基于特征增强和校准的航拍车辆实例分割方法
2024-01-20姚俞成李旭徐启敏孔栋
姚俞成,李旭,徐启敏,孔栋
东南大学 仪器科学与工程学院,南京 210016
近年来,搭载视觉传感器的无人机在智能交通系统领域已成为一种重要工具,相较于传统载体,无人机成本更低,灵活的可部署性使其受到的空间环境因素制约较少,能快速适配不同任务需求开展数据收集[1],且无人机航拍可提供更广的视角,进而可为智能化交通监管提供更丰富多样的数据来源。随着交通状况的愈加复杂,基于航拍视角的车辆实例分割技术是当下无人机应用于智能交通监管领域的研究热点,对推动智能交通系统的构建与发展具有重要意义。基于航拍视角的车辆实例分割不仅包含车辆个体层面的位置信息,还实现了对车辆像素级的分割,即实例分割技术同时完成了目标检测和语义分割目的的更高层级的任务[2]。此外,实例分割可以很好地抑制车辆外的背景像素,以便于智能交通系统后续的高层复杂视觉任务(例如车辆重识别、语义地图制作等)的应用。
概括地讲,航拍视角下的车辆实例分割算法主要遵循2 种路线,一是基于语义分割网络自下而上的路线,二是基于目标检测网络自上而下的路线。
1)基于语义分割网络的方法
基于语义分割网络的方法一般遵循先分割后检测的范式,首先对图像进行像素级的分割,再使用聚类等方法区分不同的实例,得到实例掩码。Mou 和Zhu[3]提出一种基于边界的语义分割多任务学习模型,将车辆实例分割划分成车辆区域语义分割和边界语义检测2 个子任务,利用边界语义检测子网络辅助车辆区域语义分割子网络以区分不同车辆实例,并在BPL[3]数据集上取得了初步的实例分割效果。Ammour 等[4]则提出了一种结合了图像分割算法和深度学习算法的车辆实例分割方法,首先用均值漂移聚类算法分割出不同尺寸的同质区域,其次使用预训练的VGG[5]网络提取每个区域内的图像特征,然后使用支持向量机SVM 将像素分类为“车”和“非车”,最后进行区域平滑和合并,该方法由于主要使用了机器学习的聚类方法和层数较少的深度学习网络,因此对训练数据依赖较小,推理时间也较低。Audebert 等[6]将实例分割分为3 个步骤,首先是使用SegNet[7]对无人机图像进行语义分割,其次使用图形学开运算腐蚀车辆掩码以区分不同车辆实例,最后使用预训练的分类网络VGG-16 对每个掩码进行分类。基于语义分割网络的方法一般依赖于车辆尺度等先验信息,仅仅适用于高度固定的垂直视角的航拍图像,一旦高度变化或视角倾斜,会导致精准度显著降低,泛化性能差,且后处理步骤较为繁琐,难以实现端到端训练。
2)基于目标检测网络的方法
基于目标检测网络的方法则一般先通过目标检测定位出包含每个实例的检测框,再在检测框内部分割出每个实例掩码。基于目标检测网络的实例分割方法可以分为一阶段方法、二阶段方法和多阶段方法。对于一阶段方法,YOLACT[8]将实例分割任务划分为2 个子任务:一个分支负责生成一系列原型掩码另一个分支负责针对每个实例预测其掩码系数。CondInst[9]在YOLACT 基础上引入对相对位置信息较为敏感的条件卷积提升了预测效果。FB-ISNet[10]在CondInst 基础上进行改进,将深度聚合网络DLA[11]作为骨干网络,同时将双向特征金字塔BiFPN[12]引入CondInst 从而实现多尺度特征融合,将其应用在了遥感图像实例分割领域。一阶段网络结构简洁,去除了候选框提取网络,因此效率较高,但由于原型掩码分支使用的特征图分辨率较低,因此整体精度较低。对于二阶段方法,Mask R-CNN[13]在目标检测网络Faster R-CNN 的基础上增加掩码分支实现了实例分割。受目标检测中旋转检测框的启发,Mask OBB[14]将旋转矩形框的回归问题转换成像素级分类问题以消除旋转矩形框定义的模糊性,提出了用于增强特征提取的特征横向连接网络和用于提供语义特征的语义注意力网络,从而使掩码分割分支能更有效地区分前景和背景。同样受旋转检测框启发,Pan 等[15]提出了旋转候选框方法,在RoI 模块后增加一个旋转RoI 匹配模块,以有监督地将水平检测框转换成旋转检测框。为了避免RoI 池化中的量化操作,Hu 等[16]使用精确RoI 池化在池化过程中采用双线性插值以避免量化操作,并自适应地学习池化子区域的个数,从而使候选框更加精确,Zhang等[17]则使用多尺度自适应融合模块和区域注意力模块对Mask R-CNN 进行改进,同时提出了UVSD 航拍车辆实例分割数据集。二阶段网络由于候选框提取网络去除了大量背景,所以掩码分支简单易学,且对于小目标检测效果较好,整体精度较高,是应用最为广泛的网络类型。对于多阶段方法,Cascade Mask R-CNN[18]通过分别级联多个检测框分支和多个掩码分支,实现了高精度的实例分割。HTC[19]在Cascade Mask RCNN 的基础上进行改进,将检测任务和分割任务进行交互并融入语义分割分支提高预测效果。HQ-ISNet[20]则基于Cascade Mask R-CNN 对特征金字塔和掩码分支进行改进并应用于遥感图像。多阶段网络基于逐阶段精细化预测的思想,对二阶段网络在精度上有了进一步提高,但由于其级联多个分支的特性,网络参数量和计算量都较大。
综上,基于目标检测的方法分割精度相对较高,支持端到端训练,部署方便且泛化性更好,是当前实例分割的主流方法。然而,当前基于目标检测网络的实例分割方法大都面向通用目标或垂直视角的遥感图像场景,难以适应车辆分布密集、车辆遮挡多、车辆尺度变化大的航拍车辆实例分割任务。
针对以上问题,本文提出了一种基于特征增强和校准的航拍车辆实例分割方法,其主要创新点如下:
1)本文提出一种多尺度语义增强模块(MSEM),充分利用骨干网络中的高层语义特征,通过多个空洞卷积块,实现对特征的多次重用,实现对多尺度语义特征的融合,最后将融合特征输入空间注意力模块,抑制冗余信息,增强特征表达。MSEM 可以应对航拍车辆实例分割中车辆尺度变化大的问题,提高不同尺度车辆预测效果。
2)本文提出一种全局-局部特征校准模块(GLFCM),其子模块全局特征校准模块(Global Feature Calibration Module,GFCM)整合特征金字塔中多个尺度的特征,利用通道注意力和自注意力机制学习全局特征之间的依赖关系,实现全局特征的校准;其子模块局部特征校准模块(Local Feature Calibration Module,LFCM)利用改进的多头自注意力机制Transformer[21]抑制局部特征中的干扰信息,实现局部特征的校准。GLFCM 可以充分挖掘全局特征的上下文信息以提高小尺度车辆的预测效果,同时抑制局部干扰以应对车辆的遮挡问题。
1 本文方法
特征金字塔结构是在实例分割网络中广泛应用的模型结构,其使用侧向连接的方法,自上而下地将高级的语义特征融合到多个尺度的特征图中,并输出多个尺度的特征图到后续头部网络进行预测。在特征融合阶段,高层特征会自上而下地将丰富的语义信息逐级融合到低层特征中,但在开始融合前,高层特征经过侧向连接,其通道数会减小为原来的1/4,从而一定程度上造成了语义信息的损失。ThunderNet[22]采用全局平均池化的方法压缩特征空间信息,利用广播操作与不同层次的特征相加来抑制语义信息的损失,但使用池化操作融合特征图会将特征图压缩成一维向量,直接丢失了大量空间关系信息,对于有多目标密集分布的航拍图像并不适用。因此,本文提出多尺度语义增强模块(Multi-scale Semantic Enhancement Module,MSEM)嵌入特征金字塔结构,其结构如图1 中MSEM 所示,在不损失空间关系信息的前提下,MSEM 充分利用高层特征,使用多个空洞卷积密集连接的结构提高其在后续特征融合阶段的多尺度适应性,并增加空间注意力结构以捕获各个子区域的语义信息依赖关系。
同时,为了抑制特征图中的冗余信息,许多研究将注意力模块添加到特征金字塔结构和头部网络之间以对各通道特征进行重新校准,然而,这些方法往往只对特征金字塔中各个尺度特征图分别进行“局部”校准。无人机视角下的视觉任务中,全局上下文信息对于各个尺度目标的预测效果都有十分关键的作用,且航拍图像的分辨率高、噪声干扰多等特点,因此,为了实现全局多尺度特征之间的信息交互和特征校准,同时充分抑制局部特征的干扰以提取精确的位置信息,本文提出全局-局部特征校准模块(Global-Local Feature Calibration Module,GLFCM),其结构如图1 中GLFCM 所示。GLFCM 分为2 个部分:全局特征校准模块(GFCM)和局部特征校准模块(LFCM)。GFCM 主要构建全局各层次的特征之间的依赖关系,LFCM 则使用高效的多头局部注意力,分别对各个尺度特征进行特征校准,将特征图映射到多个独立的注意力子空间进行学习,均衡单个注意力子空间可能产生的注意力偏差,提高单一尺度特征内部信息整合的多样性,同时为了减少参数量和计算量,本文对注意力模块进行了线性化。其整体的模型结构如图1所示。
1.1 多尺度语义增强模块MSEM
主干网络自底向上提取的特征图为{F2,F3,F4,F5},其示意如图2 所示,在特征金字塔网络中,通过侧向卷积,生成一组通道数一致的特征图{L2,L3,L4,L5},特征图通道数一般都为256,生成的L5会自上而下地逐级与{L4,L3,L2}以直接相加的方式进行特征融合,得到最终输出{P2,P3,P4,P5},在自上而下融合过程中,较低层次的特征会从较高层次的特征上获得更丰富的语义信息,从而具有更丰富的上下文信息表示,但是在特征金字塔自上而下逐级融合的过程中存在2点不足:①转化过程的中间特征L5仅包含单一尺度的特征,多尺度信息不够丰富。② 在F5→P5的转化过程中,特征通道数会减少为原来的1/4,存在很大的特征损失;

图2 主干网络提取特征示意图Fig.2 Features extracted from backbone
因此,针对以上问题,为了在不增加卷积核大小的情况下提取不同尺度的特征,MSEM 模块使用多个空洞卷积丰富高层语义特征的多尺度信息;为了在不增加额外特征层的情况下融合空洞卷积提取到的特征,MSEM 模块以密集连接的结构对多尺度特征逐级融合,最终使用一个空间注意力模块抑制其中部分噪声,并将融合特征添加到原特征中,以实现特征增强,缓解特征损失的作用。增强特征在后续与各个尺度特征的融合过程中,为其提供了更丰富的多尺度信息,从而有利于提高其多尺度适应性,最终提高其对不同尺度车辆的预测效果。MSEM 模块仅对F5进行处理,为研究增加增强特征的数量对网络效果的提升作用,本文增加了相关对比实验,实验结果及分析见附录A。MSEM 网络结构如图3 所示。
具体地,MSEM 模块的5 个空洞卷积块的空洞率分别为{3,6,9,12,18},对于第l个空洞卷积块,为了适应性地融合多个尺度的特征,本文参考DenseNet[23]提出的密集连接结构,同时为了避免语义特征的通道损失,将原始的特征图和前l-1 个空洞卷积块的所有输出沿通道进行拼接,作为第l个空洞卷积块的输入,即
式中:xl为第l个空洞卷积块输出的特征图,Dl为第l个空洞卷积块。
在卷积块内部,为了控制整个模型的大小,使用通道降维的方法减少内部计算量,首先使用卷积核大小为1 的卷积将通道压缩到512,其次进行组数为32 的组归一化,然后使用ReLu 进行激活,之后进行空洞卷积,同时将通道数再次压缩到256,然后通过ReLu 激活函数,最后使用Dropout 操作以提高模型的鲁棒性。
DenseNet 的提出主要是为了在减小参数量的情况下缓解神经网络加深过程中的梯度消失问题,并增强特征的传递和特征重用,将密集连接引入MSEM 模块主要是为了在减少通道特征的损失的前提下,以一个合理的网络结构,融合不同尺度的上下文信息,缓解特征在自上而下传递过程中出现的特征尺度不匹配问题,并对特征多次重用,增强特征表达。
尽管通过MSEM 模块输出的特征图融合多尺度的特征,但并非所有位置的特征都是有效的,为了捕捉融合特征中各个子区域中重要的特征,本文将输入空间注意力模块。对于空间注意力模块,其主要关注特征中不同位置上的哪些特征更为重要,首先将沿通道方向进行平均池化操作AvgPool(·)得到和最大池化操作MaxPool(·)得到,2 种池化操作可以保留中不同数值大小的信息,同时压缩通道减少网络参数量,将得到的压缩特征图沿通道拼接后通过一个卷积层conv(·)学习特征不同位置的权重,从而抑制不重要位置的噪声,强调重要位置的特征,然后通过一个Sigmoid 激活函数σ(·)进行激活,最后以残差连接的方式与得到最终空间注意力特征图相加得到最终输出P5,即
经过MSEM 模块输出的特征P5,中间特征和主干网络提取的特征F5的对比如图4 所示,可以看到相较于F5,不同尺度的信息更加丰富,而经过空间注意力模块输出的P5相较于保留了各个子区域中更为重要的信息,抑制了部分噪声。

图4 MSEM 模块中间特征示意图Fig.4 Intermediate features in MSEM
1.2 全局特征校准模块
尽管通过MSEM 将丰富的多尺度语义信息自上而下地逐级进行融合,并且避免了通道特征的损失和特征尺度的不匹配问题。但仅仅依靠自上而下的特征融合,仍然无法从全局角度学习到不同特征通道之间的依赖关系,因此本文提出全局特征校准模块(GFCM),由于GFCM 中没有引入任何降低特征分辨率的下采样操作,因此可以在不损失信息的同时更充分地对全局特征进行校准。
式中:Wi∈R1×1×2C×C为卷积层权重;⊙表示广播点乘操作;‖表示通道级拼接操作。
至此,各层级特征完成了层级间充分的信息交互和校准,从而具备了真正意义上的全局信息。GFCM 模块效果对比如图5 所示,第1 行为特征金字塔输出的5 层特征图,第2 行为GFCM模块校准后的5 层特征图,可以看到校准后各层级的特征发生了明显的信息交互,从而具备较为完整和丰富的全局信息,更有利于提升整体网络的预测效果。

图5 GFCM 校准效果图Fig.5 Calibration effect of GFCM
1.3 局部特征校准模块
MSEM 和GFCM 会对各个尺度的特征进行融合并对全局特征重新校准,使得各个尺度的特征具有跨特征层次的全局上下文信息,这对小目标检测十分有效,但航拍图像中,背景复杂,干扰多,而局部特征对抑制干扰,提取精确的位置信息也有非常重要的作用。因此本节提出一个具有多头结构的局部特征校准模块(LFCM)对GFCM 输出的每个层次的特征分别进行局部特征校准,以丰富当前尺度特征的局部特征表示,得到局部特征校准后的特征其网络结构如图6 所示。多头结构将特征图映射到多个独立的注意力子空间进行学习,其因此注意力模型更容易收敛,Pecoraro 等[25]量化分析了多头结构在对特征之间的依赖进行建模的过程中,无论从特征关系的数量还是参数维度,其规模都小于单头结构,也因此更为高效。同时,LFCM 还结合了改进的线性自注意力模块,可以极大减少局部特征提取的计算和空间复杂度。值得一提的是,多头结构支持多头并行计算,因此对比单头结构并不会增加额外的计算的时间。
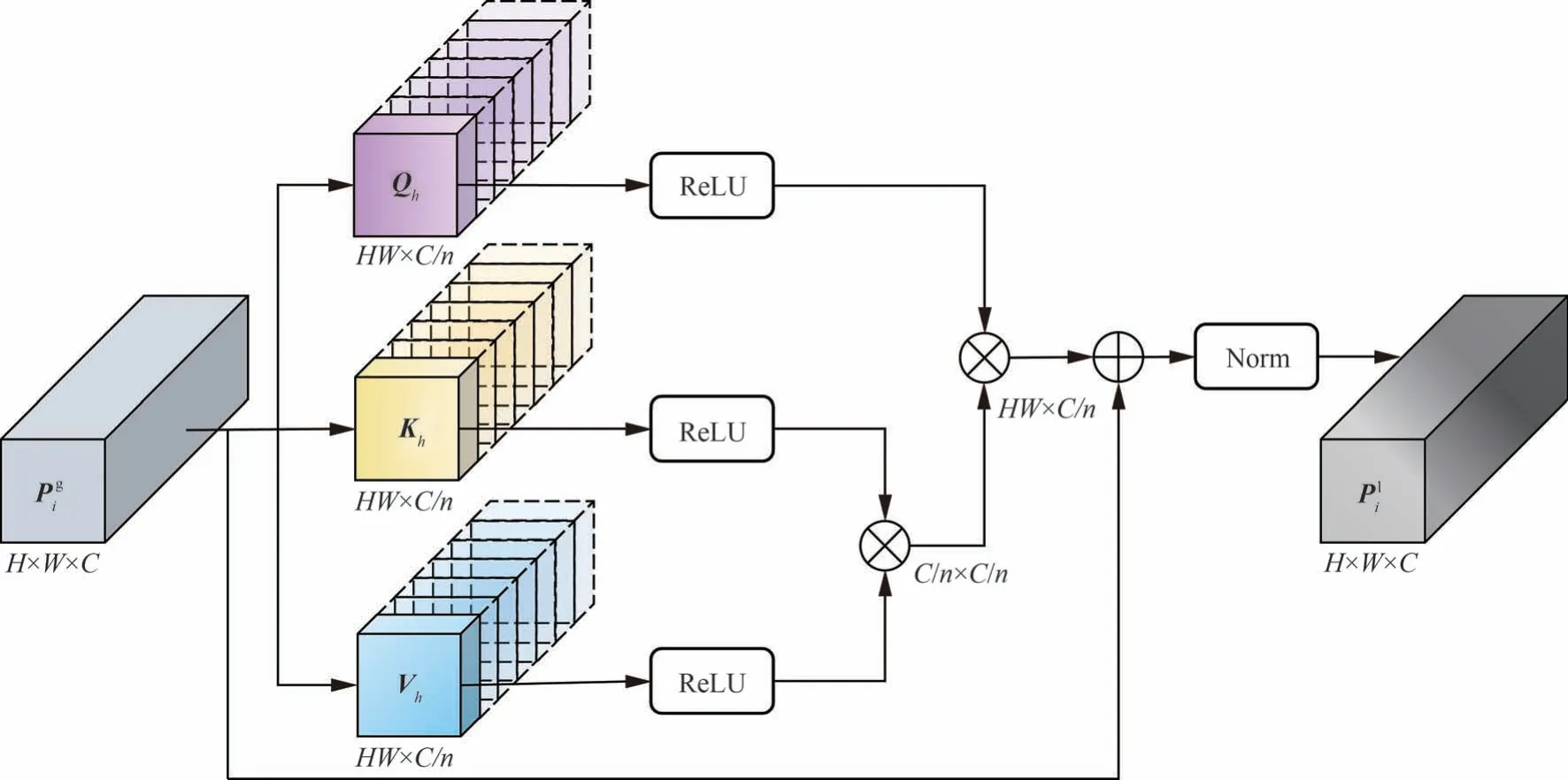
图6 LFCM 网络结构Fig.6 Network structure of LFCM
接下来,需要将局部特征映射到多个子空间,具体地,设局部特征头数为n∈N+,将Q、K、V按通道方向切分成n份并转换成二维张量,对于第h个头,得到其输入(Qh、Kh、Vh)
接着在每个头内部,对Qh、Kh、Vh使用自注意力机制Transformer 进行自注意力运算即可。然而,Transformer 模块具有极高的计算复杂度和空间复杂度,具体来说,对于第h个头内部的Transformer 模块A(·) 可以定义为输入是Qh、Kh、Vh矩阵的计算局部自注意力矩阵Mh∈RHW×C/n的函数,其输出Mh可以表示为
式中:sim(qi,kj)为计算Qh矩阵通道i的特征qi∈R1×C/n与Kh矩阵通道j的特征kj∈R1×C/n的相似度函数,普遍方法是使用即整体结构变成矩阵点积函数与Softmax 归一化函数的结合。值得注意的是,Softmax 操作具有2 种非常重要的性质:①Softmax 可以保证注意力矩阵的非负性;② Softmax 以一种非线性重加权机制使注意力特征分布在训练过程中保持稳定。但是Softmax 操作与特征图大小的平方(H2W2)正相关,计算Mh的时间复杂度达到O(H2W2C/n),空间复杂度达到O(H2W2),在航拍图像中这样的高分辨率是无法容忍的。为了将时间和空间复杂度降低到线性,一些学者将sim(qi,kj)推广到核函数的形式[26],去掉Softmax归一化形式,式(10)可以重写成
式中:ϕ(·)表示一种核函数,意在将qi、kj映射到核函数定义的核空间,其相似度就可以以核空间向量的内积进行度量,此时Transformer 的时间和空间复杂度就有了线性化的可能,由矩阵乘法的结合律可知
因此,可以将式(11)进一步化简,得到
此时 Transformer 的时间复杂度为O(HW(C/n)2),空间复杂度为O((C/n)2),对于图像的特征图来说通常有HW≫C/n,因此这对于时间空间复杂度是极大的优化。例如Katharopoulos 等[27]就选择ϕ(·)=elu(·)+1 作为核函数。
受NLP 领域中cosFormer[28]及其对比实验的启发,为了保证注意力矩阵的非负性,同时抑制负相关信息的干扰,本文选择ReLU(·)作为核函数ϕ(·)嵌入Transformer 模块从而有效避免负注意力值的出现,代入式(13),得到
在原始的cosFormer 中,为了增强对局部特征的学习,减弱过远的距离的信息关联,采用了余弦分解的方法进行权值平衡,但该方法主要针对一维信息,不适用于航拍图像等二维信息,且在视觉任务中,卷积网络本身也具有较强的局部性,因此本文没有使用原cosFormer 中的权值平衡后处理方法。
线性化注意力模块可以即插即用地嵌入网络模型,易于部署和实现,并以较低的时间和空间代价提高模型的局部特征表示能力。在本文的多头模型中,每个头内部都独立部署了本节的线性化注意力模块。
经过LFCM 之后得到第h个头的输出Mh∈RHW×C/n,将n个头的输出转化为三维张量,并在沿通道进行拼接,得到整体的输出
不同LFCM 校准效果对比如图7 所示,第1 行为GFCM 模块输出的5 层待校准特征图,第2、3 行分别为原始Transformer 构成的LFCM 模块和线性Transformer 构成的LFCM 模块进行局部特征校准后输出的5 层特征图,可以看到2 种LFCM 对每个层次的局部特征中的噪声均具有一定抑制作用,输出的各层次特征具有更精确的位置信息。线性LFCM 模块在分辨率较低的对噪声抑制较好,这会使得其在预测相对较大尺度的车辆时表现更好,但在分辨率较高的其特征却不如显著,这可能会一定程度上降低整体网络在预测小尺度车辆时的精度。

图7 不同LFCM 校准效果对比图Fig.7 Comparison of calibration effects of different LFCMs
2 实验与分析
2.1 数据集与实验设置
采用具有挑战性的航拍车辆实例分割数据集UVSD[17]进行广泛的实验验证,UVSD 包括城市道路、郊区、停车场、高速公路等场景的数据,其数据具有多视角、尺度变化大、有局部遮挡、分布密集、光照变化大等特点,其中包含5 874 张4K 图片共98 600 个高质量实例级标注的车辆,平均每张图片车辆数高达150 辆。该车辆实例分割数据集的主要难点在于:①车辆分布密集,车辆或其他物体如路灯、树木等会对车辆实例形成遮挡。② 无人机拍摄角度和飞行高度变化大,数据包含垂直拍摄视角和倾斜拍摄视角,飞行高度覆盖10~150 m,车辆实例的尺寸变化较大,包含了许多小目标。③场景光照变化大,包含夜晚,强光直射,且通过图像处理手段对数据的亮度、对比度进行调整,还增加了很多干扰噪声和模糊处理。依照基准实验的配置,使用3 564 张图片作为训练集,585 张图片作为验证集,1 725 张图片作为测试集。
数据集的标注信息被转化成COCO 格式,因此也采用COCO 标准作为评价标准,网络的有效性可以使用所有类别平均精度的均值mAP(mean Average Precision)体现,由于车辆实例分割任务只包含一个类别,因此mAP 等价于AP(Average Precision)。根据COCO 标准,AP50表示交并比IoU 阈值为0.5 时的平均精度,AP75表示交并比IoU 阈值为0.75 时的平均精度,而AP为交并比IoU 阈值t从0.5~0.95 之间的10 个阈值的平均精度的均值,即
APs、APm、APl分别表示对于小目标(面积<322像素)、中目标(322像素<面积<962像素)、大目标(面积>962像素)的平均精度。由于实例分割包含检测和分割2 个任务,因此AP 还具体分为APbbox和APmask,分别表示检测框和分割掩膜的平均精度。网络复杂度具体评估指标为模型参数量Params(Parameters)用于衡量模型内存资源的消耗,每秒浮点运算次数FLOPs(FLoatingpoint Operations Per second)用于衡量模型的计算复杂度。
实验设置方面,本文使用的实验平台搭载Intel 至强E5 系列CPU,128 GB 内存,并在NVIDIA RTX 3090 GPU 上进行单卡训练。在不改变图像比例的情况下,所有原始图像都被处理成1 333×H或W×800 的大小。训练过程中,为了对比公平性,所有超参数设置都保证严格一致,批大小Batchsize 设置为4,训练时间为1×12 epochs 周期,使用随机梯度下降(Stochastic Gradient Descent,SGD)优化器进行学习率优化,其中初始学习率设置为0.002,权重衰减设置为0.000 1,动量设置为0.9,整个训练和测试过程中没有引入如多尺度输入、剪切翻转、噪声等任何数据增强操作。
2.2 不同实例分割方法对比
由于MSEM 和GLFCM 可以应用于任何基于特征金字塔结构的网络,因此本文选取了一阶段实例分割代表性的网络YOLACT,二阶段实例分割代表性网络Mask R-CNN 与多阶段实例分割代表性的网络Cascade Mask R-CNN 作为基线网络,分别加入MSEM 和GLFCM 以验证本文方法有效性。各个模型采用的骨干网络均为ResNet-50,且使用ImageNet-1K 上训练的预训练权重,基于各类代表性网络的效果对比如表1所示。
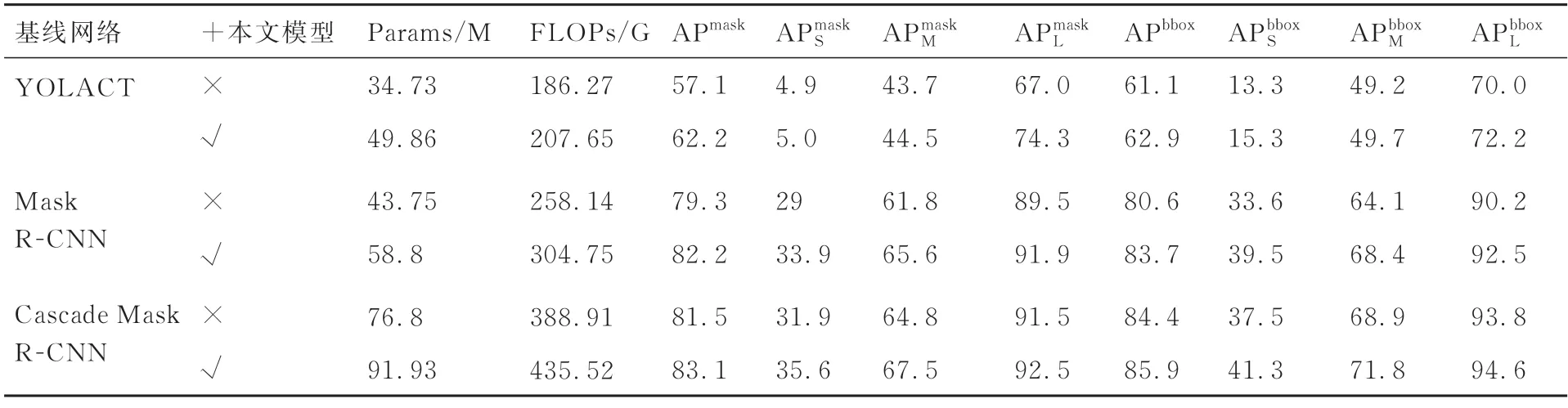
表1 基于各类代表性网络的效果对比Table 1 Comparisons based on different representative networks
对于YOLACT,添加本文模型之后整体APmask提升了5.1%,APbbox提升了1.8%,由于一阶段网络直接生成全局掩膜而没有经过局部区域的裁剪和RoI Align 的过程,因此对于小目标的检测效果总体不佳,尽管如此,得益于高层语义信息的充分利用依然取得了2%的提升,而分割方面,为了减少计算量,YOLACT 对输入图像进行了压缩,导致原型掩码预测分支采用的特征图分辨率还不足输入图像的1/8,因此对于小目标的分割效果较差仅有5%左右。而对于中尺度,大尺度车辆的检测和分割效果均有一定提升,其中大尺度车辆提升最大,提升了7.3%提升了2.2%,这主要得益于本文网络充分抑制了特征图中的背景干扰和冗余信息,因此在YOLACT 的原型掩码预测分支中各个原型掩码粒度更细、耦合更少,进而提高了原型掩码的表达能力。
对于Mask R-CNN,添加本文模型之后整体APmask、APbbox分别达到了82.2%和83.7%,效果较好,相较于基线网络分别提升了2.9% 和3.1%,在各尺度车辆的检测和分割都取得了较大提高,对于网络各个模块的实验分析具体可见2.3 节。值得一提的是,相较于多阶段实例分割代表性网络Cascade Mask R-CNN,在参数量减少18M,每秒浮点操作数减少84.16G 的情况下,APmask高出了0.7%,对于小尺度车辆的检测和分割精度均高出了2%,充分验证了本文网络对全局语义信息利用的充分性。
对于Cascade Mask R-CNN,其通过级联多个阶段的检测头,逐步增加IoU 阈值,相较于二阶段网络大大提升了检测精度,尽管如此,得益于本文网络对高层语义特征的充分利用和对全局特征、局部特征的重新校准,多阶段网络添加本文模型之后整体APmask、APbbox依然分别提升了1.6%和1.5%,对于小尺度和中尺度车辆效果最为明显分别提升了3.7% 和3.8%,分别提升了2.7%和2.9%。
模型效率方面,本文模型对于所有网络均会增加约15M 的参数量和约46.61G 的少量每秒浮点操作数,却得到了较大的精度提升。
为验证本文方法相较于其他针对遮挡、小目标问题的先进实例分割方法的优越性,本文选取了SOLO[29]、QueryInst[30]、MSOA-Net[17]、PointRend[31]、DetectoRS[32]与本文基于Mask RCNN改进的方法进行对比,实验结果如表2 所示。综合来看,本文方法在整体和各个尺度的APmask均取得了最优效果。具体地说,APmask相较最先进的DetectoRS 提高了0.5%,对于小尺度车辆目标的预测效果尤其突出相较最先进的DetectoRS 分别提高了1.3% 和1.4%。此外,在目标检测方面,本文方法的和指标仅仅稍低于DetectoRS,这主要是由于DetectoRS 是一个模型复杂度较高的多阶段网络,在检测方面具有一定优势,但其参数量相较于本文方法增加了75.5M,FLOPs 增加了132.65G。

表2 不同先进方法的对比实验结果Table 2 Comparisons of experimental results with different state-of-the-art methods
实验结果证明,本文模型从减少高层语义特征损失,提高其语义特征的多尺度适应性,对全局特征和局部特征进行特征校准,抑制冗余信息干扰等角度,在增加一定参数量和少量的计算量的前提下,提高了基于特征金字塔结构的网络的目标检测与实例分割性能,且本文模型适用于添加到多种一阶段、二阶段、多阶段实例分割网络中。对比其他先进的实例分割方法,本文方法在预测精度和模型复杂度之间取得了较好的平衡,即以更小的模型规模和计算代价在实例分割任务中取得了最好的精度,其中小尺度车辆的检测和分割效果最为突出。
2.3 消融实验
为了验证本文方法各个子结构对整体网络的贡献,本节对MSEM 和GLFCM 模块进行消融实验,同时将本文使用的线性Transformer 结构与原始Transformer 结构进行对比。由于一阶段网络YOLACT 精度较低而多阶段网络Cascade Mask R-CNN 参数量和计算量过高,因此选择模型复杂度较为适中,预测精度较高的Mask R-CNN 作为基线网络进行消融实验,所有实验的骨干网络均为ResNet-50,消融实验的实验设置与2.2 节保持一致。
从表3 可知,对于MSEM 模块,其主要作用是减少高层语义特征的通道特征的损失,同时解决与低层次特征融合的过程中的尺度不匹配问题,根据表3,可以发现添加MSEM 后的网络相比于基线网络,APmask提升了0.8%,APbbox提升了0.9%,对于小尺度、中尺度、大尺度车辆的分割和检测效果均有较大的提升。在特征金字塔结构中,由于MSEM 的输入是骨干网络最高层的特征,并且没有引入任何通道压缩操作,因此减少了高层语义特征的通道特征损失,而多尺度空洞卷积与密集连接结构则增强了语义特征的尺度适应性与特征表达能力,这也是所有尺度车辆的检测和分割效果都有提升的原因,其中小尺度和中尺度车辆效果提升最为明显,小尺度的检测和分割效果分别提升了1.4%和0.3%,中尺度的检测分割效果分别提升了1.6%和1.2%。模型效率方面,由于引入了密集连接结构,参数量增加了12.95M,FLOPs 增加了12.96G。
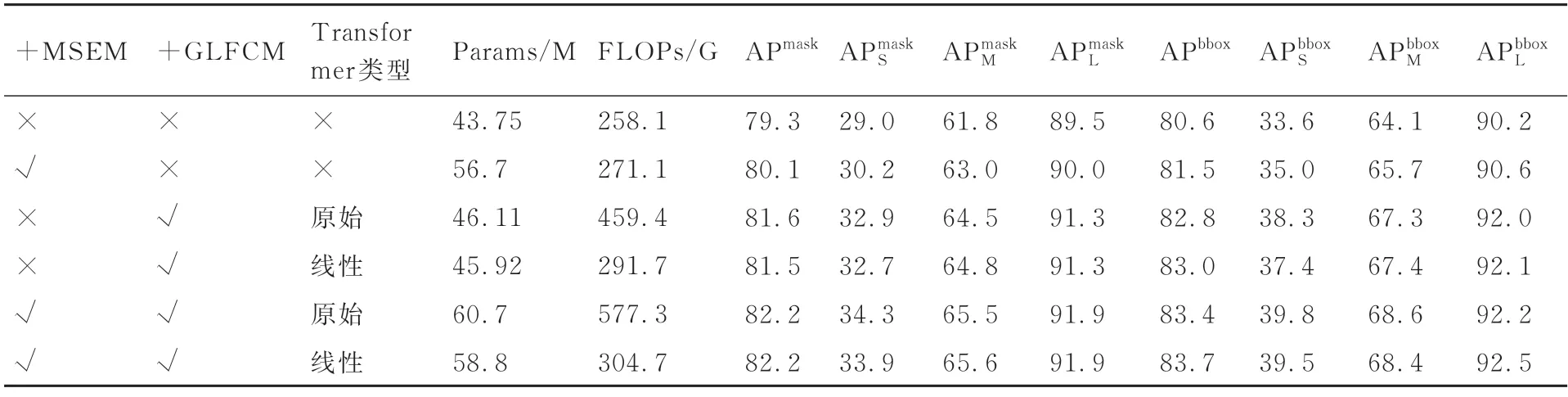
表3 本文方法中各模块的消融实验Table 3 Ablation studies of each component in our methods
为了量化评估MSEM 中密集连接的多个空洞卷积模块和空间注意力模块对网络的贡献,本文对这2 个子模块进行了消融实验,实验结果如表4 所示。从表4 中可知,仅在MSEM 模块中使用空间注意力模块,模型的参数量增加了0.2M,FLOPs 增加了0.2G,同时该模块对检测和分割效果提升较小,这是由于空间注意力模块仅仅起到抑制噪声的作用,并没有引入新的信息,没有起到特征增强的作用。仅在MSEM 模块中使用空洞卷积模块会使得模型的参数量增加12.8M,FLOPs 增加12.8G,同时整体APmask和APbbox分别提升了0.5%和0.7%,小尺度车辆和中尺度车辆的检测和分割效果均有较大的提升和分别提升了1.0% 和1.2%,和分别提升了0.7%和1.2%,这是因为空洞卷积模块可以增强高层语义特征的多尺度信息,这对于提升小中尺度车辆的检测和分割十分重要。同时使用空洞卷积模块和空间注意力模块会使模型的参数量增加13.0M,FLOPs 增加13.0G,相比于仅使用空洞卷积模块,模型复杂度几乎没有增加,但各个尺度车辆的检测和分割精度有了进一步的提升,这是因为增加的空间注意力模块抑制了增强特征中的噪声,从而保证了多尺度信息的准确性。

表4 MSEM 模块的消融实验Table4 Ablation studies of each component in MSEM
对于GLFCM 模块,其主要作用是对全局各个尺度的特征进行重新校准,学习全局特征之间的依赖关系,并采用多头结构的自注意力机制抑制局部特征的中复杂背景的干扰,分而治之地提高各个层次的特征图的表征能力。为了验证本文线性Transformer 能够在保持与原始Transformer 相近的预测精度的同时,降低模型的参数量和计算量,还增加了与原始Transformer 的对比。根据表3 可以发现在基线网络上添加使用原始Transformer 的GLFCM 模块,APmask提升了2.3%,APbbox提升了2.2%,添加使用线性Transformer 的GLFCM 模块,APmask提升了2.2%,APbbox提升了2.4%,其中原始Transformer 极大地提高了小尺度车辆的检测(+4.7%)和分割(+3.9%)精度,而线性Transformer 在中尺度和大尺度车辆的检测和分割方面则有更好的表现,其APmask与原始Transformer 差距较小,APbbox甚至提升了0.2%。模型效率方面,使用原始Transformer 的GLFCM 模块参数量增加了2.36M,由于Softmax 中存在大规模的矩阵运算,FLOPs 增加了201.26G,而进行线性化之后,参数量减少了0.19M,FLOPs 减少了167.61G。从实验中可以看出,无论是使用原始Transformer 还是线性Transformer,都能够极大地提升小尺度车辆的检测和分割效果,同时中尺度和大尺度车辆也有较大提升,线性化Transformer会导致小尺度车辆的检测和分割精度稍有下降,在特征金字塔之后,候选框提取网络之前加入GLFCM 模块可以帮助模型更好地学习不同尺度特征之间的依赖关系并抑制干扰,从而获得更丰富的特征表征。
将 MSEM 和不同 Transformer 类型的GLFCM 模块加入基线网络,根据表3,可以发现,使用线性Transformer 的模型在APmask、APbbox均取得了最佳精度,相较基线网络分别提升了2.9%和2.2%,在各尺度车辆的检测和分割都取得了较大提高,其中提升了5.5%提升了3.6%提升了1.3%提升了1.9%,提升了2.4%提升了1.7%。而使用原始Transformer 的模型,在小尺度车辆的检测和分割上表现要更好,相较基线网络提高了2.3%提高了5.8%。模型效率方面,使用线性Transformer 的模型增加了15.05M 的参数量和46.61G 的FLOPs,相较于使用原始Transformer 的模型,在总体精度稍高,小尺度车辆检测和分割精度稍有下降的前提下,减少了一定的参数量和大量的FLOPs,因此MSEM 加上线性GLFCM 的结构为本文最终采用的模型。
实验结果表明,MSEM 模块添加到特征金字塔结构中能有效减少高层语义特征的损失,同时提高语义特征的多尺度适应性,在各个尺度车辆的检测和分割都取得了提升,GLFCM 模块则可以对全局各个尺度的特征进行重新校准,并采用多头结构的自注意力机制抑制局部特征的中复杂背景的干扰,进一步提高了各尺度车辆的检测和分割效果,其中,中尺度和小尺度车辆效果提升最为明显,对GLFCM 模块中的Transformer模块进行线性化之后,网络效果没有明显降低的同时减少了网络一定参数量和大量的计算量。
2.4 算法有效性分析
由于二阶段网络Mask R-CNN 精度远高于一阶段网络YOLACT,且在参数量和计算量远少于多阶段网络Cascade Mask R-CNN 的情况下与其精度差距很小,因此本文选择使用添加本文模型的改进Mask R-CNN 网络进行预测,如图8 所示,本文从UVSD 数据集中分别选取了如遮挡、车辆尺度小、光照强度低、背景干扰多4 个不同场景以验证本文方法对多种场景的适应性,同时如图9 所示对比基线网络Mask R-CNN 的预测效果,以验证本文模型的有效性。图8(a)中车辆密集排布,存在被截断或相互之间形成一定遮挡的现象,距离越远的车辆形成的遮挡越严重,图8(b)中车辆排布密集,且无人机飞行高度较高,造成图中车辆尺度均较小,图8(c)拍摄于夜间,图片亮度对比度低,图8(d)中居民楼和树木占据了图片的很大部分,背景干扰多。图8 中场景同时包含了遮挡、排布密集、车辆尺度小、光照强度低、背景干扰多等多种特点,具有挑战性,图中可以看到,对于车辆尺度较大的场景,网络能够一定程度克服遮挡问题,并准确分割出车辆的边缘,对于明暗对比较低或车辆尺度小的场景,网络依然能在车辆边缘形状不清晰的情况下准确实现检测,并实现一定分割效果。

图8 不同场景下本文方法检测和分割效果Fig.8 Detection and segmentation effect of proposed methods in different scenarios
图9(a)样例1 中,受遮挡或背景等因素的干扰,左侧的基线网络产生了较多的误检现象,导致检测和分割效果不佳,而右侧本文方法,由于充分利用了语义信息,且对特征图进行了特征校准,因此抑制了许多冗余信息,一定程度上避免了误检现象的产生,同时对车辆的分割效果更为精细。图9(b)样例2 中,由于远处车辆尺度较小且排布密集而导致车辆特征不明显,实例区分度低,左侧的基线网络产生了许多漏检,而右侧本文方法对于宽>15 像素,高度>12 像素的小尺度车辆检出率和分割效果都有明显提升,而对于面积更小且遮挡严重的极小尺度车辆的检测和分割效果则有待提高。图9(c)样例3 中,由于光照较少、亮度较低,相邻车辆特征区分度不明显,左侧基线网络产生了较多误检,而右侧本文方法对车辆实例分割效果较为准确,且边缘更为平滑。
3 结论
针对航拍车辆实例分割任务中存在的分布密集、存在遮挡、背景干扰多、车辆尺度小等问题,本文提出了基于特征增强和校准的航拍车辆实例分割方法。
该方法主要包含MSEM 模块和GLFCM 模块,MSEM 可以减少语义特征的通道特征损失,提高特征融合过程中语义特征的多尺度适应性;GLFCM 则通过多头结构和线性化的Transformer,可以在仅增加极少的参数量和计算量的情况下,学习到全局特征的依赖关系并抑制局部特征中的冗余信息。
基于航拍车辆实例分割数据集UVSD 的验证结果表明,在遮挡多、车辆尺度小、光照变化大、背景干扰多等挑战下,本文方法在检测和分割任务上对于多个尺度的车辆都有明显的提升,并且,本文方法适用于一阶段、双阶段、多阶段的基于特征金字塔结构的实例分割网络。
对于一些遮挡严重、像素极少的极小尺度车辆,本文方法还有一定的提升空间,可以作为未来航拍车辆实例分割任务的重点研究方面。
附录A:
本文进行了3 组对比实验,分别使用MSEM模块增强F5、F5+F4、F5+F4+F3以对比MSEM 模块增强不同层次特征时对网络效果的提升作用,实验结果如表A1 所示。模型复杂度方面,每增加一个MESM 模块增强一个层次的特征,网络参数量会增加约9M,在增加F4时,FLOPs 相对增加了41.4G,在增加F3时FLOPs相对增加了144.9G,这主要是因为层次越低的特征分辨率越高,对其进行特征增强所增加的计算量越多。模型精度方面,增加增强特征的数量仅对具有较小的提升,F5+F4+F3的相对于F5提升了0.3%,这是因为对高分辨率特征F4、F3进行增强能在一定程度上丰富小尺度车辆的特征,但这会极大地增加模型复杂度。此外,其他指标的提升效果则并不明显,精度变化均在0.2% 以内,F5+F4相比于F5在的精度甚至有所下滑。因此,为平衡模型精度和复杂度,最终MSEM 模块仅用于增强特征F5。

表A1 MSEM 模块增强不同特征对网络效果的提升作用的对比实验Table A1 Comparison of enhancement effect of different features on network performance by MSEM
