基于GPU粗细粒度和混合精度的SAR后向投影算法的并行加速研究
2024-01-31田卫明刘富强王长军邓云开
田卫明 刘富强 谢 鑫 王长军 王 健 邓云开,4
(1.北京理工大学信息与电子学院雷达技术研究所,北京 100081;2.北京中建建筑科学研究院有限公司,北京 100076;3.北京理工大学重庆创新中心,重庆 401135;4.北京理工大学卫星导航电子信息技术教育部重点实验室,北京 100081)
1 引言
SAR(Synthetic Aperture Radar,合成孔径雷达)因其全天时、全气候的特点,在军事和民用领域得到了广泛应用[1]。随着SAR 成像指标的提高和回波数据量的增加,对SAR 数据处理的时效性提出了更高的要求[2]。后向投影成像算法采用逐点计算以获取精确的聚焦图像,能够适应任意运动轨迹下的SAR 成像,但其运算量大、效率低的缺点严重制约了SAR图像获取的时效性[3-4]。
为了提高后向投影成像算法的成像速度,只在算法层面降低后向投影算法的运算量并不能满足SAR 图像获取的高效性。因此,DSP(Digital Signal Processing,数字信号处理器)、FPGA(Field Programmable Gate Array,现场可编程逻辑门阵列)和GPU(Graphics Processing Unit,图像处理单元)等处理器被应用于SAR 成像算法的优化中。由于FPGA 和DSP 在并行系统中都使用了多块芯片,导致硬件成本太高、结构复杂且开发周期长等问题而渐渐被GPU 所取代。GPU 拥有强大的算力和高带宽,使得在运算量大、逻辑分支简单、数据密度高的并行计算中具有巨大优势[5-6]。因此GPU 对后向投影成像算法的加速技术具有很好的工程应用前景。
文献[3]基于像素点并行实现了后向投影成像算法的优化,并避免了内存访问冲突;文献[4]基于GPU 对反投影结构进行优化,实现了不同方位PRT的雷达数据处理的并行,但两种方法的优化速度均受限于像素点数和方位PRT 的数量,在像素点或PRT 数量增加时,算法加速性能将会明显降低。文献[7]基于多GPU 计算节点进一步提高了程序执行的并行性;文献[8]基于GPU 锁页主机内存提升了内存和显存之间的数据拷贝速度,优化了圆迹SAR成像效率,但锁页主机内存的使用一定程度上会降低主机系统的性能,影响成像算法处理效率。
本文以后向投影成像算法作为算法基础,从GPU 异步流并行技术、共享内存、粗细粒度并行和混合精度运算上展开研究,提出了一种基于GPU 后向投影成像算法并行优化方案。该方案充分利用GPU 内部计算资源和内存资源对后向投影成像算法实现了并行优化,使得SAR 成像处理效率得到明显提升。该文第二部分介绍了SAR 后向投影成像算法基本原理,并分析了算法流程中各步骤的计算量。第三部分提出具体的并行优化处理方案,从GPU 异步流并行、高效矩阵转置、GPU 粗细粒度并行优化了SAR 后向投影成像算法;提出一种基于混合精度的数据处理方法来优化相参计算过程,进一步提升了成像处理效率。第四部分基于实测数据验证了所提出的并行优化方案的正确性与高效性。
2 后向投影算法
后向投影成像算法是一种典型的时域成像算法,该算法不存在任何近似运算,可实现精准成像。算法通过对雷达运动过程中获取的场景回波信号先进行距离向脉冲压缩,实现距离维的高分辨聚焦,然后沿方位向进行多普勒相位补偿和相干叠加,实现方位维高分辨聚焦,以获取二维高分辨SAR图像。
2.1 后向投影算法原理
图1 所示为后向投影成像示意图,其中雷达起始位置为(X0,Y0,H),雷达速度为V,成像网格大小为M×N,η1,η,ηn为雷达平台运行的三个不同方位时刻,P(m,n),P1(m1,n1),P2(m2,n2)为成像场景中的任意三个散射点,R(η)为雷达平台在η时刻与空间目标点P之间的单程距离,表示为R(η,n,m)=其中m,n为成像场景中某像素点的位置坐标。
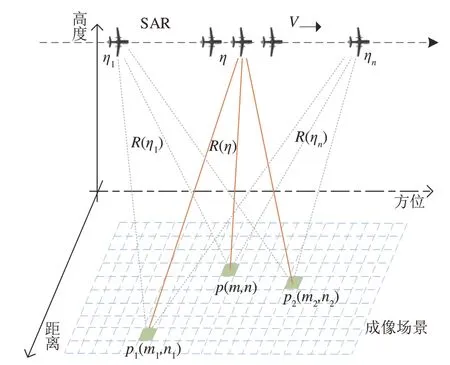
图1 后向投影几何模型Fig.1 Backward projection geometric model
SAR 在η时刻对探测区域中某目标点P(m,n)进行探测,经调制后的回波信号可表示为:
其中τ为距离维时间,η为方位维时间,A为回波信号幅度,fc为SAR发射信号载频。
对SAR 回波信号与时域匹配滤波器h(t)进行卷积,可得脉冲压缩后信号模型如下:
对脉冲压缩后信号进行多普勒相位补偿,并对结果沿着雷达飞行方向的进行相干累加,可得到成像空间中最终图像[9-11]:
2.2 后向投影算法计算量分析
图2 所示为合成孔径雷达后向投影处理流程图,其分为距离维脉冲压缩和方位维相参处理两部分。在距离维度脉冲压缩过程完成距离维度FT、参考函数相乘和距离维IFT,在方位维相参计算过程完成多普勒相位补偿和相干累加运算。
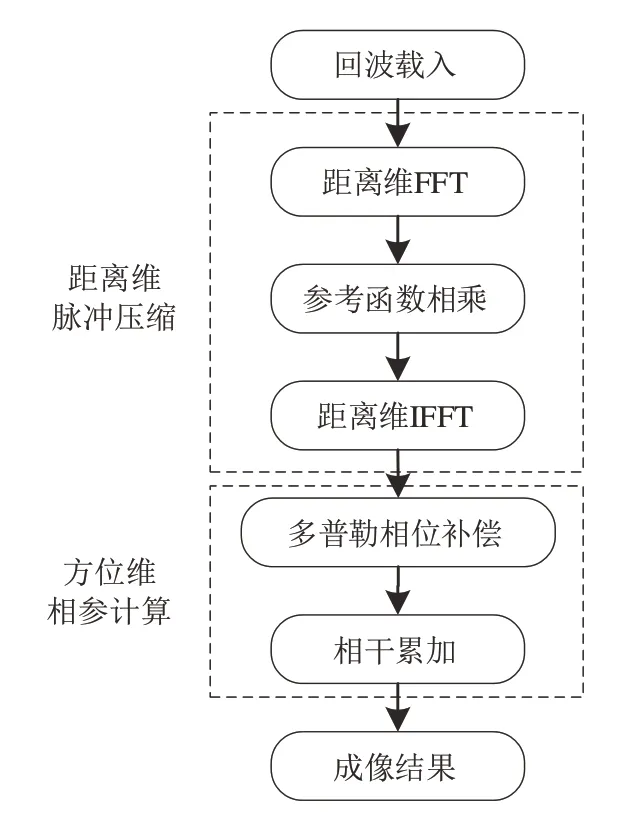
图2 后向投影成像处理流程Fig.2 Backward projection imaging processing flow
假设回波矩阵大小为M×N,其中M为距离维点数,N为方位维点数,设成像场景大小为P×Q,其中P为场景距离维尺寸,Q为场景方位维尺寸,表1为整个成像处理流程中所包含的运算量。

表1 后向投影算法运算量Tab.1 Computation of backward projection algorithm
通过以上分析,SAR 后向投影成像算法的运算量和回波尺寸与成像场景大小直接相关。在雷达回波数据一定条件下,如果在后向投影成像的流程中增加滤波和插值等操作或者增大成像场景,都将进一步增加算法运算量。因此,需要开展SAR 后向投影成像算法的高效处理技术研究。
3 基于GPU 的后向投影算法并行加速处理技术
GPU 是一种可进行高效并行计算的处理器单元,拥有几十至几百个流处理器[12-14]。图3(a)所示为GPU 内部结构,每个流处理器包含有大量的整数计算单元(INT32)、浮点运算单元(FP32)、寄存器(Register)等资源,并在每个时钟周期执行一次整数或者浮点计算指令。因此GPU 的计算峰值能力取决于其内部拥有的计算核心数量和进行协调线程资源的调度单元数量[15]。图3(b)为GPU 内部线程(Thread)、线程块(Block)及网格(Grid)的层次结构图,线程之间彼此独立,因此支持同时的并行计算。GPU 通过调度单元可实现线程对运算核心的调度,完成数据矩阵的并行处理[16]。因此GPU 适合处理包含数据并行的计算密集型任务,在大规模计算问题中能有效提高运算处理速度和性能。
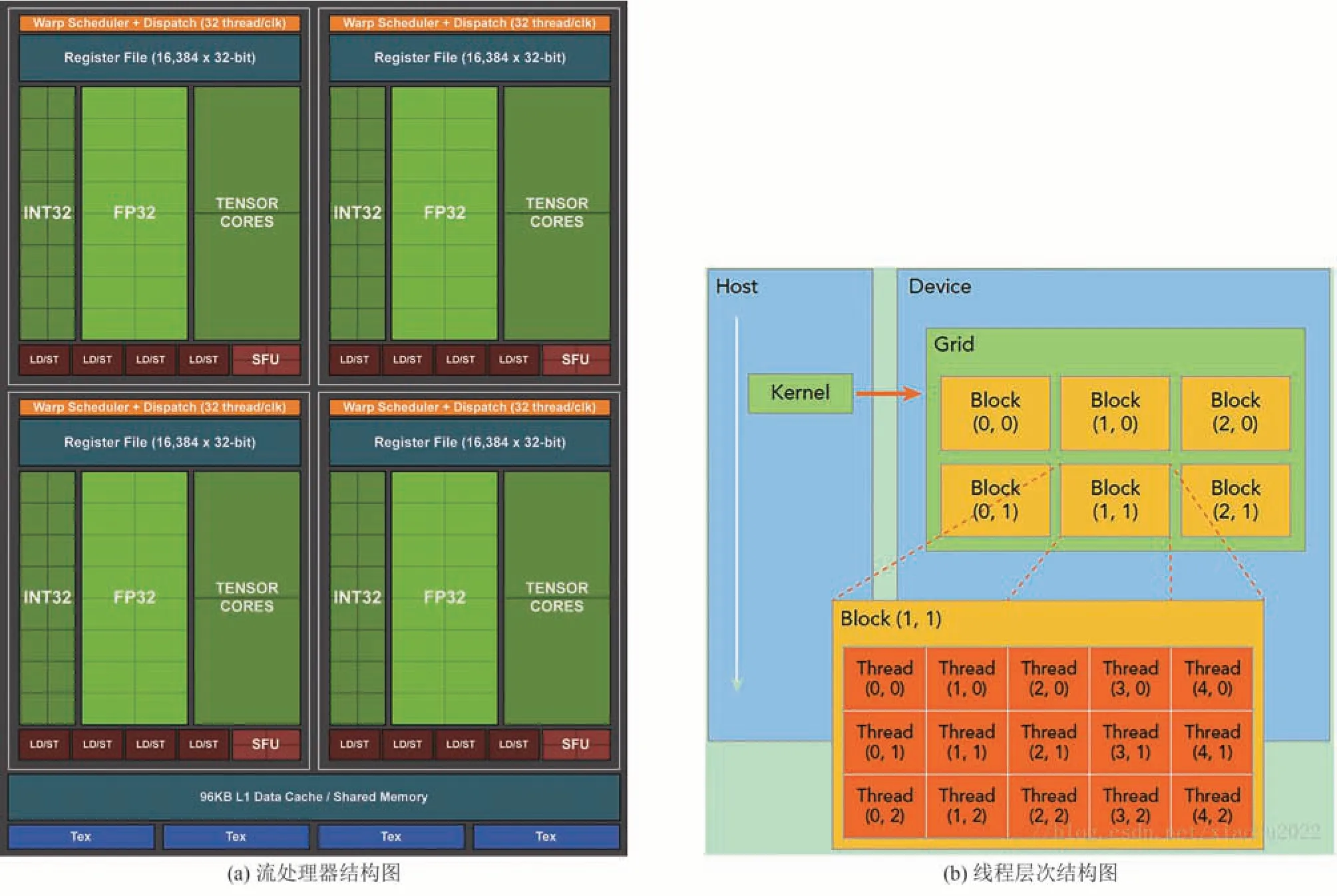
图3 GPU 流处理器结构图和线程层次结构图[13]Fig.3 SM structure diagram of GPU and thread hierarchy diagram[13]
3.1 后向投影算法并行加速处理技术方案
针对后向投影成像算法运算量大的问题,结合GPU 的高性能并行处理能力,该文提出了合成孔径雷达后向投影成像算法GPU 并行加速处理技术方案,通过数据传输和处理并行、矩阵转置加速、线程和线程块的粗细粒度并行、混合精度运算等技术,实现了高效处理,后向投影算法的GPU 并行处理流程如图4所示,其中的关键技术如下:
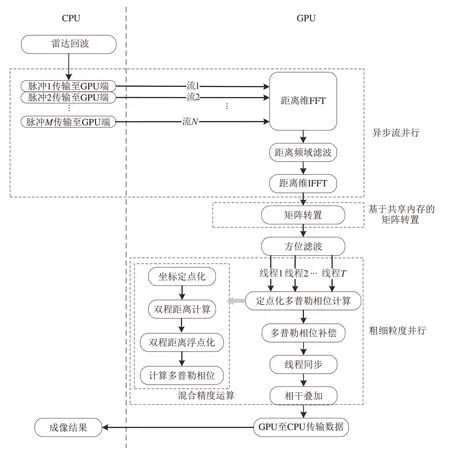
图4 基于GPU的后向投影算法处理流程Fig.4 GPU based backward projection algorithm processing flow
(1)基于异步流并行的数据传输与脉冲压缩
针对原始回波数据量大导致数据传输与数据处理串行,提出一种基于异步流的数据传输和脉冲压缩的异步并行技术,实现了数据传输与数据处理的异步并行,减少了数据传输与数据处理的耗时。
(2)基于共享内存的高效矩阵转置方法
针对已有矩阵转置方法需要借助辅助显存和效率低的问题,提出一种基于共享内存的高效矩阵转置方法,实现对矩阵的高效转置,减少对全局显存的占用,可支持更大的原始回波矩阵。
(3)基于双层粒度的后向投影算法并行处理技术
针对成像算法反投影过程运算量大、运算复杂的问题,提出一种粗细粒度并行的后向投影计算优化技术,通过线程和线程块双层粒度的并行,实现了粗细两层粒度的并行,加速数据处理效率。
(4)基于混合精度数据处理方法
针对成像算法相参计算过程中双精度数据处理效率低的问题,提出了基于混合精度的数据处理方法,在确保误差可接受的范围内进一步提高了算法效率。
3.2 基于异步流并行的数据传输与脉冲压缩
异步流是GPU的一系列异步操作的集合。在同一个流中的异步操作有严格的执行顺序,而在不同流中的操作在执行顺序上不受限制。通过创建多个流,将任务分配到各个流上,处于同一个流内的数据拷贝与计算是串行执行的,但不同流之间的数据拷贝与计算可以同时执行,因此可以有效掩藏数据传输时间。
因雷达回波数据需要跨平台由CPU 端传输至GPU 端进行脉冲压缩处理,且不同PRT 间的处理彼此独立,因此可结合GPU 异步流并行技术实现数据传输和脉冲压缩分流并行处理。图5 为GPU 异步流并行处理示意图,通过将M个PRT 回波数据分成N个异步流并行传输,每个流执行单个PRT 的数据传输和脉冲压缩,多个流实现PRT 间数据传输与脉冲压缩的并行,达到不同PRT 对应距离维数据的传输与处理重叠,实现耗时的压缩。流的数量由设备所能支持的最大并发内核数量和所能调度的资源决定[12-13]。GPU 异步并行技术相比CPU/GPU 串行执行,流之间的并行优化实现了平台间数据传输和脉冲压缩的处理效率的大幅度提升。
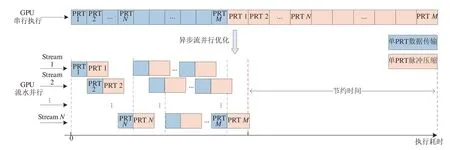
图5 基于GPU异步流脉冲压缩的并行实现Fig.5 Parallel implementation of asynchronous stream pulse compression based on GPU
3.3 基于共享内存的高效矩阵转置方法
后向投影算法脉冲压缩完成后需要对脉冲压缩结果进行矩阵转置以重新排列数据,提高方位滤波的数据访问速度。现有矩阵转置算法主要将原数据矩阵按行读取、按列写入等大的辅存空间完成矩阵的转置[7,17],该过程过度依赖辅存空间,会产生显存不足的问题,并且数据的非连续访存使得数据访存速度慢,导致矩阵转置效率低。
GPU 作为一个集成的高性能组织架构,其有两种类型的内存,一种是板载内存,位于GPU 芯片外面;一种是片上内存,位于GPU 芯片内部。板载内存属于片外内存,具有高延迟和低带宽的特点,如全局内存。片上内存具有低延迟和高带宽的特点,可以提供比全局内存等片外内存高得多的带宽,具有较高的访问速度,如共享内存。此外,共享内存允许线程块内所有线程的访问,使得共享内存所存储数据可以被重复使用,可以大大降低核函数访存所需的带宽,但需要注意线程之间的访问冲突,避免读写竞争带来的计算错误。
该文提出了基于共享内存的高效矩阵转置方法,实现了大数据矩阵的高效转置,其处理原理如下:如图6,为了更好的适应方阵回波数据和非方阵回波数据,提高矩阵转置方法的通用性,该文通过在GPU 端对数据矩阵sig 进行补零形成方阵,并划分成若干小方块矩阵SM(Shared Memory,共享内存),通过块内转置与对应块间交换实现对补零方阵的转置,表2 为矩阵转置的算法实现,其中block-Idx.x、blockIdx.y、threadIdx.x、threadIdx.y为GPU 内部线程块和线程的索引。如图6(a),在GPU 端按行合并读取子方阵SM 的行数据并写入共享内存中,从共享内存中再按列读取共享内存列数据,并合并写入原子方阵中可实现子方阵的转置。如图6(b),按合并访问方式将子方阵写入原显存空间转置后所对应的子方阵中,完成子方阵间数据交换,综上两步可完成数据矩阵的转置。

表2 基于GPU共享内存的矩阵转置算法实现Tab.2 Realization of matrix transpose algorithm based on GPU shared memory
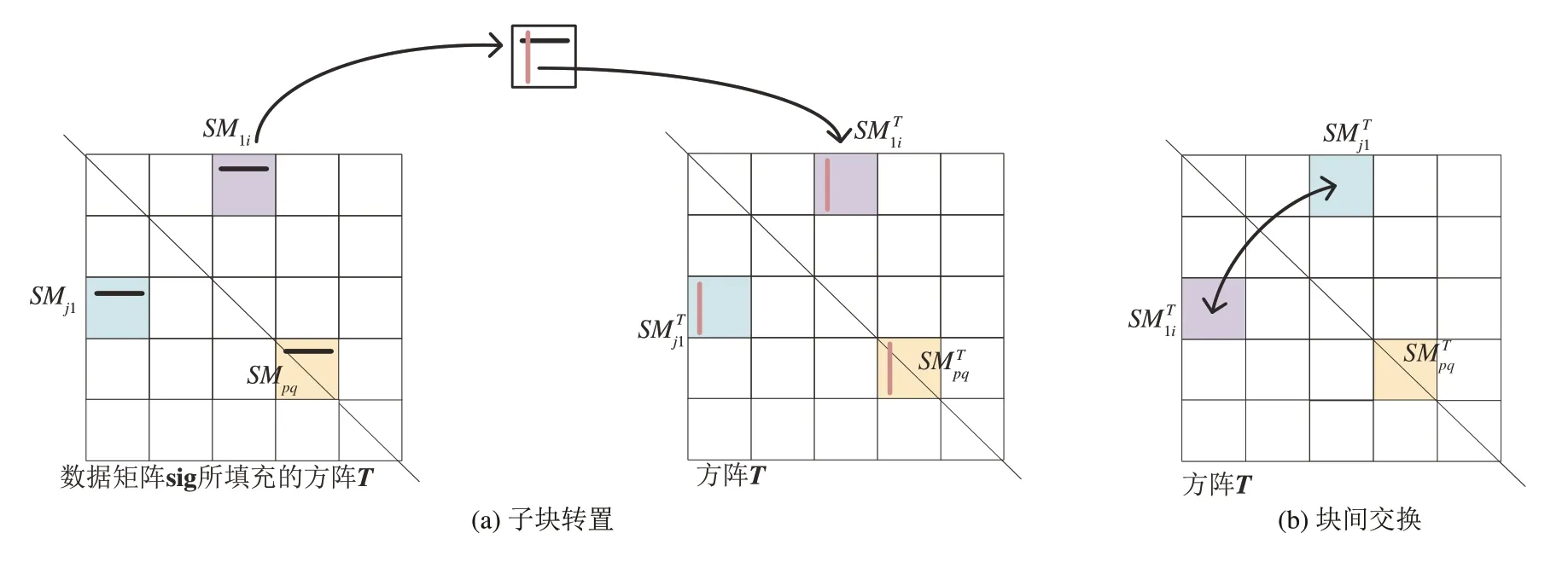
图6 基于共享内存的矩阵转置Fig.6 Shared memory based matrix transpose
3.4 基于粗细粒度并行的后向投影优化
在GPU 中,线程块和其所包含线程可同步执行,通过合理分配GPU资源可充分体现GPU的高并行性[18]。文献[3]是遍历PRT,核函数的运行次数受限于PRT 数量,当PRT 数量增加时,核函数执行次数也会增加,降低算法处理效率。文献[7]是遍历成像空间像素点,核函数的运行次数受限于成像网格中像素点的数量,当成像空间像素点划分巨大时,核函数执行次数也会增加,降低算法处理效率。该文提出一种基于粗细粒度并行的后向投影优化方法,通过结合线程和线程块两层粒度实现并行优化处理,避免了成像场景尺寸和PRT 数量对核函数调用次数的影响,极大提高了算法效率,并基于共享内存实现线程块内数据的累加,进一步提高了内存的访存效率。
图7 为基于GPU 粗细粒度并行的后向投影优化原理图,在细粒度层面将PRT 时刻映射为线程,为图中Thread,粗粒度层面将成像空间像素点映射成线程块,为图中Block。细粒度层面表现为线程块内线程代表PRT,GPU 通过线程并行,使得线程块内所有线程并行运算,每个线程完成每个PRT 时刻双程距离计算、多普勒相位计算和多普勒相位补偿,完成对应PRT 时刻的像素点的处理。粗粒度层面表现为线程块代表成像空间的像素点,GPU 通过线程块并行,可并行完成对整个成像空间中所有像素点的处理。在线程与线程块并行下,式(4)、(5)、(6)可实现双程距离计算、多普勒相位计算和多普勒相位补偿:
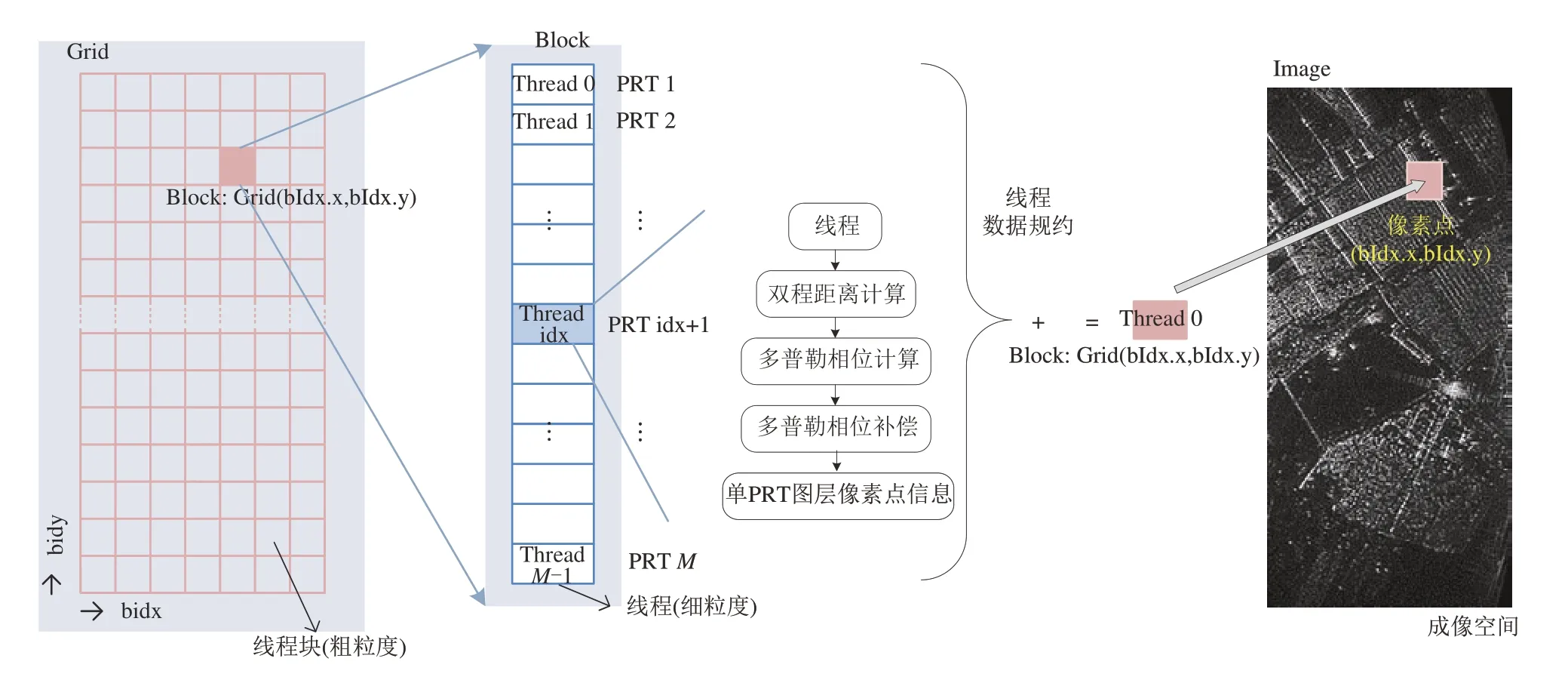
图7 基于GPU粗细粒度并行的后向投影优化Fig.7 Backward projection optimization based on GPU coarse and fine granularity parallel
其中,bIdx.x,bIdx.y 为线程块索引,表示线程块Grid(bIdx.x,bIdx.y),可以在像素空间内唯一标识一个像素点Grid(bIdx.x,bIdx.y)。tIdx 为线程块内的线程索引,Position(tIdx)为方位时刻tIdx 雷达的空间坐标,ΔR为在方位时刻为tIdx 时,雷达坐标距成像空间像素点的单程距离模值,φ为ΔR对应的多普勒相位,Sig 为距离维脉冲压缩结果,SM 为共享内存矩阵,存储单个像素点在每个PRT 处经过多普勒相位补偿后的结果。
在SM 中完成同一像素点在不同PRT 时刻数据的累加,可得到最终成像结果Image:
3.5 基于混合精度数据处理方法
后向投影逐点运算使得成像过程中双程距离计算的运算量大,3.4 节是基于双精度浮点数对成像过程中相参计算进行的优化,保证了成像结果精度,但计算过程中双精度浮点数(FP64)的指令调度开销却限制了数据的处理效率[19-21]。针对双精度数据处理效率低的问题,该文提出一种基于混合精度的数据处理方法,在保证数据准确性的条件下,实现GPU并行处理效率的进一步提升。
定点化通过量化的思想实现浮点数据与整型数据的转换,可以通过设计处理字长和数据格式降低数据传输带宽,充分利用GPU 内部资源,在保证成像精度的条件下的提高成像处理速度。图8显示了Lbit 定点数的数据格式,包含1 bit 符号位,Fbit 小数位,L-1-Fbit 整数位,可表示数据范围为[-2L-1-F,2L-1-F-1],数据精度为2-F,可见对于Lbit的定点数,数据范围与数据精度相互制约,因此可通过调节F的大小,调节数据精度。
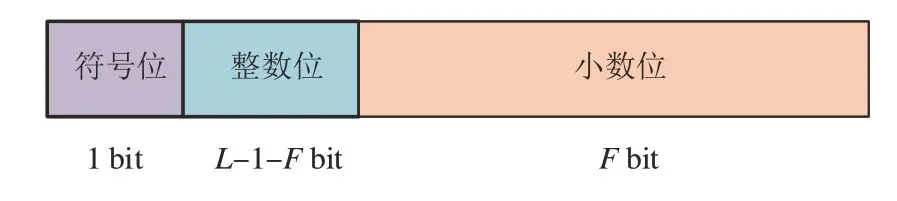
图8 L-bit定点数数据格式Fig.8 The fixed-point data format of L-bit
浮点数的定点化实现如式(8),其中F为小数位宽,2F为量化因子:
由于定点化后的数据类型的受bit数限制,因此xquantized存在最大表达范围,则小数位数F应满足式(9):
如INT32 定点数表达范围为[-231,231-1],则小数位宽F应满足式(10):
根据式(8),若将一个浮点数转成定点数,需要找到浮点数绝对值最大的值,然后确定F值满足式(10)。
通过定点数原理,浮点数的乘法与加法分别可以通过式(11),式(12)来表示:
可见通过对浮点数进行定点化处理,实现一个整型数据即可表达一个浮点型数据,减少了数据的传输带宽和浮点运算的时间周期,提高了计算效率。
目前主流GPU支持INT8,INT16,INT32,FP32和FP64的计算核心,针对后向投影成像算法中双精度浮点(FP64)计算精度高效率低,单精度浮点(FP32)计算效率高精度低的问题,该文提出了32 bit定点与双精度浮点联合处理的计算方案,通过对数据进行归一化处理将数据缩放,可使得小数位宽最大为31位,数据精度为2-31。在保证计算精度的同时大幅提高了计算效率。根据典型的后向投影算法成像模型,后向投影算法混合精度数据处理的设计方法如下:
(1)对雷达坐标和成像区域坐标进行归一化处理,并通过引入量化因子2F,实现浮点数据定点化,如式(13)、(14);
(2)将定点化后的数据采用定点计算方式计算定点斜距,并利用GPU并行处理实现加速,如式(15);
(3)将定点斜距通过量化因子和归一化因子转化回浮点数,进行后续反投处理,如式(16);
其中,2F为量化因子,xg,yg,zg为成像网格空间坐标,xg-int,yg-int,zg-int为其量化结果;xr,yr,zr为SAR 航迹坐 标,xr-int,yr-int,zr-int为其量化结果。该文采用INT32来存储定点化数据,即L=32,其符号位宽1位,数据位宽1 位,可容纳数据范围[-2,2),小数位宽F=30,可实现的数据精度为2-30。
该文通过32 bit定点数数据处理方法优化运算,实现4 byte 传输8 byte 数据,减少了数据传输带宽,并且浮点数据的定点化充分利用了GPU 中的整型资源,提高GPU资源利用率,提高了数据处理效率。
4 基于GPU成像实测数据处理及对比分析
4.1 实验处理平台及性能参数
表3 为回波数据成像时所采用的CPU 及GPU型号和配置。

表3 CPU/GPU平台型号参数Tab.3 CPU/GPU platform model parameters
该文以机载P 波段SAR 的实测数据为例,验证后向投影成像算法的并行加速效果。该SAR 的方位向采样数目Na为2678,距离向采样数目Nr为1024,成像空间网格大小M×N=601 ×1401,通过对两个平台处理结果对比分析,来判断基于GPU 平台双精度数据处理的正确性及高效性。
4.2 实测数据处理结果及耗时
为了证明该文所提出的基于GPU 平台并行实现后向投影成像算法成像的准确性与高效性,在保证后向投影计算之前的处理方法相同的条件下,将所提出的方法与文献[3]和文献[7]中所提出方案1和方案2进行对比,结果如图9所示。

图9 CPU和GPU成像结果Fig.9 Imaging results of CPU and GPU
图9(a)为北京市平谷区金海湖机场(E117.23°,N40.19°)附近农田的场景照片。图9(b)、(c)、(d)所示分别为基于CPU 和GPU 平台获得的成像结果。表4 为CPU 与GPU 平台耗时及不同方案加速比,相较于CPU 成像方案,本方案的双精度成像加速比达到了12.82,混合精度加速比达到了93.84 倍;相较于方案1和方案2,本方案大幅度缩短了成像耗时。
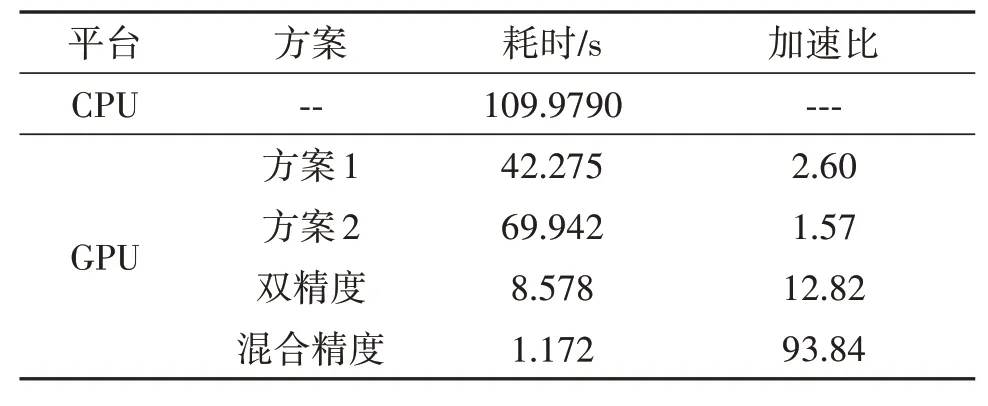
表4 CPU与GPU平台耗时及加速比Tab.4 CPU and GPU platform time and speed ratio
以GPU 平台下双精度的成像结果为真值,表5所示为GPU 在不同处理精度下幅度和相位误差的标准差和均值,其中GPU 双精度结果的幅度和相位下相对误差的均值分别为10-13和10-12量级,可以视为与CPU 端双精度处理的图像完全一致。GPU 单精度结果的幅度和相位下相对误差的均值分别为10-3和10-3量级,GPU混合精度结果的幅度和相位下相对误差的均值分别为10-7和10-6量级,可见混合精度相对于单精度提高了精度。图10 为不同精度下幅度和相位的相对误差点数量分布图,可看出混合精度相对于单精度在一定程度上实现了成像结果精度的提升,且进一步缩小了误差的范围。因此混合精度对后向投影并行处理的进一步优化,可以更好的控制数据处理过程中产生的误差,并且验证了基于GPU 的成像算法的并行加速方案是正确可行的。
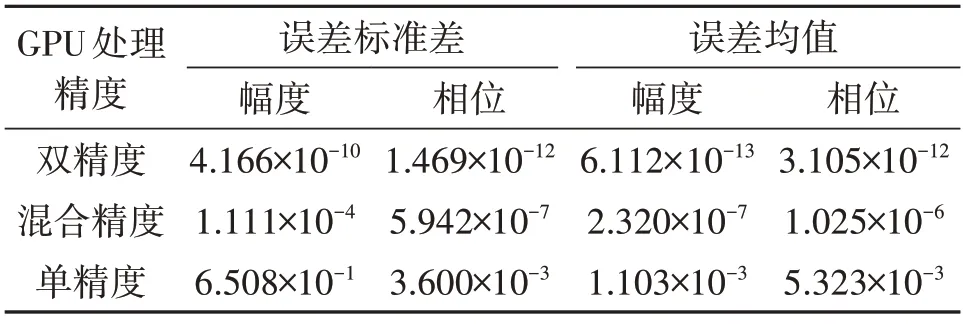
表5 不同处理精度下的幅度和相位误差的标准差及均值Tab.5 Standard deviation and mean value of amplitude and phase errors under different processing precision
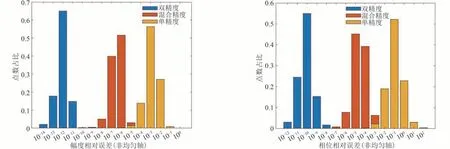
图10 GPU在不同精度下幅度和相位的相对误差分布图Fig.10 The relative error distribution of GPU amplitude and phase under different precision
5 结论
该文基于GPU 平台,针对SAR 后向投影算法处理时效性不足的问题,提出了一种SAR 后向投影成像算法GPU 并行加速处理方法。通过异步流并行技术、矩阵转置、粗细粒度并行技术对成像算法流程进行了初步优化。针对数据处理精度和数据处理效率之间存在的制约关系,通过分析浮点数和定点数数据格式及精度差异,提出了基于混合精度的数据处理方法,充分利用GPU 资源,在保证误差可接受范围内,进一步提高了算法处理效率。在GPU 平台上对SAR 实测数据进行了成像验证和结果误差对比分析,验证了对算法优化的高效性和正确性。
