自杀行为预测中的机器学习方法:一项系统综述
2024-01-26钱春莲何宇豪张强尤静杨丽
钱春莲,何宇豪,张强,尤静,杨丽
(1.天津大学教育学院,天津 300350;2.天津市自杀心理与行为研究实验室,天津 300350;3.天津大学应用心理研究所,天津 300350;4.普洱学院,普洱 665000;5.天津中医药大学,天津 301617)
全球每年有80万人死于自杀,自杀既是一个严重的社会问题,也是一个世界公共卫生问题,准确预测自杀是临床研究的重点[1]。美国疾病控制与预防中心(Center for Disease Control and Prevention,CDC)指出,自杀行为(suicidal behavior)是指个体有意结束自己生命的相关想法和行为,主要包括自杀意念(suicidal ideation)、自杀尝试(suicidal attempt)和自杀死亡(suicidal death)。自杀意念是指想到、思考或计划自杀;自杀尝试被定义为指向自我的、非致命性的、具有一定程度死亡意图的潜在自我伤害行为;自杀死亡被看作是这种行为的后果[2]。
机器学习(machine learning,ML)是一种为了获得复杂数据的变量间潜在规律的方法,这种方法可以通过数据的输入和模型的输出来不断迭代提升模型的准确性及其效能,目前已应用于各类疾病的早期识别、实时预测、辅助诊断以及预后。根据所使用数据是否带有结果变量值作为标签,可以将机器学习分为监督学习、无监督学习和半监督学习。在自杀行为预测领域中,基本采用监督学习下的分类预测模型,即拥有每个个体是否发生自杀行为的数据。测试的方式即是用模型预测的结果与样本真实的标签进行对比。常用的机器学习模型评价指标有:准确性(accuracy,ACC),指模型预测的真阳性与真阴性个体占总样本的比例;阳性预测值(positive predictive value,PPV),指模型预测为阳性的个体中真的患病的比例;敏感性(sensitivity),指本来就患病的个体中模型预测为阳性的比例;特异性(specificity),指本来未患病的个体中模型预测为阴性的比例;操作者特征曲线(receiver operating characteristic curve,ROC曲线),指通过不同模型阈值下的敏感性与准确性所绘制的曲线,ROC 曲线下的面积(area under curve, AUC)是最常用的模型整体效能指标,取值范围是0.5~1,越接近1,表示预测效果越好。
Franklin 等人对365 篇自杀风险因素文章进行了元分析,结果显示对自杀风险的预测能力在过去50年没有得到改善,仅略高于猜测水平。原因是传统方法大多根据已有假设,孤立地测试较少的预测因素[1]。自杀是生物、心理和社会因素复杂交互作用导致的[2],对自杀的预测可能需要考虑数百个风险因素的复杂组合[3]。机器学习可以迭代测试大量潜在因素的复杂关系,产生优化预测的算法,提高对自杀预测的能力[4,5]。Caon,Mann等学者的早期研究显现出应用机器学习进行自杀预测的可能性[6,7]。Burke,Passos等学者使用横断数据进行预测[8,9],Walsh,Simon等人使用纵向数据预测未来自杀风险[10,11],ROC曲线下面积达到0.84~0.93,明显优于传统方法得到的0.56~0.58[1]。
近年来关于机器学习与自杀的研究已经受到了广泛关注,但是对于机器学习这种方法的临床意义以及如何将其真正应用于临床实践还有许多问题需要解决。对此,一些学者持积极态度。自杀风险的早期精准识别可以显著增加自杀预防的成功率,节省紧缺的危机干预资源。机器学习在可扩展的保健质量和提高资源效率方面的潜在收益非常具有吸引力[12]。也有学者则提出了怀疑或反对的意见,主要集中在以下几点:第一,模型本身的可信度存在争议,虽然机器学习在预测的准确性上拥有传统方法无法比拟的效果,但是一个机器学习模型会受到数据质量、应用场景和特征选择等诸多限制[13];第二,预测结果的可解释性需要加强,如何将模型的结果有效地传达给相关人员是将机器学习方法应用于临床实践的关键[14];第三,当前机器学习研究的重点在于长期预测,这样的模型在公共卫生环境下的是十分适用的,但现实情境中可能更需要获得患者接下来几天内会做出自杀行为的风险的信息[15];第四,在大规模实施机器学习算法对自杀风险的早期识别与实时监测之前,必须先开发出一套针对自杀行为的成熟有效的循证干预措施,否则即使识别出一个有自杀风险的人,又如何向其提供进一步的支持呢?可以看出机器学习是否能帮助医生及相关人员做出更好的决策是一个重要的议题[4]。
先前系统综述搜索得到35 篇用机器学习预测自杀想法和行为的研究,预测自杀死亡的仅有五项,大多使用军队数据,缺少普通群体的预测模型[16]。但初步搜索可以发现,此综述发表以来,运用机器学习预测自杀行为的研究还在快速增长,尤其是出现了很多运用在普通群体中预测自杀死亡的研究。因此,本研究对自杀行为预测中的机器学习方法进行了全面的回顾,并尝试为该领域未来研究提出展望。
1 方法
1.1 检索策略
搜索了发表在PubMed、EMBASE、Web of Science 数据库2022 年11 月之前的文章。以Web of Science 为例,搜索关键词为:TS=(“artificial intelligence”or“machine learning”or“data mining”or“statistical learning”or“big data”or“exploratory analyses”)AND TS =(“suicide”or“suicidality”or“suicidal behavior”or“suicide attempt”or“suicide death”or“suicide plan”or“suicide thoughts”or“suicide ideation”or“suicide gesture”or“suicide threat”or“STB(suicidal thought and behavior)”or“STBs(suicidal thoughts and behaviors)”or“parasuicide”or suicid*)。
1.2 纳入排除标准
纳入标准为:(1)纳入以下一项或多项结果:自杀意念、自杀尝试、自杀死亡;(2)使用机器学习技术预测自杀想法和行为结果;(3)可提取原文献结果;(4)用英语书写;和(5)同行评审。
排除标准为:(1)没有验证程序(如交叉验证,Bootstrapping 等方法);(2)自杀相关结局变量的综合结果报告(例如仅报告自杀风险,没有自杀意念预测效果的单独报告);(3)特征仅使用一个或者两个量表测量(探索量表对自杀风险预测效果为主);(4)重复数据;(5)仅使用生物标记或开发系统的行为数据;(6)目标重点是为了开发算法;(7)无法获取原文。
1.3 信息提取
两名作者独立地提取纳入文献的下列信息:第一作者、发表年份、研究对象、样本信息、研究设计、机器学习算法、预测变量和模型评价指标。其中预测变量分类参考了Burke(2019)划分的类别,对于有分歧的信息与第三位作者深度讨论直到达成共识。
2 结果
通过检索获得4773 篇文献,最终纳入71 篇,其中报告自杀意念预测的有21篇、自杀尝试43篇、自杀死亡17篇。图1、图2和图3为机器学习对这3种自杀行为进行预测的样本、算法和预测变量差异的雷达图。

图1 不同自杀行为结果预测所使用的样本
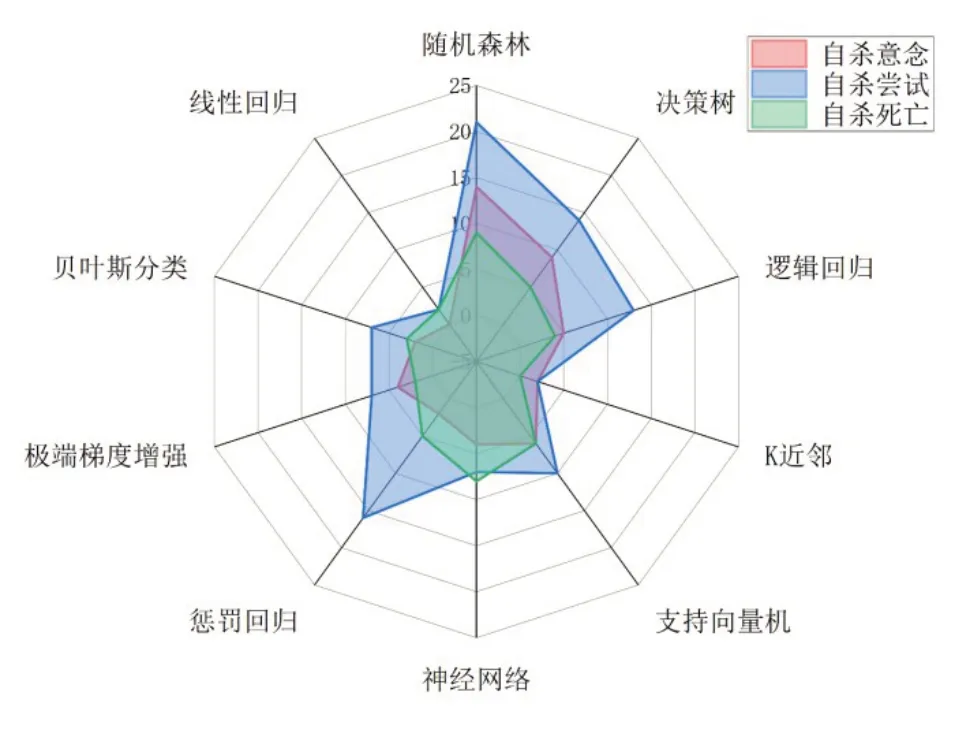
图2 不同自杀行为结果预测所使用的算法
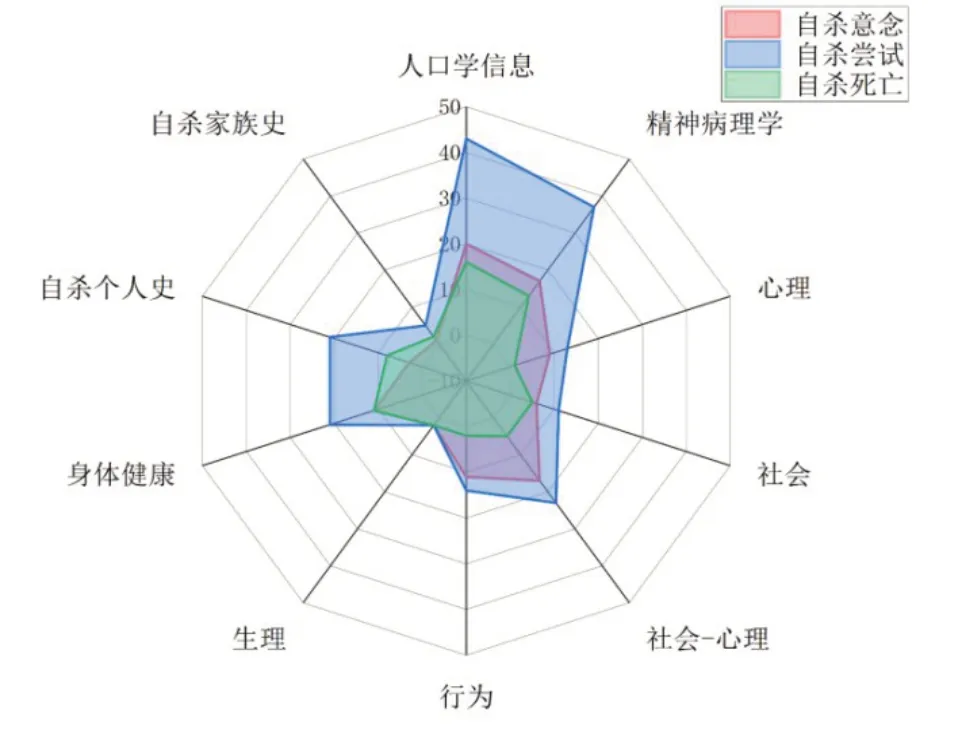
图3 不同自杀行为结果预测所使用的预测变量
2.1 自杀意念预测
通过搜索得到21 项以自杀意念为结果变量的研究,6 篇采用纵向设计(30 天~5 年),研究对象大多是社区人群(13 篇),样本量范围为624~77973人。这些研究选取了6~5554 个指标,纳入模型最多的预测因素是人口统计学和社会变量,使用多种(1~6种)机器学习方法进行比较预测,使用最多的算法是随机森林与决策树。应用机器学习预测自杀意念的AUC 区间为0.70~0.97,PPV 区间为0.17~0.82,敏感性区间为0.50~0.91,特异性区间为0.67~1.00。在与传统预测方法进行比较时,有3项研究直接对比了机器学习算法和传统方法(正则逻辑回归、逻辑回归)的预测效果,其中2 项表明机器学习预测效果更好[17,18]。4 项研究的间接对比中,2项研究支持机器学习预测效果更好的结论[19,20]。
2.2 自杀尝试预测
通过搜索得到43 项以自杀尝试为结果变量的研究,18 篇采用纵向设计(30 天~12 年),研究对象大多是临床样本(20 篇),样本量范围为75~3714105 人。这些研究选取了17~5554 个指标,纳入模型最多的预测因素是人口统计学和精神病理学变量,使用多种(1~7 种)机器学习方法进行预测,使用最多的算法是随机森林与惩罚回归。应用机器学习预测自杀尝试的AUC 区间为0.63~0.96,PPV区间为0.04~0.98,敏感性区间为0.15~0.91,特异性区间为0.39~0.99。在与传统预测方法进行比较时,有13项研究直接对比了机器学习算法和传统方法(广义线性模型、逻辑回归、Cox回归、非正则化逻辑回归、正则逻辑回归、惩罚回归)的预测效果,其中10项表明机器学习预测效果更好[5,11,21-28]。3项研究的间接对比也都支持机器学习预测效果更好的结论[19,29,30]。
2.3 自杀死亡预测
通过搜索得到17 项以自杀死亡为结果变量的研究,7 篇采用纵向设计(30 天~730 天),研究对象大多是社区人群(7 篇),样本量范围为251~2960929人。这些研究选取了6~8071个指标,纳入模型最多的预测因素是人口统计学和精神病理学变量,使用多种(1~8 种)机器学习方法进行预测,使用最多的算法是随机森林与神经网络。应用机器学习预测自杀死亡的AUC 区间为0.69~0.93,PPV 区间为0.007~0.27,敏感性区间为0.11~0.82,特异性区间为0.58~0.83。在与传统预测方法进行比较时,有6 项研究直接对比了机器学习算法和传统方法(广义线性模型、逻辑回归、Cox 回归)的预测效果,其中4项表明机器学习预测效果更好[31-34]。
3 讨论
本研究发现机器学习方法对于自杀行为具有优秀的预测效能,62.1%的模型AUC 高于0.8,敏感性与特异性也表现良好,特异性普遍比敏感性更高,表明模型筛选出的阴性结果比阳性结果更加可信。本文注意到机器学习模型的阳性预测值普遍偏低,仅6 项研究的PPV 超过0.5,预测自杀死亡的平均PPV甚至只有0.11。PPV较低意味着对自杀行为更多的虚报,可能导致医护资源的浪费,这似乎与应用机器学习的初衷背道而驰。然而低PPV 并不意味着模型缺乏实用价值,因为一次成功预防自杀的效益可能远远超过对被模型虚报的个体进行评估或干预的成本。
PPV低的根本原因可能在于自杀的发生率本身是较低的,即使在精神病患者这样的高风险人群中。这样常常造成类别不平衡现象,即所使用数据中的自杀行为者只占总样本的一小部分,这样会给模型的训练带来很大的误差。常用的改进方法包括上采样(如SMOTE、ADASYN 等算法)、下采样(如EasyEnsemble、BalanceCascade 等算法)以及上下采样相结合的综合采样(如SMOTETomek、SMOTEENN等算法)。上采样是把其中一类较少的样本量生成和样本量多的一类相同;而下采样则相反,把样本量较多的类的样本量减少到和样本量少的一方相同。又或者采用代价敏感学习(cost-sensitive learning)方法调整每一类结果的样本在模型中的权重。
当前研究所选用的样本主要为临床样本和社区样本,缺乏学校样本。然而青少年与大学生心理健康问题更加突出,学校的自杀预防与危机干预工作当前越来越受到重视。这不仅仅是教育与管理问题,更是牵动人心的社会问题,处理不当极有可能会带来严重的社会后果。本研究认为接下来学校应该同样成为该领域研究与应用的重心,对于自杀这个重要问题的处理,亟需更多跨领域的合作。从提取的数据结果来看,EHR 数据(12 项研究)、军队数据(13项研究)、国家调查数据(24项研究)是该领域研究中最大的数据来源。这可能和机器学习本身对数据量的要求有关,独立研究难以获取大量的数据,尤其是在地广人稀、基础建设较薄弱的地方。未来需要大量高质量数据,要实现这个目标就需要做到不同研究的数据透明化和不同机构的数据共享。
当前的研究还存在一个局限,即纳入模型的预测变量较为单一,大多数为人口统计学与精神病理学变量。未来还需要来自于不同维度与视角的多模态数据信息,包括那些传统上不在临床环境中检查的经济、社会和网络因素[35]。与此相关的,语音、文字、生物、行为信息,这些同样与自杀预防息息相关的因素尚未被广泛研究,但已经有学者进行了探索。Pestian 就是通过语音处理来识别[36]。Tsui的研究则是将临床常用的结构化数据与非结构化的、医生记录的文字信息相结合之后来进行预测[37]。还有一些研究则是利用一些生物学的信息[38]。基于微博树洞的深度学习研究则是使用一些发帖信息、在线活跃信息等来进行自杀风险的判断。Chadha Akshma从Reddit中抽取了一个包含20000个帖子的数据集,并使用多种有效的word2vec 技术将其预处理为令牌,通过结合卷积神经网络中的注意力模型和长短期记忆,提出了一种新的混合方法。这项研究的目的是开发一个有效的学习模型来评估社交媒体上的数据,以便有效和准确地识别有自杀念头的人。随着技术的发展,时间密集型数据变得更容易获取,移动端数据、可穿戴设备数据是现在的热门应用[39]。为确定自杀风险与睡眠质量变化和食欲紊乱之间的关系,Berrouiguet设计了一个系统,能够从智能手机的本地传感器和先进的机器学习和信号处理技术的数字足迹获得临床信息,以识别自杀风险[40]。
预测变量并不是越多越好。随着维度的增加,机器学习模型的效能确实会显著提升。但是分类器有一个临界点,临界点所对应的纳入特征数量即最优特征数,在这之后再增加特征数反而会降低效能,这种现象被称为维度诅咒[41]。这是因为过多的特征会使数据空间变得稀疏,导致模型过拟合,即只在训练集中保持高效能,但应用于新的数据集时预测准确性可能会大大减弱。为了提高机器学习算法的生态效度,未来必须进一步完善特征的筛选工作。当前的思路主要有两个方向:一是通过先验的自杀相关理论模型来对特征进行主观选择;二是通过算法本身的特征工程来进行事后调整。未来该领域应该更多地探索理论驱动与数据驱动之间的平衡。理论试图理解因果机制,而机器学习则是以牺牲可解释性为代价,专注于优化预测效果。Schafer 的元分析结果表示,意念-行为框架内的理论对自杀行为的预测效果优于其他传统自杀理论,但机器学习对自杀意念、自杀尝试和自杀死亡的预测要远好于各种理论驱动框架[42]。如果能将两者结合,那将进一步促进对自杀的理解和预测。
目前研究所使用的算法更多为传统机器学习算法,最常使用的是随机森林和惩罚回归。随机森林的准确率非常高,优于大多数传统算法,但是可解释性较差。惩罚回归,例如拉索回归、岭回归,这些方法可能单独使用,也可能放在构建模型的前期,用于选择预测因子。不过自杀死亡的预测中已经开始较多地使用神经网络及深度学习算法。这类算法最大的优势在于可以充分利用数据,数据的量级和复杂性到达一定水平后,就极难再提高效能了,但神经网络的表现仍然能继续与数据量保持正相关。机器学习的算法更新换代十分迅速,即使是传统算法也已经有了不同程度的升级优化,而应用于自杀预测领域中的算法迟迟缺乏更新。这种现状可能正是由数据本身的复杂性较低所决定的。一个有效的解决方法是收集纵向数据。Schafe发现使用纵向数据比使用横向数据的机器学习对自杀相关结果进行了更好的分类,意味着未来研究需要更多适配纵向数据的算法[43]。
虽然把预测自杀行为这项至关重要的工作交由机器学习来执行,从直觉上是一件令人怀疑的、不够可靠的事,但也正是因为自杀问题的严重性和紧迫性,任何有利的、有效的循证方法都是值得尝试的。需要强调的是,机器学习应该被认为是相关人员做出临床决策的补充,而不是取代他们。目前比较谨慎的做法是将机器学习作为辅助筛查工具配合相应的筛查问卷和电子病历一起使用。传统问卷的最大缺陷在于难以识别作答者的不真实作答,从而导致漏报,机器学习可能有能力弥补这一缺陷,从作答者的其他相关变量中“捕获”其内隐的自杀风险。
