基于损失函数优化的命名实体识别算法研究
2024-01-15樊康男沈春锋王池社
樊康男,沈春锋,王池社*
(1.安徽理工大学计算机科学与工程学院,安徽 淮南 232001;2.金陵科技学院网络与通信工程学院,江苏 南京 211169;3.南京中医药大学常州附属医院,江苏 常州 213003)
命名实体识别(named entity recognition,NER)的主要任务是从文本中识别实体的语义类型(如个人、地点、组织等)[1],在关系抽取、实体链接、知识图谱中具有重要应用[2]。NER算法通常分为三类:基于序列标注的方法[3-4]、基于跨度的方法[5-7]和基于序列到序列的方法[8-10]。这些方法都需要对预测标签进行解码,以获得最终的实体。
针对预测标签解码,标签的设计尤为重要。基于序列标注的方法通常为句子中的每个词元分别分配BIO或者BILOU标签[11-13],以表示每个词元是否在实体内。基于跨度的方法通过记录实体的头尾位置标签确定实体在句子中的位置,同时记录跨度对应的类别标签判别实体类别。基于序列到序列的方法[10]生成不同的数字,分别表示实体词元在句子中的位置和实体对应的类别。在这些标签设计方法中,一个实体对应多个标签,实体中的标签只有全部预测正确才能获取正确的实体,这种限制导致高标签预测精度也可能解码出低实体预测精度。如图1所示,假设标签1、标签2解码获得实体1,标签3、标签4解码获得实体2。上述解码过程存在以下两种情况:情况1,属于实体1的标签全部预测正确,属于实体2 的标签全部预测错误,此时标签的预测准确率为50%,整体的实体预测准确率为50%;情况2,实体1和实体2的标签各有一半预测正确,此时标签的预测准确率也为50%,但实体预测准确率为0%。因此在标签预测精度相同的情况下,同一实体内部的标签预测正确性一致时,整体实体预测性能更好。

图1 多标签组成实体示例
本文选择W2NER[14]为基模型,采用RCL-NER算法,通过关系一致性损失(relation consistency loss,RCL)解决高标签预测精度解码出低实体预测精度问题;同时,在RCL中引入权重因子[15]获得协调关系一致性损失(focal relation consistency loss,FRCL),缓解W2NER中出现的类别不平衡问题。
1 方法及实现
1.1 总体结构
RCL-NER算法总体结构如图2所示。W2NER模型设计关系标签,将NER任务转换成词元间的关系预测任务。首先输入句子到W2NER骨干网络获取全局关系网格,再从全局关系网格生成实体关系网格。全局关系网格用于计算全局损失,全局损失体现句子中所有的预测关系与真实关系间的差异。实体关系网格用于计算实体损失,实体损失确保相同实体内的关系具有相近的预测得分,每个实体关系网格只表示属于相同实体的关系。将全局损失和实体损失结合,获取RCL,最后在RCL中引入权重因子获得FRCL,这两种改进的损失都可以用来代替基模型的损失函数。

图2 总体结构
1.2 实体关系网格生成
输入句子“I am having aching in legs and shoulders”到W2NER骨干网络,生成的全局关系网格如图3左侧所示,全局关系网格中的结点表示词元两两对应关系的向量化表示,可以看作一个三维矩阵V∈N×N×C,其中Vij表示词元(xi,xj)间的关系向量,C表示关系类数,N表示输入句子的长度。句子中存在两个实体aching in legs和aching in shoulders,基于这两个实体生成了图3右侧的两个实体关系网格。

图3 实体关系网格的生成
在全局关系网格中,深色结点代表句子中所有的NNW(next neighboring word)关系,即实体内部相邻词元间存在位置上的相邻关系,如aching in legs实体中的词元对aching和in、in和legs;浅色结点代表THW*(tail head word*)关系,即实体的尾部词元和头部词元之间存在的尾头关系,如aching in legs中的词元对legs和aching。通过THW*关系可以获得实体的头词元和尾词元在句子中的位置以及实体本身的类别信息。按照所属实体的不同,将全局关系网格中的关系划分到两个网格中,获得对应的实体关系网格。
1.3 关系一致性损失
关系一致性损失由全局损失和实体损失结合得到。全局损失使用交叉熵损失,对于每个句子S=[x1,x2,…,xN],训练目标为:
(1)

(2)
(3)

(4)
(5)
1.4 协调关系一致性损失函数

(6)
(7)
(8)
(9)
(10)
(11)
2 结果与分析
2.1 实现细节
本文在两个公共的命名实体识别数据集(连续实体数据集CoNLL-2003[16]和不连续数据集CADEC[17])上进行实验。所有数据集设置和W2NER[14]一致,实体关系网格只用于训练阶段,全局关系网格用于解码实体,超参数如表1所示。

表1 超参数设置
实验随机种子设置为123,用于避免随机初始化带来的误差。以AdamW作为优化器,实现框架使用Pytorch,在NVIDIA TESLA P100 GPU上进行训练。使用4个指标度量性能,分别为F1、准确率(Presicion)、召回率(Recall)和关系实体转换率(relation to entity,R2E)。R2E为自定义的指标,可表示为:
(11)
式中,F1Entity表示实体的F1值,F1Rel表示关系的F1值。
2.2 实验结果
2.2.1 在公共数据集上的结果
使用式(4)作为RCL时,RCL记作RCLmin,FRCL记作FRCLmin。使用式(5)作为RCL时,RCL记作RCLmax,FRCL记作FRCLmax。记录关系和实体的F1、Presicion和Recall,如表2所示。在不连续数据集CADEC上,RCL-NER使用上述4种损失函数后,相比于基模型W2NER都出现了性能提升,实体F1值最大提高了1.81个百分点。当使用FRCLmin损失时,RCL-NER达到最佳性能,指标值优于最新的不连续实体识别模型TOE。

表2 不同模型在两种数据集上的识别结果 单位:%
在连续数据集CoNLL-2003上,RCL-NER使用上述4种损失函数后,相比于基模型W2NER(除FRCLmax外)都表现出性能提升,实体F1值最大提升了0.36个百分点。应用RCLmax损失时性能最好,指标值优于新出的统一命名实体识别模型UIE。
2.2.2 消融实验

表3 不同模型在数据集CADEC上的消融结果
2.2.3 比较关系实体转换率
通过记录RCL的两个变种在数据集CADEC和CoNLL-2003上的R2E值,验证RCL在缓解高标签预测精度可能解码出低实体预测精度问题上的有效性,结果如表4所示。在CADEC上R2E最大提升了1.52个百分点,在CoNLL-2003上R2E最大提升了0.11个百分点。结果表明,RCL达到了设计之初的目标,即通过提高关系实体转换率提升模型性能。
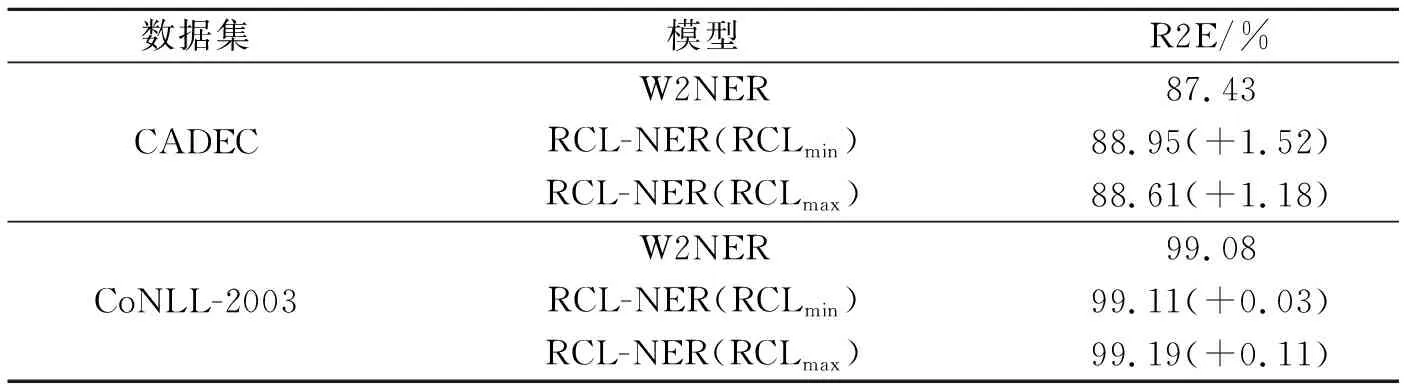
表4 不同模型在两种数据集上的关系实体转换率
表2和表4显示,应用RCL的RCL-NER算法通过提高关系到实体的转换率提升实体预测精度,应用RCL能够缓解高标签预测精度解码出低实体预测精度的问题。
2.2.4 连续实体和不连续实体预测对比
为了验证提出的方法对两类实体的影响,计算了实体在CADEC上预测正确的数量。如表5所示,应用RCLmin的RCL-NER算法预测正确的不连续实体数小幅降低,预测正确的连续实体数量增加。应用FRCLmin的RCL-NER预测正确的不连续实体和连续实体数量都增加。分析认为,相较于应用RCLmin的RCL-NER算法,应用FRCLmin的RCL-NER算法可以同时保存不连续实体的跳跃特性和连续实体的连续特性。

表5 在CADEC测试集中预测正确的不连续实体和连续实体数量
2.2.5 超参β的影响
如式(4)和式(5)所示,实体关系得分可以取最大值也可以取最小值,因此存在RCLmin和RCLmax两种RCL变体。使超参λ固定,分别设置超参β值为e-2、e-1、e-0.5和e-0.1,比较数据集CADEC上超参β对两种变体的影响。如表6所示,RCLmax在超参β=e-2、λ=0.001时性能最好,F1达到73.30%;RCLmin在超参β=e-1、λ=0.001时性能最好,F1达到73.41%。

表6 不同超参β的识别结果 单位:%
随着超参β的改变,应用RCLmax基准模型的实体F1值的改变更加平滑,表明RCLmax对超参不敏感。使用不同的超参β,结果相较于基模型性能都有提升,显示RCLmax和RCLmin对超参β具有鲁棒性。
相较于CoNLL-2003数据集,在CADEC数据集中应用FRCL的RCL-NER算法性能提升更加显著,原因可能是CADEC数据集比CoNLL-2003数据集更加稀疏。如表7所示,在CADEC数据集中,单句子平均实体数为0.83,句子平均长度为16.18;CoNLL-2003中的单句子平均实体数为1.70,句子平均长度为14.38。相较于CoNLL-2003数据集,CADEC数据集中的单句子实体更加稀疏,从而加剧了类别不平衡问题。因此用于解决类别不平衡的权重因子更适用于CADEC数据集。

表7 训练数据集中的句子和实体情况
3 结 语
本文提出了RCL-NER算法,通过改进损失函数实现同一实体内的关系具有相同的得分分布,从而提高了关系到实体的转换率,缓解了高标签预测精度可能解码出低实体预测精度的问题。同时引入权重因子,降低高得分类别的得分权重占比,缓解稀疏数据集中的类别不平衡问题。消融实验结果表明,权重因子和实体损失在改进的损失中扮演重要的角色。实验使用的数据集的种类相较于通用的模型数量较少。不同的超参β对于性能的影响仍有待探索。未来研究应进一步挖掘算法的普适性,使算法在多种类型数据集上都具有较好的性能,同时探索超参β如何对性能产生影响。
