基于马铃薯病虫害知识图谱的问答系统
2024-01-24赵赛杨婉霞王巧珍王梦瑶熊磊
赵赛 杨婉霞 王巧珍 王梦瑶 熊磊


摘 要: 开展农业知识图谱的问答系统研究在整个智能农业领域中具有重要的意义。以马铃薯病虫害为例,设计了马铃薯病虫害知识图谱问答系统,通过BIO、BMES 和BIOES 3 种方式标注数据后设计了BIiLSTM-CRF、Word2vec-BILSTMCRF和Bert-BILSTM-CRF 3 种模型进行命名实体识别。试验结果表明,BEMS 标注方式效果最佳,Bert-BILSTM-CRF 模型在命名实体识别时性能最佳,其F1 值为85.62%。结合Neo4j 图数据库匹配相应Cypher 语句实现问答交互,应用基于Javascript语言的VUE 前端框架,搭建完整的问答系统页面。
关键词:马铃薯;知识图谱;问答系统;病虫害;命名实体识别;Neo4j 图数据库
中图分类号:S532文献标识码:A文章编号:2095-1795(2023)08-0029-09
DOI:10.19998/j.cnki.2095-1795.2023.08.006
0 引言
马铃薯淀粉含量较高,含有丰富的蛋白质和维生素,是我国重要的粮食作物之一[1]。科学种植马铃薯,保证其增产增收尤为重要。其中,马铃薯耕种环节的病虫害防治在马铃薯生长周期中更为重要,直接影响马铃薯的产量和质量。目前农业生产者面对种植、病虫害防治等一系列问题主要通过网络查询以获得相关的解决办法。但利用搜索引擎查询相关专业问题时,往往会得到大量的与问题不相关的内容,还需要进行人工的筛选[2]。为此,本研究利用自然语言处理技术、神经网络和深度学习技术,通过构建马铃薯病虫害防治的专业领域知识图谱,以此图谱设计了灵活、便捷和专业的智能查询系统,为农业生产者提供更为相关、系统和多形式的查询方式,及时答疑解惑。
知识图谱的提出源于谷歌优化其搜索引擎的目的,在储存实体和关系上有一定的优越性[3]。主要以三元组作为基础单元将实体?关系?属性相互链接,通过实体、实体属性及实体间的关系来刻画知识关联,构成了一种揭示实体之间关系的语义网络[4]。用图表示知识、储存知识,可以完成智能分析、智能查询和智能问答等一系列自然语言处理任务[5]。知识图谱不仅精确度高、直观性强,而且扩展性和可塑性强,广泛应用于军事、医学、经济和农业等领域,特别是智慧农业,结合领域知识图谱与问答系统的研究方向备受关注且已开展大量研究[6]。
吴赛赛[7] 对大规模数据进行清洗,并采用新型标注方式和实体关系联合抽取有效缓解重叠关系抽取问题。徐帅博[8] 使用Bert-BILSTM-CRF 模型进行命名实体识别,以规则匹配的方式构成三元组关系,并构建了枸杞病虫害知识图谱。吴茜[9] 利用Protégé工具对收集的农业数据进行本体构建,并实现知识图谱可视化。朱淑媛等[10] 利用TensorFlow 框架通过对Word2vec 训练得到其对应的词向量,使获得的词向量空间中包含了实体和关系的语义信息,并通过与Trans E 等3 种模型进行试验对比证实Word2vec 的词向量效果。陈亚东等[11] 将知識图谱的构建过程划分4 个层级,并从8 类数据源中抽取知识,形成了苹果产业知识图谱。张云中等[12] 和LIU S 等[13] 将知识图谱的构建和问答数据库结合,设计了智能问答系统,实现了理论和应用的良好结合。
知识图谱的构建及其在各领域的应用极为广泛,但农业领域的知识图谱构建及应用依然存在较多的疑难点尚未攻破[14]。如大量数据的高质量批处理,实体分类的精准度不够,数据标注较为单一,模型的稳定性和效率不高等问题。因此,本研究以马铃薯病害虫防治知识图谱构建和查询系统的建立为目标,针对目前农业领域知识图谱构建存在的上述问题和挑战,从数据标注方法、实体细粒度分类和模型优化构建方面开展试验和分析。在已有的BIOES 标注基础上,结合试验数据的特点,添加BEMS 标注方式和BIO 标注方式作为对比,试验验证3 种标注方式对知识抽取精度的影响。通过对试验数据特征的深入分析,添加了新的实体类型,即加入“防治”实体及关系使数据结构更加完整。模型构建方面,设计了多种模型进行对比试验以获得更适合本研究数据性能的更优模型用于知识抽取。
1 整体结构
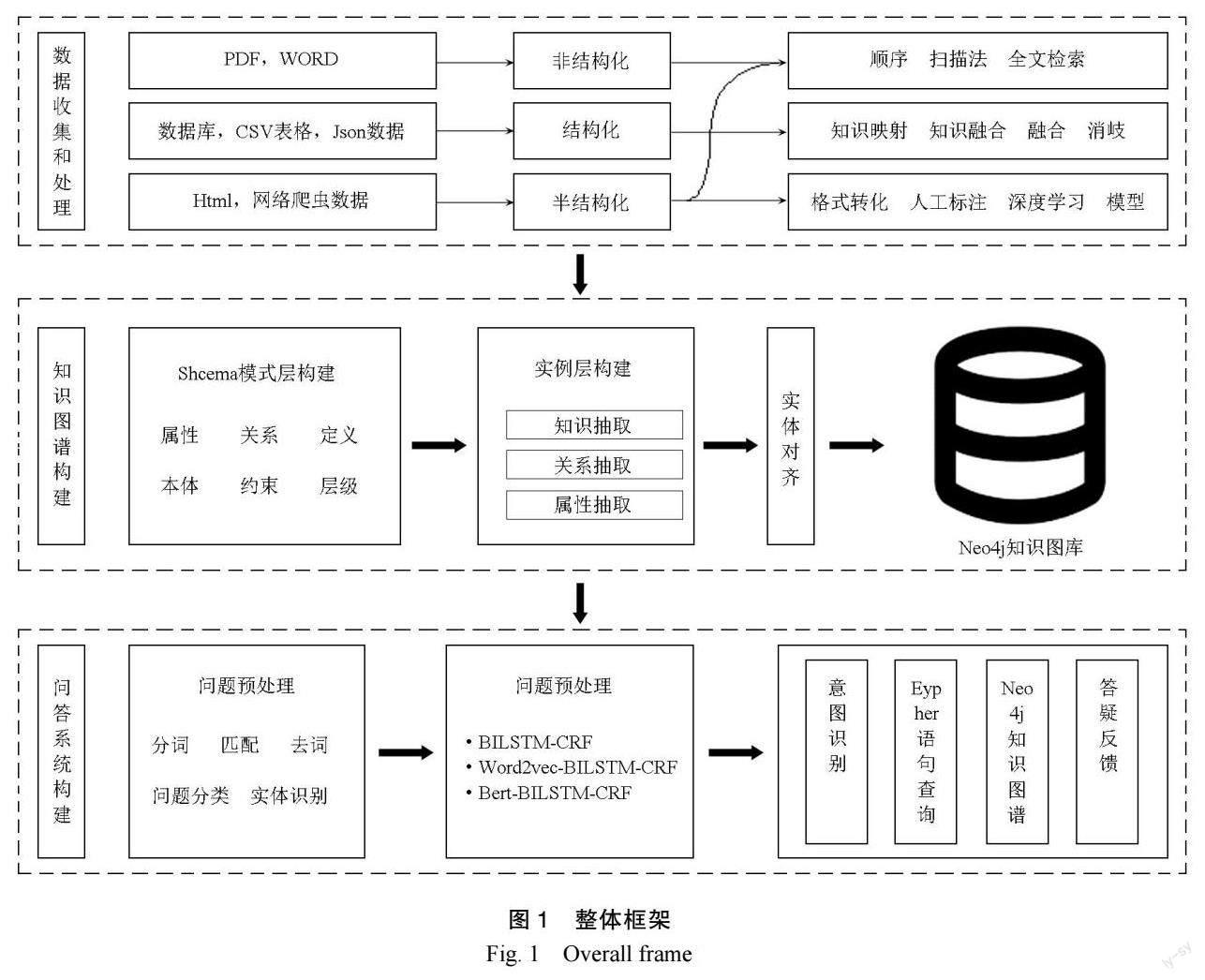
基于马铃薯病虫害知识图谱的问答系统整体结构设计如图1 所示,以自上而下的结构分为数据收集和处理、知识图谱构建及问答系统建立3 部分组成。其中数据收集和处理包含对结构化、半结构化和非结构化3 大类型数据的收集和预处理,分别处理不同类型的数据并对其合理清洗,以保证模型训练数据的高辨识性。知识图谱属于智能查询系统的知识库存储部分,主要包含模式层和实例层构建。模式层采用Shcema 方式构建,也即为实体层。实例层的创建是利用清洗后的数据,抽取出相应的实体及关系,以三元组的形式“实体?关系?实体”或“实体?关系?属性”保存到Neo4j 知识图库。Neo4j 是一种基于Java 的开源图数据库,可将数据存储于灵活的网络结构中,并且具有高性能、高可靠性和高可扩展性等优势,既能更加直观体现实体与实体之间的关系,又提升检索效率[15]。问答系统首先对问题进行预处理,并对用户问题进行识别和分类;之后利用本研究的Bert-BILSTM-CRF 模型进行命名实体识别,利用Bert-textcnn 模型进行意图识别,对用户的问题实现匹配;再通过Eypher 语句查询Neo4j 知识图库中相应的实体关系三元组后将其答案反馈给用户[16-18]。
问答系统展示层以Vue 框架搭建前端展示平台,并接入语音识别和语音播报作为扩展,通过Uniapp 软件使项目整体迁移到手机App 移动端。整个系统以Javascript 和Python 两种语言并行完成项目设计并应用语音、移动端和微信聊天模式等多个功能。
2 知识图谱构建
知识图谱的构建分为模式层框架搭建、数据收集与处理、实例层搭建、命名实体识别及可视化呈现5大部分。首先,分析马铃薯病虫害体系结构、关系和特征,构建模式层的本体框架;然后,标注预处理后的数据,并设计和优化模型准确抽取数据中的实体、关系和属性,形成三元组;最后,结合Neo4j 软件可视化三元组结构。
2.1 模式层定义
模式层作为知识图谱的核心部分,对知识图谱的结构层次和规模起着决定性作用。通过对马铃薯病虫害机理和关联因素的深入分析,构建了马铃薯病虫害知识图谱模式层结构,如图2 所示。主要包含马铃薯病虫害本体、发病部位、分布区域、病原、症状和防治方法6 大实体。
2.2 数据收集与处理
本研究数据主要来源于国家农业科学数据共享中心、维基百科和中国作物种质信息网等,其中大部分是非结构化数据,对于多源及大量的非结构化数据,通过设计爬虫工具获取较为准确的数据。然后对获得的原始数据进行清洗、去重之后保存为Mongo DB 数据库。进一步利用Yedda 标注工具对样本数据进行实体标注后用于知识抽取模型的训练。对标注后的数据整理后获得包括6 种实体类型、8 种关系类型共计8 971个实体样本的训练数据集,将该数据集以6∶2∶2 比例划分为训练集、验证集、测试集,用于命名实体识别试验,训练数据集具体如表1 所示。
2.3 实例层构建
实例层构建需要完成知识抽取、关系抽取和属性抽取3 个阶段,依据不同的疾病和不同的类型,将实体分为疾病名称、发病症状、疾病病原、防治方法和疾病多发地区。关系分为分布区域、防治方法、发病症状、病原名称和发病部位。属性分为疾病别称、适应温度区间、适应pH 值区间和传播途径。以此定义抽取知识以三元组“实体?关系?属性”存储于Neo4j 知识图库。基于此知识库,问答系统对相应的实体进行查询并对其关系和属性进行相应匹配从而输出知识单元。实体及关系的详细定义如表2 和表3 所示。
2.4 实体对齐
实体对齐对于实体的准确抽取和知识图谱的质量起到非常关键的作用。其原因是在大量来源不同的数据中可能均包含同一实体,如果不用实体对齐进行信息融合,会发生在知识图谱中出现实体重复和歧义等现象。早期的实体对齐方法主要依赖于定义各种独立于语言的特征或者机器翻译技术来实现跨语言的连接。近年来,基于嵌入的实体对齐方法将知识图谱嵌入到低维向量空间中进行运算,显著提升了实体对齐效果[19]。本研究采用后者进行实体对齐,具体过程如图3 所示。
式中 xi、yi——词汇
a——向量
b——向量
|a|——向量a 模长
|b|——向量b 模长
当两个向量方向相同时,余弦相似度为1;当两个向量方向完全相反时,余弦相似度为?1;当两个向量互相垂直时,余弦相似度为0。结果表明,夹角越小,代表词汇x 与词汇y 越相似。
2.5 命名实体识别
命名实体识别(Named Entity Recognition,NER)旨在识别文本中具有特定意义或者指代性强的实体。命名实体识别是知识图谱构建的重要环节,其识别准确率的高低直接决定知识图谱的内涵,也是知识圖谱构建的挑战问题之一。传统的命名实体识别方法通常有基于规则、字典的方法,以及无监督学习方法。但在试验中传统命名实体识别方法对于多文本、多实体结构等复杂语料有较大的局限性,具体体现有精准度不够、运行速度缓慢和误差较大等问题。
采用基于特征的监督学习方法,在数据处理中相比于传统方法,此类方法准确率更高,适用于中小型数据。目前,在实体命名识别中常用的经典模型是基于深度学习的BILSTM+CRF 模型,该模型对文本中词义的表达有些欠缺。为此对其进行了改进,在此基础上加入BERT 词嵌入层,通过BERT 词嵌入层将输入文本转化为具有丰富语义的词向量, 然后经过BILSTM 双向编码,可获得全面的上下文信息。但该层不能通过隐藏状态决策标签,最后进过设计CRF 随机向量层思考标签之间的上下关系来获得全局的最佳标签。为了选择最优的词向量层,文本设计了Word2vec-BILSTM-CRF 模型和Bert-BILSTM-CRF 模型进行对比试验,以获得最优的实体命名识别模型。
2.5.1 Word2vec-BILSTM-CRF 模型
在数据集中,各个实体之间相互独立,很难看出向量间存在关系,传统BILSTM-CRF 模型在面对此类数据集,会存在维度灾难和语义缺失等问题。因此采用Word2vec 嵌入对稠密向量将相关向量进行关系链接,很好解决语义缺失等问题。因此,研究采用Word2vec模型的CBOW 算法实现语义表达。CBOW 分为输入层Input layer、隐藏层Hidden layer、输出层Output layer。设词向量空间为β、行数为n,词向量总空间的大小为|β|×n,|β|表示整体词向量词语数量。以样本a 为例,a=“马铃薯青枯病是由青枯假单胞菌引起的、发生在马铃薯的病害”。序列化处理为(r1,r2,…,rm),m 是实体个数;取得ri(1
2.5.2 Bert-BILSTM-CRF 模型
Bert 是基于Transformer 的深度双向预训练语言模型,Transformer 用于将输入语料库转换为特征向量,Transformer 层的核心是通过自注意力函数Attention()计算词与词之间的关联度。
式中 P——预测为正的样本是真正为正样本的概率
R——在样本中的正样本被预测正确概率
F1——结合准确率和召回率的加权和平均
TP——预测正样本
FP——预测负样本
FN——本身正样本预测为负样本
2.6.2 标注方式探究及分析
在知识图谱问答系统中命名实体识别试验非常关键,为了让模型更好识别实体,在进行命名实体识别试验中首先要对语料进行准确标注。为此,设计并探究了BIO、BMES 和BIOES 标注方式对实体识别准确率的影响,以从中选出最佳的标注方式用于知识图谱构建的知识抽取。其对比试验模型设定为Word2vec-BILSTM-CRF。模型的重要参数学习率设置为0.05,Batch_size 为16。在此,首先对3 种标注方式进行详细举例说明。相应举例如图6 所示。
其中,BIO 标注方式中B 代表实体开头、I 代表实体中间、O 代表其他非实体;BMES 标注方式B 表示一个词的词首位值、M 表示一个词的中间位置、E 表示一个词的末尾位置、S 表示一个单独的字词;BIOES标注方式中B 表示开始、I 表示内部、O 表示非实体、E 实体尾部、S 表示改词本身就是一个实体。相比之下,在BMES 和BIOES 两种标注方式对单个实体有很好标注方式,这一点优于BIO 标注方式。
将3 种方式标注的试验样本输入Word2vec-BILSTM-CRF 模型进行对比试验,采用上文中定义的准确率P、召回率R 及F1 值3 项指标对试验结果进行综合评测,其值如表4 所示。为了更直观地体现对比试验结果,采用图形对比显示F1 值(图7)。由表4 和图7 可知,采用模型Word2vec-BILSTMCRF识别实体,BEMS 标注方式下模型输出的F1 值最高,BIO 标注方式F1 值略有偏差,BIOES 标注方式的效果较为逊色,可能的原因是BIOES 标注中实体边界比较模糊,负样本数量较多,对效果产生负面影响。
2.6.3 模型性能分析
为探究本研究设计的Bert-BILSTM-CRF 模型在命名实体识别方面的优越性,采用表1 列举的试验数据,试验验证较优的BEMS 标注方式训练模型实现实体识别,并且与Word2vec-BILSTM-CRF、BILSTM-CRF 模型进行了对比试验,其结果如表5 所示。为了更直观地表达3 种模型的优越性,对3 种模型的F1 值做出了对比值,结果如图8 所示。
由表5 和图8 可知,在相同数据集下Bert-BILSTMCRF模型相较于BILSTM-CRF、Word2vec-BILSTM-CRF两种模型在F1 值上分别提升了18.23 和8.61 个百分点,并在速度上优越于其他模型,在第一个Epoch 训练中F1 值已经达到71.82%。进一步说明Bert 对模型输入层进行了优化,提高了文本特征提取的准确率,解决了部分模型不宜学习长文本数据和一词多义的问题,而Bert 模型生成的字符级动态特征向量可以很好地解决这类问题,试验结果也证明了在相同的条件下Bert-BILSTM-CRF 模型在命名实体识别方面更为效性。
2.7 知识储存及可视化
采用Neo4j 图数据库形式来储存数据,相比其他存储方式,图数据具有扩展性强、更加直观和稳定性强等优势。将试验中获得的三元组数据通过驱动工具Py2neo 导入Neo4j,然后采用Cypher 语言编程实现图谱可视化,文本构建的马铃薯病虫害知识图谱可视化如图9 所示。
3 问答系统设计
3.1 问答终端整体结构
基于马铃薯病虫害知识图谱的智能问答系统是一种很有价值和实践指导的应用方式。为了能够将其更为便捷地使用,设计了在线和离线端分离两种模式的问答系统,结构如图10 所示。
在线端以Python 为基础语言对输入问题进行命名实体识别并在Neo4j 知识图库检索最佳答案反馈给用户。离线端以Java 为基础语言,搭建相应数据库,利用Vue 前端框架搭建问答交互网页对问题采用自上往下方式进行数据库检索并反馈用户。
3.2 在线问答系统
在线问答系统利用常规自然语言处理技术,包括问题预处理、问题识别分析、Neo4j 知识图库检索最佳答案和反馈用户4 部分组成。
3.2.1 问题预处理
问题预处理首先利用Python 自带的Jieba 分词对用户输入的问题进行分类,以增加系统的处理效率,使用户可以更加便捷、快速地实现查询。本系统将马铃薯病虫害问题划分闲聊、症状类问题、防治类问题、属性类问题、周期性问题和其他类问题6 个类别。闲聊类问题如你好、再见、你叫什么名字等;症状类问题如马铃薯青枯病的发病症状、马铃薯早疫病的叶子变化等;其他问题属于马铃薯病害虫领域的相关了解部分包括对于发病地区和易发病环境的问答,对用户有一定的指导意义,详细内容如表6 所示。
3.2.2 问题识别分析
问题识别分析是对以上划分的类别进一步详细处理,首先,采用Bert+Text CNN 文本分类模型实现对用户意图的识别,其目的是判断用户的Query 属于哪一类问题,其次,建立语义槽,对问题进行槽位填充。如问句:“马铃薯青枯病的发病原因”其中“马铃薯青枯病”和“发病原因”分别作为疾病名称和疾病发病原因的语义槽,结合命名实体识别任务,进行槽位填充。
采用Bert+Text CNN 模型完成意图识别和文本分类任务,通过Bert 模型对问题进行向量化处理后利用Text CNN 对多个不同的Kernel size 提取句子中的關键信息, 将不同的Kernel size 的结果进行拼接实现Pooling(对其用中文解释)操作,以更好地获取文本的局部特征,最后对特征进行拼接完成用户的意图识别,其试验结果如表7 所示,准确率达到92%。
3.2.3 Neo4j 知识图库检索
使用Cypher 语句对Neo4j 图数据库进行查询,对于用户的问题进行分类后,在6 类不同的用户意图类别下分别搭建相应的查询语句模板,如查询“马铃薯早疫病的防治方法”,系统首先进行命名识别得到实体“马铃薯早疫病”,之后通过意图识别进行问题分类到“疾病防治”类别进行检索,对应的Cypher 查询语句为:Match(a)-[:has prevent]-(b)where b.name=“马铃薯早疫病”return a.name.
3.2.4 问答交互
利用前端技术搭建问答框架,即将Python 中的Py2neo 与Neo4j 图数据库连接,可以满足用户与系统实时交互。用户向系统提出问题,系统将接收信息输入Neo4j 图数据库,再将反馈信息通过窗口化反馈,本系统构建的问答交互界面如图11 所示。
3.3 离线问答系统
离线系统基于JavaScript 语言设计,并采用相关的轻便型框架进行搭建,常见的Web 框架有Flask、Vue框架等。Vue 框架的特点是轻量级、体积小,比较适合快速的开发,并且运行效率较高,生态丰富,学习成本低[20]。所以本系统构建采用Vue 框架。总体分为内置数据库搭建、问答交互和页面可视化。
3.3.1 内置数据库搭建
内置数据库搭建采用MOCKJS 模拟后端接口,生成所需数据,可模拟对数据的增删改查。优势在于前后端分离,可随机生成大量的数据,用法便捷,数据类型丰富,可扩展数据类型。
3.3.2 问答交互
问答交互采用Element 框架构建,以搜索查找模式进行交互,并调用科大讯飞语音问答功能扩展本项目功能。本系统问答交互页面如图12 所示。
通过对数据库的双向Context 绑定,对相应问题点击详情, 即可跳转疾病详情页。查询功能基于Javascript 中的Dom 属性设定,对于问句逐字拆分,如“马铃薯虫害”,拆分为“马”“马铃”“马铃薯”“马铃薯虫”和“马铃薯虫害”5 部分,然后从前往后对内置数据库进行遍历,筛选出最佳对象并进行反馈。
3.3.3 可视化展示
Echarts 模块是以JavaScript 语言为基础的一款可视化图标库。利用该模块搭建初始化页面,设计图谱,通过与内置数据库产生联调,生成相应三元组视图,问答系统的可视化如图13 所示。
通过Vue 框架中的内置API 指令V-mode 对点击事件和内置数据库进行双向绑定,通过点击图谱即可跳转详情页进行查看,使用更加便捷。
4 结束语
农业智能化是未来的发展趋势,而农业知识图谱是智能化的基础。以深度学习、Neo4j、命名实体识别和Javascript 等技术为基础构建了马铃薯病虫害的知识图谱,基于此图谱设计实现了多模式的问答系统,系统不仅交互便捷,其知识量丰富且精准,知识间的语义关联更加紧密,而且该系统的可扩展性较强,可方便地应用于马铃薯生产领域。
知识图谱问答系统的构建中,实现从大量非结构化数据中抽取实体、关系和属性等知识最为关键,其中模型的构建和数据标注方式是主要影响因素。为此,设计了BIO、BIOES 和BEMS 标注方式,并对其在同一模型上进行对比试验,结果证明了BEMS 标注方式在本试验中效果最佳,可将F1 值提升2.29 个百分点。在前期研究的基础上设计了Bert-BILSTM-CRF 的知识抽取模型, 并与BILSTM-CRF 和Word2vec-BILSTMCRF模型进行试验对比。在同样的BEMS 数据标注方式下,模型Bert-BILSTM-CRF 的加权平均F1 值最高。
说明本设计模型在利用BERT 解决语义缺失和一词多义等问题后模型性能大大提高,能够准确地抽取非结构化数据中的知识,进一步提升问答系统中问句实体的识别率,实现精准问答。由于在马铃薯病害虫领域数据量有限,模型在性能上还有提升空间,接下来将进一步优化数据集和模型输入层,以获得更好的试验效果。
参考文献
张克艳,谢冬.甘肃省马铃薯产业发展现状与前景展望[J].农村经济与科技技,2020,31(1):227,238.
陶永芹.专业领域智能问答系统设计与实现[J].计算机应用与软件,2018,35(5):95-101.
TAO Yongqin. Design and implementation of intelligent question answeringsystem in professional field[J]. Computer Applications andSoftware,2018,35(5):95-101.
XIAO G , CORMAN J. Ontology-mediated SPARQL query answeringover knowledge graphs[J]. Big Data Research, 2020, 23:100177.DOI:10.1016/j.bdr.2020.100177.[3]
劉峤,李杨,段宏,等.知识图谱构建技术综述[J].计算机研究与发展,2016,53(3):582-600.
LIU Qiao,LI Yang,DUAN Hong,et al.Knowledge graph constructiontechniques[J]. Journal of Computer Research and Development,2016,53(3):582-600.
孙亚茹,杨莹,王永剑.基于知信图卷积神经网络的开放域知识图谱自动构建模型[J].计算机工程,2022,48(10):116-122.
SUN Yaru, YANG Ying, WANG Yongjian. Knowledge graph automaticconstruction model in open domain based on knowledge-informedgraph convolutional neural network[J].Computer Engineering,2022,48(10):116-122.
申存,黄廷磊,梁霄.基于多粒度特征表示的知识图谱问答[J].计算机与现代化,2018(9):5-10.
SHEN Cun, HUANG Yanlei, LIANG Xiao. Knowledge graph questionanswering based on multi-granularity feature representation[J].Computer and modernization,2018(9):5-10.
吴赛赛.基于知识图谱的作物病害虫智能问答系统[D].北京:中国农业科学院,2021.
WU Saisai. Design and implementation of intelligent question and answeringsystem for crop diseases and pests based on knowledgegraph[D]. Beijing: Chinese Academy of Agricultural Sciences,2021.
徐帅博.基于枸杞病虫害知识图谱的问答系统研究与实现[D].银川:宁夏大学,2020.
XU Shuaibo. Research and implementation of question answering systembased on diseases and pests knowledge graph of lycium barbarum[D].Yinchuan:Ningxia University,2020.
吴茜.基于知识图谱的农业智能问答系统设计与实现[D].厦门:厦门大学,2019.
WU Qian.Design and implementation of agricultural intelligent Q & Asystem based on knowledge graph[D]. Xiamen: Xiamen University,2019.
朱淑媛,罗军.基于本体的领域自动问答系统研究[J].计算机应用与软件,2019,36(8):98-105,154.
ZHU Shuyuan, LUO Jun. Domain automatic question answering systembased on ontology[J].Computer Applications and Software,2019,36(8):98-105,154.
陈亚东,鲜国建,寇远涛,等.我国苹果产业知识图谱构建研究[J].中国农业资源与区划,2017,38(11):40-45.
CHEN Yadong,XIAN Guojian,KOU Yuantao,et al.Study on constructionof knowledge graph of apple industry in China[J]. ChineseJournal of Agricultural Resources and Regional Planning, 2017,38(11):40-45.
张云中,郭冬,王亚鸽.基于知识图谱的红色历史人物知识问答服务框架研究[J].图书情报工作,2021,65(16):108-117.
ZHANG Yunzhong,GUO Dong,WANG Yage.Framework of knowledgeQ & A service for red historical figures based on knowledgegraph[J].Library and Information Service,2021,65(16):108-117.
LIU S, TAN N, YANG H, et al. An intelligent question answeringsystem of the Liao dynasty based on knowledge graph[J].InternationalJournal of Computational intelligence Systems,2021,14(1):1-12.
丁晟春,侯琳琳,王颖.基于电商数据的产品知识图谱构建研究[J].数据分析与知识发现,2019,3(3):45-56.
DING Shengchun, HOU Linlin, WANG Ying. Product knowledgemap construction based on the e-commerce data[J]. Data Analysis andKnowledge Discovery,2019,3(3):45-56.
张琳,熊斯攀.基于Neo4j 的社交网络平台设计与实现[J].情报探索,2018(8):77-82.
ZHANG Lin,XIONG Sipan.Design and implementation of social networkplatform based on Neo4j[J]. Information Research, 2018( 8) :77-82.
DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training ofdeep bidirectional transformers for language understanding[J].2018.DOI:10.48550/arXiv.1810.04805.
MIKOLOV T, CHEN K, CORRADO G, et al. Efficient estimationof word representations in vector space[C]// Proceedings of the InternationalConference on Learning Representations (ICLR 2013),2013.
ESULI. EMNLP 2015: Empirical methods in natural language processing[C]// Empirical Methods in Natural Language Processing.http://www.emnlp2015.org/submissions.html.
車超,刘迪.基于双向对齐与属性信息的跨语言实体对齐[J].计算机工程,2022,48(3):74-80.
CHE Chao,LIU Di.Cross-language entity alignment based on bidirectionalalignment and attribute information[J]. Computer Engineering,2022,48(3):74-80.
李航.统计学习方法[M].北京:清华大学出版社,2012.陈倩怡,何军.Vue+Springboot+MyBatis 技术应用解析[J].电脑编程技巧与维护,2020(1):14-15,28.
