基于3σ-SSA的数据清洗方法在大坝智慧安全监测系统中的应用
2024-01-26陈伟楠杜国志王亦斌
陈伟楠,杜国志,张 锏,王亦斌
(1.浙江省水利水电勘测设计院有限责任公司,浙江 杭州 310000;2.中国南水北调集团水网水务投资有限公司,北京 100000)
1 研究背景
目前,我国已建成近10万座水库大坝,形成了世界上规模最大、范围最广、受益人口最多的水利基础设施体系,水利工程事关人民群众生命财产安全、防洪供水安全和经济社会稳定大局,保障水库大坝安全建设运行是水利工程运管工作的重中之重。“十四五”以来,水利部高度重视智慧水利建设,先后出台了《关于大力推进智慧水利建设的指导意见》《智慧水利建设顶层设计》《“十四五”智慧水利建设规划》《“十四五”期间推进智慧水利建设实施方案》等系列文件[1],将推进智慧水利建设作为推动新阶段水利高质量发展的6条实施路径之一,并将智慧水利作为新阶段水利高质量发展的显著标志[2]。
大坝安全监测及数据分析预警是掌握大坝实时工作性态、解析大坝变化规律的关键途径。随着数字孪生水利工程要求的不断提高,未来水利工程安全监测数据具有以自动化监测为主、数据量庞大、信息丰度高的基本特征,将监测获得的资料进行及时而准确的分析,从而掌握工程运行性态,对工程整体安全性能作出研判至关重要。目前,水库大坝安全监测数据几乎仍处于人工加自动化收集数据、人工分析数据的阶段,通常专业技术人员以年、半年为周期对监测数据进行分析,人力成本较高且缺乏时效性。因此,构建大坝智能安全监测系统,着手安全监测数据收集—处理—分析—研判全链路智能化技术路线研究,实现监测数据到大坝运行状态信息的实时量化变现,能够为传统水利工程向数字孪生水利工程智能化、智慧化转型提供关键技术支撑[3-10]。
大坝智能安全监测系统中,安全监测数据的收集和处理是后续分析研判工作的基础,及时、准确地识别海量监测数据中的异常值并将非结构原因导致的粗差剔除,是保证后续分析准确可靠的关键。目前,行业内常用异常值识别方法主要包括过程线法、专家经验法、统计模型法和统计检验法,这些传统异常值识别方法在面对海量自动化监测数据进行数据清洗时往往略显乏力,存在如过程线法、专家经验法判断异常值需要人工干预无法实现自动化,统计模型法需要人工建立回归模型且要求环境量和效应量数据回传同频,以3σ准则法、Grubbs准则等为代表的统计检验法在面对一组内有多个异常值时准确性低等问题[11-12]。
为此,本文提出利用奇异谱分析(Singular Spectrum Analysis,SSA)对3σ准则法进行优化,通过奇异谱分析对数据序列进行重构,并利用3σ准则对实测值及重构后的主频数据之间的残差序列进行统计检验,从而实现数据异常值的自动识别。构建的3σ-SSA分析数据清洗方法具有易于实现自动化、对环境量数据依赖度低、处理异常值较多的自动化监测数据仍保持较高准确性等特点,目前已依托国内某水库数字孪生建设工程,在该水库的大坝智慧安全监测系统中得到成功应用。
2 基于3σ-SSA的数据清洗方法原理
2.1 3σ准则
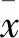
(1)
2.2 基于3σ-SSA的数据清洗方法
为解决传统3σ准则在处理自动化监测数据时的局限性,同时避免环境量、效应量数据传输可能不同频带来的影响,本文引入奇异谱分析(singular,SSA)对3σ准则进行优化[14-15]。奇异谱分析是一种融合概率论与多变量统计的非参数方法,该方法能从序列测值信息中有效识别出噪声和周期振荡成分,且易于实现自动化,能够为监测数据实时自动清洗提供支撑。
基于3σ-SSA的数据清洗方法步骤如下,基本流程如图1所示。

图1 3σ-SSA数据清洗流程图
Step1:感知设备收集回传实时监测数据,原始数据序列Xdata{x1、x2、……、xn}。
Step2:对原始数据序列进行奇异谱分析(SSA),将原始数据序列映射成一个窗口长度为L的向量序列,形成一个K个长度为L的向量,即根据窗口长度L将数据序列滞后排列,生成轨迹矩阵X为:
(1)
式中,窗口长度L(2≤L≤N),尽量不超过N/3,可取数据周期的整数倍;1≤i≤K。
Step3:对轨迹矩阵X进行奇异值分解,令S=XXT,得到L个特征值λ1≥λ2≥…≥λL≥0及对应正交特征向量。令d=rank(X),轨迹矩阵可分解为:
X=X1+X2+…+Xd
(2)
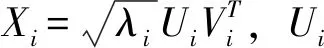
Step4:将下标集合{1,2,…,d}划分为m个互不相交的子集{I1,…,Im},则有
X=XI1+XI2+…+XIm
(3)
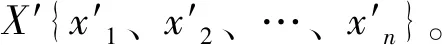
(4)

3 工程实例
为验证所述3σ-SSA数据清洗方法的应用效果,选取浙江某水资源配置重要枢纽工程闸室钢筋计2022年度自动化监测数据,分别以传统3σ准则和改进后的3σ-SSA方法进行异常值识别,并对比数据清洗效果。原始数据序列如图2所示,受自动化监测设备影响,该测点原始数据存在多个数值较大的明显异常测值。
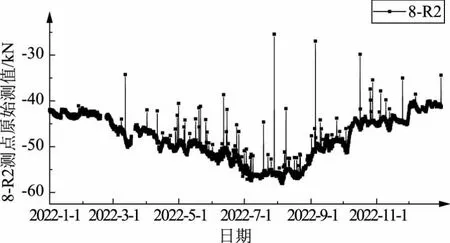
图2 自动化监测原始数据
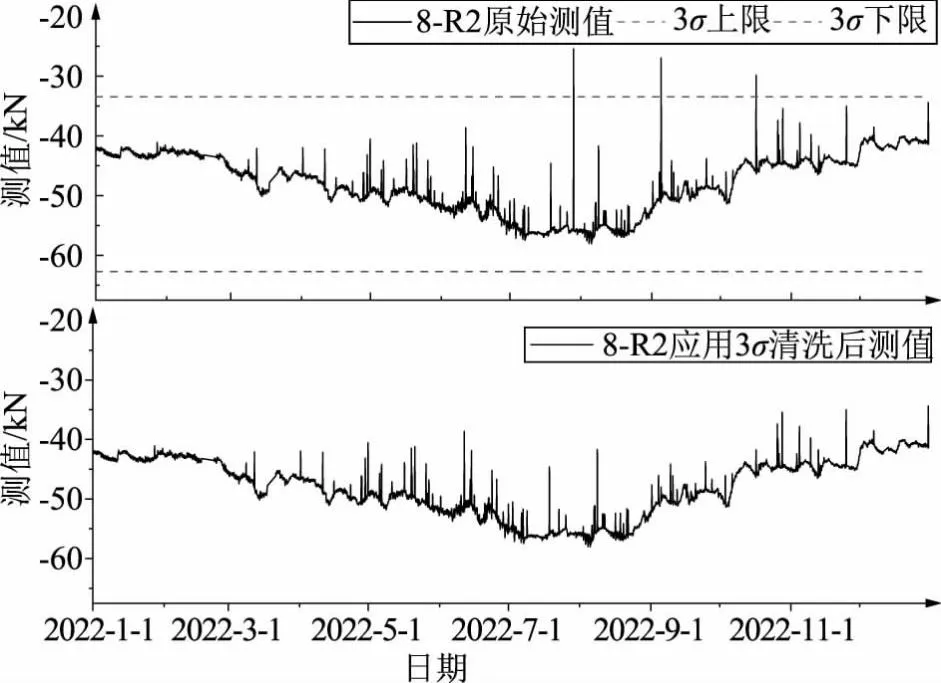
图3 3σ准则数据清洗结果
采用3σ-SSA数据清洗方法对原始数据序列进行处理,首先用奇异谱分析法对原始数据进行分解、重构,此处取窗口长度L=30,提取出的重构序列如图4所示,降序排列后各重构序列对应特征向量λi值及占比统计见表1,文中仅展示贡献率前十的特征向量及对应重构序列。从图4、表1中可以看出,重构序列1基本能够反映原始数据序列的分布规律及发展趋势,贡献占比达87.64%,后续重构序列2贡献占比均低于1%且波动极小,可视作噪声。因此,以重构序列1作为奇异谱分析后重构结果,计算与原始数据序列之差,生成残差序列,残差序列过程线如图5所示。根据3σ准则,计算残差标准差σ为1.05,结合重构序列划定异常值识别上、下限,数据清洗结果如图6所示。
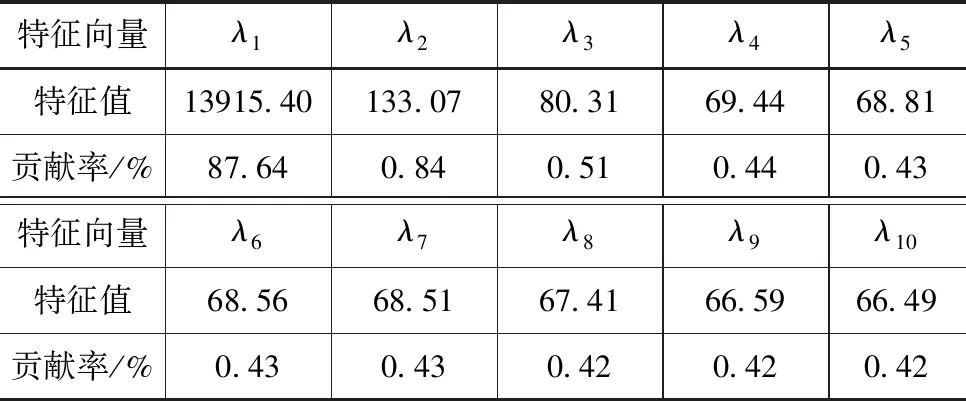
表1 奇异谱分析分量贡献率统计表

图4 奇异谱分析前十重构序列
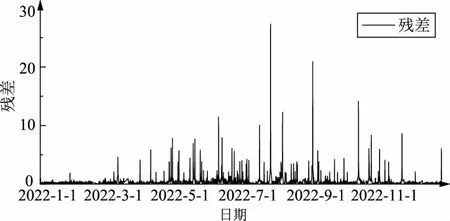
图5 残差序列过程线
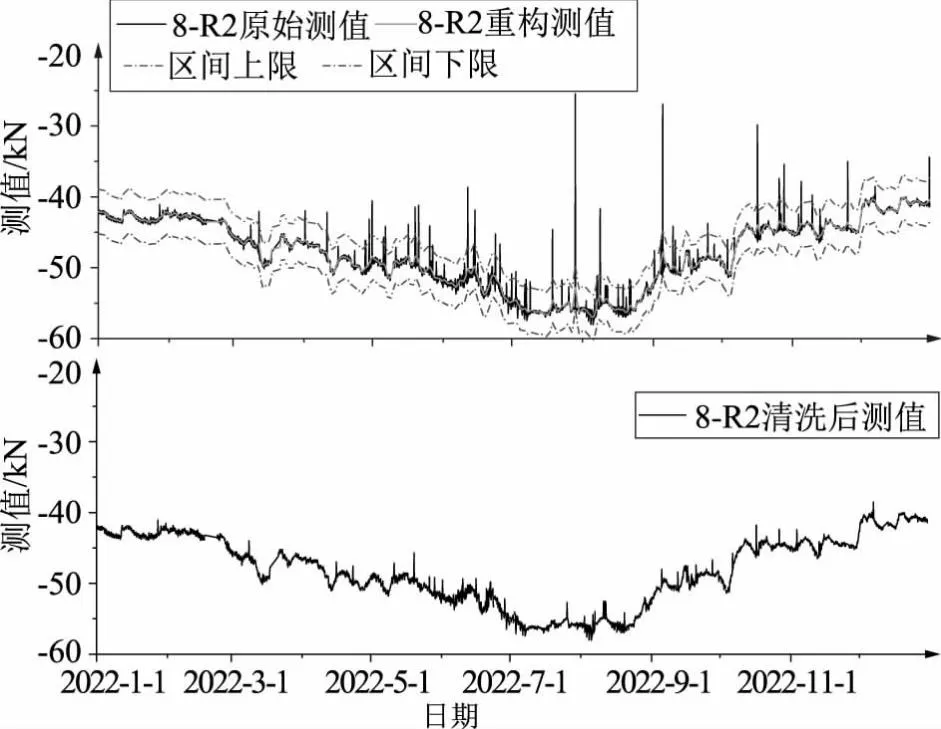
图6 3σ-SSA数据清洗结果
对比图6及图3的数据清洗结果,可以看出,利用奇异谱分析改进后的3σ-SSA数据清洗方法在处理存在大量异常值的自动化监测数据时,能够避免异常数据的不良影响,识别异常值并予以剔除,清洗后的数据基本平滑,满足后续数据分析精度要求。
综上所述,基于3σ-SSA的数据清洗方法在处理存在较多异常值的自动化监测数据时,仍具有较高的准确性,基本不受异常数据的影响,稳定性优于传统3σ数据清洗方法。
4 系统应用
为验证该方法的可应用性,将算法内嵌于某大坝智慧安全监测系统的数据管理模块,接入自动化监测设备实时数据进行数据清洗测试。
该系统的数据管理模块基于测点管理模块中预设的点位,对测点的数据的底层管理,支持自动化监测数据接入、自动清洗,以及溯源和修正等功能。本文提出的3σ-SSA的数据清洗方法为该模块安全监测数据的实时清洗提供支撑,检测和提取由于网络异常或设备异常等情况产生的异常值,并将信息进行推送至用户,方便排查是否存在需要修正的问题,提高数据维护水平,为数据分析、预警指标拟定等上层功能提供准确有效的数据基础。
系统接入自动化监测设备实时数据后,通过3σ-SSA数据清洗方法对原始数据进行预处理,清洗后的数据序列基本去除明显异常点,过程线较为平稳无突跳,基本能够满足后续分析、建模需求。
综上所述,基于3σ-SSA的数据清洗方法能够实现自动化,内嵌于大坝智慧安全监测系统后,能够满足监测数据高质量自动清洗要求,具有较高的可应用性。
5 结论
针对自动化监测数据监测频次高、数据量大、异常值多,传统数据清洗方法难以满足数据处理要求的问题,本文通过引入奇异谱分析法对传统3σ分析方法进行改进,提出了适用于自动化监测数据的3σ-SSA数据清洗方法,并依托工程实例验证其有效性及可应用性,得出结果如下:
(1)有效性验证。改进后的3σ-SSA数据清洗方法在处理存在大量异常值的自动化监测数据时,仍具有较高的准确性,基本不受异常数据的影响,稳定性及异常值识别精度明显优于传统3σ准则数据清洗方法。
(2)可应用性验证。基于3σ-SSA的数据清洗方法内嵌于大坝智慧安全监测系统后,可实现监测数据的实时清洗,清洗后的数据质量较高,基本能够满足后续数据分析、数据建模等上层应用要求。
