基于距匹配及判别表征学习的多模态特征融合分类模型研究:高级别胶质瘤与单发性脑转移瘤的鉴别诊断
2024-01-29张振阳谢金城钟伟雄梁芳蓉杨蕊梦2
张振阳,谢金城,钟伟雄,梁芳蓉,杨蕊梦2,,甄 鑫
1南方医科大学生物医学工程学院,广东 广州 510515;2华南理工大学附属第二医院(广州市第一人民医院)放射科,广东 广州 510180;3华南理工大学医学院,广东 广州510006
原发性高级别胶质瘤(HGG)和颅内转移瘤是成年人中发病率较高的恶性脑部肿瘤[1,2],无创区分这两种肿瘤有助于医师为病人选择合适的治疗方案和临床管理策略[3,4]。然而,因为HGG和SBM在影像学上通常具有相似的表现,仅仅依靠影像学特征来区分HGG与单发性脑转移瘤(SBM)仍然具有挑战[5,6]。同时,在一些相关对比研究中,放射学家往往表现出鉴别力不足甚至较弱的情况[7-9]。例如,在一项研究中两位不同经验的神经放射学家根据MRI影像特征对HGG和SBM进行区分,结果显示最佳ACC=0.65,SEN=0.66,SPE=0.65[7]。这一表现明显低于他们构建的影像组学模型(ACC=0.83;SEN=0.80,SPE=0.87)。因此,开发比人类更有效的机器模型具有现实意义。
神经影像技术已经被视为诊断脑部疾病的有效工具,特别是,已经证明多模态神经图像(如MRI、PET、CT等)可以提供脑部异常区域的结构信息和功能信息[10]。事实上,不同序列的MRI图像可以看作是从多个角度描述脑部信息的多模态图像。因此,一个有意义的课题是开发一个基于多模态神经影像特征融合用于鉴别HGG和SBM的分类模型。
多模态医学数据的融合可以利用不同模态间的互补性和相关性等特性,从而对临床相关问题进行更彻底和更全面的建模[11-13]。例如,有研究从MRI、氟脱氧葡萄糖正电子发射断层扫描和脑脊液中提取多模态特征,并在特征水平上将它们融合,以训练基于内核的极限学习机,用于诊断阿尔茨海默病和轻度认知障碍[14]。使用类型特异性编码子网络从多组学数据中学习特征,并将其连接到一个表征中,然后使用多层分类网络进行药物反应预测[15]。有研究提出了一种分层融合框架,在决策层融合同质和异质分类器,用于医疗决策[16]。尽管这些传统融合策略很容易实现,但他们的有效性可能会因为无法学习潜在特征、无法识别模态之间的关系或相互作用以及无法提高特征的判别性等缺点而受到影响[11,17]。关于医疗数据融合的另一个问题是高维度,这通常使泛化模型的构建具有挑战性(称为“维度灾难”)[18]。特征降维方法旨在通过将多模态高维数据投影到嵌入空间来缓解这个问题,例如主成分分析(PCA)[19]、典型相关分析(CCA)[20,21]、判别相关分析(DCA)[22,23]和非负矩阵分解(NMF)[24]。特征选择方法通过筛选特征子集降低数据维度,例如ReliefF[25]、LASSO[26]和SVM-RFE[27]等。然而,这些传统的特征降维和特征选择方法最初大多是为单模态数据提出的,它们对多模态高维数据的有效性仍不确定。最后,值得注意的是,许多相关研究常采用深度学习的方法进行建模[28-31]。然而,医学数据往往面临数据量不足的问题,这导致深度学习的优势难以充分发挥,此时传统机器学习方法相较于深度学习更容易获得较优的模型性能,且其训练时间短、计算复杂度低、可解释性强[32]。
基于此,本研究提出了一种基于距匹配及判别表征学习的多模态特征融合分类模型,以探索来自多个MRI序列的影像组学特征之间的相互作用,并将多模态影像组学特征投影到共享表征空间进行融合以构建分类模型。通过与其他模型的鉴别性能进行比较验证所提出模型的有效性和优越性,通过融合特征的可视化实验验证该多模态特征融合方法的有效性。该方法可以得到更有利于鉴别HGG和SBM的融合特征,在患者相关检查不全的情况下,该模型有望成为计算机辅助鉴别HGG或SBM的有效工具。
1 资料和方法
1.1 研究对象
本研究为回顾性研究,遵守《赫尔辛基宣言》并经伦理委员会批准(批准号:K-2019-012-01),符合HIPAA标准无需患者知情同意。收集2007年9月~2020年9月于广州市第一人民医院(华南理工大学附属第二医院)经病理学证实为HGG 或SBM 的121 例患者(61 例HGG和60例SBM)资料。纳入标准:经组织病理学检查证实为HGG或SBM。排除标准:MRI图像上存在明显伪影;肿瘤病灶为单纯囊性。HGG组患者和SBM组患者之间的性别差异没有统计学意义,SBM组患者年龄与HGG组患者相比较大(Ρ=0.001,表1)。在分析前,所有资料均被匿名化,使用ITK-SNAP 软件(http://www.itksnap.org),于MRI图像的横断位平面上手动逐层勾画肿瘤的感兴趣目标区(ROI),这一工作由两名经验丰富的放射诊断专家(5年、16年放射诊断经验)共同完成。

表1 HGG和SBM患者队列的人口统计学特征Tab.1 Demographic characteristics of the patients with HGG and SBM
1.2 研究方法
本研究创新性地提出了一种基于距匹配及判别表征学习的多模态特征融合分类模型用于鉴别HGG和SBM,该模型首先将多序列的MRI图像特征融合为更有利于鉴别的融合特征,再使用融合特征训练分类器用于鉴别HGG和SBM。该模型主要包含3个部分:特征提取,特征融合和模型训练验证(图1)。

图1 基于距匹配及判别表征学习的多模态特征融合分类模型流程图Fig.1 Framework of the multimodal feature fusion classification model based on distance matching and discriminative representation learning.
1.2.1 特征提取 本研究使用开源影像组学工具包Pyradiomics(https://pyradiomics.readthedocs.io/en),在上述4个序列的MRI图像(T1WI、CE_T1WI、T2WI和T2_FLAIR)的ROI中各提取109个影像组学特征(表2),其中包括一阶特征(19个特征)、形态特征(15个特征)、灰度共生矩阵特征(24个特征)、灰度级大小矩阵特征(16个特征)、灰度运行长度矩阵特征(16个特征)、相邻灰度色差矩阵特征(5个特征)和灰度相关矩阵特征(14个特征)[33]。

表2 提取到的影像组学特征Tab.2 Extracted radiomic features
1.2.2 特征融合 本研究提出了一种新的多模态特征融合方法,在本研究中该方法将不同MRI序列视为多模态数据,该方法融合了从4个MRI序列中提取的多序列影像组学特征,如(图1)。首先,为每个序列的影像组学特征定义了特征矩阵Xi∈ℝ109×n,i∈()1,4 其中i表示MRI序列的序号(共4个MRI序列),n为训练样本的样本数。为了融合每个序列的影像组学特征并从多序列特征中学习隐藏的共享特征,假设存在一个潜在的共享表征空间,其中经过投影的多序列特征将在任何两种序列之间遵循相似的分布,因此,为每个特征矩阵定义了投影矩阵Qi∈ℝk×109,i∈(1,4),k为共享表征空间中特征的维度。将投影后序列间相似性通过数据分布中的第一原始矩和第二中心矩来量化,并将这个矩匹配问题通过下面的公式最小化使得任何两个序列在表征空间的特征具有相似的分布:
其中M(QiXi)=QiXie和Var(QiXi)=(QiXi)°2e-(QiXie)°2分别表示第一原始矩(或平均值)和第二中心矩(或方差),e是一个所有元素都为1的n×1的列向量,(·)°2是哈达玛积形式的平方表示l2范数。因此,共享表征空间中的融合特征矩阵通过以下方式获得:
然后,通过添加施加在共享表征空间中的融合特征矩阵V上的正则项重写方程(1):
由于融合特征是针对鉴别分类任务学习的,为了使融合特征更利于分类任务,该方法引入判别分析中的类内散度和类间散度作为融合特征的优化目标。类内散度矩阵和类间散度矩阵的计算公式如下:
其中SW(V)和SB(V)分别是V的类内散射矩阵和类间散射矩阵是V的cth类中的jth样本,μc是V的cth类中样本的平均向量,μ是V的所有样本的平均矢量,nc是cth类的样本数,在本研究的模型中c=2。
类内样本距离和类间中心距离可以表示为tr(SW(V))和tr(SB(V))。通过一些代数步骤,可以得到tr(SW(V))和tr(SB(V))的简化公式,如下所示:
其中,矩阵S中的元素满足如果vi和vj两者都属于该cth类,反之sij=0;矩阵L=U-S,其中U是一个对角矩阵,其ith对角元素是S的ith行的和,并且E是一个元素都为的矩阵。然后,基于类内散度和类间散度的融合特征优化目标项可以写成:
最后,目标函数可表示为:
最小化方程(10)中的目标函数可以公式化为以下优化问题:
求解方程(11)本质上是一个无约束最小化问题,本研究使用梯度下降方法对其进行优化,需要计算目标函数F相对于Q的梯度。请注意,Q中的每个元素Qi在F中都是独立最小化的,这相对于Qi是可微的。
接着可以算出F对于Qi的导数:
是哈达玛积形式的平方,⊙表示哈达玛积。
目标函数(10)的解决方案可以被描述为更新Qi←Qi-η∇F的迭代过程,其中是与迭代次数t和固定超参数a、t0以及t1相关的自适应步长。给定Qi的随机初始化,其在每次迭代中的更新规则为
此外,在每次迭代时,需要对Qi的每一列进行归一化步骤,由=1,2,…,109 表示:
在算法1中给出了所提出的算法的伪代码(表3)。

表3 多模态特征融合算法伪代码Tab.3 Pseudocode of the proposed multimodal feature fusion algorithm
1.2.3 模型验证 本研究通过研究分类器对鉴别分类模型的影响选择最佳的分类器构建鉴别分类模型,并通过网格搜索法确定模型中的参数。确定好参数和评估标准(五折交叉验证)后,将本模型与几种其他的多模态特征鉴别分类模型进行比较。最后,比较融合特征与原始特征产生的样本散点图。下面简要介绍其他模型:
基线被定义为直接对多模态特征进行特征串联的模型,然后进行分类器训练,而不进行任何进一步的特征选择或特征降维。
特征降维(或特征选择)方法。四种典型的方法作为比较基准,包括:(1)主成分分析(PCA)[19];(2)基于信息论的条件互信息(CMIM)[34];(3)基于谱图理论的谱特征选择(SPEC)[35];以及(4)基于稀疏学习的无监督判别特征选择(UDFS)[36]。基于无偏比较,所有这些方法的缩减特征的维数k都与所提出的方法一致,也都采用相同的分类器。
多模态融合方法。实验采用了两种多模态/视图学习模型作为特征融合的比较基准,包括:(1)典型相关分析(CCA)[20];(2)多视图降维(MDCR)[37],通过探索每个视图内的相关性,并通过内核匹配联合最大化不同视图之间的相关性,找到一个共同的低维子空间。对于CCA,通过在{1 0-10,…,101} 范围内的交叉验证来优化正则化参数。对于MDCR,超参数λ 在{0,0.5,…,3} 范围内确定。基于无偏比较,所有这些方法都采用相同的分类器。
下面对可视化样本散点实验介绍:
将原始特征与融合特征分别进行流形降维(tdistributed stochastic neighbor embedding,t-SNE[38])到二维特征空间,并将它们绘制为二维散点图,比较两者二维散点图中HGG与SBM样本的可分性。
2 结果
2.1 分类器对鉴别分类模型的影响
结果显示几乎所有分类器(“决策树”除外)都比一些基准方法取得了更好的性能,而最佳结果是通过逻辑回归实现的(表4)。
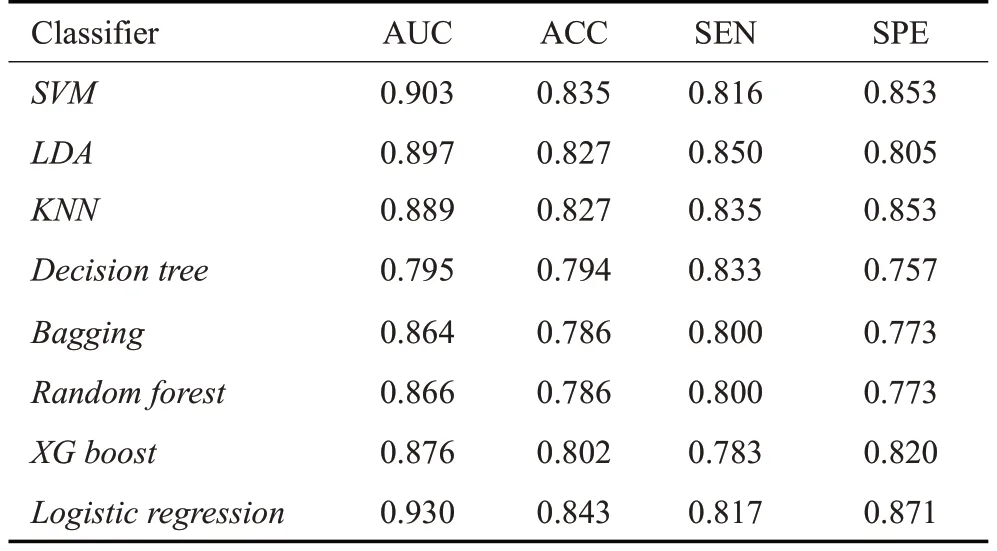
表4 采用不同分类器的情况下模型的鉴别性能比较Tab.4 Performance comparison of the models using different classifiers
2.2 HGG和SBM鉴别分类评估结果
本研究提出的模型除了在SEN中没有最优的表现,在SPE、ACC和AUC方面都优于其他模型(表5)。
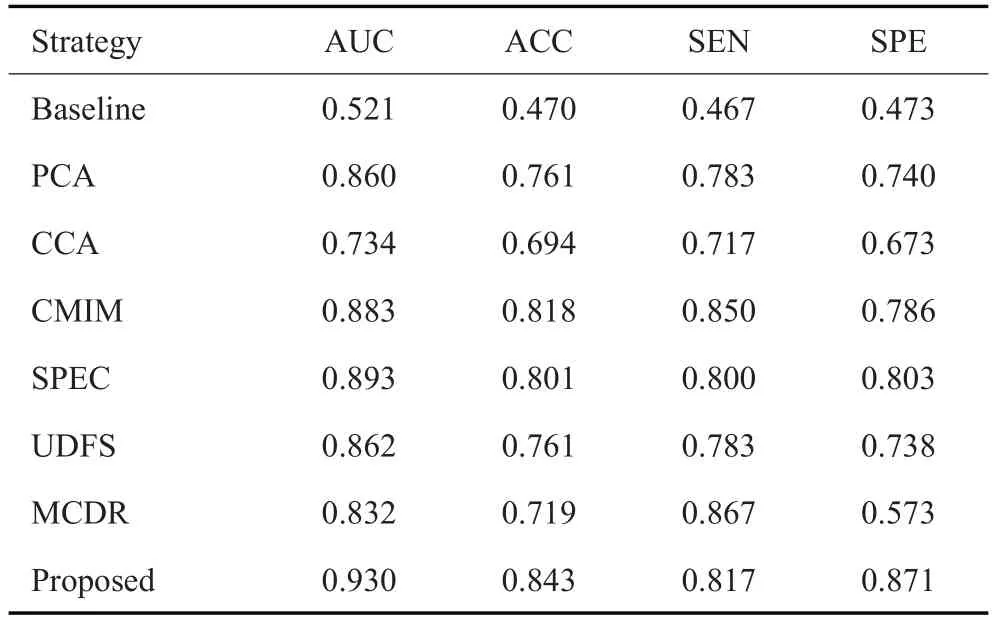
表5 基于距匹配及判别表征学习的多模态特征融合分类模型与其他模型在鉴别HGG与SBM中的鉴别性能比较Tab.5 Performance comparison between the proposed multimodal feature fusion classification model with other models for HGG and SBM discrimination
2.3 融合特征可视化实验结果
结果显示,融合特征样本散点图比由原始特征样本散点图更容易区分HGG与SBM样本散点(图2)。
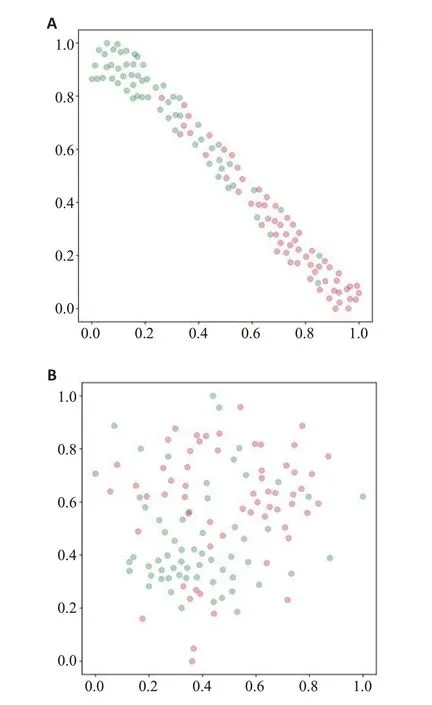
图2 融合特征(A)和原始特征(B)样本散点可视化实验Fig.2 Scatter plot visualization experiment of fused features(A)and original features(B)samples.
3 讨论
本研究创新性地提出了一种基于距匹配及判别表征学习的多模态特征融合分类模型,并利用该模型构建了高级别胶质瘤HGG与单发性脑转移瘤SBM的鉴别分类模型,对高级别胶质瘤HGG 与单发性脑转移瘤SBM进行鉴别分类,提高了术前无创区分HGG和SBM的准确度。结果显示,本研究提出的基于距匹配及判别表征学习的多模态特征融合分类模型在鉴别HGG和SBM有较好的鉴别性能且本研究使用的特征融合方法比其他方法也具有一定的优势。
首先,实验结果表明所有采取特征降维、特征选择和特征融合过程的模型都比未经任何降维,选择或融合操作的基线模型具有更高的鉴别性能。这说明采用多模态特征融合策略能够提高模型鉴别性能,特征降维、特征选择和特征融合过程都能够不同程度缓解多模态高纬度数据带来的“维度灾难”,从而使模型得到更好的鉴别性能。在临床问题中,合理地利用多模态医疗数据,有效地解决多模态医疗数据中的“维度灾难”,噪声等问题对构建临床问题的鉴别分类模型是至关重要的。
其次,从实验结果中可以看出,本研究所提出的方法优于所有4种特征选择方法(即PCA,CMIM,SPEC和UDFS)。这说明本研究通过共享表征学习探索不同模态间的相互联系提高鉴别分类模型的诊断性能,使得本研究提出的多模态特征融合方法学习的共享表征特征在提高分类精度方面比原始空间中使用的特征更有效。同时,传统的特征选择和特征降维方法对于多模态高维度数据也具有一定局限性:首先,特征降维和特征选择过程中通常会忽略模态间关系。相关研究领域的研究揭示了模态内和模态间的信息在捕获数据融合中模态间潜在关联的积极作用[39-41];其次,特征降维和特征选择过程中尚未充分探索特征与标签之间的关联。在临床问题中,希望利用多模态医疗数据和标签的关系产生针对特定诊断或预后任务的融合数据,这样的融合数据针对特定的任务会有更好的区分能力;最后,特征降维和特征选择过程通常在原始特征空间中,而在原始特征空间中跨模态的共享信息往往是潜在的和无形的。有相关研究[21,42]已经讨论过,将原始的多模态数据映射到一个潜在的空间可以帮助捕获不同模态之间的潜在特征。因此,将原始的多模态医疗数据映射到一个潜在的共享表征空间有望提取多模态医疗数据中的潜在信息。本研究通过将原始特征投影到共享表征空间形成新的特征空间一定程度上克服了传统的特征选择和特征降维方法的局限性,使得多模态特征模态间的关系得到了挖掘,捕获到更多潜在特征,同时也利用判别分析中的类间散度和类内散度作为优化目标充分探索了特征与标签之间的关联。
最后,实验结果表明本研究提出的模型也取得了优于两种特征融合方法(CCA和MCDR)的性能。这说明本研究提出的多模态特征融合方法能够更好地利用不同模态之间的相互联系提高对HGG和SBM的鉴别能力。同时,本研究提出的多模态特征融合算法将判别分析中的类间散度和类内散度作为优化目标进一步提高融合特征对于HGG与SBM样本的可分性,这也使得本研究提出的多模态特征融合方法比其他两种特征融合方法取得更好的鉴别性能。通过观察融合特征和原始特征的二维样本散点图,融合特征得到的二维样本散点图中的HGG与SBM样本比原始特征中的更具有可分性。同时,因为t-SNE流形降维最大程度保留了高维特征空间中的样本相对位置关系[38],二维散点图可以一定程度反映高维特征空间中样本的分布,因此可以说明融合特征比原始特征在鉴别HGG与SBM是更具有区分性,这也说明了我们引入判别分析优化目标的有效性。
本研究提出的基于距匹配及判别表征学习的多模态特征融合分类模型主要优势在于构建模型时使用创新的多模态特征融合方法。本研究使用的新特征融合方法通过将多模态特征投影到一个共享表征空间形成融合特征,并在此过程中加入判别分析将类结构信息融入融合特征。可以看出,本研究提出的特征融合方法不仅可以同时为进行特征融合和特征降维提供集成架构,还可以在优化过程中利用数据内在属性:样本间的判别关系,将其表述为优化目标。这种方法不仅一定程度上解决了“维度灾难”,而且有望从多模态数据中挖掘出更有意义和更具辨别性的潜在信息,并提高诊断的准确性。因此,来自不同MRI序列的影像组学特征不仅被融合,而且融合特征在用于鉴别HGG和SBM时更具有区分性。
虽然本研究提出的模型在鉴别HGG与SBM方面有更加有竞争力的鉴别性能,但仍存在一些可以缺陷。第一,在分类器选择上,实验已经应用融合的多模态特征来训练几个分类器,只选择了具有最好鉴别性能的分类器作为该研究的分类器。一个实际原因是,医疗决策问题在临床中通常是针对特定问题的,并且各种分类器可能对不同的疾病和临床问题具有不同的表现。为了更准确和稳定的预测,一种可能的解决方案是构建多分类器融合(MCF)系统,该系统在决策级别集成来自各种分类器的预测输出。相关研究已经证明了MCF系统在辅助医疗决策方面的功效[16,43,44],当将MCF应用于所提出的方法学习的融合数据时,可能会有进一步的改进。第二,本研究采集的资料样本量较小。因此,在后续的研究中需要采集更大的样本量对本模型的鉴别性能进行评估。第三,基于投影矩阵的该方法可能在不同设备表现出较强的特异性,在涉及多设备或多中心研究时可能会呈现不一致的性能。
综上所述,本研究提出一种创新的基于距匹配及判别表征学习的多模态特征融合分类模型用于HGG和SBM的鉴别分类。所提出的模型将特征降维和特征融合集成到一个统一的框架中,并加入包含类结构信息的判别优化目标。与其他多模态特征融合分类模型相比,本研究所提出的方法在HGG和SBM的鉴别诊断中更有优势,在实现计算机辅助诊断上具有一定的潜力。