三通道超分辨率微小面部表情识别算法研究
2024-01-24程其玉钟志水刘华敏
程其玉 钟志水 刘华敏 汪 立 李 璐
( 安徽信息工程学院计算机与软件工程学院,安徽 芜湖 241100 )
一、引言
随着智能化时代的到来, 面部表情识别技术作为人工智能中对于研究人的行为状态的基础, 逐渐在各个领域发展应用起来。 由于在机器开发时模拟的图像仅为实验室中的理想情况, 即使已经考虑到光线、眼镜、遮挡等因素,但在实际生活中摄像头采集到的面部图像往往达不到所需的识别尺寸, 因而识别精准度就会随之降低。 图像识别中,当输入图像的尺寸减小时, 神经网络的特征提取程度也受到限制,反之,图像进行放大时,会导致部分细节的丢失,从而导致图像分辨率降低, 进而导致图像识别的准确率降低。
近些年,随着人脸识别和面部表情识别的发展,部分学者不再拘泥于理想数据库进行训练。 2017 年胡(HU)等人首次提出了对微小人脸面部区域进行检测, 并且训练出了可以在不同面部尺寸中进行检测的多尺度的模型[1]。 2018 年白(BAI)等人将超分辨率网络应用到人脸检测和识别中[2],该网络使用超分辨率网络对图像进行细化以生成清晰且真实的高分辨率图像, 最终实现了能够最低检测10*10 像素的面部图像。2019 年邵(SHAO)等人重点研究了尺寸为16*16 像素的微小面孔, 通过探索生成对抗性网络W-GAN (Wasserstein Generative Adversarial Net)的潜力,将它们重建到8 倍上采样版本[3]。 2020 年,余(YU)等人提出了一种新的超分辨率变革性对抗性神经网络,以同时产生幻觉(由8 倍的上采样)和正面化微小(16*16 像素)不对齐的人脸图像[4]。 南(NAN)等人提出一种基于特征超分辨率的人脸表情识别方法FSR-FER, 可针对低分辨率面部表情图像进行训练识别, 通过在RAF-DB 数据库上放大2 倍、3 倍、4倍、8 倍验证了所提出网络的效果, 即最小能够识别25*25 像素大小的面部图片[5]。 言(YAN)等人从滤波器学习的角度来执行低分辨率的面部表情识别,在CK+、MMI、JAFFE 数据库上进行了输入大小为8*8、16*16、32*32 分别放大4 倍、2 倍、1 倍的验证,在RAF-DB 数据库上也进行了放大三倍实验的验证[6]。综上,近些年研究者们提出的超分辨率方法,大多都是通过网络深度的提升来提高超分辨率的性能,而要加深网络的整体深度, 对训练时的时间要求以及对计算机性能的要求也都会提高。 因此,本文提出一种微小面部表情识别网络CTE-FER,网络结构如图1 所示,旨在解决在图像采集中由于像素等原因导致采集到的面部图像较小以及分辨率较低, 从而导致面部表情识别准确率降低的问题。 首先,本文引入来自Cutblur 的图像预处理机制[7], 结合EDSR(Enhanced Deep Residual Networks for Single Image Super-Resolution)超分辨率网络进行训练[8]。 由于要纵向加深网络的整体深度, 其训练的时间延长以及对计算机性能要求也会提高。 综合考虑网络层次深度以及超分辨率效果, 本文在不改变EDSR 网络纵向深度的同时提出了在横向程度上添加通道, 以构成三通道的EDSR 网络。其次,将其与FER 面部表情识别网络结合, 构成端对端的基于Cutblur 的三通道EDSR 表情识别网络,称之为CTE-FER 网络。 最后,本文采用多项实验对比验证所提出算法的有效性。

图1 CTE-FER 网络结构
二、三通道超分辨率微小面部表情识别网络结构
本文提出的三通道超分辨率微小面部表情识别网络分为三个部分。如上文图1 所示,分别为Cutblur图像预处理部分、 三通道EDSR 超分辨率部分以及FER 面部表情识别部分。 CTE-FER 图像预处理部分是将面部图像在超分辨率网络训练之前进行色块方面的预处理, 以减少图像特征处理时对超分辨率结果和表情识别结果的影响。 三通道的EDSR 网络对处理后的图像特征进行学习, 三通道将网络的横向深度加深, 保证了网络纵向深度不变的同时提升其训练效果和稳定性。 表情识别部分为对超分辨率处理后的图像特征进行面部特征的提取和分类, 最终得到识别的结果。
(一)CTE-FER 框架原理
CTE-FER 算法首先采用Cutblur 对图像进行预处理, 通过在空间上将不同分辨率的图像色块相互填充, 从而实现有针对性地对某一特征区域进行超分辨率处理。 如图2 所示, 将低分辨率图像 (lowresolution ,LR) 中的图像块进行裁剪并粘贴在高分辨率图像(high-resolution ,HR) 中对应位置; 使用HR 对放大后的LR 反向进行局部区域的填充操作。通过预处理,既可以让模型知道如何处理,也可以知道哪里需要处理, 即算法可以自适应地对图像进行不同程度的处理, 而不是盲目地对所有像素进行超分辨率处理。
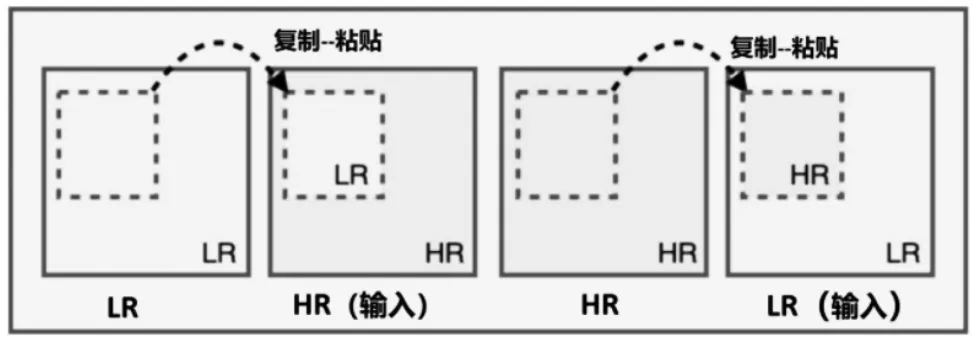
图2 Cutblur 预处理原理
假设给定LR 图像xLR∈RW*H*C和HR 图像xLR∈RW*H*C,CTE-FER 首先对LR 图像进行s 倍的双三次插值,再通过剪切、粘贴进行色块相互填充,生成成对的训练样本xLR∈RW*H*C:
其中s 是放大倍数,M∈0.{ }1sW*sH为二值Mask,其主要功能为确定所需要进行裁剪粘贴的部分。
本文提出的三通道EDSR 网络如图3 所示, 将经过Cutblur 处理后的特征向量作为输入信息T1in、T2in、T3in,输入到三通道EDSR 的网络中。再经过低分辨率特征提取块conv(s,n)得到提取后的特征T′1in、T′2in和T′3in。
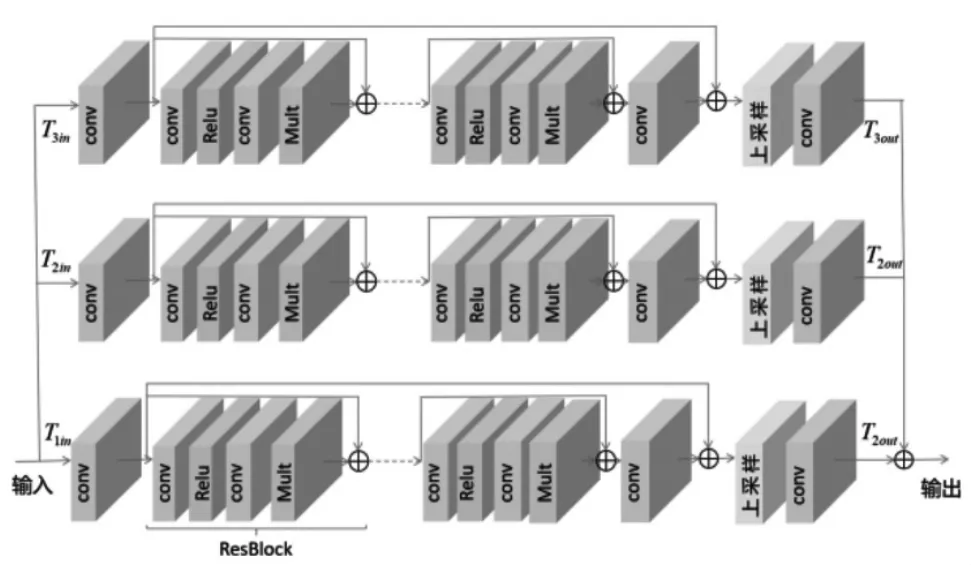
图3 三通道EDSR
conv(s,n)代表卷积层,公式中的s 和n 分别是滤波器的大小和数目。 之后便将这些特征进行残差块ResBlock 多次迭代。
fRes表示T′in,ResBlock 层, 经多次迭代加和后将输出的残差结构进行上采样以及图像重建,如此便得到了经过残差网络训练的超分辨率放大后的图像特征T1out、T2out和T3out。 之后再将三通道得到的图像特征进行加权, 得到综合的超分辨率特征值Tout。
其中μ 为权重, 具体参数获取方法将在消融实验给出。
(二)表情识别部分及损失函数
在得到三通道加权后的超分辨率图像特征之后,CTE-FER 将图像特征放入面部表情识别网络中进行面部特征提取与分类。
其中,I0表示面部表情识别输出结果,fSMFER表示面部表情网络。
此CTE-FER 网络的损失函数可以表示为:
其中,LDF表示三通道EDSR 网络的损失函数,Lfer表示面部表情识别网络的损失函数。 在此选择交叉熵作为损失函数。λDE和λfer表示正则化参数。其中,三通道EDSR 网络采用损失函数L1 来优化, 面部表情网络采用交叉熵损失函数优化。 因此可以表示为:
其中,μ值与公式9 一致,LSR1、LSR2、LSR3分别对应三个通道的损失,THR为输入的高分辨率图像特征,即目标特征。 Ix为表情识别实际标签。
三、实验结果分析
(一)实验参数及实验环境
本实验在Pytorch3.6 的环境中运行, 使用NVIDIA2080GPU 进行训练。 训练时一共有700 000个steps,每训练1 000 个steps 显示一次。 在网络中使用Adam 优化器优化网络参数,初始学习率为1e-4。 对于三通道的EDSR 网络来说,训练时间和改进之前的训练时间相差无几, 在输入低分辨率图像大小为12*12 像素放大四倍的情况下,每训练1 000 个steps 大约需要10 分钟。
(二)消融实验
表1 展示了本文所提出的CTE-FER 算法与采用CARN 网络和不同通道分别在CK+、FER2013、BU-3DFE 数据库中的表情识别结果的比较。 放大倍数为3和4 时,将数据库采用双三次插值法缩小到原来1/3 和1/4 分别得到大小为16*16 像素和12*12 像素的输入。
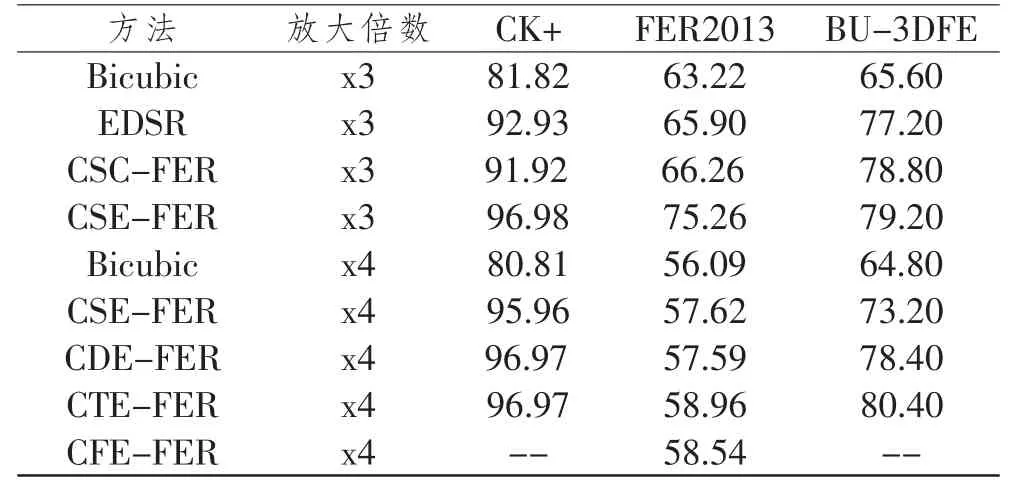
表1 消融实验
在表1 中,CSC-FER 为在单通道时采用CARN算法时的结果, 其在CK+数据集上的结果为91.92%, 在FER2013 和BU-3DFE 的结果分别为66.26%和78.8%。 但对于其未采用Cutblur, 只采用EDSR 结果相对比结果并不理想。 CSE-FER 为单通道采用EDSR 网络时的结果,可以看到,在三个数据集上该算法得到的结果较采用同等网络深度网络(CARN)时的结果要好,并且在放大三倍的情况下整体面部表情识别的准确率也较为理想。 因此,在网络中选取EDSR 作为基础网络, 同时为进一步验证多通道的有效性,本文将输入大小缩小为12*12 像素,即缩小4 倍的情况。 可以看出, 在图像进一步缩小时,各个数据库的识别准确率都有一定程度的降低。综合比较单通道(CSE-FER)、双通道(CDE-FER)、三通道(CTE-FER)时的情况可以看出,在按通道时所有数据库的准确率均有明显提升。 进一步进行四通道训练时, 在FER2013 数据库中可以看到准确率开始下降,也正是因为训练所需时间为三通道的两倍,针对四通道之后的训练不再继续。
上文公式(9)中有三个参数μ1、μ2、μ3,分别用于确定三通道EDSR 网络中的各个通道的影响。 本实验采用FER2013 数据库进行实验,首先采用不定系数法保持μ1=1 不变, 然后调整μ2和μ3的值来观察识别准确率,从下页图4 可以看出,当μ2=μ3=0.08 时面部表情识别准确率最高;之后保持μ2=μ3=0.08 不变,调整μ1的值,得出的结果如下页图5 所示。 可以看出当μ1=0.8 时,面部表情识别准确率达到最高。 综上,本实验在μ1=0.8,μ2=μ3=0.08 时达到最优值。
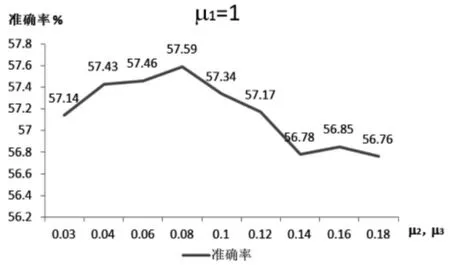
图4 μ1=1,改变μ2,μ3 时面部表情识别准确率的变化

图5 μ2=μ3=0.08 时,改变μ1 时面部表情识别准确率的变化
(三)算法自我评估
图6 展示出本算法在CK+、FER2013、BU-3DFE数据库中的混淆矩阵分析,从图中可以看到,各种表情开心与惊讶的表情准确率相对较高, 而其他的表情准确率相对略低, 并且不同的数据库中的相同表情准确率的顺序也不相同, 这是因为每个数据库中的各个表情所占比重不同, 以及每个数据库的图像来源、清晰度、表情程度等均对其造成影响。
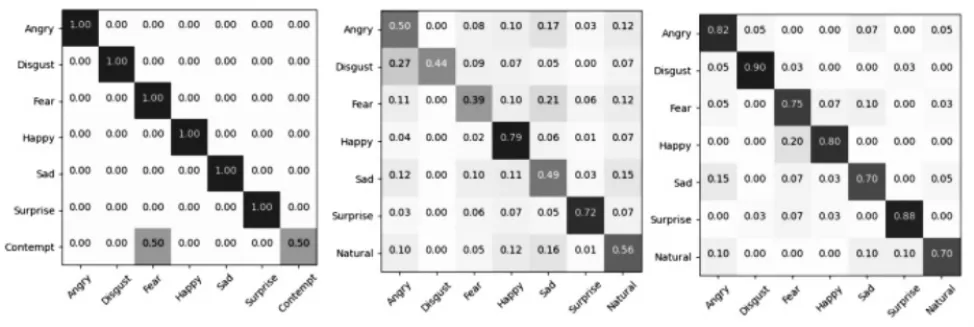
图6 CTE-FER 在三个数据库上的混淆矩阵
(四)与先进算法比较
表2 展示了在数据库CK+、FER2013、BU-3DFE本章算法与先进算法结果进行比较, 可以看出在本文输入大小仅为12*12 像素时,CK+数据库和BU-3DFE 数据库中得到的结果可以与先进算法相媲美,达到96.97%和80.40%,而对于FER2013 数据库, 由于其原始数据库是由网络中的图片得到,存在较大的噪声,且分辨率较低,在进行超分辨率训练时, 高分辨率的图像决定训练结果的最优值,因此FER2013 数据库得到的效果与先进算法存在一定差距。
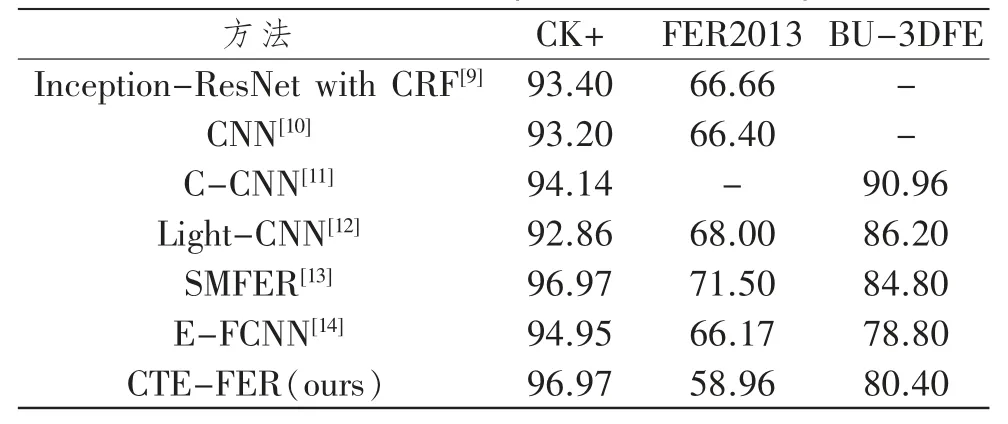
表2 不同方法在CK+、FER2013、BU-3DFE 数据库上的准确度(不同输入大小)
(五)相同输入大小时面部表情识别的比较
为了验证在相同输入大小时的CTE-FER 网络性能, 将其在放大倍数为4 时的结果与其他网络在相同输入大小时进行比较。 对比结果如表3 所示,在相同输入大小时,本文提出的CTE-FER 网络的表情识别结果高于其他网络。

表3 面部表情识别在CK+、FER2013、BU-3DFE 数据库上的准确度(相同输入大小)
(六)低分辨率面部表情识别比较
为了进一步对本文提出了网络性能进行验证,针对RAF-DB 数据库进行实验, 并与现有的部分超分辨率面部表情识别算法进行比较,实验结果于表4所示。 可以看出与其他网络的结果对比,在放大倍数为2 的情况下,准确率略低于E-FCNN 算法结果,而在放大3 倍和放大4 倍时得到的结果均高于其他算法。 因此,在高放大倍数的情况下,本章所提算法具有优越性。

表4 RAF-DB 数据库的低分辨率面部表情识别比较
四、结语
研究提出一种基于超分辨率的面部表情识别算法CTE-FER, 对于微小尺寸的面部表情进行识别,通过针对超分辨率算法进行多通道的改进, 提升针对小尺寸下面部表情图像的超分辨率效果, 进而提升整体面部表情识别的准确率。 同时,研究采用大量的对比实验评估该算法的性能,实验结果表明,本文提出的算法有效地提升了微小面部表情的识别准确率。 未来研究将进一步提升算法的性能,降低算法训练时间的同时提升准确率。
