面向计算机视觉的吸烟检测方法研究综述
2024-01-18何嘉彬李雷孝徐国新
何嘉彬,李雷孝,2,林 浩,徐国新
1.内蒙古工业大学 数据科学与应用学院,呼和浩特 010080
2.内蒙古自治区基于大数据的软件服务工程技术研究中心,呼和浩特 010080
3.天津理工大学 计算机科学与工程学院,天津 300384
近年来,与吸烟有关的死亡人数每年都在增加,在一些地区,吸烟导致死亡的人数甚至超过了交通事故或饮酒[1]。此外,在公共场所吸烟也存在很多潜在危害。吸烟不仅严重危害自身健康,吐出的二手烟还会影响他人。烟草中含有多种有害物质,吸入人体后会在肺泡内壁慢慢沉积导致肺部出现损伤。一支香烟通常燃烧时间在10 min左右,被随意丢弃的烟头接近易燃物品极易引发火灾。因此,为了保护自身健康和公共财产安全,对吸烟检测方法展开研究具有重要意义。
目前,吸烟检测的研究成果可分为基于硬件设备和无线信号,以及基于计算机视觉的检测方法。其中,基于硬件设备和无线信号的检测方法适应性较差,在一些特殊场景使用效果不佳。针对这些局限性,近年来基于计算机视觉的吸烟检测方法被广泛应用。与此同时,监控系统从仿真时代、网络化时代、高清时代逐渐步入智能化时代。监控资源不再作为局部监控功能,而是与计算机视觉相结合,实现智能监控。根据吸烟产生烟雾的特点,利用图像处理相关算法提取疑似烟雾区域并准确分割识别,可以极大改善传统烟雾探测器的高误报率和低检测率。并且随着深度学习的成功,基于深度学习的目标检测算法迅速发展并成为检测烟雾和烟支的主流方法。与传统机器学习相比,它具有更强大的特征学习和特征表示能力,能够更好地满足大数据时代的需求。这类方法主要基于单帧图像提取目标的高维特征,对于吸烟检测而言,没有很好利用吸烟动作的时序规律性。另一类方法是基于行为识别[2]的吸烟动作检测,它更多地关注吸烟动作的时序信息,利用模型构造动作特征描述人体吸烟动作变化。其中人体骨架的高层次表示特征以及对视点、外观和背景噪声的鲁棒性使得骨骼数据在动作识别中更具有优势。Yang 等人[3]通过实验证明了在同一数据集上使用相同的分类器,基于人体骨骼的特征优于外观特征。所以基于骨骼数据的吸烟动作检测受到更多的学者们关注。
当前研究只针对某一类方法,该领域还没有系统归纳的综述。因此本文基于现有吸烟检测方法展开研究。首先,探讨基于硬件设备和无线信号的非计算机视觉检测方法,并分析其优劣。其次,分别综述三类主流计算机视觉检测方法:(1)针对烟雾检测从颜色、外观和运动等多特征融合角度进行论述;(2)烟支目标检测利用单阶段和两阶段检测算法对烟支目标直接检测,或利用人脸、人体初步筛选烟支候选区域,再利用目标检测算法定位识别烟支目标;(3)吸烟动作检测从行为识别角度出发,主要基于骨骼数据展开研究。最后总结全文并展望未来吸烟检测研究的发展方向。本文结构如图1所示。
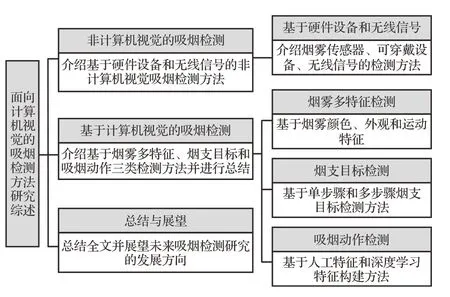
图1 全文结构Fig.1 Full-text structure
1 基于硬件设备和无线信号的吸烟检测
对吸烟行为检测的研究由来已久,传统的检测方法主要基于烟雾传感器[4]。其中离子式烟雾传感器利用烟雾会干扰带电离子正常运动的原理,改变电流电压,产生报警信息;光电式烟雾传感器在烟雾的作用下,利用红外光漫反射原理进行检测;气敏式烟雾传感器通过检测特定气体浓度,分析环境中是否存在香烟烟雾。由于香烟烟雾浓度低、飘散快的特点,烟雾传感器需要具备较高的灵敏度。此外,室外环境还要考虑空气中其他物质对传感器造成的干扰。近几年,可穿戴设备[5]依靠其方便、快捷的优势逐渐成为吸烟检测的解决方案。吸烟的频率或方式通常因人而异,然而不同人的吸烟行为和生理现象总是存在相似之处。吸烟者一次吸烟过程通常包括以下动作,点燃香烟后手部持烟准备吸入,动作表现为手部逐渐靠近嘴部;手部持烟一段时间吸入烟雾,动作表现为手部与嘴部保持重合;吸入烟雾后动作表现为手部逐渐远离嘴部。此时会有短暂的烟雾滞留在肺部,吸烟者通过鼻子或嘴呼出烟雾。这种特殊的呼吸方式和此时产生的心律变化相较于非吸烟者存在明显差异,通过可穿戴设备表征这些差异可以检测吸烟行为。虽然这类方法可以平衡外部环境因素导致吸烟检测准确度低的问题,但穿戴复杂的设备会给人带来强烈的不适感,并且传感器的响应通常会受到吸烟者行为运动的影响。随着无线通信技术和射频识别技术的发展,部分研究使用无线信号来识别身体运动。主要利用WiFi 信号[6]的信道状态变化检测有规律的吸烟行为,在非视线区和穿墙环境中也能提取有价值的信息。还有研究利用超宽带雷达信号[7]、声学和光学信号[8-9]结合可穿戴设备进行吸烟检测。基于无线信号的检测方法不仅需要考虑信号覆盖问题,而且易受混淆活动和吸烟行为多样性的影响。基于硬件设备相关研究如表1所示。
以上方法都具有很大的局限性,测试过程也仅限于实验环境,无法同时满足实际场景高精度检测和实时性需求。相比基于硬件设备和无线信号的检测方法,基于计算机视觉的吸烟检测不受环境因素的干扰,也不需要考虑硬件成本问题。不少研究者利用计算机视觉中先进的技术对吸烟行为进行检测,并取得了良好的检测效果。下面将分别介绍三种基于计算机视觉的吸烟检测方法。
2 烟雾多特征检测
这类方法使用特征提取和分割技术从图像中提取所需特征,然后将这些特征与目标对象的特征进行比较。如果从图像中提取的特征与目标对象特征匹配或相似,则认为检测到目标对象。常用机器学习方法如支持向量机(support vector machine,SVM)分类器对提取的特征进行分类。基于烟雾多特征的吸烟检测方法利用图像处理技术,通过提取烟雾的颜色、外观和运动等特征并送入分类器进行判别。这种吸烟烟雾检测技术相比于烟雾探测器更适用于复杂、广阔的室外环境,同时提供了丰富的早期烟雾视觉信息。
2.1 颜色特征
基于颜色特征算法利用不同颜色空间特点增强烟雾视觉特性,将移动块标记为潜在的烟雾块。常用的颜色空间包括RGB、HSV、YCbCr、YUV、HSI 等。潘广贞等人[15]通过分析研究大量稀薄烟雾图片,发现图像中RGB颜色空间3个分量值差距不大,导致无法区分稀薄烟雾区域。将RGB 转换HSV 颜色空间后,各通道分量值存在明显差异。利用该特点分割稀薄烟雾和相似背景。唐杰等人[16]混合RGB和HSV颜色空间得到了更准确的烟雾区域。胡春海等人[17]发现在YCrCb 颜色空间中,烟雾区域和非烟雾区域颜色布局描述符Y通道方差值差异明显,利用该特点可以更好地分割烟雾和非烟雾区域。Lin 等人[18]将烟雾待检测区域定位在口腔附近,吸烟产生的烟雾会改变口腔区域的饱和度和灰度值,通过计算这两个属性以检测面部区域是否有烟雾。当口腔图像中白色像素点数量大于设置阈值且当口腔饱和度明显低于设置阈值时,确定口腔中有白色烟雾。
2.2 外观特征
基于外观特征的算法在决策过程中考虑了烟雾扩展方式和增长速度以及烟雾形状特征,通过定义烟雾物理属性和烟雾轮廓特征的不规则变化来判断图像的运动区域是否与烟雾相似。汪祖云等人[19]利用烟雾扩散变大、向斜上方缓慢运动的特性,计算烟雾的面积变化速率和质心相对角度变化共建SVM分类器判别吸烟行为。黄训平等人[20]在此基础上计算烟雾凸包周长与轮廓周长的比值、烟雾轮廓内外接矩形面积比,对烟雾的不规则性加以定义。
2.3 运动特征
基于运动特征算法利用烟雾运动模式选择潜在的烟雾区域。单帧图像显然无法描述物体运动,所以需要基于视频图像序列获取烟雾运动特征,从而分割出目标区域以及更多视觉特征。经典的烟雾运动视频序列如图2所示。

图2 烟雾运动视频序列Fig.2 Smoke motion video sequence
在静止背景的情况下,运动目标的提取方法有帧间差分法、背景差分法和光流法,如表2 所示。传统运动目标提取方法主要利用贝叶斯分类器的光流计算和运动熵来检测图像中的运动区域是否代表烟雾。为了更好地将烟雾运动目标从图像背景中分离出来,有研究提出使用自适应混合高斯模型进行运动区域分割[21]。利用混合高斯模型的无偏差性和有效性对图像背景建模,结合运动目标提取方法可以提取清晰的烟雾运动信息。其流程如图3所示。

表2 静止背景情况下运动目标提取方法对比Table 2 Comparison of moving object extraction methods in static background

图3 混合高斯模型+帧差法提取烟雾区域流程Fig.3 Mixed Gaussian model+frame difference method to extract smoke area process
2.4 小结
分析上述烟雾多特征检测方法发现。烟雾颜色特征利用RGB、HSV 等颜色空间的色彩分量和饱和度特性检测烟雾,虽然有一定的判别能力,但面对复杂环境时颜色特征易受外部环境因素干扰。外观特征主要表现为提取烟雾区域的凸形特征计算周长面积,但应用的前提是必须提取完整的疑似烟雾区域。运动特征利用烟雾的漂移特性和扩散特性,结合运动目标提取方法描述烟雾运动信息,此类方法复杂度较高,需要计算每个像素点或块的运动,且抗噪能力不强。除了上述特征外还包括烟雾纹理、统计量特征。文献[15,19]对每个像素点进行HSV 颜色空间转换时,疑似烟雾区域内的像素点可能存在漏检或误检情况。针对这一问题,张日东[22]利用形态学的腐蚀和膨胀操作消除图像中目标边界点,使其边界向内部收缩。从而消除区域内部存在的空洞和外在的孤立点。吸烟烟雾多特征简述如表3 所示。数据表明烟雾独特的扩散性使得特征提取主要集中于颜色和运动特征。但单一特征容易受到场景约束,所以特征多以组合形式出现。

表3 多特征融合方法Table 3 Multi-feature fusion method
综上所述,吸烟烟雾检测大多采用烟雾多特征结合方法,通过判断所选特征的一定数量是否符合烟雾条件来确定图像是否包含烟雾。虽然在一定程度上解决了烟雾易扩散、颜色较浅的缺点,但实际上烟雾检测环境复杂多变,烟雾多特征需要的预处理步骤较多,检测过程中会出现大量的计算。为解决上述问题已有学者提出结合目标检测方法检测烟雾,将在3.3节介绍。
3 烟支目标检测
目前吸烟检测使用较为广泛的方法是利用目标检测算法提取图像中的烟支。早期阶段,目标检测算法主要依赖于人工特征提取和选择,较多采用滑动窗口方法遍历整幅图像,利用尺度不变特征变换(scale-invariant feature transform,SIFT)、HOG 等方法提取特征。由于缺乏图像特征表示能力,研究者只能设计复杂的特征尽可能地描述场景。随着卷积神经网络(convolutional neural network,CNN)的快速发展,基于深度学习的目标检测方法受到了越来越多的关注。2014 年,Girshick等人[23]提出了RCNN(region convolutional neural network)首次将CNN用于目标检测。此后,Redmon等人[24]于2015年提出了单阶段检测算法YOLO(you only look once)。YOLO 将图像分割成网格,同时预测每个网格的边界框和概率。围绕RCNN 和YOLO 衍生了一系列目标检测方法。根据方法设计框架不同,现有的目标检测主要分为两阶段和单阶段算法。两阶段的目标检测基本原理同传统目标检测方法类似,算法流程如图4(a)所示。一阶段提取一定数量的目标候选区域,二阶段利用特征提取网络对这些候选区域进行区分和定位。相比于传统目标检测方法使用卷积神经网络代替手工特征提取,显著提高目标的特征表达能力。虽然两阶段目标检测算法在精度识别方面表现足够优秀,但其复杂的计算过程无法满足实时检测需要。单阶段目标检测算法为了提高检测速度,取消了两阶段目标检测算法中候选框生成网络,直接从特征映射中输出目标边界框,大大提高了检测效率。单阶段目标检测算法流程如图4(b)。

图4 目标检测算法流程Fig.4 Target detection algorithm flow
3.1 单步骤目标检测
单步骤目标检测利用目标检测算法提取整张输入图像特征。包括目标人物手拿烟未吸入等情况都会被检测,这种检测方式适用于对吸烟把控较严格的场景。在目标检测任务中,对于小目标的定义还没有统一的标准,而是根据不同的应用场景有不同定义[25]。烟支目标与常规目标相比分辨率较低且特征信息不明显,针对烟支小目标检测问题,研究人员已经提出多种优化方法。
2019 年,Poonam 等人[26]首次使用两阶段目标检测算法Faster RCNN(faster region convolutional neural network)进行吸烟检测,并且在自建数据集上取得了93.87%的准确率。结果表明,以烟支为目标,使用Faster RCNN 可以用于吸烟场景的检测,有效克服了传统目标检测算法特征提取的缺陷。基于两阶段的目标检测算法虽然提高了烟支目标检测精度,但仍然不能满足吸烟场景实时检测需要。因此烟支目标检测大多基于检测速度更快的单阶段目标检测算法。Liao 等人[27]基于YOLOv3 网络对公共场所的吸烟行为进行检测。YOLOv3 利用了特征金字塔网络结构(feature pyramid network,FPN)将不同特征图上的特征进行融合,再利用融合得到的特征图上进行预测。小尺寸特征图用于检测大尺寸物体,大尺寸特征图用于检测小尺寸物体,以此来提高烟支小目标的检测准确率。文献[28-29]使用自制数据集和YOLOv3网络训练烟支目标检测模型,并基于GUI(graphical user interface)开发图形用户界面构建实时推理系统,为后续模型嵌入硬件设备进行实时检测提供研究基础。除YOLOv3外,YOLOv5也常被应用于吸烟检测研究,其检测网络共分为四个版本YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x,其 中YOLOv5s 的网络深度和特征图宽度均为最小。Zou 等人[30]通过比较YOLOv5 与其他模型的优缺点,选择YOLOv5l 作为基础模型,在自制的吸烟检测数据集上取得了良好的检测效果。杨国亮等人[31]将Transformer引入YOLOv5s 网络颈部模块,用于扩大特征图的感受野,减少模型误检率。综上所述,Faster RCNN 通过牺牲检测时间来换取检测精度,而YOLO 恰恰相反,它是牺牲检测精度来换取检测效率。Yang 等人[32]提出使用SSD(single shot multibox detector)单阶段检测算法对驾驶员异常驾驶行为予以表征。SSD 算法结合上述两者的优点,兼顾了mAP 和实时性要求,有效解决了吸烟、打电话等非法驾驶的行为检测问题。烟支目标检测相关研究如表4所示。
表4 烟支目标检测相关算法研究Table 4 Research on correlative algorithm of cigarette target detection
除了上述目标检测模型外,还有学者使用自建网络模型展开吸烟检测的研究[47-48]。Zhang 等人[49]提出了一种基于CNN 的吸烟图像检测模型SmokingNet,它在GoogLeNet 的Inception 模块基础上进一步优化,使用非方卷积核增强了对目标图像的特征提取能力。SmokingNet 相比于传统目标检测方法性能有明显提升,但依然不能与发展成熟的单阶段、两阶段目标检测算法相媲美。Zhang 等人[50]借鉴YOLOv5 算法思想,基于自定义注意力机制模块和改进的残差网络模块设计了一种单阶段检测模型,通过主干网络提取小目标的语义信息和位置信息,利用YOLOv5的FPN结构和路径聚合网络结构(path aggregation network,PAN)进行不同尺度的特征融合,提高小目标的检测精度。图5 为FPN+PAN 结构示意图。同一个数据集下,该自定义模型无论在精度和速度方面要优于Faster RCNN、SSD、YOLOv5 等基础模型。Zhao 等人[51]提出了一种基于FPN和扩张卷积技术相结合的方法,以检测驾驶员图像中的烟支小目标对象并识别他们的吸烟行为。该模型的网络结构相对于其他网络结构来说比较简单,方便将编程语言转换成硬件运行主板支持的语言并嵌入到平台中。自建网络模型和已经发展成熟的目标检测模型相比,能更好地适应特殊应用场景,鲁棒性更强。
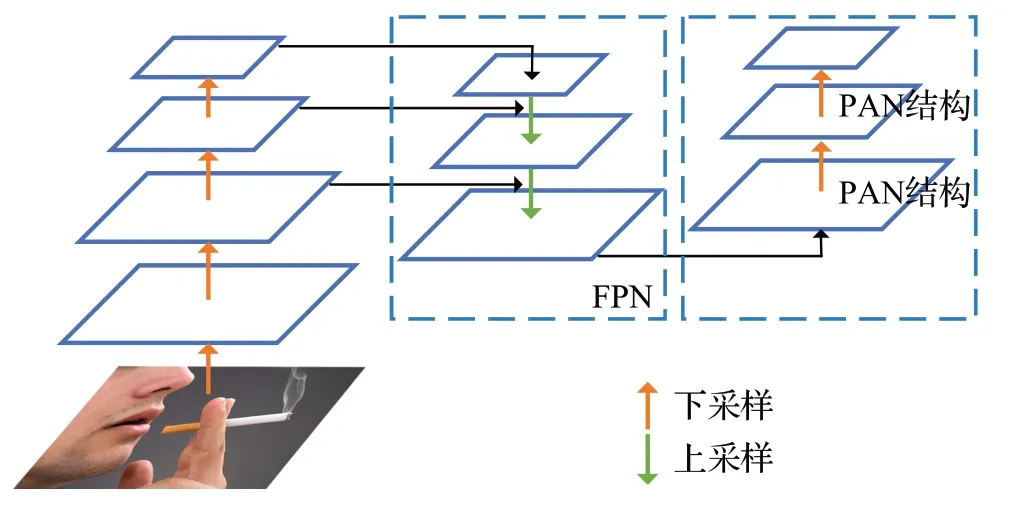
图5 FPN+PAN结构示意图Fig.5 Schematic diagram of FPN+PAN structure
3.2 多步骤目标检测
烟支目标检测背景复杂、易受环境噪声干扰。多步骤目标检测结合人脸或人体区域提取算法进一步缩小烟支目标范围,有效解决小目标特征提取不充分问题。再提取到目标区域基础上使用目标检测算法定位识别烟支目标。
部分研究对正在发生的吸烟行为进行检测(烟支和嘴部重合代表正在吸烟),这种方式能降低手拿烟未吸入等情况的误检率。因此多步骤目标检测的区域提取网络大多基于人脸检测模型提取人脸为候选区域。其中应用较为广泛的人脸检测算法包括OpenCV 库[52]、Dlib库[53]、MTCNN算法[54]和RetinaFace算法[55],OpenCV库的人脸检测算法通过构建Haar-like 特征和AdaBoost分类器实现人脸的检测;Dlib 库的人脸检测算法利用HOG 和级联SVM 分类器构建;MTCNN 算法是中科院深圳研究院提出的用于人脸检测的多任务神经网络模型;RetinaFace 是InsightFace 团队提出的一种鲁棒的单阶段人脸检测网络。程淑红等人[56]将吸烟检测任务转换为图像分类问题,提出一种多任务分类网络以检测吸烟行为,检测流程如图6 所示。模型首先利用MTCNN算法进行人脸的判别,在此基础上利用级联残差回归树方法定位嘴部感兴趣区域(region of interest,ROI),最后通过残差网络提取特征对吸烟行为做出判别。多算法融合构建的多任务分类模型可以精准识别正在发生的吸烟行为,但模型检测速率不高输出仅为25帧/s。文献[57-59]都采用人脸到烟支的多步骤目标检测方法,首先结合人脸检测算法缩小烟支目标待检测区域,再利用目标检测算法精准定位烟支目标,此类方法相比于单步骤目标检测具有较低的误检率。

图6 基于多任务分类的吸烟检测流程Fig.6 Smoking detection process based on multitask classification
由于吸烟者不会经常把香烟叼在嘴里,他们大部分时间都是手里拿着香烟。为了防止出现漏检的情况,基于手部区域提取是有意义的。然而由于手部的不对称性和吸烟手势的不同使得定位手中烟支目标更加困难。文献[60-61]提出将目标候选区域扩大至人体,在减少目标检测面积的同时还不丢失烟支目标特征,基于人体候选区域的吸烟检测流程如图7 所示。人体检测利用方向梯度直方图HOG的梯度信息反映图像目标的边缘信息并通过局部梯度的大小将图像局部的外观和形状特征化,最终通过SVM 分类器正确分离人体目标。将人体作为烟支目标检测的候选区域,再使用CNN 提取人体图像中烟支目标特征。无论是基于人脸还是人体,多步骤目标检测方法的核心思想是缩小整张输入图像的烟支目标范围以提高准确率,但也伴随着区域提取网络的开销问题,所以需要兼顾烟支目标检测精度和模型检测速率问题。
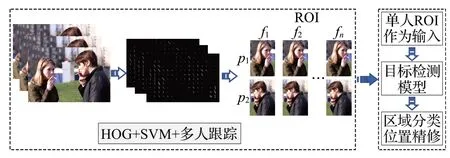
图7 基于多人追踪的吸烟检测流程Fig.7 Smoking detection procedures based on multi-person tracking
3.3 小结
上述方法在烟支目标检测领域都取得了不错的效果。首先,基于深度学习的检测方法在精度方面可以达到传统方法无法达到的水平,在工业产品中更具实用性。其次,算法的运行速度越来越快,能够在可接受的时间范围内得到相应的结果。验证了基于深度学习的方法已经明显优于传统方法。其中单步骤烟支目标检测方法更依赖网络的特征提取能力,适用于实时性要求高的场景。但对整张图像提取特征无法有效利用图像局部信息,容易出现特征的冗余和缺失问题。多步骤目标检测把每个阶段提取出的特征用于下一层的图像处理,在提高检测精度的同时增加了计算量和复杂度。近年来,无论是单步骤检测还是多步骤检测都围绕提高模型精度和速率展开研究[62]。表5对所列举的不同改进策略、机制、优势、局限性和适用场景进行了提炼分析。在实际应用中需要根据具体情况综合考虑,选择合适的检测方法。
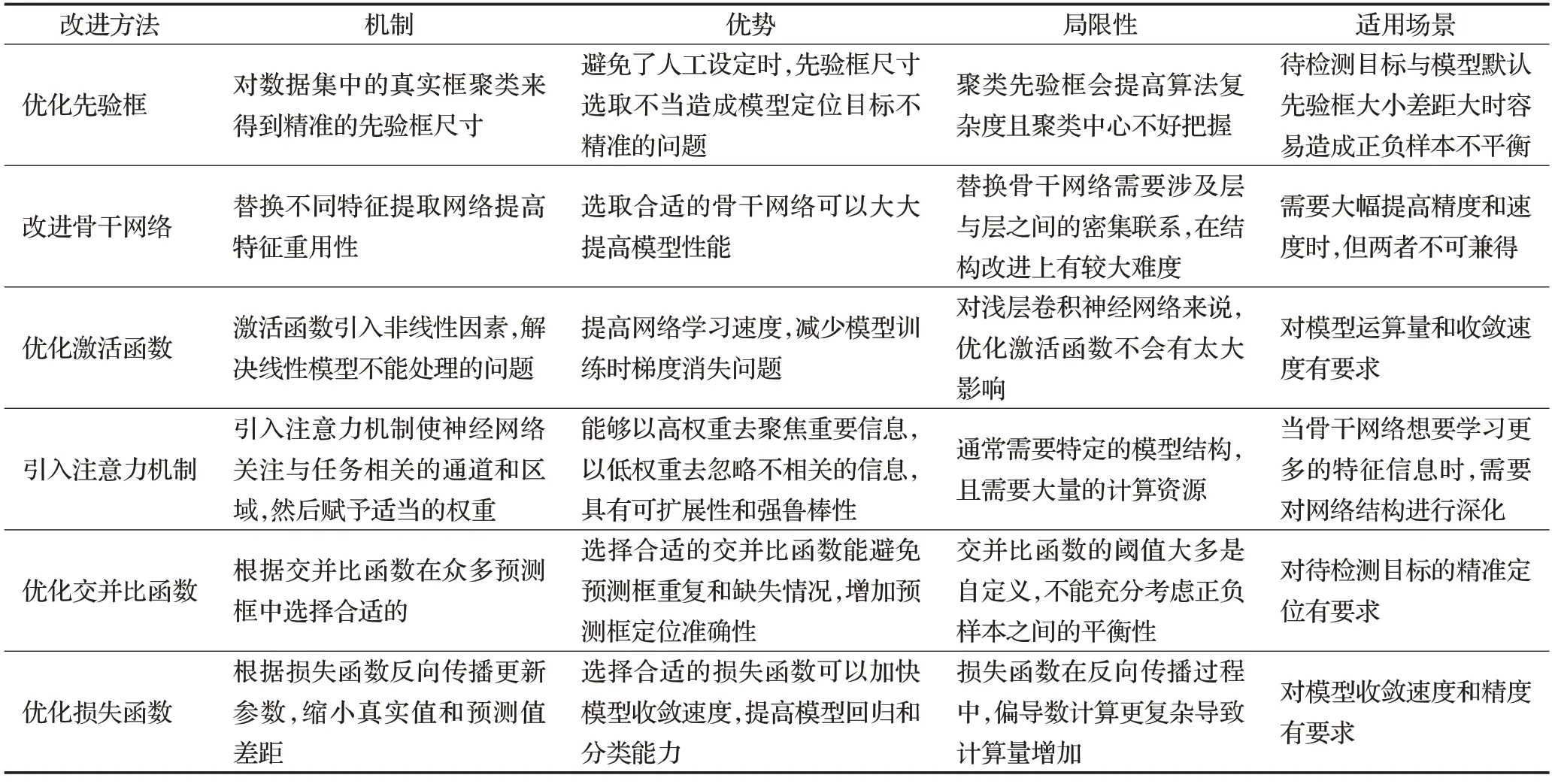
表5 不同改进策略对比Table 5 Comparison of different improvement strategies
近几年,目标检测算法也常被应用于吸烟烟雾检测。史芳菲[63]使用混合高斯模型和帧差法提取疑似烟雾区域,再对疑似烟雾区域分别提取局部二值模式特征(local binary pattern,LBP)和方向梯度直方图(histogram of oriented gradient,HOG)特征进行融合,最后通过SVM 分类器标记真实烟雾区域。也有相关研究利用目标检测模型来训练烟雾数据集。Yang等人[64]对EfficientDet算法进行改进,引入双通道注意力机制并改进Bi-FPN 特征融合算法,解决了小烟雾区域的漏检问题。Sha 等人[65]使用光流来检测两帧之间烟雾运动信息,再利用区域RCNN网络检测烟雾。Chen等人[66]基于烟雾动态特性,采用混合高斯模型初筛烟雾区域,结合YOLOv5s算法检测烟雾。上述方法均结合目标检测模型,相较于传统吸烟烟雾检测模型,无论在性能和准确率方面都有所提升,也为后续吸烟烟雾检测提供了新的研究方向。
4 吸烟动作检测
人体骨骼关键点检测是计算机视觉领域中的一个重要研究方向,已被广泛应用于行为识别、视频监控等方面。通过检测出人体主要关节,识别并获取关键点在图像中的坐标数据,以此来对人体行为动作加以描述。由于吸烟动作与骨骼关键点之间存在着十分密切的联系,骨骼数据能更好地表征吸烟动作整个过程。基于烟雾多特征和烟支目标的吸烟检测方法已趋于成熟,所以本文着重针对吸烟动作的不同特征提取方法展开介绍。在计算机视觉领域,基于骨骼的动作识别定义为对一副骨架序列进行模式识别,识别这副骨架语义上所代表的执行者所表达的动作[67]。随着人体关键点检测模型和深度摄像头传感器等设备发展成熟,骨骼数据逐渐走入研究人员的视野。吸烟动作特征根据构建方式不同分为人工特征构建和深度学习特征提取两种方法。人工特征构建直接利用骨骼数据构造出物理属性特征进而判别是否符合吸烟动作。基于深度学习的特征提取方法根据数据处理方式和骨干网络不同总结为时空模型、时序模型、拓扑模型和混合模型四类,利用行为识别网络进行多特征融合,提取更全面的吸烟动作特征。基于骨骼数据的吸烟行为检测流程如图8 所示。在基于计算机视觉的研究中,首先通过摄像头传感器捕获吸烟视频数据。通过人体骨骼关键点检测模型获取到每帧的人体关键点信息,将此信息作为吸烟动作特征提取模型的输入数据,再根据不同的特征提取方式进行数据处理。通过以上步骤对吸烟动作进行判别最终输出模型检测结果。

图8 基于骨骼数据的吸烟动作检测流程Fig.8 Smoking behavior detection procedures based on bone data
4.1 人工特征构建
人工特征构建方法是通过定义关键点之间的物理属性反映出吸烟动作本身的物理特性。物理特性包括关键点相对位置、距离、角度、速度和时间周期等特征,它们不仅可以反映出吸烟时人体关键点之间的空间结构变化,还能反映出时间层面的动作动态演变过程。具体来讲,人工特征构建首先将人体关键点数据处理成方便获取物理属性的坐标数据,然后经过预先人为构建的物理属性特征模型,进行吸烟动作的检测。
近年来学者们广泛利用基于人工特征构建方法进行吸烟检测[68-71],如表6。由于整个吸烟过程历时较长且吸烟动作具有周期性规律,利用该特点刘婧等人[68]首次基于人体骨骼对多人吸烟动作进行识别。通过计算关节点间坐标描述出关节点运动轨迹,检测运动轨迹是否符合吸烟动作周期性规律。当检测到有三次符合规定的周期性动作即判断发生吸烟动作。但这种方法只能识别符合一定周期性的吸烟过程。在该方法的基础上,姜晓凤等人[69]通过计算关节点之间距离、角度和时间周期等多个属性判断是否满足吸烟动作,该方法在自建的数据集上取得了不错的效果。徐婉晴等人[71]考虑到不同图像中人体大小不同,提出采用关键点之间距离比值的方法代替欧式距离,由大量实验得出吸烟动作的最佳比例,通过判断是否满足最佳比例的持续时间来识别吸烟动作。

表6 基于人工构建吸烟动作检测模型比较Table 6 Comparison of smoking action detection models based on artificial construction
4.2 时空特征构建
基于骨骼数据的时空模型在数据处理方面通常会将人体骨骼数据映射成伪图像,分别将关键点序列时间动态编码为行变化,每一帧的空间结构表示为列,将关键点三维坐标映射为图像的RGB 三个通道,然后使用CNN模型进行特征学习和识别[72],时空模型检测流程如图9 所示。但是上述对骨骼数据的编码方式过于依赖数据集,并且人的平移和动作尺度可能会影响最终的伪图像映射结果。随着图像分类网络模型在不同数据集上的出色表现,Wang 等人[73]使用迁移学习将现有CNN模型进行微调而无需重新训练整个深度网络。通过颜色编码将关节轨迹的空间结构和动态信息都表示成三种纹理图像,然后将这些纹理图像送入模型进行分类。但这种方法比较复杂,在将三维骨架投影到二维图像时可能会丢失一些重要的信息。Liu等人[74]在Du等人[72]的基础上提出基于热力图的表示方法来编码时空骨架关节。将骨架序列建模为一组五维点,并使用数据可视化将其进一步编码为一系列彩色图像。但也存在类似的问题。Li 等人[75]针对上述问题提出平移尺度不变的图像映射方法,他不仅可以避免骨架数据平移和尺度变化带来的影响,还能将骨骼数据映射到0~255范围内的彩色图像。在此基础上Liu等人[76]提出了一种增强骨骼可视化方法,将骨骼序列表示为一系列视觉和运动增强的彩色图像,以紧凑而独特的方式隐式描述了骨骼关节的时空特征,增加彩色图像的辨别能力。将动作序列表示为骨骼数据,进而映射为彩色图像的方法能够充分利用CNN 图像特征提取的优势,提高行为识别的准确率。这种思想后续也被广泛应用于基于CNN和骨骼数据的行为识别研究中。

图9 基于时空模型的吸烟动作特征提取流程Fig.9 Extraction process of smoking action feature based on spatiotemporal model
综上所述,对骨骼数据的处理大多基于Du 等人提出的骨架图像的改进版本,仅通过隐式的关节关系来学习运动表示。近几年,计算机视觉研究界一直在研究如何在视频中建模时间动态来应用3D 人体动作识别,部分学者关注到显式地使用关节关系可以增强时间动态编码。因此新型骨架图像的表示方法陆续被提出。Yang 等人[77]考虑到若将所有关节按固定顺序连接起来会导致骨骼语义的缺失,为此提出了一种树结构骨架图像表示来保存空间关系。采用深度优先遍历对骨架图像进行重新设计,增强了骨架图像的语义。Caetano 等人[78]在此基础上引入树结构和参考关节图像提出一种新型骨架图像表示方法。除此之外,Li等人[79]通过学习几何代数时空模型的形状运动表示,对骨骼数据进行重新编码。
4.3 时序特征构建
在数据处理方面,基于骨骼数据的时序模型将所有人体骨骼关键点逐帧表示为向量序列,然后输入骨干网络模型获得预测结果,模型检测流程如图10 所示。Du等人[80]第一次使用分层循环神经网络,为基于骨架的动作识别提供了端到端的解决方案。通过手工创建的循环神经网络(recurrent neural network,RNN)子网对相邻部分(双臂、两条腿和躯干)的关系进行建模(图11(a)),但是忽略了非相邻关节部分之间的关系。Zhu等人[81]通过在模型中加入不同类型的正则化项,可以利用非相邻部分之间的关系,实现了骨骼关节特征共现的自动学习。Shahroudy 等人[82]提出了另一种解决方案,他们将记忆单元分离为基于部分的子单元,并通过连接基于部分的记忆单元学习非相邻部分关系。虽然以上两种方法利用了身体各部分之间的关系(图11(b)),但模型识别准确率不高。Liu 等人[83]提出了一个更详细的划分,他们专注于相邻关节并构造邻接图设计出骨架树遍历算法。通过在输入序列中排列最相关的关节节点来提高网络的性能(图11(c))。但这种以树的形式遍历骨架会忽略非相邻节点之间的关系。随着几何关系建模的发展表明,在非相邻关节之间添加关系可以进一步提高网络识别性能。Zhang等人[84]设计了8组几何关系特征来表示相邻关节和非相邻关节之间的关系(图11(d)),取得了很好的实验结果。Zhang等人[85]在考虑到不同视角下的骨骼数据可能会影响识别结果,为此引入了一种新的视角适应方案,在动作发生过程中自动调节观察视角以达到最先进的识别效果。
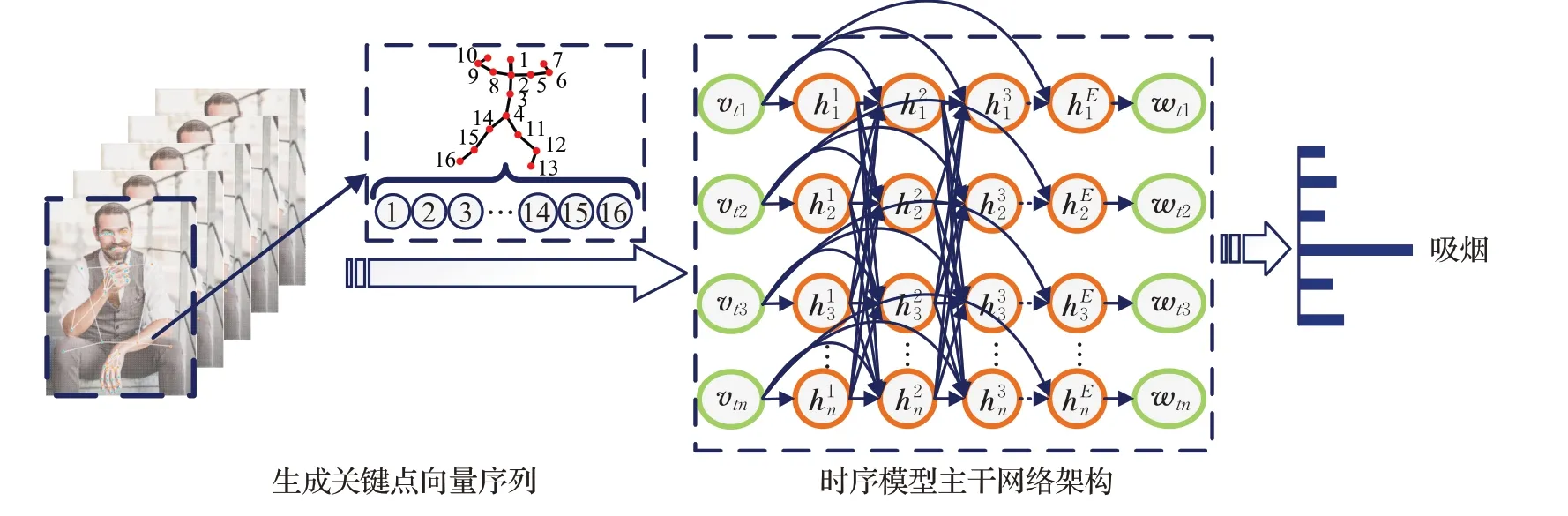
图10 基于时序模型的吸烟动作特征提取流程Fig.10 Extraction process of smoking action feature based on time series model

图11 不同关节间的特征建模Fig.11 Characteristic modeling between different joints
4.4 拓扑特征构建
一副人体骨架可以抽象为两种元素即关键点和骨骼,关键点的作用是连接两根相邻的骨骼,拓扑模型的数据处理就采用这种方式。因此可以把骨架简化为一个由点和边所构成的拓扑图。尽管CNN 和RNN 在基于结构规则的欧式空间数据的特征提取中取得很好的效果,但是不适用于非欧式空间生成的图结构数据。2018年,Yan等人[86]第一次将图卷积(graph convolutional networks,GCN)应用于骨骼行为识别中,并将图卷积网络扩展为时空图卷积(spatial temporal graph convolutional networks,ST-GCN)模型。其中每个节点对应人体的一个关节,节点边包括两种类型,即符合关节自然连通性的空间边和跨越连续时间步长的连接相同关节的时间边。在此基础上构造了多层时空图卷积,实现了信息在空间维度和时间维度上的集成,拓扑模型检测流程如图12 所示。这类方法要优于传统骨架模型,ST-GCN可以捕获动态骨架序列中的运动信息,实现对RGB模态的补充。

图12 基于拓扑模型的动作特征提取流程Fig.12 Extraction process of action feature based on topological model
但是这种固定的骨架拓扑图仅能捕捉关节间的局部物理依赖性,可能会遗漏隐式关节相关性。为了捕获更丰富的依赖关系,Thakkar 等人[87]引入基于部分的图卷积网络,他们将骨架拓扑图划分为四个子图,子图之间共享关节并使用几何和运动特征来代替每个顶点的三维关节位置。使用基于部分的图卷积网络可以更好消除与对象的交互歧义。除此之外,Li等人[88]提出一个编码器-解码器结构从数据中自适应学习图形,以捕获特定于动作的潜在依赖关系,从而获取有用的非局部信息。Shi等人[89]在2019年首先提出将骨架表示为一个有向无环图并对其建模实现信息传播。然而在这种基于手动设定拓扑图的方法中,对于分层GCN 和不同动作样本来说可能不是最优的,针对这一问题Shi 等人[90]在此前的研究基础上提出使用反向传播算法以端到端方式自适应学习骨架拓扑图,以提高图构建模型的灵活性和通用性。通过上述讨论,最常见的关注点仍然是数据驱动,想要的只是获取人体骨架序列数据背后的潜在信息,尤其是骨骼数据本身具有时空耦合性。而且在将骨骼数据转化为拓扑图时,如何确定关节和骨骼之间的连接方式仍然是未来研究的重点。
4.5 小结
分析上述吸烟动作检测方法可分为人工特征构建和深度学习特征提取两种方式。基于人工设定的吸烟动作特征可解释性强且特征模型构建简单。相比于深度学习方法不需要训练。表6 列举了不同人工特征构建方式,随着特征属性不断增加,模型在自建数据集上的准确率得到不断提升。但利用自身先验知识定义特征主观性较强,过于片面,难以有效捕获数据之间的复杂关系。所以不能很好表征整个吸烟动作状态,导致模型的泛化能力不强。深度学习特征提取方法相比于人工构建特征较为客观,但模型需要依赖大量样本训练。其中时空模型在动作识别空间域的特征提取上有一定优势,但忽略了人体骨骼固有的结构信息。而拓扑模型相比于时空模型不仅考虑到相邻关键点之间关系,而且能够学习骨骼序列的时空关系,更符合人体结构。但是他们对处理长序列动作而言,捕获时序信息的能力不强。而时序模型依据它的“记忆”能力可以随时间推移学习到动作变化,对处理时序分类任务更突出。因此,混合模型基于上述三种模型的骨干网络架构组合而成,一般采用其中的两种。它的输入需要依据所组合模型的数据处理方式,输入相应关键点信息表示方式。混合模型通过组合不同网络可以达到特征互补和信息增强等效果,更适用于处理动作识别任务。然而不同网络的结合会导致参数量增长、模型训练时间长等问题,对混合模型的优化方法也有待发掘。表7 分别给出了不同模型在NTU RGB+D数据集上的准确率实验,其中数据集涉及吸烟、喝水、打电话等多种日常动作。评价标准CS 和CV 分别代表按照人物和按照相机划分训练集和测试集。

表7 深度学习特征构建骨干网络相关研究Table 7 Research on deep learning features to build backbone networks
结果表明,在该数据集上仅使用拓扑模型比仅使用时空模型的平均准确率高约5%,比时序模型的平均准确率高约7%。这也证明图卷积网络在基于骨骼数据的动作识别领域更具优势。混合模型通过组合不同网络得到的准确率也较高,但模型复杂度过高会直接导致模型检测效率下降。为了学习更全面的动作特征,已有学者综合考虑提出将人工特征构建方法与深度学习特征提取相结合。文献[111-112]通过显式计算骨骼关节的矢量几何性质等属性来编码时间动力学,有效约束补充骨骼时空动态信息。然后输入到已提出的深度学习模型中进行高级特征学习。基于骨骼数据的吸烟动作检测涉及多方面技术细节,应用范围也较为广泛。例如室内室外公共区域和一些特殊场景,其发展趋势不仅受到诸如深度学习等方法的推动,还面临着实际监控场景的迫切需要。Zhang 等人[113]针对建筑工人在非吸烟区违反吸烟行为进行检测,使用AlphaPose 算法获取人体骨骼信息,利用ST-GCN网络提取吸烟动作特征对吸烟行为进行初步识别。Jiao 等人[114]依据人工特征与自学习特征相结合的方式对驾驶员吸烟行为进行有效判定。通过人为定义骨骼结构向量,计算关键点之间矢量角度和模量比作为人工特征。将原始骨骼数据作为自学习特征,通过这种方式不仅可以避免人工特征构建的主观性,模型准确率也大大提升。人工定义特征结合自学习的深度特征更有利于吸烟行为检测准确率的提高。
5 总结与展望
本文深入总结分析了近年来吸烟检测研究现状,对非计算机视觉的吸烟检测方法进行简要介绍,重点围绕基于计算机视觉的检测方法进行分类总结。分别从烟雾多特征、烟支目标、吸烟动作三个方面分析总结。其中吸烟烟雾和烟支目标是吸烟检测最具代表性的特征,吸烟烟雾的检测环境复杂多变且烟雾本身具有易扩散性,导致烟雾检测停滞于图像处理阶段。随着目标检测模型的愈发完善,烟支目标检测逐渐成为吸烟检测的主要方法,相关研究围绕改进小目标检测模型开展。考虑到吸烟动作的时序规律性,从行为识别角度出发对吸烟动作展开研究可能是未来发展方向。虽然目前的研究成果已经取得了较好的进展,但仍存在一些问题。例如大部分吸烟检测方法只是在理想状态下实验的,无法适用于真实的吸烟场景。由于缺少统一数据集导致模型好坏无法衡量。并且随着准确率的提高模型复杂度也随之增加。侧重于解决当前问题,本文提出以下展望。
(1)完善吸烟数据集。常用吸烟检测数据集并不多,来源主要是利用Kinect摄像机自行获取多模态吸烟动作信息或截取网络图片和视频。因此构建大规模高质量的吸烟数据集更有利于提高模型适用性。且应考虑不同的场景,例如图书馆、加油站、车站等公共场所。未来可以利用摄像头传感器拍摄多角度、多类型的图片作为吸烟检测数据集,以便模型能更好适应不同场景的吸烟行为检测任务。
(2)构建完备的烟雾特征工程。目前的烟雾检测主要基于烟雾的视觉特性与运动特性,特征算子基本靠先验知识手工设计。未来研究需要跳出传统框架,多利用机器学习或深度学习方法寻找更能体现烟雾本质的特征。
(3)优化烟支小目标特征提取网络。烟支目标相比常规目标可利用的像素较少,导致难以提取到较好的特征。除了3.3 节总结的不同改进策略外,可以利用多尺度学习同时学习深层语义和浅层表征信息;还可以结合生成对抗网络提高烟支目标分辨率。
(4)细粒度吸烟动作识别。细粒度行为识别在智能辅助领域极其重要,它更关注细微的时空语义差异。因此了解吸烟动作的细节执行方式,设计出更细致的行为识别特征提取器,能更好区分吸烟、喝水、托腮等易混淆动作。
(5)多方法融合。通过组合不同方法进一步提高吸烟检测模型精准率。例如在提取图像中烟支空间特征的同时,结合吸烟动作时序特征构建新型时空特征模型,或结合烟雾烟支检测。但需要考虑不同模型的机制匹配构建合理的联合算法,而不是简单的模型组合。
(6)构建轻量级网络模型。随着数据信息载体转移到移动端,网络模型的轻量化就尤为重要。优化模型的参数和计算可以从调整模型的设计结构或分解模型参数这两个方面入手。在实际应用场景中,模型不仅要适用于嘈杂的背景环境,还要达到实时响应的结果。因此期望设计低延时高性能的吸烟检测模型并应用于实际场景。
除此之外,吸烟检测还需要关注特殊场景下的应用情况。例如当烟雾多特征检测遇到浮尘等能见度低的环境时,会对烟雾的特征提取造成影响。此时可以结合浮尘传感器或利用烟支燃烧温度点另作判断。有研究发现烟支在抽吸过程中,烟头达到800~900 ℃,在近红外图像上形成一个热点,提出的方法旨在检测吸烟者头部区域周围的热点[115]。在吸烟者侧身情况或有遮挡条件下,解决被遮挡目标在复杂场景的检测问题。目前已有研究针对遮挡目标从数据集和改进检测算法角度着手[116]。在行为识别领域,将多视图数据进行三维重建,构建全方位的三维信息[117]。进一步设计基于三维视频数据的特征提取器以解决遮挡目标的检测问题。因此如何有效处理吸烟行为检测的特殊情况也是未来研究的重点和难点之一。
