逻辑内建自测试技术进展综述
2024-01-26金敏向东
金 敏 向 东
(清华大学软件学院 北京 100084)
1 引 言
使用外部测试设备进行大规模集成电路测试的传统测试方法因测试应用时间长、I/O 通道有限和存储器资源昂贵,使得测试成本变得越来越不可控。解决这一问题的一种常用方法被称为逻辑内建自测试(logic buit-in self-test,LBIST),它将一些特定的测试电路结构嵌入到被测电路中,以减少对外部测试设备的需求[1]。
应用该技术产生测试激励和分析输出响应的功能电路都被内嵌到待测芯片内部或芯片所在的同一板上的其他地方,因此可以方便地使用片上时钟、总线等资源,使开展时序相关故障检测的全速测试变得相对容易。此外,处理器核若以内建自测试方式设计,会使片上系统测试更加容易,因为这样的处理器核在后期集成到系统中之后仍然可测[2]。
用于测试随机逻辑的 LBIST 技术大致可分为两大类:在线 LBIST 和离线 LBIST[3]。在线LBIST 指在执行测试时,芯片功能电路处于正常操作模式,其又可以分为并发和非并发两种情况。并发在线 LBIST 的测试流程可与功能电路正常操作同时进行,而非并发在线 LBIST 需要功能电路处于空闲模式时才可以执行测试流程。离线LBIST 指在执行测试时,芯片功能电路处于非正常操作模式,在业界常用于检测系统级、板级或芯片级非实时故障,其又可以分为功能化和结构化两种情况。功能化离线 LBIST 依据功能电路的功能规范执行测试,并且通常采用功能级或更高级的故障模型。结构化离线 LBIST 依据功能电路的电路结构执行测试。
由于易于与传统扫描体系结构集成,因此,多输入特征寄存器和并行移位序列产生器的自测试(self-test using MISR and parallel SRSG,STUMPS)架构是迄今为止工业界唯一广泛使用的 LBIST 体系架构[4]。但是由于使用了伪随机测试样例,其故障覆盖率往往不能令人满意,因此该技术无法被全部的应用场景所采纳。在过去的几十年,STUMPS 架构仍然处于不断被改进优化的过程中。
2 国内外研究进展
STUMPS 架构在故障覆盖率方面存在天然的能力不足,自其正式发表之后就有大量确定性自测试类方法被提出,可改善故障覆盖率。通常情况下,各相邻测试向量之间的相关性较差,与正常功能模式相比,测试模式下的各扫描单元出现数据位跳变的概率大大增加,从而使得电路整体功耗大幅上升。在 LBIST 电路上,测试模式功耗陡增的情况尤为严峻,因此,LBIST测试的低功耗设计和实现成为一个研究热点。LBIST 技术需要在正常功能电路中嵌入额外的测试结构,不可避免地带来更多的面积和接口开销。当今时代,电路规模往往趋于庞大且面积受限,如何缩减这些开销是另外一个研究热点。在测试模式下,电路输出往往会产生未知值(常以“X”标识),LBIST 架构中的测试压缩模块在输入存在“X”值时难以正常工作,因此,如何设计“X”容忍的 LBIST 电路也是一项不小的挑战。
2.1 国外研究进展
LBIST 的国外相关研究团队有斯坦福大学的 Subhasish Mitra 教授、德国斯图加特大学的 Hans-Joachim Wunderlich 教授、杜克大学的Krishnendu Chakrabarty 教授、德克萨斯大学奥斯汀分校的 Jacob Abraham 及 Nur A.Touba 教授、普渡大学的 Pomeranz 教授、布雷西亚大学的 Marco Metra 教授、佛罗里达大学的 Mark M.Tehranipoor 教授等。
近年来,针对低功耗设计和实现,有学者试图通过测试向量产生器(test pattern generator,TPG)改进设计[5-8]、多输入特征寄存器(multipleinput signature register,MISR)改进设计[9]和扫描链分组及加权选通[10]等方法来降低测试功耗,均产生了一些新的研究成果。针对降低 LBIST 架构的面积开销和接口需求,Shiao 等[11]利用基于线性反馈移位寄存器(linear feedback sift register,LFSR)的同一硬件结构来同时实现测试向量产生和测试响应压缩的功能,以达到减少内建测试电路面积开销的效果。另外,适应多核[12]、多时钟域[13]的片上系统或 2.5D、3D 更高集成度的封装方式[14]是 LBIST 架构面向日益复杂的具体应用而衍生出的新的研究课题。
2.2 国内研究进展
LBIST 的国内相关研究团队主要有中国科学院计算技术研究所李晓维及李华伟研究员、合肥工业大学的梁华国教授、清华大学软件学院的向东教授等。
李晓维研究员团队在确定性自测试电路结构设计方面作出了一些贡献[15-16],梁华国教授团队则在随机自测试与确定性自测试结合方面有一些研究成果[17-18],向东教授团队在内建自测试的测试码产生[19]、扫描链结构优化设计[20]、测试压缩[21]等方面均有比较好的研究成果产出。
与国外团队的研究成果相比,国内研究成果的差距主要体现在:(1)国外研究成果涉及LBIST 架构的各个模块,其理论体系更为完整、成果数量更多、成果形式更为丰富,国内研究成果稍显零散;(2)大部分里程碑式的原创研究成果均出自国外研究团队,国内团队的研究成果多是对已发表方法或思想的改进和扩展;(3)国外研究成果很多是基于项目或工程应用中的实际电路开展的实验,提出方法的工程可实现性一般比较高,而国内研究大部分是基于典型测试电路开展,实验效果的说服力会打一些折扣。
3 逻辑内建自测试技术剖析
3.1 基本原理
经典的 LBIST 架构——STUMPS 架构如图1所示,包含一个伪随机测试样例产生器(pseudorandom pattern generator,PRPG)、一个线性移相器、一个线性相位压缩器和一个 MISR。

图1 经典的 STUMPS 架构Fig.1 Classic STUMPS architecture
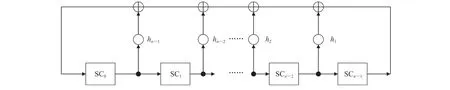
图2 标准 n 阶(外部异或)LFSRFig.2 Standard n-th order (external XOR) LFSR

图3 标准 n 阶(内部异或)LFSRFig.3 Standard n-th order (internal XOR) LFSR

图4 n 阶多输入特征寄存器Fig.4 n-th order multi input signature register
伪随机测试样例产生器常常由 LFSR 自动产生伪随机测试向量,通过线性移相器的异或网络产生相邻相关性更小,且数量更加庞大的测试样例,扫描链从线性移相器并行加载测试样例,然后系统时钟驱动完成测试捕获,测试响应在线性相位压缩器完成压缩,最后移出到多输入特征寄存器,形成最终用于正确性比对的签名(signature)。测试响应被移出的同时,新的测试样例被扫描移入,无缝衔接进入下一组测试。
对于包含扫描链的设计来说,可以基于这种扫描架构进行内建自测试(built-in self-test,BIST)电路设计,由此产生的 BIST 架构通常称为Test-Per-Scan BIST 测试系统[22]。如图1 所示,STUMPS 架构属于 Test-Per-Scan 架构。这种架构对每个测试向量执行与扫描链长度相同的移位时钟周期数(扫描链所有扫描单元均被填充)后被应用到电路(执行一次捕获),下一个测试向量在再次执行相同移位周期的同时,当前测试向量的测试响应也移位到电路输出[23],然后,MISR 被使能进行响应压缩生成测试响应特征,该特征再与无故障电路的响应特征进行比较,以得出电路是否存在故障的结论。这种架构的缺点是需要外部TPG 和 MISR 的操作。
3.2 时序控制
LBIST 除了可将大部分测试功能转移到待测电路上,从而降低测试开销外,其价值还在于可以为高速、高性能电路提供全速测试。使用 LBIST 最关键也最困难的部分是如何使用适当的捕获时钟方案有效地测试时钟域内故障和时钟域间故障。有 3 种基本的捕获时钟方案可用于测试多个时钟域电路,分别为单次捕获、偏斜导入、双捕获。其中,单次捕获包括独热的和交错的两种,如图5~6 所示;偏斜导入包括独热的、捕获对齐的、启动对齐的和交错的 4 种,如图7~10 所示;双捕获也包括独热的、捕获对齐的、启动对齐的和交错的 4 种,如图11~14所示[24]。

图5 独热的单次捕获时序图Fig.5 One-hot single-capture timing diagram
在图5~6 中,单次捕获用于慢速测试,各时钟域共用全局扫描使能信号(global scan enable,GSE),可以测试时钟域内和跨时钟域的结构型故障。如图5 所示,独热的单次捕获在一个捕获窗口内仅有一个时钟域的电路被使能,这种方法的主要优点是,设计者在自测试期间不必担心两个时钟域之间的时钟偏移,因为每个时钟域都是独立测试的。如图6 所示,交错的单次捕获允许在同一捕获窗口内不同时钟域电路依次被使能,这样可以显著简化具有多个时钟域的设计的物理实现,但如果捕获时钟的有序序列对于所有捕获周期而言都是固定的,则时钟域之间可能存在一些结构故障的覆盖率损失。

图6 交错的单次捕获时序图Fig.6 Staggered single-capture timing diagram
图7~10 中的偏斜导入是一种全速延迟测试技术,以工作频率运行测试时钟,最后一个移位脉冲后紧接着一个捕获脉冲,来启动转换并捕获输出响应。各时钟域分别享有独立的扫描使能信号(scan enable,SE)。如图7 所示,独热的偏斜导入每个扫描使能信号(SE1 或 SE2)必须在一个时钟周期内完成移位到捕获的操作切换(d1 或d2),并且只能完成时钟域内,而不能完成跨时钟域的延迟故障检测。如图8~9 所示,捕获对齐或启动对齐的偏斜导入可以弥补上述不足,通过引入共同的参考时钟完成时钟对齐可以实现跨时钟域故障检测,但需要额外的时钟抑制电路来产生不使能时钟脉冲(图中虚线)。如图10 所示,交错的偏斜导入不需要时钟精确对齐,可以在一定程度上降低物理实现的难度,但每个时钟域均需要一个全速的扫描使能信号。

图7 独热的偏斜导入时序图Fig.7 One-hot skewed-load timing diagram
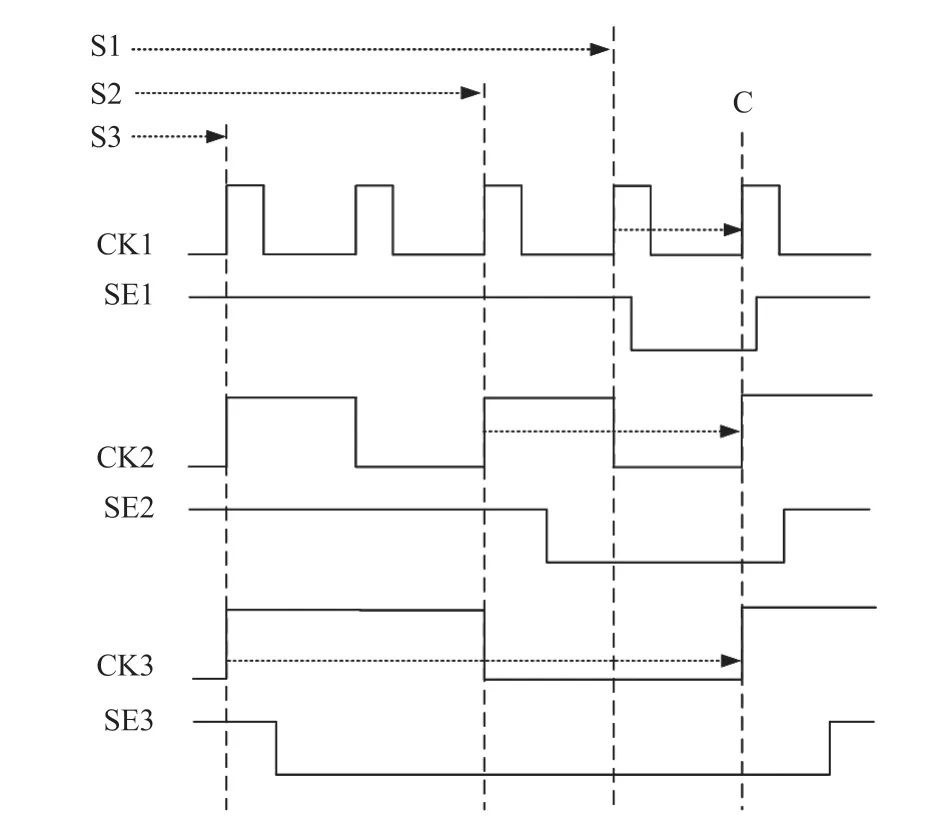
图8 捕获对齐的偏斜导入时序图Fig.8 Capture aligned skewed-load timing diagram

图9 启动对齐的偏斜导入时序图Fig.9 Launch aligned skewed-load timing diagram

图10 交错的偏斜导入时序图Fig.10 Staggered skewed-load timing diagram
如图11~14 所示,双捕获是另一种全速测试技术,使用慢速的全局扫描使能信号(GSE),物理实现难度相对较低。如图11 所示,独热的双捕获各时钟域在 GSE 控制下分别依次完成连续两次捕获。与独热的单次捕获相同,该方法不能检测跨时钟域故障。如图12~13 所示,捕获对齐或启动对齐的双捕获可以实现跨时钟域延迟故障检测。如图14 所示,交错的双捕获容易与扫描或自动测试码产生工具结合使用,以提高故障覆盖率。

图11 独热的双捕获时序图Fig.11 One-hot double-capture timing diagram
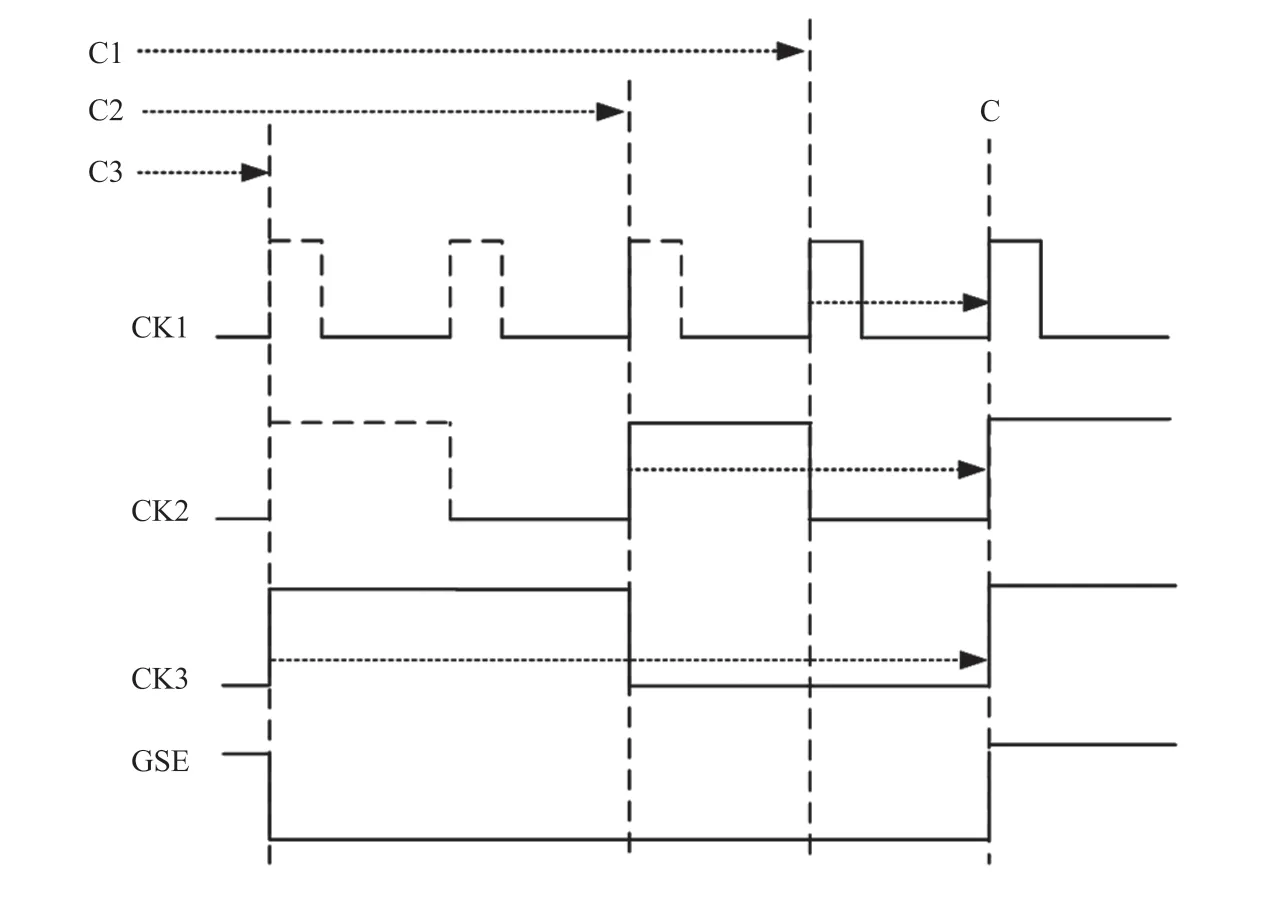
图12 捕获对齐的双捕获时序图Fig.12 Capture aligned double-capture timing diagram

图13 启动对齐的双捕获时序图Fig.13 Launch aligned double-capture timing diagram
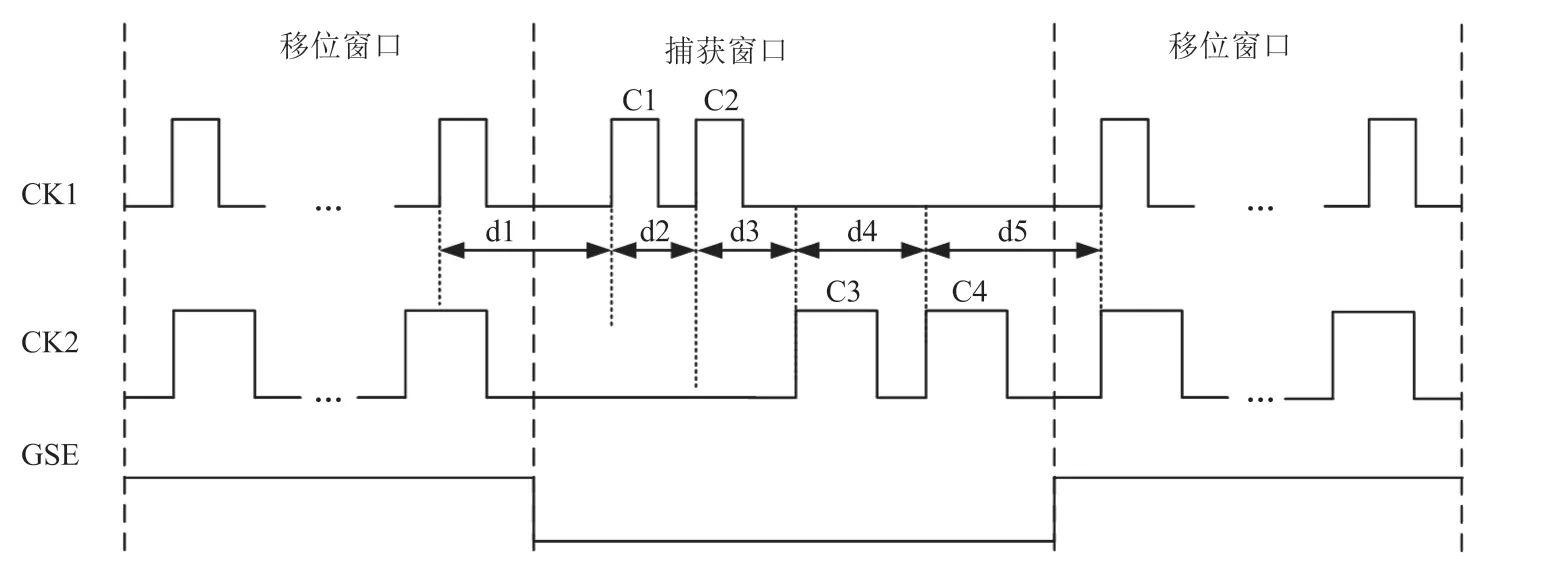
图14 交错的双捕获时序图Fig.14 Staggered double-capture timing diagram
3.3 确定性自测试
经典的内嵌确定性自测试架构如图15 所示[25],在片上嵌入解压器和压缩器,以减少自动测试设备上存储的测试激励和测试响应的存储空间需求。

图15 内嵌确定性自测试架构Fig.15 Embedded deterministic self testing architecture
图1 所示的经典 STUMPS 架构中采用随机产生的测试向量,其测试的故障覆盖率往往难以得到保证。为提高故障覆盖率,可结合使用确定性自测试。确定性自测试可针对随机自测试阶段后剩余的难测故障生成确定性测试向量。在完成随机自测试后,接着进行确定性自测试,以提高故障覆盖率。
结合随机自测试和确定性自测试的方式有多种,主要包括测试点插入、ROM 压缩存储、LFSR 重播种等。
测试点插入技术对功能电路进行改造,在合适的位置使用多路选择器(MUX)或者使用与、或等基本逻辑门实现电路功能切换和确定性测试向量注入,如图16~17 所示,可插入控制点或观测点。该技术的主要问题是需要增加额外的硬件开销,插入的测试点数量受限。Sun 等[26]介绍了测试点插入方法的历史,包括用于增加故障覆盖率、压缩测试样例、检测路径延迟故障和降低测试功率的测试点插入。测试性能、功耗和面积(PPA)是测试点插入技术的 3 项核心评价指标。共享插入测试点可以实现在尽量不降低测试性能的前提下降低测试功耗和面积开销。Foutz 等[27]提出了一种结合物理实现工具进行大量测试点共享时减少布线冲突的方法。Shi 等[28]利用深度学习的方法,训练了一种新的深度加强学习模型,并将其实例化为图神经网络和深度 Q 学习网络的组合,以最大限度地提高测试覆盖率。该方法是人工智能技术应用于大规模集成电路测试的积极探索和实践。
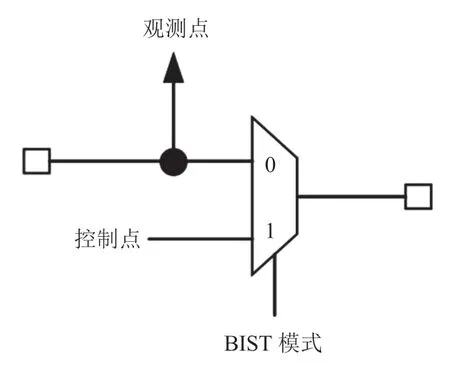
图16 使用多路选择器的测试点插入Fig.16 Test point insertion using a multiplexer

图17 使用与-或门的测试点插入Fig.17 Test point insertion using and-or gates
ROM 压缩存储的方式是将产生的确定性测试向量存储到片上的只读存储器(ROM)中,在确定性自测试阶段读出,并对功能电路进行激励测试。ROM 压缩存储的问题是无法满足大数据量存储。近期,许多减少确定性测试向量存储空间的方法被提出来。Kaczmarek 等[29]提出了一种用于汽车集成电路的基于扫描的混合逻辑BIST 的低成本测试模式生成方案,采用两种技术来尽可能复用种子,降低种子对存储空间的要求。一种是采用种子翻转 PRPG,以树遍历方式周期性地对 PRPG 各阶进行取反。另一种是基于种子排序方法,允许在测试数据量和测试覆盖率之间进行额外的权衡。Sharma 等[30]提出了一种用于测试样例压缩的人工智能方法,该方法不增加存储器开销,且仅需最小的额外硬件(仅包括组合逻辑)。Pomeranz[31]描述了一种用于导出芯片上存储器的测试数据条目的缩减集合的软件过程,该过程包含测试向量位翻转和测试集划分。通过压缩测试集降低存储需求的同时,利用软件过程进一步降低存储需求。Pomeranz[32]描述了一种基于存储的 LBIST 方法,其中,存储的测试数据具有可变长度。该方法不是直接存储扫描向量,而是存储一个序列,使用比扫描矢量短的可变长度序列减少了存储需求。Gopalsamy 等[33]提出了一种减少存储的确定性测试数据的 LBIST 方法,该方法将以下两种类型的测试数据存储在芯片上:从确定性测试的缩减集合获得的扫描向量的一个子集;用于指示如何组合扫描向量的扫描向量排列的索引集合。ROM 压缩存储的这些方法均可以有效降低测试向量的存储空间需求,但是需要考虑对故障覆盖率造成的影响。
LFSR 重播种技术利用 LFSR 的结构特性对确定性测试向量进行编码(解线性方程组),片上存储器仅须保存测试向量解码所需的“种子”,降低对片上存储空间的需求。同时,为进一步提高 LFSR 的编码能力,可将其配置为不同本原多项式,以实现存储相同数量的“种子”的同时得到更多确定性测试向量的效果,如图18 所示。Saleem 等[34]提出了一种可编程和可参数化的 LFSR,可以根据应用选择生成任意范围的矢量位。此外,反馈多项式可以被参数化,以生成不同长度的序列和不同的结构模型。Vikranth等[35]提出的 LFSR 模式生成器可以根据控制信号同时采用外部和内部 LFSR 工作,该设计实现了阶数在 3~11 之间的本原多项式。这些方法可以进一步提高 LFSR 重播种技术的编码能力或故障覆盖率。
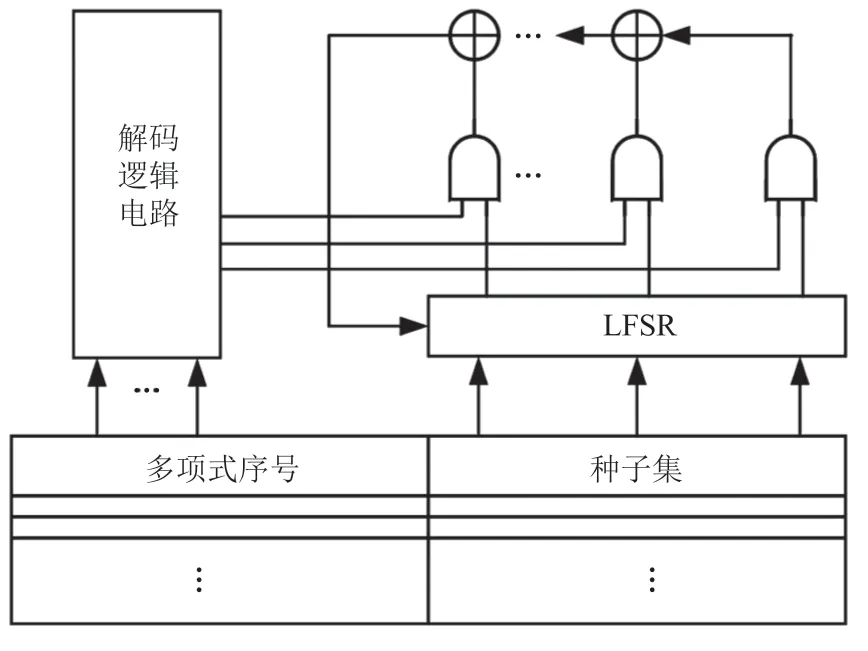
图18 使用多项式集的重播种电路Fig.18 Reseeding circuit using polynomial sets
3.4 低功耗逻辑内建自测试
LFSR 生成的随机性降低了连续伪随机测试向量之间及每个测试向量的相关性,这极可能导致相邻测试向量之间更多的比特位跳变,使得芯片在测试模式下的功耗会远远超过正常功能模式下的功耗。大功耗产生的热剩余不能在短时间内散出去,将形成局部的热效应,可能影响待测芯片的使用寿命,甚至直接造成芯片烧毁。因此,降低测试应用过程中的功耗成为 LBIST 电路设计的一个重要目标[36]。
低功耗 LBIST 主要有优化测试码产生和测试链路加权选通两种设计思路。如图19 所示,Puczko[37]改进了一种 LFSR 设计,通过在一个时钟周期内产生 q 个新的测试位来降低功耗。如图20 所示,Moryani 等[38]改进设计了一种带控制门控逻辑时钟的 LFSR,可以产生这样一组测试向量集——集合内两个连续测试向量的汉明距离均为 1,可减少测试向量比特位跳变。如图21 所示,Xiang 等[39-40]设计了带加权选通信号的低功耗 LBIST 架构,扫描单元以扫描森林的结构组织起来,同时为每条扫描链关联一个随机选通信号,某一时刻仅有一条扫描链被激活而允许移入测试向量,k条扫描链在k个不同的时刻依次选通,可以大大降低电路测试模式下的功率密度。

图19 改进 LFSR 低功耗设计Fig.19 Improved low power design of LFSR
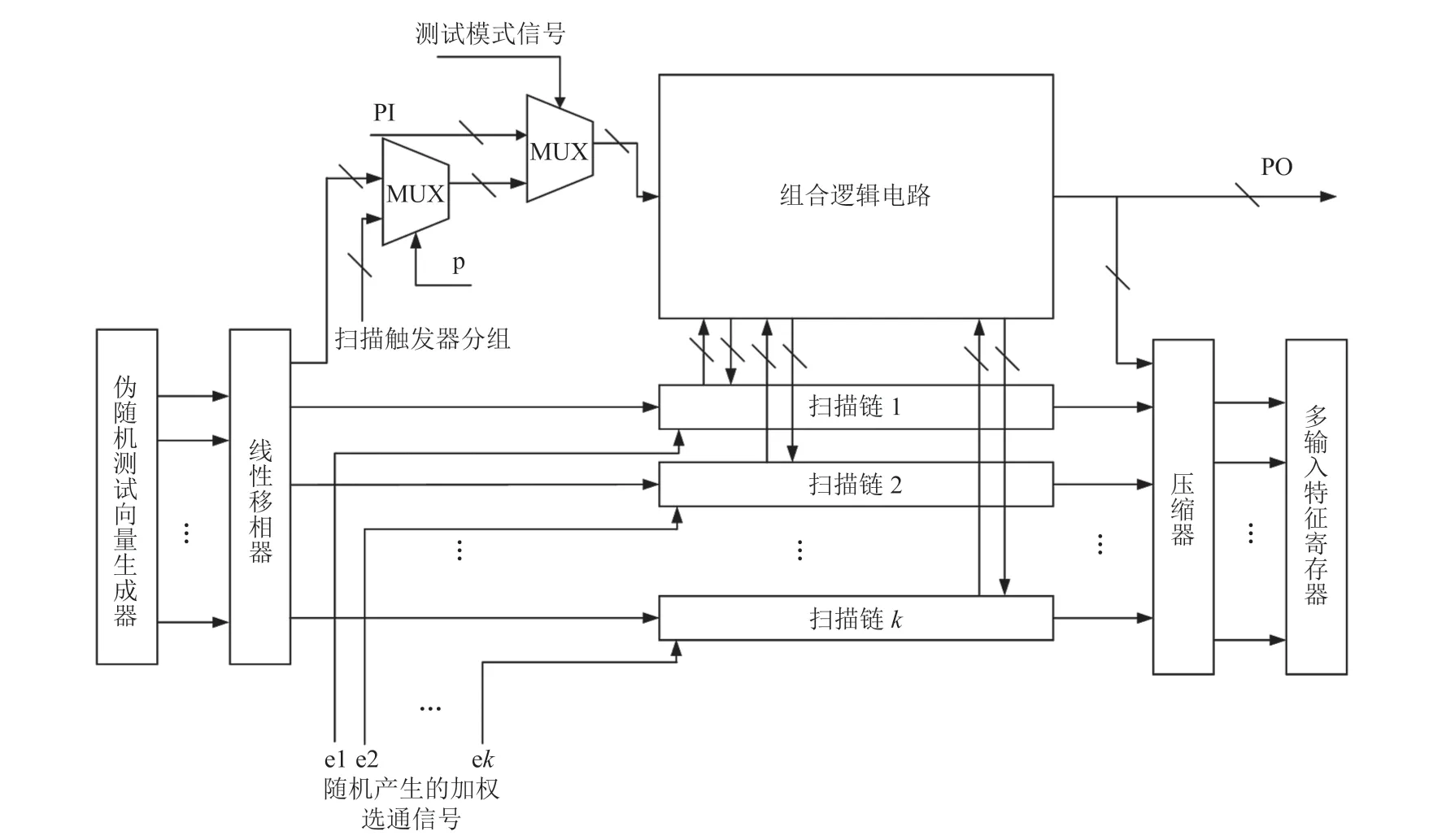
图21 带加权选通信号的低功耗 LBIST 架构Fig.21 Low power LBIST architecture with weighted gating signal
3.5 逻辑内建自测试的“X”容忍
输出响应中有许多未知值的来源,如未初始化的存储器、模拟块、三态门、假路径、多循环路径等。扫描输出的“X”值会降低故障覆盖率,特别是 LBIST 中的扫描输出,还会在压缩后进入MISR,对输出响应压缩提出了更大挑战[41]。
Wohl 等[42]提出了一种“X”容忍 LBIST 解决方案(XLBIST),该解决方案使用压缩器/解压缩器结构,包括“X”控制逻辑,这些结构已经插入到扫描压缩确定性样例的设计中。ATPG 利用这些结构来生成高效的 XLBIST 样例。ATPG可以为任何数量(或密度)的“X”生成样例,并权衡由此产生的测试覆盖率。XLBIST 架构如图22 所示。将确定 PRPG 和“X”容忍 PRPG 分割开来。这对于分离相邻模式的加载和卸载而言,是必要的。因为只有设置加载确定位和计算非确定位,并且模拟设计之后,在 ATPG 过程中才知道“X”值。此时,如果相同的 PRPG 用于加载和卸载位,则冲突可能会限制可用的确定位,甚至导致不可满足的条件。
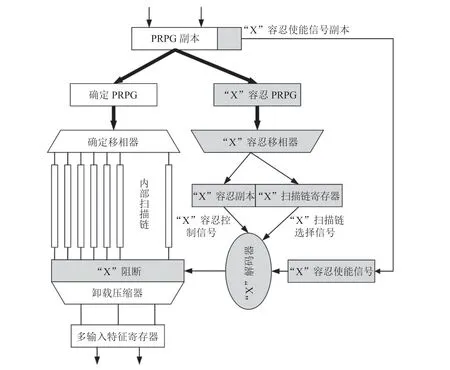
图22 XLBIST 架构Fig.22 XLBIST architecture
Liu 等[43]介绍了一种“X”容忍可调压缩器maXpress,其架构如图23 所示。maXpress 架构部署了一种新的扫描链选择机制,能够根据许多系统内或单向流测试应用程序的要求,在可重新确定的扫描链组和指定的扫描移位周期内完全屏蔽“X”状态。Liu 等[43]所提出的方案还支持单独的观察扫描链,与传统扫描设计中多个移位周期进行一次捕获不同,该扫描链在每个移位周期均捕获错误输出,同时其内容逐渐移位到与其余链共享的压缩器中。除了一种新的布局友好的架构外,作者还提出了基于扫描链选择规则的算法自动化 maXpress 控制设置,以抑制“X”状态。
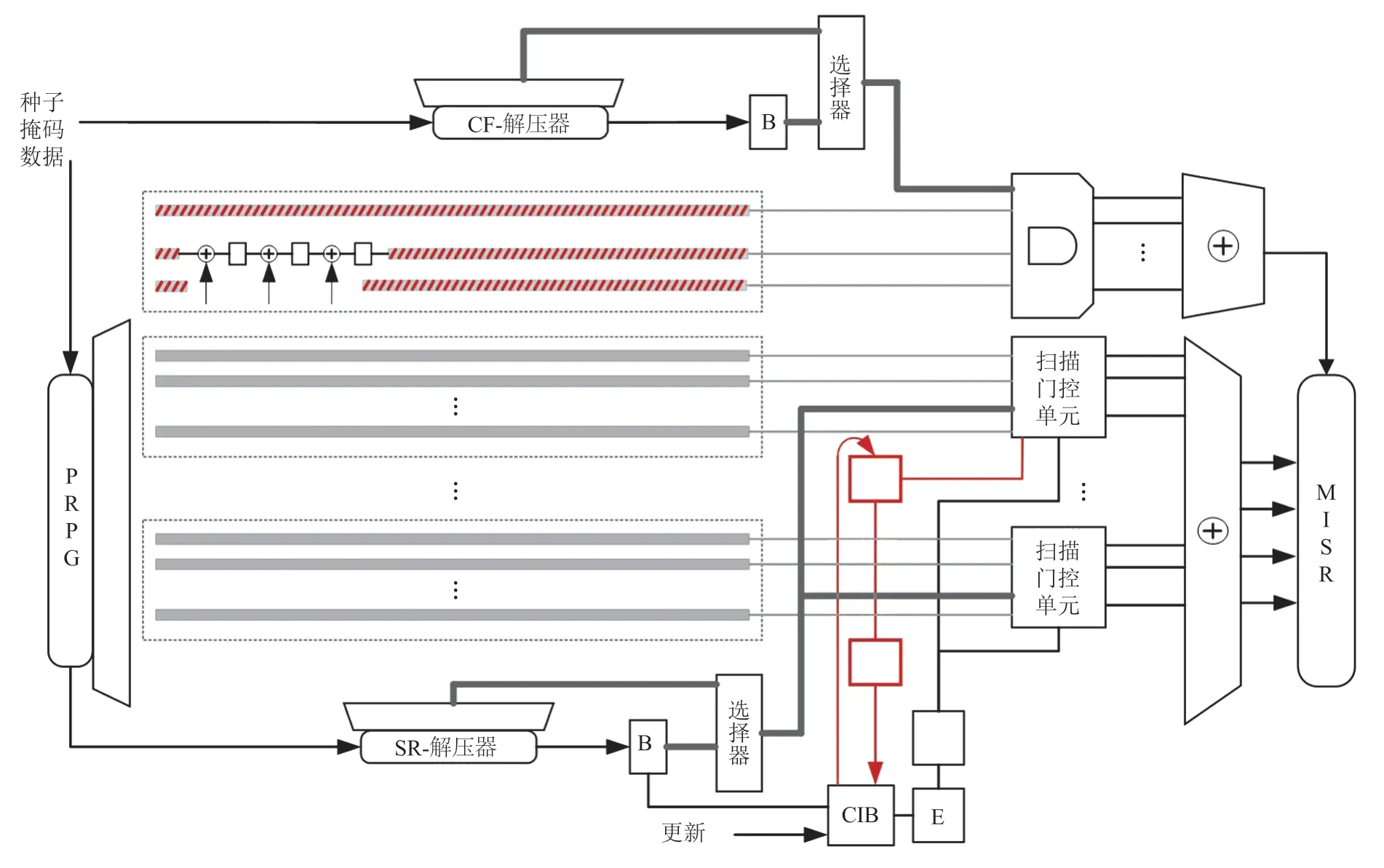
图23 maXpress 架构Fig.23 maXpress architecture
总之,“X”容忍并不像业界认为的那样难以驾驭,可以采用类似上述一些便捷的结构或策略予以实现。
4 商用逻辑内建自测试工具
主流的商用 LBIST 工具提供商主要是Siemens EDA 和 Synopsys 两家,占据了全球大部分的 EDA 市场份额。
4.1 Mentor 工具
Tessent LogicBIST 是 Mentor 推出的内建自测试解决方案,用于测试集成电路的数字逻辑模块。它是安全关键设备(如用于汽车和医疗应用的集成电路)的理想测试解决方案。Tessent LogicBIST 试图将每一个测试环节中最先进的解决方案结合在一个完整的测试流程中,以确保总的故障覆盖率。其自测试架构如图24 所示,主要特性包括以下几个方面:

图24 Tessent LogicBIST 自测试架构Fig.24 Tessen LogicBIST self test architecture
(1)对安全性能要求严苛的关键应用的完整系统内测试,包括上电、定期功能模式测试、电源感知测试和诊断;
(2)与 Tessent MissionMode、IEEE 1687 IJTAG 和第三方系统测试接口完全集成;
(3)支持平顶自上而下或分层自底向上的测试集成流;
(4)混合 TK(TestKompress)/LBIST 片上逻辑单元提供了系统内和生产制造环节测试功能,可减少整体面积开销;
(5)支持在运行时选择应用随机测试样例或压缩测试样例;
(6)单一综合自动化流程,可快速集成所有综合测试功能。
Tessent LogicBIST 采用先进技术,可提高LBIST 的测试覆盖率,并显著减少测试样例数量,是目前可用的最高效的系统内测试解决方案。主要的技术特点如下。
a.VersaPoint 测试点技术
Tessent VersaPointTM 测试专为混合 TK/LBIST 应用而设计,同时改进了 ATPG 测试码数量和 LBIST 的可测试性。与传统 LBIST 测试点相比,VersaPoint 测试点将 LBIST 覆盖率提高了 2%~4%,此外,与单独使用 TestKompress 相比,ATPG 向量数有较大幅度降低。
b.观测扫描技术
观测扫描技术在捕获周期中、每个移位周期中均观测电路数据,显著减少了达到目标逻辑BIST 的测试覆盖率所需的向量数。该技术是可选的,可对 VersaPoint 测试点技术起到很好的补充作用。
在系统级,可以通过片上任务模式控制器和标准 IEEE 1687 IJTAG 网络或任何第三方系统测试接口访问逻辑 BIST 控制器和其他测试资源。Tessent 任务模式可以在 CPU 或直接内存访问(DMA)模式下运行,这使得嵌入式测试功能更容易被访问,以便在功能运行期间测试和诊断设备。在许多安全关键应用中,设备在现场定期测试自身的能力是必要的,并且是满足 ISO 26262《道路车辆功能安全》(以下简称“ISO 26262”)标准中规定的可靠性要求的关键。Tessent LogicBIST 提供满足 ISO 26262 标准严格要求的特定能力,包括上电和定期测试,以及低功耗测试。
4.2 Synopsys 工具
DFTMAX LogicBIST 是 Synopsys 公司推出的LBIST 工具,该工具是面向自动驾驶、医疗和航空航天等应用的数字集成电路系统内自测试的综合解决方案,且遵循 ISO 26262 等自动驾驶半导体产业安全标准。该解决方案的主要特性包括:
(1)BIST 控制器的面积开销很小;
(2)可重用已经实现用于生成测试的扫描链和测试向量的控制逻辑;
(3)LogicBIST 模式的管脚需求很低;
(4)简单的功能逻辑接口;
(5)种子和预期的签名可以固定编码或者可编程;
(6)面向单固定型故障或转换延迟故障;
(7)简单的 one-pass DFT 插入流程。
DFTMAX LogicBIST 架构如图25 所示,主要由四部分组成:LogicBIST 控制器、LogicBIST压缩器、LogicBIST 解压器和 LogicBIST 时钟控制器。

图25 DFTMAX LogicBIST 架构Fig.25 DFTMAX LogicBIST architecture
DFTMAX LogicBIST 流程如图26 所示,概括如下:

图26 DFTMAX LogicBIST 处理流程Fig.26 DFTMAX LogicBIST processing flow
(1)在设计中插入 LogicBIST DFT 逻辑,在初始的网表文件中传送的种子和签名与逻辑 0绑定;
(2)使用 TetraMAX ATPG 对设计生成自测试样例,TetraMAX ATPG 为设计选择一个种子值,然后计算对这个种子值所期望的签名;
(3)使用 TetraMAX ATPG 计算出来的传送的种子、签名和样例数量值修改网表文件中的对应值;
(4)在类似 VCS 的 Verilog 仿真器中仿真得到的网表文件,以验证自动化的 BIST 操作的正确性。
4.3 工具对比
Tessent LogicBIST 与 DFTMAX LogicBIST都是商业界相当成功的软件工具,均有各自在产品特性上的独到之处。其优缺点对比如下:
(1)Tessent 提供成熟的 TK(TestKompress)/LBIST 混合解决方案,可同时保证足够高的故障覆盖率和足够小的测试数据存储空间要求;
(2)Tessent 向用户开放一系列底层控制和调试命令,用户可以根据自身需求更加灵活地配置软件参数;
(3)DFTMAX LogicBIST 与其他 DFTMAX流程基本一致,用户可以保持一样的软件操作习惯;
(4)与 Tessent LogicBIST 相比,DFTMAX LogicBIST 的使用成本略低。
5 逻辑内建自测试技术展望
STUMPS 架构自 1982 年被提出后,因为易于集成实现而迅速被业界接受和采纳,成为最成功的 LBIST 架构。但是,经典的 STUMPS 架构在实际应用中还存在故障覆盖率不够高、测试向量存储空间需求大、测试功耗大、未知值影响测试响应压缩、不可忽视的额外的面积开销等问题,大量学者针对这些问题对 STUMPS 架构进行了改进设计。
凭借其在测试成本和测试性能方面的独特优势,LBIST 仍是学术研究和商业应用的热点技术。预测未来的 LBIST 技术将向以下几个方面进一步发展。
(1)适应更复杂的功能电路结构。当今,超大规模的 IC 设计往往具有部分或全部片上系统设计的特征,甚至包括一些设计重用的宏模块和嵌入式的处理器内核,涉及多核、多时钟域等复杂电路结构。为满足人们日益增长的需求,更加复杂多样的电路结构也将层出不穷,而 LBIST 技术也将随之不断更新换代。
(2)实现更智能的自测试解决方案。目前,自测试和可测试性设计的各环节设计流程和软件工具相对独立,设计实现的效果仍然很大程度上取决于设计人员的经验和智慧。可以利用深度学习等臻于成熟的人工智能技术简化和改进设计流程,减少人工参与,以实现综合考虑各关键特性的最优方案,提高大规模集成电路测试的自动化和智能化水平。
(3)适应更高频的测试时钟。在线全速测试是 LBIST 的一大技术优势,可以在很大程度上减少测试时间,也使得一些如小延迟故障等复杂故障模型变得方便可测。功能电路的时钟频率持续增大,LBIST 的测试时钟也需要不断与功能电路的工作时钟相匹配,同时,更高的测试时钟频率也会给 LBIST 设计带来更多的挑战。
(4)适应更多样的故障模型。芯片集成度越来越高,特征尺寸越来越小,生产加工工艺也日新月异,芯片可能出现的功能故障和性能缺陷也将越来越多样化,如何精准地测试和诊断各种故障模型是 LBIST 技术面临的又一大挑战。
(5)达到更低廉的设计及实现成本。LBIST的面积开销和硬件实现难度是其设计实现过程中无法避免的问题,以更小的代价达到相同的测试效果对 LBIST 产业应用具有很大的现实意义,也是未来 LBIST 技术发展和突破的关键着力点。
6 总 结
现场 LBIST 测试对于军事、医疗和汽车等关键应用场景中的设备而言是必须的。上述场景中需要达到的测试目标也是非常严格的,即在最短的测试时间内实现最大的故障覆盖率。LBIST的故障检测能力决定了测试质量和测试耗时,并且取决于测试时序、PRPG 种子选择和添加的插入点数量等因素。为了获得最大的故障覆盖率,LBIST 需要针对具体应用和设计进行具体的分析和优化。可以预期,未来,LBIST 仍是大规模集成电路测试领域的一大研究热点。
