基于LightGBM和贝叶斯优化的车辆碰撞检测模型
2024-01-16任小强王官云
任小强,王官云
(西南交通大学希望学院信息工程系,四川 成都 610400)
随着人民生活水平的提高,汽车数量越来越多,车辆碰撞问题时有发生,往往造成财产损失和人员伤亡。如何精准检测车辆是否发生碰撞具有重要研究意义。但是车辆信息非常多,而用户路况信息和用户使用偏好不同,很难找到一种准确识别碰撞的方法。郭烈等人[1]采用图像检测和分割算法对车辆碰撞进行检测识别,马小龙等人[2]通过广义帕累托分布(Generalized Pareto Distribution,GPD)建立制动减速度分布模型,得到车辆的碰撞概率,高利等人[3]建立环境复杂度量化模型,使得碰撞预警的正确率达92%,宋鑫[4]利用智慧灯杆物联网数据采集平台,解决极端复杂环境下的车辆碰撞检测这一难题。传统的车辆碰撞识别方法需要大量的人力物力,周期长,成本高。近年来,机器学习的快速发展促进了相关算法在智能交通领域中应用研究,国内外学者提出了集成学习模型作为一种低廉高效的车辆碰撞检测方法,如Random Forest、AdaBoost和XGBoost等。例如,彭一川等人[5]提出一种新的基于权重的欠采样提升算法(weight-based under sampling boost, WUSBoost),计算车辆的平均碰撞风险;申海洋等人[6]提出一种基于机器视觉和深度学习的车辆碰撞预警算法。虽然这些模型在车辆碰撞检测中取得了不错的效果,但是相对而言,增加了算法复杂度,预测精度也还有较大的改进空间。轻量化梯度促进机(Light Gradient Boosting Machine,LightGBM)[7]是一种基于决策树的集成算法(Gradient Boosting Decision Tree,GBDT),支持并行学习,可以高效处理大数据,解决了计算效率低、实时性差等问题,广泛应用在各个领域[8-15],文献研究表明LightGBM相较传统算法具有较高的精度,同时还兼顾提升了模型的训练效率。但是,LightGBM算法的分类模型也存在一些挑战,如LightGBM算法模型中的关键参数需要调整以获得理想的准确率,传统优化算法容易达到局部最优解,甚至导致早熟收敛。本文借鉴上述文献中的观点,首先利用公开数据集构建碰撞特征,其次提出一种经贝叶斯优化的改进LightGBM算法,最后使用该算法解决车辆碰撞检测问题。
1 特征工程
在数据挖掘领域,特征往往起着很重要的作用,不同特征集决定了机器学习预测模型的质量,好的特征集可以挖掘更多的关联信息,从而得到更加精准的机器学习预测模型。
1.1 特征构建
车辆碰撞是一个连续瞬间过程,瞬间速度变化很快,其它时刻速度变化较小,因此本文通过移位(shift)、运算(diff)、滑动窗口(rolling)运算和原始特征构建车辆碰撞的统计特征,如碰撞时间、主负继电器状态和速度特征,并以速度特征构造车辆瞬时加速度,局部加速度,统计加速度、统计速度等特征描述碰撞过程。三种运算的定义如下,通过这三种运算,利用初始特征,构建的特征如表1所示。

表1 特征名称及其构建方法
shift(x):数据平移,x表示移动的幅度,可正可负,默认值是1,表示数据向前移动一次,移动之后索引位置没有值的,值为NaN。
diff(x):一阶差分,是指数据与平移后数据进行比较得出的差异数据,根据计算差值的方向不同分为向前差分和向后差分。
rolling(x):x为样本点数目,窗口从上到下依次滑动时,会将每个窗口里面的元素按照相应运算进行计算。
1.2 特征选择
本文选择Pearson相关系数从原始连续型特征集中提取特征子集,去除冗余特征和无关特征,相关系数计算公式如式(1)所示,X和Y为一对连续变量,σX和σY为X和Y的标准差;cov(X,Y)为X与Y的协方差。
分析发现整车当前总电流、整车当前总电压与车速、构造特征a_min5的相关性很高,为了避免训练模型过拟合,相关性系数高的特征中仅保留一个特征,数据特征选择后有效特征由最初数据集的20个特征变为14 个,其中包括表1中构建的特征。为了寻找模型的最优输入特征集,本文利用森林算法(Random Forest,RF)对筛选后的特征进行重要性排序,其中a_min5,a_mean5,v_diff1,a_max3,if_off和if_on的重要性程度较高,约占全部特征的95%左右,使用上述6个特征,通过LightGBM算法进行模型训练,车辆碰撞识别结果能够达到98 %左右,因此本文选用这6个特征作为识别车辆碰撞模型的输入,后续超参数的优化都是基于筛选后的特征。
2 车辆碰撞检测算法模型
2.1 LightGBM算法概述
GBDT是一种流行的、有竞争力的、高度稳健且可解释的机器学习算法。它被广泛用于许多机器学习任务,并且优于其他传统模型。但是,在处理海量样本数据时,GBDT运算会消耗大量的时间,效率较低。为了克服这些限制,微软提出LightGBM算法,它是一种新颖的GBDT算法,基于Histogram对特征的分裂进行优化,如图1所示。LightGBM被认为是一种高效的模型,可以处理大规模数据并以更快的训练速度和最小的内存使用量获得更好的准确性,它还支持并行和分布式学习。

图1 直方图优化
LightGBM算法包含两种新技术,分别是基于梯度的单侧采样和专有特征捆绑。给定一个训练数据集,其中x代表样本数据,y代表类别标签,f(x)代表估计函数,损失函数定义如式(2)所示:
决策树可以表示为wq(x),q∈{1,2,┅,J},其中J表示叶子的数量,q代表决策树的决策规则,w是一个向量,表示叶子节点的样本权重。因此,LightGBM将在第t次迭代时以加法形式进行训练,如式(4)所示:
在LightGBM中,目标函数用牛顿法快速逼近,为简单起见,去掉式(4)中的常数项后,公式简化为式(5):
其中gi和hi表示损失函数的一阶和二阶梯度统计量。Ij表示叶子的样本集,并且式(5)可以转换为式(6):
其中IL和IR分别是左右分支的样本集,与传统基于GBDT的技术不同,LightGBM利用带深度限制的Leaf-wise叶子生长策略替代传统的层生长决策树策略,最大程度避免了过拟合,Leaf-wise和Levelwise的对比如图2所示。
图2 Level-wise和Leaf-wise叶子生长策略的对比
2.2 车辆碰撞检测模型
对碰撞样本使用特征向量表示并标记,得到带标签的碰撞样本,在此基础上进行二分类的有监督学习,这样就将碰撞检测特殊问题,转换为机器学习中的通用问题。该模型如图3所示,通过数据清洗及特征提取、特征选择、模型训练和模型碰撞检测几个步骤来实现。首先,进行数据清洗及特征提取,其次是特征选择,选择了合理特征参数,提高模型训练精度,然后使用贝叶斯优化LightGBM超参数,通过输入最优的LightGBM超参数得到最终模型。最后应用测试数据集进行性能评估指标。

图3 碰撞识别模型
从本文构造的特征来看,发生强烈碰撞的分类标签是容易区分的,考虑到模型的泛化能力,分隔阈值设得很大,取非碰撞车辆瞬时加速度v_diff1、局部加速度v_diff2和瞬时速度差v_diff3中最小值的2倍为分割阈值,目的是为了避免过拟合。此外,为了增强树模型的预测能力和增加特征之间的非线性,我们对特征进行交叉修正,如式(10)-(13)所示,使得主要特征与分类特征的相关性更为明显,具有实际意义。
不同超参数组合会导致模型在预测性能上存在很大的差别,因此必须对模型进行调参,搜索出能使模型性能更佳的超参数,常用方法包括人工搜索、网格搜索和随机搜索等[16-18],网格搜索支持并行计算,很消耗内存,随机搜索则不能确保得到全局最优解。贝叶斯优化(Bayesian Optimization,BO)是一种自适应的超参数搜索方法[19],利用目标函数的过去评估结果建立概率模型,寻找最小化目标函数的参数,在效率和精度上都获得更好的效果。本文使用TPE(Tree Parzen Estimator)代理模型和期望改善(Expected Inprovement,EI)采集函数构造贝叶斯算法优化LightGBM参数[20],TPE算法的概率分布定义如式(14)所示,其中e(x)为观测值{x(i)}形成的密度,g(x)为除{x(i)}外剩余观测值形成的密度。
从式(15)可看出,为了能获得最大期望提升,超参数x在e(x)的概率要尽可能大,而在g(x)的概率要尽可能小。通过g(x)/e(x)评估每一个超参数x,在每次迭代中,算法将返回具有最大EI的超参数值。
3 实验仿真与结果分析
3.1 数据集与数据处理
数据集来源于公共数据集Kaggle,主要包括车号、采集时间、加速踏板位置、电池包主负继电器状态、电池包主正继电器状态、制动踏板状态、整车当前总电流、整车当前总电压、车速等20个原始特征[21]。其中训练数据集有3 928 449条数据,其中第20位Label列为标签属性,代表是否碰撞,1表示碰撞,0代表无碰撞,测试数据集有4 285 948条数据。数据清洗对提高模型性能非常重要,包括缺失值处理、异常值处理、删除重复值、类型转化和特征编码等。对于连续性特征变量,缺失值和异常值使用均值填充;对于分类变量,直接删除异常数据。数据集中的数据通常以字符串类型存储,特征编码将字符串类型数据转化为数值类型。对于只有两种取值的特征使用标签编码(LabelEncoder),例如电池包主负继电器状态、制动踏板状态等,用0、1表示两种状态,整车钥匙状态含有三种取值,可以使用独热编码(One-Hot Encoding),它会增加数据特征的数量,经过数据清洗和特征提取后,样本数为19 950条。为了平衡样本数据,对样本数据进行欠采样和过采样,数据欠采样满足以下三个条件:(1)汽车碰撞后电池包主负继电器处于断开状态,即电池包主负继电器状态恒等于0;(2)训练集的所有标签均分布在继电器断开瞬间附近,if_off处于-3~-5的区间,考虑到停车时被追尾,增加车速大于零这个条件;(3)删除启动阶段低于正常车速的数据,这里要求车速在20km/h以上。通过这三个删选条件,测试样本数由3 928 449条变为29 23 559条。此外,车辆碰撞是一个连续过程,将碰撞时间前后5秒内样本标签均标记为碰撞,对训练集标签进行过采样,过采样后训练集碰撞标签由49个变为154个。本实验仿真所用电脑为Windows7系统,配备4GB内存,处理器为英特尔第七代酷睿i5-7200U@2.50GHz。
3.2 仿真结果分析
为了探究特征个数对模型性能的影响,将特征工程得到的特征,使用本文模型进行训练,并在测试集上采用F1-score、查准率(precision)、查全率(recall)进行模型评估,结果如图4所示,当特征个数小于8个时,模型评价指标总体呈上升趋势,此时模型欠拟合;当特征个数大于8个后,因为模型过拟合导致模价指标呈下降趋势;当特征个数为8个时,模型性能最优。
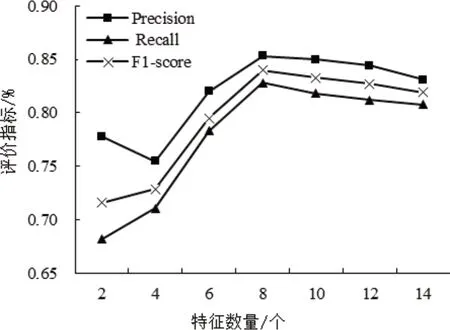
图4 特征数与评价指标的关系
为了建立一个有效的预测模型,将文献[22]中的支持向量机模型(Support Vector Machine,SVM)、文献[23]中的随机森林模型(Random Forest,RF)、文献[24]中的梯度提升决策树模型(eXtreme Gradient Boosting,XGBoost)和本文LightGBM模型进行对比研究。为了结果更加可靠,分别进行3组试验,每组重复测试10次,取其平均值作为模型最终评价指标。各模型预测结果如图5所示,LightGBM模型在实验中的评价指标优于其它模型,其平均准确值约为0.94,平均查准率约为0.97,F1-score值约为0.93。

图5 不同分类器的预测结果
LightGBM参数较多,基于交叉验证的手动调参操作复杂且易影响预测效果,本文采用贝叶斯优化方法调整最佳参数。为了验证贝叶斯优化算法的优越性,将贝叶斯优化与网格搜索、随机搜索以及LightGBM的默认参数进行对比,不同的优化方法选择相同范围的参数空间,并使用运行时间与均方误差MSE作为评估指标。实验结果如图6所示,表中网格搜索的运行时间为其搜索完待选参数空间所需的时间,随机搜索的运行时间为其迭代5 000次的时间,贝叶斯优化的运行时间为其精度不再变化后的时间,即完成收敛所需的时间。超参数列表的顺序为learning_rate、feature_fraction、bagging_fraction、bagging_freq、num_leaves和min_data_in_leaf。

图6 LightGBM超参数优化方式对比
由图6中可以看出,默认参数的碰撞检测精度低,运行时间较长;网格搜索虽然有精度上的提升,但是会花费大量的时间成本;随机搜索的运行时间相比网格搜索大大减少了,而且在精度上也比网格搜索略好一些;贝叶斯优化算法相比网格搜索与随机搜索,在精度上有显著的提升,而且运行时间远远小于网格搜索与随机搜索,所以使用贝叶斯优化算法寻找超参数是有效的。贝叶斯优化LightGBM算法在进行模型预测时,随着不断迭代,模型的均方误差MSE趋于平稳,当迭代次数为200次时,均方误差MSE达到了最小值,此时对应的超参数 learning_rate=0.005,num_leaves=80,max_depth=7,min_data_in_leaf=210,bagging_fraction=0.9,feature_fraction=0.7。贝叶斯优化后的LightGBM模型评价指标提升比较明显,可以满足车辆碰撞识别的要求,对交通管理部门和汽车生产商具有重要的参考价值。
数据集的正负样本不平衡会导致模型预测出现偏差。这里使用数据样本欠采样和碰撞标签过采样技术平衡样本,平衡数据集和不平衡数据集分别输入LightGBM进行分类,实验结果如图7所示,平衡数据集后Precision指标从97.01%提升到98.99%,Recall指标从88.67%提升到98.86%,F1-score从88.64%提升到97.98%,这些结果表明平衡数据集样本可以提升模型的预测性能。

图7 平衡数据集优化方式对比
4 结语
针对车联网大数据碰撞识别问题,本文提出一种基于LightGBM算法的碰撞检测模型。通过数据清洗与特征工程删选特征,欠采样、重采样提高碰撞识别预测的准确性,有效利用了各个特征与碰撞之间的相关性,同时使用LightGBM模型进行车辆碰撞进行识别,运行总时间为300~450 s左右。
