一种基于时间帧差的行为识别方法
2024-01-26张颖李英杰
张颖 李英杰



摘要:视频中人类行为的跟踪和识别是计算机视觉的重要任务。视频中特征提取和建模是识別行为的关键问题。研究基于时间帧差的特征提取方法和行为识别的方法。首先,对相邻视频帧计算帧差图像,再计算帧差图像的光流,形成帧差序列和光流序列;然后,从帧差序列和光流序列中提取一组特征;最后,利用隐马尔可夫模型进行建模和识别。方法在Weizmann数据库和KTH数据库上分别获得了97.2%和85%的识别精度,验证了提出特征的性能,并验证了时间帧差图像对行为识别的有效性。另外,通过对一些特殊动作视频的测试,验证了提出方法的鲁棒性。
关键词:时间帧差;人类行为;光流;隐马尔可夫模型
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2023)35-0033-05
开放科学(资源服务)标识码(OSID)
0 引言
视频中人类的行为分析是计算机视觉的一个重要领域,有很多潜在应用,例如智能监控、无人驾驶、基于内容的视频检索和智能建筑等[1]。构建一个像人类一样,在复杂场景中具有无与伦比的识别能力,的系统,是人工智能的梦想。
传统的行为识别方法,大多数研究都集中在特征提取和描述上,例如:时空兴趣点、外观特征、光流等。近年来,随着深度学习技术研究的不断深入,其技术在视频中人的行为识别方面的研究层出不穷。包括卷积神经网络、递归神经网络等均可应用在行为的建模中[2-3]。当然,传统的行为识别方法的研究仍在深入进行,并且,传统方法与基于深度学习的方法也有互相补充和融合的趋势。传统的视频中人的行为识别方法通常分为几个过程,包括特征提取、行为建模和行为识别。本文基于传统方法,重点研究在视频中适宜行为识别的特征。
视频是识别的数据来源。当摄像头固定时,通过不同时间帧的差获得的帧差图像可用于表示运动的差,而不是整个身体的运动。帧差图像中许多特征细节(如颜色、纹理和体型)都会丢失[4]。另外,当物体停止移动时,它无法检测到物体。所以,帧差一般与其他特征相结合才可能较全面地描述运动。然而,本文研究表明,只基于帧差图像,能够获得足够的特征,以有效地识别行为。
1 方法与相关工作
1.1 方法
本文的研究结合帧差图像和帧差的光流提取特征,进行视频中行为的建模与识别,其具体的流程如图1所示。
首先,通过连续视频帧相减并设定阈值来获取帧差序列。每个帧差图像都是一个二值图像;之后,计算连续帧差图像的光流;再从帧差图像和光流图像中提取特征向量。提取的特征主要是外观特征和运动特征;之后,从特征向量序列中学习并建立每种行为的HMM模型。对于新的视频片段,通过前面的步骤获取其特征向量序列,并通计算与每类HMM模型的似然来识别其中的行为。
本文方法与已有的研究方法相比,有两个方面不同。首先,方法中所有特征都完全从时间帧差序列中提取;其次,从时间帧差序列及其光流中分别提取的特征进行组合,以提高行为表征的准确性和鲁棒性。
1.2 基于外观表征行为的方法
多年来,基于外观的特征在识别人类行为方面发挥着作用,而区域和轮廓是外观的直观表示[4]。通常,特征是从前景区域或轮廓中提取的,并表示为每个帧的姿势[4]。
Hota 等人在监控视频中测试了有助于区分人与其他物体的特征[5]。其研究表明,许多基于外观的特征有助于识别人的形状,例如:胡不变矩、最小外接矩形(Minimum Bounding Rectangle,MBR)的高度与宽度比、填充率(MBR内前景点面积与MBR面积的比率)以及周长等。当然,基于外观的方法可能会受视点、遮挡、缩放和个体变化的影响[4-5]。
1.3 基于兴趣点的功能
空间兴趣点提供了图像中特殊点的紧凑和抽象表示,并且它们是比例不变的。它们能够在存在遮挡和动态背景的情况下实现检测事件[6-7]。Ivan Laptev等人基于Harris和Forstner的方法提出了新的兴趣点提取方法[7]。
1.4 光流计算
光流表达两个图像之间的像素运动。两个图像通常是视频中两个连续帧。光流以流表示第一张图像中每一个像素映射到第二张图像中对应的像素的位移。Horn和Schunck提出了光流的计算方法,其假设像素灰度值在连续帧之间变化最小,并使用全局平滑[8]。然而,在运动边界、平滑区域或者大位移运动过程的光流计算会出现模糊和残留问题。因此,一些新方法和改进方法被提出。例如,对于人体运动问题,由于人体是多关节体和非刚性的,可能会产生较大的位移。Lu和Liu使用哈里斯点来补偿变分光流场[9]。基于块匹配的方法也是一种可以处理大位移的匹配方法[10]。
1.5 HMM模型
马尔可夫链(Markov chain)是一种随机过程,该过程由有限历史约束的状态组成。这意味下一状态的概率分布只由当前状态决定,在时间序列中,再前面的事件均与下一状态无关。隐马尔可夫模型(Hidden Markov Model, HMM)是一种统计模型,其中假设正在建模的系统是具有隐藏状态的马尔可夫过程。虽然人类行为并不严格符合有限历史状态约束,但许多研究表明,HMM可以正确模拟人类行为[11]。
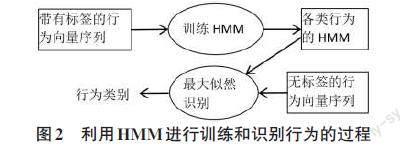
HMM模型由5元组指定:μ=(S,Q,∏,A,B),其中S和Q分别是状态和观测值的集合[12]。∏是原始状态概率的集合。A 是表示状态之间转移概率的矩阵。B是一个矩阵,表示从状态到观测值的传递概率。当观测序列具有相同的行为标签时,可以通过最大化概率 P(Q|μ)来训练模型μ。不同行为的模型,表示为 {μ1,μ2,...,μi,...},可以使用相应的观测值进行训练。使用不带标签的观测值,可以计算最大似然将其分类。基于从视频中获取的特征向量序列,HMM训练和识别流程如图2所示。
2 时间帧差和帧差的光流计算
2.1 Weizman行为数据库
Weizman行为数据库,是一个经典的人的行为识别的视频数据库[13]。数据库中的视频有十种行为,分别是:bending, jumping jack, jumping, jumping in place (pjump), running, jumping sideways, skipping, walking, one hand waving (wave1), and two hands waving (wave2)。每个行为分别有由10个人表演的视频段。视频帧速度为25帧/秒,每帧144*188像素。视频是用固定摄像机拍摄的。数据库中提供了每个视频的确切背景图像,因此可以方便地使用背景减法来获取完整的前景图像。以下叙述中的实验数据来源于此数据库中的视频。
2.2 时间帧差
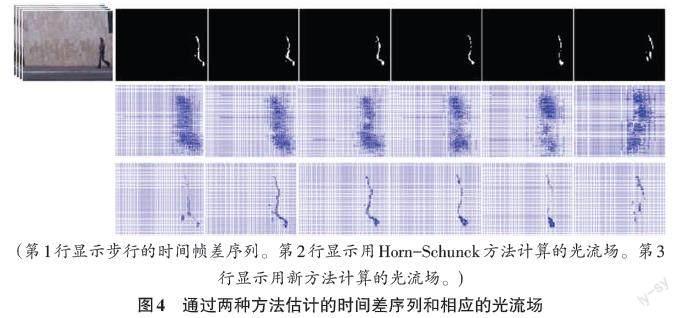
通过在包含运动对象的视频中的两个相邻帧之间相减,会在差的图像中获得两组点。一组点值为正,另一组点值为负。经过阈值估计过程后,它们被投影到时差图像中的两条边。如果只使用一组中的点,例如,只保留具有正值的点,则将得到半时差图像。如果使用二组点将获得全差分图像。为了感知前景图像、时间帧差图像和半时差图像之间的差异,图3显示了一些样本。
在图3中,时间帧差图像中检测到动作时刻运动部分的近似轮廓,不动的部分丢失了。半帧差图像保留了大约一半的运动轮廓,丢失了更多的运动信息。但是,后面将验证,在半时间帧差序列中仍然包含识别行为的有效信息,并且可以简化光流的计算。因此,半时间帧差序列将作为本文工作的基础。下文中,为叙述简洁,“半时间帧差”将简称为“时间帧差”,不再强调“半”。
2.3 帧差的光流计算
欲计算时间帧差序列的光流,前述的光流计算方法可能存在局限性,可能的原因如下:
1)时间帧差图像是二值的。任何前景区域点和任何背景区域点之间的灰度值都是相同的。无论是通过变分方法还是基于块的方法,这两个区域都可能引入不正确的匹配。
2)通过全局平滑,即使涉及各向异性惩罚,运动边缘也会严重模糊。
3)时间帧差的前景范围小于序列图像中的前景范围,并且时间帧差序列中没有背景运动问题。
所以,光流计算可以简化。因此,提出了一种新的方法来估计相邻时间帧差图像之间的光流。它描述如下:
1)通過两个质心的位移在前景区域中建立非常原始的流动。
2)将第一个图像和第二个图像划分为大小相同的网格,例如 9×9 网格。计算相应网格质心的前景位移,并通过其位移修改每个网格中的原始流。但是,零位移网格中的原始流被保留。在此过程中忽略所有背景点的流。
3)计算每个图像的哈里斯角,匹配角点,并修改匹配点的流。哈里斯角点由一阶曲率估计,并且对尺度和仿射变换不变[14]。一些在前一个步骤中无法反映的拐角运动预计将通过此步骤进行调整。
4)在前景中平滑。
图4中,第2行显示的是用传统方法计算出的帧差的光流,可以看到其中方向和边缘模糊。第3行显示的是新方法计算得到的光流。可以看到,大多数流向量的方向和速度都正确,边缘没有模糊。
3 特征向量提取
为了减少缩放的影响,即从相机到物体的距离变化,引入了最小正接矩形(Upgrade Minimum Bounding Rectangle,UMBR)。UMBR 是一个包含所有前景点的框,并且与坐标垂直。引入UMBR,是假设拍摄视频的摄像机与地面垂直。
参考人类对行为的感知,从时间帧差和相应的光流场中定义了几个统计特征,用于表征行为。提取出的特征用符号M=(m1, m2, ..., mk)表示。下标 1, 2, ..., k,仅用于特征索引,特征顺序无关紧要。光流场表示为U,其中的矢量表示为(u,v)。
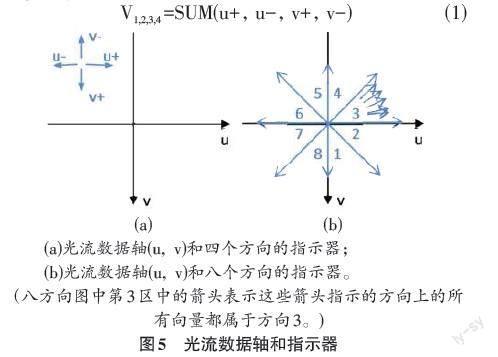
3.1 四个方向的速度特征
光流表征的是前景中每个点的运动方向和速度。人类可以感知运动总量和细节。虽然捕获所有细节可以更准确地表示动作,但计算更复杂,并且可能对噪声点更敏感。因此,本文的方法只计算运动总量。首先将速度方向分为四个,如图5(1)所示。从一个光流场U中,计算四个方向的总速度的和,如公式(1)。再获取光流场中所有前景点的UMBR。之后,将四个方向的总速度除以UMBR的对角线长度以进行标准化。这样,对于一个光流场,产生了前4个特征,就是m1~m4。
V1,2,3,4 =SUM(u+, u-, v+, v-) (1)
3.2 运动方向分布特征
人类身体不同部分的运动方向分布可以表示不同的动作。增加身体每个部位的运动方向分布特征可以增强动作识别的效果。但分割身体部位可能只在特定的场景中才能完成。从时间帧差图像中分割身体部位更加困难。此外,收集所有方向的统计分布很复杂,也会产生高维数据。本文方法中把方向分为八个,如图5(b)所示,每个方向是一个扇区。在一个光流场U中,计算八方向直方图以指示运动方向分布,计算如公式(2)。再计算U的前景面积。之后,用八方向向量的点个数除以前景面积,进行标准化。这样,对于一个光流场,获取了另外8个特征,就是m5~m12。
[dk=count(u,v)∈sectionk(u,v)] (2)
到目前为止,基于一幅帧差的光流场获得了12个特征,是m1~m12。那么,从一段视频中可以获得一组,具有12个特征的矢量序列。这个序列表征的是运动特征。
3.3 基于外观的特征
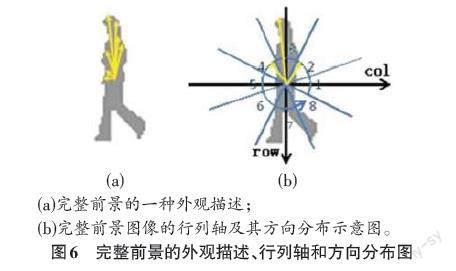
为了进一步增强行为特征的可区分性,引入了一些外观特征,这些特征将来源于帧差图像的前景。Gupta等提出了一种用于表示闭合形状的描述符如图6(a)所示。其方法中以质心与形状的所有轮廓像素点之间的欧氏距离的序列来表示形状[15]。为了避免数据维数过大,将方向划分了8区间,如图6的(b)所示。其中坐标表示为(col,row),原点设置为前景区域的质心。对每个区间,采集质心与轮廓像素之间的最远距离。之后,将距离除以UMBR的对角线长度进行标准化,得到m13~m20 。利用这些特征,可以粗略地表征身体部位的延伸和缩进。需要说明的是,图9中使用完整的前景图像作为示例图像,以清楚地表达描述符的概念。本文工作中,提取m13~m20时是取之于帧差图像。帧差图像是二值图像,其中前景区块可能有不连续问题。在计算质心、面积和UMBR时,所有前景点将视为一个区域。
图6(a) 中箭头表示从质心到轮廓上的像素的距离。(b)完整前景图像的行列轴及其方向分布示意图。图6(b) 中原点设置在质心,分8个方向,三个箭头表示 2、3 和 4 方向的最远距离。
另外,为了估计像素分布,按图6(b)中8个方向区域划分,计算帧差图像中每个区域的像素计数。并将像素计数除以前景区域面积进行标准化。结果是m21~m28。
至此,从帧差图像序列中提取出向量m13~m28序列,用于表征外观形状特征;从光流序列中提取出向量m1~m12序列,用于表征运动特征。特征向量序列m1~m28将用于HMM建模和识别行为。
4 实验和讨论
使用本文方法,在Weizmann数据库和KTH数据库上进行了一系列实验。实验包括分类测试、特征贡献测试和鲁棒性测试,另外,还与一些相关方法进行了比较。
4.1 在Weizmann数据库上的分类精度测试
Weizmann数据库包含10个行为,每个行为由9个人表演,那么,其中有90个视频。从实验上讲,每个视频段中包含15 帧,就足以识别其中的行为。因此,实验中将90个视频划分成更多的视频段,以产生更多的训练和测试数据。对于视频段,从中获取28个特征的序列,每个序列的大小为 28×15。由于人类的行为是对称的,例如:如从左到右跑,从右到左跑;挥动右手和挥舞左手等。为了在不重复的情况下获得更多数据,每个序列都生成一个逆特征序列。
下面的测试遵循留一策略:从一个行为序列中选择一个随机序列作为测试序列,其他序列将用于训练该行为的HMM。每次运行测试,利用训练序列,训练并构建10个行为的HMM。之后,对保留的10个序列(每种行为保留1个序列,共10个序列)进行测试,识别它们分别属于哪个行为。为了减少随机因素的影响,进行了100次运行测试。最终,获得了97.2%的识别准确率。图7所示的混淆矩阵展示了更多细节。从中可以看到“run”和“skip”之间混淆较大。当然,这两个行为在肢体的速度和运动上非常相似。
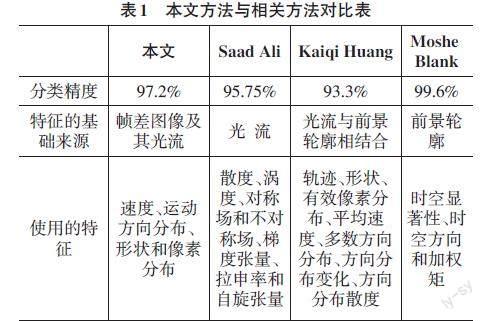
表1展示了本文方法与相关研究的对比。对比的研究有:Saad Ali等人的方法、Kaiqi Huang等人的方法,以及Moshe Blank等人的方法[13,16-17]。表中展示的都是在Weizmann行为数据库上的实验結果。可以看出,本文方法的性能与其他方法的性能相当。尽管本文方法在分类精度上不是最好的方法。但是,本文方法的所有特征都是来源于帧差序列,计算量少于其他方法。
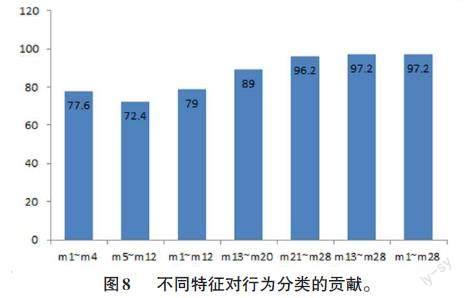
4.2 特征贡献测试
为了测试不同特征的贡献,利用之前从Weizmann数据库中获取的特征序列集,构造了不同特征的子集。测试了不同子集的性能,结果如图8所示。x 轴显示特征子集的构成,y轴显示相应的分类精度。从中看出,贡献最大的单个特征是像素分布,综合的外观特征对分类的贡献也很突出。另外可以看出,对于行为识别,所有特征,即外观特征和运动特征的组合,与单独的外观特征相比并没有更多贡献。当然,在后面的实验中可以看到运动特征对鲁棒性的贡献。
特征有:速度(m1~m4)、运动方向分布 (m5~m12)、运动特征(m1~m12)、形状(m13~m20)、像素分布(m21~m28)、外观特征(m13~m28)和全部特征 (m1~m28)。
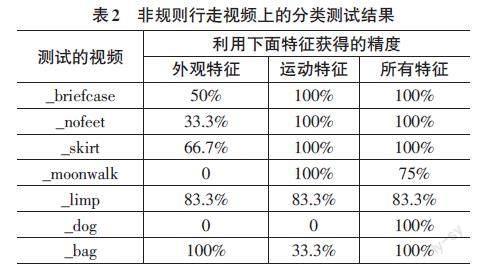
4.3 鲁棒性试验
Weizmann数据库中有一组特殊的步行视频,其中包含一些非常规的步行活动。包括:_briefcase(拎公文包行走),_dog(与狗一起散步),_nofeet(行走时用盒子遮挡脚),_skirt(穿裙子行走),_moonwalk(像慢动作一样行走),_limp(跛行),_bag(提个袋子行走)。HMM 使用之前的普通Weizmann数据库进行训练。在非规则行走视频段上进行分类测试,结果如表2所示。可以看出,运动特征在识别上比外观特征更鲁棒。通过组合外观特征与运动特征,提高了识别方法的鲁棒性。
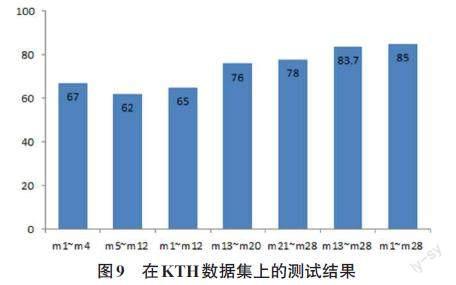
4.4 KTH数据库分类实验
KTH行动数据库是另一个经典的行为数据集,其中包含六个动作[18]。他们是: boxing,handclapping,handwaving,jogging,running和walking。每个动作由25个人在4个不同的场景中进行。这是一个具有挑战性的用于行为识别的数据集,因为其中的行为表演场景比较多样,例如:穿不同服装、带包、光线变化、视角变化和缩放等。通过本文方法对该数据集进行测试,识别精度达到85%,如图9所示。
5 结论
提出一种基于时间帧差的用于识别视频中行为识别的新方法。新方法中综合了运动和外观特征。本文工作的主要贡献总结如下:
1)基于时间帧差序列,提出运动与外观相结合的特征集,并验证了其识别行为的有效性。
2)提出了一种基于时间帧差序列计算光流的方法。
3)通过对非常规步行集的测试,验证了基于时间帧差的运动特征比基于外观的特征在动作识别方面鲁棒性更强。
人类可以在复杂的场景中评估信息并快速识别行为。挖掘人类的深层意识,并开发更有效、更强大的动作描述方法是我们的长期目标。
参考文献:
[1] 刘锁兰,田珍珍,王洪元,等.基于单模态的多尺度特征融合人体行为识别方法[J].计算机应用,2023,43(10):3236-3243.
[2] 朱煜,赵江坤,王逸宁,等.基于深度学习的人体行为识别算法综述[J].自动化学报,2016,42(6):848-857.
[3] 黄勇康,梁美玉,王笑笑,等.基于深度时空残差卷积神经网络的课堂教学视频中多人课堂行为识别[J].计算机应用,2022,42(3):736-742.
[4] REVATHI A R,KUMAR D.A survey of activity recognition and understanding the behavior in video survelliance[EB/OL].2012:arXiv:1207.6774.https://arxiv.org/abs/1207.6774.pdf
[5] HOTA R N,VENKOPARAO V,RAJAGOPAL A.Shape based object classification for automated video surveillance with feature selection[C]//Proceedings of the 10th International Conference on Information Technology.ACM,2007:97-99.
[6] LAPTEV I,LINDEBERG T.Velocity adaptation of space-time interest points[C]//Proceedings of the 17th International Conference on Pattern Recognition,2004.ICPR 2004.August 26,2004.Cambridge,UK.IEEE,2004.
[7] LAPTEV,LINDEBERG.Space-time interest points[C]//Proceedings Ninth IEEE International Conference on Computer Vision.October 13-16,2003.Nice,France.IEEE,2003.
[8] HORN B K P,SCHUNCK B G.Determining optical flow[J].Artificial Intelligence,1981,17(1/2/3):185-203.
[9] LU Z Y,LIU W.The compensated HS optical flow estimation based on matching Harris corner points[C]//Proceedings of the 2010 International Conference on Electrical and Control Engineering.ACM,2010:2279-2282.
[10] KITT B,RANFT B,LATEGAHN H.Block-matching based optical flow estimation with reduced search space based on geometric constraints[C]//13th International IEEE Conference on Intelligent Transportation Systems.September 19-22,2010.Funchal,Madeira Island,Portugal.IEEE,2010.
[11] AHMAD M,LEE S W.HMM-based human action recognition using multiview image sequences[C]//18th International Conference on Pattern Recognition (ICPR'06).Hong Kong,China.IEEE,2006.
[12] Kevin Murphy. Bayes net toolbox for Matlab[EB/OL].[2020-09-12]. http://www.cs.ubc.ca/~murphyk/Software/HMM/hmm_ usage.html.
[13] BLANK M,GORELICK L,SHECHTMAN E,et al.Actions as space-time shapes[C]//Tenth IEEE International Conference on Computer Vision (ICCV'05) Volume 1.October 17-21,2005.Beijing,China.IEEE,2005.
[14] HARRIS C,STEPHENS M.A combined corner and edge detector[C]//Proceedings ofthe Alvey Vision Conference 1988.Manchester.Alvey Vision Club,1988.
[15] GUPTA L,SRINATH M.Invariant planar shape recognition using dynamic alignment[C]//ICASSP '87.IEEE International Conference on Acoustics,Speech,and Signal Processing.Dallas,TX,USA.Institute of Electrical and Electronics Engineers,1987.
[16] ALI S,SHAH M.Human action recognition in videos using kinematic features and multiple instance learning[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2010,32(2):288-303.
[17] HUANG K Q,WANG S Q,TAN T N,et al.Human behavior analysis based on a new motion descriptor[J].IEEE Transactions on Circuits and Systems for Video Technology,2009,19(12):1830-1840.
[18] SCHULDT C,LAPTEV I,CAPUTO B.Recognizing human actions:a local SVM approach[C]//Proceedings of the 17th International Conference on Pattern Recognition,2004.ICPR 2004.August 26,2004.Cambridge,UK.IEEE,2004.
【通聯编辑:光文玲】
