基于张量分解的地铁车轮健康指数构建
2024-01-30胡志强楚柏青赵媛媛寇淋淋
胡志强,楚柏青,赵媛媛,寇淋淋
(北京市地铁运营有限公司,北京 100044)
1 背景
轮对作为地铁车辆走行部重要部件之一,直接决定车辆运行状况的安全性与平稳性[1]。在列车运行过程中,由于地铁轮对和钢轨、车闸间存在直接接触关系,因此会产生滚动摩擦和滑动摩擦,导致列车轮对出现磨损。随着运行里程的增加,车轮的健康状态会逐渐退化,产生的重大事故隐患风险越来越高。此外,车轮踏面等位置容易出现应力集中等现象,同时雨水、油污甚至腐蚀剂的侵蚀将加剧轮对非正常磨耗。为保证列车行驶安全,需要准确识别车轮退化状态,以便及时进行维护和保养。
在实际应用中,地铁车辆运维主要采用基于时间的检修机制(计划修),即对轮对各类尺寸,如轮对内侧距、轮径尺寸、轮缘高度、轮缘厚度、轮缘综合值和轮径差等指标进行测量,一旦测量值超限便对其进行镟修。但这种方式存在一定的局限,如由于实际工况的不确定性、失效形式的多样性,容易产生测量误差(例如失圆情况下会导致轮径测量值反而增大),导致临时性维修频繁[2]。实际检修流程中,主要由人工根据测量值标注磨损程度,实行一级报警和二级报警,一般采用周期性检测方式,无法做到对车轮状态的实时监测。
2 地铁轮对健康管理存在的问题
近年来,加速度传感器成为地铁列车车轮状态实时监测的有效手段之一,应用广泛。通过测量振动信号间接评估地铁车轮的工作状态实现对车轮的磨损程度的实时监测,对辅助实现从基于人工的计划修向基于状态的维修策略升级提供坚实的技术支撑[3]。目前,各类信号分析方法,如小波变换[4]、经验模态分解[5]等已经用于检测车轮损伤,此类算法多依赖人工经验,且对数据质量要求较高。随着人工智能的发展,各类机器学习算法,如支持向量机[6]、长短时记忆模型[7]等,在车轮退化状态智能化评估方面应用广泛。此类方法不需要提前构建精确的性能退化机理模型,不依赖于人工经验,只需要对传感器监测数据进行分析,提取状态特征,并进行分类或异常检测,推断出车轮的健康状态。基于数据驱动的车轮退化状态评估目前已成为学术研究和实际工程应用的热点。
然而,在轨道交通领域,机器学习主要针对高速列车转向架[8]等系统部件,利用多重卷积递归神经网络和马尔可夫建模思想等方法进行健康状态评估,侧重于对走行部、转向架等结构的总体评估,仅针对车轮退化状态的评估方法较少。对于机械设备的状态评估问题主要集中在轴承、齿轮箱等支承元件。文献[9]提出一种基于深度置信神经网络和改进的支持向量描述的状态退化评估方法。Zhang 等提出一种将长短期记忆模型用于数据驱动型轴承性能退化评估的方法[10]。XU 等将基于指数权重移动平均的加强堆叠自动编码机用于健康指数构建[11]。文献[12]则应用卷积神经网络提取深度特征构建健康指数,并解决退化趋势中的毛刺现象。但现有方法无法规避不规则噪声的干扰,难以获取原始特征中的趋势性,严重阻碍健康指数的构建[12]。
受负载和速度的变化、轨道状态、车辆悬架系统等因素影响,原始轮对振动信号不规则噪声显著,对轮对退化过程的有效表征造成严重阻碍。因此,从含不规则噪声的实际监测数据中自动识别退化状态的变化区间,以代替现有企业检测流程中的一级/二级报警是本文的主要研究目的。具体要解决以下问题:①由于车辆轴箱振动信号不仅包含车轮磨损信息,如图1 所示,还包括轨道状态信息以及地铁车辆正常运行中所处环境温度、载荷、路况等因素,极易对轮对振动信号产生不规则噪声干扰,如图2 所示,难以准确描述车轮退化过程;② 采集到的轮对振动信号的状态信息既无人工标注,也无法提前假设其为正常或异常,即为无监督学习问题,较难建立准确的机器学习模型,同时,车轮磨损到一定程度出现失圆现象,振动信号波动加剧,随后会再次磨圆,振动信号变化放缓,即出现“虚假状态恢复”现象,但整体车轮已经处于不稳定状态,磨损会在一定时间后再次加剧,如图3 中退化过程的振动有效值曲线所示,实际上,目前企业常采用一级/二级报警的检修机制目的就是实现对状态变化的预警,当有不规则噪声的时候,图3 所示退化过程的状态变化将被严重干扰;③状态评估应自适应完成,减少人工干预,提高部署性。需要强调的是,虽然现在已有部分针对车轮踏面故障识别的研究[13-15],但这些工作大多需要一定的先验知识对监测数据进行分析,不能自适应地评估车轮的健康状态,一定程度降低了检测方法的实用性。

图1 地铁车轮结构示意图
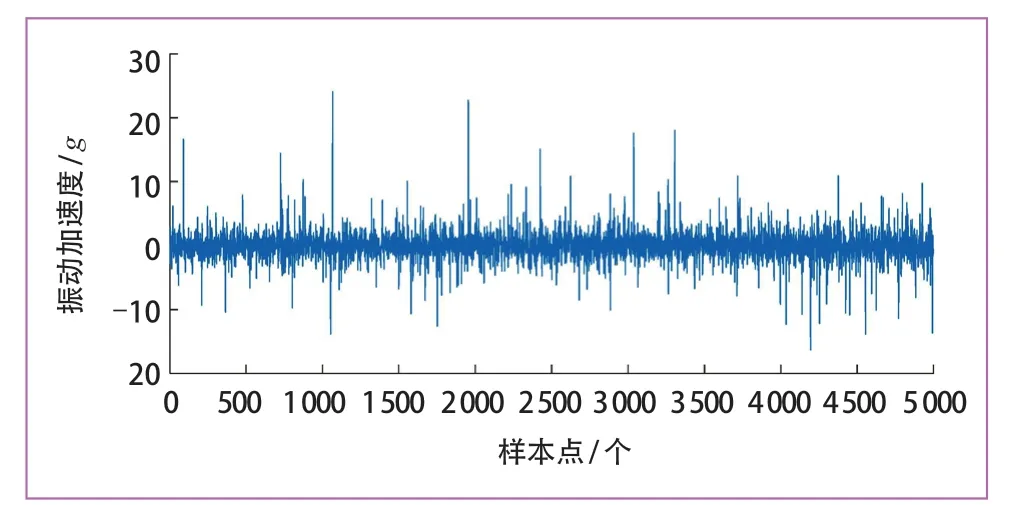
图2 地铁车轮振动加速度信号
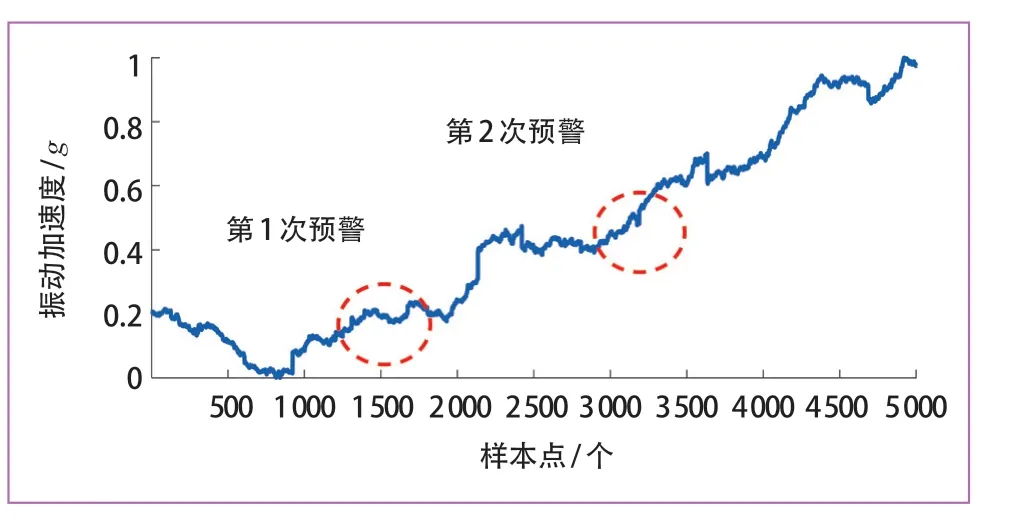
图3 地铁车轮振动有效值
为解决上述问题,本文提出了一种基于张量重构的地铁轮对无监督健康指数构建方法,对退化过程振动信号的自适应特征提取,可有效降低不规则噪声干扰,以准确描述车轮退化过程。首先,利用张量Tucker 分解从原始信号中获取核心张量,挖掘信号与时序之间更深层次的联系,在通过张量重构得到降噪后的退化序列后,利用Savitzky-Golay 滤波器进一步去除去噪信号的趋势项,从而得到有效的振动信号序列。最后,通过无监督深度自编码器网络提取时序深度特征,再使用主成分分析法通过降维构建车轮的健康指标,自适应地划分出车轮退化状态等级。该方法利用北京地铁列车的实际车轮退化数据进行了有效性验证。
3 健康指数构建
3.1 基于张量 Tucker 分解降噪
由于地铁车辆轮对的原始振动信号中普遍存在不规则噪声,因此在进行信号数据分析之前需要对此类信号进行预处理。本文采用张量Tucker 分解对轮对的原始信号进行去噪处理,然后通过重构获得具有良好表示能力的振动信号,以提取有效的深层特征。
张量通常被认为是一个高维数组,其阶数代表空间的维度。零阶张量是标量,一阶张量是向量,二阶张量是矩阵,三阶及以上张量称为高阶张量。张量Tucker 分解是高阶主成分分析的一种形式。它将张量分解为核心张量和每个维度上因子矩阵的乘积。核心张量的空间比原始张量小很多,但可以保存原始张量的本质信息。每个维度中的因子矩阵也称为每个维度中张量的基矩阵或主成分。核心张量G和n因子矩阵U通过n阶张量的Tucker 分解得到。公式如下:
图4 为三阶张量上的Tucker 分解示例,分解结果由1 个核心张量和3 个因子矩阵U1,U2和U3组成。
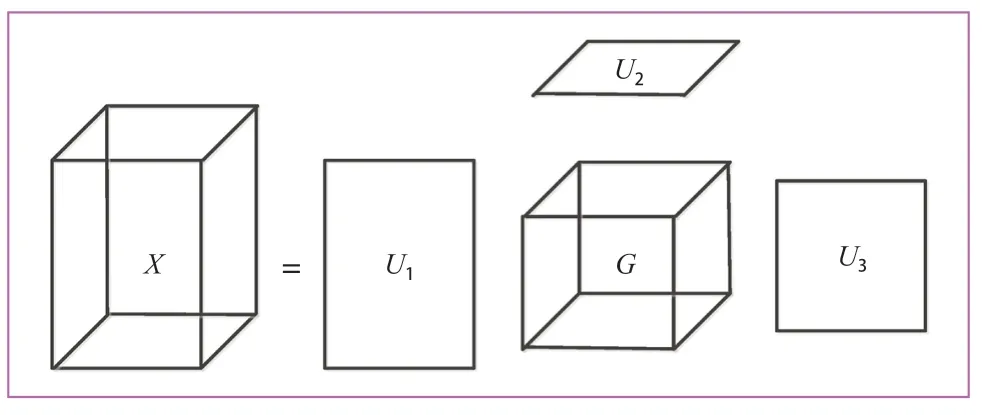
图4 三维张量Tucker 分解
利用多路延迟嵌入变换将原始监测数据沿时间维度进行转换,得到数据量更大、特性更好的三阶张量。假设原始监测数据为其中m为样本长度,n为每个样本的采样点数。通过多路延迟嵌入变换,可以得到一个三阶张量其中τ是时间窗口,m -τ+1 是重构后的样本长度。然后,使用张量Tucker 分解技术将其分解为1 个核心张量(核心属性)和1 组因子矩阵,以捕捉特征序列之间的内在相关性。在分解核心张量和因子矩阵的过程中,应尽量减少损失,使重建数据与原始数据大致相等。这种损失可以通过式(3)来描述。
式(3)~式(4)中,losstucker为重构损失;G为核心张量;G(t)为重构后的信号。
3.2 消除趋势项
由于深度自编码网络采用无监督学习模式,因此输入数据的质量对于特征提取的性能很重要。为减少趋势项的影响,最好在特征提取前消除趋势,使原始信号成为规律性强的数据。Savitzky-Golay 滤波器可以有效的找出信号的趋势项,并将其从输入信号中减去,达到去除趋势项的目的。多项式拟合函数作为滤波器内核,如式(5)所示。
通过式(6)最小化多项式函数的系数,可得
式(5)~式(6)中,F(t)是Savitzky-Golay 滤波器的核函数;S是滤波器的跨度;r和β分别是多项式函数的阶数和系数。本模型中,S=1 001。
滤波后的信号序列可以通过式(7)中的减法运算得到:
3.3 基于深度自编码算法的健康指数构建
去除趋势项后的信号序列被输入深度去噪自编码器以获得深度特征。自编码器作为一种无监督算法,可解决健康指数构建过程中数据无标注问题。它由编码层、隐藏层和解码层组成,其模型结构如图5 所示。自编码器可以通过隐藏层将未标注的数据映射到自身,并在这个过程中找到合适的隐藏层(特征表示)。

图5 深度自编码模型
编码器是从输入层到隐藏层,用编码函数公式(8)表示,实现高维信息的压缩和降维,是特征提取过程。
式(8)中,h是隐藏层向量;σ是激活函数;W1是权重矩阵;b1是对应的偏差。
解码器是从隐藏层到输出层,用解码函数公式(9)表示,实现数据重构。
通过最小化编码和解码过程中的损失lossAE,实现解码后的数据与原始数据近似相等。压缩损失使用均方误差损失,计算如下:

图6 方法流程图
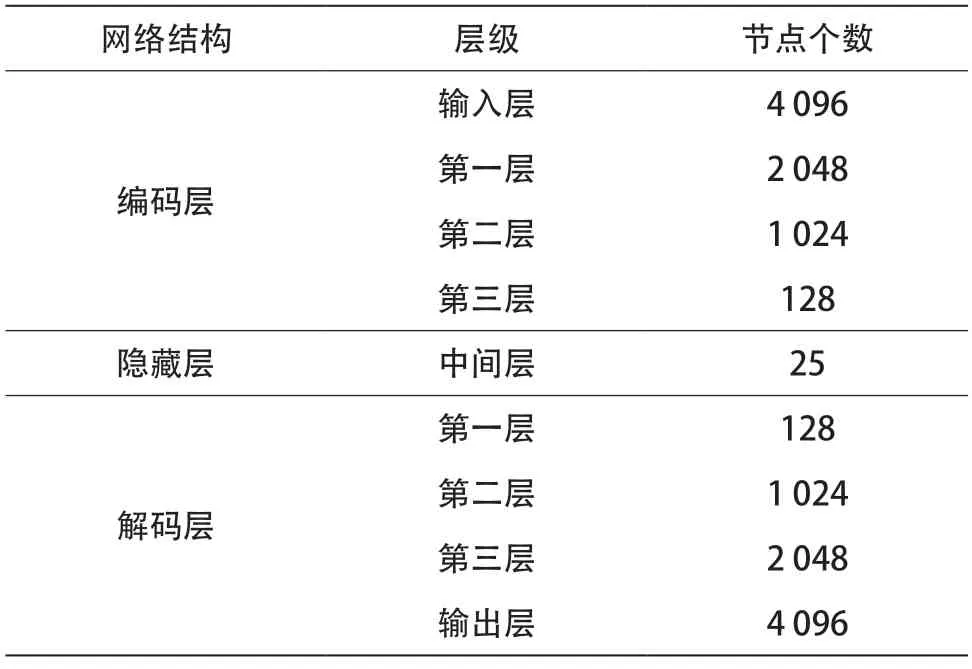
表1 深度自编码网络模型参数 个
4 实验验证
4.1 数据描述
本文采用某地铁线路的轮对振动信号进行实验验证,数据集为2020 年全年数据,包含22 001 个样本,每个样本有4 096 个采样点,采样频率为2 000 Hz。
4.2 健康指数构建结果
图7 为张量 Tucker 分解和Savitzky-Golay 滤波器的信号处理结果。其中,图7a 中的原始振动信号不规则,噪声非常明显,图7b 中的信号具有明显的周期性。由此可见,该方法在消除不规则噪声方面效果显著。

图7 所提方法处理轮对数据的结果
将去噪信号输入深度自编码网络提取25 维深度特征,并采用主成分分析法降维后得到车轮初步健康指数曲线,如图8 所示的蓝色线部分。再经移动平均法平滑处理后,得到最终健康指数曲线,如图8 所示的黑色线部分。从该健康指数曲线可以看出,随着轮对运用时间延长,健康指数整体呈增加趋势,代表轮对状态随时间退化显著。由图8 可观察到在[6 000,8 000]数据区间中的退化趋势急剧增加然后减少,最后趋于相对平坦,其原因为随着轮对的磨损,轮缘厚度会逐渐减小,振幅逐步趋于稳定。这表示地铁轮对的健康指数在整体区间内并非单调递增。但直观上,文章构建的健康指数可以判断异常轮对的状态区间,为后续的状态评估和故障检测提供依据。
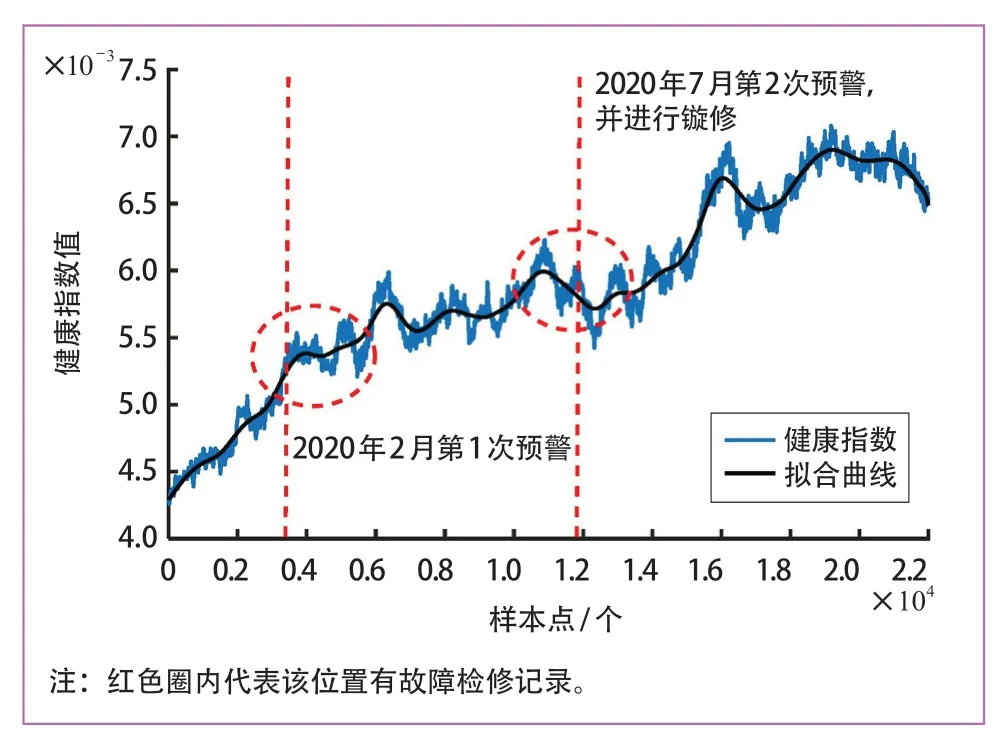
图8 车轮健康指数构建方法结果
4.3 结果对比
为证明所提出方法的有效性,采用2 种具有代表性的去噪方法与之进行比较。
方法1 为小波包去噪法。将采集到的振动信号通过小波包分解[16]正交分解成几个子频带,并将分解系数重构到高维相空间中,从而得到去噪信号。
方法2 为移动平均法去噪。使用移动平均法[17]计算包含一定数量项目的序列平均值,同时对原始序列进行修剪和平滑处理。
为确保对比公平性,仅将张量重构部分替换为上述2 种方法,其余部分保持不变。各步骤的实验结果分别如图9、图10 和图11 所示。很明显,图11 中提出的方法可以显著降低噪声并有效反映退化趋势。小波包去噪法和移动平均法去噪都无法得到具有良好趋势性的健康指数曲线。

图9 小波包去噪法的结果
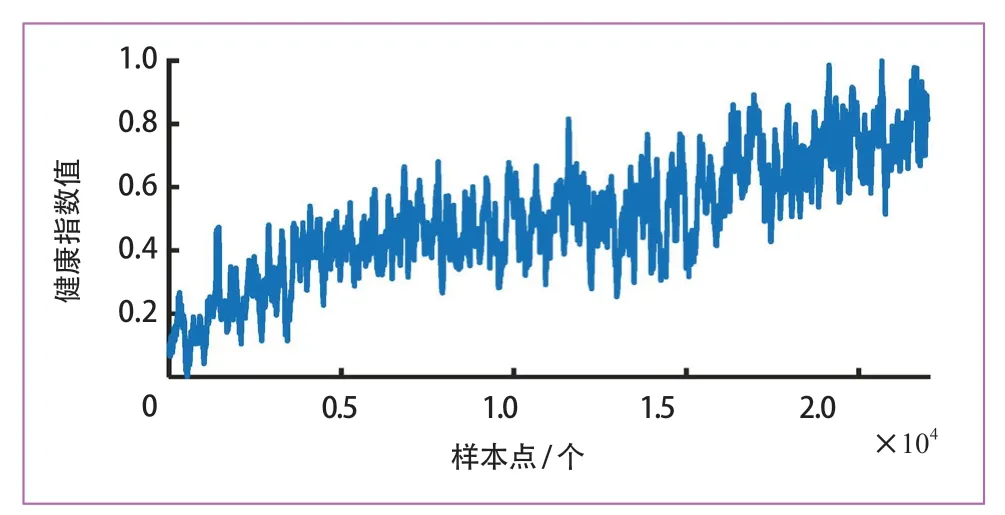
图10 移动平均法去噪结果
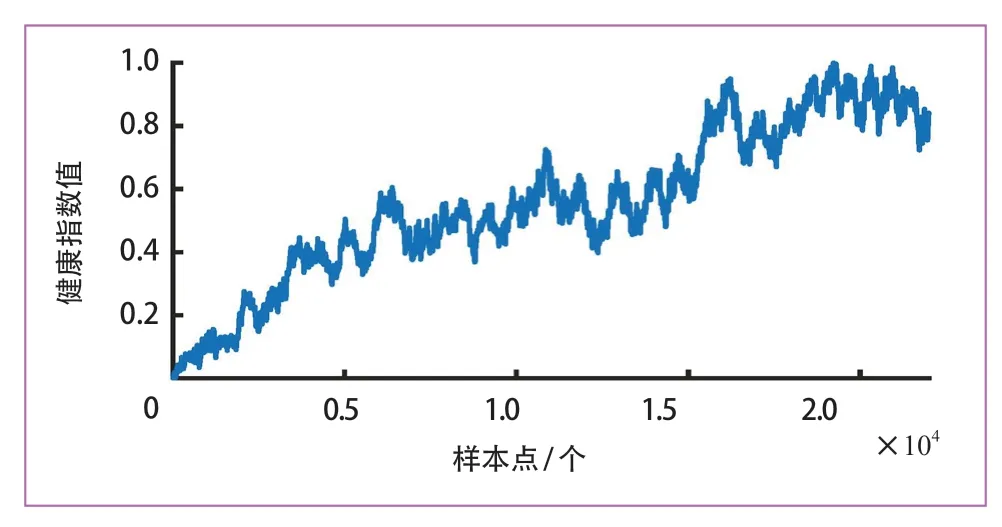
图11 本文所提方法结果
为验证深度自编码网络的可行性,选择3 个常用的统计特征进行比较,包括时域的峭度特征、频域的有效值特征和时频域的经验模态分解。使用这3 个统计特征的健康指数曲线如图12 所示。
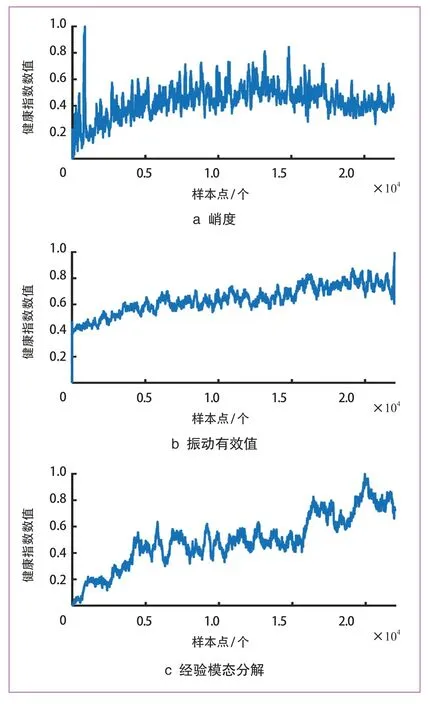
图12 使用3 个统计特征的健康指数曲线
很明显,图12a 中的峰度趋势缺乏必要的单调性,而对早期断层不敏感。因此不能有效地显示退化趋势。如图12b 所示,虽然有效值的趋势具有本质上的单调性,但该趋势并没有明显地揭示出退化趋势。经验模态分解曲线趋势具有明显的单调性和趋势性,但由于波动较大,难以准确量化轮对的退化情况,以用于下一步的早期故障检测。相反,图11 中提出的方法得到的健康指数具有整体趋势和单调性,还可以反映轮对的状态变化,对早期故障具有良好的敏感性。
4.4 早期故障检测
为进一步验证健康指数的实用性,按滑动窗口大小为500,移动步长为100 逐序列对健康指标进行拟合与求导,以二阶导数值为指标,确定异常区间,并对轮对磨损异常状态进行评估。使用2021 年某地铁线路全年的检测数据,共18 000 个样本点,进行分析,如图13 所示。
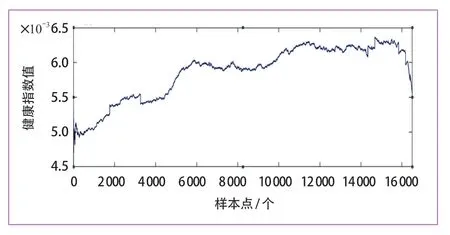
图13 提取的健康指数
同时,按滑动大小为500,移动步长为100 逐序列对健康指标进行拟合与求导,以二阶导数值为指标,确定异常区间,并对轮对磨损异常状态进行评估。图14分别为拟合的健康指数曲线的一阶导,二阶导和相对应的健康指数曲线走势。
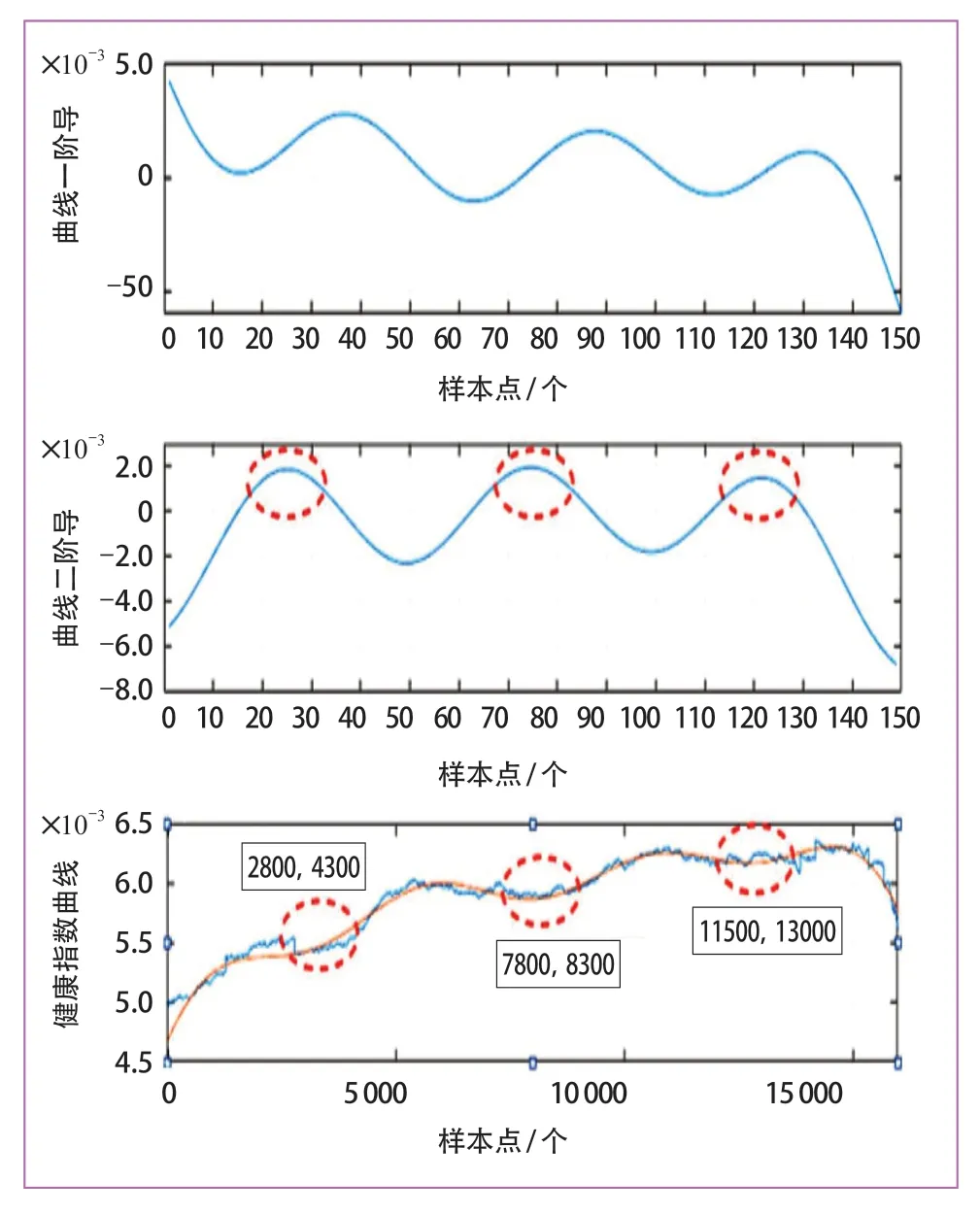
图14 健康指数曲线的一阶导、二阶导和相对应的健康曲线走势
结合轮径测量值和其镟修记录,图15 中标黄的测量值为磨损异常标记,带有“椭”字说明轮对已磨损为椭圆形。从显示记录可见,轮对在2021 年3 月25 日—5 月31 日之间轮径值变小说明发生明显磨损,在6 月、7 月、8 月加剧磨损进而进行标记,在8 月12 日的轮径测量中进行标黄处理,持续磨损直至10 月14 日轮对标记为椭,最后在10 月26 日进行镟修。

图15 检测维修记录
根据健康指标不同的变化阶段,拟将二阶导出现极大值的次数作为异常评估的等级指标,第一次出现极大值的区间为一级异常,第二次出现极大值的区间为二级异常,第三次出现极大值的区间为三级异常,即需要及时进行镟修,与检修记录相契合。
5 结论
本文针对地铁车辆车轮自适应的健康状态评估问题,提出一种无监督张量分解深度自编码的健康指标构建模型。利用张量分解算法可有效抑制数据中的不规则噪声干扰,在一定程度上提高了自编码特征的多样性,避免数据量不充足情况下的过学习问题。从无标记退化状态数据中提取具有良好趋势性的深度特征,可极大地简化后端的异常检测或状态评估算法,通过简单的二阶导即可有效识别状态变化区间,完成对实际检修流程中一级/二级报警的准确匹配,且能较好地对应实际的镟修记录。文章所提方法不仅有效解决不规则噪声干扰下的问题,同时模型简单、可靠,人工干预少,具有较好的自适应性,获得的健康指数序列有助于掌握车轮退化特性,为车轮磨损的剩余寿命预测和运维策略优化奠定坚实的基础。
