性。④数据可视化方法的探索。本文现有的研究工作主要通过简单的数据降维等方法实现学科交叉主题的呈现,在有效呈现学科交叉主题方面还存在一定不足。在后续的研究中,除了关注学科交叉主题发现方法的研究,还需要探索适合当前任务的、能有效传达视觉效果的学科交叉主题可视化呈现功能,助力学科交叉主题预测预警平台的界面友好性。
