面向中文法律裁判文书的抽取式摘要算法
2024-01-26温嘉宝
温嘉宝 杨 敏
1(中国科学院深圳先进技术研究院 深圳 518055)2(中国科学院大学 北京 100049)
1 引 言
随着人民群众法律意识的提高和案件数量增长速度的加快,截至 2023 年 1 月,中国裁判文书网已公布超过 1.3 亿份的裁判文书,并以每日数千份的速度继续增加。这些文书包括民事、刑事、行政、赔偿、执行等多种类型,经过筛选和专业处理后被公布,形成了法律领域中数据量最大的数据库,为司法智能化、信息化提供了强有力的数据基础。优质裁判文书的不断增加对司法领域的发展具有重要意义,如可以为法律从业者提供更多的案例参考,缓解“同案不同判”的困境。然而,这也带来了一些新的问题。
裁判文书是法律从业者日常工作中接触的重要资料之一,包括进行类案检索和撰写类案检索报告。随着裁判文书数据量的增加,法律从业者需要从检索出的大量裁判文书中挑选出最合适的裁判文书。然而,裁判文书通常较长,平均长度可达数千字,甚至有少数文件长达上万字,从中查找出关键信息并进行分析无疑变得越来越困难。因此,对裁判文书进行自动摘要,以去除冗余信息、精简文本内容,能极大程度地减少法律从业者的工作量,使得他们有更多的精力从事更有价值的工作,从而提升司法行业的效率。由此可见,裁判文书自动摘要对司法领域有着重要研究价值和现实意义。
根据摘要方式,自动摘要模型可分为抽取式模型和生成式模型,本文提出的方法属于抽取式模型。抽取式模型通过从原文中直接选择若干个重要句子进行排列重组,以形成摘要。根据学习方式的不同,抽取式摘要算法可进一步划分为无监督式抽取和有监督式抽取。无监督抽取式文本摘要方法因运行速度快,且无须人工标注训练数据而广受应用。相比之下,有监督抽取式文本摘要方法的优势在于其具有更高的准确性。
2 抽取式摘要研究现状
抽取式摘要是一种直接从原文中抽取关键句的方式,这种方式在句法上错误率低。从学习方式上,抽取式摘要算法可以分为无监督和有监督两大类。无监督抽取式摘要通常采用图、聚类等方式。而有监督抽取式摘要多采用基于神经网络的方法。
2.1 无监督抽取式摘要算法
无监督抽取式摘要最简单的实现方式是“Lead-3”法,即从文本前 3 个句子中提取信息,并作为摘要。由于作者通常在文章的标题和开头部分阐述文章的主题(如新闻报道),因此,这种方式在该类文本中较为有效。然而,法律裁判文书的关键信息分布较为均匀,因此,采用 Lead-3法进行法律裁判文书的摘要不能达到理想效果。
2004 年,Erkan 等[1]提出的 LexRank 是一种基于图排序的抽取式摘要算法,其以句子为节点,以句子间相似度为边的权值,构建无向有权图。该算法采用词袋模型表示句子向量,维度是目标语言中单词的数量。对于出现在句子中的每个单词来说,句子向量中相应维数的值是该单词的 TF-IDF[2]值。通过计算句子向量与图中质心之间的相似度,判断句子是否为重要句子。其中,两个句子之间的相似性由向量间的余弦相似度定义,而质心是由文档中 TF-IDF 值超过某一阈值的词构成的向量。该算法具有简单和易于实现的优点。然而,它在表示句子向量的方式上存在一定的缺陷。其一,维度较大,导致生成的句子向量非常稀疏。其二,句子向量中相应维数的值是该单词的 TF-IDF 值。由于 TF-IDF 基于词频统计,无法考虑语义信息,因此,LexRank 在判断句子相似性时无法充分考虑语义层面的相似度。
2004 年,Mihalcea 等[3]提出的 TextRank 算法是一种基于图的排序算法,其设计灵感源自于 PageRank[4]网络排序算法。该算法将文档表示为图模型,将文档中的每个句子作为图中的一个节点,节点之间的连边表示句子之间的相关性。然后,通过 PageRank 算法计算每个节点的TextRank 值,以确定文档中最重要的句子,并选择其中得分最高的几个句子作为摘要。然而,TextRank 的句子相似度衡量方式采用了两个句子之间的共现词数量,即采用了词袋模型,无法考虑同义词、词序等其他信息。这使得 TextRank算法的表现会受到一定的限制。
2016 年,Padmakumar 等[5]提出了一种基于聚类的抽取算法。首先,利用 Skip Thought Vectors 进行无监督学习,得到句子的嵌入向量。然后,通过聚类算法对生成的句子嵌入向量进行聚类。最后,将距离簇质心最近的向量所对应的句子作为文本摘要。Skip Thought Vectors 的思想是通过一个句子预测它上下文的句子,具体做法是通过 LSTM[6]编码器将中间句子编码为向量,再用两个独立的 LSTM 解码器将句子向量解码出前后句子。这种方式与 2013 年 Mikolov 等[7]提出的 Word2Vec 中的 Skip-gram 训练策略相似,依据的原则是一个句子与其前后相邻句子之间存在语义联系。在该论文中,Padmakumar 等[5]尝试了 K-means 和 Mean-shift 两种聚类方法。然而,该算法的不足之处在于 LSTM 无法实现并行训练,以及在处理长序列时可能面临梯度消失和梯度爆炸的风险。
2021 年,Padmakumar 等[8]提出了一种基于点互信息的摘要算法。该算法利用 GPT-2[9]计算给定两个句子之间的点互信息,而点互信息定义为在给定前句的情况下,得到后句的概率。通过对摘要与原文档中所有句子对的点互信息进行求和,可以得到摘要与原文档的相关性。同时,通过对摘要内部所有句子对的点互信息进行求和,可以确定摘要的冗余性。最终,摘要由一个句子集合组成,该集合能最大化相关性减去冗余性的值。该算法的优点在于利用预训练语言模型计算句子间的点互信息,从而实现无监督抽取式摘要。然而,缺点在于其时间复杂度较高,需要计算所有句子之间的点互信息。当文档句子数量较大时,推理时间将会较长。
2.2 有监督抽取式摘要算法
2017 年,Nallapati 等[10]提出了一种名为SummaRuNNer 的方法,将文本摘要任务转化为序列标注问题。对文本中的每个句子都进行二分类(0 或 1):0 表示不纳入摘要,1 表示纳入摘要。最终的文本摘要由标记为 1 的句子组成。该模型包含两个双向门控循环单元[11]:第一个双向门控循环单元对句子进行词级建模,以获得词级表示,接着,对句子中各词的词级表示求平均,得到句子嵌入;第二个双向门控循环单元则对句子嵌入进行句级建模,以获取句级表示。最后,通过一个分类器对句级表示进行二分类,得到最终的摘要结果。该模型的优点在于,它不仅双向考虑了句子的局部和全局信息,还充分考虑了句子与文档的关系、句子与前后句子的关系、绝对位置和相对位置等因素。然而,该模型的缺陷在于采用循环神经网络(recurrent neural network,RNN)进行特征提取,导致无法进行并行训练。此外,在处理长序列时,模型可能会面临梯度消失和梯度爆炸的风险。
2017 年,Isonuma 等[12]将文本分类任务与摘要任务相结合,以提升摘要效果。该方法首先采用卷积神经网络对句子进行编码,获取句子向量;然后使用基于 RNN 的编码器-解码器框架为每个句子生成摘要概率。具体而言,在编码器中,为每个句子生成隐藏状态;在解码器中,利用前一个句子的摘要概率、句子向量和隐藏状态生成当前句子的隐藏状态,并根据该隐藏状态计算当前句子的摘要概率。接着,以摘要概率为权重,对句子向量进行加权平均,得到文本向量。最后,利用文本向量预测文本的类别。Isonuma等[12]认为,文本的类别可以被视为文本的粗糙摘要。若模型能根据文本向量准确预测文本类别,则说明模型具有抽取关键信息的能力。因此,可以将摘要概率较高的句子作为文本的摘要。该方法的优点在于利用文本分类任务增强模型的摘要能力。然而,该方法也存在一些缺点:(1)卷积神经网络主要通过局部卷积操作捕捉文本中的局部特征,对长距离依赖关系的捕捉能力较弱;(2)卷积神经网络的卷积操作对输入的顺序不敏感,在捕捉文本中的词序信息方面存在局限;(3)基于 RNN 的编码器-解码器架构无法并行计算,且存在梯度消失和梯度爆炸的风险;(4)计算过程为单向操作,在计算当前句子摘要概率时,无法考虑后续句子的信息。
2019 年,Liu[13]首次将 BERT[14]应用于抽取式摘要任务,提出了名为 BERTSUM 的方法。即在每个句子前插入[CLS]词元,句子后添加[SEP]词元,最终将每个[CLS]对应的输出视为每个句子的句子向量。Liu[13]采用了 3 种方式对句子进行分类:(1)连接线性层和 Sigmoid 函数,计算句子的重要性得分;(2)句子向量表示单独接入 Transformer[15]进行分类;(3)将句子向量表示单独接入 LSTM 进行分类。BERTSUM 的优势在于充分利用了预训练语言模型的强大特征提取能力。通过对输入数据进行简单的预处理和微调预训练语言模型,便可完成抽取式摘要任务。此方法具有实现相对简单、训练代价较低等优点。然而,BERTSUM 也存在一定的缺陷,即需要将整篇文本一次性输入到 BERT 中,当文本长度超出模型输入限制时,则难以完成摘要任务。
2020 年,Zhong 等[16]提出了 MatchSum 模型,将摘要任务转化为文本匹配任务。该模型利用预训练语言模型对文本进行编码,通过比较文档上下文表示与真实摘要及候选摘要的上下文表示,计算相似度并更新参数。模型认为目标摘要与原文档之间的相似度应最为接近,因此,当存在比目标摘要更接近原文档的摘要时,计算损失并更新参数。文档的候选集由多个句子的所有组合构成。为防止文档句子过多导致组合爆炸,Zhong 等[16]采用 BERTSUM 进行粗略摘要,将部分不重要的句子剔除。在推理阶段,选择与原文档语义相似度最高的候选摘要作为摘要结果。该算法的优点在于将摘要任务转换为文本匹配任务,仅需将匹配得分最高的候选结果作为摘要答案。然而,该算法也存在一些缺点:(1)使用BERTSUM 进行粗略摘要,在处理长文本时,可能会截断文本,导致信息丢失;(2)不适用于处理句子较多的文本,当文本句子数量较大时,候选摘要集规模也会很大,将增加计算成本。
2022 年,Shi 等[17]提出了一个基于星形架构的抽取式摘要模型 StarSum:首先,通过BERTSUM 生成每个句子的句子表示;其次,将句子表示与位置嵌入相加;再次,输入星形 Transformer 进行文档级编码;最后,利用Sigmoid 函数对最后一层每个句子的输出进行分类,从而得到文本摘要。星形 Transformer 由多个卫星节点和一个星节点组成,构成一个全连接的星形结构。在此结构中,文本序列中第i个句子的特征由第i个卫星节点的状态表示。星形Transformer 包括环连接和基本连接两种连接方式。卫星节点通过类似双向 RNN 的环状连接从其邻居节点收集信息(其中,第一个和最后一个卫星节点相互连接),而星节点则通过基本连接从所有卫星节点获取信息。卫星节点可以通过星节点以两跳的方式实现信息的相互传播。这种架构的优点在于提高了计算效率和处理长期依赖关系的能力。然而,其缺点在于利用 BERTSUM生成句子向量表示,在处理长文本摘要时,BERTSUM 可能会截断文本,从而导致信息丢失。
3 基于 Transformer 编码器的抽取式摘要算法
本文所提抽取式摘要模型由一个基于RoBERTa-Large[18]的句子向量生成模型和一个基于 Transformer 编码器的句分类模型组成,最后接入全连接层进行二分类,得到句子重要性,文本摘要则由重要句子组成,如图1~2 所示。
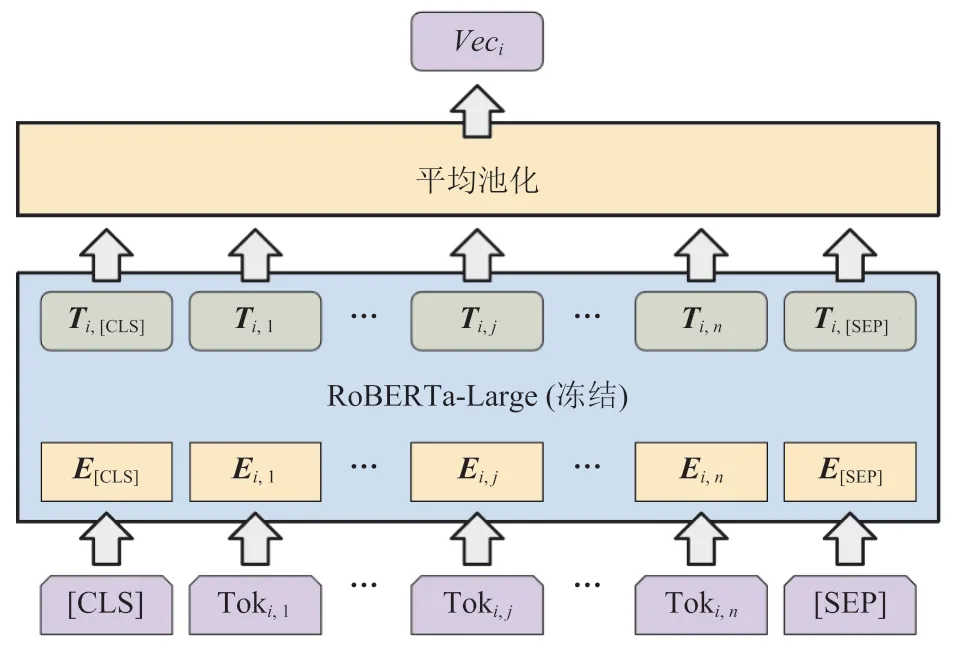
图1 句向量生成模型Fig.1 Sentence vector generative model
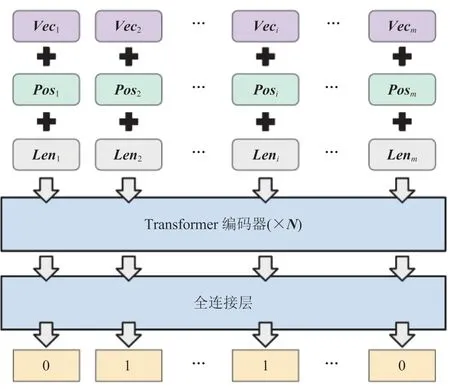
图2 抽取式摘要模型结构Fig.2 Extractive summarization model
3.1 基于预训练语言模型的句子向量生成模型
抽取式摘要实际上可以建模为序列标注任务,核心思想是对文本中每个句子进行二分类,0 表示不重要,1 表示重要,所有标签为 1 的句子组成文本摘要。使用预训练语言模型处理文本分类问题常见的方式是在文本前插入[CLS]词元,并使用该词元所对应的输出进行全连接分类。但裁判文书属于长文本,其长度普遍超过常见预训练语言模型的单次输入长度,如BERT(512 个 token),甚至会超过一些可以处理长文本的预训练语言模型的单次输入最大长度,如 Longformer[19](4 096 个 token),因此无法使用在每个句子前插入[CLS]词元,并以[CLS]词元作为句子分类特征的方式。本文所用方法将抽取式摘要分解为句向量生成模型和句分类模型。
基于预训练语言模型的句向量生成模型单次处理一个句子,将预训练语言模型最后一层的输出进行平均池化,得到句向量,最终裁判文书的表示为 。这种方式可以有效增加模型可处理文本长度,并减少内存需要,但无法对句向量生成模型进行微调。
3.2 基于 Transformer 编码器的句分类模型
第 3.1 小节中用句子向量生成模型对每个句子单独编码,并不包含句子的上下文信息,而抽取式摘要需要考虑到上下文,因此不能直接对所生成的句向量进行分类。
对于一个给定的句子来说,它的输入表示由句子向量、位置嵌入及长度嵌入求和得到。句子向量代表句子所包含的基本语义信息。位置嵌入代表句子在裁判文书中的位置,其中,每个位置对应一个可训练向量。长度嵌入表示当前句子所包含的长度信息,将句子长度按区间划分,每一个长度区间对应同一个可训练向量,计算方式如公式(1)所示。其中, 为句子长度;interval为区间间隔,一般取 5 或 10;idx为区间下标,对应长度嵌入中具体的一个可训练向量。
模型训练过程分为 5 步:(1)将一个裁判文书中每个句子的句子向量、位置嵌入及长度嵌入求和,得到每个句子的输入特征;(2)将裁判文书中所有句子输入特征按顺序拼接输入由 Transformer 编码器组成的文本级编码器中;(3)通过多头自注意力机制,从多维度融合句子上下文信息,生成句子的文本级表示;(4)通过全连接层对句子文本级表示进行二分类,得到句子重要性,0 表示不重要,1 表示重要;(5)计算损失,更新模型。句子输入特征计算过程如公式(2)所示。

4 实验分析与评估
4.1 数据集与评价指标
本文使用 CAIL2020 摘要数据集作为实验数据,该数据集共收录 13 531 份一审民事判决书,涵盖了侵权责任、借款合同、继承合同、劳动合同、租赁合同等多种民事纠纷类别。样本中的裁判文书预先以多个句子划分,每个句子均有是否重要的标签,同时提供与之对应的全文参考摘要。文书字数平均为 2 586 个,其中,最长的一篇达 14 413 个字,所有文本长度超过 512 个字,99.7% 的文书长度超过 1 024 个字,63.4% 的文书长度超过 2 048 个字。平均每个文书包含 57 个句子,最多的一份达 496 个句子。每篇文书平均抽取 12 个句子作为摘要,最多抽取 69 个句子。每个句子平均包含 44 个字,最长的一个句子长达 640 个字。文书摘要字数平均为 791 个字,最长的一个摘要长达 3 790 个字。数据集中共包含782 879 个句子,其中,171 745 个句子为重要句子,611 134 个句子为非重要句子,即正负样本的比例为 1∶3.55。该数据集属于长文本摘要数据集。
数据集格式如表1 所示。其中,id 表示案例唯一标识;summary 字段表示人工总结的与文档对应的全文参考摘要;text 字段是一个列表,按顺序包含案例中每个句子,text 中的一个元素表示文本的一个带标签的句子,带标签的句子中包含 sentence 和 label;sentence 表示句子具体内容;label 表示这个句子是否重要,0 表示不重要,1 表示重要。本文所研究的方法为抽取式摘要算法,只用到 text 字段,summary 字段属于生成式摘要所需标注的数据,对本文所研究方法作用不大,因此舍弃。

表1 司法摘要数据集格式Table 1 Legal summarization dataset format
鉴于将抽取任务转化为对句子的分类任务,将F1作为评估指标,比精确率(Precision)和召回率(Recall)更能准确评价一个模型的好坏。F1指标如公式(10)所示。为了更好地与基线模型对比,本实验还使用 ROUGE[20]指标,该指标包含多种度量摘要之间相似性的自动评估方法,是一种常用的文本摘要评价指标。ROUGE-N的召回率如公式(6)所示。
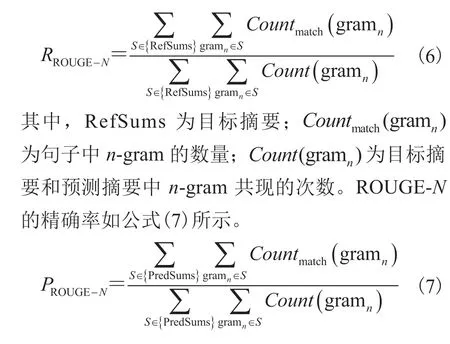
其中,PredSums 为预测摘要。ROUGE-L 的计算公式如公式(8)和公式(9)所示。
其中,LCS用于计算两个字符串最长公共子串的长度;m为目标摘要长度;n为预测摘要长度。
本实验的实验超参数说明如表2 所示。Max_sent_len 表示句子向量生成模型所能处理的最大句子长度。Seq_len 表示句子分类模型能处理的最大句子数量。Pos_weight 和 Neg_weight表示正例和负例的权重,由于数据集中摘要句子的正负例失衡,负例数量是正例的 3.55 倍,因此,设置正负例权重纠正偏差。Interval 表示长度间隔,模型通过长度间隔引入句子的长度信息,具体做法是将处于相同长度区间内的句子映射到同一个可训练的长度嵌入,具体如公式(1)所示。Layer 表示句子分类模型中 Transformer 编码器的层数。
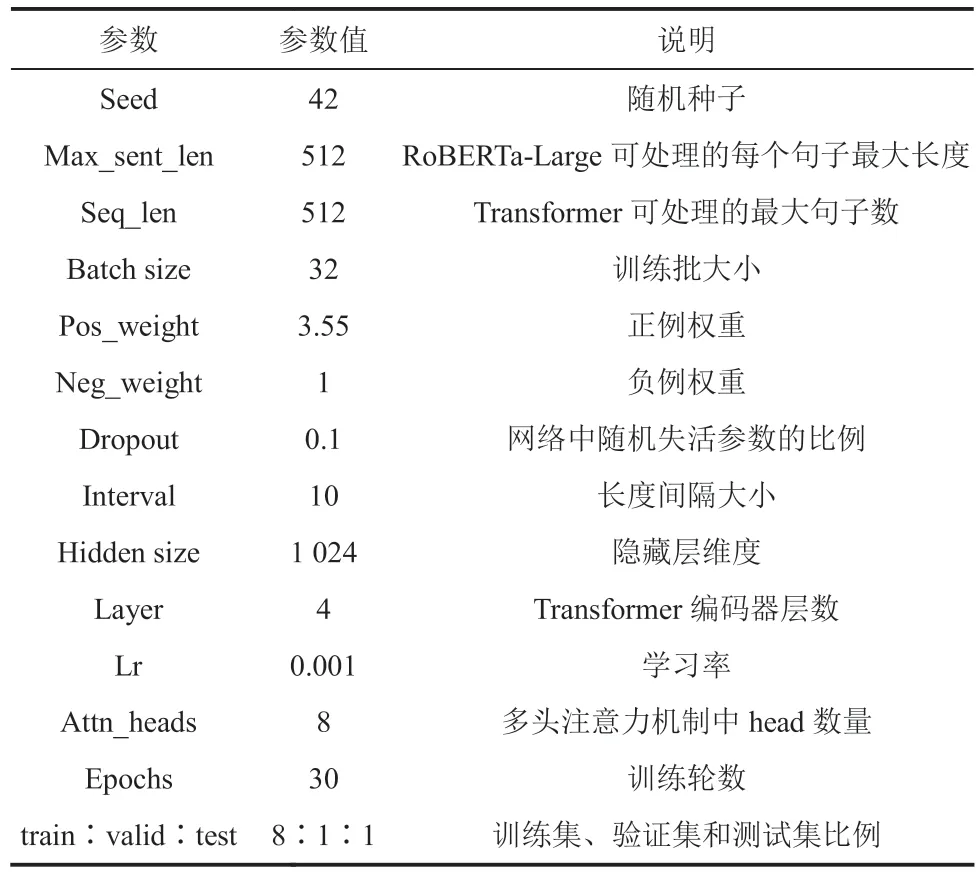
表2 实验超参数Table 2 Hyperparameters in experiment
4.2 实验结果
本文提出的模型将 RoBERTa-Large 作为句子编码器,将多层 Transformer 编码器结构作为句子分类模型,将抽取任务转化为句子的分类任务,并且与无监督 TextRank 基线模型进行了对比,证明了该模型的有效性。此外,本文在抽取式摘要模型中引入了与长度相关的特征,进一步提升了模型效果。实验结果如表3~5 所示,与基线模型相比,本文提出的抽取式摘要模型在ROUGE-1、ROUGE-2 和 ROUGE-L 指标上均有明显提升。
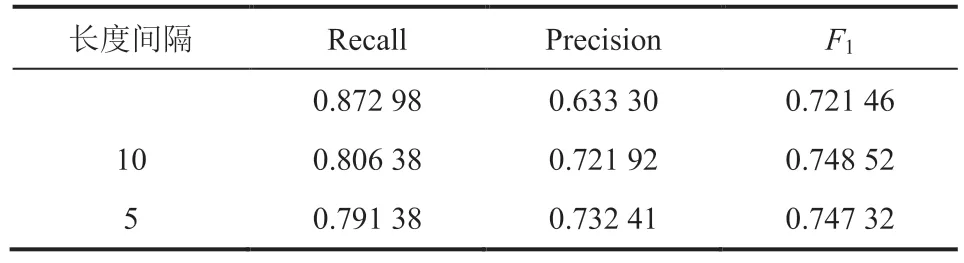
表3 模型在不同长度间隔上实验的结果Table 3 Experimental results of the model on differentlength intervals
4.3 讨论与分析
经过数据分析发现,句子长度信息对句子重要程度有一定影响,因此,本实验引入了句子长度信息。具体方式是将文本长度位于相同区间的文本共享同一个可训练向量,并在文本输入阶段与句子嵌入、句子位置融合,得到句子向量。实验结果如表3 所示,表中结果为 Transformer 编码器为 4 层的实验结果。由表3 可知,加入长度信息后,F1指标有一定提升。长度间隔为 5时,F1提升 2.586%;长度间隔为 10 时,F1提升2.706%。可以看出,句子长度信息是抽取句子所需的重要信息之一。
为了选择最优的 Transformer 编码器层数,本研究进行了一系列实验,针对 1~6 层分别计算了 Recall、Precision 和F1指标,结果如表4 所示。从表4 可以看出,随着编码器层数的增加,Precision 指标逐渐提高,而 Recall 指标则呈逐渐下降的趋势。然而,F1指标与层数之间并没有太大的相关性,这表明层数对模型的整体性能影响有限。在本实验中,当编码器层数为 4 时,模型在F1指标上取得了最佳效果。
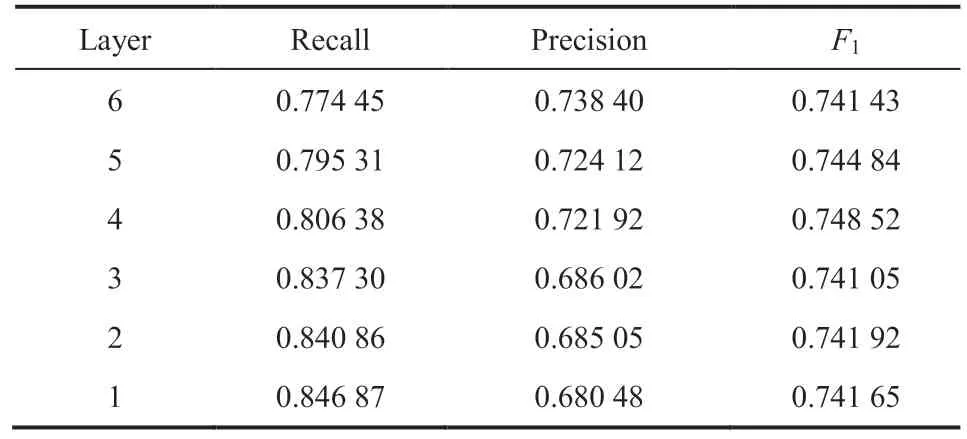
表4 模型在不同 Transformer 编码器层数上实验的结果Table 4 Experimental results of the model on differentTransformer encoder layers
在与基线模型进行对比的实验中,采用了ROUGE-1、ROUGE-2、ROUGE-L 指标,实验结果详见表5。其中,RoBERTa-Large-Transformer编码器的 Transformer 层数为 4。
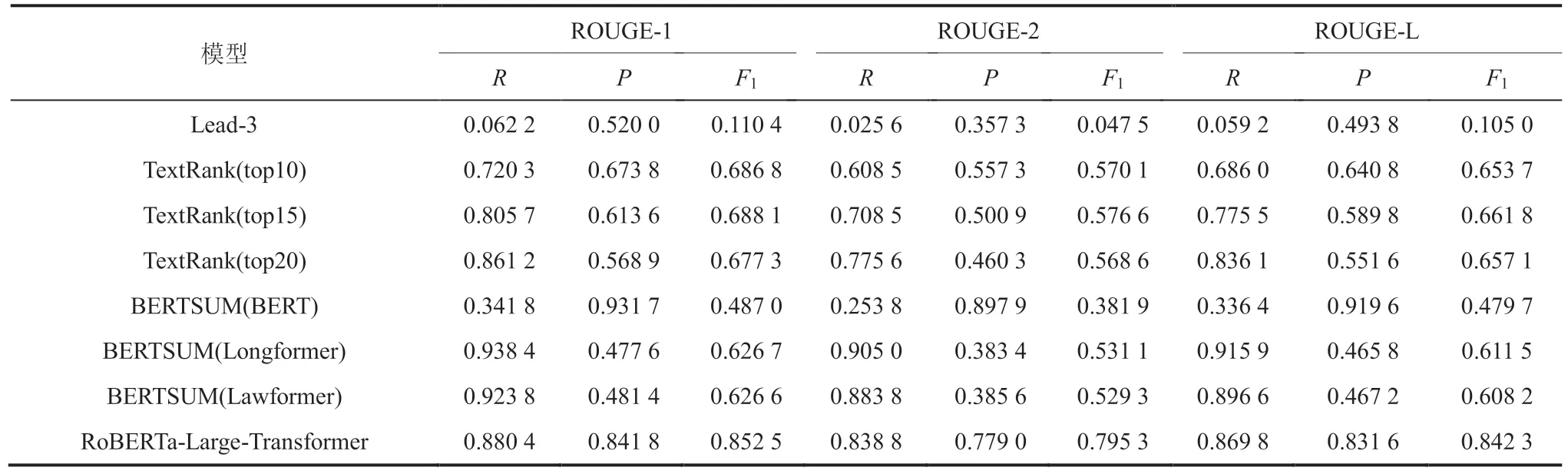
表5 模型与基准模型的指标对比Table 5 Comparison of metrics between the model and the baseline model
Lead-3 模型直接将文档前 3 句话作为摘要,这种方式并不适用于重要信息比较均匀的法律文本,因此其指标并不高。
TextRank 在选择召回分数最高的 15 个句子时表现最佳。由表5 可知,与无监督的 TextRank模型相比,RoBERTa-Large-Transformer 编码器在3 个指标上均有较大提升。其中,ROUGE-1 的F1指标提升 16.44%;ROUGE-2 的F1指标提升21.87%;ROUGE-L 的F1指标提升 18.05%,3 个指标平均提升 18.79%。
BERTSUM 模型是 BERT 在抽取式摘要中的首次应用。其具体做法是在句子之前插入[CLS]词元,在句子之后插入[SEP]词元,通过预训练语言模型提取特征,根据[CLS]词元对应的输出预测句子的重要性。然而,这种方法的缺点是输入长度受到预训练语言模型的限制。例如,BERT 仅能输入 512 个词元,而即使 Longformer和 Lawformer 极大程度地增加了模型的可输入长度,数据集中依旧有超过一半的数据超出其长度限制。本实验采用了截断的方式来处理超出长度限制的部分。
基于 BERT 的 BERTSUM 模型在精确率方面具有较高的表现,但由于信息截断的影响,其召回率较低,因此,F1值相对较低。相反,基于 Longformer 的 BERTSUM 模型具有较高的召回率,但精确率偏低,同样导致F1值较低。与基于 Longformer 的 BERTSUM 模型相比,RoBERTa-Large-Transformer 编码器在 ROUGE-1的F1指标上提升了 22.58%;在 ROUGE-2 的F1指标上提升了 26.42%;在 ROUGE-L 的F1指标上提升了 23.08%,3 个指标的平均提升为24.03%。
5 结 论
本文针对中文裁判文书摘要任务提出一种基于 Transformer 编码器的抽取式摘要模型。该模型首先通过预训练语言模型采用平均池化的方式为每个句子生成句嵌入;然后通过 Transformer编码器将句子嵌入、句子位置嵌入及句子长度嵌入融合;最后通过全连接网络对句子表示进行分类,从而完成抽取式摘要任务。本文所提出模型避免了直接将长文本输入模型导致超出预训练语言模型的最大输入长度的问题,从而极大程度地扩大了摘要模型可处理的文本长度。此外,抽取式摘要算法将句子长度以区间划分,并进行映射,从而使模型可以考虑句子的长度信息,提升模型效果。本文所提出的抽取式摘要算法在ROUGE-1、ROUGE-2、ROUGE-L 指标上均远超过基线模型。
中文法律裁判文书的抽取式摘要任务仍处于早期探索阶段,由于缺乏公开数据集,或是数据集中裁判文书种类不全,裁判文书属于长文本,而常见的预训练语言模型并不支持长文本等原因,该任务依然面临着巨大挑战。而从模型层面,长文本抽取式摘要仍有许多待解决的问题,例如:根据现在的分句标准,句子长度极其不均衡,一些句子长度过长,进行句子嵌入生成时,信息可能会被过度压缩,导致语义信息丢失。而如果对句子进行更细致的分割,则又可能导致少部分文本句子数量过多,从而使得处于末尾部分的位置嵌入无法得到充分训练,并会出现模型抽取少句子的文本效果好,而抽取多句子的文本效果差的情况。这些问题亟待进一步研究解决。
