数据恢复技术在计算机数据处理中的运用研究
2024-02-03余琳睆
余琳睆
(江西制造职业技术学院 江西 南昌 330095)
0 引言
在互联网技术飞速发展的背景下,应用与用户交互产生的数据量也随之增大,计算机作为现阶段采用的一种应用组件,其为个性化推荐、实施交互等提供了运行环境,但是计算机磁盘损坏、数据丢失等情况也层出不穷,对数据恢复技术进行研究迫在眉睫[1]。 有关研究显示,磁盘损坏导致数据丢失概率为80%[2]。 为实现丢失数据的恢复,相关研究人员提出C⁃Algorithm 和U⁃Algoithm 两种数据恢复算法,这两种算法可实现数据恢复时的负载均衡[3]。 部分研究人员通过BP 方案实现丢失数据的恢复,但是此种方案的数据恢复时间相对较长[4]。 基于此,本文提出一种基于稀有度感知的分阶段数据恢复算法,在现有数据的分布情况与利用情况的基础上,通过分段恢复的方式,实现丢失数据的有效恢复。
1 计算机数据丢失、恢复问题分析
1.1 计算机数据中心架构
假设云系统计算机数据中心架构为3 层树状结构(如图1 所示),主要由交换机与物理服务器组成,交换机作用在于连接物理机,物理机中包含大量原始数据。

图1 计算机系统中心架构
若计算机数据中心中物理机数量为N物理机、原始数据数量为N原始,此时计算机数据中心可表示为式(1)所示。
1.2 数据中心服务和数据
对于计算机数据中心而言,其主要是根据数据分析结果,通过消耗相应的带宽实现与用户之间的交互,以此来为用户提供相应的服务[5]。 因此,计算机数据中心所提供的服务可表示为式(2)所示。
式(2)中,Sj为第j个数据副本;Di为带宽资源的需求。
对于计算机数据中心中的数据而言,其主要是以不同的形式存储,故服务对Sj的依赖主要是对某一数据进行分析。
假设Bjk为数据Sj的第k个数据,此时计算机中心所提供的服务可进一步表示为式(3)所示。
式(3)中,Bjk为数据在Sj在Pk中的数据副本,Pk为物理机。 此时可通过公式(4)表示服务Fi访问的数据副本,即:
则服务与数据副本两者之间的关系可表示为式(5)所示。
由此可看出,服务主要由数据副本、物理机、带宽资源等部分组成,服务主要是由相应的数据副本提供支持,数据副本可为多个服务提供支持。 对于数据副本而言,其在计算机系统中的重要性与对服务的支持程度,可在服务对带宽资源需求的基础上,定义其负载,即式(6)所示。
式(6)中,NF为数据中心服务数量。 因此,为有效提升数据安全质量,数据需遵循相应的安全分布原则,各组数据至少需有两个副本分布在不同的机架中,当机架失效后,剩余副本仍能提供相应的服务。 对于数据副本的分布情况而言,可通过物理机对数据副本的承载关系以及物理机的位置关系进行表示,即式(7)、式(8)所示。
此时Sj在计算机系统中的副本数量可表示为式(9)所示。
在上述系统架构的基础上,若出现磁盘失效导致数据副本丢失时,系统将自动恢复数据,也就是将源物理机中相应的数据副本拷贝到目标物理机中[6]。 在数据恢复过程中,数据的拷贝量对目标物理机造成一定的影响。 若系统中未做相应的数据拷贝,则服务质量最佳,将其记为1;若系统中数据拷贝难以满足带宽资源需求时,则可根据资源平均利用规则,将资源分配量进行转变,此时物理机上应用的服务质量Q(Pi)可表示为式(10)所示。
式(10)中,1/(k+1)为转变后的资源分配量。
此时,系统的整体服务质量QoS可表示为式(11)所示。
对数据的恢复而言,其主要是为了实现QoS的最大化。
1.3 计算机数据副本恢复问题
通过上述分析得知,在磁盘失效导致计算机系统中样本数据丢失的情况下,可在确定数据恢复数量的基础上,选择适量的目标物理服务器。 由于目标物理机在安全规则的基础上只能够接收部分拷贝数据样本,并且数据副本拷贝过程中会严重影响服务质量。 因此,在数据恢复过程中,需选择能够恢复所有预数据副本的物理机,进而降低服务质量的损耗[7]。
通过上述分析得知,数据副本的恢复问题属于集合覆盖的问题,也就是说需从相应的集合中,选择若干个集合,这些集合中包含所有基本元素,且每个集合中都存在相应的选择成本,这样可将选中集合中的成本之和降低至最小。 对于数据副本恢复选中的目标服务器可接收副本集合(记为set(Pi))、 服务质量的损耗(记为cost(Pj)) 而言,其实质与集合覆盖问题中的基本集合、成本相对应。因此,为有效降低数据拷贝对服务质量造成的影响,需从时间、数量等方面降低数据拷贝的数量。
2 基于稀有度感知的分阶段数据恢复算法
2.1 算法分析
对于分阶段数据副本恢复算法而言,其主要是将需要恢复的数据副本划分成不同恢复阶段,进而降低数据副本恢复过程中的链路资源开销。 基于此,本文通过稀有度模型来描述数据中心中数据的冷热程度。 对于稀有度而言,其主要是根据数据负载以及数据副本的个数进行确定,在通常情况下,确定数据负载主要表示该数据的副本负载之和,可表示为式(12)所示。
式(12)中,Ljk为Cjk的负载,NP为数据中心物理机个数。
则数据的稀有度可表示为式(13)所示。
式(13)中,β主要根据Hj的大小以及式中其他变量进行调节。 在数据稀有度RTj小于0 的情况下,说明数据活跃度相对较高,则数据稀有度较低,需进行恢复。 反之,数据为冷数据,稀有度较高,无须修复,但是这部分数据需遵循相应的安全规则。
2.2 算法实施过程
在进行数据稀有度感知分阶段数据恢复时,首先需要确定恢复集合setA、setB,在这两个集合中,setA中的数据不满足安全规则,需要对其中的数据进行恢复,而setB中的数据满足安全规则,但是该集合中数据的负载相对较高,需对其中的数据副本进行恢复处理;其次,在setA、setB集合的基础上,采用分阶段数据副本恢复算法,根据相应的安全等级,对副本进行安全恢复处理(优先恢复安全等级高的数据副本),在恢复过程中,需选择负载相对较小的物理机,在最小负载机的物理机不满足要求时,选择小负载物理机。
3 算法测试分析
3.1 测试环境
为验证本文提出算法的可行性,对其数据恢复效果进行测试。 测试环境参数为:在机架内增设4 台物理机、2台交换机,1 个交换机连接1 个机架中的2 台物理机,通过路由器实现交换机之间的连接,链路带宽定为1 000 Mb/s。 对于其中所使用的物理机而言,其可存储1 000 个数据,且物理机中包含的数据副本初始数量在2 ~5 个范围内,符合正态分布,并且满足相应的安全规则。 当数据处理为初始条件下时,系统中会出现相应的服务,其中的每个服务与数据副本相对应,且服务负载为50 ~200 的正态分布。 为提升数据处理效果,试验采用配置为Inteli7 处理器、8 GB 内存的计算机,通过该计算机模拟物理机的失效过程,并分析文献[1]算法与本文算法数据恢复效果。
为测试不同负载下各算法数据恢复效率,测试过程中将服务的总带宽需求作为衡量系统负载u的指标,具体表示为式(14)所示:
式中,F平为平均负载,等于每台物理机上服务负载之和的平均值;L链路为链路带宽。
通过计算得知,系统负载在40%~80%之间。
3.2 测试结果分析
(1)不同算法数据恢复平均服务质量评估对比分析
根据测试环境,对系统中磁盘失效时数据副本的恢复平均服务质量进行评估,评估结果详见表1。
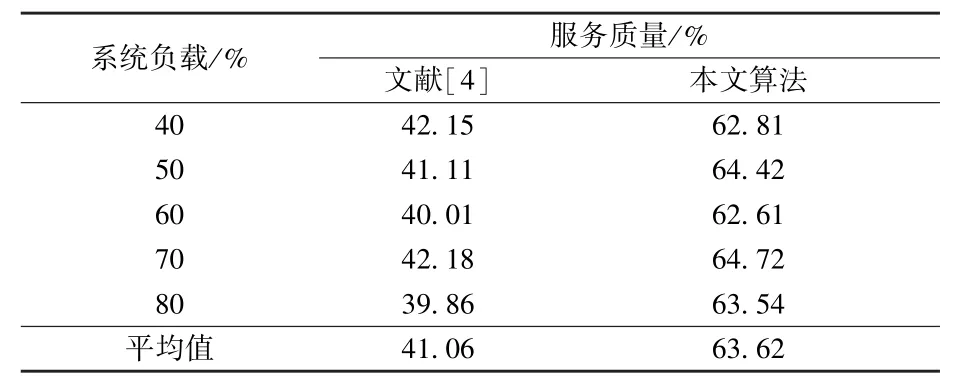
表1 系统中磁盘失效时数据副本的恢复平均服务质量评估结果
通过分析表1 中的数据得知,本文算法平均服务质量相对较高,由此表明本文提出算法在服务治疗保证方面效果显著。 除此之外,系统负载不断增加的情况下,同一算法的服务质量变化量不大,究其原因主要是由于数据拷贝过程中,拷贝仍占用大量的带宽资源,当原有服务负载小于100%时,其资源抢占能力大致相同。
(2)不同算法数据恢复时间评估度对比分析
对于数据副本恢复而言,其主要目的在于提升服务质量,数据恢复时间作为衡量数据恢复效果一个重要指标,系统恢复时间越长,表明系统再次失效的概率大。 针对此种情况,需在上述测试环境的基础上,对不同算法数据的恢复时间进行评估,评估结果详见表2。

表2 不同算法数据恢复时间评估度结果
对系统负载而言,其主要体现当前环境下服务自身的带宽需求,同时也对数据恢复过程中可用带宽资源造成一定影响,导致数据恢复过程中的带宽资源受到影响。 从表2 中可看出,文献[4]数据恢复时间相对较短,造成此种情况的原因在于文献[4]中的算法直接将所有数据恢复,在数据恢复过程中产生的数据拷贝任务相对较多,进而抢占了大部分带宽资源,促使其数据恢复时间缩短。 虽然本文算法的数据恢复时间相比较文献[4]算法长,但是仍处于可接受范围内。 但是,在本文算法数据恢复过程中,首先对不符合安全规则的数据进行恢复,且恢复时间远小于总恢复时间。 在恢复不符合安全规则的数据后,系统便具备了应对磁盘再次失效的能力。
4 结语
针对计算机系统中的数据副本丢失问题,本文提出一种基于稀有度感知的分阶段数据副本恢复算法,并以提升应用服务质量为目标,模拟测试了该算法在应用服务质量保障方面的效率。 测试结果表明,本文算法的数据恢复时间虽然长,但是仍处于可接受范围内。
