基于BERT 的百科知识库实体对齐
2024-01-16张丽萍赵宇博
高 茂,张丽萍,侯 敏,闫 盛,赵宇博
(内蒙古师范大学 计算机科学技术学院,内蒙古 呼和浩特 010022)
知识图谱(knowledge graph,KG)是使用图(graph)形式实现知识建模与管理的有效手段[1],在教育领域,知识图谱由于其出色的知识建模能力备受研究者的关注[2]。Yang 等[3]针对高中阶段课堂的答疑效果较差问题,构建了基于高中数学课程知识图谱的问答系统,为学习者提供知识反馈。金天成等[4]构建了面向程序设计课程的知识图谱,为学习者推荐习题资源,提升学生的程序设计实践能力。视觉、听觉是人类孩子认知世界的重要方式,对于人类理解客观事物有很大的价值[5]。数据来源包括课程教材、百度百科以及国家教育公共服务平台等知识社区[6]。李振等[7]提出在构建教育知识图谱的过程中要汇聚多模态资源,为学习者提供个性化的知识服务。李艳燕等[8]则从学习需求的角度探讨学科知识图谱中多模态学习资源的重要意义。
实体对齐是判断不同来源的实体是否对应同一个现实对象的任务,通常被用于多个知识库的合并过程中[9]。已有研究为了扩充知识图谱中实体的多源描述信息,将百度百科、互动百科社区[10]作为知识来源对齐词条信息,采用的方法多为基于相似度计算的方法,但该种方法需要人工参与阈值的设定且语言模型本身没有经过领域样本的训练微调,不能很好地应用至下游的实体对齐任务。
针对上述问题,本文探索高效的将不同来源的多模态资源映射到同一实体的技术方法,提出微调BERT 词嵌入的实体对齐模型,利用领域样本微调BERT 词嵌入的分类模型,并针对样本不均衡问题提出负采样策略,优化模型性能,将测试的简介文本对输入微调后的BERT 模型计算相似概率,选取相似概率排名最高的简介文本对应的词条资源进行对齐。
1 相关工作
1.1 实体对齐
相关学者考虑到现有知识图谱中文本信息对于课程知识表达的局限,利用实体对齐技术扩充知识图谱中实体的多源描述信息。将百度百科、互动百科社区作为知识来源对齐词条信息,第一种方式是基于相似度计算的方法,利用余弦距离、欧式距离求出实体间的实体名、属性、简介文本的相似度并设定相应的阈值,如果相似度大于阈值则对齐,否则不对齐。另一种方法,将实体对齐建模成具有约束条件的分类问题[11],使用实体名、属性、简介文本或者其他信息对特征送入二分类模型,获得相似与不相似概率,以此判断实体是否对齐。
第一种方式是基于相似度计算进行实体对齐。刘振鹏等[12]将潜在狄利克雷分布(latent Dirichlet allocation,LDA)主题模型结合余弦相似度的计算方式应用于百度百科和维基百科的简介文本对齐研究中,与TF-IDF 等方法相比表现更好。周炫余等[13]在初中数学知识图谱构建的研究中,考虑到从百度百科和互动百科网站爬取的半结构化数据和教材中的非结构化数据之间没有建立联系,导致实体的数据来源零散和权威性不够等问题,提出基于层次过滤思想的知识融合模型,很大程度上丰富了课程实体的多种描述信息。其中,对百度资源和教材资源均经过预处理层、字符串匹配层等五个环节进行实体对齐。在该过程中,除了使用传统的字符串匹配操作,还在实体融合层中,赋予属性和简介文本不同的权重,综合计算词条的相似度。文献[14]提出一种对齐百度百科和互动百科词条的方法。首先,使用基于编辑距离的算法计算词条之间的属性相似度,选取最大值与设定好的阈值作比较,若大于则继续计算简介文本的相似度,否则利用BERT 模型计算相似度找到最大值继续比较;其次,使用BERT+余弦距离的方式计算简介文本对的相似度;最后,通过加权融合的方式计算属性和简介文本整体的相似度,选取相似度最高的实体对作为最终输出。王雪鹏等[15]分别计算实体属性名称、类别标签和简介文本的相似度,然后赋予不同的权重,计算百度百科和互动百科中的实体是否对齐。乔晶晶等[16]同样面向百度百科和互动百科知识库,提出融合实体名称、实体简介文本等多种特征的百科实体对齐方法,获得了较好的效果。
第二种方式是将实体对齐任务看作二分类问题。张佳影等[17]针对不同医院对同一项检查中的指标称谓不同,导致区域间医疗共享受到影响的问题,将实体名称、缩写以及参考值的相似度特征作为输入,输入二分类模型进行实体对齐,较好地完成了指标项对齐的任务。文献[18]将实体对齐视作NLP 中的句子对分类任务。首先,构建候选实体对,将其标注为匹配或者不匹配;其次,将实体对的属性值连接,输入基于BERT 的二分类模型中进行微调;最后,将候选实体对输入微调后的BERT 模型,输出预测标签,获取最终匹配的实体对。
在实体对齐任务中,计算相似度的方式是比较常见的方法。然而,这种方法需要依赖于阈值,即对齐的阈值。研究者通常依靠人工分析实体之间的相似度来选择阈值,这种方法不仅缺乏说服力,而且需要投入相当的人工成本,迁移能力也不强。相比基于相似度计算的方式,基于二分类的实体对齐方法不需要人工制定阈值。但是,如果简单地使用相似概率大于50% 来判断相似与否,那么效果通常不太好,因为二分类任务得到的相似概率通常很大。如果将其用于排序,即如果A、B的相似概率大于A、C的相似概率,证明B相较于C与A更相似,则可以获得更好的效果。
1.2 BERT 模型
BERT 模型的实质是一个语言模型。语言模型经历了Word2vec、ELMO(embeddings from language models,ELMO)、GPT(generative pre-training,GPT)、BERT 等几个阶段,前几个语言模型均存在一些不足,如Word2vec 模型训练出来的词向量属于静态词嵌入,无法表示一词多义。GPT 则是单向语言模型,无法获取一个字词的上下文信息。而对于BERT 模型而言,它是综合ELMO 和GPT 这两者的优势而构造出来的模型,能够很好地兼顾多义词处理和上下文的语义表示信息。BERT、ELMO 以及GPT 的模型结构如图1 所示。
BERT 模型可以根据下游的工作对各个参数进行调整,这就使向量表示不再是固定的,它是一个很好的解决单字多义方法。利用BERT 模型进行词嵌入是当前命名实体识别、语义相似度计算等自然语言处理任务研究的一个热点方向。首先,将训练文本转换成原始词向量E1,E2,…,EN作为输入;其次,对输入的语料数据进行训练并调整训练参数,目的是在具体的下游任务中得到更精确的贴合领域的表示信息。BERT 模型通过无监督的方式训练,采用基于“Masked”的遮蔽语言模型和下一句预测的方法,能够有效提取词级别和句子级别的特征。遮蔽语言模型通过随机遮盖少部分的词,训练模型预测遮蔽部分原始词汇的能力,以得到更丰富的上下文特征。下一句预测的方法通过训练模型判断句子之间是否具有上下文关系,进而对其进行标注,能够获取更多的句子级特征。
BERT 模型的关键在于Transformer 编码结构,其由自注意力机制(self attention)与前馈全连接神经网络组成。相比于传统的RNN 神经网络及其改进形式LSTM,Transformer 具备更远距离序列特征的捕捉能力,Transformer 的编码结构,如图2 所示。
自注意力机制的原理是计算文本序列中词与词之间的相互关系,依据这些相互关系所体现出来的不同词之间的关联程度以及重要程度调整每个词的权重,进而获得每个词新的特征表示,该种特征表示在表征词本身的同时也蕴含了其他词与这个词的关联,可以有效地获取文本中全局的语义特征表示,计算公式为

图2 Transformer 编码结构Fig.2 Transformer encoding structure
其中,Q,K,V分别表示查询向量,键向量和值向量,dk则表示输入向量的维度。
Transformer 编码结构为多头注意力机制的形式,也可以理解为将自注意力机制的模式多复制了几次,目的是为了使模型能够在多个表示子空间下学习相关信息。与单头注意力机制相比,可以获取多维度信息,使得词向量的表征更为准确。具体实现过程是对Q、K、V进行多次的线性映射,并将得到的结果进行拼接,如式(2)—(3),
将Transformer 结构中注意力机制的输出表示为Z,则前馈全连接神经网络可以表示为式(4),其中b1和b2表示偏置向量。
考虑到自注意力机制不能有效提取词的位置信息,Transformer 架构引入位置向量,将词向量和位置向量融合作为模型的输入。此外,为解决模型训练过程中出现的梯度消失问题,下一层输入包含了上一层的输入与输出信息,图2 中的残差连接与归一化层就包含了上一层的输入与输出信息,归一化是从加快神经网络训练速度的角度出发进行设置的。
1.3 softmax 损失函数
基于神经网络的分类任务,分类器性能对分类效果的影响非常关键。通常模型最后一层全连接层的特征是文本信息在特征空间的映射,对全连接层的输出使用jaccard、余弦距离等度量方式比较特征之间的相似度,进而完成特征分类。分类模型中常采用softmax 损失函数解决多分类任务,训练过程中通常在最后的全连接层加入softmax,之后计算交叉熵损失函数,如式(5)。
其中,n和N分别代表训练样本数量和训练类别的数量,y代表训练样本所对应的标签,Wj表示第j个类别的权重表示,fi是第i个样本在全连接层输出的向量表示,θ是向量之间的角度,bj是第j个类别的偏置。
2 微调BERT 词嵌入的百科实体对齐
以百度百科知识库作为已知知识库,互动百科作为待融合知识库,对于百度百科知识库的每一个词条对应的简介文本,利用微调BERT 的分类模型,遍历互动百科中的实体简介文本并筛选相似概率最高的简介文本对。同时,针对数据集中的样本比例不平衡的问题,利用负采样的策略填充负样本,进一步提升模型的AUC 值。
应用BERT-softmax 分类模型进行实体对齐,模型结构如图3所示,其输入为两个简介文本句子,首先对其进行token 切分,然后拼接:句子的开头设置一个[CLS]符号,句子的结束设置[SEP],形如“[CLS]边没有方向的图称为无向图。[SEP]无向图是指一个二元组
将token 序列转换为BERT 可以接受的输入形式。首先,将token 映射到预训练的词向量中,获取token embeddings,用来捕捉token 之间的语义和上下文信息;其次,每个token 分配segment embeddings,代表每一个token 其所在的句子标记,将百度百科简介文本中的segment embeddings 都设置为0,代表第一个句子,互动百科简介文本中的segment embeddings 都设置为1,代表第二个句子;最后,每个token 分配position embeddings,表示token 在句子的 位 置 信 息。将token embeddings、segment embeddings、position embeddings 拼接并输入至BERT 模型中,BERT 输入的形式化表示如图4 所示。接着通过BERT 模型中的12 层Transformer 学习数据结构文本的语义表示,编码上下文语义信息,获得输出hb。这里的hb是特殊标记[CLS]的输出向量,其他字符向量的输出可以代表字符的语义信息,而特殊标记[CLS]可以很好地代表整个序列,作为分类器的输入更有用。

图4 BERT 输入的形式化表示Fig.4 Formal representation of BERT input
考虑到深度学习模型具备大量的超参数,且本文用到的模型数据样本较少,因此将BERT 模型的输出连接随机失活层(dropout)解决模型可能出现的过拟合问题。作为一种可选择的神经网络训练策略,dropout 能够随机地让神经元的激活值不进行工作,使不同隐层节点之间的相互作用减少,增强模型的泛化性能,有效预防模型过于依赖局部特征的不利情况。具体流程如下:(1)将网络中的隐藏层神经元暂时地从特定概率中剔除;(2)在该网络中向前传播该输入,然后在该网络上逆向传播该输入,并在每个batch_size 完成后,根据随机梯度降低算法更新相应的权重W和偏置b;(3)重新生成被丢弃的神经元,在这个时候,被抛弃的神经元参数不会被抛弃,同时更新未被丢弃的神经元参数;(4)迭代步骤(1)—(3)。经上述步骤获得hd。
使用Dense+softmax 处理BERT 模型的输出,Dense 是全连接层。将BERT 模型的输出向量连接dropout 层获得hd,如公式(6)。在全连接层进行线性映射,利用softmax 函数进行归一化,输出对应类别的概率,以预测两个文本对之间的语义关系,如公式(7)。
其中,Wp和bp分别代表权重和偏置向量,hd表示dropout 层的输出。运用交叉熵损失函数来度量预测标签与实际标签的差值,依据交叉熵损失函数得到的梯度优化BERT 内部结构参数和softmax 参数,对模型进行迭代微调,直到有效地提取抽象的语义特征。
负采样策略的实现过程如下。将简介文本对输入微调后的BERT 分类模型,会输出相似和不相似的概率,将每一个百度百科简介文本对应的简介文本匹配概率进行排序并存储,排序依据概率越大排名就越高的原则,在每个候选实体被排序和存储后,将得分最高的句子作为最终预测的结果。通过分析发现,利用爬虫获得的简介文本对构成的数据集多数为正样本,这会导致模型学习不到更多的负样本特征,对负样本识别困难。针对上述问题提出负采样策略:首先,对于每一个百度百科简介文本,遍历经过分类器筛选后的互动百科简介文本集合,并根据概率对其进行排序,将排序结果存储;其次,根据需要填充的负样本数量,遍历每一个百度百科简介文本对应的排序列表,选取相似概率最低的M个简介文本对(M依据所需的负样本数量制定)进行存储,从存储结果中选取一定数目的简介文本对进行标记并作为负样本扩充数据集;最后,将扩充后的数据集输入至微调后的BERT+softmax 模型中继续训练,不断地调节神经元的权重,使其能够持续地改善模型的预测性能。
3 结果分析
3.1 数据来源
为汇聚不同来源知识社区的多模态资源,搭建实体对齐训练模型,构建相应的数据集。由于目前还没有公开的用于课程资源实体对齐的数据集,所以通过领域专家定义数据结构课程文本中的实体,在百度百科和互动百科知识社区进行爬虫,获取包含属性、简介文本、图片和视频的词条资源。选取其中的简介文本对构建数据集,去除描述完全相同的简介文本,得到百度百科、互动百科的简介文本对200 对,中间用空格隔开,如果两个实体的简介文本不完全相同、但表达的是同一个实体的语义,则将其标记为1,反之标记为0,标记同样与文本用空格隔开。将数据集划分为train.csv 和test.csv,比例为8∶2,train.csv 包含160 对,test.csv 包含40 对。
3.2 参数设置
实体对齐实验的配置信息和参数设置如表1—2 所示。

表1 配置信息Tab.1 Configuration information
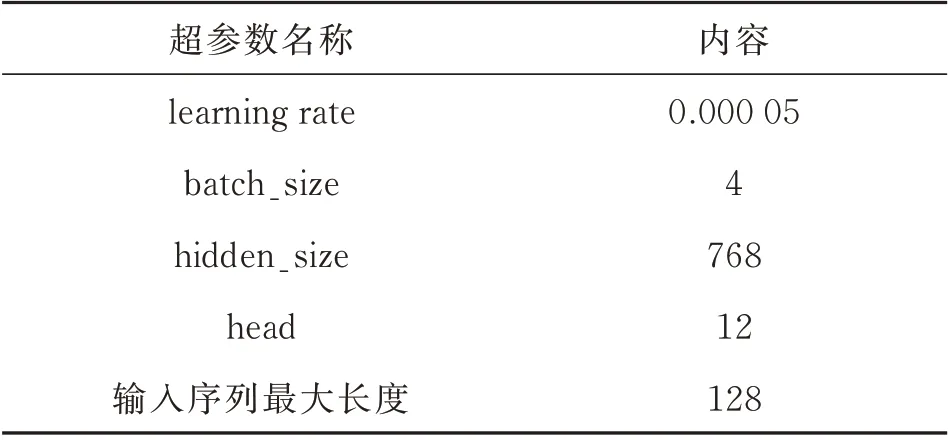
表2 实验参数设置Tab.2 Experimental parameter settings
3.3 评估指标
微调BERT 词嵌入的分类模型,将其应用到简介文本对齐的任务中,优化模型参数和权重,利用微调后的BERT 模型遍历文本对,获取相似概率并进行排名,选取相似概率最高的作为最终对齐的简介文本对。主要针对BERT 模型的微调过程以及依据BERT+softmax 模型输出的相似概率进而排序的预测结果进行评估。
本文微调BERT 模型的下游任务是分类任务。传统分类器大都是根据正确率进行评价,如公式(8),即正确识别出的样本量占全部样本量的比例。但这样的评价方法也有其局限性,在一些分类任务的具体应用中,数据往往存在类别不均衡的情况,某一类样本数目远超其他类型。在此条件下,分类器的效果将会受到影响,预测结果往往会倾向于样本数量较多的类别,导致模型性能下降。相关研究者针对样本不均衡问题,提出使用AUC 值进行评估,如公式(9)。
AUC 常被用于二分类任务的评估,它代表了ROC(receiver operating characteristics)曲线下的面积大小,AUC 的范围介于0.5~1,其值越大,则代表模型的分类性能越好,即对于数据集中随机给定的一对正负样本,正样本的预测值大于负样本的概率越大。在二分类的预测任务中,AUC 不受正、负样本之间比例变化的影响,所以常被用于数据不均衡的分类任务评估中。本文选取AUC作为BERT 模型微调过程的评估指标。
在微调BERT 模型的基础上,将简介文本对输入微调后的BERT 模型获得相似概率,并依据相似概率排名获取最终的预测结果,使用P值、R值和F1 值进行评估,如公式(10)—(12)。
将实体对齐评估中的数据分为测试集数据和预测结果数据,数据类型分为正类与负类。在此之上,其结果分为TP(true positive)、FP(false positive)、TN(true negative)和FN(false negative)四种评估结果类型,代表的含义见表3。
3.4 结果分析
数据集中的数据分布极不平衡,正样本一共有187 条,训练集中有150 条,而负样本仅为13 条,训练集中有10 条。本节设置负采样模型优化策略填充训练集中的负样本,提升模型的准确程度与鲁棒性。首先,对于百度百科中的每一个实体的简介文本,遍历互动百科中的简介文本,依据相似概率对其进行排序;其次,将扩充训练集中负样本的数量分别设置为正样本的1/2 倍、1 倍、3/2 倍以及2 倍进行对比,采用二分类任务中的AUC 指标进行实验结果分析,实验结果见表4;最后,根据不同数量负样本的实验结果保存模型性能最优时的训练参数,将测试集输入微调后的BERT 模型进行排名预测,使用P值、R值和F1 值进行评估。
观察实验结果发现,模型在输入负样本的数量为75 时AUC 值得到提升,说明模型推远了百度百科简介文本与之相对应的互动百科简介负样本之间的语义联系,即给定一对正样本与负样本,预测正样本大于负样本的概率也在提升。在取得N=150,即正样本与负样本数量相当时实验效果最好,但随后N取225、300,负样本多于正样本时模型的性能会下降,可能是负样本太多导致模型学习到了无用的信息。通过分析本文认为添加负样本能够帮助模型有效地学习到百度百科与互动百科简介文本之间的语义关系,提升负样本的预测准确程度,但是过多地添加负样本可能会导致模型学习到无用的信息导致模型性能下降。另一方面,添加负样本可以从数据集的角度均衡正样本与负样本的数量,最大程度地提升模型性能。
AUC 值代表分类任务的性能,其能够有效评估分类任务中正样本、负样本的排序能力。因此选取扩充后负样本数目为150,AUC 值为0.95 时保存模型的训练参数,将测试集中的简介文本对输入模型中,与未采用负采样策略的模型进行对比,并利用P值、R值、F1 值评估实验结果(表5)。观察模型结果发现,采用负采样策略优化后的模型能够使得实验结果的F1 值提升,证明了负采样策略的有效性。

表3 实体对齐评估相关数据含义Tab.3 Meaning of data related to entity alignment evaluation

表4 负采样策略实验结果对比Tab.4 Comparison of experimental results of negative sampling strategy
将本文提出的模型与其他模型比较,对比的模型是当前文本相似度计算较为流行的Word2vec+余弦相似度和BERT+余弦相似度的方法。
Word2vec+余弦相似度:在大量的数据结构文本语料库上通过无监督的方式训练Word2vec 模型,在Word2vec 模型上输入简介文本对,得到词向量表示,然后利用余弦相似度计算句对之间的相似度,选择相似度最大值与人工分析设定的阈值0.76 进行比较,若大于阈值则将词条资源对作为最终对齐的结果。
BERT+余弦相似度:将简介文本对输入至BERT 模型中进行向量表示,计算文本对之间的余弦相似度,同样将文本对对应的相似度最高值与人工分析设定的阈值0.73 比较,若大于阈值则判断两个简介文本对应的词条资源对齐。
选定样本数目为150 时保存本文模型的训练参数,然后将测试集中的简介文本对输入模型中,与上述模型进行对比,利用P值、R值、F1 值评估实验结果(表6)。

表5 采用负采样策略后的模型预测结果Tab.5 The model predictive results by using negative sampling strategy

表6 不同模型对比结果分析Tab.6 Analysis of comparison results of different models
由表6 可知,本文采用的微调BERT 词嵌入的模型取得了最佳的实验效果,同时通过对比Word2vec+余弦相似度和BERT+余弦相似度的实验效果可知,Word2vec 模型表现更好,通过将电子课程教材输入Word2vec 模型训练,并经过结合课程词典生成的词向量表示要优于直接使用BERT 以无监督方式生成的词向量表示,进而带来下游任务准确率的提升。基于二分类的方法实验结果好于基于相似度计算的Word2vec+余弦距离、BERT+余弦距离方法,原因是通过标记正负样本为分类器提供训练数据并微调分类器,分类器通过学习已标记样本的特征,可以更好地区分两个类别的样本。同时利用负采样策略平衡正负样本的比例,不断优化和调整模型参数,使得对齐模型的性能表现更优。
4 结语
本文提出微调BERT 词嵌入的实体对齐方法,通过负采样策略设置不同的负样本数量优化模型性能,然后与基于相似度计算的Word2vec+余弦相似度、BERT+余弦相似度方法进行对比。实验结果证明负采样策略能够有效提升该模型的AUC 值,与其他模型对比也证明本文基于相似概率排名的方式相较于基于相似度计算的方式表现更好,在F1 值上有明显的提升。
